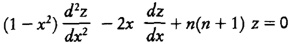El pensamiento matemático Parte II
Morris Kline
Capítulo 19
El cálculo infinitesimal en el siglo XVIII
Y así pasa que los matemáticos de este tiempo actúan como hombres de ciencia, empleando mucho más esfuerzo en aplicar sus principios que en comprenderlos.Contenido:
Berkeley
1. Introducción1. Introducción
2. El concepto de función
3. Técnicas de integración y cantidades complejas
4. Integrales elípticas
5. Otras funciones especiales
6. Funciones de varias variables
7. Los intentos de proporcionar rigor al valor infinitesimal
Bibliografía
El mayor logro del siglo XVII fue el cálculo infinitesimal. De ese manantial brotaron nuevas e importantes ramas de la matemática: ecuaciones diferenciales, series, geometría diferencial, cálculo de variaciones, funciones de variable compleja y muchas otras. El germen de alguna de estas materias estaba ya presente en los trabajos de Newton y Leibniz, y en el siglo XVIII estuvo dedicado en buena medida al desarrollo de estas ramas del análisis. Pero antes de que esto pudiese llevarse a cabo hubo que desarrollar el propio cálculo infinitesimal, pues, si bien Newton y Leibniz habían creado los métodos básicos, restaba mucho por hacer. Había que identificar como tales, o crearlas, muchas nuevas funciones de una variable así como funciones de dos o más variables; había que extender las técnicas de derivación y de integración a ciertas funciones conocidas y a otras todavía por conocer y quedaban por establecer los fundamentos lógicos del cálculo infinitesimal. El primer objetivo consistió en ampliar la materia objeto del cálculo infinitesimal y a ello están dedicados el presente capítulo y el próximo.
Los matemáticos del siglo XVIII extendieron el cálculo infinitesimal y fundaron nuevas ramas del análisis, encontrándose en el proceso con los sufrimientos, los errores, las imperfecciones y la confusión de todo proceso creativo. Elaboraron un tratamiento puramente formal del cálculo infinitesimal y de las ramas del análisis resultantes de él.
Su habilidad técnica fue insuperable, aunque no fue guiada por un elaborado pensamiento matemático sino por agudas percepciones de carácter físico e intuitivo. Estos esfuerzos formales resistieron la prueba de posteriores exámenes críticos y dieron lugar a grandes líneas de pensamiento. La conquista de nuevos dominios de la matemática tiene algo de las conquistas militares: ataques audaces en el territorio enemigo permiten capturar plazas fuertes y, después, estas incursiones han de ser seguidas y apoyadas por operaciones más amplias, profundas y cautelosas a fin de asegurar lo que sólo había sido alcanzado inseguramente a manera de ensayo.
Para apreciar el trabajo y los argumentos de los pensadores del siglo XVIII será útil tener presente que ellos no distinguían entre álgebra y análisis. Al no apreciar la necesidad del concepto de límite y, en consecuencia, los problemas que se introducían por el uso de series infinitas, contemplaban el cálculo infinitesimal, de un modo ingenuo, como una extensión del álgebra.
La figura clave en la matemática del siglo XVIII es Leonhard Euler (1707-83), físico teórico preeminente del siglo y hombre que hay que situar a la altura de Arquímedes, Newton y Gauss. Nacido cerca de Basilea de un padre pastor calvinista, que quería que estudiase teología, ingresó en la universidad de esa ciudad, completando sus estudios a la edad de quince años. En Basilea estudió matemáticas con Jean Bernoulli; decidió dedicarse a esta ciencia y comenzó a publicar a la edad de dieciocho años, ganando a los diecinueve un premio de la Academia de Ciencias francesa por un trabajo sobre la arboladura de buques. Gracias a los hijos de Jean Bernoulli, Nicolaus (1695-1726) y Daniel (1700-82), consiguió un puesto en la Academia de San Petersburgo, en Rusia, comenzando como ayudante de Daniel Bernoulli y sucediéndole pronto como profesor. Aunque Euler pasó unos años difíciles (1733-41) bajo un gobierno autocrático, llevó a cabo una cantidad asombrosa de investigaciones cuyos resultados aparecieron en artículos publicados por la Academia de San Petersburgo. También colaboró con el gobierno ruso en numerosos problemas físicos. En 1741, invitado por Federico el Grande, se trasladó a Berlín, donde permaneció hasta 1766. A lo largo de este período, Euler impartió lecciones a la princesa de Anhalt-Dessau, sobrina del rey de Prusia; estas lecciones, sobre diversos temas —matemáticas, astronomía, física, filosofía y religión—, fueron publicadas más tarde como las Cartas a una princesa alemana y todavía se leen con placer. A petición de Federico el Grande, Euler trabajó sobre problemas de seguros así como diseño de canales y obras hidráulicas. Durante su estancia de veinticinco años en Berlín, también envió cientos de artículos a la Academia de San Petersburgo y la asesoró en sus asuntos.
En 1766, a petición de Catalina la Grande, regresó a Rusia, aunque temiendo los efectos del riguroso clima sobre su debilitada vista (había perdido la vista de un ojo en 1735); en efecto, se volvió ciego al poco de llegar a Rusia, permaneciendo los últimos diecisiete años de su vida totalmente privado de visión. No fueron por ello menos fructíferos esos años que los precedentes; Euler tenía una memoria prodigiosa; recordaba las fórmulas de trigonometría y de análisis así como las potencias, hasta la sexta, de los cien primeros números primos, por no hablar de innumerables poemas y de la Eneida entera. Su memoria era tan impresionante que podía realizar mentalmente cálculos que otros matemáticos competentes realizaban con dificultad sobre el papel.
La productividad matemática de Euler es increíble; sus principales campos de interés fueron el cálculo infinitesimal, las ecuaciones diferenciales, la geometría analítica y diferencial de curvas y superficies, la teoría de números, las series y el cálculo de variaciones, aplicando todo ello a todos los dominios de la física; él fue quien creó la mecánica analítica (en contraposición a la antigua mecánica geométrica) y la mecánica de los cuerpos rígidos; calculó el efecto de perturbación de los cuerpos celestes sobre la órbita de un planeta, así como las trayectorias de proyectiles en medios con rozamiento. Su teoría de las mareas y sus trabajos sobre diseño y velamen de buques contribuyeron a mejorar la navegación; en este dominio, su Scientia Navalis (1749) y la Théorie complete de la construction et de la manceuvre des vaisseaux (1773) son obras sobresalientes. Investigó el pandeo de vigas y calculó la carga de seguridad de una columna. En acústica, estudió la propagación del sonido y la consonancia y disonancia musical. Sus tres volúmenes sobre instrumentos ópticos contribuyeron al diseño de telescopios y microscopios; fue también el primero en tratar analíticamente las vibraciones de la luz y en deducir la ecuación del movimiento teniendo en cuenta la dependencia de la elasticidad y la densidad del éter, obteniendo muchos resultados sobre refracción y dispersión de la luz. En el tema de la luz, fue el único físico del siglo XVIII que apoyó la teoría ondulatoria frente a la corpuscular. Las ecuaciones diferenciales fundamentales del movimiento de un fluido ideal le pertenecen, y las aplicó al flujo de la sangre en el cuerpo humano. En la teoría del calor, contempló éste, con Daniel Bernoulli, como una oscilación de moléculas, ganando un premio en 1783 con su Ensayo sobre el fuego. También le interesaron la química, la geografía y la cartografía, realizando un mapa de Rusia. Se decía que las aplicaciones eran una excusa para sus investigaciones matemáticas, pero no cabe duda que gustaba de ambas.
Euler escribió textos sobre mecánica, álgebra, análisis matemático, geometría diferencial y analítica y sobre cálculo de variaciones que fueron obras clásicas por más de cien años. En este capítulo nos ocuparemos de varias de ellas: los dos volúmenes de la Introductio in Analysin Infinitorum (1748), que constituye la primera exposición unificada del cálculo infinitesimal y el análisis elemental; la obra más amplia Institutiones Calculi Differentialis (1755), y los tres volúmenes de Institutiones Calculi Integralis (1768-70); todas ellas obras señeras. Los libros de Euler contenían todos algunas características muy originales; su mecánica, como se ha dicho, estaba basada en métodos analíticos más bien que geométricos; fue el primero en dar un tratamiento con entidad del cálculo de variaciones. Aparte de los textos, Euler publicó artículos de investigación originales de gran calidad a un ritmo de aproximadamente ochocientas páginas al año durante la mayor parte de los años de su vida; la calidad de estos artículos puede juzgarse por el hecho de que ganó tantos premios por ellos que las correspondientes dotaciones constituyeron un complemento casi regular de sus ingresos. Algunos de los libros, así como cuatrocientos de sus artículos de investigación, los escribió después de volverse completamente ciego. Cuando se complete la edición en curso de sus obras completas comprenderá setenta y cuatro volúmenes.
A diferencia de Descartes o Newton antes que él o de Cauchy después que él, Euler no inició nuevas ramas de la matemática, pero nadie fue más prolífico ni más diestro en utilizarla; nadie llegó a dominar y utilizar los recursos del álgebra, la geometría y el análisis para obtener tantos resultados admirables. Euler tuvo una magnífica inventiva metodológica y una gran habilidad técnica; nos topamos con su nombre en todas las ramas de la matemática: hay fórmulas de Euler, polinomios de Euler, constantes de Euler, integrales eulerianas y líneas de Euler.
Podría pensarse que sólo pudo mantener tal volumen de actividad a costa de todos los demás intereses; pero Euler se casó y tuvo trece hijos, estando siempre atento al bienestar de su familia; educó a sus hijos y nietos, construyendo juegos científicos para ellos y pasando tardes leyéndoles la Biblia. También era aficionado a opinar sobre cuestiones filosóficas, aunque aquí descubrió su único punto débil y recibió por ello frecuentes pullas de Voltaire; en una ocasión se vio forzado a reconocer que nunca había estudiado filosofía y lamentó haber creído que se podía comprender dicha materia sin haberla estudiado; pero el ánimo de Euler para las disputas filosóficas no disminuyó y continuó empeñándose en ellas; incluso se divertía con las mordaces críticas que recibía de Voltaire.
Rodeado de un respeto universal —bien merecido por la nobleza de su carácter— pudo, al final de su vida, considerar como discípulos suyos a todos los matemáticos de Europa. El 7 de septiembre de 1783, después de charlar sobre los asuntos del día, los Montgolfiers[1] y el descubrimiento de Urano, «cesó de calcular y de vivir», según las muy citadas palabras de J. A. N. C. de Condorcet.
2. El concepto de función
Como hemos visto, durante el siglo XVII se introdujeron y utilizaron tanto el concepto de función como las funciones algebraicas y trascendentes más simples. A medida que Leibniz, Jacques y Jean Bernoulli, L'Hôpital, Huygens y Pierre Varignon (1654-1722) abordaban problemas como el movimiento del péndulo, el perfil de una cuerda suspendida de dos puntos fijos, el movimiento a lo largo de trayectorias curvilíneas, el movimiento con rumbo constante sobre una esfera (la loxódroma), evolutas e involutas de curvas, cáusticas que aparecen en reflexión y refracción de la luz y la trayectoria de un punto de una curva que gira sobre otra, no sólo empleaban las funciones ya conocidas sino que llegaban a formas más complicadas de funciones elementales. Como consecuencia de estas investigaciones y del avance, en general, del cálculo infinitesimal, las funciones elementales alcanzaron un nivel de conocimiento y desarrollo prácticamente equivalente al de hoy en día. Por ejemplo, la función logarítmica, originada como relación entre los términos de una progresión geométrica y una aritmética y que fue tratada en el siglo XVII como la serie resultante de la integración de 1/(1 + x) (cap. 17, sec. 2), fue introducida sobre una nueva base. El estudio de la función exponencial por Wallis, Newton, Leibniz y Jean Bernoulli mostró que la función logarítmica era la inversa de la exponencial, cuyas propiedades son relativamente simples. William Jones (1675-1749) dio, en 1742, una introducción sistemática a la función logarítmica de esa manera (cap. 13, sec. 2). Euler, en su Introductio, define ambas funciones como
![]()
El estudio de las funciones hiperbólicas comenzó cuando se observó que el área bajo una circunferencia estaba dada por
![]()
![]()
El concepto de función había sido formulado por Jean Bernoulli. Euler, en el mismo comienzo de la lntroductio, define una función como cualquier expresión analítica formada, de modo arbitrario, a partir de una cantidad variable y de constantes; incluye los polinomios, las series de potencias y las expresiones trigonométricas y logarítmicas; también define las funciones de varias variables. Euler comienza con la noción de función algebraica, en la que las operaciones que se hacen sobre la variable independiente son únicamente algebraicas, las cuales a su vez se dividen en dos clases: racionales, en las que intervienen solamente las cuatro operaciones elementales, y las irracionales, en las que intervienen raíces. A continuación, introduce las funciones trascendentes, a saber, las trigonométricas, la logarítmica, la exponencial, las potencias de exponente irracional y ciertas integrales.
La principal diferencia entre las funciones, escribe Euler, consiste en la combinación de variables y constantes que las componen. Así, añade, las funciones trascendentes se distinguen de las algebraicas en que aquéllas repiten un número infinito de veces las operaciones de estas últimas. Es decir las funciones trascendentes estarían dadas por series infinitas. Euler y sus contemporáneos no se planteaban la necesidad de considerar la validez de las expresiones obtenidas al aplicar infinitas veces las cuatro operaciones racionales.
Euler distinguía entre funciones implícitas y explícitas y entre funciones univalentes y multivalentes, siendo estas últimas las raíces de ecuaciones en dos variables de grado superior cuyos coeficientes son funciones de una variable. En este punto, señala, si una función tal como 3√P, donde P es una función univalente, toma valores reales para valores reales del argumento, entonces se podrá incluir en la mayoría de las ocasiones entre las funciones univalentes. A partir de estas definiciones (que no están libres de contradicciones), Euler considera las funciones racionales enteras o polinomios; estas funciones con coeficientes reales se pueden descomponer, afirma Euler, en factores de primero y segundo grado con coeficientes reales (ver sec. 4 y cap. 25, sec. 2).
Por función continua, Euler, como Leibniz y otros pensadores del siglo XVIII, entendía una función especificada por una fórmula analítica; su término «continua» significa en realidad «analítica» para nosotros, excepto en lo que se refiere a una discontinuidad excepcional como en y = 1/x[6]. También fueron identificadas otras funciones y las curvas que las representaban se calificaban de «mecánicas» o «de trazo libre».
La Introductio de Euler fue la primera obra en que se estableció el concepto de función como una noción básica sobre la que ordenar el material de los dos volúmenes de aquélla. Algo del espíritu de este libro puede extraerse de las observaciones de Euler sobre el desarrollo de funciones en series de potencias[7]. Afirma allí que cualquier función puede desarrollarse de ese modo, pero en seguida dice que «si alguien duda de que cualquier función puede desarrollarse así, la duda quedará desechada desarrollando de hecho la función. Sin embargo, con el fin de que la presente investigación abarque el dominio más amplio posible, además de las potencias enteras positivas de z, también se admitirán términos con exponentes arbitrarios. De este modo, es ciertamente evidente que cualquier función puede expresarse en la forma Azα + Azβ + Czγ+ Dzδ…, donde los exponentes α, β, γ, δ… pueden ser números cualesquiera». Para Euler, la posibilidad de desarrollar en serie todas las funciones estaba confirmada por su propia experiencia y la de todos sus contemporáneos; y, de hecho, era cierto en aquellos tiempos que todas las funciones dadas por expresiones analíticas admitían un desarrollo en serie.
Aunque surgió una controversia acerca de la noción de función en relación con el problema de la cuerda vibrante (ver cap. 22) que llevó a Euler a generalizar su propia noción de lo que era una función, el concepto que predominó en el siglo XVIII fue todavía el de función dada por una única expresión analítica, finita o infinita. Así, Lagrange, en su Théorie des fonctions analytiques (1797), definía una función de una o varias variables como cualquier expresión útil para el cálculo en que dichas variables intervenían de cualquier manera. En las Leçons sur le calcul des fonctions (1806), dice que las funciones representan distintas operaciones que han de realizarse sobre cantidades conocidas para obtener los valores de cantidades desconocidas, y que éstas son estrictamente sólo el último resultado del cálculo. En otras palabras, una función es una combinación de operaciones.
3. Técnicas de integración y cantidades complejas
El método básico para integrar funciones algebraicas, por mínimamente complicadas que fueran, y funciones trascendentes consistía en representar las funciones en serie e integrar término a término, técnica que fue introducida por Newton. Poco a poco, los matemáticos fueron desarrollando técnicas que permitían pasar de una forma cerrada a otra.
El uso del concepto de integral en el siglo XVIII fue bastante restringido. Newton había utilizado la derivada y la antiderivada, o integral indefinida, mientras que Leibniz puso el énfasis en las diferenciales y su suma. Jean Bernoulli, presumiblemente siguiendo a Leibniz, trató la integral como inversa de la diferencial, de modo que si dy=f (x) dx, entonces y =f (x). Es decir, la antiderivada de Newton se tomaba como integral, pero se utilizaba la diferencial en lugar de la derivada de Newton. De acuerdo con Bernoulli, el objeto del cálculo integral era encontrar, a partir de una relación dada entre diferenciales de variables, la relación existente entre las variables. Euler subrayó que la derivada era la razón entre las diferenciales evanescentes y dijo que el cálculo integral se ocupaba de hallar la propia función; sólo utilizó la idea de suma para la evaluación aproximada de integrales. En realidad, todos los matemáticos del siglo XVIII trataron la integral como inversa de la derivada o de la diferencial dy. La existencia de una integral nunca fue puesta en cuestión; se determinaba, por supuesto, explícitamente en la mayoría de aplicaciones que se realizaban en ese siglo, con lo que la cuestión no se planteaba.
Merece la pena considerar algunos ejemplos del desarrollo de las técnicas de integración. Para calcular
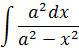
![]()
![]()
![]()
Jean Bernoulli y Leibniz, en la correspondencia entre ambos, aplicaron dicho método a la integral
![]()
![]()
![]()
![]()
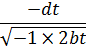
Sin embargo, estos resultados en seguida suscitaron una viva polémica acerca de la naturaleza de los logaritmos de números negativos y de números complejos. En su artículo de 1712[12] y en un intercambio de cartas con Jean Bernoulli durante los años 1712-13, Leibniz afirmaba que los logaritmos de números negativos eran inexistentes (él decía imaginarios), mientras que Bernoulli intentaba probar que tenían que ser reales. El argumento de Leibniz era que los logaritmos positivos se utilizaban para números mayores que 1 y los logaritmos negativos para números entre 0 y 1, con lo que no podían existir logaritmos para los números negativos; además, si -1 tuviese logaritmo, el logaritmo de √-1 tendría que valer la mitad, pero era evidente que √-1 no podía tener logaritmo. Que Leibniz argumentase de este modo después de haber introducido los logaritmos de números complejos en integración resulta inexplicable. Por su parte, Bernoulli argüía que dado que
![]()
La clarificación final de lo que es el logaritmo de un número complejo se hizo posible gracias a otros desarrollos análogos que tienen importancia por sí mismos y que llevan a la relación existente entre la función exponencial y las trigonométricas. En 1714 Roger Cotes (1682-1716) publicó [13] un teorema sobre números complejos que, en notación moderna, establece que
![]()
y = 2 cos x
ey = e √-1x+ e-√-1x
eran ambas soluciones de la misma ecuación diferencial (que él identificó gracias a soluciones en serie) con lo que habían de ser iguales. Publicó esta observación en 1743[14], a saber,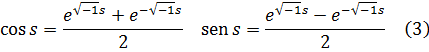
Mientras se producían estos progresos, Abraham de Moivre (1667-1754), que abandonó Francia y se estableció en Londres cuando fue revocado el Edicto de Nantes que protegía a los hugonotes, obtuvo, al menos implícitamente, la fórmula que hoy lleva su nombre. En una nota de 1722, que utiliza un resultado ya publicado en 1707[15], afirma que se puede obtener una relación entre x y t, que representan los senoversos de dos arcos (senver α = 1 cos α) que están en una razón de 1 a n, eliminando z de las dos ecuaciones
1 2zn + z2n = 2znt y 1 2z + z2 = 2zx.
En este resultado está implícita la fórmula de De Moivre, ya que si se pone x = 1 cos ϕ, t= 1 cos nϕ, se obtiene(cos ϕ ± √-1 sen ϕ)n= cos nϕ ± √-1 sen nϕ (4)
Para de Moivre, n era un entero positivo; en realidad, él nunca escribió este último resultado explícitamente; fue Euler quien dio la formulación final[16] y quien lo generalizó para todo número real n.Para 1747, Euler disponía ya de la suficiente experiencia con las relaciones entre exponenciales, logaritmos y funciones trigonométricas como para obtener los resultados correctos sobre logaritmos de números complejos. En un artículo de 1749, titulado «De la controversia entre Messrs. Leibnitz et Bernoulli sur les logarithmes négatifs et imaginaires»[17], Euler se muestra en desacuerdo con el contraargumento de Leibniz de que d (log x) = dx/x sólo para x positivo. Según él, si la objeción de Leibniz fuese correcta quebraría los fundamentos de todo el análisis, a saber, que las reglas y operaciones son válidas sea cual sea la naturaleza de los objetos a los que se aplican aquéllas. Euler afirma que d (log x) = dx/x es correcta para valores positivos y negativos de x, pero añade que Bernoulli olvida que de la fórmula (1) de más arriba sólo se puede concluir que log (-x) y log (x) difieren en una constante. Esta constante ha de ser log (-1), ya que log (-x) = log (-l-x) = log (-l) + log x. En efecto, Bernoulli ha supuesto que log (-1) =0, pero hay que demostrarlo. Bernoulli había proporcionado otros argumentos a los que también respondió Euler. Por ejemplo, Bernoulli afirmaba que dado que (-a)2= a2, entonces log (-a)2 = log a2, de donde 2 log (-a) = 2 log a y, por tanto, log (-a) = log a. Euler replica que dado que (a √-l)4 = a4, se tiene que log a = log (a √-1) = log a + log √-1, con lo que, en este caso, cabe presumir que log √-1 debería ser 0. Pero el propio Bernoulli, dice Euler, estableció en otro contexto que log (√-1) = -(√-1) π/2
Leibniz había argumentado que dado que
![]()
![]()
La respuesta de Euler a este argumento fue que de
![]()
-1/2 = 1 + 3 + 9 + 27 +…
mientras que para x = 1 resulta1/2 = 11 + 1 1 +…
con lo que sumando miembro a miembro se obtiene0 = 2 + 2 + 10 + 26 +…
En consecuencia, afirma Euler, el argumento basado en las series no prueba nada.Después de refutar a Leibniz y Bernoulli, Euler da lo que, según los criterios actuales, es un argumento incorrecto. Escribe
![]()
![]()
y = i (x1/i -1)
Como x1/i —«la raíz con exponente i infinitamente grande»— toma infinitos valores complejos, eso ocurre con y, y como y = log x, lo mismo se puede afirmar de log x. De hecho, Euler escribe[19]![]()
![]()
![]()
4. Integrales elípticas
Después de haber logrado integrar algunas funciones racionales por el método de fracciones simples, Jean Bernoulli afirmó en las Acta Eruditorum de 1702 que la integral de cualquier función racional no implicaba más funciones trascendentes que las trigonométricas y la logarítmica. Como el denominador de una función racional es un polinomio en x de grado n, la validez de esa afirmación dependía de si cualquier polinomio con coeficientes reales podía expresarse como un producto de factores de primer y segundo grado con coeficientes reales. En su artículo de las Acta de 1702, Leibniz opinaba que ello no era posible y daba el ejemplo de x4 + a4. Señalaba que
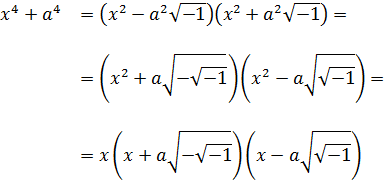
x4 + a4 = (a2 + x2)2 2a2x2= (a2 + x2 + ax √2) (a2 + x2ax √2)
de donde se sigue que la función l/(x4+ a4) se puede integrar en términos de funciones trigonométricas y de la logarítmica.También se estudió la integración de funciones irracionales. Jacques Bernoulli y Leibniz se escribieron sobre este tema debido a que tales integrandos aparecían con frecuencia. En 1694[20], Jacques estaba interesado en la elástica, el perfil que adopta una barra delgada cuando se ejercen fuerzas sobre ella —por ejemplo, en sus extremos—. Para cierto conjunto de condiciones en los extremos, encontró que la ecuación de la curva está dada por
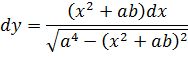
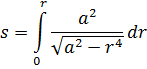
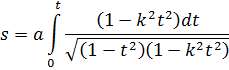
![]()
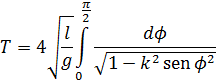
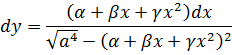
La clase de integrales que comprende los ejemplos anteriores se conoce como la de las integrales elípticas, proviniendo el nombre del cálculo de la longitud de arco de una elipse. En el siglo XVIII no se sabía, pero estas integrales no se pueden evaluar en términos de las funciones algebraicas, las circulares, la logarítmica o la exponencial[21]. Las primeras investigaciones sobre integrales elípticas estaban dirigidas no tanto a evaluarlas como a intentar reducir las más complicadas a las que surgen al rectificar la elipse y la hipérbola. La razón de este enfoque estriba en que desde el punto de vista geométrico, que era el que primaba en la época, las integrales para los arcos elípticos e hiperbólicos parecían ser las más simples. Se inició un nuevo punto de vista con la observación de que la ecuación diferencial
![]()
amyp = bnxq, m + p = n + q,
aunque no dio ninguna demostración.El conde Giulio Cario de’ Toschi di Fagnano (1682-1766), un matemático aficionado, comenzó en 1714 a ocuparse de estos problemas[23]. Consideró las curvas y = (2/m + 2) x(m + 2)/am/2 con m racional, para las cuales es bastante sencillo probar (fig. 19.1) que
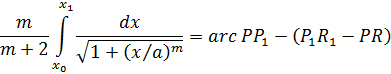
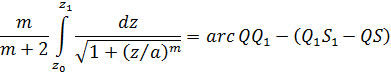
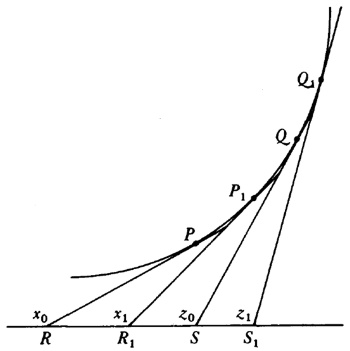
Figura 19.1
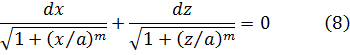
arc QQ1 arc PP1 = (Q1S1QS) (P1R1PR) (9)
Una solución de (8) para m = 4 es![]()
Fagnano probó además que sobre la elipse, lo mismo que sobre la hipérbola, se pueden encontrar infinitos arcos tales que la diferencia de cada dos de ellos se puede expresar algebraicamente, incluso aunque individualmente los arcos no se puedan rectificar. Así, en 1716 probó que la diferencia de dos arcos elípticos cualesquiera es algebraica. Analíticamente, partía de
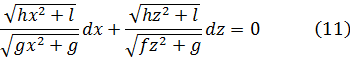
X dx + Z dz = 0
donde h, l, f, g, x y z satisfacen la condiciónfhx2z2 +flx2 + flz2 + gl= 0 (12)
Fagnano probó que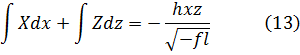
![]()

Figura 19.2
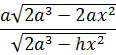
![]()
![]()
![]()
arc BP + arc BP' arc BA = e2 xx'/a (16)
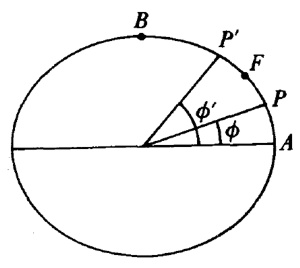
Figura 19.3
arc BF arc AF = a — b (17)
A partir de 1714, Fagnano se ocupó también de la rectificación de la lemniscata mediante arcos elípticos e hiperbólicos y en 1717 y 1720 logró integrar otras combinaciones de diferenciales. Así, probó que
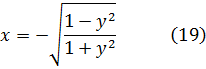
x2 + y2 + x2y2 = 1 (20)
Una manera de enunciar este resultado es: entre dos integrales que expresan arcos de lemniscata (con a = 1) existe una relación algebraica, incluso aunque cada integral por separado sea una función trascendente de una nueva clase. Después de esto, Fagnano estableció otras relaciones análogas que le permitieron obtener resultados especiales sobre la lemniscata[25]. Por ejemplo, probó que si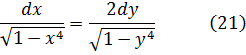
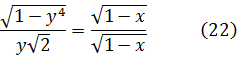
y despejando la x,
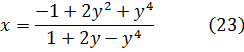

Figura 19.4
Así pues, Fagnano hizo más que dar respuesta a la cuestión de Bernoulli, mostrando que la misma notable propiedad algebraica que caracterizaba las integrales que representaban las funciones trigonométricas y la logarítmica se verificaba para ciertas clases, al menos, de integrales elípticas.
Alrededor de 1750, Euler prestó atención al trabajo de Fagnano sobre la elipse, la hipérbola y la lemniscata y comenzó una serie de investigaciones por su cuenta. En el artículo «Observationes de Compartione Arcuum Curvarum Irrectificabilium» [26], Euler, después de repetir parte del trabajo de Fagnano, mostró cómo dividir el área de un cuadrante de la lemniscata en n + 1 partes supuesto que ya está dividida en n partes. Señala luego que su trabajo y el de Fagnano proporcionaban varios resultados útiles sobre integración, y así la ecuación (18) tenía, aparte de la integral obvia x = y, la integral particular adicional
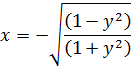
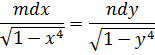
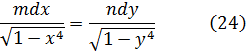
De las investigaciones de Fagnano se seguía que la ecuación (18) se satisfacía por la integral particular (19) o (20). La integral de cada miembro de (18) es un arco de lemniscata con semieje 1 y abscisa x, y la integración de la ecuación diferencial ordinaria (18) equivale a encontrar dos arcos de la misma longitud. Euler había indicado que x = y era otra integral particular de (18), con lo que la integral completa había de reducirse a esas dos integrales particulares para valores especiales de la constante arbitraria. Guiado por estos hechos, Euler encontró que la integral completa de (18) era
x2 + y2 + c2y2x2 = c2 +2xy √(1 c4) (25)
o sea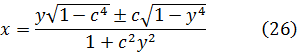
En el resultado (25) está implícito lo que se conoce a menudo como teorema de adición de Euler para estas integrales elípticas simples. Es claro por simple derivación que
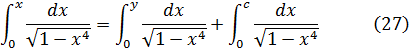
Utilizando los resultados (25) y (27) es bastante sencillo probar que si
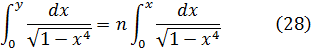
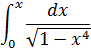
En el mismo artículo de 1756-67 y en el volumen 7 de la misma revista[28], Euler abordó integrales elípticas más generales; expone el siguiente resultado que, según dice, obtuvo por medio de tanteos. Si se diferencia
![]()
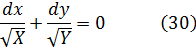
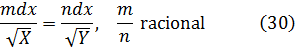
A partir de estos resultados, Euler llegó a lo que ahora se conoce como teorema de adición para integrales elípticas de primera especie. Consideremos la integral elíptica

R(x) = Ax4 = Bx3 + Cx2 + Dx + E.
Entonces, el teorema de adición establece que la ecuación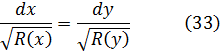
Este resultado conduce a otro teorema que puede ser más ilustrativo. Si la suma o la diferencia de dos integrales elípticas de la forma

Euler fue más allá. Así como el tratamiento de Fagnano de la diferencia de dos arcos de lemniscata lo condujo a la integral elíptica general de primera especie, lo realizado por el mismo Fagnano para la diferencia de dos arcos de elipse (ver (11)) condujo a Euler a un teorema de adición para una segunda clase de integrales[30]. Euler se lamentó de que sus métodos no se pudieran extender a raíces superiores a la raíz cuadrada o a radicandos de grado superior a cuatro y vio, por otro lado, un grave defecto en su trabajo en que no había obtenido sus integrales completas algebraicas por un método general de análisis; así, sus resultados no se podían relacionar de manera natural con otras partes del cálculo infinitesimal.
La obra definitiva sobre integrales elípticas fue realizada por Adrien-Marie Legendre (1752-1833), un profesor de la Ecole Militaire que formó parte de varios comités gubernamentales; más tarde fue examinador de estudiantes en la Ecole Polytechnique. Hasta su muerte en 1833 nunca dejó de trabajar con pasión y regularidad. Su nombre pervive en un gran número de teoremas, muy variados porque abordó las más diversas cuestiones. Sin embargo, no tuvo la originalidad ni la profundidad de Lagrange, Laplace o Monge; su trabajo dio origen a teorías muy importantes, pero sólo después de que fuese asumido por inteligencias más profundas; su nivel se sitúa justo detrás de sus tres contemporáneos arriba citados.
Los teoremas de adición de Euler constituían los principales resultados de la teoría de integrales elípticas cuando Legendre se ocupó del tema en 1786. Durante cuatro décadas fue el único que aportó nuevas investigaciones sobre dichas integrales a la literatura; dedicó dos artículos fundamentales al tema[31] , y después escribió los Exercices de calcul intégral (3 vols., 1811, 1817, 1826), el Traité des fonctions elliptiques[32] (2 vols., 1823-26) y tres suplementos dando cuenta del trabajo de Abel y Jacobi en 1829 y 1832. Los resultados de Euler, como los de Fagnano, estaban ligados a consideraciones geométricas, mientras que Legendre se centró en lo analítico.
El resultado principal de Legendre, que aparece en su Traité, consistió en probar que la integral elíptica general
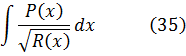

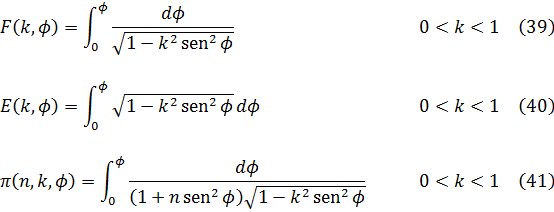
![]()
Esas formas se pueden convertir, mediante el cambio de variable x — sen 0, en las formas de Jacobi:
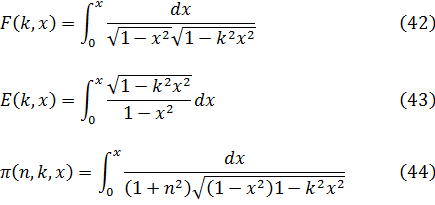
El trabajo de Legendre sobre integrales elípticas tuvo mucho mérito; extrajo numerosas conclusiones, no enunciadas anteriormente, del trabajo de sus predecesores y estructuró matemáticamente dicha materia; sin embargo, no añadió nuevas ideas ni alcanzó la profundidad y penetración de Abel y Jacobi (cap. 27, sec. 6), quienes invirtieron esas integrales, introduciendo así las fundones elípticas. Legendre llegó a conocer el trabajo de Abel y Jacobi, a los cuales elogió con mucha humildad y, probablemente, cierta amargura. Al dedicar los suplementos a su trabajo de 1835 a las nuevas ideas de aquéllos, comprendió muy bien que éstas arrojaban a las sombras todo lo que él había hecho en la materia; pasó al lado de uno de los grandes descubrimientos de su época.
5. Otras funciones especiales
Las integrales indefinidas elípticas son funciones trascendentes nuevas. Al irse desarrollando el trabajo analítico del siglo XVIII, se fueron obteniendo más funciones trascendentes, de las que la más importante es la función gamma, surgida de los trabajos sobre dos cuestiones, teoría de interpolación y antidiferenciación. El problema de la interpolación había sido considerado por James Stirling (1692-1770), Daniel Bernoulli y Christian Goldbach (1690-1764); fue planteado a Euler y éste anunció su solución en una carta del 13 de octubre de 1729 a Goldbach[33]. En una segunda carta, de 8 de enero de 1730, se planteó el problema de la integración[34]. En 1731, Euler publicó resultados sobre ambos problemas en un artículo, «De Progressionibus...»[35].
El problema de la interpolación consistía en dar sentido a n! para valores no enteros de n. Euler indicó que
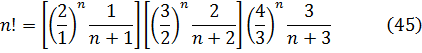
![]()
Euler podría haber utilizado (45) como su generalización del concepto de factorial y, de hecho, hoy se introduce a menudo en la forma equivalente, también dada por Euler,
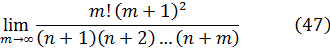
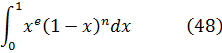
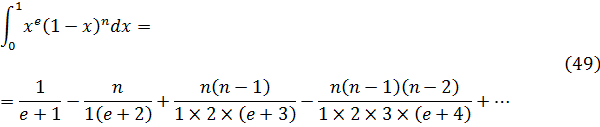
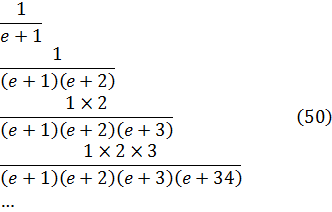
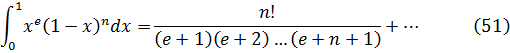
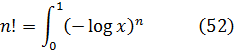
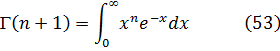
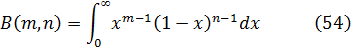

![]()
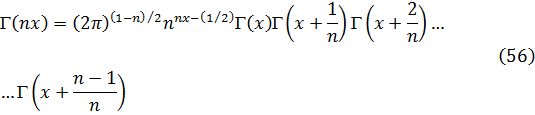
El desarrollo del cálculo infinitesimal de funciones de dos y tres variables se inició a comienzos de siglo. Señalaremos solamente algunos detalles.
Aunque Newton obtuvo a partir de ecuaciones polinomiales en x e y, es decir, f(x,y) = 0, expresiones que hoy obtenemos por derivación parcial de f respecto a x e y, su trabajo no fue publicado. Jacques Bernoulli también utilizó derivadas parciales en su trabajo sobre problemas isoperimétricos, como también hizo Nicolaus Bernoulli (1687-1749) en un artículo de las Acta Eruditorum de 1720 sobre trayectorias ortogonales. Sin embargo, fueron Alexis Fontaine des Bertins (1705-71), Euler, Clairaut y D’Alembert quienes crearon la teoría de derivadas parciales.
Al principio, la diferencia entre una derivada parcial y una ordinaria no fue reconocida explícitamente, y se utilizaba el mismo símbolo d para ambas. En el caso de funciones de varias variables independientes, era el significado el que indicaba la derivada de que se trataba, correspondiente a cambios en una única variable.
La condición para que dz = p dx + q dy, donde p y q son funciones de x e y, sea una diferencial exacta, es decir, proveniente de z = f(x,y) al formar la diferencial
dz = (∂f/∂x) dx + (∂f/∂y) dy,
fue obtenida por Clairaut[38]. Su resultado fue que pdx + qdy es una diferencial exacta si y sólo si ∂p/∂y = ∂q/∂x.El principal impulso para trabajar con derivadas de funciones de dos o más variables vino de los primeros trabajos en ecuaciones en derivadas parciales. Así, Euler desarrolló un cálculo de derivadas parciales en una serie de artículos dedicados a problemas de hidrodinámica. En un artículo de 1734 [39] demuestra que si z = f(x,y), entonces
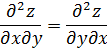
En el trabajo de Newton, en los Principia, sobre la atracción gravitatoria ejercida por esferas y casquetes esféricos sobre partículas, están ciertamente implicadas integrales múltiples, pero Newton utilizó argumentos geométricos. En el siglo XVIII el trabajo de Newton fue reformulado analíticamente y ampliado. Aparecen integrales múltiples en la primera mitad del siglo, siendo utilizadas para denotar la solución de ∂2z/∂x ∂y =f(x,y) y también, por ejemplo, para determinar la atracción gravitatoria ejercida por una lámina sobre partículas. Así, la atracción de una lámina elíptica de grosor δc sobre un punto situado directamente sobre el centro a una distancia de c unidades es igual a una constante por la integral
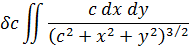
Para 1770, Euler tenía una idea clara de la integral doble definida sobre un dominio acotado limitado por arcos y dio un procedimiento para calcular tales integrales mediante integración iterada[41]. Lagrange, en su trabajo sobre la atracción ejercida por elipsoides de revolución[42], expresó dicha atracción como una integral triple; encontrando difícil realizar el cálculo en coordenadas rectangulares, efectuó un cambio a coordenadas cilíndricas, a saber,
x = a + r sen ϕ cosθ
y = b + r sen ϕ senθ
z = c + r cos ϕ,
donde a, b y c son las coordenadas del nuevo origen, d es la longitud, θ la colatitud y 0 ≤ ϕ ≤ π, 0 ≤ θ < 2π. Lo esencial en la transformación de la integral es reemplazar dx dy dz por r2 sen θdθ dϕ dr. Comenzó así Lagrange el tema de los cambios de variables en las integrales múltiples; de hecho, desarrolló el método general, aunque no muy claramente. También Laplace dio el cambio a coordenadas esféricas casi simultáneamente[43].7. Los intentos de proporcionar rigor al cálculo infinitesimal
El desarrollo de los conceptos y las técnicas del cálculo infinitesimal fue acompañado de esfuerzos para dotarlo de los fundamentos de que carecía. Los libros sobre la materia que aparecieron después de los intentos fallidos de Newton y Leibniz para explicar los conceptos y justificar los procedimientos empleados intentaron aclarar la confusión existente, pero en realidad la aumentaron.
La manera de enfocar el cálculo infinitesimal de Newton era potencialmente más fácil de rigorizar que la de Leibniz, aunque la metodología de éste era más fluida y más práctica en las aplicaciones. Los ingleses pensaron que podrían conseguir el rigor en ambos enfoques intentando ligarlos a la geometría de Euclides, pero confundieron los momentos de Newton (sus incrementos indivisibles) con sus fluxiones, las cuales se refieren a variables continuas. Los continentales, siguiendo a Leibniz, trabajaron con diferenciales e intentaron dotar de rigor a este concepto. Las diferenciales se consideraban bien como infinitesimales, es decir, cantidades no nulas pero tampoco de ningún tamaño finito, o, a veces, como cero.
Brook Taylor (1685-1731), que fue secretario de la Royal Society de 1714 a 1718, intentó, en sus Methodus Incrementorum Directa et Inversa (1715), clarificar las ideas del cálculo infinitesimal, aunque limitándose a funciones algebraicas y ecuaciones diferenciales algebraicas; pensó que podía considerar siempre incrementos finitos pero fue impreciso acerca de la transición de éstos a fluxiones. La exposición de Taylor, basada en lo que podríamos llamar diferencias finitas, no logró muchos partidarios a causa de su naturaleza aritmética cuando los británicos estaban intentando relacionar el cálculo infinitesimal con la geometría o con la noción física de velocidad.
Se puede también apreciar algo de la oscuridad y del fracaso de los esfuerzos del siglo XVIII en la obra de Thomas Simpson (1710-61) A New Treatise on Fluxions (1737). Después de algunas definiciones preliminares, define así una fluxión: «La magnitud en la que cualquier cantidad fluente sería uniformemente incrementada en una porción dada de tiempo con la celeridad generadora en una posición o instante dados (si permaneciese invariable desde entonces) es la fluxión de dicha cantidad en esa posición o instante.» En nuestro lenguaje, Simpson está definiendo la derivada diciendo que es (dy/dx) Δt. Algunos autores se dieron por vencidos. El matemático francés Michel Rolle señalaba en una ocasión que el cálculo infinitesimal era una colección de falacias ingeniosas.
El siglo XVIII asistió también a nuevos ataques al cálculo infinitesimal. El más duro fue el realizado por el obispo George Berkeley (1685-1753), quien temía la creciente amenaza planteada a la religión por el mecanicismo y el determinismo. En 1734 publicó The Analyst, Or A Discourse Addressed to an Infiel del Mathematician. Wherein It is examied whether the Objet, Principies and inferences of the módem Analysis are more distinctly conceived, or more evidently deduce d, than Religious Mysteries and Points of Faith. «First cast out the beam out of thine Eye; and then shalt thou see clearly to cast out the mote of thy brother’s Eye.» (El «infiel» era Edmond Halley.)[44]
Berkeley señaló con razón que los matemáticos estaban procediendo más bien inductiva que deductivamente y que no daban la lógica o las razones de sus pasos. Criticó muchos de los argumentos de Newton; por ejemplo, en el tardío De Quadratura, en el que dice que había evitado lo infinitamente pequeño, da a x un incremento denotado por o, desarrolla (x + o)n, resta xn, divide por o para hallar la razón de los incrementos de xn y x y a continuación desprecia los términos que contienen o obteniendo así la fluxión de xn.
Berkeley dice que Newton da primero a x un incremento pero que después lo hace cero; esto, dice, es un desafío a la ley de contradicción y la fluxión obtenida es, en realidad, 0/0. Berkeley atacó también el método de diferenciales según lo presentaban L'Hôpital y otros en el continente; la razón de las diferenciales, decía, determinaría la secante y no la tangente; el error se anula al despreciar diferenciales de orden superior y así «en virtud de un doble error, aunque no a una ciencia, se llega a pesar de todo a la verdad», gracias a que los errores se compensaban uno al otro. Criticó también la segunda diferencial d (dx) por ser la derivación de una cantidad, dx, ya por sí misma poco menos que imperceptible; escribe: «En cualquier otra ciencia los hombres demuestran las conclusiones a partir de los principios y no los principios a partir de las conclusiones.»
En lo que atañe a la derivada contemplada como la razón de los incrementos evanescentes en y y x, o sea, dy y dx, éstos no eran «ni cantidades finitas, ni cantidades infinitamente pequeñas ni siquiera nada». Estas razones de cambio no eran sino «los espectros de las cantidades difuntas. Ciertamente... quien pueda digerir una segunda o tercera fluxión... no ha de hacer, creo yo, remilgos a ningún argumento de la teología». Concluía Berkeley que los principios de las fluxiones no eran más claros que los del cristianismo y rechazó que el objeto, los principios y las inferencias del análisis moderno estuviesen concebidos más claramente ni deducidos más sólidamente que los misterios religiosos o lo argumentos de la fe.
El Analyst fue replicado por James Jurin (1684-1750), el cual publicó en 1734 Geometry, No Friend to Infidelity, en donde mantenía que las fluxiones eran claras para aquellos versados en geometría. Jurin intentó sin éxito explicar los momentos y las fluxiones de Newton; por ejemplo, definía el límite de una cantidad variable como «cierta cantidad determinada a la que la cantidad variable se supone que se aproxima continuamente» estando más cerca de ella que cualquier diferencia dada, pero a continuación añadía «sin sobrepasarla nunca»; aplicó esta definición a una razón variable (el cociente incremental). La demoledora respuesta de Berkeley, titulada A Defense of Freethinking in Mathematics (1735)[45], afirmaba que Jurin estaba tratando de defender lo que no comprendía; Jurin replicó pero no clarificó la cuestión.
Entró entonces en la refriega Benjamin Robins (1707-51) con artículos y un libro, A Discourse Concerning the Nature and Certainty of Sir Isaac Newton’s Method of Fluxions and of Prime and Ultímate Ratios (1735). Robins dejó de lado los momentos del primer artículo de Newton, subrayando, sin embargo, la importancia de las fluxiones y de las razones primeras y últimas; definía un límite así: «Definimos un límite como una magnitud última, a la cual una magnitud variable se puede acercar con cualquier grado de aproximación, aunque pueda no llegar a hacerse nunca totalmente igual a ella.» En su opinión, las fluxiones eran la idea correcta, mientras que las razones primeras y últimas representaban únicamente una explicación; dijo también que el método de fluxiones se establecía sin recurrir a límites, a pesar de que él dio explicaciones en términos de variables que se aproximan a un límite, y rechazó los infinitesimales.
Para responder a Berkeley, Colin Maclaurin (1698-1746), en su Treatise of Fluxions (1742), intentó dotar de rigor al cálculo infinitesimal; fue un esfuerzo encomiable pero fallido. Lo mismo que Newton, Maclaurin amaba la geometría, y por ello trató de fundamentar la doctrina de las fluxiones en la geometría de los griegos y el método de exhausción, en particular, tal como fue utilizado por Arquímedes, esperando de este modo evitar el concepto de límite; su logro fue utilizar tan hábilmente la geometría que persuadió a otros a hacer lo mismo y abandonar el análisis.
Los matemáticos continentales se fiaban más de las manipulaciones formales de expresiones algebraicas que de la geometría. El representante más importante de este enfoque fue Euler, quien rechazaba la geometría como base para el cálculo infinitesimal y trató de trabajar con funciones de una manera puramente formal, es decir, razonando a partir de su representación algebraica (analítica).
Euler rechazó el concepto de infinitesimal, una cantidad menor que cualquier cantidad fijada y sin embargo no nula. En sus Institutiones de 1755 sostenía que[46]:
No hay duda de que cualquier cantidad puede disminuirse hasta tal punto que se anule completamente y desaparezca. Pero una cantidad infinitamente pequeña no es otra cosa que una cantidad evanescente y por tanto ella misma ha de ser igual a 0. Ello está también en armonía con esa definición de cosas infinitamente pequeñas según la cual se dice que son menores que cualquier cantidad fijada; ciertamente, debería ser nula, pues si no fuese igual a O se le podría asignar una cantidad igual, lo que es contrario a la hipótesis.Puesto que Euler desterró las diferenciales tenía que explicar cómo dy/dx, que para él era 0/0, podía ser igual a un número bien definido. Lo hizo de la siguiente manera: dado que para cualquier número n se tiene que n 0 = 0, entonces n = 0/0; la derivada es simplemente un método útil de determinar 0/0; para justificar el despreciar (dx)2 en presencia de dx, Euler afirma que (dx)2 se anula antes de que lo haga dx, de modo que, por ejemplo, la razón de dx + (dx)2 a dx es igual a 1. Aceptó ∞ como número, por ejemplo, como la suma 1 + 2 +…, y también distinguió órdenes de ∞. Así, a/0 = ∞, pero a/(dx)2 es un infinito de segundo orden, y así sucesivamente. Procede entonces Euler a obtener la derivada de y = x2 como sigue: da a x el incremento ω; el correspondiente incremento de y es
η = 2xω + ω2
y la razón η/ω vale 2x + ω; dice entonces que esta razón se aproxima tanto más a 2x cuanto más pequeño se toma ω, pero recalca que estas diferenciales η y ω son absolutamente cero y que no se puede deducir de ellas otra cosa que su razón mutua, la cual se reduce finalmente a una cantidad finita. Así, Euler acepta incondicionalmente que existen cantidades que son absolutamente cero pero cuyas razones son números finitos. Hay más «razonamientos» de esta naturaleza en el capítulo 3 de las Institutiones, donde alienta al lector señalando que no hay tanto misterio oculto en la derivada como se piensa, lo que provoca sospechas sobre el cálculo infinitesimal en el espíritu de tantos.Como ejemplo adicional de los razonamientos de Euler, consideremos su derivación de la diferencial de y = log x, en la sección 180 de sus Institutiones (1775). Reemplazando x por x + dx se tiene
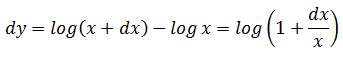
![]()
![]()
![]()
Lagrange, en un artículo de 1772[47] y en su Théorie des fonctions analytiques[48], llevó a cabo el intento más ambicioso de reconstruir los fundamentos del cálculo infinitesimal. Él subtítulo de su libro revela su desvarío; dice así: «Conteniendo los principales teoremas del cálculo diferencial sin hacer uso de lo infinitamente pequeño, ni de cantidades evanescentes ni de límites o fluxiones, y reducido al arte del análisis algebraico de cantidades finitas.»
Lagrange critica el enfoque de Newton señalando que, en lo que se refiere a la razón límite del arco a la cuerda, Newton considera iguales arco y cuerda no antes o después de desvanecerse sino cuando se desvanecen. Como señala correctamente Lagrange, «Este método tiene el inconveniente de considerar cantidades en el estado en que, por así decirlo, cesan de ser cantidades; pues aunque siempre podemos concebir correctamente las razones de dos cantidades mientras ellas permanecen finitas, la mente no se hace una idea clara y precisa de esa razón cuando sus términos se convierten, ambos al mismo tiempo, en nada.» El Treatise of Fluxions de Maclaurin muestra, dice Lagrange, lo difícil que es justificar el método de fluxiones. Tampoco le satisfacen los ceros pequeños (infinitesimales) de Leibniz y Bernoulli ni los ceros absolutos de Euler, todos los cuales, «aunque en realidad correctos no son lo suficientemente claros como para servir de fundamento a una ciencia cuya certeza debe reposar en su propia evidencia».
Lagrange quiso dotar al cálculo infinitesimal del rigor de las demostraciones de los antiguos y propuso lograr esto reduciéndolo al álgebra, la cual, como señalamos más arriba, incluía las series como extensiones de polinomios. En efecto, la teoría de funciones es para Lagrange la parte del álgebra que se refiere a las derivadas de funciones; concretamente, Lagrange propuso utilizar series de potencias, señalando con discreta modestia su extrañeza de que este método no se lo hubiese ocurrido a Newton. Se propone entonces hacer uso del hecho de que toda función f(x) se pude expresar en la forma:
f(x + h) = f(x)+ph + qh2 + rh3+ sh4 +… (58)
en donde los coeficientes p, q, r, contienen x pero son independientes de h; pero quiere estar seguro antes de continuar de que tal desarrollo en serie de potencias es siempre posible. Desde luego, afirma, esto se sabe por numerosos ejemplos familiares, pero concede que hay casos excepcionales; los que Lagrange tiene in mente son aquellos en los que alguna derivada de f(x) se hace infinita y aquellos en los que la función y sus derivadas se hacen infinitas; pero estas excepciones sólo ocurren en puntos aislados y Lagrange no las tiene en cuenta; sin mayores miramientos hace frente a una segunda dificultad: tanto Lagrange como Euler aceptaban sin reservas que era perfectamente posible un desarrollo en serie conteniendo potencias enteras y fraccionarias de h pero Lagrange quería eliminar la necesidad de las potencias fraccionarias; éstas surgen, pensaba Lagrange, solamente si f(x) contiene radicales, con lo que también las descarta como casos excepcionales. Deja así todo listo para seguir adelante con (58).Mediante un argumento un tanto complicado pero puramente formal, Lagrange concluye que podemos obtener 2q de p del mismo modo que obtenemos p de f(x), y que una conclusión análoga se tiene también para los demás coeficientes r, s, …de (58). De aquí, si denotamos p por f'(x) y designamos por f''(x) una función derivada de f'(x) como f'(x) se deriva de f(x), entonces
![]()
A Lagrange le resta todavía mostrar cómo deriva p o f'(x) de f(x). Para ello, utiliza (58) despreciando todos los términos después del segundo. Así pues, f(x + h) f(x) = ph, divide por h y concluye que p=f(x).
En realidad, la suposición de Lagrange de que una función se puede desarrollar en serie de potencias es uno de los puntos débiles de su esquema. El criterio, hoy conocido, para que tal desarrollo sea posible requiere la existencia de derivadas, y esto es lo que Lagrange pretendía evitar. Sus argumentos para justificar las series de potencias sólo sirvieron para añadir confusión acerca de qué funciones admitían tal desarrollo; incluso cuando éste es posible, Lagrange muestra cómo calcular los coeficientes sólo si conocemos el primero, es decir, f'(x); y en cuanto a éste, utiliza los mismos toscos argumentos de sus predecesores. Finalmente, la cuestión de la convergencia de la serie (58), en rigor no la plantea; prueba que para h suficientemente pequeño el último término que se conserva es mayor que lo que se desprecia y también da en este libro la forma de Lagrange del resto en un desarrollo de Taylor (cap. 20, sec. 7), pero esto no desempeña ningún papel en los argumentos de más arriba. A pesar de todos estos puntos débiles, el enfoque de Lagrange del cálculo infinitesimal gozó de gran aceptación durante bastante tiempo, siendo más tarde abandonado.
Lagrange creyó que había prescindido del concepto de límite. Reconocía[49] que el cálculo infinitesimal se podía fundamentar sobre una teoría de límites, pero afirmó que la clase de metafísica que era necesario emplear era ajena al espíritu del análisis. A pesar de las insuficiencias de su método, contribuyó, como lo hizo Euler, a separar la fundamentación del análisis de la geometría y la mecánica; en esto, su influencia fue decisiva. Aunque esta separación no es pedagógicamente deseable, ya que impide la comprensión intuitiva, dejó claro que, desde el punto de vista lógico, el análisis debía desarrollarse por sus propios medios.
Hacia finales de siglo, el matemático, soldado y administrador Lazare N. M. Carnot (1753-1823) escribió una obra popular, muy vendida, Réflexions sur la métaphysique du calcul inifnitésimal (1797), en la que pretendió dotar de precisión al cálculo infinitesimal; intentó probar que el fundamento lógico estribaba en el método exhaustivo y que todas las maneras de tratar la materia no eran sino simplificaciones o atajos cuya lógica podría ser justificada fundamentándose sobre dicho método. Después de muchas reflexiones acabó concluyendo, con Berkeley, que los errores en los razonamientos habituales del cálculo infinitesimal se compensaban unos con otros.
Entre la multitud de esfuerzos para rigorizar el cálculo infinitesimal, unos pocos de ellos fueron por el buen camino. Los más notables de éstos fueron los de D’Alembert y, antes, Wallis. D’Alembert pensaba que Newton había tenido la idea correcta y que él simplemente explicaba lo que había querido decir Newton. En su artículo «Différentiel» de la célebre Encyclopédie of Dictionnaire Raisonné des Sciences, des Arts et des Métiers (1751-80), afirma: «Newton nunca contempló el cálculo diferencial como un cálculo de infinitesimales, sino como un método de razones primeras y últimas, es decir, un método para encontrar el límite de estas razones.» Pero D’Alembert definía una diferencial como «una cantidad infinitamente pequeña o al menos más pequeña que cualquier magnitud fijada». Pensaba que el cálculo de Leibniz podía edificarse sobre tres reglas de diferenciales; sin embargo, era partidario de la derivada en tanto que límite; en su objetivo de utilizar límites afirmó, como Euler, que 0/0 podía valer cualquier cantidad que se quisiera.
En otro artículo, «Limite», afirma: «La teoría de límites es la verdadera metafísica del cálculo... No es nunca cuestión de cantidades infinitesimales en el cálculo diferencial: es únicamente una cuestión de límites de cantidades finitas. Así pues, la metafísica de las cantidades infinitas y las infinitamente pequeñas, mayores o menores que otra, es completamente inútil en el cálculo diferencial.» Los infinitesimales eran simplemente una manera de hablar que evitaba las descripciones más extensas en términos de límites. De hecho,
D’Alembert dio una buena aproximación a la definición correcta de límite en términos de una cantidad variable que se aproxima a una cantidad fija con un error menor que cualquier cantidad fijada, aunque aquí también él dice que la variable nunca alcanza el límite. Con todo, D’Alembert no llevó a cabo una exposición formal del cálculo infinitesimal que incorporase y utilizase sus, en esencia, correctas opiniones. Fue también impreciso en cierto número de cuestiones; por ejemplo, definió la tangente a una curva como el límite de la secante cuando los dos puntos de intersección se hacen uno. Esta imprecisión, especialmente en su enunciado de la noción de límite, originó un debate sobre la cuestión de si una variable puede alcanzar su límite. Al no existir una presentación explícita correcta, D’Alembert aconsejaba a los estudiantes de cálculo infinitesimal, «Persistid y os llegará la fe».
Sylvestre-Frangois Lacroix (1765-1843), en la segunda edición (1810-19) de su Traité du calcul différentiel et du calcul intégral, vio más explícitamente que la razón de dos cantidades, cada una de las cuales se aproxima a 0, puede aproximarse a un número bien definido al que tiene como límite; considera la razón ax/(ax + x2) y observa que es la misma que a/(a + x), y que ésta se aproxima a 1 cuando x se aproxima a 0. Además, señala que 1 es el límite incluso cuando x se acerca a 0 con valores negativos; sin embargo, también habla de la razón de los límites cuando éstos valen 0 e incluso utiliza el símbolo 0/0. Introdujo la diferencial dy de una función y =f(x) en términos de la derivada; así, si y = ax3, dy = 3ax2 dx. Utilizó al principio el término de «coeficiente diferencial» para la derivada; así, 3ax2 sería el coeficiente diferencial.
Casi todos los matemáticos del siglo XVIII realizaron algún esfuerzo o al menos se pronunciaron acerca de la lógica del cálculo infinitesimal, pero aunque uno o dos de ellos estaban en el buen camino todos los esfuerzos resultaron fallidos. La distinción entre un número muy grande y un «número» infinito difícilmente se hacía; si un teorema era cierto para todo n parecía claro que también lo era para n infinito. De manera análoga, un cociente incremental se reemplazaba por la derivada y una suma de un número finito de términos difícilmente se distinguía de una integral; los matemáticos pasaban de una a otra con toda libertad. En 1755, en su Institutiones, Euler distinguía entre el incremento de una función y la diferencial de esa función y entre la sumación y la integral, pero estas distinciones no eran proseguidas. Todos esos esfuerzos podrían resumirse en la descripción de Voltaire del cálculo infinitesimal como «el arte de numerar y medir exactamente una cosa cuya existencia no puede ser concebida».
A la vista de la ausencia casi total de alguna clase de fundamento, ¿cómo procedían los matemáticos para manipular tal diversidad de funciones? Aparte de su gran confianza en los significados físico e intuitivo, tenían in mente un modelo —las funciones algebraicas más simples, como los polinomios y las funciones racionales—; trasladaban a todas las funciones las propiedades que descubrían en estas funciones concretas, explícitas: continuidad, existencia de infinitos y discontinuidades aisladas, desarrollo en serie de potencias, existencia de derivadas e integrales. Pero cuando se vieron obligados, en buena medida a causa de los trabajos sobre la cuerda vibrante, a ampliar el concepto de función, como lo expresó Euler, a cualquier curva de trazo libre (las funciones mixtas, o irregulares, o discontinuas de Euler) ya no les fue posible por más tiempo utilizar como guía las funciones más simples. Y cuando la función logarítmica hubo de extenderse a los números negativos y a los complejos, procedieron ya sin ninguna base fiable en absoluto; esta es la razón por la que eran comunes las discusiones sobre estas materias. La rigorización del cálculo infinitesimal no fue alcanzada hasta el siglo XIX.
Bibliografía
- Bernoulli, Jacques: Opera, 2 vols., 1744, reimpresos por Birkhaüser, 1968.
- Bernoulli, Jean: Opera Omnia, 4 vols., 1742, reimpresos por Georg Olms, 1968.
- Boyer, Cari B.: The concepts of the Calculas, Dover (reimpresión), 1949, cap. 4.
- Brill, A. y M. Nóther: «Die Entwicklung der Theorie der algebraischen Funktionen in álterer und neuerer Zeit», Jahres. der Deut. Math.-Verein, 3, 1892/3, 107-566.
- Cajori, Florian: «History of the Exponential and Logarithmic Concepts», Amer. Math. Monthly, 20, 1913, 5-14, 35-47, 75-84, 107-117, 148-151, 173-182 y 205-210. —: A History of the Conceptions of Limits and Fluxions in Great Britain from Newton to Woodhouse Open Court, 1919. —: «The History of Notations of the Calculus», Annals of Math., (2), 25, 1923, 1-46.
- Cantor, Moritz: Vorlesurtgen über Geschichte der Matbematik, B. G. Teubner, 1898 y 1924, vols. 3 y 4, las secciones correspondientes.
- Davis, Philip J.: «Leonhard Euler’s Integral: A Historical Profile of the Gamma Function», Amer. Math. Monthly, 66, 1959, 849-869.
- Euler, Leonhard: Opera Omnia, B. G. Teubner y Orell Füssli, 1911-; ver en el capítulo referencias a volúmenes específicos.
- Fagnano, Giulio Cario: Opere Matematiche, 3 vols., Albrighi Segati, 1911.
- Fuss, Paul H. von: Correspondance mathématique et physique de quelques célebres géométres du XVIIIeme siécle, 2 vols., 1843, Johnson Reprint Corp., 1967.
- Hofmann, Joseph E.: «Über Jakob Bernoullis Beitráge zur Infinitesimalmathematik», L'Enseignement Mathématique (2), 2, 61-171, 1956; publicado también separadamente por el Instituí de Mathématiques, Ginebra, 1957.
- Mittan-Leffler, G.: «An Introducion to the Theory of Elliptic Functions», Armáis of Math., (2), 24, 1922-23, 271-351.
- Montucla, J. F.: Histoire des Mathématiques, A. Blanchard (reimpresión), 1960, vol. 3, pp. 110-380.
- Pierpont, James: «Mathematical Rigor, Past and Present», Amer. Math. Soc Bulletin, 34, 1928, 23-53.
- Struik, D. J.: A Source Book in Mathematics (1200-1800), Harvard University Press, 1969, pp. 333-338, 341-351 y 374-391.
Capítulo 20
Series
Leed a Euler, leed a Euler, él es el maestro de todos nosotros.Contenido:
P. S. Laplace
1. Introducción1. Introducción
2. Los primeros trabajos sobre series
3. Los desarrollos de funciones
4. El manejo de las series
5. Series trigonométricas
6. Fracciones continuas
7. El problema de la convergencia y la divergencia
Bibliografía
Las series fueron consideradas en el siglo XVIII, y lo son hoy todavía, una parte esencial del cálculo infinitesimal. En efecto, Newton consideraba las series como inseparables de su método de fluxiones, ya que la única manera en que podía manejar las funciones algebraicas mínimamente complicadas y las funciones trascendentes era desarrollándolas en serie y derivando o integrando término a término. Leibniz, en sus primeros artículos publicados de 1684 y 1686, también dio importancia a las «ecuaciones generales o indefinidas». Los Bernoulli, Euler y sus contemporáneos confiaban grandemente en el uso de series. Sólo gradualmente, como señalamos en el capítulo precedente, descubrieron los matemáticos cómo trabajar con las funciones elementales en forma cerrada, es decir, como expresiones analíticas simples. No obstante, las series eran la única representación para ciertas funciones y el medio más eficaz para operar con las funciones trascendentes elementales.
Los éxitos obtenidos mediante la utilización de series fueron siendo más numerosos a medida que los matemáticos desarrollaban su disciplina; las dificultades con el nuevo concepto no fueron identificadas como tales, al menos por un tiempo; las series eran simplemente polinomios infinitos y se podían tratar como tales. Por otro lado, parecía claro, como creían Euler y Lagrange, que toda función podía expresarse en forma de serie.
2. Los primeros trabajos sobre series
Las series, normalmente bajo la forma de progresiones geométricas indefinidas de razón menor que 1, aparecen muy pronto en matemáticas. Aristóteles[50] incluso admitió que tales series poseen una suma. Aparecen esporádicamente entre los matemáticos medievales tardíos, quienes consideraron series para calcular la distancia recorrida por cuerpos móviles cuando la velocidad cambia de un período temporal a otro. Oresme, que había considerado algunas de esas series, incluso demostró en un tratado, Quastiones Super Geometrian Euclidis (h. 1360), que la serie armónica
![]()
![]()
En su Varia Responsa (1593, Opera, 347-435), Vieta dio la fórmula para la suma de una progresión geométrica infinita; tomó los Elementos de Euclides que la suma de n términos a1 + a2 +… + anestá dada por
![]()
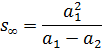
Mercator y Newton (cap. 17, sec. 2) descubrieron la serie
![]()
Wallis advirtió esta dificultad pero no pudo explicarla. Newton obtuvo muchas otras series para funciones algebraicas y trascendentes. Así, para obtener la serie de arc sen x, en 1666, utilizó el hecho (fig. 20.1) de que el área OBC = (1/2) arc sen x, de donde
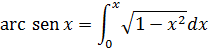
En su obra De Analysi, de 1669, dio las series de sen x, cos x, arc sen x y ex; algunas de ellas las dedujo de otras invirtiendo una serie, es decir, despejando la variable independiente en términos de la variable dependiente. Su método para lograrlo es tosco e inductivo, pero Newton estaba enormemente satisfecho por haber deducido tantas series.
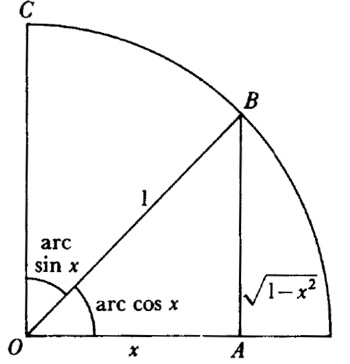
Figura 20.1
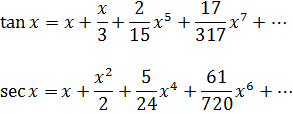
Estos y otros pensadores que utilizaban el teorema binomial para exponentes negativos y fraccionarios en la obtención de muchas de esas series no sólo pasaban por alto las cuestiones que se plantean en el uso de series, sino que no disponían siquiera de una demostración de dicho teorema; aceptaban también sin ninguna duda que la función que se desarrollaba en serie era efectivamente igual a ésta.
En 1702, Jacques Bernoulli[51] obtuvo las series de sen x y cos x por medio de expresiones que él había obtenido para sen na en términos de sen a, haciendo tender a a 0 mientras n se hace infinito, de modo que na tiende a π mientras que n sen a, que es igual a na sen ala, también tiende a x. Wallis había mencionado en la edición latina de su Algebra (1693) que Newton había dado de nuevo estas series en 1676; Bernoulli tomó nota de esta observación pero no reconoció la prioridad de Newton; por otra parte, de Moivre dio una demostración de los resultados de Newton en las Pbilosopbical Transactions de 1698[52], y aunque Bernoulli utilizó y se refirió a esta revista en otro trabajo, no dio ninguna indicación de que conociese por esta fuente el trabajo de Newton.
Una de las principales aplicaciones de las series, aparte de su uso en cuestiones de derivación e integración, está en el cálculo de cantidades especiales, tales como π y e, y en las funciones trigonométricas y la logarítmica. Newton, Leibniz, James Gregory, Cotes, Euler y muchos otros estaban interesados en las series con este propósito. Sin embargo, algunas series convergen tan lentamente que en la práctica no son útiles para efectuar cálculos. Así, Leibniz obtuvo en 1674[53] el célebre resultado
![]()
![]()
Newton inició otra aplicación más de las series; dada la función implícita f(x,y) = 0, para trabajar con la y como función de la x sería deseable disponer de la correspondiente función explícita; puede haber varias de estas funciones explícitas, como resulta evidente del ejemplo trivial de x2 + y2 1 = 0, que tiene las dos soluciones y = ± √(1 x2), ambas emanando del punto (1, 0). En este caso simple, las dos soluciones se pueden expresar en términos de expresiones analíticas cerradas, pero, en general, cada una de las expresiones de y vendrá dada como una serie en x; no obstante, estas series no son necesariamente series de potencias, en particular si los puntos alrededor de los cuales se busca el desarrollo son puntos singulares (fx = fy = 0). En su Method of Fluxions Newton publicó un esquema para determinar las formas de las distintas series, una para cada solución explícita; su método, que utiliza lo que se conoce como paralelogramo de Newton, muestra cómo determinar los primeros exponentes en una serie de la forma
![]()
El problema de determinar los exponentes de cada serie es fastidioso, y Taylor, James Stirling y Maclaurin dieron algunas reglas; Maclaurin intentó extenderlas y demostrarlas pero no logró progresos. Una demostración del método de Newton fue llevada a cabo independientemente por Gabriel Cramer y Abraham G. Kästner (1719-1800).
4. Los desarrollos de funciones
Uno de los problemas a los que se enfrentaron los matemáticos de finales del siglo XVII y del XVIII fue el de la interpolación de tablas de valores. Era necesaria una mayor precisión de los valores interpolados de las tablas trigonométricas, logarítmicas y náuticas para ir al paso de los progresos en navegación, astronomía y geografía. El método usual de interpolación (la palabra es de Wallis) se denomina interpolación lineal porque se supone que la función es una función lineal de la variable independiente en el intervalo entre dos valores conocidos; pero las funciones en cuestión no son lineales y los matemáticos eran conscientes de que se necesitaba un método de interpolación mejor.
El método que vamos a describir fue iniciado por Briggs en su Arithmetica Logarithmica (1624), aunque la fórmula clave la dieron James Gregory en una carta a Collins (Turnbull, Correspondence, 1, 45-48) del 23 de noviembre de 1670, e, independientemente, Newton. El trabajo de éste aparece en el lema 5 del libro III de los Principia y en Methodus Differentialis, que, aunque publicado en 1711, fue escrito hacia 1676; el método utiliza lo que se conoce como diferencias finitas y es el primer resultado importante relativo al cálculo de éstas.
Supongamos que f(x) es una función cuyos valores se conoce en a, a + c, a + 2c, a + 3c,…, a + nc. Sean
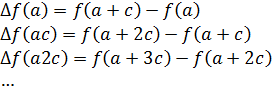
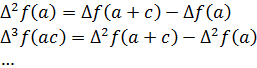
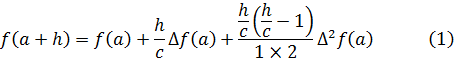
Para calcular f(x) en un valor de x comprendido entre dos valores en los que se conoce/(x) basta hacer simplemente h = x — a; el valor calculado no es necesariamente el verdadero valor de la función; lo que da la fórmula es el valor de un polinomio en h que coincide con la verdadera función en los valores especiales a,a + c,a + 2c,...
La fórmula de Gregory-Newton se aplicó también en integración aproximada. Dada una función g(x) que hay que integrar, quizá para hallar el área bajo la correspondiente curva, se determinan g(a), g(a + c), g(a + 2c),. .. y sus diferencias primeras y de orden superior; se sustituyen estos valores en (1) y se obtiene entonces una aproximación polinomial de g(x); y dado que los polinomios, como señala Newton, se integran fácilmente, se consigue así una aproximación a la integral de g(x).
Gregory aplicó también (1) a la función (1 + d)x; conocía los valores de esta función en x = 0, 1, 2, 3,. . . y con ellos obtuvo f(0) = 1, Δf(0) = d, Δ2f(0) = d2 y así sucesivamente. Haciendo entonces a = 0, c = 1 y h = x 0 en (1) y utilizando los valores de f(0) , Δf(0) ,. . ., obtuvo
![]()
La fórmula de interpolación de Gregory-Newton fue utilizada por Brook Taylor para elaborar el método más potente para desarrollar una función en serie. El teorema binomial, el efectuar la división en una función racional o el método de coeficientes indeterminados son recursos limitados. En su Methodus Incrementorum Directa et Inversa (1715), la primera publicación en la que trató del cálculo de diferencias finitas, Taylor derivó el teorema que todavía lleva su nombre y que él mismo había enunciado en 1712. Por cierto, elogia a Newton pero no hace mención del trabajo de Leibniz de 1673 sobre diferencias finitas, a pesar de que Taylor conocía este trabajo.
El teorema de Taylor ya era conocido por James Gregory en 1670 y fue descubierto independientemente algo más tarde por Leibniz, pero ninguno de ellos lo publicó. Jean Bernoulli publicó prácticamente el mismo resultado en las Acta Eruditorum de 1694, y aunque Taylor conocía este resultado no se refirió a él. Su propia «demostración» fue de un tipo diferente; lo que hizo equivale a sustituir c por Δx en la fórmula de Gregory-Newton; entonces, por ejemplo, el tercer término del segundo miembro de (1) se convierte en
![]()
![]()
El teorema de Taylor para a = 0 se conoce hoy como teorema de Maclaurin. Colin Maclaurin, que sucedió a James Gregory como profesor en Edimburgo, estudió este caso especial en su Treatise of Fluxions (1742), afirmando que no era sino un caso especial del resultado de Taylor; históricamente, sin embargo, se le ha atribuido a Maclaurin como un teorema independiente. Por cierto que Sterling dedujo este caso especial para funciones algebraicas en 1717 y para funciones generales en su Methodus Differentialis de 1730.
La demostración de Maclaurin de su resultado se basa en el método de coeficientes indeterminados; procede como sigue: sea
f(z) = A + Bz + Cz2 + Dz3 + … (5)
Entoncesf'(z) = B + 2Cz + 3Dz2 + …
f''(z) = 2C + 6Dz + …
….
4. El manejo de las series
Jacques y Jean Bernoulli llevaron a cabo una gran cantidad de trabajos con series. Jacques escribió cinco artículos entre 1689 y 1704 que fueron publicados por su sobrino Nicolaus (1695-1726, hijo de Jean) como suplemento al Ars Conjectandi (1713) de Jacques. La mayor parte del trabajo en estos artículos está dedicado al uso de representaciones en serie de funciones con el objeto de derivarlas e integrarlas y obtener áreas bajo curvas y longitudes de curvas. Aunque estas aplicaciones constituían una importante contribución al cálculo infinitesimal, no eran especialmente originales; sin embargo, merecen destacarse algunos de los métodos que utilizaba para sumar series, pues ilustran la naturaleza del pensamiento matemático del siglo XVIII.
En el primer artículo (1689)[54], Bernoulli comienza con la serie
![]()
![]()
![]()
Considera después la serie armónica ordinaria y demuestra que su suma es infinita[55]. Toma los términos
![]()
![]()
![]()
Jean Bernoulli había dado antes una «demostración» diferente de la suma infinita de la serie armónica; se procede así:
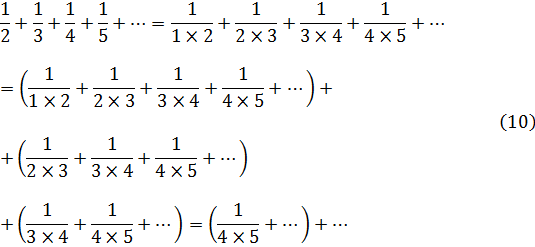
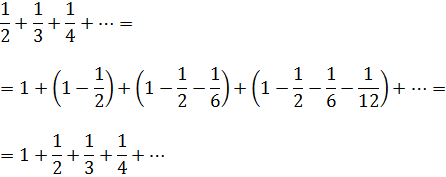
En los siguientes cuatro estudios sobre series, Jacques Bernoulli hace muchas cosas con tan poca precisión que cuesta creer que reconociese alguna vez la necesidad de tener cautela con la series. Por ejemplo, en el segundo de los artículos (1692)[56] argumenta como sigue: de la fórmula para las progresiones geométricas se tiene que 1 + 1/2 + 1/4 + 1/8 + … = 2; entonces, tomando 1/3 de ambos miembros se obtiene 1/3 + 1/6 = 1/12 + … = 2/3; si se toma 1/5 queda 1/5 + 1/10 + 1/20 + … = 2/5, y así sucesivamente; la suma de los miembros de la izquierda, que es la serie armónica completa, será igual a la suma de los miembros de la derecha, o sea,
![]()
En el tercer artículo (1696) [57] escribe
![]()
![]()
En el segundo artículo sobre series reemplazó el término general por la suma o la diferencia de otros dos términos generales, efectuando después operaciones que le llevaban a determinados resultados; esas sustituciones son legítimas para series absolutamente convergentes, pero no para las condicionalmente convergentes; llegó por ello a resultados erróneos, que él describía también como paradojas.
Uno de los resultados ciertamente interesantes de Jacques se refiere a la serie de recíprocos de las potencias n-ésimas de los números naturales, o sea, la serie 1 + 1/2n+ 1/3n + 1/4n + …; probó que la suma de los términos de lugar impar es a la suma de los términos de lugar par como 2n 1 es a 1; esto es correcto para n ≥ 2, pero no dudó en aplicarlo al caso n = 1 y n = 1/2, resultado este último que encontró paradójico.
Otro resultado sobre series debido a Jacques Bernoulli afirma que la suma de la serie 1 + 1/√2+1/√3+… es infinita, porque cada término es mayor que el correspondiente de la serie armónica; aquí utilizó con acierto el criterio de comparación.
La serie que provocó la mayor discusión y controversia fue
1 1 + 1 1 +… (12)
que es la (11) cuando 1 y m son iguales a 1.Parecía claro que escribiendo la serie en la forma
(1 1) + (1 1) + (1 1)+… (13)
la suma debería ser 0. Igual de claro resultaría escribiendo la serie como1 (1 1)(1 1)(1 1) …
que la suma habría de ser 1. Pero, si se denota la suma de (12) por S, entonces S=1 S, de donde S = 1/2, que es precisamente el resultado de Bernoulli en (11). Guido Grandi (1671-1742), un profesor de matemáticas de la universidad de Pisa, en su pequeño libro Quadratura Circuli et Hyperbolae {La cuadratura de círculos e hipérbolas, 1703), obtuvo el tercer resultado por otro método; hizo x= 1 en el desarrollo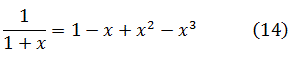
![]()
En una carta a Christran Wolf (1678-1754), publicada en las Acta[58], Leibniz consideró también la serie (12). Se mostraba de acuerdo con el resultado de Grandi, pero pensaba que era posible obtenerlo sin recurrir a su razonamiento; en su lugar, Leibniz argüía que si toma el primer término, la suma de los dos primeros, la suma de los tres primeros y así sucesivamente, se obtiene 1, 0, 1, 0, 1, -, de modo que 1 y 0 son igualmente probables y por lo tanto habría que tomar su media aritmética, que es también el valor más probable, como valor de la suma. Esta solución fue aceptada por Jacques y Jean Bernoulli, Daniel Bernoulli y, como veremos, por Lagrange; Leibniz concedía que su razonamiento era más metafísico que matemático pero fue más allá, hasta decir que había más de verdad metafísica en la matemática de lo que generalmente se reconocía. Sin embargo, estaba probablemente mucho más influenciado por el razonamiento de Grandi de lo que él mismo se daba cuenta, pues cuando, en correspondencia posterior, Wolf quería concluir que
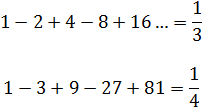
En realidad, los trabajos sobre series comenzaron en toda su amplitud alrededor de 1730 con Euler, en quien el tema despertó un enorme interés. Había, sin embargo, mucha confusión en su pensamiento; para obtener la suma de
1 1 + 1 1 +1…
Euler decía que, dado que![]()
![]()
Del mismo modo, con x = 2 se tiene en (15)
![]()
![]()
![]()
![]()
0 = 1 -3 +5 7 + … (19)
Hay multitud de ejemplos de este tipo de razonamientos en sus trabajos.Haciendo x = 1 en (18) se ve que
∞ = 1 + 2 +2 +3 +4 + 5 +… (20)
Euler aceptaba este resultado; por otra parte, haciendo x = 2 en (15) se ve que-1 = 1 + 2 + 4 + 8 + … (21)
y como el segundo miembro de (21) ha de superar al segundo miembro de (20), resulta que la suma 1+2 + 4 + 8 + … ha de superar a ∞; pero, de acuerdo con (21), esa suma da -1. Euler concluía que ∞ ha de ser una especie de frontera entre los números positivos y los negativos y que en este aspecto se asemejaba al 0.A propósito de (19), Nicolaus Bernoulli (1687-1759) afirmó, en una carta a Euler de 1743, que la suma de esta serie 1 3 + 5 7 +… es -∞ (l)∞; decía que el resultado de Euler (0) era una contradicción insoluble. También observó Bernoulli que haciendo x = 2 en (15) se tiene
1 = 1+ 2 + 4 + 8 +…
y que de![]()
-1 = 1 + 1 + 2 + 3 +….
El hecho de que dos series diferentes diesen -1 era también una contradicción insoluble, pues en otro caso se podrían igualar ambas series.Euler indicó ciertamente en un artículo que las series sólo pueden utilizarse para aquellos valores de x para los que convergen, pero exactamente en el mismo artículo[59] concluía que
![]()
![]()
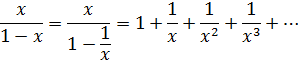
En un artículo anterior[60], Euler comenzaba con la serie
![]()

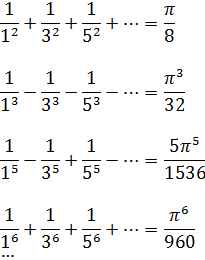
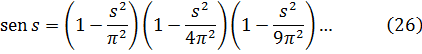
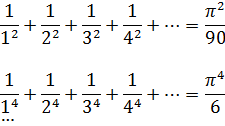
En un artículo posterior[64], Euler obtuvo uno de sus triunfos más brillantes,
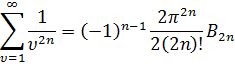
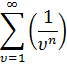
Euler también trabajó sobre series armónicas, es decir, series tales que los recíprocos de sus términos están en progresión aritmética. En particular, demostró [66] cómo se puede sumar un número finito de términos de la serie armónica ordinaria utilizando la función logarítmica. Comienza con
![]()
![]()
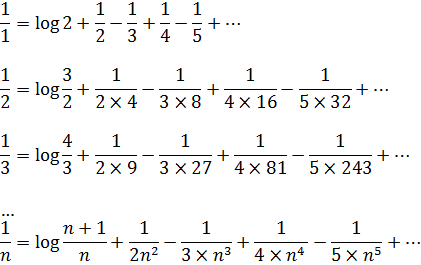
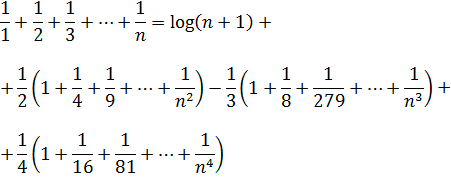
![]()
![]()
En su artículo «De Seriebus Divergentibus» [67], Euler investigó la serie divergente
![]()
x2y' + y = x (31)
Pero esta ecuación diferencial tiene el factor integrante x2e-1/x, de modo que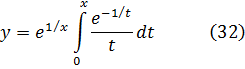
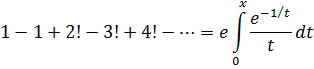
Hay que hacer notar otro resultado célebre de Euler en el campo de las series. En su Ars Conjectandi, Jacques Bernoulli, tratando el tema de la probabilidad, introdujo los hoy ampliamente utilizados números de Bernoulli. Buscaba una fórmula para las sumas de las potencias enteras positivas de los números enteros y dio sin demostración la siguiente fórmula:
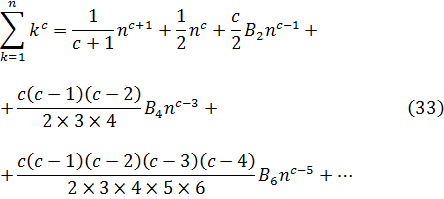
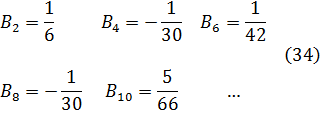
Bernoulli dio también la relación de recurrencia que permite calcular esos coeficientes.
El resultado de Euler, la fórmula de sumación de Euler-Maclaurin, es una generalización[68]. Sea f(x) una función real de la variable real x. Entonces (en notación moderna) la fórmula reza así
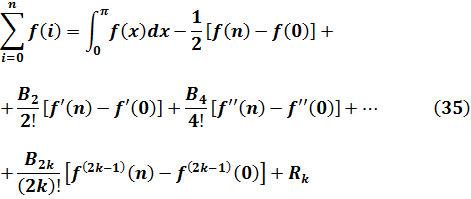
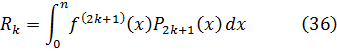

La serie

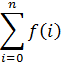
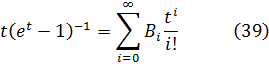
Euler también introdujo[72] una transformación de series que todavía se conoce y utiliza. Dada una serie
![]()
![]()
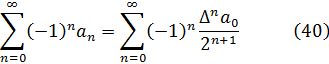
1 1 + 1 1 +…, (41)
entonces el segundo miembro de (40) da 1/2. Análogamente, para la serie1 2 + 22 23 + 24 (42)
(40) da
Ha de quedar claro el espíritu de los métodos de Euler: él es el gran manipulador que señaló el camino para miles de resultados establecidos más tarde rigurosamente.
Hay que mencionar otra serie célebre. En su Methodus Differentialis[73], James Stirling consideró la serie que hoy escribimos en la forma
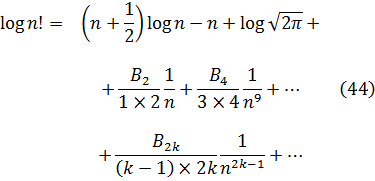
![]()
5. Series trigonométricas
Los matemáticos del siglo XVIII también trabajaron mucho con las series trigonométricas, especialmente en su teoría astronómica. La utilidad de tales series en astronomía es evidente si se tiene en cuenta que son funciones periódicas y que los fenómenos astronómicos son en buena medida periódicos. Ese trabajo representó el origen de un vasto campo cuyo pleno significado no fue apreciado en el siglo XVIII. El problema con el que se inició el uso de series trigonométricas fue el de la interpolación, en particular, la determinación de las posiciones de los planetas intermedias a las obtenidas por observación. Las mismas series fueron también introducidas en los primeros trabajos sobre ecuaciones en derivadas parciales (ver cap. 22), pero curiosamente las dos líneas de pensamiento se mantuvieron separadas a pesar de que trabajaron en ambos problemas las mismas personas.
Por serie trigonométrica se entiende una serie de la forma
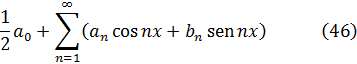
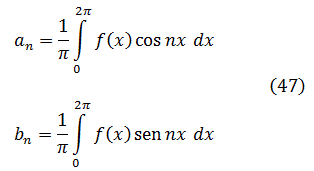
Euler había abordado en una fecha tan temprana como 1729 el problema de la interpolación, o sea, dada una función f(x) cuyos valores para x = n, n entero positivo, están prescritos, hallar f(x) para otros valores de x. En 1747 aplicó el método que había desarrollado a una función que aparece en la teoría de perturbaciones planetarias y obtuvo una representación en serie trigonométrica de la función; publicó dicho método en 1753[74].
En primer lugar, Euler atacó el problema cuando las condiciones dadas son f(n) = 1 para todo n y buscó una función periódica que valiese 1 para x entero. Su razonamiento es interesante porque ilustra el análisis de la época. Pone f(x) = y y, por el teorema de Taylor, escribe
![]()
![]()
![]()
ez 1 = 0
A continuación, determina las raíces de esta última ecuación; para ello, comienza con la ecuación polinómica de grado n![]()
![]()
![]()

![]()
ak sen 2kπx +Ak cos 2kπx
de (49). El factor lineal z mencionado antes da lugar a una solución constante y, dado que f(0) = 1 es una condición inicial, Euler obtiene finalmente
Este artículo contiene también un resultado que es formalmente idéntico a lo que llegaría a conocerse como desarrollo de Fourier de una función arbitraria, así como la determinación de los coeficientes mediante integrales. Concretamente, Euler demostró que la solución general de la ecuación funcional
f(x)=f(x 1) + X(x)
es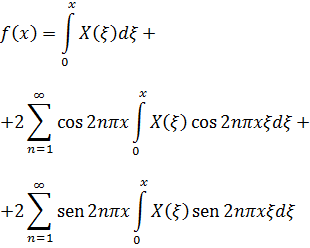
En 1754, D’Alembert[76] consideró el problema de desarrollar el recíproco de la distancia entre los planetas en una serie de cosenos de los múltiplos del ángulo que forman los rayos que van del origen a los planetas, y aquí también podemos encontrar las expresiones en integrales definidas para los coeficientes de las series de Fourier.
En otro trabajo, Euler obtiene representaciones de funciones en series trigonométricas de una manera completamente diferente[77]. Comienza con la serie geométrica
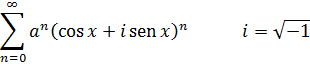
![]()
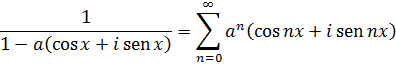
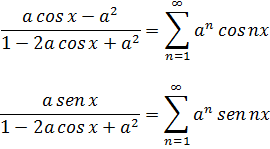
½ = 1 ± cos x + cos 2x ± cos 3x + cos 4x ± … (51)
(La serie es en realidad divergente.) A continuación integra y obtiene![]()
![]()
![]()
sen x ± 2 sen 2x + 3 sen 3x ± … = 0
cos x ± 4 cos 2x + 9 cos 3x ± … = 0
y otras ecuaciones del mismo tipo. Daniel Bernoulli, que había obtenido también desarrollos tales como (52), (53) y (54), admitió que las series sólo representaban las funciones para cierto rango de valores de la x.En 1757, cuando estudiaba las perturbaciones causadas por el sol, Clairaut[78] dio un paso mucho más audaz. Afirma que va a representar cualquier función en la forma
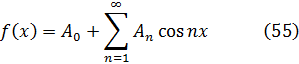
![]()
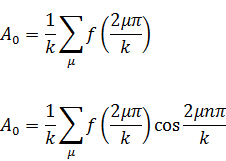
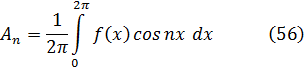
Lagrange, en su investigación sobre la propagación del sonido[79], obtuvo la serie (51) y defendió el hecho de que su suma es 1/2. Con todo, ni Euler ni Lagrange hicieron observación alguna sobre el hecho notable de que habían expresado funciones no periódicas en forma de serie trigonométrica, aunque algo más tarde sí lo advirtieron en otro contexto. D’Alembert había dado a menudo el ejemplo de xm como función que no podía desarrollarse en serie trigonométrica, pero Lagrange le demostró en una carta[80] de 15 de agosto de 1768 que x2/3 sí podía desarrollarse en la forma
x2/3 = a + b cos 2x + c cos 4x + …
D’Alembert le objetó y proporcionó argumentos en contra, tales como que las derivadas de ambos miembros no eran iguales para x = 0. Asimismo, por el método de Lagrange se podría expresar sen x en serie de cosenos, a pesar de que sen x es una función impar y el segundo miembro sería una función par. La cuestión no sería resuelta en el siglo XVIII.En 1777[81], Euler, trabajando en un problema de astronomía, obtuvo de hecho los coeficientes de una serie trigonométrica utilizando la ortogonalidad de las funciones trigonométricas, el método utilizado en la actualidad. O sea, de
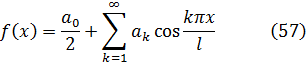
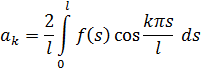
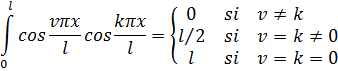
6. Fracciones continuas
Ya hemos indicado (cap. 13, sec. 2) el uso de fracciones continuas para obtener aproximaciones de números irracionales. Euler abordó este tema y, en el primer artículo sobre él[82], titulado «De Fractionibus Continuis», dedujo un buen número de resultados interesantes, tales como que todo número racional se puede expresar como una fracción continua finita. Dio después los desarrollos
![]()
![]()
En su Introductio (cap. 18), Euler estableció los fundamentos de una teoría de fracciones continuas, mostrando allí como pasar de una serie a una fracción continua que la representa, y recíprocamente.
El trabajo de Euler sobre fracciones continuas fue utilizado por Johann Heinrich Lambert (1728-77), colega de Euler y Lagrange en la Academia de Ciencias de Berlín, para demostrar[83] que si x es un número racional distinto de cero, entonces ex y tan x no pueden ser racionales; demostró de ese modo no sólo que ex, para x entero positivo, es irracional, sino que todos los números racionales tienen logaritmo natural (base e) irracional. Del resultado para tan x se sigue que, dado que tan (π/4) = 1, ni π/4 ni π pueden ser racionales. Lambert demostró, de hecho, la convergencia del desarrollo en fracción continua para tan x.
Lagrange[84] utilizó fracciones continuas para hallar aproximaciones de las raíces irracionales de ecuaciones, y, en otro artículo de la misma revista[85], obtuvo soluciones aproximadas de ecuaciones diferenciales en forma de fracciones continuas. En el artículo de 1768, Lagrange demostró el recíproco de un teorema que Euler había establecido en su artículo de 1744; dicho recíproco afirma que una raíz real de una ecuación cuadrática es una fracción continua periódica.
7. El problema de la convergencia y la divergencia
Hoy sabemos que los trabajos del siglo XVIII sobre series eran en buena parte formales y que la cuestión de la convergencia y la divergencia no se tomaba ciertamente muy en serio, aunque tampoco fue totalmente pasada por alto.
Newton[86], Leibniz, Euler e incluso Lagrange consideraban las series como una extensión del álgebra de polinomios y así difícilmente advertían que estaban introduciendo nuevos problemas al extender las sumas a un número infinito de términos. No estaban, pues, plenamente equipados para hacer frente a los problemas que las series infinitas les plantearon; con todas las dificultades evidentes que iban surgiendo les indujeron a plantearse estas cuestiones. Lo que llama la atención es que la solución correcta de las paradojas y otras dificultades fue expuesta con frecuencia, pero con igual frecuencia pasada por alto.
La distinción entre convergencia y divergencia había sido ya tenida en cuenta por algunos pensadores del siglo XVII . En 1668, lord Brouncker, tratando de la relación entre log x y el área bajo y = 1/x. demostró la convergencia de las series de log 2 y log 5/4 por comparación con una serie geométrica. Newton y James Gregory, quienes hicieron mucho uso de valores numéricos de series para calcular tablas de logaritmos y de otras funciones y para evaluar integrales, eran conscientes de que las sumas de las series podían ser finitas o infinitas. De hecho, los términos «convergente» y «divergente» fueron empleados en 1668 por James Gregory, pero no desarrolló sus ideas. Newton reconoció la necesidad de examinar la convergencia, pero no pasó de afirmar que las series de potencias convergen para valores pequeños de la variable al menos tan bien como la serie geométrica; también señaló que algunas series pueden ser infinitas para algunos valores de x y por ello no tener utilidad, como, por ejemplo, la serie de
![]()
Maclaurin, en su Treatise of Fluxions (1742), utilizó las series como un método sistemático de integración, afirmando que: «Cuando una fluente no puede representarse exactamente en términos algebraicos, ha de expresarse entonces mediante una serie convergente.» También admitió que los términos de una serie convergente han de decrecer continuamente y hacerse más pequeños que cualquier cantidad prescrita por pequeña que sea. «En ese caso, unos pocos términos del comienzo de la serie serán casi iguales al valor de la totalidad de aquéllos.» En el Treatise, Maclaurin dio el criterio integral (descubierto independientemente por Cauchy) para la convergencia de una serie:
Nicolaus Bernoulli (1687-1759) también expuso algunas ideas sobre la convergencia en cartas a Leibniz de 1712 y 1713. En una carta del 7 de abril de 1713 [88], Bernoulli afirma que la serie
![]()
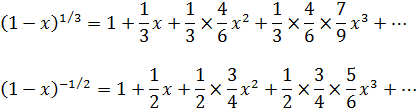
No cabe duda de que Euler advirtió algunas de las dificultades que plantean las series divergentes, en particular, al utilizarlas para efectuar cálculos, pero desde luego no fue nada claro en lo referente a los conceptos de convergencia y divergencia. Sí advirtió que los términos han de hacerse infinitamente pequeños para que haya convergencia. Las cartas que se describen a continuación nos ilustran algo, indirectamente, sobre sus opiniones.
Nicolaus Bernoulli (1687-1759), en correspondencia con Euler durante 1742-43, había cuestionado algunas de las ideas y trabajos de éste. Señalaba que el uso de Euler en su artículo de 1734/35 (ver sec. 4) de
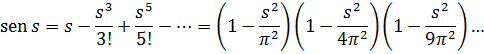
![]()
En otra carta de 1743, Bernoulli afirma que Euler debe distinguir entre una suma finita y una suma de infinitos términos; no hay último término en ese segundo caso y, por ello, no se puede aplicar a polinomios infinitos (como Euler hizo) la relación existente entre las raíces y los coeficientes de un polinomio de grado finito; para polinomios con un número infinito de términos no se puede hablar de la suma de las raíces.
No se conocen las respuestas de Euler a estas cartas de Bernoulli. En carta a Goldbach el 7 de agosto de 1745[91], Euler se remite al argumento de Bernoulli de que series divergentes tales como
+ 1 2 + 6 24 + 120 720…
no poseen suma, pero afirma que estas series tienen un valor definido; señala que no se debe utilizar el término de «suma» porque éste se refiere a una adición efectiva y establece entonces lo que él entiende por un valor definido; explica que una serie divergente proviene de una expresión algebraica finita y afirma entonces que el valor de la serie es el valor de la expresión algebraica de la que proviene la serie. En el artículo de 1754/55 (sec. 4) añade: «Siempre que una serie infinita se obtenga como desarrollo de alguna expresión cerrada, puede utilizarse en operaciones matemáticas como equivalente de dicha expresión, incluso para los valores de la variable para los que la serie diverge.» Y repite el primer principio en su Institutiones de 1755:Digamos, por tanto, que la suma de cualquier serie infinita es la expresión finita por cuyo desarrollo se genera la serie. En este sentido, la suma de la serie infinita 1 x + x2 x3 +… será 1/(1 + x), porque la serie resulta como desarrollo de la fracción, cualquiera que sea el número que se pone en lugar de x. Si se conviene en esto, la nueva definición de la palabra suma coincide con el significado ordinario cuando una serie converge; y como las series divergentes no poseen suma en el sentido propio de la palabra, no surgen inconvenientes con esta terminología. Finalmente, por medio de esta definición, podemos conservar la utilidad de las series divergentes y defender su uso ante cualquier objeción[92].
Está bastante claro que Euler entendía esta doctrina limitada a las series de potencias.
En carta a Nicolaus Bernoulli en 1743, Euler admite que sí había tenido serias dudas en cuanto al uso de series divergentes, pero que nunca había sido inducido a error por el uso de su definición de suma[93]. A esto replicó Bernoulli que una misma serie podía resultar del desarrollo de dos funciones diferentes y en este caso la suma no sería única[94]. Después de esto, Euler escribió a Goldbach (en la carta del 7 de agosto de 1745) que «Bernoulli no da ejemplos y yo no creo que sea posible que la misma serie pueda provenir de dos expresiones algebraicas realmente distintas. De ahí que, indudablemente, cualquier serie, divergente o convergente, tiene una suma o valor definido».
Hubo una interesante continuación de este debate. Euler basaba en su argumento el que la suma de series tales como
1 1 + 1 1 +1 (58)
tomarían el valor de la función de la que proviene la serie. Así, la serie anterior proviene de 1/(1 + x) cuando x = 1, por lo que su valor será 1/2. Sin embargo, unos cuarenta años más tarde, Jean-Charles (François) Callet (1744-99), en una memoria presentada a Lagrange (éste aprobó su publicación en las Mémoires de la Academia de Ciencias de París, pero la memoria nunca fue publicada), señaló que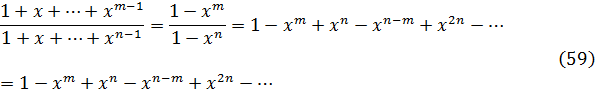
Lagrange[95] examinó la objeción de Callet y argumentó que era incorrecta; utilizó el razonamiento probabilístico de Leibniz de la manera siguiente: supongamos m = 3 y n = 5. Entonces, la serie completa de la derecha en (59) es
1+0 + 0 x3 + 0 + x5 + 0 + 0 x8 + 0 + x10 + 0 -…
Ahora, sí se toma x = 1, la suma del primer término, de los dos primeros, de los tres primeros,…, entonces de cada cinco de esas sumas parciales, tres valen 1 y dos valen 0; en consecuencia, el valor más probable (valor medio) es 3/5; y este es el valor de la serie en (59) para m = 3 y n = 5. Por cierto que Poisson repite el argumento de Lagrange sin mencionar a éste[96].Euler afirmó que había que proceder con mucha cautela en la suma de series divergentes; también distinguió entre series divergentes y series semiconvergentes, tales como (58), que oscilan en su valor cuando van añadiendo términos pero que no se hacen infinitas; llegó a conocer, por supuesto, la diferencia entre series convergentes y divergentes; en una ocasión (1747) en la que utilizó series para calcular la atracción que ejerce la tierra, en tanto que esferoide achatado, sobre una partícula situada en el polo, dice que la serie «converge impetuosamente».
También Lagrange fue consciente en cierta medida de la distinción entre convergencia y divergencia. En sus primeros trabajos fue sin duda descuidado en la materia; dice en un artículo[97] que una serie representará un número si converge a su extremidad, es decir, si su término n-ésimo se aproxima a 0. Más tarde, a finales del siglo XVIII, trabajando con la serie de Taylor, estableció lo que conocemos como teorema de Taylor[98], a saber,
![]()
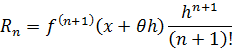
D’Alembert distinguió también las series convergentes de las divergentes. En su artículo «Série» de la Encyclopédie dice: «Cuando la progresión o la serie se aproxima cada vez más a una cantidad finita, y, consiguientemente, los términos de la serie, o cantidades de las que se compone, van disminuyendo, se dice que la serie es convergente, y si se continúa hasta infinito, se hará finalmente igual a dicha cantidad. Así, 1/2 + 1/4 + 1/8 + 1/16 +… forma una serie que se aproxima constantemente a 1 y que se hará finalmente 1 cuando se continúe la serie hasta infinito.» En 1768, D’Alembert expresó sus dudas acerca del uso de series no convergentes; decía: «En cuanto a mí, confieso que todos los razonamientos basados en series que no son convergentes... me resultan muy sospechosos, incluso cuando los resultados concuerdan con verdades a las que se llega por otros caminos.»[99] En vista de las eficaces aplicaciones de las series llevadas a cabo por Jean Bernoulli y Euler, no fueron tenidas en cuenta, en el siglo XVIII, dudas como las expresadas por D’Alembert. En este mismo volumen, D’Alembert dio un criterio para la convergencia absoluta de la serie u1+ u2+ u3 +…, a saber, si para todo n mayor que un cierto r se tiene que |un+1/un| < ρ es independiente de n y menor que 1, la serie converge absolutamente[100].
Edward Waring (1734-98), Lucasian professor de matemáticas en la universidad de Cambridge, sostuvo opiniones avanzadas sobre la convergencia; probó que
![]()
Aunque Lacroix afirmó varias cosas absurdas sobre series en la edición de 1797 de su influyente Traité du calcul différentiel et du calcul intégral, fue más precavido en su segunda edición. Tratando de
![]()
a (a x)y = 0.
Pero si se sustituye en esta ecuación y por la serie, veremos que la serie también la satisface; se sabe, prosigue Lacroix, que lo mismo sería para cualquier otro ejemplo y remite al gran número de ellos que presenta en el texto.Es justo decir que en los trabajos sobre series del siglo XVIII dominó el punto de vista formal. En general, los matemáticos incluso se resentían por cualquier limitación, tal como la necesidad de reflexionar acerca de la convergencia. Sus trabajos producían resultados útiles y quedaban satisfechos con tal pragmática sanción; sobrepasaron los límites de lo que podían justificar, pero al menos fueron prudentes en su utilización de las series divergentes. Como veremos, durante la mayor parte del siglo XIX predominó la insistencia en restringir el uso de series a las convergentes; pero, al final, los hombres del siglo XVIII fueron vindicados: dos ideas esenciales que ellos vislumbraron en las series infinitas habrían de ganar más tarde aceptación. La primera fue que las series divergentes pueden ser útiles para aproximaciones numéricas de funciones, y la segunda que una serie puede representar una función en operaciones analíticas, incluso aunque la serie sea divergente.
Bibliografía
- Bernoulli, Jacques: Ars Conjectandi, 1713, reimpreso por Culture et Civilisation, 1968. —: Opera, 2 vols., 1744. reimpresos por Birkhaüser, 1968.
- Bernoulli, Jean: Opera Omnia, 4 vols., 1742, reimpresos por Georg Olms, 1968.
- Burkhardt, H.: «Trigonometrische Reihen und Intégrale bis etwa 1850», Encyk. dermath. Wiss., B. G. Teubner, 1914-15,2, parte 1, pp. 825-1354. —: «Entwicklungen nach oscillirenden Funktionen», Jabres. derDeut. Math. Verein., vol. 10, 1908, pp. 1-1804. —: «Uber den Gebrauch divergenter Reihen in der Zeit: 1750-1860», Math. Ann., 70, 1911, 189-206.
- Cantor, Mortiz: Vorlesungen üher Geschichte der Mathematik, B. G. Teubner, 1898, vol. 3, caps. 85, 86, 97, 109 y 110.
- Dehn, M. y E. D. Hellinger: «Certain Mathematical Achievements of James Gregory», Amer. Math. Monthly, 50, 1943, 149-163.
- Euler, Leonhard: Opera Omnia, (1), vols. 10, 14 y 16 (2 partes), B. G.
- Teubner y Orell Füssli, 1913, 1924, 1933 y 1935.
- Fuss, Paul Heinrich von: Correspondance mathématique et physique de quelques célebres géométres du XVIIIeme siécle, 2 vols., 1843, Johnson Reprint Corp., 1967.
- Hofmann, Joseph E.: «Uber Jakob Bernoullis Beitráge zur Infinitesimalmathematik», L’Enseignement Mathématique, (2), 2, 1956, 61-171; publicado también separadamente por el Instituí de Mathématiques, Ginebra, 1957.
- Montucla, J. F.: Histoire des mathématiques, A. Blanchard (reimpresión), 1960, vol. 3, pp. 206-243.
- Reiff, R. A.: Geschichte der unendlichen Reihert, H. Lauppsche Buchhandlung, 1889; Martin Sándig (reimpresión), 1969.
- Schneider, Ivo: «Der Mathematiker Abraham de Moivre: 1667-1754», Archive for History of Exact Sáences, 5, 1968, 177-317.
- Smith, David Eugene: A Source Book in Mathematics, Dover (reimpresión), 1959, vol. 1, pp. 85-90 y 95-98.
- Struik, D. J.: A Source Book in Mathematics (1200-1800), Harvard University Press, 1969, pp. 111-115, 316-324, 328-333, 338-341 y 369-374.
- Turnbull, H. W.: James Gregory Tercetenary Memorial Volume, Royal Society of Edinburgh, 1939. —: The Correspondence of Isaac Newton, Cambridge University Press, 1959, vol. 1.
Capítulo 21
Las ecuaciones diferenciales ordinarias en el siglo XVIII
1. Las motivaciones
2. Ecuaciones diferenciales ordinarias de primer orden
3. Soluciones singulares
4. Ecuaciones de segundo orden y ecuaciones de Riccati
5. Ecuaciones de orden superior
6. El método de integración por series
7. Sistemas de ecuaciones diferenciales
8. Sumario
Bibliografía
Un viajero que rehúse pasar sobre un puente hasta haber comprobado personalmente la solidez de cada una de sus partes no irá muy lejos; es necesario arriesgar algo, incluso en matemáticas.1. Las motivaciones
Horace Llamb
Los matemáticos trataron de aplicar el cálculo infinitesimal a resolver un número creciente de problemas físicos y pronto se vieron obligados a atacar una nueva clase de problemas. Lucharon más de lo que conscientemente se habían propuesto. Los problemas más simples conducían a cuadraturas que podían hallarse en términos de las funciones elementales y los algo más difíciles a cuadraturas que no podían expresarse de ese modo, como era el caso de las integrales elípticas (cap. 19, sec. 4), pero ambos tipos de problemas caían dentro de los límites del cálculo infinitesimal. Sin embargo, la resolución de problemas todavía más complicados requirió técnicas especializadas; así surgieron las ecuaciones diferenciales.
Fueron varias las clases de problemas físicos que motivaron la investigación en ecuaciones diferenciales. Una de ellas la constituían problemas en el campo de lo que hoy se conoce comúnmente como teoría de la elasticidad; un cuerpo es elástico si se deforma bajo la acción de una fuerza y recupera su forma original cuando se retira la fuerza. Los problemas de carácter más práctico tienen que ver con los perfiles que adoptan las vigas, verticales y horizontales, cuando se les aplican cargas; estos problemas, tratados empíricamente por los constructores de las grandes catedrales medievales, fueron abordados matemáticamente por hombres tales como Galileo, Edme Mariotte (¿1620?-84), Robert Hooke (1635-1703) y Wren. El comportamiento de las vigas es una de las dos ciencias que Galileo trata en los Diálogos relativos a dos nuevas ciencias; la investigación de Hooke sobre muelles condujo a su descubrimiento de la ley que establece que la fuerza recuperadora de un muelle que se estira o se contrae es proporcional a la magnitud de la elongación o la contracción. Los pensadores del siglo XVIII, equipados con un nivel más alto en matemáticas, comenzaron sus trabajos en elasticidad abordando problemas como el del perfil que adopta un cable inelástico pero flexible suspendido de dos puntos fijos, el perfil de una cuerda, o una cadena, inelástica pero flexible suspendida de un punto fijo y que vibra, el perfil que adopta una cuerda que vibra fijada en sus extremos, el perfil de una barra cuando se fijan sus extremos y se la somete a una carga y el perfil de la barra cuando se pone a oscilar.
El péndulo continuó interesando a los matemáticos; la ecuación diferencial para el péndulo circular,
![]()
El péndulo estaba íntimamente relacionado con otras dos investigaciones fundamentales del siglo XVIII, la forma de la Tierra y la verificación de la ley del cuadrado de los inversos de la atracción gravitatoria. El período aproximado de un péndulo, T = 2π √l/g, se utilizó para medir la fuerza de la gravedad en distintos puntos de la superficie de la Tierra, dado que el período depende de la aceleración g determinada por dicha fuerza; midiendo a lo largo de un meridiano longitudes sucesivas, correspondiendo cada longitud a un cambio de un grado en la latitud, se puede, con ayuda de alguna teoría y de los valores de g, determinar la forma de la Tierra; de hecho, Newton dedujo que la Tierra se abomba en el ecuador utilizando las variaciones observadas en el período en distintos lugares de la superficie terrestre.
Después de que Newton concluyese, mediante sus argumentos teóricos, que el radio ecuatorial era 1/230 más largo que el radio polar (valor que tiene un 30 por 100 de exceso), los científicos europeos estaban impacientes por confirmarlo. Un método consistiría en medir la longitud de un grado de latitud cerca del ecuador y cerca del polo; si la Tierra estuviese achatada, un grado de latitud sería ligeramente más largo en los polos que en el ecuador.
Jacques Cassini (1677-1756) y otros miembros de su familia realizaron tales medidas y llegaron en 1720 al resultado opuesto; encontraron que el diámetro de polo a polo era 1/95 más largo que el diámetro ecuatorial. Para resolver la cuestión, la Academia de Ciencias francesa envió en los años treinta del siglo dos expediciones, una a Laponia, bajo la dirección del matemático Pierre L. M. de Maupertuis, y la otra al Perú; el grupo de Maupertuis incluía un colega matemático, Alexis-Claude Clairaut. Sus mediciones confirmaron que la Tierra estaba achatada por los polos; Voltaire aclamó a Maupertuis como el «achatador de los polos y los Cassinis». De hecho, el valor de Maupertuis fue 1/178, menos preciso que el de Newton. La cuestión de la forma de la Tierra siguió siendo un tema de primera importancia y estuvo abierto por largo tiempo saber si la forma era un esferoide achatado, un esferoide alargado, un esferoide general o alguna otra figura de revolución.
El otro problema asociado, la verificación de la ley de la gravitación, se podría resolver si se conociese la forma de la Tierra. Dada la forma, se podría calcular la fuerza necesaria para mantener un objeto sobre o cerca de la superficie de la Tierra que gira; entonces, conociendo la aceleración g debida a la fuerza de la gravedad en la superficie, se puede comprobar si la fuerza de la gravedad total, que da lugar a la aceleración centrípeta y a g, responde realmente a la ley del cuadrado de los inversos. Clairaut, uno de los que cuestionaban la ley, creyó en un tiempo que debería ser de la forma F = A/r2 + B/r3. Ambos problemas de la ley de atracción y de la forma de la Tierra se entrelazan más adelante, pues cuando la Tierra se considera un fluido que gira en equilibrio, las condiciones para el equilibrio involucran la atracción mutua entre las partículas del fluido.
El campo de la física cuyo interés dominó el siglo fue la astronomía. Newton había resuelto lo que se conoce como el problema de los dos cuerpos, es decir, el movimiento de un único planeta bajo la atracción gravitatoria del Sol, idealizando cada uno de los cuerpos como una masa puntual. También había dado algunos pasos hacia el tratamiento del problema fundamental de los tres cuerpos, el comportamiento de la Luna bajo la atracción de la Tierra y el Sol (cap. 17, sec. 3). Pero esto fue solamente el comienzo de los esfuerzos para estudiar los movimientos de los planetas y de sus satélites bajo la atracción gravitatoria del Sol, así como de la atracción mutua de todos los demás cuerpos. Incluso el trabajo de Newton en los Principia, aun consistiendo de hecho en la resolución de ecuaciones diferenciales, tenía que ser reformulado analíticamente, lo que se hizo gradualmente durante el siglo XVIII. Ello fue iniciado, por cierto, por Pierre Varignon, un buen físico y matemático francés, que trató de liberar a la dinámica del estorbo de la geometría. Newton ya había resuelto algunas ecuaciones diferenciales en forma analítica, por ejemplo, en su Method of Fluxions de 1671 (cap. 17, sec. 3); y en su Tractatus de 1676 hizo observar que la solución de dny/dxn= f(x) tiene un grado de arbitrariedad dado por un polinomio de grado n 1. En la tercera edición de los Principia, proposición 34, escolio, se limita a un enunciado sobre qué formas de superficies de revolución ofrecen menor resistencia al movimiento en un fluido, pero en una carta a David Gregory de 1694 explica cómo logró sus resultados y en la explicación utiliza ecuaciones diferenciales.
Entre los problemas de astronomía, el que recibió mayor atención fue el del movimiento de la Luna, debido a que el método usual de determinar longitudes de los barcos en el mar (cap. 16, sec. 4), lo mismo que otros métodos recomendados en el siglo XVII , dependía del conocimiento en todo instante de la dirección de la Luna desde una posición fijada (que desde finales de siglo fue Greenwich, Inglaterra). Era necesario conocer esta dirección de la Luna con una precisión de 15 segundos de ángulo para determinar la hora en Greenwich con una precisión de un minuto; incluso ese margen de error podía llevar a un error de 30 kilómetros en la determinación de la posición del barco; pero con las tablas de la posición de la Luna disponibles en los tiempos de Newton, tal precisión estaba lejos de alcanzarse. Otra razón para el interés en la teoría del movimiento de la Luna es que puede utilizarse para predecir eclipses, lo que a su vez constituía una prueba de toda la teoría astronómica.
Las ecuaciones diferenciales ordinarias surgieron de los problemas que acabamos de esbozar. Al irse desarrollando la matemática, el campo de las ecuaciones en derivadas parciales dio lugar a investigaciones adicionales en ecuaciones diferenciales ordinarias, y lo mismo ocurrió con las ramas que hoy se conocen como geometría diferencial y cálculo de variaciones. En este capítulo trataremos de los problemas que llevan directamente a los principales trabajos iniciales en ecuaciones diferenciales ordinarias, es decir, ecuaciones que contienen derivadas con respecto a una única variable independiente.
2. Ecuaciones diferenciales ordinarias de primer orden
Los primeros trabajos en ecuaciones diferenciales, como ocurrió con el cálculo infinitesimal a finales del siglo XVII y comienzos del XVIII, vieron primero la luz en cartas de un matemático a otro, muchas de las cuales ya no están disponibles, o en publicaciones que a menudo repiten los resultados establecidos o reivindicados en cartas. El anuncio de un resultado por uno de ellos provocaba frecuentemente la reivindicación por otro de que él había obtenido precisamente lo mismo con anterioridad, lo que, en vista de las encarnizadas rivalidades que existían, puede o no haber sido verdad. Algunas demostraciones se esbozaban meramente, y no está claro que los autores dispusiesen de su desarrollo completo; asimismo, supuestos métodos generales de solución simplemente se ilustraban mediante métodos particulares. Por estas razones, incluso aunque pasemos por alto todo lo relativo al rigor, es difícil atribuir los resultados obtenidos a la persona correcta.
En las Acta Eruditorum de 1693[102] Huygens habla explícitamente de ecuaciones diferenciales, y Leibniz, en otro artículo de la misma revista y año[103] dice que las ecuaciones diferenciales son funciones de elementos del triángulo característico. Lo primero que normalmente aprendemos de las ecuaciones diferenciales, que aparecen al eliminar las constantes arbitrarias entre una función dada y sus derivadas, no se hizo hasta 1740, aproximadamente, y se debe a Alexis Fontaine del Bertins.
Jacques Bernoulli fue de los primeros en utilizar el cálculo infinitesimal para resolver problemas de ecuaciones diferenciales ordinarias; en mayo de 1690[104] publicó su solución al problema de la isócrona, si bien Leibniz ya había dado una solución analítica; este problema consiste en encontrar una curva a lo largo de la cual un péndulo tarde el mismo tiempo en efectuar una oscilación completa, sea grande o pequeño el arco que recorre; la ecuación, en los símbolos de Bernoulli, era
![]()
![]()
En el mismo artículo de 1690, Jacques Bernoulli planteó el problema de encontrar la curva que adopta una cuerda flexible e inextensible colgada libremente de dos puntos fijos, la curva que Leibniz denominó catenaria. El problema había sido considerado ya en el siglo XV por Leonardo da Vinci; Galileo pensó que la curva era una parábola y Huygens afirmó que esto no era correcto, demostrando, básicamente por razonamientos físicos, que si el peso total de la cuerda y de las posibles cargas suspendidas de ella es uniforme por unidad horizontal, la curva es una parábola; para la catenaria, el peso por unidad es uniforme a lo largo del cable.
En las Acta de junio de 1691, Leibniz, Huygens y Jean Bernoulli publicaron soluciones independientes. La de Huygens era geométrica y confusa; Jean Bernoulli[105] la obtuvo por métodos del cálculo infinitesimal y la explicación completa se encuentra en su texto de cálculo infinitesimal de 1691; es la que ahora se expone en los textos de mecánica y de cálculo infinitesimal y está basada en la ecuación
![]()
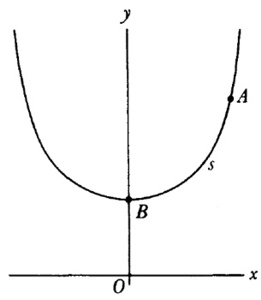
Figura 21.1
Los esfuerzos de mi hermano no tuvieron éxito; en cuanto a mí, tuve más fortuna, ya que fui capaz (lo digo sin alarde, ¿por qué había de ocultar la verdad?) de resolverlo completamente y reducirlo a la rectificación de la parábola. Es cierto que me costó un esfuerzo que me robó el descanso por una noche entera; supuso mucho para aquellos días y para la escasa edad y práctica que yo tenía entonces, pero a la mañana siguiente, rebosante de alegría, corrí donde mi hermano, que estaba luchando tristemente con este, nudo gordiano sin llegar a ninguna parte, pensando todavía, como Galileo, que la catenaria era la parábola. ¡Alto! ¡Alto! le dije, no te tortures más intentando demostrar la identidad de la catenaria con la parábola, pues es completamente falsa; la parábola sirve efectivamente para la construcción de la catenaria, pero las dos curvas son tan diferentes que una es algebraica y la otra trascendente... Pero ahora me asombra usted afirmando que mi hermano descubrió un método para resolver este problema... Le pregunto, ¿cree usted realmente que si mi hermano hubiese resuelto el problema en cuestión hubiese sido tan considerado conmigo como para no figurar entre los que lo resolvieron, únicamente para cederme a mí la gloria de aparecer solo en el escenario en calidad de primero en resolverlo, junto con los señores Huygens y Leibniz?
Durante los años 1691 y 1692 Jacques y Jean resolvieron también el problema del perfil que adopta una cuerda que cuelga y que sea flexible, inelástica y de densidad variable, el de una cuerda elástica de grosor constante y el de una cuerda sobre la que se aplica en cada uno de sus puntos una fuerza dirigida a un centro fijo; Jean resolvió también el problema inverso: dada la ecuación de la curva adoptada por una cuerda inelástica que cuelga, hallar la ley de la variación de la densidad de la cuerda con la longitud del arco.
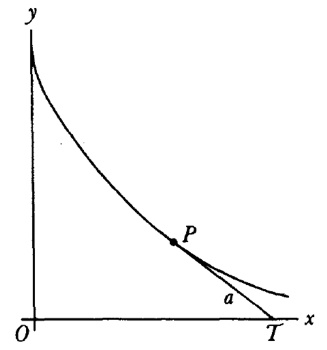
Figura 21.2
En las Acta de 1691, Jacques Bernoulli dedujo la ecuación para la tractriz, la curva (fig. 21.2) para la que la razón de PT a OT es constante para cualquier punto P sobre la curva.
Jacques obtuvo en primer lugar
![]()
![]()
![]()
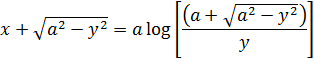
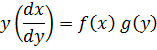
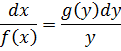
y' = f(y/x)
a cuadraturas, haciendo y = vx y sustituyendo en la ecuación, lo que la convierte en una ecuación separable. Ambas ideas, separación de variables y solución de ecuaciones homogéneas, fueron expuestas más exhaustivamente por Jean Bernoulli en las Acta Eruditorum de 1694. A continuación, Leibniz, en 1694, probó cómo reducir la ecuación diferencial ordinaria de primer orden linealy' + P(x)y = Q(x)
a cuadraturas, utilizando en su método un cambio en la variable dependiente; en general, Leibniz resolvió sólo ecuaciones diferenciales de primer orden.Jacques Bernoulli propuso luego, en las Acta de 1695[107], el problema de resolver la que hoy se conoce como ecuación de Bernoulli:
![]()
En 1694, Leibniz y Jean Bernoulli introdujeron el problema de encontrar la curva o familia de curvas que cortan con un ángulo dado a una familia de curvas dada; Jean Bernoulli denominó trayectorias a las curvas secantes y señaló, partiendo del trabajo de Huygens sobre la luz, que este problema es importante para determinar las trayectorias de los rayos de luz que recorren un medio no uniforme porque dichos rayos cortan ortogonalmente los llamados frentes de onda de la luz. El problema no se hizo público hasta 1697, cuando Jean se lo planteó como un desafío a Jacques, quien lo resolvió en algunos casos especiales; Jean obtuvo la ecuación diferencial de las trayectorias ortogonales a una familia particular de curvas y la resolvió en 1698[109]. Leibniz determinó las trayectorias ortogonales a una familia de curvas como sigue: consideremos y2 = 2bx, donde b es el parámetro de la familia (un término que él introdujo); de esta ecuación se tiene ydy/dx = b; Leibniz hace entonces b = -ydx/dy, sustituye en y2 = 2bx y obtiene y2 = -2xydx/dy como ecuación diferencial de las trayectorias; la solución es a2x2 = y2/2. Aunque sólo resolvió casos especiales, Leibniz se hizo idea del problema general y del método para resolverlo.
El problema de las trayectorias ortogonales permaneció en estado latente hasta 1715, cuando Leibniz, apuntando ante todo a Newton, desafió a los matemáticos ingleses a descubrir el método general para encontrar las trayectorias ortogonales a una familia dada de curvas. Newton, cansado después de un día en la Casa de la Moneda, resolvió el problema antes de acostarse y la solución se publicó en las Philosopbical Transactions de 1716[110] . Newton también demostró cómo hallar las curvas que cortan a una familia dada con un ángulo constante o con un ángulo que varía con cada curva de la familia supuesta conforme a una ley dada; el método no es muy diferente del actual, aunque Newton utilizó ecuaciones de segundo orden.
También trabajó sobre este problema Nicolaus Bernoulli (1695-1726) en 1716. Jacob Hermann (1678-1733), un discípulo de Jacques Bernoulli, dio en las Acta de 1717 la regla de que si F(x,y,c) = 0 es la familia de curvas dada, entonces y' = -Fx/ Fy, donde Fx y Fy son las derivadas parciales de F, y las trayectorias ortogonales tienen como pendiente Fy/Fx[111] De aquí, afirmaba Hermann, resulta que la ecuación diferencial ordinaria de las trayectorias ortogonales a F(x,y,c) = 0 es
![]()
Jean Bernoulli planteó otros problemas de trayectorias a los ingleses, siendo Newton su pesadilla particular; como los ingleses y los continentales estaban ya enfrentados, los desafíos estaban marcados por el encarnizamiento y la hostilidad.
Jean Bernoulli resolvió después el problema de determinar el movimiento de un proyectil en un medio cuya resistencia es proporcional a una potencia de la velocidad; la ecuación diferencial es en este caso
![]()
Cuando una ecuación de primer orden no es exacta, es posible muchas veces multiplicarla por una cantidad, llamada factor integrante, que la convierte en exacta. Aunque se habían utilizado factores integrantes en problemas especiales, fue Euler quien se dio cuenta (en el artículo de 1734/35) de que este concepto proporcionaba un método de integración; estableció clases de funciones para las que existen factores integrantes y demostró también que si se conocen dos factores integrantes de una ecuación diferencial ordinaria de primer orden, entonces su cociente es una solución de la ecuación. Clairaut introdujo independientemente la idea de factor integrante en su artículo de 1739 y amplió la teoría en el artículo de 1740. Hacía 1740 se conocían todos los métodos elementales para resolver ecuaciones de primer orden.
3. Soluciones singulares
Las soluciones singulares no se obtienen de la solución general dando un valor concreto a la constante de integración; es decir, no son soluciones particulares. Esto fue observado por Brook Taylor en su obra Methodus Incrementorum[113] al resolver una cuestión particular de primer orden y segundo grado. Leibniz había ya señalado en 1694 que una envolvente de una familia de soluciones es también solución. Las soluciones singulares fueron estudiadas más ampliamente por Clairaut y Euler.
El trabajo de Clairaut de 1734[114] trata de la ecuación que ahora lleva su nombre,
y = xy' + f(y') (7)
Denotemos y' por p; entonces,y = xp + f(p). (8)
Derivando respecto a x, Clairaut obtenía![]()
![]()
y = cx + f(c) (10)
Esta es la solución general, consistente en una familia de rectas. El segundo factor, x + f(p) = 0, se puede utilizar junto con la ecuación original para eliminar p, obteniéndose así una nueva solución, la solución singular. Para ver que se trata de la envolvente de la solución general tomamos (10) y derivamos respecto a c. Resultax + f'(c) = 0 (11)
La envolvente es la curva que resulta de eliminar c entre (10) y (11); pero estas dos ecuaciones son exactamente las mismas que las que proporcionan la solución singular. El hecho de que la solución singular sea una envolvente no llegó a verse entonces, pero Clairaut fue explícito en cuanto a que la solución singular no está incluida en la solución general.Clairaut y Euler habían desarrollado un método para hallar la solución singular a partir de la propia ecuación, a saber, eliminando y' de f(x,y,y') = 0 y df/dy' =0. Este hecho y el de que las soluciones singulares no estén contenidas en la solución general intrigaron a Euler; en sus Institutiones de 1768[115] dio un criterio para distinguir la solución singular de una integral particular que podía utilizarse cuando no se conocía la solución general, criterio que fue mejorado por D’Alembert[116]. A continuación, Laplace[117] extendió el concepto de soluciones singulares (que él llamó integrales particulares) a ecuaciones de orden superior y a ecuaciones diferenciales en tres variables.
Lagrange[118] llevó a cabo un estudio sistemático de las soluciones singulares y su relación con la solución general, dando el método general para obtener la solución singular a partir de la solución general por eliminación de la constante de una manera clara y elegante que supera la contribución de Laplace. Dada la solución general V(x,y,a) = 0, el método de Lagrange consistía en encontrar dy/da, igualarla a 0 y eliminar a entre esta ecuación y V = 0; se puede utilizar el mismo procedimiento con dx/da = 0. También proporcionó información complementaria sobre el método de Clairaut y Euler para obtener la solución singular a partir de la ecuación diferencial y, finalmente, dio la interpretación geométrica de la solución singular como envolvente de la familia de curvas integrales. Hubo un cierto número de dificultades especiales en la teoría de soluciones singulares que Lagrange no vio, como, por ejemplo, que pueden aparecer otras curvas singulares al eliminar y' entre f(x,y,y') = 0 y df/dy' = 0 que no son soluciones singulares, o que una solución singular puede contener una rama que es una solución particular. La teoría detallada de las soluciones singulares fue desarrollada en el siglo XIX y fueron Cayley y Darboux quienes la expusieron en su forma actual en 1872.
4. Ecuaciones de segundo orden y ecuaciones de Riccati
Las ecuaciones diferenciales de segundo orden aparecen en problemas físicos ya en 1691. Jacques Bernoulli se planteó el problema de la forma de una vela bajo la presión del viento, el problema de la velaría, lo que le llevó a la ecuación de segundo orden d2x/ds2 = (dy/ds)3, donde s es la longitud de arco. Jean Bernoulli trató este problema en su texto de cálculo infinitesimal de 1691 y estableció que es matemáticamente el mismo que el problema de la catenaria. Las ecuaciones de segundo orden aparecen a continuación al atacar el problema de determinar el perfil de una cuerda elástica que vibra, sujeta por los extremos —por ejemplo, una cuerda de violín—. Al abordar este problema, Taylor continuaba con un viejo tema; toda la cuestión de la matemática y los sonidos musicales comenzó con los pitagóricos, se prosiguió con ella en el período medieval y adquirió relevancia en el siglo XVII . Benedetti, Beeckman, Mersenne, Descartes, Huygens y Galileo destacan en esta materia, aunque no hubo nuevos resultados matemáticos que merezcan reseñarse aquí. El hecho de que una cuerda puede vibrar en muchos modos, esto es, en mitades, tercios, etc., y que el tono producido por una cuerda que vibra en k partes es el armónico n-ésimo (el fundamental es el primer armónico) era bien conocido en Inglaterra hacia 1700, en buena medida gracias a los trabajos experimentales de Joseph Sauveur (1653-1716).
Brook Taylor[119] obtuvo la frecuencia fundamental de una cuerda vibrante tensa; resolvió la ecuación
![]()
![]()
En sus esfuerzos para tratar la cuerda vibrante, Jean Bernoulli consideró, en una carta de 1727 a su hijo Daniel y en un artículo[120], una cuerda elástica sin peso cargada con n masas iguales e igualmente espaciadas; dedujo la frecuencia fundamental del sistema cuando hay 1, 2,..., 6 masas (hay otras frecuencias de oscilación del sistema de masas); Jean aplicó el que la fuerza sobre cada masa es — K veces su desplazamiento, y resolvió d2x/dt2 = -Kx, integrando, por tanto, la ecuación del movimiento armónico simple por métodos analíticos; pasó después a la cuerda continua, de la que probó, como Taylor, que ha de tener el perfil de una curva sinusoidal (en todo instante) y calculó la frecuencia fundamental; resolvió, por tanto, la ecuación, d2y/dx2 = -ky. Ni Taylor ni Jean Bernoulli estudiaron los modos superiores de los cuerpos vibrantes elásticos.
Euler comenzó a considerar ecuaciones de segundo orden en 1728. Su interés en ellas fue suscitado en parte por sus trabajos en mecánica; había trabajado, por ejemplo, sobre el movimiento del péndulo en medios con rozamiento, lo que conduce a ecuaciones de segundo orden; trabajó para el rey de Prusia sobre el efecto de la resistencia del aire sobre los proyectiles; en esto, tomó el trabajo del inglés Benjamín Robins, lo mejoró y escribió una versión en alemán (1745), la cual fue traducida al francés y al inglés y utilizada en artillería.
Consideró también[121] una clase de ecuaciones de segundo orden que redujo mediante un cambio de variables a ecuaciones de primer orden. Consideró, por ejemplo, la ecuación
axm dxp = yn df -2 d2y (12)
o, en la forma de derivadas,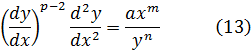
![]()
No merece la pena seguir con los detalles técnicos de este método porque se aplica únicamente a una clase de ecuaciones de segundo orden, pero históricamente este trabajo es significativo porque inicia el estudio sistemático de las ecuaciones de segundo orden y porque Euler introduce en él la función exponencial, que, como veremos, juega un papel importante en la resolución de las ecuaciones de segundo orden y de orden superior.
Antes de dejar San Petersburgo en 1733, Daniel Bernoulli terminó el artículo «Teoremas sobre oscilaciones de cuerpos conectados por un hilo flexible y de una cadena verticalmente suspendida»[122]. Comienza en él con la cadena suspendida de su extremo superior, sin peso pero cargada con pesos igualmente espaciados, y encuentra que, cuando la cadena se pone a vibrar, el sistema tiene distintos modos de (pequeña) oscilación alrededor de una línea vertical que pasa por el punto de suspensión; cada uno de estos modos tiene su propia frecuencia característica[123]. Entonces establece, para una cadena en suspensión que oscila, de densidad uniforme y de longitud l, que el desplazamiento y a una distancia x del extremo inferior (fig. 21.3) satisface la ecuación
![]()
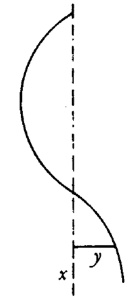
Figura 21.3
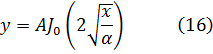
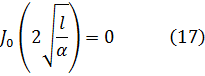
Su artículo sobre la cadena en suspensión trata también de la cadena oscilante de grosor no uniforme, introduciendo en este caso la ecuación diferencial
![]()

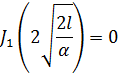
Lo que falta en las soluciones de Daniel Bernoulli es, en primer lugar, toda referencia al desplazamiento como función del tiempo, con lo que su trabajo queda, desde el punto de vista matemático, en el campo de las ecuaciones diferenciales ordinarias; y lo mismo, en segundo lugar, en cuanto a que los modos simples (los armónicos), que él identificó explícitamente como movimientos reales, se pueden superponer para formar movimientos más complicados.
Después de haber abordado el tema de los sonidos musicales en el libro Tentamen Novae Theoriae Musicae ex Certissimis harmoniae Principiis Dilucide Expositae (Investigación sobre una nueva teoría de la música, claramente expuesta a partir de incontestables principios de la armonía), escrito antes de 1731 y publicado en 1739[125], Euler prosiguió el trabajo de Daniel Bernoulli en el artículo «Sobre las oscilaciones de un hilo flexible cargado con una cantidad arbitraria de pesos»[126]. Los resultados de Euler son en buena parte los mismos de Bernoulli, salvo que los argumentos matemáticos de Euler son más claros. Para una forma de cadena continua, a saber, el caso especial en que el peso es proporcional a xn, Euler tuvo que resolver
![]()
Obtiene la solución en serie que en notación moderna está dada por[127]
![]()
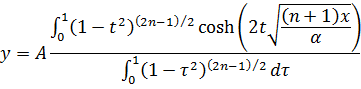
En un artículo de 1739[128] Euler se ocupó de las ecuaciones diferenciales del oscilador armónico,
M![]() + Kx = F sen ωt. (20)
+ Kx = F sen ωt. (20)
En un intento de plantear un modelo para la transmisión del sonido en el aire, Euler considera en su artículo «Sobre la propagación de impulsos a través de un medio elástico» [129]n masas M conectadas por una especie de muelles (sin peso) que yacen en una recta horizontal PQ; se consideran movimientos longitudinales, es decir, a lo largo de PQ; teniéndose para la masa k-ésima
M![]() = K (xk+12xk + xk-1), k = 1, 2, …, n
= K (xk+12xk + xk-1), k = 1, 2, …, n
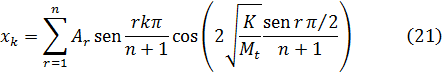
Así pues, no sólo obtiene los modos individuales para cada una de las masas sino también el movimiento de esa masa como suma de modos armónicos simples; cada modo particular que pueda aparecer depende de las condiciones iniciales, es decir, de cómo las masas se ponen en movimiento. Todos estos resultados se pueden interpretar en términos del movimiento transversal (perpendicular a PQ) de la cuerda cargada.
Alguna de las ecuaciones ya consideradas, como, por ejemplo, la ecuación de Bernoulli, no es lineal; es decir, en tanto que ecuación en las variables y, y' y y" (si aparece), contiene términos de grado dos o superior. Entre las ecuaciones de primer orden de este tipo hay algunas que tienen un interés especial por estar relacionadas íntimamente con ecuaciones de segundo orden lineales. En los primeros tiempos de las ecuaciones diferenciales ordinarias recibió una gran atención la ecuación no lineal de Riccati.
![]()
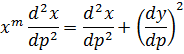
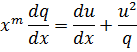
![]()
El trabajo de Riccati no es sólo importante por tratar ecuaciones de segundo orden sino por la idea de reducir ecuaciones de segundo orden al primero; la idea de reducir el orden de una ecuación diferencial por uno u otro medio llegaría a ser considerada como uno de los métodos principales para el tratamiento de ecuaciones diferenciales ordinarias de orden superior.
En 1760, Euler[131] consideró la ecuación de Riccati
![]()
z = v + u-1
convierte a aquélla en una ecuación lineal. Además, si se conocen dos integrales particulares, la integración de la ecuación original se reduce a cuadraturas.D’Alembert [132] fue el primero en considerar la forma general (22) de la ecuación de Riccati y en utilizar el término «ecuación de Riccati» para esta forma. Comenzó con
![]()
![]()
5. Ecuaciones de orden superior
En diciembre de 1734, Daniel Bernoulli escribió a Euler, quien estaba en San Petersburgo, que había resuelto el problema del desplazamiento transversal de una barra elástica (un cuerpo unidimensional de madera o de acero) fijado a una pared en uno de sus extremos y libre en el otro. Bernoulli había obtenido la ecuación diferencial
![]()
Cuatro años más tarde, en una carta a Jean Bernoulli (15 de septiembre de 1739), Euler indicaba que su solución se podía representar como
![]()
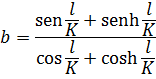
En la publicación de su trabajo[133], Euler considera la ecuación
![]()
![]()
A + Br + Cr2 + … + Lrn = 0
que se denomina ecuación característica o auxiliar. Cuando q es una raíz real simple de esta ecuación, entonces![]()
![]()
y = eqx(α + βx + γx2 +… + χxk-1) (30)
es una solución que contiene k constantes arbitrarias si q aparece k veces como raíz de la ecuación característica. Trata también los casos de raíces complejas conjugadas y de raíces complejas múltiples, con lo que Euler resuelve completamente las ecuaciones lineales homogéneas con coeficientes constantes.Algo más tarde[134] estudió la ecuación diferencial ordinaria lineal de orden n no homogénea; su método consistió en multiplicar la ecuación por em, integrar ambos miembros y proceder a determinar a de modo que la ecuación se reduzca a una de orden inferior. Así, por ejemplo, para resolver
![]()
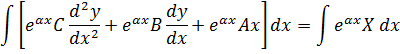
![]()
![]()
![]()
![]()
El método se aplica a ecuaciones diferenciales ordinarias de orden n lineales, reduciendo el orden paso a paso como en el ejemplo anterior. Euler también consideró los casos de raíces iguales de la ecuación en a y de raíces complejas.
Siguiendo las líneas del tratamiento de las ecuaciones lineales con coeficientes constantes, Lagrange pasó a considerar el caso de coeficientes variables[135]. Esto lleva, como veremos, al concepto de ecuación adjunta; Lagrange comienza con
![]()
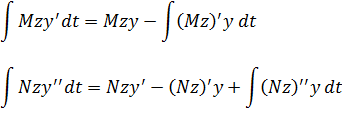
y[Mz (Nz)'] + y' (Nz) + ∫[Lz (Mz)' + (Nz)"] y dt = ∫Tz dt.
El corchete bajo el signo integral se puede tratar como una ecuación diferencial ordinaria en z igualándolo a 0; si se puede resolver en z(t), quedará para y una ecuación diferencial ordinaria de orden inferior al original. La nueva ecuación diferencial en z se dice que es la adjunta de la ecuación original, el término fue introducido por Lazare Fuchs en 1873. Lagrange no utilizó ningún término especial para ella.Para tratar la ecuación en z (la ecuación adjunta), Lagrange procede del mismo modo que para reducir el orden. Multiplica por ω(t)dt, hace como antes y llega a una ecuación en ω que permite reducir el orden de la ecuación en z; la ecuación en ω resulta ser la ecuación original (35), excepto que el segundo miembro es 0. Así pues, Lagrange descubrió el teorema que dice que la adjunta de la adjunta de la ecuación diferencial ordinaria no homogénea original es la ecuación homogénea asociada a la original. Euler hizo esencialmente lo mismo en 1778; había conocido el trabajo de Lagrange, pero al parecer lo olvidó.
En trabajos posteriores sobre ecuaciones homogéneas con coeficientes variables, Lagrange[136] extendió a estas ecuaciones algunos de los resultados que Euler había obtenido para las ecuaciones con coeficientes constantes. Lagrange descubrió que la solución general de la ecuación homogénea es una suma de soluciones particulares independientes, cada una de ellas multiplicada por una constante arbitraria, y que conociendo m integrales particulares de una ecuación homogénea de orden n se puede reducir el orden en m unidades.
6. El método de integración por series
Ya hemos tenido ocasión de señalar que algunas ecuaciones diferenciales se resolvían por medio de series. La importancia de este método, incluso en la actualidad, justifica el dedicar unos pocos comentarios específicos a la materia. Las soluciones en serie han sido utilizadas tan ampliamente desde 1700 que hemos de limitarnos a unos pocos ejemplos.
Sabemos que Newton utilizó series para integrar funciones algo complicadas, incluso cuando sólo estaban implicadas cuadraturas. También las utilizó para resolver ecuaciones de primer orden; así, para integrar
![]() = 2 + 3x -2y + x2 + x2y, (36)
= 2 + 3x -2y + x2 + x2y, (36)
y = A0 + A1x + A2x2 +… (37)
Entonces![]() = A1+ 2A2x + 3A3x2 + … (38)
= A1+ 2A2x + 3A3x2 + … (38)
A1 = 2 2A0, 2A2 = 3 2A1, 3A3 = 1 + A0 2A2 + …
Se determinan así los Ai; el hecho de que A0 queda indeterminado y que por lo tanto existen infinitas soluciones sí fue advertido, pero la importancia de una constante arbitraria no fue plenamente apreciada hasta aproximadamente 1750. Leibniz resolvió algunas ecuaciones diferenciales elementales por medio de series[137] y utilizó también el método anterior de coeficientes indeterminados.Euler puso en un primer plano el método de integración por series desde aproximadamente 1750 en adelante a fin de resolver ecuaciones diferenciales que no podían integrarse en forma cerrada. Aunque él trabajó con ecuaciones diferenciales concretas y los detalles de lo que hizo son a menudo complicados, su método es el que utilizamos en la actualidad. Euler supone que se tiene una solución de la forma
y — xλ(A + Bx + Cx2 + …),
sustituye y y sus derivadas en la ecuación diferencial y determina λ y los coeficientes A, B, C, … a partir de la condición de que sea cero el coeficiente de cada una de las potencias de x en la serie resultante. Así, la ecuación que aparece en su trabajo sobre la membrana oscilante[138] (ver cap. 22, sec, 3), a saber,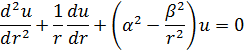
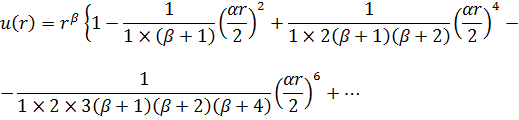
En las Institutiones Calculi Integralis[139], Euler trató la ecuación diferencial hipergeométrica.
![]()
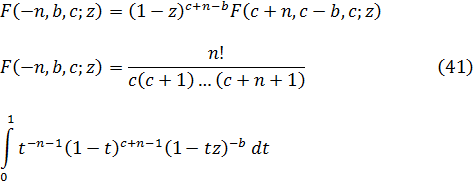
Las ecuaciones diferenciales implicadas hasta aquí en el estudio de la elasticidad eran bastante simples, debido a que los matemáticos utilizaban principios físicos un tanto toscos mientras continuaban esforzándose en captar otros más refinados. En el campo de la astronomía, sin embargo, los principios físicos, fundamentalmente las leyes del movimiento de Newton y la ley de gravitación, estaban claros y los problemas matemáticos eran mucho más profundos. El problema matemático fundamental al estudiar el movimiento de dos o más cuerpos, moviéndose cada uno bajo la atracción gravitatoria de los otros, es el de resolver un sistema de ecuaciones diferenciales ordinarias, aunque el problema se reduce con frecuencia a la resolución de una única ecuación.
Aparte de casos aislados, los trabajos sobre sistemas de ecuaciones se refirieron principalmente a problemas de astronomía. El punto de partida para escribir las ecuaciones diferenciales es la segunda ley del movimiento de Newton, f = ma, donde f es la fuerza de atracción; se trata de una ley vectorial, lo que significa que cada componente de f produce una aceleración en la dirección de la componente. En un artículo de 1750[141], Euler expresó analíticamente la segunda ley de Newton en la forma
![]()
Consideraremos brevemente las correspondientes ecuaciones diferenciales. Supongamos que un cuerpo fijo de masa M está situado en el origen y que un cuerpo móvil de masa m está en (x, y, z).
Figura 21.4
![]()
donde G es la constante de gravitación y
![]()
![]()
Si los dos cuerpos se mueven, cada uno sometido a la atracción del otro, las ecuaciones diferenciales son algo diferentes. Sean m1 y m2 las masas de dos cuerpos esféricos de masa con simetría esférica, tales que m1 + m2= M. Elijamos un sistema de coordenadas fijo (normalmente se toma como origen el centro de gravedad de los dos cuerpos) y sean (x1, y1, z1) las coordenadas de un cuerpo y (x2, y2, z2) las coordenadas del otro; sea r = √{(x1x2)2 + (y1y2)2 + (z1z2)2} la distancia entre ambos. Entonces, el sistema de ecuaciones que describe el movimiento es
De hecho, este problema del movimiento de dos esferas bajo la atracción mutua debida a la fuerza gravitatoria fue resuelto geométricamente por Newton en los Principia (libro I, sección 11). Sin embargo, no se emprendieron trabajos analíticos por algún tiempo. En mecánica, los franceses seguían el sistema de Descartes hasta que Voltaire, después de visitar Londres en 1727, regresó apoyando a Newton. Incluso Cambridge, la propia universidad de Newton, continuaba enseñando filosofía natural por el texto de Jacques Rohault (1620-75), un cartesiano. Además, los matemáticos más eminentes de finales del siglo XVII —Huygens, Leibniz y Jean Bernoulli— se oponían al concepto de gravedad y, en consecuencia, a sus aplicaciones. Los métodos analíticos para tratar el movimiento de los planetas fueron abordados por Daniel Bernoulli, quien recibió un premio de la Academia de Ciencias francesa por un artículo de 1734 sobre el problema de los dos cuerpos, el cual fue desarrollado completamente por Euler en su libro Theoria Motuum Planetarum et Cometarum[142].
Si tenemos n cuerpos, cada uno de ellos esférico y con una masa distribuida con simetría esférica (o sea, la densidad es función del radio), se atraerán entre sí como si sus masas estuviesen concentradas en sus centros. Sean m1, m2,… mn las masas y (xi, yi, zi) las coordenadas (variables) de la masa í-ésima con respecto a un sistema fijo de ejes; sea rij la distancia de mi a mj. Entonces, las componentes según el eje x de las fuerzas que actúan sobre m1 son
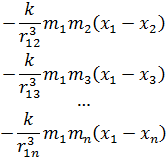
Las ecuaciones diferenciales del movimiento del cuerpo í-ésimo son entonces
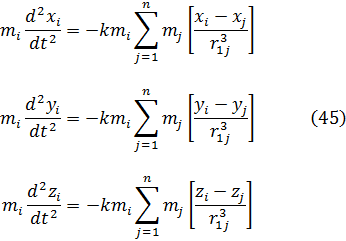
El problema de los n cuerpos, incluso para n = 3, de hecho, no se puede resolver exactamente; de ahí que las investigaciones sobre este problema hayan tomado dos direcciones. La primera se dirige a la búsqueda de cualesquiera teoremas de carácter general que se puedan obtener y que arrojen alguna luz sobre los movimientos, y la segunda, a la búsqueda de soluciones aproximadas que sean útiles durante un período de tiempo subsiguiente a un instante en el que se tengan datos disponibles, lo que se conoce como método de perturbaciones.
El primer tipo de investigaciones produjo algunos teoremas sobre el movimiento del centro de gravedad de n cuerpos, expuestos por Newton en sus Principia; por ejemplo, el centro de gravedad de los n cuerpos se mueve con velocidad uniforme en una línea recta; las diez integrales mencionadas antes, que derivan de las denominadas leyes de conservación del movimiento, constituyen también teoremas de ese tipo y eran conocidas por Euler. Hay también algunos resultados exactos para casos especiales del problema de los tres cuerpos, debidos a uno de los maestros de la mecánica celeste, Joseph-Louis Lagrange.
Lagrange (1736-1813) era de origen francés e italiano. De niño no estaba especialmente interesado en las matemáticas, pero, estando todavía en la escuela, leyó un ensayo de Halley sobre las virtudes del cálculo de Newton y se entusiasmó por el tema. A la edad de diecinueve años se convirtió en profesor de matemáticas de la Real Escuela de Artillería de Turín, ciudad en la que nació. Pronto realizó tales contribuciones a la matemática que fue reconocido desde una edad temprana como uno de los más grandes matemáticos de la época. Aunque Lagrange trabajó en muchas ramas de la matemática —teoría de números, teoría de las ecuaciones algebraicas, cálculo infinitesimal, ecuaciones diferenciales y cálculo de variaciones— y en muchas ramas de la física, su interés principal fue la aplicación de la ley de gravitación al movimiento de los planetas. Afirmaba en 1775: «Las investigaciones aritméticas son las que me han costado más dificultades y son quizá las de menos valor.» El ídolo de Lagrange era Arquímedes.
La obra más célebre de Lagrange, su Mécanique analytique (1788; segunda edición, 1811-15; edición póstuma, 1853), extendió, formalizó y coronó el trabajo de Newton en mecánica. Lagrange se quejó en cierta ocasión de que Newton había sido un hombre de los más afortunados, pues había un solo universo y Newton ya había descubierto sus leyes matemáticas; sin embargo, Lagrange tuvo el honor de hacer evidente al mundo la perfección de la teoría newtoniana. Aunque la Mécanique es un clásico de la ciencia y también es importante para la teoría y las aplicaciones de las ecuaciones diferenciales ordinarias, Lagrange tuvo dificultades para encontrar editor.
Las soluciones particulares exactas obtenidas para el problema de tres cuerpos fueron dadas por Lagrange en un artículo premiado de 1772, Essai sur le probléme des trois corps[143]. Una de estas soluciones establece que es posible poner tres cuerpos en movimiento de modo que sus órbitas sean elipses semejantes recorridas en el mismo tiempo y con el centro de gravedad de los tres cuerpos como un foco común. Otra solución corresponde a suponer que los tres cuerpos parten de los tres vértices de un triángulo equilátero, moviéndose entonces como si permaneciesen ligados al triángulo, que a su vez rota alrededor del centro de gravedad de los cuerpos. La tercera solución supone que los cuerpos son puestos en movimiento desde posiciones situadas sobre una línea recta; para condiciones iniciales apropiadas, continuarán sobre esa recta mientras ésta gira en un plano alrededor del centro de gravedad de los cuerpos. Para Lagrange, estos tres casos no tenían realidad física, pero en 1906 se encontró que el caso del triángulo equilátero se aplicaba al Sol, Júpiter y un asteroide llamado Aquiles.
El segundo tipo de problemas en relación con n cuerpos se refiere, como ya se dijo, a soluciones aproximadas, o sea, a la teoría de perturbaciones. Dos cuerpos esféricos sometidos a una atracción gravitatoria mutua se mueven a lo largo de secciones cónicas; un movimiento de este tipo se dice que es no perturbado y cualquier desviación respecto a tales movimientos, lo mismo en posición que en velocidad y sea por la causa que sea, es un movimiento perturbado. Si se trata de dos esferas pero hay resistencia por parte del medio en el cual se mueven, o si los dos cuerpos ya no son esféricos, sino, por ejemplo, esferoides achatados, o si están implicados más de dos cuerpos, entonces las órbitas ya no serán secciones cónicas. Antes de usar telescopios, las perturbaciones no eran llamativas. En el siglo XVIII, el cálculo de perturbaciones se convirtió en un problema matemático del mayor interés, al cual realizaron contribuciones Clairaut, D’Alembert, Euler, Lagrange y Laplace; el trabajo de este último en este campo fue el más destacado.
Pierre-Simon de Laplace (1749-1827) nació de padres bastante acomodados en la ciudad de Beaumont, Normandía. Pudo llegar a convertirse en sacerdote, pero se aficionó a las matemáticas en la Universidad de Caen, donde ingresó a la edad de dieciséis años; pasó cinco años en Caen y en ese tiempo escribió un artículo sobre el cálculo de diferencias finitas. Después de acabar sus estudios, Laplace fue a París con cartas de recomendación para D’Alembert, quien no le prestó atención; Laplace escribió entonces una carta a D’Alembert exponiéndole los principios generales de la mecánica y esta vez éste le hizo caso, lo llamó y le consiguió el puesto de profesor en la Ecole Militaire de París.
Laplace publicó prolíficamente ya de joven; una declaración hecha en la Academia de Ciencias de París poco después de su elección en 1773 señalaba que nadie tan joven había presentado tantos artículos sobre temas tan diversos y difíciles. En 1783, reemplazó a Bezout como examinador en artillería y examinó a Napoleón. Durante la Revolución fue nombrado miembro de la Comisión de Pesos y Medidas, pero fue expulsado más tarde, junto con Lavoisier y otros, por no ser un buen republicano. Laplace se retiró a Melun, una pequeña ciudad cercana a París, y allí trabajó en su célebre y popular Exposition du systéme du monde (1796). Después de la Revolución se convirtió en profesor de la Ecole Nórmale, en la que también enseñaba por ese tiempo Lagrange, y formó parte de diversos comités gubernamentales. Después de eso fue ministro del Interior, miembro del Senado y canciller de dicha cámara. Aunque fue honrado por Napoleón con el título de conde, Laplace votó contra él en 1814 y se unió a Luis XVIII, quien lo nombró marqués de Laplace y par de Francia.
Durante estos años de actividad política continuó dedicándose a la ciencia. Entre 1799 y 1825 aparecieron los cinco volúmenes de su Mécanique céleste, obra en la que Laplace presentaba soluciones analíticas «completas» a los problemas planteados por el sistema solar; utilizó lo menos posible datos de observación; la Mécanique céleste incorpora descubrimientos y resultados de Newton, Clairaut, D’Alembert, Euler, Lagrange y el propio Laplace; fue una obra maestra tan completa que sus inmediatas sucesoras poco pudieron añadir; quizá su único defecto es que Laplace descuidó frecuentemente el reconocer las fuentes de sus resultados, dejando la impresión de que todos eran suyos.
En 1812 publicó su Théorie analytique des probabilités; la introducción a la segunda edición (1814) constituye un popular ensayo conocido como Essai philosophique sur les probabilités, que contiene el célebre pasaje relativo a que el futuro del mundo está completamente determinado por el pasado y que si se tuviese el conocimiento matemático del estado del mundo en un instante dado, se podría predecir el futuro.
Laplace realizó muchos descubrimientos importantes en física matemática, algunos de los cuales consideraremos en capítulos posteriores. Realmente, estaba interesado en todo lo que contribuyese a interpretar la naturaleza; trabajó en hidrodinámica, en la propagación ondulatoria del sonido y en las mareas. En el campo de la química, es clásico su trabajo sobre el estado líquido de la materia; sus estudios sobre la tensión en la capa superficial del agua, que explica el ascenso de los líquidos en tubos capilares, y sobre las fuerzas de cohesión en los líquidos, son fundamentales. Laplace y Lavoisier diseñaron un calorímetro de hielo (1784) para medir el calor y midieron el calor específico de numerosas sustancias; el calor era todavía para ellos una clase especial de materia. La mayor parte de la vida de Laplace, sin embargo, estuvo dedicada a la mecánica celeste; murió en 1827 y sus últimas palabras se dice que fueron: «Lo que conocemos es muy poco; lo que ignoramos es inmenso.» —aunque De Morgan afirma que fueron: «El hombre sólo persigue fantasmas.»
A Laplace se le vincula con frecuencia a Lagrange, pero no se parecen ni en cualidades personales ni en su trabajo. La vanidad de Laplace le hizo abstenerse de dar el debido reconocimiento a los trabajos de aquellos a los que consideraba sus rivales; de hecho, utilizó muchas ideas de Lagrange sin reconocerlo, y cuando se menciona a Laplace en relación con Lagrange es siempre para elogiar las cualidades personales del segundo. Lagrange es el matemático, muy cuidadoso en sus escritos, muy claro y muy elegante. Laplace creó métodos matemáticos nuevos que posteriormente se desarrollaron en ramas de la matemática, pero nunca se preocupó de la matemática excepto en lo que le servía para estudiar la naturaleza; cuando se encontraba con un problema matemático en sus investigaciones físicas, lo resolvía casi de pasada, afirmando simplemente que «es fácil ver que...» sin molestarse en mostrar cómo había obtenido el resultado; confesaba, sin embargo, que no era fácil reconstruir su propio trabajo. Nathaniel Bowditch (1773-1838), matemático y astrónomo americano que tradujo cuatro de los cinco volúmenes de la Mécanique céleste, añadiendo explicaciones, dijo que cada vez que se encontraba la frase «es fácil ver que...» sabía que le esperaban horas de duro trabajo para rellenar las lagunas. En realidad, Laplace se impacientaba con las matemáticas y deseaba pasar a las aplicaciones; la matemática pura no le interesaba y sus contribuciones a ella eran subproductos de su gran trabajo en filosofía natural; la matemática era un medio, no un fin, un útil que había que perfeccionar con el fin de resolver los problemas de la ciencia.
El trabajo de Laplace, en lo que importa al tema de este capítulo, trata de soluciones aproximadas de los problemas del movimiento planetario. La posibilidad de obtener soluciones útiles mediante un método aproximado se apoya en los siguientes factores. El sistema solar está dominado por el Sol, que contiene el 99,87 por 100 de la masa total del sistema; esto significa que las órbitas de los planetas son casi elípticas, ya que las fuerzas perturbativas entre los planetas son pequeñas; no obstante, Júpiter posee el 70 por 100 de la masa planetaria y, además, la Luna terrestre está bastante cerca de la Tierra y por ello se influyen la una a la otra. Es necesario, por todo ello, considerar perturbaciones.
El problema de los tres cuerpos, especialmente Sol, Tierra y Luna, fue muy estudiado en el siglo XVIII, en parte porque era el paso siguiente al problema de los dos cuerpos y en parte porque se necesitaba un conocimiento preciso del movimiento de la Luna para la navegación. En el caso del Sol, Tierra y Luna, se puede sacar partido del hecho de que el Sol está lejos de los otros dos cuerpos y suponer que sólo ejerce una influencia pequeña sobre el movimiento relativo de la Tierra y la Luna. En el caso del Sol y dos planetas, se considera que uno de éstos perturba el movimiento del otro alrededor del Sol; si uno de los planetas es pequeño, se puede despreciar su efecto gravitatorio sobre el otro, pero sí hay que tener en cuenta el efecto del grande sobre el pequeño. Estos casos especiales del problema de los tres cuerpos constituyen el problema restringido de los tres cuerpos.
La teoría de perturbaciones para el problema de tres cuerpos se aplicó en primer lugar al movimiento de la Luna, cosa que realizó Newton geométricamente en el tercer libro de sus Principia. Euler y Clairaut intentaron obtener soluciones exactas para el problema de tres cuerpos, quejándose de las dificultades y recurriendo, por supu, a métodos aproximados. Clairaut logró en esto el primer progreso real (1747) utilizando soluciones en serie de las ecuaciones diferenciales; tuvo ocasión de aplicar su resultado al movimiento del cometa Halley, que había sido observado en 1531, 1607 y 1682; se esperaba que estuviese en el perihelio de su trayectoria alrededor de la Tierra en 1759; Clairaut calculó las perturbaciones debidas a la atracción de Júpiter y Saturno y predijo en un artículo leído en la Academia de París el 14 de noviembre de 1758 que el perihelio tendría lugar el 13 de abril de 1759, haciendo notar que el momento exacto era dudoso con un margen de un mes debido a que las masas de Júpiter y Saturno no se conocían con precisión y a ligeras perturbaciones causadas por otros planetas; el cometa alcanzó su perihelio el 13 de marzo.
Para calcular perturbaciones se desarrolló, y resultó ser el más eficaz, el denominado método de variación de los elementos o variación de los parámetros —o, todavía, de variación de las constantes de integración—. Vamos a examinarlo limitándonos a sus principios matemáticos y sin tomar en consideración su trasfondo físico.
El método matemático de variación de los parámetros se remonta a los Principia de Newton; después de estudiar el movimiento de la Luna alrededor de la Tierra y obtener la órbita elíptica, Newton tuvo en cuenta los efectos del Sol sobre la órbita de la Luna considerando variaciones en dicha órbita. El método había sido utilizado por Jean Bernoulli en las Acta Eruditorum de 1697[144] para resolver ejemplos aislados de ecuaciones no homogéneas y por Euler en 1739 al tratar la ecuación de segundo orden y" + k2y = X(x). Fue utilizado por primera vez para estudiar perturbaciones de los movimientos planetarios por Euler en su artículo de 1748[145], el cual trataba de las perturbaciones mutuas de Júpiter y Saturno y ganó un premio de la Academia francesa. Laplace escribió muchos artículos[146] sobre el método, método que fue desarrollado completamente por Lagrange en dos artículos[147].
Lagrange aplicó el método de variación de los parámetros para una única ecuación diferencial ordinaria a la ecuación de orden n:
Py + Qy' + Ry" +… + Vy(n) = X,
donde X, P, Q, R, … son funciones de x. Supondremos, para simplificar, que tenemos una ecuación de segundo orden.En el caso X = 0, Lagrange sabía que la solución general es
y = ap(x) + bq(x) (46)
donde a y b son constantes de integración y p y q son integrales particulares de la ecuación homogénea. Ahora, dice Lagrange, consideramos a y b como funciones de x. Entonces![]()
pa' + qb' = 0 (48)
es decir, hace igual a 0 la parte de y' que resulta de la variabilidad de a y b. Resulta entonces de (47) y (48)![]()
Sustituye ahora las expresiones de y, dy/dx y d2y/dx2 dadas por (46), (47) y (49) en la ecuación original; como (46) es solución de la ecuación homogénea y (48) permite eliminar alguno de los términos que resultan de la variabilidad de a y b, queda después de la sustitución
p'a' + q'b' = Q/R (50)
Esta ecuación y la ecuación (48) constituyen un sistema algebraico en las funciones incógnitas a' y b' que se puede resolver en términos de las funciones conocidas p, q, p', q', X y R. Entonces, a y b se pueden obtener mediante una integración o al menos quedar reducidas a una cuadratura. Con estos valores de a y b, (46) da una solución de la ecuación no homogénea original; esta solución, sumada a la solución general de la ecuación homogénea, da la solución general de la ecuación no homogénea.El método de variación de los parámetros fue tratado de una manera más general por Lagrange[148], quien demostró su aplicabilidad a muchos problemas de la física. En un artículo de 1808 lo aplicó a un sistema de tres ecuaciones de segundo orden; la técnica es, por supuesto, más complicada pero la idea es de nuevo considerar las seis constantes de integración de la solución del correspondiente sistema homogéneo como variables y determinarlas de modo que la expresión resultante satisfaga el sistema no homogéneo.
Durante el período en que estaban desarrollando el método de variación de los parámetros y en el tiempo que siguió, Lagrange y Laplace escribieron varios artículos clave sobre problemas fundamentales del sistema solar. En su obra cumbre, la Mécanique céleste, Laplace resumió el alcance de sus resultados:
Hemos dado, en la primera parte de este trabajo, los principios generales del equilibrio y el movimiento de cuerpos. La aplicación de estos principios a los movimientos de los cuerpos celestes nos condujo, por razonamientos geométricos [analíticos], sin ninguna hipótesis, a la ley de atracción universal, de la que son casos particulares la acción de la gravedad y el movimiento de proyectiles. Consideramos después un sistema de cuerpos sometido a esta gran ley de la naturaleza y obtuvimos, mediante un análisis apropiado, las expresiones generales de sus movimientos, de sus formas y de las oscilaciones de los fluidos que los cubren. A partir de estas expresiones hemos deducido todos los fenómenos conocidos del flujo y reflujo de las mareas, las variaciones de la gravedad en grados y en fuerza sobre la superficie de la Tierra, la precisión de los equinoccios, la libración de la Luna y la forma y rotación de los anillos de Saturno. Hemos deducido además, a partir de la misma teoría de la gravedad, las principales ecuaciones de los movimientos de los planetas, en particular, los de Júpiter y Saturno, cuyas grandes anomalías tienen un período de más de 900 años[149].
Laplace concluía que la naturaleza ordenaba la máquina celeste «para una duración eterna, sobre los mismos principios que prevalecen tan admirablemente sobre la Tierra, para la conservación de los individuos y para la perpetuación de las especies».
Según se fueron mejorando los métodos para resolver ecuaciones diferenciales y conociendo nuevos datos físicos sobre los planetas, se fueron produciendo esfuerzos a lo largo de los siglos XIX y XX para obtener mejores resultados sobre varias de las cuestiones que Laplace menciona, en particular, sobre el problema de los n cuerpos y la estabilidad del sistema solar.
8. Sumario
Como hemos visto, los intentos para resolver problemas físicos, que al principio involucraban solamente cuadraturas, llevaron gradualmente a darse cuenta de que se estaba creando una nueva rama de la matemática, a saber, las ecuaciones diferenciales ordinarias. A mediados del siglo XVIII las ecuaciones diferenciales se convirtieron en una disciplina independiente y su resolución en un fin en sí mismo.
La naturaleza de lo que se consideraba y buscaba como solución fue cambiando gradualmente. Al principio, los matemáticos buscaban soluciones en términos de funciones elementales, pero pronto se contentaron con dar una respuesta en términos de una cuadratura que quizá no pudiese efectuarse. Cuando fracasaron las principales vías para encontrar soluciones en términos de funciones elementales y de cuadraturas, los matemáticos se contentaron con buscar soluciones en forma de serie.
El problema de encontrar soluciones en forma cerrada no cayó en el olvido, pero en lugar de intentar resolver de ese modo las ecuaciones diferenciales concretas que surgían de los problemas físicos, los matemáticos buscaron ecuaciones diferenciales que admitiesen soluciones en términos de un número finito de funciones elementales; se encontró un gran número de ecuaciones diferenciales de este tipo. D’Alembert (1767) trabajó en este problema e incluyó las integrales elípticas entre las respuestas admisibles. Un enfoque típico de este problema, desarrollado —entre otros— por Euler (1769), consistía en empezar con una ecuación diferencial cuya integración no se podía realizar en forma cerrada y derivar de ella otra ecuación diferencial; en otro enfoque, se buscaban condiciones bajo las cuales la solución en serie pudiese contener solamente un número finito de términos.
Interesante, pero infructuoso, fue el trabajo de Marie-Jean-Antoine-Nicolas Caritat de Condorcet (1743-94) en Du calcul intégral intentando poner orden y método en los diversos y numerosos métodos y artificios para resolver ecuaciones diferenciales. Enumeró las operaciones de derivación, eliminación y sustitución y trató de reducir todos los métodos a esas operaciones canónicas, pero su trabajo no llevó a ninguna parte. En línea con ese objetivo, Euler demostró que cuando es posible la separación de variables, existe un factor integrante, pero no recíprocamente; también demostró que la separación de variables no es aplicable a ecuaciones diferenciales de orden superior. En cuanto a las sustituciones, no halló principios generales para obtenerlas[150]; hallar sustituciones es tan difícil como resolver directamente la ecuación diferencial; sin embargo, una transformación puede reducir el orden de una ecuación diferencial y Euler sacó partido de esta idea para resolver la ecuación diferencial ordinaria lineal no homogénea de orden n, e incluso pensó que, en el caso de la ecuación homogénea, cada exp [Jp dx], con el apropiado valor de p, daría un factor de primer orden de la ecuación diferencial ordinaria. Reducir el orden fue también el objetivo de Riccati. Se idearon otros métodos, como el de los multiplicadores de Lagrange, que se creyó que sería general pero resultó no serlo.
La búsqueda de métodos generales para integrar ecuaciones diferenciales ordinarias finalizó hacia 1775. Quedaba mucha labor por hacer en el campo de las ecuaciones diferenciales ordinarias, en particular la que se derivaba de la resolución de ecuaciones en derivadas parciales, pero no se descubrieron nuevos métodos importantes fuera de los que hemos examinado aquí hasta pasados unos cien años, cuando se introdujeron, a finales del siglo XIX, los métodos operacionales y la transformada de Laplace. En realidad, los métodos generales de resolución retrocedieron a causa de que se obtenían métodos que, de una u otra forma, se mostraban adecuados a los tipos de ecuaciones que se presentaban en las aplicaciones; no hay todavía unos principios amplios y generales para la resolución de ecuaciones diferenciales ordinarias; en su conjunto, la materia ha continuado siendo una serie de distintas técnicas para los diferentes tipos de ecuaciones.
Bibliografía
- Bernoulli, Jacques: Opera, 2 vols., 1744, reimpreso por Birkhaüser, 1968.
- Bernoulli, Jean: Opera Omnia, 4 vols., 1742, reimpreso por Georg Olms, 1968.
- Berry, Arthur: A Short History of Astronomy, Dover (reimpresión), 1961, caps. 9-11.
- Cantor, Moritz: Vorlesungen über Geschichte der Mathematik, B. G. Teubner, 1898 y 1924, vol. 3 caps. 100 y 118, vol. 4, sec. 27.
- Delambre, J. B. J.: Histoire de L'astronomie moderne, 2 vols., 1821, Johnson Reprint Corp., 1966.
- Euler, Leonhard: Opera Omnia, Orell Füssli, serie 1, vols. 22 y 23, 1936 y 1938; serie 2, vols. 10 y 11, parte 1, 1947 y 1957.
- Hofmann, J. E.: «Über Jakob Bernoullis Beitráge zür Infinitesimal-mathematik», L'Enseignement Mathématique, (2), 2, 61-171. Publicado separadamente por el Institut de Mathématiques, Ginebra, 1957.
- Lagrange, Joseph-Louis: (Œuvres de Lagrange, Gauthier-Villars, 1868-1873, los artículos relevantes en vols. 2, 3, 4 y 6. —: Mécanique analytique, 1788, 4.a ed., Gauthier-Villars, 1889. La cuarta edición es una reproducción inalterada de la tercera edición de 1853.
- Lalande, J. de: Traité d’astronomie, 3 vols., 1792, Johnson Reprint Corp., 1964.
- Laplace, Pierre-Simon: (Œuvres completes, Gauthier-Villars, 1891-1904, los artículos relevantes en los vols. 8, 11 y 13. —: Traité de mécanique céleste, 5 vols., 1799-1825. También en Œuvres completes, vols. 1-5, Gauthier-Villars, 1878-82. Traducción inglesa de los vols. 1-4 por Nathaniel Bowditch, 1829-39, Chelsea (reimpresión), 1966. —: Exposition du systéme du monde, 1.a ed., 1796, 6.a ed. en (Œuvres completes, Gauthier-Villars, 1884, vol. 6.
- Motucla, J. F.: Histoire des mathématiques, 1803, Albert Blanchard (reimpresión), 1960, vol. 3, 163-200; vol. 4, 1-125.
- Todhunter, I.: A History of the Mathematical Theories of Attraction and the figure of the Earth, 1873, Dover (reimpresión), 1962.
- Truesdell, Clifford E.: Introduction to Leonhardi Euleri Opera Omnia, vol. X et XI Seriei Secundae,en Euler, Opera Omnia,(2), 11, parte 2, Orell Füssli, 1960.
Capítulo 22
Las ecuaciones en derivadas parciales en el siglo XVIII
El análisis matemático es tan extenso como la propia naturaleza.Contenido:
JOSEPH FOURIER
1. Introducción1. Introducción
2. La ecuación de ondas
3. Extensiones de la ecuación de ondas
4. Teoría del potencial
5. Ecuaciones en derivadas parciales de primer orden
6. Monge y la teoría de las características
7. Monge y las ecuaciones de segundo orden no lineales
8. Sistemas de ecuaciones en derivadas parciales de primer orden
9. El desarrollo de las ecuaciones en derivadas parciales como disciplina matemática
Bibliografía
Lo mismo que en el caso de las ecuaciones diferenciales ordinarias, los matemáticos no crearon la disciplina de las ecuaciones en derivadas parciales de una manera consciente. Continuaron explorando los mismos problemas físicos que condujeron a aquéllas, y a medida que fueron adquiriendo una mejor comprensión de los principios físicos subyacentes a los fenómenos estudiados, formularon proposiciones matemáticas que hoy pertenecen al campo de las ecuaciones en derivadas parciales. De este modo, si los desplazamientos de una cuerda que vibra habían sido estudiados separadamente como función del tiempo y como función de la distancia de un punto de la cuerda a uno de sus extremos, el estudio de aquéllos como función de ambas variables conjuntamente y el intento de comprender todos los posibles movimientos condujeron a una ecuación en derivadas parciales. La continuación natural de este estudio, a saber, la investigación de la propagación en el aire de los sonidos generados por la cuerda, introdujo nuevas ecuaciones en derivadas parciales, abordando a continuación los matemáticos el estudio de los sonidos producidos por trompas de todas las formas, tubos de órgano, campanas, tambores y otros instrumentos.
El aire es un tipo de fluido, en el sentido en que se usa el término en física, que resulta ser compresible, mientras que los líquidos son fluidos (virtualmente) incompresibles. Las leyes del movimiento de tales fluidos y, en particular, las ondas que pueden propagarse en ambos tipos de fluidos dieron lugar a un extenso campo de investigación que hoy constituye la disciplina de la hidrodinámica; también en este campo surgieron ecuaciones en derivadas parciales.
A lo largo del siglo XVIII, los matemáticos continuaron trabajando sobre el problema de la atracción gravitatoria ejercida por cuerpos de diferentes formas, especialmente el elipsoide. Si bien es éste, básicamente, un problema de integración triple, Laplace lo convirtió en un problema de ecuaciones en derivadas parciales de una manera que examinaremos en breve.
2. La ecuación de ondas
Aunque aparecieron ecuaciones en derivadas parciales concretas ya en 1734 en la obra de Euler[151] y en 1743 en el Traité de dynamique de D’Alembert, no se hizo con ellas nada que merezca la pena reseñar. El primer éxito real con las ecuaciones en derivadas parciales llegó como fruto de renovados ataques al problema de la cuerda vibrante, tipificada por una cuerda de violín. La aproximación de que las vibraciones sean pequeñas se impuso para hacer tratable la ecuación en derivadas parciales. Jean Le Rond D'Alembert (1717-83), en sus artículos de 1746[152] titulados «Investigaciones sobre la curva que forma una cuerda tensa que se hace vibrar», afirma que se propone demostrar que existen infinitas curvas además de la curva seno que son modos de vibración.
Recordemos del capítulo precedente que en las primeras aproximaciones al problema de la cuerda vibrante, ésta se contemplaba como un «collar de cuentas», es decir, la cuerda se consideraba compuesta de una cantidad discreta de n pesos iguales e igualmente espaciados, unidos por trozos de hilo elástico, flexible y sin peso. Para tratar la cuerda continua, se hacía tender a infinito el número de pesos mientras decrecía el tamaño y la masa de cada uno de ellos, de manera que la masa total de la creciente cantidad de «cuentas» individuales se aproximase a la masa de la cuerda continua; había dificultades matemáticas en ese paso al límite, pero esas sutilezas se pasaban por alto.
El caso de una cantidad discreta de masas había sido tratado por Jean Bernoulli en 1727 (cap. 21, sec. 4); si la cuerda tiene longitud l y ocupa 0 ≤ x ≤ l, y si xk es la abscisa de la masa n-ésima, n = 1, 2,..., n (la masa n-ésima, situada en x = l, no se mueve), entonces
xk =k l/n k = 1, 2,. . ., n.
Analizando la fuerza que actúa sobre la masa n-ésima, Bernoulli había probado que si yk es el desplazamiento de dicha masa, entonces![]()
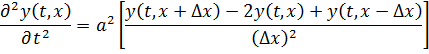
![]()
Como la cuerda está fijada en los extremos x = 0 y x = l, la solución ha de satisfacer las condiciones de contorno
y(t, 0) = 0, y(t, l) = 0 (2)
En el instante t = 0 se fuerza a que la cuerda adopte un perfil y=f(x) y entonces se suelta, lo que significa que cada partícula comienza con una velocidad inicial nula; estas condiciones iniciales se expresan matemáticamente en la forma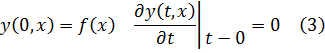
Este problema fue resuelto por D’Alembert de una manera tan ingeniosa que se reproduce con frecuencia en los textos modernos. No nos detendremos en todos los detalles; demostró en primer lugar que
![]()
![]()
ϕ(x + at) = ψ(x + at) (6)
cualesquiera que sean x y t. En consecuencia, la condición y(t, l) = 0 se convierte, a la vista de (4), en½ ϕ(at + l) = ½ ϕ(at l) (7)
y como esta última es una identidad en t, se deduce que ϕ ha de ser periódica en at + x con período 2l.La condición

ϕ'(x) = ϕ'(-x) (9)
lo que, integrando, daϕ(x) = -ϕ(-x) (10)
y por lo tanto ϕ es una función impar de x. Si utilizamos ahora en (4) el que ϕ = ψ 0, formamos y(0, x) y aplicamos (10), se tendrá quey(0, x) = ϕ (x) (11)
y como la condición inicial es y(0, x) = f(x), resultaráϕ(x) = f (x) para 0 ≤ x ≤ l (12)
Resumiendo,![]()
Pocos meses después de ver los artículos de 1746 de D’Alembert, Euler escribió por su parte el artículo «Sobre la oscilación de cuerdas», que fue presentado el 16 de mayo de 1748[153]. Aunque en el método de solución siguió a D’Alembert, Euler tenía por ese tiempo una idea completamente distinta en cuanto a qué funciones se podían admitir como curvas iniciales y, en consecuencia, como soluciones de una ecuación en derivadas parciales. Antes incluso del debate sobre el problema de la cuerda vibrante, en un trabajo de 1734, de hecho Euler aceptaba funciones formadas a partir de trozos de curvas conocidas e incluso las obtenidas dibujando curvas a pulso.
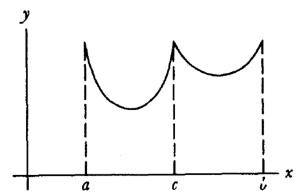
Figura 22.1
y = ϕ(ct + x) + ψ(ct x) (14)
con ϕ y ψ arbitrarias, es solución de![]()
En 1755, Euler dio como nueva definición de función la siguiente: «Si unas cantidades dependen de otras de tal modo que sufren una variación cuando estas últimas varían, entonces se dice que las primeras son funciones de las segundas.» Y en otro artículo[155] afirma que las partes de una función «discontinua» no se pertenecen unas a otras y no están determinadas por una única ecuación válida para la función en toda su extensión. Además, dado el perfil inicial en 0 ≤ x ≤ l, se repite en orden inverso en -l ≤ x ≤ 0 (para tener una función impar), imaginando después una repetición continua de la curva resultante en cada intervalo de longitud 2l, hasta el infinito. Entonces, si se utiliza esa curva [y = f(x)] para representar la función inicial, la ordenada en el instante t correspondiente a la abscisa x de la cuerda que oscila, estará dada por (cf. (13) y (12))
![]()
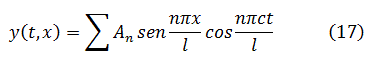
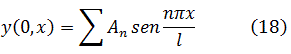
Al introducir sus funciones «discontinuas», Euler comprendió que había dado un gran paso hacia adelante; el 20 de diciembre de 1720 escribió a D’Alembert que «el considerar tal tipo de funciones, no sujetas a ninguna ley de continuidad [analiticidad], nos abre todo un nuevo campo de análisis»[156].
El problema de la cuerda vibrante fue resuelto de una manera completamente diferente por Daniel Bernoulli; su trabajo suscitó otro motivo para la controversia relativa a las soluciones admisibles. Daniel Bernoulli (1700-82), hijo de Jean Bernoulli, fue profesor de matemáticas en San Petersburgo de 1725 a 1733 y después, sucesivamente, profesor de medicina, metafísica y filosofía natural en Basilea; realizó su obra más importante en hidrodinámica y elasticidad, ganando, en el primero de estos campos, un premio por un artículo sobre el flujo de las mareas; también consideró la aplicación de la teoría sobre el movimiento de líquidos al flujo de la sangre humana en los vasos sanguíneos. Fue un hábil experimentador y descubrió antes de 1760, mediante trabajo experimental, la ley de atracción de cargas eléctricas estáticas, ley que habitualmente se atribuye a Charles Coulomb. La Hydrodinamica de Bernoulli (1738), que contiene estudios que aparecieron en diversos artículos, es el primer texto importante en su campo; incluye un capítulo sobre la teoría mecánica del calor (en tanto que opuesta a la consideración del calor como una sustancia) y da muchos resultados sobre la teoría de gases.
En su artículo de 1732-33 citado en el capítulo precedente, Daniel Bernoulli había afirmado expresamente que la cuerda vibrante podía tener modos superiores de oscilación; en un artículo[157] posterior sobre la oscilación de una cuerda vertical flexible cargada con pesos, hizo la siguiente observación:
Análogamente, una cuerda musical tensa puede producir sus vibraciones isócronas de muchas maneras, incluso, de acuerdo con la teoría, de infinitas maneras..., y además en cada momento emite una nota superior o inferior. El primer y más natural modo tiene lugar cuando la cuerda produce en sus oscilaciones un sólo arco; se produce entonces la oscilación más lenta y se emite el tono más bajo de entre todos los posibles, fundamental respecto al resto. El siguiente modo exige que la cuerda produzca dos arcos a lados opuestos [de la posición de equilibrio de la cuerda] siendo entonces la oscilación el doble de rápida y emitiéndose ahora la octava del sonido fundamental.Describe después los modos superiores; no proporciona los argumentos matemáticos pertinentes, pero parece evidente que disponía de ellos.
En un artículo sobre las vibraciones de una barra y los sonidos que ésta emite[158], Bernoulli no sólo da los distintos modos en que la barra puede vibrar sino que afirma claramente que ambos sonidos (el fundamental y un armónico superior) pueden existir a la vez. Es ésta la primera afirmación de la coexistencia de oscilaciones armónicas pequeñas; Bernoulli la basó en su comprensión física de cómo pueden comportarse la barra y los sonidos, pero no dio ningún argumento matemático para justificar que la suma de dos modos es una solución.
Cuando leyó el primer artículo de D’Alembert de 1746 y el de Euler de 1749 sobre la cuerda vibrante, se apresuró a publicar las ideas que había obtenido durante muchos años[159]. Después de permitirse sarcasmos sobre el carácter abstracto de los trabajos de D’Alembert y Euler, reitera que pueden existir simultáneamente muchos modos de oscilación en la cuerda vibrante (ésta responde entonces a la suma o superposición de todos los modos) y pretende que esto es todo lo que Euler y D’Alembert habían demostrado. Plantea después una cuestión fundamental; insiste en que todas las posibles curvas iniciales se pueden representar en la forma.
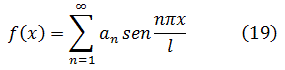

Mi conclusión es que todos los cuerpos sonoros incluyen una infinidad de sonidos con una correspondiente infinidad de vibraciones regulares... Pero no es de esta multitud de sonidos de la que los señores D’Alembert y Euler dicen hablar... Cada clase [cada modo fundamental generado por una curva inicial] se multiplica un número infinito de veces para ajustar a cada intervalo un número infinito de curvas, de modo que cada punto comienza y termina en el mismo instante estas vibraciones mientras que, de acuerdo con la teoría del señor Taylor, cada intervalo entre dos nodos adoptará la forma de la asociada de la cicloide [la función seno] muy alargada.En esta última observación, Bernoulli atribuye a Taylor algo que éste nunca demostró conocer. Aparte de esto, las afirmaciones de Bernoulli son enormemente importantes.
Señalemos además que la cuerda AB no puede vibrar sólo conforme a la primera figura [modo fundamental] o la segunda [segundo armónico] o la tercera, y así hasta el infinito, sino que podrá hacerlo según una combinación de esas vibraciones entre todas las combinaciones posibles, y que todas las nuevas curvas dadas por D’Alembert y Euler son únicamente combinaciones de las vibraciones de Taylor.
Euler puso inmediatamente objeciones a la última afirmación de Bernoulli. De hecho, el artículo de Euler de 1753 presentado a la Academia de Berlín (ya mencionado más arriba) era en parte una réplica a los dos artículos de Bernoulli. Euler resalta la importancia
de la ecuación de ondas como punto de partida para el estudio de la cuerda vibrante; elogia cómo Bernoulli vio que pueden existir simultáneamente muchos modos de vibración y, por ende, que la cuerda puede emitir en un movimiento muchos armónicos, pero niega, lo mismo que D’Alembert, que todos los posibles movimientos puedan representarse por (20). Admite que una curva inicial tal como
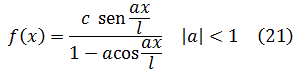
![]()
Euler se refirió también, en este caso correctamente, a la serie de Maclaurin afirmando que ésta no podía representar cualquier función arbitraria; en consecuencia, tampoco podía hacerlo una serie de senos. Todo lo más, concedía que las series trigonométricas de Bernoulli representaban soluciones particulares y, en efecto, el propio Euler había obtenido tales soluciones en su artículo de 1749 (ver [17] y [18]).
D’Alembert, en su artículo «Fondamental» del volumen 7 (1757) de la Encyclopédie, atacó también a Bernoulli. No creía que todas las funciones periódicas e impares se pudiesen representar mediante una serie como (19), pues la serie es derivable dos veces mientras que no toda función de aquel tipo tiene por qué serlo. No obstante, incluso cuando la curva inicial es suficientemente derivable y D’Alembert requería en su artículo de 1746 que fuese dos veces derivable— no tiene por qué ser representable en la forma de Bernoulli. D’Alembert puso también reparos, sobre la misma base, a las curvas discontinuas de Euler. De hecho, el requisito de D’Alembert de que la curva inicial y = f(x) sea dos veces derivable era correcto, pues una solución obtenida a partir de una f(x) que no tenga derivada segunda en ciertos valores de x ha de satisfacer condiciones especiales en tales puntos singulares.
Bernoulli no se retractó de su postura. En una carta de 1758[160] repite que tiene en los an una cantidad infinita de coeficientes a su disposición que, elegidos apropiadamente, le permiten hacer coincidir la serie de (19) con cualquier función en una cantidad infinita de puntos. En cualquier caso, Bernoulli insistió en que (20) era la solución más general. La discusión entre D’Alembert, Euler y Bernoulli continuó por una década sin que se alcanzase un acuerdo. La esencia del problema era la amplitud de la clase de funciones que se podían representar mediante una serie de senos, o, más generalmente, una serie de Fourier.
En 1759, Lagrange, entonces joven y desconocido, se unió a la controversia. En su artículo, que trataba de la naturaleza y propagación del sonido[161], daba algunos resultados sobre este tema y después aplicaba su método a la cuerda vibrante. Procedió como si estuviese abordando un problema nuevo, aunque repitió mucho de lo que habían hecho antes Euler y Daniel Bernoulli. Lagrange comenzó también con una cuerda cargada con un número finito de masas iguales e igualmente espaciadas, pasando después al límite cuando ese número se hace infinito. Aunque criticó el método de Euler por restringir los resultados a curvas continuas (analíticas), Lagrange afirmó que demostraría que la conclusión de Euler —que cualquier curva inicial puede servir—, era correcta. Pasemos inmediatamente a la conclusión de Lagrange para la cuerda continua; había obtenido
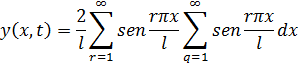
![]()
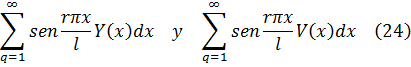
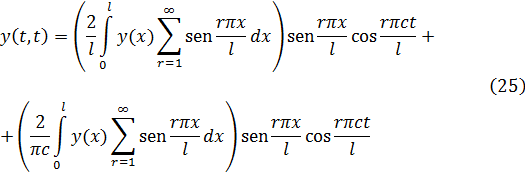
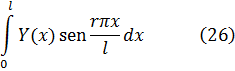
![]()
más allá de toda duda y establecida sobre principios directos y claros que no reposan en absoluto sobre la ley de continuidad [analiticidad] que D’Alembert requiere; así es, además, cómo puede ocurrir que la misma fórmula que sirve para respaldar y probar la teoría de Bernoulli sobre la mezcla de vibraciones isócronas cuando el número de cuerpos es... finito nos muestra su insuficiencia... cuando el número de esos cuerpos se hace infinito. En efecto, el cambio que sufre esta fórmula al pasar de un caso a otro es tal que los movimientos absolutos simples que componen los movimientos absolutos del sistema completo se anulan entre sí en su mayor parte, y los que quedan están tan desfigurados y alterados que resultan completamente irreconocibles. Verdaderamente, es una contrariedad que una teoría tan ingeniosa... resulte falsa en el caso principal, con el cual están relacionados todos los movimientos recíprocos pequeños que se presentan en la naturaleza.Todo esto es un absurdo casi completo.
El principal argumento de Lagrange para sostener que su solución no exige restricciones sobre la curva inicial Y(x) y la velocidad inicial V(x) es que no aplica a éstas la operación de derivación. Pero si intentásemos rigorizar lo que él hizo sí habría que imponer restricciones.
Euler y D’Alembert criticaron el trabajo de Lagrange, pero en realidad apuntaron a detalles de sus «prodigiosos cálculos», como dijo Euler, y no señalaron sus principales fallos. Lagrange intentó responder a las críticas, siendo las réplicas y refutaciones de ambos campos demasiado extensas para relatarlas aquí, aunque muchas de ellas son reveladoras del pensamiento de la época. Por ejemplo, Lagrange reemplazó sen π/m para m = ∞ por π/m y sen vπ/2m por vπ/2m para m = ∞. D’Alembert aceptaba lo primero pero no lo segundo, porque los valores de v implicados eran comparables a los de m. La objeción de que una serie de la forma
cos x + cos 2x + cos 3x + …
podía ser divergente fue también suscitada por D’Alembert, replicando Lagrange con el argumento, común en aquel tiempo, de que el valor de la serie es el valor de la función de la que la serie proviene.Aunque Euler criticó algunos detalles matemáticos, su juicio de conjunto sobre el artículo de Lagrange, comunicado en una carta del 23 de octubre de 1759[162], fue elogiar la destreza matemática de Lagrange y afirmar que ponía toda la discusión más allá de cualquier objeción, y que todo el mundo debería ya aceptar el uso de funciones irregulares y discontinuas (en el sentido de Euler) en esta clase de problemas.
El 2 de octubre de 1759, Euler escribió a Lagrange: «Estoy encantado de saber que está usted de acuerdo con mi solución... que D’Alembert ha intentado socavar con diversos reparos por la sola razón de que no la obtuvo él mismo. Ha amenazado con publicar una refutación de peso; no sé si realmente lo hará; él piensa que podrá engañar a los semicultos con su elocuencia. Dudo que sea serio, a no ser que esté, quizá, completamente cegado por la egolatría.»[163]
En 1760-61, Lagrange, intentando responder a las críticas que D’Alembert y Bernoulli habían comunicado por carta, dio una solución diferente al problema de la cuerda vibrante[164]. Esta vez, Lagrange arranca directamente de la ecuación de ondas (con c = 1) y, multiplicando por una función incógnita junto con otros pasos adicionales, reduce la ecuación en derivadas parciales a la resolución de dos ecuaciones diferenciales ordinarias. Mediante nuevos pasos, no todos correctos, Lagrange obtiene la solución
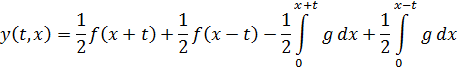
El debate continuó con pleno vigor durante todos los años sesenta y setenta del siglo. Incluso Laplace entró en la refriega en 1779[165], poniéndose al lado de D’Alembert; éste prosiguió en una serie de folletos, titulados Opuscules, que comenzaron a aparecer en 1768. Polemizó contra Euler porque éste admitía curvas iniciales demasiado generales y contra Bernoulli porque su solución (la de D’Alembert) no se podía representar como suma de curvas seno, con lo que las soluciones de Bernoulli no eran suficientemente generales. La idea de que una serie de funciones trigonométricas

Muchos de los argumentos presentados por cada uno de ellos eran muy incorrectos y los resultados obtenidos en el siglo XVIII no fueron definitivos. Una de las principales cuestiones, la representabilidad de una función arbitraria mediante una serie trigonométrica, no se aclaró hasta que Fourier se ocupó de ella. Euler, D’Alembert y Lagrange estuvieron a punto de descubrir la importancia de las series de Fourier, pero no llegaron a apreciar lo que tenían delante. Tanto ellos tres como Bernoulli tenían razón, juzgando por los concomimientos de la época, en sus principales aseveraciones. D’Alembert, siguiendo una tradición establecida desde los tiempos de Leibniz, insistía en que todas las funciones habían de ser analíticas, de tal manera que un problema que no se pudiera resolver en tales términos era irresoluble. Tuvo razón en el argumento de que y(t, x) ha de ser periódica en x, pero no vio que, dada una función arbitraria en, por ejemplo, 0 ≤ x ≤ l, dicha función se puede repetir en cada intervalo [nl,(n + 1)l], con n entero, y resultar así periódica. Por supuesto, puede que tal función periódica no sea representable mediante una fórmula cerrada. Euler y Lagrange tenían razones, al menos en su tiempo, para creer que no toda función «discontinua» se puede representar por una serie de Fourier, y también tenían razón al creer (aunque no disponían de una demostración) que la curva inicial podía ser muy general; no necesita ser analítica ni tampoco ser periódica. Bernoulli fue quien mantuvo la postura correcta con argumentos físicos, pero no la pudo justificar matemáticamente.
Uno de los aspectos ciertamente curiosos del debate sobre la representación de funciones mediante series trigonométricas es que todos los implicados sabían que se puede representar (en un intervalo) funciones no periódicas por tales series. Una consulta al capítulo 20 (sec. 5) mostrará que Clairaut, Euler, Daniel Bernoulli y otros habían obtenido de hecho tales representaciones; muchos de sus artículos traían también las fórmulas para los coeficientes de las series trigonométricas. Estos trabajos estaban impresos prácticamente todos en 1759, el año en que Lagrange presentó su fundamental artículo sobre la cuerda vibrante. Podía éste, por tanto, haber inferido de dichos trabajos que toda función admite un desarrollo en serie trigonométrica y haber tomado de ellos las fórmulas para los coeficientes, pero no lo hizo. No fue hasta 1773, cuando el ardor de la controversia había pasado, cuando Daniel Bernoulli hizo observar que la suma de una serie trigonométrica puede representar distintas expresiones algebraicas en intervalos distintos. ¿Por qué todos estos resultados no ejercieron ninguna influencia sobre la controversia relativa a la cuerda vibrante? Se puede explicar de diversas maneras. Muchos de los resultados sobre la representación en serie trigonométrica de funciones bastante generales aparecieron en artículos sobre astronomía y pudo ocurrir que Daniel Bernoulli no los hubiese leído, no pudiendo así recurrir a ellos para defender su postura. Euler y D’Alembert, que tuvieron que conocer el trabajo de Clairaut de 1757 (cap. 20, sec. 5), no estaban probablemente inclinados a estudiarlo ya que refutaba sus propios argumentos y, además, ese trabajo astronómico de Clairaut fue pronto superado y olvidado. Por otra parte, aunque Euler utilizó series trigonométricas, como en su trabajo sobre teoría de la interpolación, para representar expresiones polinomiales, no aceptó el resultado general de que funciones muy generales se pudiesen representar así; la existencia de tales representaciones en serie, cuando las utilizaba, se aseguraba por otros medios.
Otra cuestión, la de cómo una ecuación en derivadas parciales con coeficientes analíticos (por ejemplo, constantes) podía tener una solución no analítica, no llegó realmente a clarificarse. En el caso de ecuaciones diferenciales ordinarias, si los coeficientes son analíticos, las soluciones también lo han de ser, pero esto no es cierto para ecuaciones en derivadas parciales. Aunque Euler tenía razón al afirmar que son admisibles soluciones angulosas (e insistió en ello), la determinación de las singularidades que son admisibles en la solución de una ecuación en derivadas parciales estaba todavía lejos.
3. Extensiones de la ecuación de ondas
Mientras continuaba la controversia sobre la cuerda vibrante, el interés en los instrumentos musicales propició nuevos trabajos no sólo sobre las vibraciones de estructuras físicas, sino también sobre cuestiones hidrodinámicas concernientes a la propagación del sonido en el aire. Ello implica, en lo matemático, extensiones de la ecuación de ondas.
En 1762, Euler abordó el problema de la cuerda vibrante con grosor variable. Había sido estimulado a ello por una de las principales cuestiones de la estética musical: Jean-Philippe Rameau (1683-1764) había explicado en 1726 que la consonancia de un sonido musical es debida al hecho de que los tonos que componen cualquier sonido son armónicos del tono fundamental, es decir, que sus frecuencias son múltiplos enteros de la frecuencia fundamental. Pero Euler, en su Tentamen Novae Theoriae Musicae (1739)[166], mantenía que únicamente en instrumentos musicales apropiados los tonos superiores eran armónicos del tono fundamental. Se propuso por ello demostrar que la cuerda de espesor variable o de densidad σ(x) y tensión T no uniformes emite tonos superiores no armónicos.
La ecuación diferencial resultante es
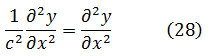

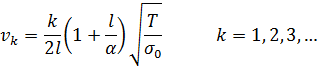
En este artículo de 1762-63. Euler consideró también las vibraciones de una cuerda compuesta de dos trozos de longitudes a y b y grosores diferentes m y n. Dedujo la ecuación para las frecuencias o) de los modos, a saber,
![]()
Pero Euler abordó de nuevo esta cuestión en otro artículo sobre la cuerda vibrante de espesor variable[168], y partiendo de (28) demuestra que existen funciones c(x) para las que las frecuencias de los modos superiores no son múltiplos enteros de la fundamental.
También D’Alembert estudió la cuerda de espesor variable[169], utilizando un importante método de resolución que había introducido anteriormente para la cuerda de densidad constante. Se basa en la idea de separación de variables y hoy constituye un método fundamental para resolver ecuaciones en derivadas parciales[170]. Para resolver
![]()
y = h(t) g(x)
sustituye esto en la ecuación diferencial y obtiene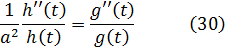

.![]()
En su artículo de 1763, D’Alembert escribió la ecuación de ondas en la forma
![]()
![]()
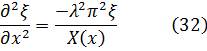
Otro de los problemas abordados por Euler fue el de las oscilaciones transversales de una cuerda horizontal continua pesada. En el artículo «Sobre el efecto modificador de su propio peso sobre el movimiento de las cuerdas» [171], Euler obtiene la ecuación diferencial

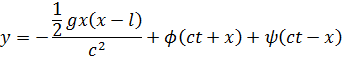
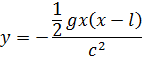
Se publicaron hasta finales de siglo muchos otros artículos, de los que los anteriores son sólo una muestra, sobre la cuerda vibrante y la cadena colgante. Los autores continuaron sin estar de acuerdo, corrigiéndose unos a otros y cometiendo toda clase de errores al hacerlo, incluyendo contradicciones con lo que ellos mismos habían dicho e incluso probado. Formularon afirmaciones, argumentos y refutaciones sobre la base de razonamientos poco rigurosos y, a menudo de, simplemente, predilecciones y convicciones personales. Sus referencias a artículos para probar sus argumentos no demostraban lo que afirmaban y también recurrían al sarcasmo, la ironía, la invectiva y el autobombo. Mezclados con estos ataques estaban los acuerdos aparentes para buscar favores, particularmente con D’Alembert, que tenía una considerable influencia con Federico II de Prusia y como director de la Academia de Ciencias de Berlín.
Los problemas de ecuaciones en derivadas parciales de segundo orden descritos hasta aquí hacían intervenir una sola variable espacial además del tiempo. En el siglo XVIII no se fue mucho más allá de esto. En un artículo de 1759[172], Euler abordó las vibraciones de una membrana rectangular, considerando así un medio bidimensional, y obtuvo para los desplazamientos verticales z de la misma la ecuación
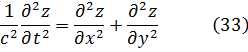
z = v(x, y) sen (ωt + α),
obteniendo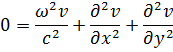
![]()
![]()
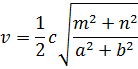
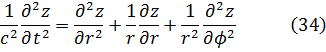
z = u(r) sen (ωt + A) sen (βϕ + B) (35)
obteniendo que u(r) ha de satisfacer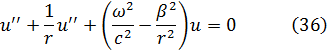
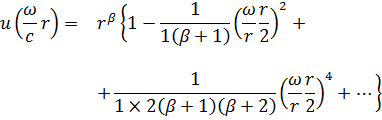
![]()
![]()
Euler, Lagrange y otros trabajaron sobre la propagación del sonido en el aire. Euler escribió frecuentemente sobre el tema del sonido desde sus veinte años (1727), estableciendo este campo como una rama de la física matemática. Su mejor trabajo en la materia siguió a sus principales artículos sobre hidrodinámica de los años cincuenta del siglo. El aire es un fluido compresible y la teoría de la propagación del sonido es parte de la mecánica de fluidos (y de la elasticidad, pues el aire es también un medio elástico). No obstante, Euler hizo, para tratar la propagación del sonido, simplificaciones razonables de las ecuaciones generales de la hidrodinámica.
En 1759, se leyeron en la Academia de Berlín tres artículos excelentes y definitivos. En el primero, «Sobre la propagación del sonido»[174], Euler considera la propagación del sonido en una dimensión espacial. Después de algunas aproximaciones, que vienen a significar el considerar ondas de pequeña amplitud, llega a la ecuación de ondas unidimensional
![]()
En su segundo artículo[175], Euler da la ecuación bidimensional de propagación en la forma
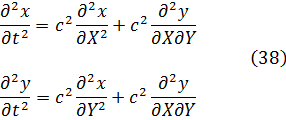
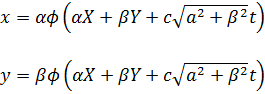
![]()
![]()
Euler muestra a continuación cómo conseguir la ecuación diferencial cuyas soluciones se denominan ondas cilíndricas, por propagarse como cilindros que se expanden. Pone
![]()
![]()
![]()
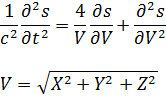
De la propagación de ondas de sonido en el aire sólo había un paso al estudio de los sonidos emitidos por instrumentos musicales que utilizan el movimiento del aire. Este estudio fue iniciado por Daniel Bernoulli en 1739. Bernoulli, Euler y Lagrange escribieron numerosos artículos sobre los tonos emitidos por una variedad casi increíble de tales instrumentos. En una publicación de 1762, Daniel Bernoulli demostró que no puede darse condensación de aire en el extremo abierto de un tubo cilíndrico (un tubo de órgano)[176]. En un extremo cerrado, las partículas de aire han de estar en reposo. Dedujo de ello que un tubo cerrado o abierto en ambos extremos tiene el mismo modo fundamental que un tubo la mitad de largo, pero abierto en un extremo y cerrado en el otro. Descubrió también el teorema de que para tubos de órgano cerrados las frecuencias de los armónicos son múltiplos impares de la frecuencia de tono fundamental. En el mismo artículo, Bernoulli consideró tubos de forma distinta a la cilíndrica, en particular el tubo cónico, para el que obtuvo expresiones para los tonos (modos) individuales pero reconoció que sólo eran válidas para conos infinitos y no para el cono truncado. Para el tubo cónico (infinito), los tonos superiores resultaron ser armónicos del fundamental. Bernoulli confirmó muchos de sus resultados teóricos mediante experimentos.
También estudió Euler tubos cilíndricos y figuras no cilíndricas de revolución[177] y consideró la reflexión en extremos cerrados y abiertos. Los esfuerzos de estos pensadores estaban dirigidos a comprender las flautas, tubos de órgano, toda clase de trompas con forma de cilindro, de cono y de hiperboloide, trompetas, cornetas y otros instrumentos de viento.
En su conjunto, estos esfuerzos para resolver ecuaciones en derivadas parciales en tres y cuatro variables fueron limitados, principalmente porque las soluciones se expresaban mediante series en que aparecían varias variables, en contraste con la mayor simplicidad de las series trigonométricas en x y t separadamente (cfr. [20]). Pero los matemáticos sabían poco de las funciones que aparecían en esas series más complicadas y de los métodos para determinar los coeficientes, métodos que pronto se desarrollarían.
Merece la pena mencionar que Euler, al considerar el sonido de una campana y al reconsiderar algunos de los problemas de la vibración de barras, hubo de plantearse ecuaciones en derivadas parciales de cuarto orden. Sin embargo, no fue capaz de hacer mucho con ellas y, de hecho, su estudio no avanzó en lo que quedaba de siglo.
4. Teoría del potencial
El desarrollo de las ecuaciones en derivadas parciales fue impulsado además por otra clase de investigaciones físicas. Uno de los principales problemas del siglo XVIII era la determinación de la magnitud de la atracción gravitatoria que una masa ejerce sobre otra, siendo los principales casos el de la atracción del Sol sobre un planeta, la de la Tierra sobre una partícula exterior o interior a ella y la de la Tierra sobre otra masa extensa. Cuando dos masas están muy alejadas en comparación con sus tamaños, cabe tratarlas como masas puntuales; pero en otros casos, señaladamente el de la Tierra atrayendo una partícula, hay que tener en cuenta el tamaño de la Tierra. Claramente, hay que conocer la forma de la Tierra para calcular la atracción gravitatoria que su masa distribuida ejerce sobre una partícula o sobre otra masa distribuida. Aunque la forma precisa continuó siendo un tema de investigación (cap. 21, sec. 1), era claro en 1700 que debería ser algún tipo de elipsoide, quizá un esferoide achatado (un elipsoide engendrado al girar una elipse alrededor del eje menor). Para un esferoide achatado sólido, la fuerza de atracción, lo mismo sobre una partícula externa que sobre una interna, no se puede calcular como si la masa estuviese concentrada en el centro.
En un artículo premiado de 1740 sobre las mareas, y en su Treatise of Fluxions (1742), Maclaurin demostró que, para un fluido de densidad uniforme y bajo rotación angular constante, el esferoide achatado es una figura de equilibrio. A continuación, Maclaurin demostró sintéticamente que dados dos elipsoides homogéneos de revolución homofocales, las atracciones que ambos cuerpos ejercen sobre una misma partícula exterior a ambos, supuesto que la partícula esté en la prolongación del eje de revolución o en el plano del ecuador, serán proporcionales a los volúmenes. En el siglo XIX, James Ivory (1765-1842) y Michel Chasles también establecieron geométricamente algunos otros resultados particulares.
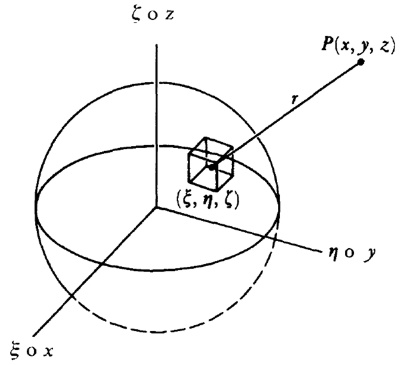
Figura 22.2
Señalemos en primer lugar algunos hechos relativos a la formulación analítica. La fuerza de gravitación ejercida por un cuerpo extenso sobre una unidad de masa P considerada como una partícula es la suma de las fuerzas ejercidas por todas las pequeñas masas que constituyen el cuerpo. Si dξ,dη, dζ representa un pequeño volumen del cuerpo (fig. 22.2), tan pequeño como para poder considerarlo localizado en el punto (ξ, η, ζ), y si P tiene por coordenadas (x, y, z), la atracción ejercida por la pequeña masa de densidad g sobre la partícula unidad es un vector dirigido de P a la pequeña masa que, por la ley de gravitación de Newton, tiene por componentes (cap. 21, sec. 7)
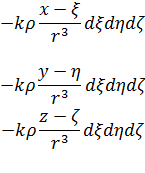
![]()
La fuerza que ejerce todo el cuerpo sobre la masa unidad situada en P tiene por componentes:
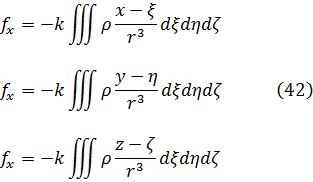
En lugar de tratar separadamente cada componente de la fuerza, es posible introducir una función V(x, y, z) cuyas derivadas parciales respecto a x, y y z sean respectivamente las tres componentes de la fuerza. Esta función es
![]()
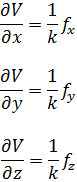
Si se conoce la distribución de la masa en el interior del cuerpo, lo que significa conocer g como función de ξ, η y ζ, y si se conoce la forma exacta del cuerpo, se puede en ocasiones obtener V mediante el cálculo efectivo de la integral. Sin embargo, esa integral triple no es expresable en términos de funciones simples para la mayor parte de formas de cuerpos y además no se conoce la distribución real de la masa en el interior de la Tierra y de otros cuerpos. En consecuencia, V se ha de calcular por otros métodos. El hecho principal relativo a V es que para puntos (x, y, z) exteriores al cuerpo atractor dicha función satisface la ecuación en derivadas parciales
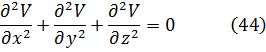
La idea de que una fuerza puede derivar de una función potencial, e incluso el término de «función potencial», fueron utilizados por Daniel Bernoulli en su Hydrodynamica (1738). La propia ecuación del potencial aparece por primera vez en uno de los principales artículos de Euler, elaborado en 1752, «Principios del movimiento de fluidos»[178]. Al estudiar las componentes u, v y w de la velocidad de un punto del fluido, Euler había probado que udx + vdy + wdz tenía que ser una diferencial exacta. Introduce la función S tal que dS = u dx + v dy + w dz y entonces
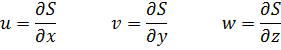
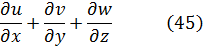
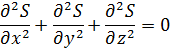
Antes de que podamos examinar los trabajos realizados para resolver la ecuación del potencial y aplicarla a la atracción gravitatoria, debemos pasar revista a algunos esfuerzos para evaluar esa atracción directamente por medio de las integrales (42) o sus equivalentes en otros sistemas coordenados.
En un artículo escrito en 1782 aunque publicado en 1785 y titulado «Recherches sur l’attraction des sphéroides»[180], Legendre, interesado en la atracción ejercida por sólidos de revolución, demostró el siguiente teorema: si se conoce la atracción de un sólido de revolución sobre todo punto exterior situado en la prolongación de su eje, entonces se conoce para todo punto exterior. Primero, expresó la componente de la fuerza de atracción en la dirección del radio vector r por medio de
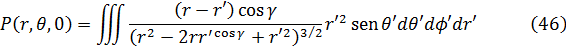
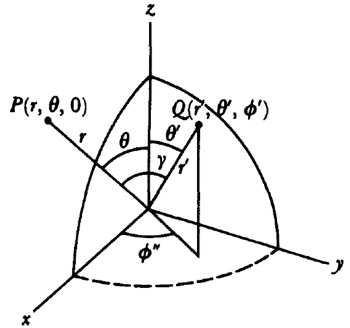
Figura 22.3
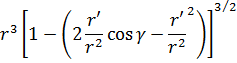
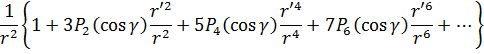
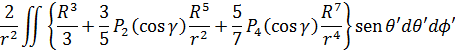
cos γ = cos θ cos θ' + sen θ sen θ' cos ϕ'.
Después de establecer el resultado auxiliar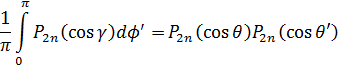
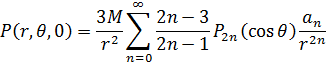
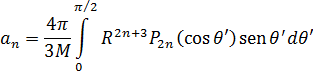
Del resultado anterior, y gracias a una comunicación recibida de Laplace, Legendre obtuvo la expresión de la función potencial, y de ésta dedujo la componente de la fuerza de atracción perpendicular al radio vector.
En un segundo artículo escrito en 1784[182], Legendre dedujo algunas propiedades de las funciones P2n. Así,
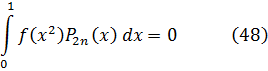

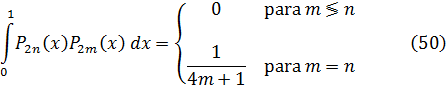
Después, con ayuda de la condición de ortogonalidad (50), demuestra (por integración de la serie término a término) que una función dada de x2 se puede expresar de modo único mediante una serie de funciones P2n(x).
Finalmente, utilizando éstas y otras propiedades de sus polinomios, Legendre vuelve al problema principal de la atracción gravitatoria y utilizando la expresión (43) para el potencial y la condición de equilibrio de una masa de fluido que gira, obtiene la ecuación de la curva meridiana de tal masa en la forma de una serie de sus polinomios. Legendre creyó que esa ecuación incluía todas las posibles figuras de equilibrio para un esferoide de revolución.
Entra entonces en esta historia Laplace, quien había escrito varios artículos sobre la fuerza de atracción ejercida por volúmenes de revolución (1772, pub. 1776; 1773, pub. 1776, y 1775, pub. 1778), en los cuales había trabajado con las componentes de la fuerza pero no con la función potencial. El artículo de Legendre de 1782, publicado en 1785, inspiró un célebre y destacado cuarto artículo de Laplace, «Théorie des attractions des sphéroides et de la figure des planétes»[183]. Sin mencionar a Legendre, Laplace abordó el problema de la atracción ejercida por un esferoide arbitrario en contraste con las figuras de revolución de Legendre. Por esferoide, Laplace entendía cualquier superficie dada por una ecuación en r, θ y ϕ.
Comienza con el teorema que establece que el potencial V de la fuerza que un cuerpo arbitrario ejerce sobre un punto exterior, expresado en coordenadas esféricas r, θ, ϕ con μ = cos θ, satisface la ecuación del potencial
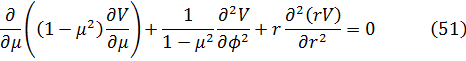
En el artículo de 1782 Laplace pone
![]()
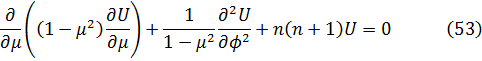

r = a(1 + αy) (55)
donde α es pequeño e y es una función de θ' y ϕ' sobre el esferoide. Laplace supone que y (θ, ϕ) se puede desarrollar en serie de funcionesy = Y0+ Y1 + Y2 + … (56)
donde las Yn son funciones de θ y ϕ y satisfacen la ecuación diferencial (53). Obtiene en primer lugar el resultado de que![]()
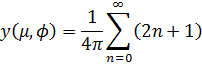

Laplace no considera aquí el problema general del desarrollo de cualquier función de θ y ϕ en serie de las Yn. Supone, aquí como en artículos posteriores, que tal desarrollo es posible y que es único. Maneja funciones racionales enteras de
![]()
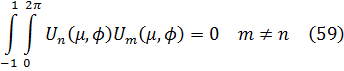
Laplace escribió varios artículos más sobre la atracción de esferoides y sobre la forma de la Tierra (por ejemplo, 1783, pub. 1786; 1787, pub. 1789) y en esos artículos utiliza desarrollos en funciones esféricas. En el último artículo, en el que Laplace dio la ecuación del potencial en coordenadas rectangulares, cometió un error de importancia al suponer que dicha ecuación es válida cuando la masa puntual atraída por el cuerpo está en el interior de éste. Este error fue corregido por Poisson (cap. 28, sec. 4).
Legendre continuó sus investigaciones durante los años ochenta del siglo. Su cuarto artículo, escrito en 1790[186], introdujo los Pn(x) para n impar. (La expresión [47] para los Pn(x) es válida para todo n.) Legendre demuestra que para todo par de enteros positivos m y n se tiene
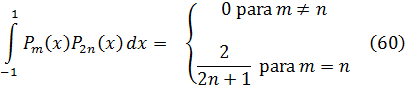
t= cos θ cos θ' + sen θ sen θ' cos (ϕ ϕ')
y, entonces, poniendo μ = cos θ, μ' = cos θ' y ψ = ϕ ϕ', demuestra que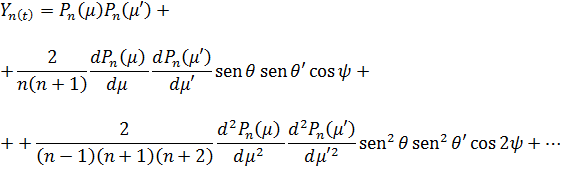
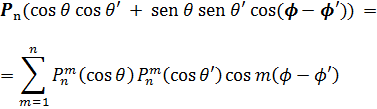
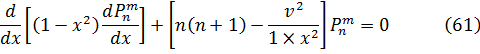
![]()

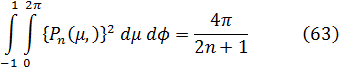
Este, Laplace y otros obtuvieron muchos más resultados especiales relativos a los polinomios de Legendre y a los armónicos esféricos. Un resultado fundamental es la fórmula de Olinde Rodrigues (1794-1851), dada en 1816[187]
![]()
Estas series de funciones son análogas a las series trigonométricas de las que Bernoulli afirmaba que se podían utilizar para representar funciones arbitrarias. La elección de la clase de funciones depende de la ecuación diferencial a resolver y de las condiciones iniciales y de contorno. Por supuesto, quedaba mucho por hacer con estas funciones para que fuesen más útiles en la resolución de ecuaciones en derivadas parciales.
5. Ecuaciones en derivadas parciales de primer orden
Hasta la época de Lagrange se había llevado a cabo muy poco trabajo sistemático sobre las ecuaciones en derivadas parciales de primer orden. La atención se había centrado en las ecuaciones de segundo orden a causa de los problemas físicos que conducen directamente a ellas. Habían sido resueltas algunas ecuaciones de primer orden especiales, pero porque se integraban inmediatamente o mediante algún artificio ingenioso. Había una excepción, la que hoy se conoce habitualmente como ecuación en diferenciales totales y que tiene la forma
![]()
![]()
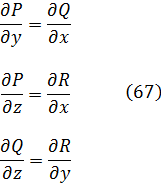
Clairaut demostró también que si (65) no es exacta, entonces cabe que sea posible encontrar un factor integrante, es decir, una función μ(x, y, z) tal que al multiplicar por ella la ecuación el nuevo primer miembro resulte una diferencial exacta. Clairaut[189] y más tarde D’Alembert (Traité de Véquilibre et du, mouvement desfluides, 1744) dieron una condición necesaria para que la ecuación sea integrable (con la ayuda de un factor integrante). Esta condición (que también es suficiente) es
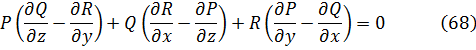
![]()
Para comprender el trabajo de Lagrange, hay que dar cuenta, antes que nada, de su terminología, la cual todavía está en uso. Lagrange clasificaba las soluciones de las ecuaciones de primer orden no lineales como sigue. Una solución V (x, y, z, a, b) = 0 que contenga dos constantes arbitrarias es la solución completa o integral completa de la ecuación. Haciendo b = ϕ(a), con ϕ función arbitraria, se obtiene una familia uniparamétrica de soluciones. Con ϕ(a) arbitraria, la envolvente de esa familia es la integral general de la ecuación; si se considera una ϕ(a) concreta, la envolvente es un caso particular de la integral general. La envolvente de todas las soluciones incluidas en la integral completa se llama integral singular de la ecuación. Veremos después lo que significan geométricamente estas soluciones. La integral completa no es única en el sentido de que puede haber muchas diferentes que no se obtienen una de la otra mediante un simple cambio en las constantes arbitrarias; pero de cualquiera de ellas se pueden obtener todas las soluciones dadas por otra por medio de los casos particulares y la integral singular.
Entre dos importantes artículos de 1772 y 1779, que examinaremos en seguida, Lagrange escribió un artículo en 1774 en el que discutía las relaciones entre las soluciones singular, general y completa de una ecuación en derivadas parciales de primer orden. La integral general se obtiene eliminando a entre V (x, y, z, a, ϕ(a)) = 0 y ∂V/∂a = 0, donde ϕ(a) es arbitraria[190]. (Para una ϕ(a) particular se obtiene una solución particular.) La solución singular se obtiene eliminando a y b entre V(x, y, z, a, b) = 0, ∂V/∂a = 0 y ∂V/∂b = 0.
Lagrange desarrolló primero la teoría general de las ecuaciones de primer orden no lineales. En el artículo de 1772[191], considera una ecuación general de primer orden en dos variables independientes x e y, con z como variable dependiente, mejorando y generalizando lo que antes había hecho Euler. Considera la ecuación (69) dada en la forma
qQ(x, y, z, p) = 0 (70)
es decir, con q como función de x, y, z, p, y trata de determinar p como función de x, y, z de modo que las dos ecuaciones![]()
dz pdx qdy (72)
se convierta, multiplicándola por un factor M (x, y, z) apropiado, en una diferencial exacta dN de N(x, y, z). Para ello necesita que se tenga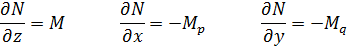
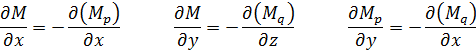
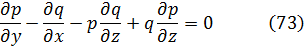

![]()
Lagrange dio en 1779 su método para resolver las ecuaciones en derivadas parciales de primer orden lineales[192]. Considera la que todavía se denomina ecuación lineal de Lagrange
Pp + Qq = R (76)
donde P, Q y R son funciones de x, y, z; la ecuación se dice que es no homogénea debido a la presencia del término R. Esta ecuación está íntimamente ligada a la ecuación homogénea en tres variables
![]()
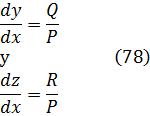
Si se pone este trabajo sobre ecuaciones lineales en relación con el trabajo de 1772 sobre ecuaciones no lineales, se ve que Lagrange había logrado reducir una ecuación de primer orden arbitraria en x, y y z a un sistema de ecuaciones diferenciales ordinarias simultáneas; no establece el resultado explícitamente, pero se deduce de dicho trabajo. Curiosamente, en 1785 tenía que resolver una ecuación particular de primer orden y afirmó que era imposible hacerlo con los métodos existentes; había olvidado su trabajo de 1772.
A continuación, Paul Charpit (m. 1784) combinó, presumiblemente en 1784, los métodos para ecuaciones no lineales y para ecuaciones lineales a fin de reducir cualquier f(x, y, z, p, q) = 0 a un sistema de ecuaciones diferenciales ordinarias. Lacroix afirmó en 1798 que Charpit había presentado en 1784 un artículo (que no fue publicado) en el que reducía las ecuaciones en derivadas parciales de primer orden a sistemas de ecuaciones diferenciales ordinarias. Jacobi encontró sorprendente esa afirmación y expresó su deseo de que el trabajo de Charpit fuese publicado, pero esto nunca se hizo y no sabemos si la afirmación de Lacroix era correcta. Incluso Lagrange pudo haber hecho todo el trabajo y Charpit no haber añadido nada. El método que se expone en los textos modernos, llamado método de Lagrange, de Lagrange-Charpit o de Charpit, consiste en la fusión de las ideas de Lagrange presentadas en los artículos de 1772 y de 1779. Establece que para resolver la ecuación general en derivadas parciales de primer orden f(x, y, z, p, q) = 0 hay que resolver el sistema de ecuaciones diferenciales ordinarias (las ecuaciones características de f = 0),
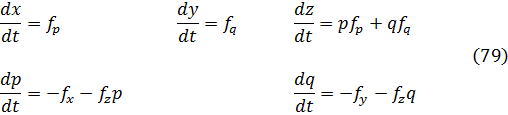
El método de Lagrange se denomina a menudo método de las características de Cauchy debido a que la generalización a n variables del método por el que se llega a (79) empleado por Lagrange y Charpit para una ecuación en dos variables independientes presenta algunas dificultades que fueron superadas por Cauchy en 1819[194].
6. Monge y la teoría de las características
Gaspar Monge (1746-1815) introdujo el lenguaje de la geometría allí donde Lagrange había trabajado de un modo puramente analítico. Su trabajo en ecuaciones en derivadas parciales no fue tan importante como el de Euler, Lagrange o Legendre, pero inició el movimiento para interpretar geométricamente los trabajos analíticos, introduciendo de ese modo muchas ideas fructíferas. Vio que, así como problemas que involucran curvas conducen a ecuaciones diferenciales ordinarias, así problemas que involucran superficies conducen a ecuaciones en derivadas parciales. De manera más general, geometría y análisis eran para Monge una sola materia, mientras que para los demás matemáticos del siglo eran dos ramas distintas con sólo algunos puntos de contacto. Monge comenzó su trabajo en 1770, pero no publicó hasta mucho más tarde.
Fue primeramente en el campo de las ecuaciones en derivadas parciales de primer orden donde Monge no sólo introdujo la interpretación geométrica sino que puso énfasis en un nuevo concepto, el de curvas características 45. Sus ideas sobre las características y sobre las integrales en tanto que envolventes no fueron comprendidas por sus contemporáneos, que las tacharon de principio metafísico; la teoría de características, sin embargo, habría de convertirse en una materia importante en trabajos ulteriores. Monge desarrolló sus ideas más completamente en sus lecciones y en subsiguientes publicaciones, especialmente en las Feuilles d'analyse appliquée á la géometrie (1795). La mejor manera de ilustrar sus ideas es con su propio ejemplo.
Consideremos la familia biparamétrica de esferas con radio constante R y centro en cualquier punto del plano XY. La ecuación de esta familia es
(xa)2 + (yb)2 + z2 = R2 (80)
Esta ecuación es la integral completa de la ecuación en derivadas parciales de primer orden no linealz2(p2 + q2 + 1) =R2 (81)
ya que (80) contiene dos constantes arbitrarias, a y b, y satisface claramente (81). La subfamilia de esferas introducida al hacer b = ϕ(a)es una familia de esferas con centro en una curva, la curva y = ϕ(x)del plano XY. La envolvente de esta familia uniparamétrica de esferas (una superficie tubular) es también una solución de (81). Esta solución particular se obtiene eliminando a entre(xa)2 + (yϕ(a))2 +z2= R2 (82)
y la derivada parcial de (82) con respecto a a, a saber,(xa) + (y (ϕ(a)) ϕ'(a) = 0 (83)
Para cada elección particular de a, las ecuaciones (82) y (83) representan cada una de ellas, una superficie particular, y por tanto ambas, consideradas simultáneamente, representan una curva llamada curva característica. Esta curva es también la intersección de dos esferas «consecutivas» de la subfamilia y el conjunto de curvas características genera o cubre la envolvente, es decir, la envolvente toca a cada miembro de la su familia a lo largo de la característica. La integral general es el agregado de superficies (envolventes de familias uniparamétricas), cada una de las cuales está generada por un conjunto de curvas características. La envolvente de todas las soluciones de (80), o sea, la solución singular, obtenida por eliminación de a y b entre y las derivadas parciales de (80) con respecto a a y b, es z =± R.Las curvas características aparecen también por otro camino. Consideremos dos subfamilias de esferas cuyas envolventes son tangentes a lo largo de una esfera cualquiera; podemos denominar envolventes consecutivas a tales envolventes. La curva de intersección de esas dos envolventes consecutivas es la misma curva característica sobre la esfera que la obtenida considerando miembros consecutivos de cualquiera de las dos subfamilias. Cualquier esfera puede pertenecer a una infinidad de diferentes subfamilias cuyas envolventes son todas distintas, con lo que habrá distintas curvas características sobre la misma esfera. Todas son circunferencias de círculos máximos situados en planos verticales.
Monge dio la forma analítica de las ecuaciones diferenciales de las curvas características, lo que equivale al hecho de que las ecuaciones (79) determinan las curvas características de (69). (Monge utilizó ecuaciones en diferenciales totales para expresar las ecuaciones de las curvas características.)
Monge introdujo también (en 1784) la noción de cono característico. En cualquier punto (x, y, z) del espacio (fig. 22.4), se puede considerar el plano cuya normal tiene la dirección del vector (p, q,...
Faltan las págs.713 y 714
...sus lecciones de 1806, por una curva característica se puede hacer pasar infinitas superficies integrales que son tangentes una a otra sobre dicha curva.
7. Monge y las ecuaciones de segundo orden no lineales
Además de las ecuaciones de segundo orden lineales que ya hemos examinado, los matemáticos del siglo XVIII tuvieron ocasión de considerar ecuaciones de segundo orden lineales en dos variables independientes más generales e incluso ecuaciones no lineales. Estudiaron, así, la ecuación lineal
Ar + Bs + Ct + Dp + Eq + Fz+ G = 0 (85)
donde las letras r, s, t, p y q tienen el significado obvio. Laplace demostró en 1773[195] 47 que al ecuación (85) se puede reducir, mediante un cambio de variables, a la formas + ap + bq + cz + g = 0 (86)
donde a, b, c y g son funciones únicamente de x e y, supuesto que B2 4AC ≠ 0. Resolvió después la ecuación en términos de una serie. En sus Feuilles d’analyse, Monge consideró la ecuación no linealRr + Ss + Tt = V (87)
en donde R, S, T y V son funciones de x, y, z, p y q, de modo que la ecuación es lineal sólo en las derivadas segundas r, s y t. Este tipo de ecuación aparece en el trabajo de Lagrange sobre superficies mínimas, esto es, superficies de área mínima limitadas por curvas dadas en el espacio, caso en el que la ecuación diferencial concreta es (1 + q2)r2pqs + (1 + p2)t = 0. (Ver también cap. 24, sec. 4). Aunque Monge ya había efectuado algún trabajo sobre la ecuación (87), en el presente artículo (1795) fue capaz de resolverla elegantemente por el método que vamos a esbozar.Partiendo de los resultados inmediatos
dzp dx + q dy (88)
dpr dx + s dy (89)
dq = s dx + t dy (90)
y eliminado r y t de (87), (89) y (90) obtuvo la ecuación
s(Rdy2Sdxdy + Tdx2) (Rdy dp + T dx dqV dx dy) = 0 (91)
Argumenta entonces que siempre que sea posible resolver simultáneamenteR dy2S dx dy + T dx2 = 0 (92)
yR dy dp + T dx dqV dx dy = 0 (93)
se satisfará (91) y lo mismo ocurrirá con (87)La ecuación (92) es equivalente a dos ecuaciones de primer orden:
dyW1(x, y, z, p, q) dx = 0
ydyW2(x, y, z, p, q) dx = 0. (94)
Las ecuaciones (88) y (93), junto con una de las de (94), constituyen un sistema de tres ecuaciones en diferenciales totales en las cinco variables x, y, z, p, q. Cuando se pueden resolver estas tres ecuaciones, es posible encontrar dos soluciones:u1(x, y, z, p, q ) = C1
yu2(x, y, z, p, q ) = C2
y entoncesu1 = ϕ (u2) (95)
con ϕ arbitraria, es una ecuación en derivadas parciales de primer orden. La ecuación (95) se denomina integral intermedia y su solución general es la solución de (87). Si se puede utilizar la otra ecuación de (94) junto con (88) y (93), se obtiene otra función:u3 = ϕ (u4) (96)
En este caso, (95) y (96) se pueden resolver simultáneamente en p y q y estos valores se sustituyen en (88), pudiéndose entonces resolver esta ecuación en diferenciales totales. Este es al menos el esquema general, aunque hay detalles en los que no entraremos. La integración por Monge de la ecuación de las superficies mínimas fue una de sus reivindicaciones de gloria.Monge introdujo también la teoría de características para la ecuación (87). La ecuación en diferenciales totales de las características es (92), es decir,
R dy2S dx dy + T dx2 = 0.
Esta ecuación, que aparece en su obra ya en 1784[196], define en cada punto de una superficie integral dos direcciones que son las direcciones características en ese punto. Por cada punto de una superficie integral pasan dos curvas características, a lo largo de cada una de las cuales se tocan dos superficies integrales consecutivas.8. Sistemas de ecuaciones en derivadas parciales de primer orden
Los sistemas de ecuaciones en derivadas parciales surgieron por primera vez en los trabajos del siglo XVIII sobre dinámica de fluidos o hidrodinámica. El interés por los fluidos incompresibles —agua, por ejemplo—, estaba motivado por problemas prácticos tales como el diseño de cascos de buques para reducir la resistencia al movimiento en el agua y el cálculo de las mareas, del flujo de los ríos, del flujo del agua en surtidores y de la presión del agua sobre los costados de un buque. Los trabajos sobre fluidos compresibles, el aire en particular, intentaban analizar la acción del aire sobre las velas de un navío, el diseño de las aspas de los molinos de viento y la propagación del sonido. Los trabajos que examinamos anteriormente sobre la propagación del sonido supusieron, desde el punto de vista histórico, una aplicación de los trabajos sobre hidrodinámica particularizados a ondas de pequeña amplitud.
Después de haber tratado en 1752 los fluidos incompresibles en un artículo titulado «Principios del movimiento de fluidos»[197], Euler generalizó este trabajo en un artículo de 1755 titulado «Principios generales del movimiento de fluidos»[198]. Formuló en él las todavía célebres ecuaciones del movimiento de un fluido perfecto (no viscoso), compresible e incompresible. El fluido se contempla como un continuo y las partículas como puntos matemáticos. Euler considera la fuerza que actúa sobre un pequeño volumen del fluido de densidad g, sujeto a una presión p, y una fuerza externa de componente P,Q y R por unidad de masa.
En uno de los enfoques de la dinámica de fluidos que Euler creó, conocido en la literatura como descripción espacial, las componentes u, v y w de la velocidad del fluido en cada punto de éste están dadas por
![]()
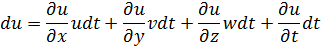
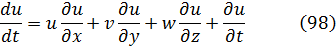
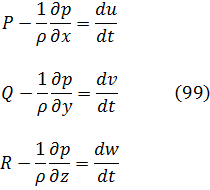
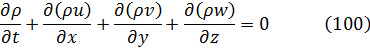
En el artículo de 1755, Euler afirma: «Y si no nos está permitido llegar a un completo conocimiento en lo que concierne al movimiento de los fluidos, no es a la mecánica o a la insuficiencia de los principios del movimiento conocidos a los que hemos de atribuir la causa. Es el análisis el que nos abandona aquí, pues toda la teoría del movimiento de fluidos ha sido reducida precisamente a la resolución de fórmulas analíticas.» Desgraciadamente, el análisis era todavía muy débil para hacer gran cosa con estas ecuaciones y Euler procedió a discutir algunas soluciones especiales. También escribió otros artículos sobre el tema y trató de la resistencia que encuentran los buques y de la propulsión de éstos. Las ecuaciones de Euler no son las ecuaciones definitivas de la hidrodinámica; no tienen en cuenta la viscosidad, que fue introducida setenta años más tarde por Navier y Stokes (cap. 28, sec. 7).
También Lagrange trabajó sobre el movimiento de fluidos. En la primera edición de su Mécanique analytique, que contiene parte del trabajo, dio las ecuaciones fundamentales de Euler y las generalizó. Atribuye en esa obra el mérito a D’Alembert y no da ninguno a Euler. Afirma también que las ecuaciones del movimiento de un fluido son demasiado difíciles para ser tratadas por el análisis y que sólo los casos de movimientos infinitamente pequeños son susceptibles de cálculos rigurosos.
Las ecuaciones de la hidrodinámica fueron, en el siglo XVIII, la principal inspiración para la investigación matemática en el campo de los sistemas de ecuaciones en derivadas parciales. En realidad, se avanzó poco en ese siglo en la resolución de sistemas.
9. El desarrollo de las ecuaciones en derivadas parciales como disciplina matemática
Hasta 1765, las ecuaciones en derivadas parciales aparecían únicamente en la resolución de problemas físicos. El primer artículo dedicado a un trabajo puramente matemático sobre tales ecuaciones se debe a Euler: «Recherches sur l’intégration de l’equation
Antes del trabajo de D’Alembert de 1747 sobre la cuerda vibrante, las ecuaciones en derivadas parciales eran conocidas como ecuaciones de estado y sólo se buscaban soluciones especiales. Después de ese trabajo y del libro de D’Alembert sobre las causas generales de los vientos (1746), los matemáticos comprendieron la diferencia entre soluciones especiales y la solución general. Sin embargo, una vez conscientes de esa distinción, creyeron, aparentemente, que debían ser más importantes las soluciones generales. En el primer volumen de su Mécanique céleste (1799), Laplace todavía se quejaba de que no se pudiese integrar de manera general la ecuación del potencial en coordenadas esféricas. No se llegó a valorar en este siglo que soluciones generales como las obtenidas por Euler y D’Alembert en el problema de la cuerda vibrante no eran tan útiles como las soluciones particulares que satisfacen determinadas condiciones iniciales y de contorno.
Sí se dieron cuenta los matemáticos de que las ecuaciones en derivadas parciales no implicaban nuevas técnicas operativas, pero que diferían de las ecuaciones diferenciales ordinarias en que pueden aparecer en su resolución funciones arbitrarias. Esperaban determinar éstas reduciendo las ecuaciones en derivadas parciales a ordinarias. Laplace (1773) y Lagrange (1784) afirmaban claramente que consideraban integrada una ecuación en derivadas parciales cuando quedaba reducida a un problema de ecuaciones diferenciales ordinarias. Una alternativa, como la utilizada por Daniel Bernoulli para la ecuación de ondas y Laplace para la ecuación del potencial, consistía en buscar desarrollos en serie de funciones especiales.
El principal logro de los trabajos del siglo XVIII sobre ecuaciones en derivadas parciales fue poner de manifiesto su importancia en los problemas de elasticidad, hidrodinámica y atracción gravitatoria. Excepto en el caso del trabajo de Lagrange sobre las ecuaciones de primer orden, no se desarrollaron métodos generales ni se supieron valorar las potencialidades del método de desarrollos en serie de funciones especiales. Los esfuerzos se dirigían a resolver ecuaciones especiales que aparecían en problemas físicos. Quedaba por elaborar la teoría de la resolución de ecuaciones en derivadas parciales, y la materia en su conjunto estaba todavía en su infancia.
Bibliografía
- Burkhardt, H.: «Entwicklungen nach oscillirenden Funktionen und Integration der Differentialgleichungen der mathematischen Physik», Jahres. der Deut. Math.-Verein.,10, 1908, 1-1804.
- Burkhardt, H. y W. Franz Meyer: «Potentialtheorie», Encyk. der Math. Wiss., B. G. Teubner, 1899-1916, 2, A7b, 464-503.
- Cantor, Moritz: Vorlesungen über Geschicbte der Mathematik, B. G. Teubner, 1898 y 1924; Johnson Reprint Corp., vol. 3, 858-878, vol. 4, 873-1047.
- Euler, Leonhard: Opera Omnia, Orell Füssli, (1), vols. 13 (1914) y 23 (1938); (2), vols. 10, 11, 12 y 13 (1947-55).
- Lagrange, Joseph-Louis: Œuvres, Gauthier-Villars, 1868-70, los artículos relevantes en vols. 1, 3, 4 y 5.
- Laplace, Pierre-Simon: Œuvres completes, Gauthier-Villars, 1893-94, los artículos relevantes en vols. 9 y 10.
- Montucla, J. F.: Histoire des mathématiques (1802), Albert Blanchard (reimpresión), 1960, vol. 3, págs. 342-352.
- Langer, Rudolph E.: «Fourier Series: The Génesis and Evolution of a Theory», Amer. Math. Monthly, 54, núm. 7, parte 2, 1947.
- Taton, René: L'Œuvre scientifique de Monge, Presses Universitaires de France, 1951.
- Todhunter, Isaac: A History of the Mathematical Theories of Attraction and the Figure of the Earth (1873), Dover (reimpresión), 1962.
- Truesdell, Clifford E.: Introduction to Leonhardi Euleri Opera Omnia, vol. X et XI Seriei Secundae, en Euler, Opera Omnia, (2), 11, parte 2, Orell Füssli, 1960. —: Editoras Introduction en Euler, Opera Omnia, (2), vol. 12, Orell Füssli, 1954.—: Editor’s Introduction en Euler, Opera Omnia, (2), vol. 13, Orell Füssli, 1956.
Capítulo 23
Geometría analítica y diferencial en el siglo XVIII
Aparentemente, en ocasiones, la geometría puede tomar ventaja sobre el análisis, pero de hecho lo precede únicamente como un sirviente cuando adelanta a su amo para limpiar el recorrido e iluminarlo en su camino.
James Joseph Sylvester
1. Introducción1. Introducción
2. Geometría analítica básica
3. Curvas planas de grado superior
4. Los orígenes de la geometría diferencial
5. Curvas planas
6. Curvas en el espacio
7. La teoría de superficies
8. El problema de los mapas
Bibliografía
La exploración de problemas físicos lleva inevitablemente a la búsqueda de un mejor conocimiento de las curvas y superficies, ya que las trayectorias de objetos en movimiento son curvas y los objetos en sí mismos son objetos de tres dimensiones limitados por superficies. Los matemáticos, ya de por sí entusiasmados por el método de la geometría de coordenadas y por la fuerza del cálculo, abordaron los problemas geométricos con estas dos poderosas herramientas. Los resultados impresionantes del siglo fueron obtenidos en el área ya establecida de la geometría de coordenadas y el nuevo campo creado por la aplicación del cálculo a los problemas geométricos, que se llamó geometría diferencial.
2. Geometría analítica básica
La geometría analítica de dos dimensiones fue explorada extensamente durante el siglo XVIII. Los avances en la geometría analítica plana elemental ya han sido resumidos. Mientras que Newton y Jacques Bernoulli habían introducido y empleado lo que son esencialmente las coordenadas polares para curvas especiales (cap. 15, sec. 5), en 1729, Jacob Hermann no solamente proclamó su utilidad general, sino que las aplicó libremente al estudio de las curvas, proporcionando a su vez la transformación de coordenadas polares a rectangulares. Estrictamente hablando, Hermann usó variables, q, cos θ, sen θ, que él designó por z, n y m. Euler extendió el uso de las coordenadas polares y utilizó explícitamente la notación trigonométrica; con él, prácticamente, el sistema es el moderno.
A pesar de que algunos autores del siglo VI, por ejemplo, Jan de Witt (1625-72) en su Elementa Curvarum Linearum (1659), redujeron algunas ecuaciones de segundo grado en x e y a formas canónicas, James Stirling, en su Lineae Tertii Ordinis Neutonianae (1717), redujo la ecuación general de segundo grado en x e y a las diversas formas canónicas.
En su Introductio (1748), Euler incorpora la representación paramétrica de las curvas, donde x e y son coordenadas, en términos de una tercera variable. En este famoso texto, Euler trató sistemáticamente la geometría plana con coordenadas.
Las sugerencias de una geometría de coordenadas de tres dimensiones pueden ser encontradas, como sabemos, en las obras de Fermat, Descartes y La Hire. El desarrollo efectivo fue trabajo del siglo XVIII. Aunque alguna parte de los trabajos iniciales, por ejemplo, el de Pilot y Clairaut, están ligados al desarrollo de la geometría diferencial, consideraremos por ahora únicamente la geometría de coordenadas.
La primera tarea consistió en mejorar la sugerencia de La Hire respecto a un sistema coordenado de tres dimensiones. Jean Bernoulli, en una carta a Leibniz de 1715, introduce los planos de tres coordenadas que utilizamos hoy en día. A través de aportaciones demasiado detalladas para incluirlas aquí, Antonie Parent (1666-1716), Jean Bernoulli, Clairaut y Jacob Hermann clarificaron la noción de que una superficie puede ser representada por una ecuación en tres coordenadas. Clairaut, en su libro Recherche sur les courbes a double courbure (Investigaciones sobre las curvas de doble curvatura, 1731) no sólo proporcionó las ecuaciones de algunas superficies, sino que mostró que dos de esas ecuaciones son necesarias para describir una curva en el espacio. También vio que ciertas combinaciones de las ecuaciones de dos superficies que pasan a través de una curva —por ejemplo, la suma—, proporcionan la ecuación de otra superficie que contiene la curva. Usando este hecho, explica cómo se pueden obtener las ecuaciones de las proyecciones de estas curvas, o, equivalentemente, las ecuaciones de los cilindros perpendiculares a los planos de proyección.
Las superficies cuadráticas, por ejemplo la esfera, el cilindro, la paraboloide, el hiperboloide de dos hojas y el elipsoide, por supuesto eran conocidas geométricamente antes de 1700; de hecho, algunas de ellas aparecen en las obras de Arquímedes. En su libro de 1731, Clairaut dio las ecuaciones de algunas de estas superficies. También mostró que una ecuación homogénea en x, y y z (donde todos los términos son del mismo grado) representa un cono con vértice en el origen. A este resultado, Jacob Hermann, en un ensayo de 1732[201], añadió que la ecuación x2 + y2 = f(z) es una superficie de revolución alrededor del eje z. Tanto Clairaut como Hermann estaban primordialmente interesados en la forma de la Tierra, que en su tiempo se pensaba tenía cierta conformación de elipsoide.
A pesar de que Euler había realizado un trabajo previo sobre las ecuaciones de superficies, es en el capítulo cinco de su apéndice al segundo volumen de su Introductio[202] donde aborda sistemáticamente la geometría plana tridimensional. Presenta mucho de lo que ya se había realizado hasta entonces y, posteriormente, estudia la ecuación general de segundo grado en tres variables
ax2 + by2 + cz2 + dxy + exz + fyz + gx + hy + kz = l 1
Ahora, Euler busca cambiar los ejes para reducir esta ecuación a las formas que resultan de tomar los ejes principales de las superficies cuadráticas representadas por (1) como ejes coordenados.Introduce la transformación del sistema xyz al sistema x'y'z', cuyas ecuaciones están expresadas (fig. 23.1) en términos de los ángulos ϕ, ψ y θ.
El ángulo ϕ es medido en el plano xy a partir del eje x a la línea de nodos, que es la línea en que el plano x'y' corta el plano xy. El ángulo ψ se mide en el plano x'y' y localiza a x' con respecto a las líneas de los nodos.
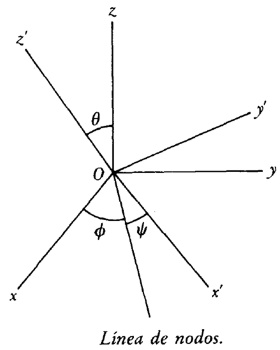
Figura 23.1.
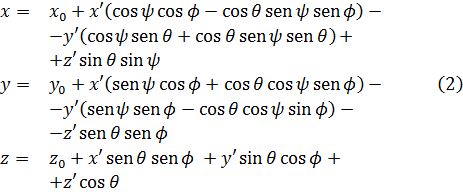
Después de continuar trabajando en este problema de cambio de ejes, escribió otro ensayo[203], en el cual considera la transformación que llevará de x2 + y2 + z2 a x'2 + y'2 + z'2.
Él aquí, y Lagrange un poco más tarde, en un ensayo sobre la atracción de los esferoides[204], proporcionó la forma simétrica para la rotación de ejes, la transformación lineal ortogonal homogénea

Los escritos de Gaspar Monge contienen una gran cantidad de geometría analítica tridimensional. Su contribución sobresaliente a la geometría analítica como tal se encuentra en un ensayo de 1802, escrito junto con su discípulo Jean Nicolás Pierre Hachette (1769-1834), «Application de l’algébre a la géométrie»[205] («Aplicación del álgebra a la geometría»). Los autores muestran que cada sección plana de una superficie de segundo grado es una curva de segundo grado, y que planos paralelos cortan en curvas similares análogamente situadas. Estos resultados son análogos a los teoremas geométricos de Arquímedes. Los autores también muestran que el hiperboloide de una hoja y el paraboloide hiperbólico son superficies regladas, esto es, cada una puede ser generada de dos maneras diferentes por el movimiento de una línea, o bien cada superficie está formada por dos sistemas de líneas. El resultado en el hiperboloide de una hoja era conocido en 1669 por Christopher Green, quien afirmaba que esta figura podía ser generada girando una línea alrededor de otra que no se encontrara en el mismo plano. Con el trabajo de Euler, Lagrange y Monge, la geometría analítica se convirtió en una rama de las matemáticas independiente y acabada.
3. Curvas planas de grado superior
La geometría analítica descrita hasta ahora fue dedicada a las curvas y superficies de primero y segundo grado. Por lo tanto, era natural investigar las curvas de ecuaciones de grados superiores. De hecho, Descartes había discutido con anterioridad tales ecuaciones y sus curvas. El estudio de curvas de grados mayores que dos llegó a ser conocido como la teoría de curvas planas de grado superior, a pesar de ser parte de la geometría analítica. Las curvas estudiadas en el siglo XVIII eran algebraicas; es decir, sus ecuaciones están dadas por f(x, y) = 0, donde/es un polinomio en x e y. El grado u orden es el grado máximo de los términos.
El primer estudio amplio de las curvas planas superiores lo realizó Newton. Impresionado por el plan de Descartes en cuanto a clasificar curvas de acuerdo al grado de sus ecuaciones y entonces estudiar sistemáticamente las de cada grado por métodos adaptados a ese grado, Newton emprendió el estudio de curvas de tercer grado. Este trabajo apareció en su Enumeratio Linearum Tertii Ordinis (Enumeración de líneas de tercer grado), que fue publicado en 1704 como un apéndice a la edición inglesa de su Opticks (Óptica), pero ya había sido compuesto en 1676. Aunque el uso de valores negativos de x e y aparece en el trabajo de La Hire y Wallis, Newton no emplea únicamente los dos ejes y valores negativos de x e y, sino que traza los cuatro cuadrantes.
Newton mostró cómo todas las curvas comprendidas por la ecuación general de tercer grado
ax3 + bx2y + cxy2 + dy3 + ex2 + fxy + gy2 + hx + jy + k = 0 (3)
pueden, con un cambio de ejes, ser reducidas a una de las cuatro formas siguientes:

Figura 23.2
Newton no proporcionó las pruebas de muchas sus afirmaciones en su Enumeratio. En su Lineae, James Stirling demostró o refutó de otras maneras la mayoría de las afirmaciones pero no el teorema de la proyección, que Clairaut[206] y François Nicole demostraron (1683-1758) [207]. También, mientras que Newton reconocía setenta y dos especies de curvas de tercer grado, Stirling añadió cuatro más y el abad Jean-Paul de Gua de Malves, en un pequeño libro de 1740 titulado Usage de l’analyse de Descartes pour decouvrir sans le secours du calcul differential... (Uso del análisis de Descartes para descubrir...), añadió dos más.
El trabajo de Newton sobre curvas de tercer grado estimuló mucho la labor de otros sobre curvas planas superiores. El tema de la clasificación de curvas de tercer y cuarto grado de acuerdo con uno u otro principio continuó interesando a matemáticos de los siglos XVIII y XIX. El número de clases encontradas variaba con los métodos de clasificación.
Como es evidente a partir de las figuras de las cinco especies de curvas cúbicas de Newton, las curvas de ecuaciones de grado superior exhiben muchas peculiaridades no encontradas en curvas de primero y segundo grado. Las peculiaridades elementales, llamadas puntos singulares, son puntos de inflexión y puntos múltiples. Antes de seguir, veamos cómo son algunos de éstos.
Los puntos de inflexión son familiares en el cálculo. Un punto en el cual existen dos o más tangentes que pueden coincidir es llamado punto múltiple. En tal punto dos o más ramas de la curva se intersecan: si dos ramas se intersecan en un punto múltiple, se llama punto doble; si tres ramas se intersecan, entonces se llama un punto triple, y así en adelante.
Si tomamos la ecuación de una curva algebraica
f(x, y) = 0
siendo f un polinomio en x e y, podemos mediante una traslación suprimir siempre el término constante. Si se hace esto y si hay términos de primer grado en f, digamos a1x + b1y, entonces a1x + b1y = 0 proporciona la ecuación de la tangente a la curva en el origen. El origen no es un punto múltiple en este caso. Si no existen términos de primer grado, y si a2x2 + b2xy + c2y2 son términos de segundo grado, entonces surgen varios casos. La ecuación a2x2 + b2xy + c2y2 = 0 puede representar dos rectas diferentes.
Figura 23.3 Lemniscata
a2(y2x2) + (y2 + x2)2 =0 (4)
y los términos de segundo grado dan y2x2 = 0. Entonces, y = x e y = -x son las ecuaciones de las tangentes.
Figura 23.4 Folio de Descartes
x3 + y3 = 3axy
y las tangentes en el origen, que es un nodo, están dadas por x = 0 e y = 0.Cuando las dos rectas tangentes coinciden, la única recta es considerada como una tangente doble y las dos ramas de la curva se tocan una a otra en el punto de tangencia, el cual es llamado cúspide. (Algunas veces las cúspides están incluidas entre los puntos dobles.)
Así la parábola semicúbica (fig. 23.5) tiene una cúspide en el origen, y la ecuación de las dos tangentes coincidentes es y2 = 0.
Figura 23.5. Parábola semicúbica

Figura 23.6
Cuando las dos tangentes son imaginarias, el punto doble es llamado punto conjugado. Las coordenadas del punto satisfacen la ecuación de la curva, pero el punto está aislado del resto de la curva.
Figura 23.7
La curva
ay3 3ax2y = x4
(fig. 23.8) tiene un punto triple en el origen. La ecuación de las tres tangentes esay3 3 ax2y = 0
o bieny = 0 e y=±x√3
Figura 23.8
Figura 23.9
Las curvas de tercer grado (orden) pueden tener un punto doble (el cual puede ser una cúspide) pero ningún otro punto múltiple. Existen, desde luego, cúbicas sin puntos dobles.
Para retomar la historia propiamente dicha, muchos de estos puntos especiales o singulares de las curvas fueron estudiados por Leibniz y sus sucesores. Las condiciones analíticas para dichos puntos, tales como que y = 0 en un punto de inflexión y que y sea indeterminada en un punto doble, eran conocidas incluso por los fundadores del cálculo.
Clairaut, en su libro de 1731, al que nos habíamos referido, supone que una curva de tercer grado no puede tener más de tres puntos de inflexión reales y que al menos debe tener uno. De Gua, en el Usage, probó que si una curva de tercer grado tiene tres puntos de inflexión reales, una recta que une dos de ellos pasa por el tercero. Este teorema se le atribuye comúnmente a Maclaurin. De Gua también investigó los puntos dobles y proporcionó la condición de que si f(x, y) = 0 es la ecuación de la curva, entonces fx y fy deben ser 0 en el punto doble. Un punto de k-pliegue está caracterizado por la anulación de todas las derivadas parciales hasta las de (k 1)ésimo orden. De Gua mostró que las singularidades están compuestas por cúspides, puntos ordinarios y puntos de inflexión. Además, trató los puntos medios de las curvas, la forma de ramas extendiéndose al infinito y las propiedades de tales ramas.
En su Geometría Orgánica (1720), escrita cuando sólo tenía diecinueve años, Maclaurin probó que el número máximo de puntos dobles de una curva irreducible de n-ésimo grado es (n — 1) (n — 2)/2. Para este propósito contó un punto de k-pliegue como k(k l)/2 puntos dobles, y proporcionó también cotas superiores para el número de puntos de mayor multiplicidad de cada clase. Más adelante introdujo la noción de deficiencia (posteriormente llamada género) de una curva algebraica como el máximo número posible de puntos dobles menos el número verdadero.
Entre las curvas, aquellas cuya deficiencia es 0, o poseedoras del máximo número posible de puntos dobles, recibieron gran atención. Tales curvas también son llamadas racionales o unicursales. Geométricamente, una curva unicursal puede ser recorrida por el movimiento continuo de un punto móvil (el cual puede, sin embargo, pasar a través del punto del infinito). De aquí que las cónicas, incluyendo la hipérbola, sean curvas unicursales.
En su Method of Fluxions (Método de fluxiones), Newton dio un método, al que uno se refiere comúnmente como el diagrama de Newton o el paralelogramo de Newton, para determinar representaciones en series de las diversas ramas de una curva en un punto de inflexión (cap. 20, sec. 2). En el Usage, De Gua reemplazó el paralelogramo de Newton por un triangle algébrique (triángulo algebraico). Entonces, si el origen es un punto singular, para una x pequeña, la ecuación de una curva algebraica se descompone en factores de la forma ymAxn, donde m es un entero positivo y n un entero. Las ramas de la curva están dadas por los factores para los cuales n también es positiva. Euler notó (1749) que De Gua había ignorado ramas imaginarias.
Gabriel Cramer (1704-52), en su Introduction a l'analyse des lignes courbes algébriques (Introducción al análisis de las líneas curvas algebraicas, 1750), también abordó el desarrollo de y en términos de x cuando y y x están dadas por una función implícita, esto es, que f(x, y) = 0 determina la expresión en serie para cada rama de la curva, particularmente las ramas que se extienden al infinito. Cramer trató y como una serie ascendente y descendente de las potencias de x. Al igual que De Gua, usó el triángulo en lugar del paralelogramo de Newton, y como otros, también ignoró las ramas imaginarias de las curvas.
La conclusión resultante del trabajo de obtener expansiones en serie para cada rama de la curva emanando de un punto múltiple fue obtenida mucho más tarde por Víctor Puiseux (1820-83)[209] y se conoce como el teorema de Puiseux: el entorno total de un punto (x0, y0) de una curva algebraica plana puede ser expresado por un número finito de desarrollos
yy0 = a1(xx0)q1/q0 +a2(xx0) q2/q0 + … (7)
Estos desarrollos convergen en algún intervalo alrededor de x0 y los qi no tienen factores comunes. Los puntos dados por cada desarrollo son las llamadas ramas de la curva algebraica.Las intersecciones de una curva y una recta y de dos curvas es otro tema que recibió gran cantidad de atención. Stirling, en sus Lineae (Líneas) de 1717, demostró que una curva algebraica de grado n-ésimo (en x e y) está determinada por n(n + 3)/2 de sus puntos, ya que tiene ese número de coeficientes esenciales. También afirmó que dos rectas paralelas cualesquiera cortan a una curva en el mismo número de puntos, reales o imaginarios, y probó que el número de ramas de una curva que se extiende al infinito es par. La obra de Maclaurin Geometría orgánica fundó la teoría de intersecciones de curvas planas superiores: generalizó resultados para casos especiales y sobre esta base concluyó que una ecuación de grado m-ésimo y una de grado n-ésimo se intersecan en mn puntos.
En 1748, Euler y Cramer buscaron demostrar este resultado, pero ninguno ofreció una prueba correcta. Euler[210] se apoyó en un argumento por analogía; dándose cuenta de que su argumento no era completo, dijo que se debía aplicar el método a ejemplos particulares. En su libro de 1750, la «prueba» de Cramer descansaba por completo en ejemplos y, desde luego, no fue aceptada. Ambos tomaron en cuenta los puntos de intersección con coordenadas imaginarias y los que estaban en el infinito, y notaron que el número mn sería obtenido sólo si ambos tipos de puntos eran incluidos y si cualquier factor, tal como ax + by, común a ambas curvas era excluido.
Sin embargo, ambos fracasaron al asignar la debida multiplicidad a varios tipos de intersecciones. En 1764, Etienne Bezout (1730-83) dio una prueba mejor del teorema, pero ésta también estaba incompleta en la cuenta de la multiplicidad asignada a puntos en el infinito y puntos múltiples. El cálculo correcto de la multiplicidad fue solucionado por Georges Henri Halphen (1844-89) en 1873[211].
En su libro de 1750 Cramer estudió una paradoja mencionada por Maclaurin en su Geometría concerniente al número de puntos comunes a dos curvas. Una curva de grado n está determinada por n(n + 3)/2 puntos. Dos curvas de grado n-ésimo se encuentran en n2 puntos. Ahora, si n es 3, la curva deberá, por el primer argumento, estar determinada por nueve puntos. Así, ya que dos curvas de tercer grado se encuentran en nueve puntos, esos puntos no determinan una curva única de tercer grado. Una paradoja similar surge cuando n = 4. La explicación de Cramer respecto a esta paradoja, que ahora se le adjudica a él, era que las n2 ecuaciones que determinan los n2 puntos de la intersección no son independientes. Todas las cúbicas que pasan por ocho puntos fijos de una cúbica dada deben pasar por el mismo noveno punto fijo. Esto es, el noveno es dependiente de los ocho primeros. Euler proporcionó la misma explicación en 1748[212].
En 1756 Matthieu B. Goudin (1734-1817) y Achille Pierre Dionis du Séjour (1734-94) escribieron el Traité des courbes algébriques (Tratado de curvas algebraicas). Sus nuevas características son que una curva de orden (grado) n no puede tener más de n(n 1) tangentes con una dirección dada, ni más de n asíntotas. Como ya había hecho Maclaurin, ellos señalaron que una asíntota no puede cortar la curva en más de n 2 puntos.
En el siglo XVIII, los dos mejores compendios de resultados sobre curvas planas de grado superior son el segundo volumen de la Introductio (1748) de Euler y el Ligues courbes algébriques (Líneas curvas algebraicas) de Cramer. El último libro posee una gran unidad de punto de vista, está excelentemente expuesto y reseña muy buenos ejemplos. El trabajo era citado con frecuencia, llegando al extremo de adjudicarse a Cramer algunos resultados que originalmente no eran suyos.
4. Los orígenes de la geometría diferencial
Mientras la geometría diferencial estaba en sus inicios, la geometría analítica se extendía, y de tal forma que los dos desarrollos con frecuencia se entretejieron. El interés por la teoría de las curvas algebraicas declinó durante la última parte del siglo XVIII, y la geometría diferencial se hizo más importante en cuanto concernía a la geometría. Esta materia consiste en el estudio de aquellas propiedades de las curvas y superficies que varían de punto a punto y que, por lo tanto, pueden ser comprendidas únicamente con las técnicas del cálculo. El término «geometría diferencial» se usó por primera vez por Luigi Bianchi (1856-1928) en 1894.
En gran medida, la geometría diferencial fue el crecimiento natural de los propios problemas del cálculo. Las consideraciones sobre las normales a las curvas, puntos de inflexión y curvaturas es de hecho la geometría diferencial de curvas planas. Sin embargo, muchos nuevos problemas de la última parte del siglo XVII y primera del XVIII, el mayor conocimiento acerca de la curvatura de las curvas planas y espaciales, envolventes de familias de curvas, geodésicas sobre superficies, el estudio de los rayos de luz y de superficies de onda de luz, problemas dinámicos de movimiento junto con curvas y restricciones impuestas por superficies, y, por encima de todo, el trazado de mapas llevaron a preguntas sobre curvas y superficies: se hizo evidente que se tenía que aplicar el cálculo.
Los cultivadores de la geometría diferencial del siglo XVIII y primera parte del XIX usaron argumentos geométricos junto con los analíticos, aunque estos últimos dominaron la escena. El análisis era aún basto. El infinitesimal o diferencial de una variable independiente era observado como una constante en extremo pequeña. No se había dado una verdadera distinción entre el incremento de una variable independiente y el diferencial. A las diferenciales de órdenes superiores se las tomaba en cuenta, pero se las veía a todas como muy pequeñas, dándose la libertad de despreciarlas. Los matemáticos hablaban de puntos adyacentes o próximos de una curva como si no hubiera puntos entre los puntos adyacentes si la distancia entre los dos era suficientemente pequeña, por lo que una tangente a una curva conectaba un punto con el siguiente.
5. Curvas planas
La primera aplicación del cálculo a las curvas se hizo con las curvas planas. Algunos de los conceptos subsecuentemente tratados por el cálculo fueron introducidos por Christian Huygens, quien usó únicamente métodos geométricos. Su trabajo en este sentido estuvo motivado por su interés en la luz y el diseño de relojes de péndulo. En 1673, en el tercer capítulo de su Horologium Oscillatorium (Péndulo oscilatorio), introdujo la involuta a una curva plana C.

Figura 23.10
Huygens trató entonces la evoluta de una curva plana. Dada una normal fija en un punto P sobre la curva, cuando una normal adyacente se mueva hacia ella, el punto de intersección de las normales llega a una posición límite sobre la normal fija, el cual es llamado centro de curvatura de la curva en P. Huygens mostró que la distancia desde el punto sobre la curva a lo largo de la normal fija a la posición límite es (en notación moderna)
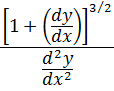

Figura 23.11
También Newton, en su Geometría Analytica (Geometría analítica, publicada en 1736 aunque la mayor parte de ella fue escrita en 1671) introduce los centros de curvatura como los puntos límites de la intersección de una normal en P con una normal adyacente. Entonces afirma que el círculo con centro en el centro de curvatura y radio igual al radio de curvatura es el círculo de contacto más cercano a la curva en P; es decir, ningún otro círculo tangente a la curva en P puede interponerse entre la curva y el círculo de contacto más cercano. Este círculo de contacto más cercano es llamado el círculo osculador, habiendo sido usado el término «osculador» por Leibniz en un ensayo de 1686[214]. La curvatura de este círculo es el recíproco de su radio y es la curvatura de la curva en P. Newton proporcionó también la fórmula para la curvatura y calculó la curvatura de varias curvas, incluyendo la cicloide. Notó que en el punto de inflexión una curva tiene curvatura cero. Estos resultados duplican aquellos de Huygens, pero Newton probablemente deseaba mostrar que él podía utilizar métodos analíticos para establecerlos.
En 1691, Jean Bernoulli retomó el estudio de las curvas planas y obtuvo algunos resultados nuevos sobre envolventes. La cáustica de una familia de rayos de luz, esto es, la envolvente de la familia, había sido introducida por Tschirnhausen en 1682. En el Acta Eruditorum de 1692, Bernoulli obtuvo las ecuaciones de algunas cáusticas, por ejemplo, la cáustica de rayos reflejada desde un espejo esférico cuando un haz de rayos paralelos choca con él[215]. Más adelante atacó el problema propuesto por Fatio de Guillier: encontrar la envolvente de la familia de parábolas que son trayectorias de balas de cañón disparadas desde un cañón con la misma velocidad inicial, pero con diferentes ángulos de elevación. Bernoulli mostró que la envolvente es una parábola cuyo foco está en el arma. Este resultado ya había sido establecido geométricamente por Torricelli. En el Acta Eruditorum de 1692 y 1694[216] Leibniz proporcionó el método general para encontrar la envolvente de una familia de curvas. Si la familia está dada (en nuestra notación) por f(x, y, α) = 0, donde α es el parámetro de la familia, el método requiere eliminar a entre f= 0 y ∂f/∂a = 0. El texto de L'Hôpital, L’analyse des infinimentpetits (El análisis de los infinitamente pequeños, 1696) ayudó a perfeccionar y extender la teoría de las curvas planas.
6. Curvas en el espacio
Clairaut inició la teoría de las curvas en el espacio, el primer avance importante en la geometría diferencial de tres dimensiones. Alexis-Claude Clairaut (1713-65) fue precoz. A los doce años de edad ya había escrito un buen trabajo sobre las curvas. En 1731 publicó Recherche sur les courbes á double courbure (Investigación sobre las curvas de doble curvatura), que escribió en 1729, cuando tenía dieciséis años de edad. En este libro discutió el aspecto analítico de las superficies y curvas espaciales (sec. 2). Otro ensayo de Clairaut lo llevó a su elección a la Academia de Ciencias de París a la edad sin precedente de diecisiete años. En 1743 realizó su trabajo clásico sobre la forma de la Tierra. Aquí trató de una manera más completa de lo que lo había hecho Newton y Maclaurin la forma de un cuerpo que gira, tal como la que toma la Tierra bajo la atracción gravitacional mutua de sus partes. También trabajó sobre el problema de los tres cuerpos, principalmente para estudiar el movimiento de la Luna (cap. 21, sec. 7), escribió varios ensayos sobre ello, y uno por el que ganó el premio de la Academia de San Petersburgo en 1750. En 1763 publicó su Théorie de la Lune (Teoría de la Luna). Clairaut poseía un gran encanto personal y fue una figura de la sociedad parisina.
En su trabajo de 1731 trató analíticamente problemas fundamentales de las curvas en el espacio. Llamó a las curvas espaciales «curvas de doble cuadratura» porque, siguiendo a Descartes, consideraba sus proyecciones sobre dos planos perpendiculares: las curvas espaciales entonces «participan» de las curvaturas de las dos curvas sobre los planos. Pensó geométricamente una curva en el espacio como la intersección de dos superficies; analíticamente, la ecuación de cada superficie era expresada como una ecuación de tres variables (sec. 2). Clairaut estudió entonces tangentes a las curvas, y vio que una curva puede tener infinitas normales localizadas en un plano perpendicular a la tangente. Las expresiones para la longitud de arco de una curva espacial y la cuadratura de ciertas áreas sobre superficies también se deben a Clairaut.
A pesar de que Clairaut había dado algunos pasos en la teoría de las curvas en el espacio, muy poco se había hecho en esta materia o en la teoría de las superficies en 1750. Esto se refleja en la Introductio (Introducción) de Euler de 1748, donde presentó la geometría diferencial de las figuras planas y espaciales. La primera era bastante completa, pero no así la segunda.
El siguiente paso importante en la geometría diferencial de curvas espaciales fue dado por Euler. Gran parte de su trabajo en geometría diferencial estuvo motivado por uso de curvas y superficies en mecánica. Su Mechanica (Mecánica, 1736)[217], escrita cuando contaba veintinueve años de edad, es una contribución muy importante a los fundamentos analíticos de la mecánica. Proporcionó otro tratamiento de la materia en su Theoria Motus Corporum Solidorum seu Rigidorum (Teoría del movimiento de los cuerpos sólidos y rígidos, 1765)[218]. En este trabajo obtuvo las fórmulas actuales para el uso de coordenadas polares en las componentes radial y normal de la aceleración de una partícula moviéndose a lo largo de una curva plana, es decir,
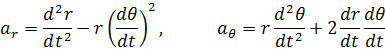
Euler representó las curvas espaciales mediante las ecuaciones paramétricas
x = x(s), y = y(s), z = z(s)
donde s es la longitud de arco, y, como otros autores del siglo XVIII, utilizó la trigonometría esférica para llevar a cabo su análisis. A partir de las ecuaciones paramétricas obtienedx = p ds, dy = q ds, dz = r ds,
donde p, q y r son cosenos directores, variando de punto a punto y, por supuesto, con p2 + q2 + r2 = 1. La cantidad ds, diferencial de la variable independiente, la consideraba como una constante.Para estudiar las propiedades de la curva introdujo la indicatriz esférica. Alrededor del punto (x, y, z) de la curva, Euler describe una esfera de radio 1. La indicatriz esférica puede ser definida como el lugar sobre la esfera unitaria de los puntos cuyos vectores de posición partiendo del centro O son iguales a la tangente unitaria en (x, y, z) y las tangentes unitarias en los puntos vecinos.

Figura 23.12
Más adelante deriva una expresión analítica del radio de curvatura
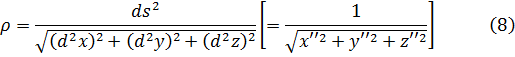
x(r dqq dr) + y(p dr r dp) + z(q dp p dq) = t,
donde t está determinada por el punto (x, y, z) sobre la curva por el que pasa el plano osculador. Esta ecuación es equivalente a la que se escribe en notación vectorial hoy en día como(Rr) ∙ r' × r" = 0
donde r(s) es el vector de posición con respecto a algún punto en el espacio del punto sobre la curva en el cual el plano osculador está determinado y R es el vector de posición en cualquier punto en el plano oscilante. En forma vectorial, r está dado porx(s)i + y(s)j + z(s)k
y R tiene la forma Xi + Yj + Zk, donde (X, Y, Z) son las coordenadas de R.Clairaut había introducido la idea de que una curva espacial tiene dos curvaturas. Una de éstas fue sistematizada por Euler en la forma que acabamos de describir. La otra, ahora llamada «torsión» y que representa geométricamente la proporción en la que una curva se aleja de un plano en un punto (x, y, z), fue formulada explícita y analíticamente por Michel Ange Lancret (1774-1807), ingeniero y matemático alumno de Monge, quien trabajó en esa tradición. Lancret señaló[221] tres direcciones principales en cualquier punto sobre una curva. El primero es el de la tangente. Las tangentes «sucesivas» descansan en el plano osculador. La normal a la curva que descansa en el plano osculador es la normal principal, y la perpendicular al plano osculador, la binormal, es la tercera dirección principal. La torsión es la proporción de cambio en la dirección de la binormal con respecto a la longitud de arco. Lancret usó la terminología flexión de planos osculadores sucesivos o binormales sucesivas.
Lancret representó una curva mediante
x = ϕ (z), y = ψ (z)
y llamó dμ el ángulo entre los planos normales sucesivos y dω el correspondiente entre los osculadores sucesivos. Entonces, en notación moderna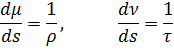
Cauchy mejoró la formulación de los conceptos y precisó gran parte de la teoría de curvas espaciales en su famoso Leçons sur les applications du calcul infinitesimal de la géometrie (Lecciones sobre las aplicaciones del cálculo infinitesimal a la geometría, 1826)[222]. Descartó los infinitesimales constantes, los ds', y aclaró la confusión entre los incrementos y las diferenciales. Señaló que cuando alguien escribe
ds2 = dx2 + dy2 + dz2
se debe entender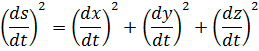
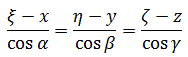
Prácticamente, el desarrollo de Cauchy de la geometría de curvas es moderno. Eliminó la trigonometría esférica de sus demostraciones, pero también tomó la longitud de arco como variable independiente y obtiene para los cosenos directores de la tangente en cualquier punto
![]()
![]()
![]()
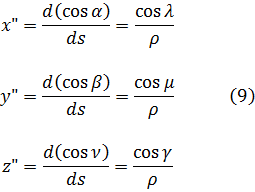
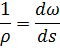
Introduce el plano osculador como el plano de la tangente y la normal principal. La normal a este plano es la binormal y sus cosenos directores cos L, cos M y cos N están dados por las fórmulas
![]()
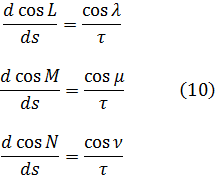
Las fórmulas (9) y (10) son dos de las tres famosas fórmulas de Serret-Frénet, la tercera es

7. La teoría de superficies
Como la teoría de curvas en el espacio, la teoría de superficies tuvo un inicio lento. Empezó con el estudio de las geodésicas sobre superficies, con las geodésicas sobre la Tierra como preocupación principal. En el Journal des Scavans de 1697, Jean Bernoulli propuso el problema de encontrar el arco mínimo entre dos puntos sobre una superficie convexa[225]. Le escribió a Leibniz en 1698 para señalarle que el plano osculador (el plano del círculo osculador) en cualquier punto de una geodésica es perpendicular a la superficie en ese punto. En 1698 Jacques Bernoulli resolvió el problema de las geodésicas sobre cilindros, conos y superficies de revolución. El método era limitado, a pesar de que en 1728 Jean Bernoulli[226] tuvo cierto éxito con el método y encontró las geodésicas sobre otros tipos de superficies.
En 1728 Euler [227] proporcionó las ecuaciones diferenciales para las geodésicas sobre superficies. Euler usó el método que había introducido en el cálculo de variaciones (véase cap. 24, sec. 2). En 1732 Jacob Hermann[228] también encontró geodésicas en superficies particulares.
En 1733 y también en 1739[229], en su trabajo sobre la forma de la Tierra, Clairaut trató las geodésicas sobre superficies de revolución de una manera más completa. Demostró en su ensayo de 1733 que para cualquier superficie de revolución, el seno del ángulo formado por una curva geodésica y cualquier meridiano (cualquier posición de la curva generadora) que cruza, varía inversamente con la longitud de la perpendicular a partir del punto de intersección al eje. En otro ensayo[230], demostró también el bello teorema de que si en cualquier punto M de una superficie de revolución un plano pasa por la normal a la superficie y al plano del meridiano en M, entonces la curva determinada en la superficie tiene un radio de curvatura en M igual a la longitud de la normal entre M y el eje de revolución. Los métodos de Clairaut eran analíticos, pero, como la mayoría de sus predecesores, no utilizó las ideas que hoy en día asociamos con el cálculo de variaciones.
En 1760, en su Recherches sur la courbure des surfaces (Investigaciones sobre la curvatura de las superficies)[231], Euler estableció la teoría de las superficies. Este trabajo es la contribución más importante de Euler a la geometría diferencial y un punto culminante de la materia. Euler representa una superficie por z = f(x, y) e introduce la actual notación
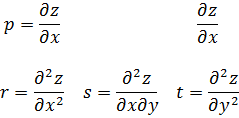
Primero obtiene una expresión bastante compleja del radio de curvatura de cualquier curva obtenida al cortar una superficie con un plano. Entonces particulariza el resultado al aplicarlo a secciones normales (secciones conteniendo una normal a una superficie). Para las secciones normales, la expresión general para el radio de curvatura se simplifica un poco. Más adelante define la sección normal principal como la sección normal perpendicular al plano xy. (Este uso de «principal» no se sigue hoy en día.) El radio de curvatura de una sección normal cuyo plano forma un ángulo ϕ con el plano de la sección normal principal tiene la forma
![]()
Se sigue de los resultados de Euler que la curvatura de cualquier otra sección normal que forma un ángulo α con una de las secciones con curvatura principal es
![]()
Los mismos resultados fueron obtenidos en 1776 de una manera más elegante por un alumno de Monge, Jean-Baptiste-Marie-Charles Meusnier de la Place (1754-93), quien también trabajó en hidrostática y en química con Lavoisier. Más adelante, Meusnier[232] estudió la curvatura de secciones no normales, para las cuales Euler había obtenido una expresión muy compleja. El resultado de Meusnier, aún llamado teorema de Meusnier, afirma que la curvatura de una sección plana de una superficie en un punto P es la curvatura de la sección normal a lo largo de la misma tangente en P dividida por el seno del ángulo que el plano original forma con el plano tangente en P. Le sigue el bello resultado de que si uno considera la familia de planos a lo largo de la misma línea tangente MM' a una superficie, entonces los centros de curvatura de las secciones determinadas por estos planos están en un círculo en un plano perpendicular a MM' y cuyo diámetro es el radio de curvatura de la sección normal. Meusnier, entonces, prueba el teorema de que las únicas superficies para las cuales las dos curvaturas principales son iguales en todo punto son los planos o las esferas. Su ensayo fue particularmente simple y fértil; ayudó a hacer intuitivos un buen número de resultados obtenidos durante el siglo XVIII.
Una preocupación especial de la teoría de las superficies, motivada por las necesidades de la cartografía, es el estudio de las superficies desarrollables: dado que la esfera no puede ser cortada y luego aplanada, el problema era encontrar superficies con formas cercanas a la de una esfera que pudieran ser desarrolladas sin gran distorsión. Euler fue el primero en considerar el tema. Este trabajo se encuentra contenido en su «De Solidis Quorum Superficiem in Planum Explicare Licet»[233] (Los sólidos...). En el siglo XVIII, las superficies eran consideradas como fronteras de sólidos; por ello habla Euler de sólidos cuyas superficies pueden ser desdobladas sobre un plano. En este ensayo introduce la representación paramétrica de superficies, esto es:
![]()
![]()
Más adelante, Euler investigó la relación entre las curvas en el espacio y las superficies desarrollabas y mostró que la familia de tangentes a cualquier curva en el espacio llena o constituye una superficie desarrollable. Intentó sin éxito demostrar que toda superficie desarrollable es una superficie reglada, esto es, una superficie generada por una línea recta en movimiento, y a la inversa. El recíproco es, de hecho, falso.
Gaspard Monge trató independientemente el tema de las superficies desarrollables. Con Monge, la geometría y el análisis se apoyaban mutuamente. Consideró simultáneamente ambos aspectos del mismo problema y mostró la utilidad de pensar tanto geométrica como analíticamente. El efecto del doble punto de vista de Monge fue colocar a la geometría, al menos, en igualdad con el análisis e inspirar el renacer de la geometría pura. A pesar de que el análisis había dominado en el siglo XVIII, a pesar de la geometría analítica y la geometría diferencial de Euler y Clairaut, Monge es el primer y verdadero innovador en geometría sintética después de Desargues.
Su extenso trabajo en geometría descriptiva (la cual sirve principalmente a la arquitectura), geometría analítica, geometría diferencial y ecuaciones diferenciales ordinarias y parciales ganó la admiración y envidia de Lagrange, quien después de escuchar una conferencia de Monge, le dijo: «Usted acaba de presentar, mi querido colega, muchas cosas elegantes. Yo desearía haberlas hecho.» Monge contribuyó mucho a la física, química, metalurgia (problemas de forja) y maquinaria. En química trabajó con Lavoisier. Monge vio la necesidad de la ciencia en el desarrollo de la industria y abogó por la industrialización como una vía por la mejora de la vida. Estaba inspirado por una activa preocupación social, tal vez porque conoció el infortunio de orígenes humildes; por esta razón apoyó la Revolución Francesa y sirvió como ministro de la Marina y como miembro del Comité de Salvación Pública en los gobiernos sucesivos. Diseñó armamentos e instruyó a personal del gobierno en asuntos técnicos. Su admiración por Bonaparte lo sedujo a seguirlo con sus medidas antirrevolucionarias.
Monge ayudó a organizar la Ecole Polytechnique y como profesor fundó una escuela de geómetras. Fue un gran maestro y una fuerza inspiradora de la actividad matemática del siglo XIX. Sus conferencias vigorosas y fértiles comunicaron entusiasmo a sus alumnos, entre quienes estuvieron al menos una docena de los más famosos personajes del siglo XIX. A él se deben resultados en geometría diferencial tridimensional que van mucho más allá que los de Euler. Su artículo de 1771 «Mémoire sur les développées, les rayons de courbure et les différents genres d’inflexions des courbes á double courbure» («Memoria sobre las desarrolladas, los radios de curvatura y los diferentes géneros de inflexión de las curvas de doble curvatura»), publicado mucho después[234], fue seguido por su Feuilles d’analyse appliquée á la géométrie (Hojas de análisis aplicado a la geometría, 1795; segunda edición, 1801). Las Feuilles era tanto geometría diferencial como geometría analítica y ecuaciones diferenciales parciales. Basándose en notas de conferencias ofrece una sistematización y extensión de antiguos resultados, nuevos resultados de cierta importancia y el traslado de varias propiedades de curvas y superficies al lenguaje de las ecuaciones diferenciales parciales. Al perseguir la relación entre las ideas del análisis y las de la geometría, Monge reconoció que una familia de superficies, al tener una propiedad geométrica común o al estar definidas por el mismo método de generación, deberían satisfacer una ecuación diferencial parcial (cap. 22, sec. 6).
El primer trabajo importante de Monge, el ensayo en torno a las superficies desarrollables sobre curvas de doble curvatura, relaciona curvas en el espacio y superficies asociadas a ellas. En ese momento, Monge no conocía el trabajo de Euler sobre las superficies desarrollables. Trata las curvas en el espacio ya sea como la intersección de dos superficies o por medio de sus proyecciones sobre dos planos perpendiculares, dados por y = ϕ(x) y z = ψ(x). En cualquier punto ordinario hay una infinidad de normales (perpendiculares a la línea tangente) que están en un plano, el plano normal. En este plano existe una línea que llama eje (polar), el cual es el límite de la intersección con un plano normal vecino. Cuando uno se mueve a lo largo de la curva los planos normales envuelven una superficie desarrollable, llamada la polar desarrollable. La superficie también es engendrada por los ejes de los planos normales. La perpendicular desde P al eje en el plano normal en P es la normal principal y el pie Q de la perpendicular es el centro de curvatura.
Para obtener la ecuación de la polar desarrollable, Euler encuentra la ecuación del plano normal y elimina x entre esta ecuación y la derivada parcial de la ecuación con respecto a x. También obtiene una regla para encontrar la envolvente de cualquier familia de planos uniparamétrica, que es la que actualmente usamos. La regla, que se aplica igual a familias uniparamétricas de superficies, es esta: en nuestra notación, toma F(x, y, z, a) = 0 como la familia. Para encontrar dónde ésta encuentra «una superficie infinitesimalmente cerca», halla ∂F/∂α = 0. La curva de intersección de las dos superficies es llamada la curva característica. La ecuación de la envolvente se encuentra al eliminar a entre F = 0 y ∂F/∂α = 0. Euler aplica este método al estudio de otras superficies desarrollables, cada una de las cuales considera como la envolvente de una familia uniparamétrica de planos.
Monge también tuvo en cuenta la arista de regresión (arete de rebroussement) de una superficie desarrollable. La arista (curva) está formada por un conjunto de líneas generando la superficie. La intersección de dos líneas vecinas cualquiera es un punto y el lugar de tales puntos es la arista de regresión. Entonces las tangentes a Γ son las generatrices, o Γ es la envolvente de la familia de líneas generatrices. La arista de regresión separa la superficie desarrollable en dos películas u hojas, de la misma manera que una cúspide separa a una curva plana en dos partes. Monge obtuvo las ecuaciones de la arista de regresión. En el caso de la superficie polar desarrollable de una curva en el espacio, la arista de regresión es el lugar geométrico de los centros de curvatura de la curva original.
En 1775, Monge presentó a la Académie des Sciences otro ensayo sobre superficies, particularmente las superficies desarrollables que aparecen en la teoría de las sombras y las penumbras[235]. Usando la definición de que una superficie desarrollable puede ser aplanada sin distorsión, argumenta intuitivamente que una superficie desarrollable es una superficie reglada (pero no recíprocamente) sobre la cual dos líneas consecutivas son concurrentes o paralelas y que cualquier desarrollable es equivalente a aquella formada por las tangentes de una curva en el espacio. Es en este ensayo de 1775 donde proporciona la representación general de las superficies desarrollables. Sus ecuaciones son siempre de la forma
![]()
zxxzyyz2xy = 0
Después estudia Monge las superficies regladas y da una representación general para ellas. También proporciona la ecuación diferencial parcial de tercer orden que satisfacen, e integra esta ecuación diferencial. Demuestra que las superficies desarrollables son un caso especial de las superficies regladas.En su «Mémorie sur la théorie des deblais et des remblais» («Memoria sobre la teoría de excavaciones y rellenos») de 1776[236], considera el problema surgido en la construcción de fortificaciones, que involucra el transporte de tierra y otros materiales de un lugar a otro, y busca encontrar la solución más eficiente, esto es, que el material transportado por la distancia transportada debe ser un mínimo. Únicamente parte de este trabajo es importante para la geometría diferencial de superficies; ciertamente los resultados del problema práctico no son muy realistas —según dice Monge— y publica el ensayo por los resultados geométricos encontrados allí. Aquí inicia el tratamiento del problema de una familia de líneas dependiendo de dos parámetros o de una congruencia de rectas. Siguiendo el trabajo de Euler y Meusnier, considera la familia de normales a una superficie S, que forman también una congruencia de líneas. Considérense, en particular, las normales a lo largo de una línea de curvatura (una línea de curvatura es una curva sobre la superficie que tiene una curvatura principal en cada punto de la curva). Las normales a la superficie en estos puntos de la línea de curvatura forman una superficie desarrollable llamada normal desarrollable. Análogamente las normales a la superficie a lo largo de la línea de curvatura perpendicular a la primera forman una superficie desarrollable. Ya que hay dos familias de líneas de curvatura en la superficie, existen dos familias de superficies desarrollables y los miembros de una intersecan a los miembros de la otra en ángulo recto. De hecho, la intersección de dos cualesquiera tiene lugar sobre la normal a la superficie. En cada normal hay dos puntos que distan de la superficie precisamente las dos curvaturas principales.
Figura 23.13
Para el estudio de las ecuaciones diferenciales parciales son muy significativos los detalles ulteriores del trabajo de Monge sobre familias de superficies que satisfacen dichas ecuaciones diferenciales parciales no lineales y lineales de primero, segundo y hasta tercer orden.
Monge explicó sus ideas tratando a fondo un cierto número de curvas y superficies concretas. La generalización y explotación de sus ideas se llevó a cabo por los matemáticos del siglo XIX. Siempre orientado desde un punto de vista práctico, Monge concluyó sus Feuilles con una visión de cómo su teoría podía ser aplicada a la arquitectura y, en particular, a la construcción de amplios salones de juntas.
Charles Dupin (1784-1873), alumno de Monge, realizó algunas contribuciones adicionales a la teoría de superficies. Dupin se graduó de la Ecole Polytechnique como ingeniero naval, y, al igual que Monge, tuvo constantemente las aplicaciones geométricas ante él. Su texto Développements de géométrie {Desarrollos de la geometría, 1813) fue subtitulado «Con aplicaciones a la estabilidad de barcos, excavación y relleno, fortificaciones, óptica, etcétera», y otros escritos, notablemente sus Applications de géométrie et de mécanique (.Aplicaciones de la geometría y la mecánica, 1822), contienen contribuciones a estas materias. Los primeros resultados que describiremos corresponden a su libro de 1813.
Una de las contribuciones de Dupin, que extiende y clarifica trabajos previos de Euler y Meusnier, es la llamada indicatriz de Dupin. Dado el plano tangente a una superficie en un punto M, llevó en cada dirección a partir de M un segmento cuya longitud es igual a la raíz cuadrada del radio de la curvatura de la sección normal de la superficie en esa dirección. El lugar geométrico de los puntos finales de estos segmentos es una cónica, la indicatriz, la cual da una primera aproximación de la forma de la superficie alrededor de M (esto es casi igual a una sección de la superficie hecha por un plano cerca de M y paralelo al plano tangente en M). Las líneas de curvatura de una superficie en el punto, esto es, las curvas sobre la superficie que pasan por M teniendo curvatura extrema (máxima o mínima) son las curvas que tienen como tangentes en M los ejes de la indicatriz.
En un sistema tridimensional de coordenadas rectangulares, las superficies coordenadas son las tres familias de superficies x = const., y = const. y z = const. Supóngase que uno tiene tres familias de superficies, cada una dada por ecuaciones en x, y y z. Si cada miembro de una familia corta ortogonalmente a uno de los miembros de las otras dos familias, entonces las tres familias son llamadas ortogonales. El resultado más sobresaliente de Dupin en esta materia, que se encuentra en su Développements, es el teorema de que tres familias de superficies ortogonales se cortan entre sí a lo largo de las líneas de curvatura (las curvas de curvatura normal máxima o mínima) de cada superficie.
Dupin también logró extensiones de los resultados de Monge a las congruencias de líneas. Si la congruencia, la familia biparamétrica, es cortada ortogonalmente por una familia de superficies, como en el caso de la óptica donde las líneas son rayos de luz y las superficies frentes de onda, entonces la congruencia se llama normal. Usando aparentemente los resultados de Monge —aunque no se refiere a ellos— Etienne Louis Malus (1755-1812), físico francés, probó que una congruencia normal de líneas emanando de un punto (un conjunto homocéntrico) permanece igual después de la reflexión o refracción (de acuerdo con las leyes de la óptica) sobre una superficie. En 1816, Dupin demostró que dicho resultado es cierto para cualquier congruencia normal después de cualquier número de reflexiones. Lambert A. J. Quetelet (1796-1874) proporcionó más adelante una prueba de que una congruencia normal permanece normal después de cualquier número de refracciones. El tema de las congruencias de líneas y complejos de líneas, familias introducidas por Malus y que dependen de tres parámetros, fue seguido por muchos cultivadores en el siglo XIX.
8. El problema de los mapas
Gran parte de la geometría diferencial del siglo XVIII estuvo motivada por problemas de geodesia y trazado de mapas. Sin embargo, el problema de hacer mapas supone consideraciones y dificultades particulares que generaron varios desarrollos matemáticos, en especial transformaciones conformes o aplicaciones conformes, afectando a varias ramas de las matemáticas. El trazado de mapas es, por supuesto, mucho más antiguo que la geometría diferencial, y cada uno de los métodos matemáticos de representación va mucho más atrás. De éstos, la proyección estereográfica y otros métodos (cap. 7, sec. 5) surgen de Ptolomeo y la proyección de Mercator (cap. 12, sec. 2) data del siglo XVI. Respecto a que no eran reales los mapas de una esfera desdoblada en un plano, se pudo haber estado intuitivamente convencido con anterioridad al siglo XVIII, ya que no es posible aplicar una esfera sobre un plano y conservar a la vez las longitudes. Si esto fuera factible, entonces todas las propiedades geométricas podrían ser conservadas. Únicamente las superficies desarrollables pueden ser aplicadas así y, como fue revelado por la aportación del siglo XVIII, éstas son cilindros (no necesariamente circulares), conos y cualquier superficie generada por las líneas tangentes a una curva en el espacio. Puesto que en un mapa de una esfera sobre un plano no es posible conservar todas sus propiedades geométricas, la atención se dirigió hacia los mapas que conservaban los ángulos.
En tales mapas, si dos curvas sobre una superficie se cortan con un ángulo a y las curvas correspondientes en el otro se cortan con el mismo ángulo, y si la dirección de los ángulos se conserva, se dice que el mapa es conforme. La proyección estereográfica y la proyección de Mercator son conformes. Esta propiedad no significa que dos figuras finitas correspondientes sean semejantes, porque la igualdad de ángulos es una propiedad que se tiene en un punto.
J. H. Lambert inició una nueva época en la cartografía teórica, siendo el primero en considerar la aplicación conforme de una esfera sobre el plano en toda su generalidad; en un libro de 1772, Anmerkungen und Zusatze zur Entwefung der Land-und Himmelscharten (Notas y adiciones sobre diseño de mapas terrestres y mapas de los cielos), obtuvo sus fórmulas para esta representación. También Euler hizo muchas contribuciones en este tema y de hecho realizó un mapa de Rusia. En un ensayo presentado a la Academia de San Petersburgo en 1768[237], Euler, empleando funciones complejas, diseñó un método para representar transformaciones conformes de un plano en otro, pero no lo aprovechó. Más adelante, en dos ensayos presentados en 1775[238], mostró que la esfera no podía ser aplicada congruentemente en un plano. Aquí también usó funciones complejas, dando un estudio bastante general de las representaciones conformes. Asimismo, proporcionó un análisis completo de las proyecciones de Mercator y de las estereográficas. Lagrange, en 1779[239], obtuvo todas las transformaciones conformes de una porción de la superficie de la Tierra sobre un área plana, que transformaba círculos de latitud y longitud en arcos circulares.
La difusión de la geometría diferencial y la teoría de funciones complejas tuvo que esperar a que se realizara un mayor progreso en el problema de los mapas y en la representación conforme.
Bibliografía
- Ball, W. W. Rouse: «On Newton’s classification of Cubic Curves», Proceedings of the London Mathematical Society, 22, 1890, 104-143.
- Bernoulli, Jean: Opera Omnia, 4 vols. 1742, reimpresa por Georg Olms, 1968.
- Berzolari, Luigi: «Allgemeine Theorie der hoheren ebenen algebraischen Kurven», Encyk. der Math. Wiss., B. G. Teubner, 1903-15, III C4, 313-455.
- Boyer, Cari B.: History of Analytic Geometry, Scripta Mathematica, 1956, caps. 6-8. —: Historia de la matemática. Madrid, Alianza, 1986.
- Brill, A. y Max Noether: «Die Entwicklung der Theorie der algebraischen Funktionen in álterer und neuerer Zeit», Jahres. der Deut. Math.-Verein, 3, 1892-/3, 107-156.
- Cantor, Moritz: Vorlesungen über Geschichte der Mathematik, B. G. Teubner, 1898 y 1924; Johnson Reprint Corp., 1965, vol. 3, 18-35, 748-829; vol. 4, 375-388.
- Chasles, M.: Aperqu historique sur Vorigine et le développement des méthodes en géométrie (1837), 3.a edición, Gauthier-Villars, 1889, pp. 142-252.
- Coolidge, Julián L.: «The beginnings of Analytic Geometry in Three Dimensions», Amer. Math. Monthly, 55, 1948, 76-86. —: A History of Geometrical Methods, Dover (reimpresión), 1963, pp. 134-140 y 318-346. —: The Mathematics of Great Amateurs. Dover (reimpresión, 1963, cap. 12. —: A History of Conic Sections and Quadric Surfaces. Dover (reimpresión), 1968.
- Euler, Leonhard: Opera Omnia, Orell Fussli, Serie 1, vol. 6 (1921), vols. 26-29 (1953-56); Serie 2, vols. 3 y 4 (1948-50), vol. 9 (1968).
- Huygens, Christian: Horologium Oscillatorium (1673), reimpreso por Dawsons, 1966; también en Huygens, Œuvres completes, 18, 27-438.
- Hofmann, Jos E.: Über Jakob Bernoullis Beitráge zur Infinitesimallmathematik», L’enseignement mathématique, (2), 2, 61-171, 1956, publicado por separado por el Instituto de Matemáticas, Ginebra, 1957.
- Kotter, Ernst: «Die Entwickelung der synthetischen Geometrie von Monge bis auf Staudt», Jahres. der Deut. Math.-Verein., 5, parte II, 1986, 1-486; también como libro, B. G. Teubner, 1901.
- Lagrange, Joseph Louis: Œuvres, Gauthier-Villars, 1867-69, vol. 1, 3-20; vol. 3, 619-692.
- Lambert, J. H.: Ammerkungen und Zusátze zur Entwefung der Land-und Himmelscharten (1772), Ostwald’s Klassiker núm. 54, Wielhelm Engelmann, Leipzig, 1896.
- Loria, Gino: Spezielle algebraische und tranzendente ebenen Kurven, Theorie und Geschichte, 2 vols., 2.a edición, B. G. Teubner, 1910-11.
- Montucla, J. F.: Histoire des Mathématiques (1802), Albert Blanchard (reimpresión), 1960, vol. 3, pp. 63-102.
- Struik, D. J.: A Source Book in Mathematics (1200-1800), Harvard University Press, 1969, pp. 168-178, 180-183, 263-269, 413-419.
- Taton, René: Œuvre scientifique de Monge, Presses Universitaires de France, 1951, cap. 4.
- Whiteside, Derek T.: «Patters of Mathematical Thought in the Later Seventeenth Century», Archive for History of Exact Sciences, 1, 1961, 179-388. Véanse pp. 202-205 y 270-311. —: The Mathematical Works of Isaac Newton, Johnson Reprint Corp., 1967, vol. 2, 137-161. Este contiene la Enumerado (Enumeración) de Newton en inglés.
Capítulo 24
El cálculo de variaciones en el siglo XVIII
Ya que la fábrica del universo es más que perfecta y es el trabajo de un Creador más que sabio, nada en el universo sucede en el que alguna regla de máximo o mínimo no aparezca.
Leonhard Euler
1. Los problemas iniciales1. Los problemas iniciales
2. Los primeros trabajos de Euler
3. El principio de mínima acción
4. La metodología de Lagrange
5. Lagrange y la mínima acción
6. La segunda variación
Bibliografía
El cálculo de variaciones, durante sus etapas tempranas en el siglo que nos ocupa, difícilmente puede distinguirse del cálculo propiamente dicho, de modo análogo a lo que sucede en las áreas de series y ecuaciones diferenciales. No obstante, pocos años después de la muerte de Newton en 1727 se hacía evidente que una rama totalmente nueva de las matemáticas, con sus propios problemas y su metodología, había surgido. Esta nueva materia, casi comparable en importancia con las ecuaciones diferenciales para las matemáticas y las ciencias, suministró uno de los más grandes principios en toda la física matemática.
Para tener una noción preliminar de la naturaleza del cálculo de variaciones, consideremos los problemas que impulsaron a los matemáticos hacia este tema. Históricamente, el primer problema significativo fue propuesto y resuelto por Newton. En el libro segundo de sus Principia estudió el movimiento de los objetos en el agua; más adelante, en el escolio a la proposición 34 de la tercera edición, consideró el contorno que una superficie de revolución moviéndose a una velocidad constante en la dirección de sus ejes debe tener si presenta la mínima resistencia al movimiento. Newton supuso que la resistencia del fluido en cualquier punto sobre la superficie del cuerpo es proporcional a la componente de la velocidad normal a la superficie. En los Principia proporcionó únicamente una caracterización geométrica del contorno deseado, pero en una misiva, presuntamente escrita a David Gregory en 1694, Newton dio su solución.
En forma moderna, el problema de Newton es encontrar el valor mínimo de la integral
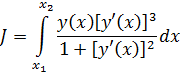
Figura 24.1
A pesar que Newton aplicó la idea de introducir un cambio en el contorno de la parte de meridiano y(x) , lo cual es casi igual a la esencia del método del cálculo de variaciones, su solución no es típica de la técnica del tema y por ello no la trataremos aquí. Puede ser de interés que las ecuaciones paramétricas de la y(x) adecuada son
![]()
donde p es el parámetro. Sobre este trabajo Newton dice: «Considero que esta proposición puede ser de utilidad en la construcción de barcos.» Los problemas de esta naturaleza han llegado a ser importantes no únicamente en el diseño de barcos, sino también de submarinos y de aeroplanos.
En el Acta Eruditorum de junio de 1696[240], Jean Bernoulli propuso como un reto a otros matemáticos el ahora famosa problema de la braquistócrona. El problema es determinar la trayectoria descendente al resbalar una partícula en el tiempo mínimo desde un punto dado a otro punto no directamente debajo.
Figura 24.2
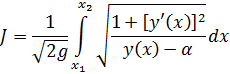
Newton, Leibniz, L'Hôpital, Jean Bernoulli y su hermano mayor Jacques encontraron la solución correcta: todas éstas fueron publicadas en el número de mayo de 1697 del Acta Eruditorum. Las soluciones de los dos Bernoulli merecen comentarios posteriores. El método de Jean[241] era ver que la trayectoria de descenso más rápido es la misma que la trayectoria de un rayo de luz en un medio con un índice de refracción adecuadamente seleccionado, n(x, y) = c/√(y α). La ley de la refracción en una discontinuidad brusca (ley de Snell) era conocida, de tal manera que Jean dividió el medio en un número finito de capas con un cambio súbito en el índice de capa a capa y más adelante hizo tender el número de capas al infinito. El método[242] de Jacques fue mucho más laborioso y geométrico, pero también más general y significó un paso más importante en dirección al método del cálculo de variaciones.
La cicloide era bien conocida a través del trabajo de Huygens y otros sobre el problema del péndulo (cap. 23, sec. 5). Cuando los hermanos Bernoulli encontraron que era también la solución para el problema de la braquistócrona, se sorprendieron. Jean Bernoulli dijo[243]: «Con justicia admiramos a Huygens porque fue el primero en descubrir que una partícula pesada recorre una cicloide en el mismo tiempo, sin importar cuál sea el punto de partida. Pero usted quedará sorprendido cuando yo diga que esta misma cicloide, la tautócrona de Huygens, es la braquistócrona que hemos estado buscando.»
Otra clase importante de problemas es el de las geodésicas, esto es, las trayectorias de longitud mínima entre dos puntos sobre una superficie. Si la superficie es un plano, entonces la integral es
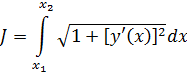
Analíticamente, los problemas hasta entonces formulados son de la forma
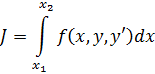
Aparte del trabajo de Zenodoro (cap. 5, sec. 7), no hubo prácticamente trabajos sobre problemas isoperimétricos hasta el final del siglo XVII . En un intento por retar y apenar a su hermano, Jacques Bernoulli propuso un problema isoperimétrico bastante complicado, que contenía varios casos, en el Acta Eruditorum de mayo de 1697[244]. Jacques aún ofreció a Jean un premio de cincuenta ducados por una solución satisfactoria. Jean dio varias soluciones, una de las cuales fue obtenida en 1701[245], pero todas eran incorrectas. Jacques proporcionó una solución correcta[246], y los hermanos pelearon sobre la veracidad de las soluciones del otro. De hecho, el método de Jacques, como en el caso del problema de la braquistócrona, fue un gran paso hacia la técnica general que pronto estaría en boga. En 1718, Jean[247] mejoró notablemente la solución de su hermano.
Analíticamente, el problema isoperimétrico básico está formulado así. Las curvas posibles se representan paramétricamente por
x = x(t), y = y(t), t1 ≤ t ≤ t2
y, ya que son curvas cerradas, x(t1) = x(t2) e y(t1) = y(t2). Más aún, ninguna curva se debe cortar a sí misma. Más adelante, el problema requiere determinar las x(t) e y(t) tales que la longitud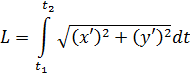
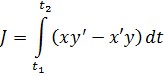
Figura 24.3
2. Los primeros trabajos de Euler
En 1728, Jean Bernoulli propuso a Euler el problema de obtener geodésicas sobre superficies aplicando la propiedad que los planos osculadores de las geodésicas cortan la superficie en ángulos rectos (cap. 23, sec. 7). Este problema inició a Euler en el cálculo de variaciones. Lo resolvió en 1728[248]. En 1734 Euler generalizó el problema de la braquistócrona para minimizar cantidades diferentes del tiempo, y tomando en cuenta un medio resistente[249].
Más adelante, Euler se propuso encontrar una aproximación más general a problemas en este terreno. Su método, que fue una simplificación del de Jacques Bernoulli, consistió en reemplazar la integral de un problema por una suma y reemplazar las derivadas en el integrando por cocientes diferenciales, haciendo de la integral una función de un número finito de ordenadas del arco y(x). Más adelante, varió una o más de las ordenadas seleccionadas arbitrariamente y calculó la variación en la integral. Igualando la variación de la integral a cero y usando un proceso de paso al límite muy tosco para transformar las ecuaciones en diferencias resultantes, obtuvo la ecuación diferencial que debía ser satisfecha por el arco minimizante.
Por el método descrito con anterioridad, aplicado a integrales de la forma
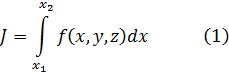
![]()
![]()
Después Euler atacó problemas más difíciles con condiciones de contorno especiales, como los problemas isoperimétricos, pero su procedimiento seguía siendo resolver la ecuación diferencial (3) para primero obtener los posibles arcos minimizantes o maximizantes y entonces determinar a partir del número de constantes en las soluciones generales de (2) o (3) qué condiciones adicionales podía aplicar. Daniel Bernoulli, en una carta de 1742, fue quien llamó su atención sobre uno de los problemas que atacó. Bernoulli propuso encontrar el contorno de una cuerda elástica sujeta a presión en ambos extremos al suponer que el cuadrado de la curvatura a lo largo de la curva con la varilla doblada, esto es,
![]()
La ecuación diferencial (3) no es la adecuada cuando los integrandos de las integrales minimizados o maximizados son más complicados que (1). En los años de 1736 a 1744, Euler mejoró sus métodos y obtuvo ecuaciones diferenciales análogas a (3) para un buen número de problemas. Estos resultados los publicó en un libro de 1744, Methodus Inveniendi Lineas Curvas Maximi Minimive Proprietate Gaudentes (El arte de encontrar líneas curvas que gozan de algunas propiedades máximas o mínimas)[251]. El trabajo de Euler en su Methodus fue pesado porque utilizó consideraciones geométricas,, diferencias sucesivas y series, y cambió derivadas por cocientes diferenciales e integrales en sumas finitas; en otras palabras, fracasó en hacer más eficaz el uso del cálculo. Pero acabó obteniendo fórmulas simples y elegantes aplicables a una gran variedad de problemas, empleando gran cantidad de ejemplos para mostrar la conveniencia y generalidad de su método. Un ejemplo se refiere a superficies mínimas de revolución. Aquí el problema es determinar la curva plana y=f(x) entre (x0, y0) y (x1, y1), de tal manera que cuando gira alrededor del eje x genera la superficie de área mínima. La integral que ha de ser minimizada es
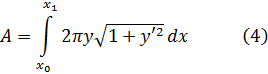
Con dicho trabajo, el cálculo de variaciones llegó a su existencia como una nueva rama de las matemáticas. Sin embargo, los argumentos geométricos fueron aplicados extensamente, y los argumentos analíticos y geométricos combinados no solamente resultaban complicados, sino que difícilmente proporcionaron un método general sistemático. Euler era completamente consciente de estas limitaciones.
3. El principio de mínima acción
Mientras que se progresaba en la solución de los problemas del cálculo de variaciones, una nueva motivación para trabajar en la materia llegó directamente de la física: este desarrollo contemporáneo fue el principio de acción mínima.

Figura 24.4
Basando sus asertos sobre este fenómeno de reflexión y en principios filosóficos, teológicos y estéticos, filósofos y científicos posteriores a los griegos propusieron la doctrina que la naturaleza actúa de la manera mínima, como Olimpiodoro (s. VI d.C.) dijo en su Catoptrica: «La naturaleza no hace algo superfluo ni cualquier trabajo innecesario.» Leonardo da Vinci afirmó que la naturaleza es económica y que su economía es cuantitativa, y Roberto Grosseteste creía que la naturaleza siempre actúa en la mejor, mínima y matemáticamente manera posible. En los tiempos medievales era aceptado comúnmente que la naturaleza se comportaba de esta manera.
Los científicos del siglo XVII fueron al menos receptivos a esta idea, pero, como científicos, intentaron acercarlo al fenómeno que lo apoyaba. Fermat sabía que bajo la reflexión la luz sigue la trayectoria que requiere el mínimo tiempo y, convencido de que la naturaleza actúa simple y económicamente, afirmó en misivas de 1657 y 1662[252] su principio de tiempo mínimo, el cual afirma que la luz siempre sigue la trayectoria que requiere el mínimo tiempo. Había dudado de la validez de la ley de la refracción de la luz (cap. 15, sec. 4), pero cuando encontró en 1661[253] que la podía deducir de su propio principio, no solamente resolvió sus dudas acerca de la ley, sino que sintió aún con mayor certeza que su principio era correcto.
El principio de Fermat se puede expresar matemáticamente en varias formas equivalentes. De acuerdo con la ley de refracción
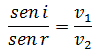
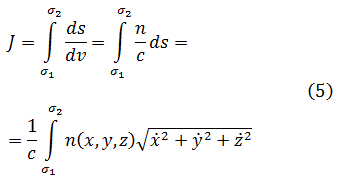
Al principio del siglo XVIII los matemáticos tenían varios ejemplos impresionantes del hecho de que la naturaleza intenta maximizar o minimizar ciertas cantidades importantes. Huygens, quien en un principio había objetado al principio de Fermat, demostró que funciona para la propagación de la luz en medios con índices variables de refracción. Incluso la primera ley del movimiento de Newton, que la línea recta o la distancia mínima es el movimiento natural de un cuerpo, mostró el deseo de economizar de la naturaleza. Estos ejemplos sugerían que podía haber algún principio más general. La búsqueda de tal principio fue realizada por Maupertuis.
Pierre-Louis Moreau de Maupertuis (1698-1759), mientras trabajaba en la teoría de la luz en 1744, propuso su famoso principio de acción mínima en su ensayo titulado «Accord des différentes lois de la nature qui avaient jusqu’ici paru incompatibles» («Acuerdo de las diferentes leyes de la naturaleza que hasta ahora parecían incompatibles»)[255]. Empezó por el principio de Fermat, pero debido a las diferencias en aquel tiempo sobre si la velocidad de la luz era proporcional al índice de refracción como creían Descartes y Newton, o inversamente proporcional como creía Fermat, Maupertuis abandonó el tiempo mínimo. De hecho, no creía que siempre fuera correcto.
La acción, decía Maupertuis, es la integral del producto de la masa, velocidad y distancia recorrida y cualesquiera cambios en la naturaleza son tales que hacen la acción mínima. Maupertuis fue algo vago, ya que fracasó en especificar el intervalo de tiempo sobre el cual el producto de m, v y s debía ser tomado y porque asignaba un significado diferente a la acción en cada una de las aplicaciones que hacía a la óptica y en algunos problemas de mecánica.
A pesar de que tenía algunos ejemplos físicos en los cuales apoyar su principio, Maupertuis lo defendía también por razones teológicas. Las leyes del comportamiento de la materia tenían que poseer la perfección que merecía la creación de Dios; y el principio de acción mínima parecía satisfacer este criterio porque mostraba que la naturaleza era económica. Maupertuis proclamó que su principio era una ley universal de la naturaleza y la primera prueba científica de la existencia de Dios. Euler, quien entre 1740 y 1744 había mantenido correspondencia con Maupertuis sobre este tema, coincidía con éste en que Dios debía haber construido el universo de acuerdo con algún principio básico y que la existencia de dicho principio evidenciaba la mano de Dios.
En el segundo apéndice de su libro de 1744, Euler formuló el principio de acción mínima como un teorema dinámico exacto. Se limitó al movimiento de una partícula individual moviéndose a lo largo de curvas planas. Más aún, suponía que la velocidad dependía de la posición o, en términos modernos, que la fuerza es derivable de un potencial. Mientras que Maupertuis escribía
mvs = mín.,
Euler escribió![]()
![]()
Euler fue más lejos que Maupertuis al creer que todos los fenómenos naturales se comportaban buscando maximizar o minimizar alguna función, de tal manera que los principios físicos básicos debían ser expresados como consecuencia de que alguna función sea maximizada o minimizada. En particular, esto debía ser cierto en la dinámica, que estudia los movimientos de los cuerpos propulsados por fuerzas. Euler no estaba muy lejos de la verdad.
4. La metodología de Lagrange
Lagrange, cuando sólo contaba diecinueve años, empezó a interesarse con Euler por problemas del cálculo de variaciones. Descartó los argumentos geométrico-analíticos de los Bernoulli y Euler e introdujo métodos puramente analíticos. En 1755 obtuvo un procedimiento general, sistemático y uniforme para una gran variedad de problemas, y trabajó en ellos por muchos años. Su más famosa publicación en esta materia fue su «Essai d’une nouvelle méthode pour déterminer les maxima et les minima des formules intégrales indéfinies» («Ensayo sobre un nuevo método para determinar los máximos y los mínimos de fórmulas integrales indefinidas»)[256]. En una carta a Euler de agosto de 1755, describió su método, al que llamó el método de variaciones, pero que Euler presentó en un ensayo a la Academia de Berlín en 1756[257] llamándolo cálculo de variaciones.
Veamos el método de Lagrange para el problema básico del cálculo de variaciones, es decir, minimizar o maximizar la integral
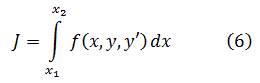
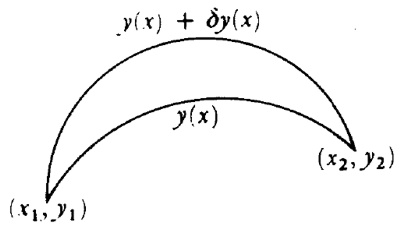
Figura 24.5
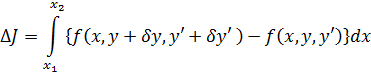
![]()
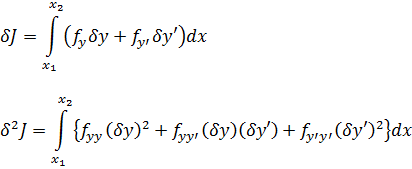
Lagrange argumenta ahora que el valor de δJ, ya que contiene los términos de primer orden en las pequeñas variaciones δy y δy', domina en el lado derecho de (7), de tal manera que cuando δJ es positivo o negativo, ΔJ será positivo o negativo. Pero en el máximo o mínimo de J, ΔJ debe tener el mismo signo, como en el caso de máximos y mínimos ordinarios de una función f(x) de una variable, de tal forma que para que y(x) sea una función maximizante, δJ debe ser 0. Más aún, Lagrange dice que
![]()
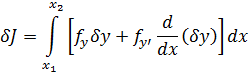
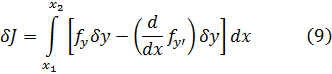
Ahora δJ debe ser 0 para toda variación δy. De aquí Lagrange concluye que el coeficiente de δy debe ser 0,[258] o que
![]()
En este ensayo de 1760-61, Lagrange dedujo también, por primera vez, condiciones finales que deben ser satisfechas por una curva minimizadora para problemas con puntos finales variables. Encontró las condiciones de transversalidad que deben cumplirse en las intersecciones de la curva minimizadora con las curvas fijas, o superficies, sobre las cuales los puntos finales de las curvas de comparación pueden variar (fig. 24.6).
Figura 24.6
![]()
Figura 24.7
Por un método similar al que había usado para la integral simple (6), Lagrange obtuvo la ecuación diferencial que la función z(x, y)minimizadora de (11) debía satisfacer. Si usamos la notación habitual
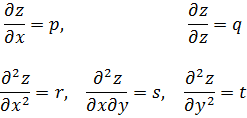
Rr + Sc + Tt = U (12)
donde R, S, T y U son funciones de x, y, z, p y q. Esta ecuación diferencial parcial de segundo orden no lineal, llamada ecuación de Monge, no es fácil de resolver; ecuaciones de este tipo han sido materia de investigación desde la época de Euler hasta hoy (cap. 22, sec. 7).En el caso del problema de la superficie mínima, la integral (1) se convierte en
![]()
![]()
Lagrange, en un ensayo posterior (1770)[261], también consideró integrales simples y múltiples en las cuales aparecen en el integrando derivadas superiores a las primeras. Este tema ha sido bien desarrollado desde los tiempos de Lagrange y es hoy material común en el cálculo de variaciones. Sin embargo, ya que los principios no son básicamente diferentes de los casos considerados con anterioridad, no nos iremos hacia este tema. En su Mécanique analytique (Mecánica analítica) se incorporan los contenidos de los ensayos sobre el cálculo de variaciones.
El cálculo de variaciones no fue muy bien entendido por los contemporáneos de Lagrange y Euler. Este explicó el método de Lagrange en numerosos escritos y lo usó para probar de nuevo un buen número de viejos resultados. A pesar de haberse percatado de que el cálculo de variaciones era una nueva rama o técnica, de la cual dice que está representada por el nuevo símbolo operacional δ, Euler, al igual que Lagrange, intentó basar la lógica del cálculo de variaciones en el cálculo ordinario. La idea de Euler [262] fue introducir un parámetro t tal que las curvas de la familia consideradas en un problema de variaciones variaría con t, esto es, para cada t en algún rango habría una curva y(x). Entonces, dice Euler, mientras que dy = (dy/dx)dx, δy = (dy/dt)dt. De aquí que la variación δ sea expresable por una derivada parcial con respecto a t. Más adelante formuló la técnica del cálculo de variaciones en términos de su nuevo concepto de diferenciación con respecto a t. Sus resultados finales fueron, por supuesto, los mismos que ya había obtenido.
Euler, durante 1779[263], consideró curvas espaciales con propiedades de máximo y mínimo y, en 1780, extensiones del problema de la braquistócrona cuando la fuerza aplicada (la cual es la gravedad en el problema usual) opera en tres dimensiones, o cuando está presente un medio resistente[264].
5. Lagrange y la mínima acción
Lagrange aplicó el cálculo de variaciones a la dinámica. Tomó de Euler el principio de la acción mínima, siendo el primero en expresar el principio en forma correcta, es decir, que para una partícula individual la integral del producto de la masa, velocidad y distancia tomada entre dos puntos fijos es un máximo o un mínimo; esto es, ∫ mv ds debe ser un máximo o un mínimo para la trayectoria que de hecho sigue la partícula. De forma alternativa, ya que ds = v dt, entonces ∫mv2 dt debe ser máximo o mínimo. La cantidad mv2 [hoy en día ½ mv2] es llamada energía cinética; en los días de Lagrange era llamada fuerza viva. Lagrange también afirmó que el principio es cierto para una colección de partículas y aun para masas extensas, aunque no tenía mucha seguridad en esto último.
Usando el principio de mínima acción y el método del cálculo de variaciones, Lagrange obtuvo sus famosas ecuaciones del movimiento. Consideremos el caso donde la energía cinética es una función de x, y y z. Entonces para una partícula individual la energía cinética T está dada por
![]()
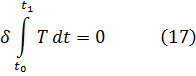
Aplicando el método del cálculo de variaciones a la integral de acción, Lagrange derivó ecuaciones análogas a las ecuaciones (2) de Euler, a saber,
![]()
Lagrange realizó el paso adelante siguiente de introducir las que ahora son llamadas coordenadas generalizadas. Esto es, en lugar de coordenadas rectangulares uno puede usar coordenadas polares o, de hecho, cualquier conjunto de coordenadas q1,q2, q3, que son necesarias para fijar la posición de la partícula (o masa extensa). Entonces
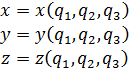
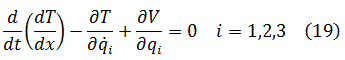
Estas coordenadas generalizadas no tienen necesariamente un significado geométrico o físico. Hoy en día, uno habla de ellas como coordenadas de un espacio de configuración y entonces las qi(t) son las ecuaciones de una trayectoria en el espacio de configuración. Así, Lagrange reconoció que el principio variacional, esto es, que la acción debe ser un mínimo o un máximo, puede ser usado con cualquier conjunto de coordenadas y las ecuaciones lagrangianas del movimiento (19) son invariantes en su forma con respecto a cualquier transformación de coordenadas.
El principio de Lagrange, no obstante equivaler a la segunda ley del movimiento de Newton, tiene varias ventajas sobre la formulación de Newton. Ante todo, cualquier sistema coordenado conveniente ya está, por así decirlo, construido en la formulación. Segundo, es más fácil manejar problemas con restricciones en el movimiento. Tercero, en lugar de una serie de ecuaciones diferenciales separadas, que podrían ser muy numerosas si se consideran muchas partículas, hay —para empezar, al menos— un principio del cual se siguen las ecuaciones diferenciales. Finalmente, a pesar de que su principio supone el conocimiento de las energías cinética y potencial de un problema, no requiere el conocimiento de las fuerzas que actúan. Con su principio, Lagrange dedujo leyes básicas para la mecánica y solucionó muchos problemas nuevos, aunque no era lo suficientemente amplio como para incluir todos los problemas de que se ocupa la dinámica. Su trabajo sobre el principio de acción está completamente discutido en su Mécanique analytique\ también inició el movimiento para deducir las leyes de otras ramas de la física de principios variacionales análogos al de acción mínima. El mismo proporcionó un principio variacional para una clase más general de problemas hidrodinámicos. Este tema lo retomaremos en nuestro estudio de la aportación del siglo XIX.
Desde el punto de vista matemático, el trabajo de Lagrange sobre la acción mínima dio la mayor relevancia al cálculo de variaciones. En particular, Lagrange había derivado las ecuaciones de Euler para una integral cuyo integrando contiene una variable independiente pero varias variables dependientes y sus derivadas. Se trata de una extensión del cálculo original del problema de variaciones, el cual contiene únicamente una variable dependiente y su derivada. En este caso más general, las ecuaciones de Euler son un sistema de ecuaciones diferenciales de segundo orden en las qi.
6. La segunda variación
La ecuación diferencial de Euler, como pensaron éste y Lagrange, es únicamente una condición necesaria de la solución para dar un máximo o un mínimo. Ellos aplicaron la ecuación diferencial a fin de encontrar la solución y entonces especularon sobre bases intuitivas o físicas si daba un máximo o un mínimo. El papel de la ecuación de Euler es del todo análogo a la condición f '(x) = 0 en el cálculo ordinario. Un valor de x que maximiza o minimiza y = f(x)debe satisfacer f' (x) = 0, pero el recíproco no necesariamente es verdadero.
La pregunta de qué condiciones adicionales debe satisfacer una solución de la ecuación de Euler para suministrar de hecho un valor máximo o mínimo de una integral, dependiendo de la y(x), fue atacado sin éxito en 1782 por Laplace y retomado por Legendre en 1786[266]. Guiado por el hecho que en el cálculo ordinario el signo de f"(x) en un valor x para el cual f'(x ) = 0 determina si f(x) tiene un máximo o un mínimo, Legendre consideró la segunda variación δ2J, remodelada su forma, y concluyó que J es un máximo para la curva y(x) que satisface la ecuación de Euler y pasa por (x0, y0) y (x1, y1) con tal que fy'y' ≤ 0 en cada x a lo largo de y(x). Del mismo modo, J es un mínimo para una y(x) satisfaciendo las primeras dos condiciones siempre que fy'y' ≥ 0 en cada x a lo largo de y(x). Más adelante, Legendre extendió este resultado a integrales más generales que (6). Sin embargo, Legendre se dio cuenta en 1787 que la condición sobre fy'y' era únicamente una condición necesaria sobre y(x) para que sea una curva maximizante o minimizante. El problema de encontrar condiciones suficientes de que una curva y(x) maximice o minimice una integral tal como (6) no fue resuelto en el siglo XVIII.
Bibliografía
- Bernoulli, Jacques: Opera, 2 vols. 1744, reimpreso por Birkhauser, 1968.
- Bernoulli, Jean: Opera Omnia, 4 vols., 1742, Georg Olms (reimpreso), 1968.
- Bliss, Gilbert A.: The Cálenlas of Variations, Open Court, 1925. —: «The Evolution of Problems in the Calculus of Variations», Amer. Math. Monthly, 43, 1936, 598-609.
- Cantor, Moritz: Vorlesungen über Geschichte der Mathematik, B. G. Teubner, 1898 y 1924, vol. 3, cap. 117, y vol. 4, 1066-1074.
- Caratheodory, C.: Introducción a las Series (1), vol. 24 de la Opera Omnia de Euler, viii-lxii, Orell Fussli, 1952. También en C. Caratheodory: Gesammelte mathematische Schriften, C. H. Beck, 1957, vol. 5, pp. 107-174.
- Darboux, Gastón: Leçons sur la théorie générale des surfaces, 2.a ed., Gauthier-Villars, 1914, vol. 1, libro III, caps. 1-2.
- Euler, Leonhard: Opera Omnia, (1), vols. 24-25, Orell Fussli, 1952.
- Hofmann, Joseph E.: «Über Jakob Bernoullis Beitráge zur InfinitesimalmatheMatik», L'Enseignement mathématique, (2), 2, 1956, 61-171; publicado por separado por el Institut de Mathématiques, Ginebra, 1957.
- Huke, Aliñe: An Historical and Critical Study of the Fundamental Lemma in the Calculus of Variations, University of Chicago Contributions to the Calculus of Variations, Chicago University Press, vol. 1, 1930, pp. 45-160.
- Lagrange, Joseph Louis: Œuvres de Lagrange, Gauthiers-Villars, 1867-69, ensayos relevantes en los volúmenes 1 a 3. —: Mécanique analytique, 2 vols, 4.a ed. Gauthier-Villars, 1889.
- Lecat, Maurice: Bibliographie du calcul des variations depuis les origines jusqu’d 1850, Gante, 1916.
- Montucla, J. F.: Histoire des mathématiques, 1802, Albert Blanchard (reimpresión), 1960, vol. 3, 643-658.
- Porter, Thomas Isaac: «A History of the Classical Isoperimetric Problem», University of Chicago Contributions to the Calculus of Variations, Chicago University Press, 1933, vol. 2, 475-517.
- Smith, David E.: A Source Book in Mathematics, Dover (reimpresión), 1959, pp. 644-655.
- Struik, D. J.: A Source Book in Mathematics (1200-1800), Harvard Unviersity Press, 1969, pp. 391-413.
- Todhunter, Isaac: A History of the Calculus of Variations during the Nineteenth Century, 1861, Chelsea (reimpresión), 1962.
- Woodhouse, Robert: A History of the Calculus of Variations in the Eighteenth Century, 1810, Chelsea (reimpresión), 1964.
Capítulo 25
El algebra del siglo XVIII
Yo presento el análisis superior como se encontraba en su niñez, pero usted lo está llevando a su madurez.
JEAN BERNOULLI, en una carta a Euler
1. La situación de los números1. La situación de los números
2. La teoría de ecuaciones
3. Determinantes y teoría de la eliminación
4. La teoría de números
Bibliografía
El significado del concepto de límite en el siglo XVIII era aún oscuro y difícilmente se distinguía entre álgebra y análisis, por lo que, en nuestro actual enfoque, sería conveniente separar estos dos campos de actividades. En el siglo XVII , el álgebra fue un centro importante de interés; en el XVIII se convirtió en algo subordinado al análisis; exceptuando la teoría de números, la motivación para trabajar en ella vino en gran parte del análisis.
Ya que la base del álgebra es el sistema numérico, describamos el estado de esta materia. En 1700 todos los miembros familiares del sistema —números enteros, fraccionarios, irracionales, y números negativos y complejos— eran conocidos. Sin embargo, la oposición hacia los tipos más nuevos se manifestó a lo largo del siglo. Típicas son las objeciones del matemático inglés barón Francis Maseres (1731-1824), miembro del Clare College en Cambridge y miembro de la Royal Society. Maseres, quien escribió ensayos aceptables en matemáticas y un tratado sustancial sobre la teoría de seguros de vida, publicó en 1759 su Dissertation on the Use of the Negative Sign in Algebra (Disertación sobre el uso del signo negativo en álgebra), donde muestra cómo evitar los números negativos (excepto para indicar la sustracción de una cantidad mayor de una menor), y en particular las raíces negativas, mediante la cuidadosa segregación de tipos de ecuaciones cuadráticas de tal forma que aquellas con raíces negativas son consideradas separadamente; y, por supuesto, las raíces negativas deben ser rechazadas. El hace lo mismo con las cúbicas. Más adelante dice de las raíces negativas:
[...] sirven únicamente, en lo que yo puedo juzgar, para confundir toda la doctrina de ecuaciones y para volver en cosas oscuras y misteriosas las que son en su propia naturaleza excesivamente simples y ordinarias [...]. Se debería desear, por lo tanto, que las raíces negativas nunca hubieran sido admitidas dentro del álgebra o que fueran, de nuevo, descartadas de ella; ya que, si esto fuera hecho, hay razón de sobra para imaginar que las objeciones que muchos hombres cultos e ingeniosos ahora hacen de los cómputos algebraicos, como ser oscurecidos y confundidos con nociones casi ininteligibles, serían por consiguiente suprimidas; siendo inevitable que el álgebra o la aritmética universal es, por su propia naturaleza, una ciencia no menos simple, clara y capaz de demostración que la geometría.Ciertamente, los números negativos no fueron realmente bien comprendidos hasta los tiempos modernos, Euler, en la última mitad del siglo XVIII, aún creía que los números negativos eran mayores que el ∞. También discutió que (1) × (1)= 1 porque el producto debe ser +1 o -1 y ya que 1 × (-1) = -1, entonces (1) × (1) = + 1. Carnot, el famoso geómetra francés, pensó que el uso de números negativos llevaba a conclusiones erróneas. Tan tarde como 1831, Augustus De Morgan (1805-710), profesor de matemáticas en el University College de Londres, famoso matemático y con trabajos en álgebra, en su On the Study and Difficulties of Mathematics (Sobre el estudio y dificultades de las matemáticas) dijo: «La expresión imaginaria √-a y la expresión negativa -b tienen este parecido: que cualquiera de ellas, cuando aparece como solución de un problema, indica alguna inconsistencia o absurdo. En cuanto se refiere al significado real, ambas son igualmente imaginarias, ya que 0 a es tan inconcebible como √-a.»
De Morgan ilustró esto por medio de un problema. Un padre tiene cincuenta y seis años; su hijo, veintinueve. ¿Cuándo será el padre el doble de viejo que su hijo? El resuelve 56 + x = 2(29 + x) y obtiene x = -2. Así el resultado, dice, es absurdo. Pero, continúa, si cambiamos x por -x y solucionamos 56 x = 2(29 x), obtenemos x = 2. Concluye que expresamos el problema original equivocadamente y fuimos, por tanto, conducidos a una respuesta inaceptable negativa. De Morgan insistió en que era absurdo considerar número menores que cero.
A pesar de que en el siglo XVIII no se hizo nada por aclarar el concepto de número irracional, hubo cierto progreso en esta materia. En 1737, Euler mostró, sustancialmente, que e y e2 eran irracionales y Lambert mostró que π es irracional (cap. 20, sec. 6). El trabajo sobre la irracionalidad de n estuvo motivado en gran parte por el deseo de resolver el problema de la cuadratura del círculo. La conjetura de Legendre de que π podría no ser la raíz de una ecuación algebraica con coeficientes racionales, llevó a la distinción entre tipos de irracionales. Cualquier raíz, real o compleja, de cualquier ecuación algebraica (polinomial) con coeficientes racionales es llamada número algebraico. Así que a las raíces de
a0xn + a1xn-1 +…+ an-1x + an = 0,
donde los son números racionales se les llama números algebraicos. Consecuentemente, todo número racional y algunos irracionales son números algebraicos, ya que cualquier número racional c es la raíz de xc = 0 y √2 es una raíz de x2 2 = 0. Aquellos números que no son algebraicos se denominan trascendentes porque, como indicó Euler, «ellos trascienden el poderío de los métodos algebraicos». Esta distinción entre números algebraicos y trascendentales, al menos ya era reconocida por Euler en fechas tan tempranas como 1744. Euler conjeturó que el logaritmo de una base racional debía ser racional o trascendente. Sin embargo, ningún número trascendente era conocido en el siglo XVIII y el problema de mostrar que había números trascendentes permanecía abierto.Los números complejos eran más que un veneno para los matemáticos del siglo XVIII. De Cardano hasta cerca de 1700, prácticamente se ignoró estos números. Entonces (cap. 19, sec. 3), los números complejos se utilizaron para hallar integrales por el método de descomposición en fracciones, al cual siguió una extensa controversia acerca de números complejos y los logaritmos de números negativos y complejos. A pesar de la correcta resolución del problema de los logaritmos de los números complejos, ni Euler ni otros matemáticos tenían ideas claras sobre tales números.
Euler intentó comprender lo que son realmente los números complejos, y en su Vollstandige Anleitung zur Algebra (Introducción completa al álgebra), que primero apareció en ruso en 1768-69 y en alemán en 1770, y que es el mejor texto de álgebra del siglo XVIII, dice:
[...]. Porque todos los números concebibles, o son mayores que cero o menores que cero o iguales a cero, entonces es claro que las raíces cuadradas de números negativos no pueden estar incluidas entre los posibles números [números reales]. Consecuentemente, debemos decir que éstos son números imposibles. Y dicha circunstancia nos lleva al concepto de tales números, los cuales por su naturaleza son imposibles, y ordinariamente son llamados números imaginarios o fantasiosos, ya que sólo existen en la imaginación.Euler cometió errores con los números complejos. En su Algebra escribe √-1 × √-4 = √4 = 2, ya que √a×√b = √ab. También da ii = 0,2078795763, pero olvida los otros valores de esta cantidad. Este número lo proporcionó originalmente en una carta a Goldbach de 1746 y también en su ensayo de 1749 sobre la controversia entre Leibniz y Jean Bernoulli (cap. 19, sec. 3). A pesar de que llama a los números complejos números imposibles, Euler dice que pueden usarse cuando atacamos problemas acerca de los cuales ignoramos si tienen o no una respuesta. De este modo, si preguntamos cómo separar 12 en dos partes cuyo producto sea 40, deberíamos encontrar que las partes son 6 + √-4 y 6 √-4. Por lo que, dice, reconocemos que este problema no puede ser resuelto.
Fueron realizados algunos pasos positivos más allá de la correcta conclusión de Euler sobre los logaritmos de números complejos, pero su influencia en el siglo XVIII fue limitada. En su Algebra (1685, caps. 66-69), John Wallis mostró cómo representar geométricamente las raíces complejas de una ecuación cuadrática con coeficientes reales. Wallis dijo, en efecto, que los números complejos no son más absurdos que los números negativos; y si estos últimos pueden ser representados en una línea recta, entonces es posible representar los números complejos en un plano. Empezó con un eje sobre el cual los números reales fueron marcados en relación con un origen; una distancia a partir de este origen a lo largo del eje representaba la parte real de la raíz, siendo medida la distancia en la dirección positiva o negativa del eje según si dicho número era positivo o negativo. Desde el punto sobre el eje de los reales así determinado, era trazada una línea perpendicular al eje de los reales cuya longitud representaba el número que, multiplicado por √-1, proporcionaba la parte imaginaria de la raíz, siendo la línea trazada en una dirección o la opuesta dependiendo si el número era positivo o negativo. (Fracasó al introducir el mismo eje y como el eje de los imaginarios.) Wallis procedió entonces a dar una construcción geométrica de las raíces de ax2 + bx + c = 0 cuando las raíces son reales y cuando son complejas. Su trabajo fue correcto, pero no fue una representación útil de x + iy con otros propósitos. Hubo otros intentos para representar los números complejos geométricamente en el siglo XVIII, pero no fueron demasiado útiles. Tampoco las representaciones geométricas de este tiempo hicieron a los números complejos más aceptables.
En la parte inicial del siglo, los matemáticos pensaban que las raíces diferentes de los números complejos introducirían tipos diferentes (u órdenes) de números complejos y que podía haber raíces ideales cuya naturaleza no podían especificar pero que de alguna manera podían ser calculadas. Pero D’Alembert, en su trabajo premiado Réflexions sur la cause générale des vents (Reflexiones sobre la causa general de los vientos, 1747), afirmó que cada expresión construida sobre los números complejos por medio de operaciones algebraicas (en las cuales incluyó elevarlos a una potencia arbitraria) es un número complejo de la forma A + B √-1. La gran dificultad que encontró para probar esta aserción fue el caso de (a + bi)g+hl. Su demostración de este hecho tuvo que ser enmendada por Euler, Lagrange y otros. En su Encyclopédie, D’Alembert mantuvo un silencio discreto acerca de los números complejos.
A lo largo de todo el siglo XVIII, los números complejos fueron usados de una manera lo suficientemente efectiva por los matemáticos como para adquirir cierta confianza en ellos (cap. 19, sec. 3; cap. 27, sec. 2). Cuando, usados en estados intermedios de los argumentos matemáticos, los resultados fueron correctos, este hecho tuvo un efecto notable. Aun así, había dudas en cuanto a la validez de los argumentos y frecuentemente también de los resultados.
En 1799, Gauss dio la primera prueba del teorema fundamental del álgebra y, como dependía esencialmente del reconocimiento de los números complejos, éste fortaleció la posición de estos números. El siglo XIX se precipitó entonces hacia adelante ciegamente con las funciones complejas. Pero aún mucho más tarde de que esta teoría fuese desarrollada y empleada en hidrodinámica, los profesores de Cambridge conservaron «una repulsión invisible a la objetable √-1, y complicados utensilios fueron adoptados para evitar su aparición o uso siempre que fuera posible».
La actitud general hacia los números complejos, incluso hasta 1831, puede verse en el libro de De Morgan On the Study and Difficulties of Mathematics (Sobre el estudio y las dificultades de las matemáticas). De Morgan comenta que este libro no contiene nada que no pueda ser encontrado en los mejores trabajos de entonces en Oxford y Cambridge. Volviendo a los números complejos, dice:
[...] hemos mostrado que el símbolo √-a carece de significado, o mejor es autocontradictorio y absurdo. Sin embargo, por medio de tales símbolos, se establece una parte del álgebra que es de gran utilidad. Ello depende del hecho, que debe ser verificado por la experiencia, de que las reglas comunes del álgebra pueden ser aplicadas a estas expresiones [números complejos] sin llevarnos a resultados falsos. Una llamada a la experiencia de esta naturaleza parece ser contraria a los primeros principios establecidos al comienzo del presente trabajo. Nosotros no podemos negar que así sea en la realidad, pero debe ser recordado que ésta no es más que una parte pequeña y aislada de una materia inmensa, en todas las demás ramas de la cual se aplican sus principios en toda su extensión.Los «principios» a los que se refiere son que las verdades matemáticas deben ser deducidas a partir de axiomas por medio del método deductivo.
Más adelante compara las raíces negativas con las raíces complejas.
Existe, entonces, esta diferencia distintiva entre los resultados negativos y los imaginarios. Cuando la respuesta a un problema es negativa, cambiando el signo de x en la ecuación que produjo el resultado, podemos o descubrir un error en el método de formación de la ecuación o mostrar que la cuestión del problema es demasiado limitada, y que puede ser extendida hasta admitir una respuesta satisfactoria. Cuando la respuesta a un problema es imaginaria éste no es el caso [...]. Nosotros debemos abocarnos a detener el progreso del estudiante entrando en todos los argumentos en pro y en contra de tales cuestiones, como el uso de cantidades negativas, etc., las cuales no podía él entender, y que son inconclusas en ambos sentidos; pero se le puede advertir que existe una dificultad, la naturaleza de la cual se le debe señalar, y entonces tal vez pueda, tomando en cuenta un número suficiente de ejemplos, tratados por separado, adquirir confianza en los resultados a los cuales llevan las reglas.Para cuando De Morgan escribió estas líneas, los conceptos de número complejo y función compleja estaban en el camino correcto para su clarificación. Pero la difusión del nuevo conocimiento era lenta. Ciertamente, a lo largo del siglo XVIII y la primera parte del XIX, el significado de los números complejos fue discutido con énfasis. Todos los argumentos de Jean Bernoulli, D’Alembert y Euler estuvieron continuamente sujetos a discusión. Aun los libros de texto del siglo XX sobre trigonometría proporcionaron presentaciones que empleaban los números complejos con pruebas que evitaban √-1.
También debemos notar aquí otra cuestión cuya significación está casi en proporción inversa a la concisión con la que puede ser establecida: en el siglo XVIII nadie se preocupó por la lógica de los sistemas de números reales o complejos. Lo que Euclides había hecho en el libro quinto de los Elementos para establecer las propiedades de las magnitudes inconmensurables fue evitado. El que esta exposición hubiera estado ligada a la geometría, mientras que ahora la aritmética y el álgebra eran independientes de la geometría, explica en parte su abandono. Más aún, este desarrollo lógico, aunque fuera modificado para liberarlo de la geometría, no podía establecer los fundamentos lógicos de los números negativos y complejos; y, también, este hecho pudo haber causado que los matemáticos desistieran de cualquier intento por fundamentar rigurosamente el sistema numérico. Finalmente, el siglo dedicaba su interés al uso de las matemáticas en las ciencias, y como las reglas de operación eran intuitivamente seguras, al menos para los números reales, nadie se preocupó realmente por los fundamentos. Típico es el argumento de D’Alembert en su ensayo sobre números negativos en la Encyclopédie. El ensayo no es del todo claro y D’Alembert concluye que «las reglas algebraicas de operación con números negativos son admitidas generalmente por todos y reconocidas como exactas, cualquiera que sea la idea que tengamos sobre estas cantidades». Los diversos tipos de números, nunca introducidos adecuadamente en el mundo, ganaron sin embargo un lugar firme en la comunidad matemática de ese siglo.
2. La teoría de ecuaciones
Una de las investigaciones que continuó a partir del siglo XVII , acaso con una ligera interrupción, fue la solución de ecuaciones polinómicas. El tema es fundamental en matemáticas y de igual manera el interés por obtener mejores métodos para resolver ecuaciones de cualquier grado, obteniendo mejores métodos para aproximar las raíces de ecuaciones, y el completar la teoría resultaba natural —en particular, demostrando que cualquier ecuación polinómica de grado n-ésimo tiene n raíces. Además, el uso del método de descomposición en fracciones para la integración originó la cuestión de si cualquier polinomio con coeficientes reales podía ser descompuesto en un producto de factores lineales o un producto de un factor lineal y otro cuadrático con coeficientes reales, para evitar el uso de números complejos.
Como vimos en el capítulo 19 (sec. 4), Leibniz no creía que cualquier polinomio con coeficientes reales podía ser descompuesto en factores lineales y cuadráticos con coeficientes reales. Euler tomó la postura correcta. En una carta a Nicolás Bernoulli (1687-1759) del 10 de octubre de 1742, Euler afirmó, sin dar una demostración, que un polinomio de grado arbitrario con coeficientes reales se podía expresar de esa manera. Nicolás no creyó que la aserción fuera correcta y dio un ejemplo
x4 4x3 + 2x2 + 4x +4
con los ceros![]()
El meollo del problema de factorizar un polinomio real en factores lineales y cuadráticos con coeficientes reales era probar que cada polinomio tenía al menos una raíz real o compleja. La prueba de este hecho, llamado teorema fundamental del álgebra, se convirtió en una finalidad primordial.
Las pruebas ofrecidas por D’Alembert y Euler fueron incompletas. En 1772[267] Lagrange, con un argumento largo y detallado, «completó» la prueba de Euler. Pero Lagrange, al igual que Euler y sus contemporáneos, aplicaron libremente las propiedades ordinarias de los números a lo que supuestamente eran las raíces, sin establecer que las raíces, en el peor de los casos, debían ser números complejos. Debido a que la naturaleza de las raíces era desconocida, la prueba, de hecho, también era incompleta.
La primera demostración sustancial del teorema fundamental, pero no aceptable para los niveles modernos de rigor, fue dada por Gauss en su tesis doctoral de 1799, en Helmstadt[268]. En este texto critica los trabajos de D’Alembert, Euler y Lagrange y ofrece su propia prueba. El método de Gauss no fue calcular una raíz, sino demostrar su existencia. Gauss señalaba que las raíces complejas a + ib de P(x + iy) = 0 corresponden a puntos (a, b) del plano y si P(x+ iy) = u(x, y) + iv(x, y), entonces (a, b) debe ser la intersección de las curvas u = 0 y v = 0. Mediante un estudio cualitativo de las curvas, muestra que un arco continuo de una une puntos de dos regiones distintas separadas por la otra. Entonces, la curva u = 0 debe cortar a la curva v = 0. El argumento era altamente original. Sin embargo, dependía de las gráficas de estas curvas, que eran algo complicadas, para mostrar que debían cruzarse. En este mismo ensayo, mostró que un polinomio de grado n-ésimo podía ser expresado como el producto de factores lineales y cuadráticos con coeficientes reales.
Gauss dio tres pruebas más del teorema. En la segunda prueba[269] evitó el uso de argumentos geométricos. Aquí también demostró que el producto de las diferencias de cada dos raíces (las que nosotros, siguiendo a Sylvester, llamamos el discriminante) puede ser expresado como una combinación lineal del polinomio y de su derivada, de tal manera que una condición necesaria y suficiente para que el polinomio y su derivada tengan una raíz común es que el discriminante se anule. Sin embargo, esta segunda prueba suponía que un polinomio no puede cambiar de signo entre dos valores diferentes de x sin anularse entre ellos. La prueba de este hecho iba más allá del rigor de aquella época.
La tercera prueba[270] aplica de hecho lo que llamamos el teorema de la integral de Cauchy (cap. 27, sec. 4)[271]. La cuarta prueba[272] es una variación de la primera en cuanto se refiere al método. Sin embargo, en esta demostración Gauss usa números complejos con mayor libertad porque —como dice— ahora son de conocimiento común. Vale la pena notar que el teorema no se demostraba en toda su generalidad en muchas pruebas. Las primeras tres pruebas de Gauss y demostraciones posteriores de Cauchy, Jacobi y Abel supusieron que los coeficientes (literales) representaban números reales, mientras que el teorema en su totalidad incluye el caso de los coeficientes complejos. La cuarta demostración de Gauss sí permitía que los coeficientes del polinomio fueran números complejos.
El método de Gauss para el teorema fundamental del álgebra inauguró un nuevo acercamiento a la cuestión de la existencia matemática. Los griegos, sabiamente, habían reconocido que la existencia de las entidades matemáticas debía ser establecida aún antes que los teoremas acerca de ellas pudieran ser obtenidos. Su criterio de existencia era la constructibilidad. En el trabajo formal más explícito de los siglos posteriores, la existencia se establecía obteniendo o estableciendo la cantidad en cuestión. Por ejemplo, la existencia de solución de la ecuación cuadrática queda establecida al mostrar cantidades que satisfacen la ecuación. Pero en el caso de ecuaciones de grado superior a cuatro, este método no puede usarse. Por supuesto, una prueba de existencia tal como la de Gauss puede no ser una ayuda al calcular el objeto cuya existencia está siendo establecida.
Mientras se abría camino al trabajo que finalmente mostró cómo toda ecuación polinómica con coeficientes reales tiene una raíz, los matemáticos también luchaban para resolver ecuaciones de grado superior a cuatro usando procesos algebraicos. Leibniz y su amigo Tschirnhausen fueron los primeros en hacer serios esfuerzos. Leibniz[273] reconsideró el caso irreducible de la ecuación de tercer grado y se convenció de que no podía evitarse el uso de números complejos para resolver este caso. Entonces atacó la solución de la ecuación de quinto grado, pero sin éxito. Tschirnhausen[274] pensó que él había resuelto este problema al transformar la ecuación dada en una nueva por medio de una transformación y = P(x), donde P(x) es un polinomio adecuado de cuarto grado.
Esta transformación eliminó todas las potencias menos la x5 y los términos constantes de la ecuación. Pero Leibniz mostró que para determinar los coeficientes de P(x) había que resolver ecuaciones de grado superior a cinco, por lo que el método resultaba inútil.
Por un tiempo, el problema de hallar la solución de la ecuación de grado n-ésimo se centró en el caso especial xn 1 = 0, llamado ecuación binomial. Cotes y De Moivre mostraron, usando números complejos, que la solución de este problema se reduce a la división de la circunferencia de un círculo en n partes iguales. Para obtener las raíces por radicales (las soluciones trigonométricas no son necesariamente algebraicas) es suficiente considerar el caso de n primo impar, ya que si n = pm, donde p es primo, entonces se puede considerar (xm)p 1= 0. Si esta ecuación puede ser resuelta para xm, entonces se considera xmA, donde A es cualquiera de las raíces de la ecuación precedente. Alexandre Théophile Vandermonde (1735-96) afirmó en su ensayo de 1771[275] que toda ecuación de la forma xn 1 = 0, donde n es primo, es soluble por radicales. Sin embargo, Vandermonde únicamente verificó que esto es así para valores de n hasta 11. El trabajo decisivo en ecuaciones binominales fue hecho por Gauss (cap. 31, sec. 2).
El mayor esfuerzo hacia la solución de ecuaciones de grado superior a 4 se concentró en la ecuación general y, con este fin, cierto trabajo subsidiario sobre funciones simétricas resultó ser importante. La expresión x1x2 + x2x3 + x3x1 es una función simétrica de x1, x2 y x3, ya que el reemplazo de cualquier xi por una xj y xj por xi deja la expresión inalterada por completo. El interés por funciones simétricas surgió cuando los algebristas del siglo XVII notaron que Newton probó que las diversas sumas de los productos de las raíces de una ecuación polinomial pueden ser expresados en términos de los coeficientes. Por ejemplo, para n = 3, la suma de los productos tomados dos a dos,
a1a2 + a2a3 + a3a1
es una función simétrica elemental; y si la ecuación es escrita comox3c1x2 + c2x c3 = 0,
la suma es igual a c2. El progreso hecho en el ensayo de 1771 de Vandermonde fue mostrar que cualquier función simétrica de las raíces es posible expresarla en términos de los coeficientes de la ecuación.El trabajo sobresaliente del siglo XVIII en el problema de la solución de ecuaciones por radicales, después de los grandes esfuerzos de hombres como Euler[276], fue el de Vandermonde —en su ensayo de 1771— y el de Lagrange, en su amplio artículo «Reflexions sur la résolution algébrique des équations» («Reflexiones sobre la resolución algebraica de ecuaciones»)[277]. Las ideas de Vandermonde son similares pero no tan extensas ni tan claras. Nosotros debemos, por tanto, presentar la versión de Lagrange. Este se propuso a sí mismo el objetivo de analizar los métodos de solución de las ecuaciones de tercero y cuarto grado, para ver por qué éstos resultaban bien y para ver qué pista le proporcionaban estos métodos en la solución de ecuaciones de grados superiores.
Para la ecuación de tercer grado
![]()
![]()
![]()
![]()
y3 r = 0.
Entonces, si hacemos que w sea la raíz cúbica de unidad (1 + √-3)/2 los valores de y son
![]()
Lagrange mostró que todos los diferentes procedimientos aplicados por sus predecesores equivalen al método anterior. Señaló que es necesario volver nuestra atención no a x como una función de los valores de y, sino a y como una función de x porque es la ecuación reducida la que permite la solución: el secreto debe estar en la relación que expresa las soluciones de la ecuación reducida en términos de las soluciones de la ecuación propuesta.
Lagrange notó que cada uno de los valores de y puede escribirse (ya que 1 + w + w2 = 0) en la forma
![]()
En segundo lugar, la relación (5) también muestra por qué es factible reducir la ecuación de sexto grado reducida a la ecuación de segundo grado, dado que entre las seis permutaciones, tres (incluyendo la identidad) vienen de intercambiar las xi y tres de intercambiar únicamente dos manteniendo una fija. Pero, entonces, en función del valor w, los seis valores de y que resulten están relacionados por
![]()
![]()
(x1 + wx2 + w2x3)3
puede tomar únicamente dos valores bajo la permutación de x1, x2 y x3, y ésta es la razón de que la ecuación que satisface y sea cuadrática en y3. Más aún, los coeficientes de la ecuación de sexto grado que satisface y son funciones racionales de los coeficientes de la cúbica original.En el caso de la ecuación general de cuarto grado en x, Lagrange considera
y = x1x2 + x3x4
Esta función de las cuatro raíces toma solamente tres valores distintos para las veinticuatro permutaciones posibles de las cuatro raíces. De aquí que ha de haber una ecuación de tercer grado que satisface y y los coeficientes de esta ecuación deben ser funciones racionales de los de la ecuación original. Estos argumentos se aplican a la ecuación de cuarto grado.A continuación, Lagrange considera la ecuación general de grado n-ésimo
xn + a1xn-1 + … + an-1x + an = 0 (7)
Los coeficientes de esta ecuación son supuestamente independientes; no debe existir una relación entre los a1, por tanto, las raíces también deben ser independientes, ya que si hubiera una relación entre las raíces sería posible mostrar que esto debería ser cierto respecto a los coeficientes (ya que, esencialmente, los coeficientes son funciones simétricas de las raíces). Así, las n raíces de la ecuación general han de considerarse como variables independientes, y cada función de ellas es una función de las variables independientes.Para entender el plan de Lagrange para hallar la solución, consideremos primero
x2 + bx + c = 0.
Conocemos dos funciones de las raíces, a saber: x1 + x2 y x1x2 que son funciones simétricas, lo cual significa que no cambian cuando los papeles de las raíces son cambiados. Cuando una función no cambia por la permutación llevada a cabo en sus variables, se dice que la función admite la permutación. Por ejemplo, la función x1 + x2 admite la permutación de x1 y x2, pero no así la función x1x2.Lagrange demostró entonces dos proposiciones importantes: si una función ϕ(x1, x2,…, xn) de las raíces de la ecuación general de grado n admite todas las permutaciones de las x, que admite otra función ψ(x1, x2,… ., xn) (y posiblemente otras permutaciones que ψ no admite), la función ϕ puede ser expresada racionalmente en términos de ψ y los coeficientes de la ecuación general (7). Así, la función x1 de la ecuación cuadrática admite todas las permutaciones que admite x1x2 (sólo existe una, la identidad), entonces
![]()
La segunda proposición de Lagrange afirma: si una función ϕ(x1, x2,…, xn) de las raíces de la ecuación general no permite todas las permutaciones admitidas por una función ψ(x1, x2,…, xn), pero toma para las permutaciones que admite ψr valores diferentes, entonces ϕ es una raíz de una ecuación de grado r cuyos coeficientes son funciones racionales de ψ y de la ecuación general dada de grado n. Esta ecuación de grado r puede ser construida. Así, x1x2 no admite todas las permutaciones de x1 + x2, pero toma los dos valores de x1x2 y x2x1; por tanto, x1x2 es una raíz de una ecuación de segundo grado cuyos coeficientes son funciones racionales de x1 + x2 y de b y c. De hecho, x1x2 es una raíz de
t2(b24c) = 0
porque b2 4ac = (x1x2)2. Con el valor de esta raíz, a saber √(b2 4c), podemos encontrar x1 por medio de la ecuación precedente para x1.Del mismo modo, para las ecuaciones x3 + px + q = 0 la expresión (la ϕ)
(x1 + wx2 + w2x3)3
donde w = (-1 + i√3)/2, toma dos valores con las seis posibles permutaciones de las raíces, mientras que x1+ x2+ x3 (la ϕ) admite las seis permutaciones. Si los dos valores son denotados por A y B, se puede mostrar que A y B son raíces de una ecuación de segundo grado cuyos coeficientes son racionales en p y q (ya que x1 + x2 + x3 = 0). Si resolvemos la ecuación de segundo grado y las raíces son A y B, podemos entonces encontrar x1, x2 y x3 a partir de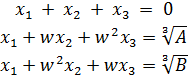
x1x2 + x3x4, (8)
que toma tres valores diferentes para las veinticuatro permutaciones posibles de las raíces, mientras que x1+ x2+ x3 + x4 admite todas las veinticuatro. De aquí que (8) sea una raíz de una ecuación de tercer grado cuyos coeficientes son funciones racionales de los de la ecuación original. Y, de hecho, la ecuación auxiliar o reducida para la ecuación general de cuarto grado es de tercer grado.Para la ecuación de grado n-ésimo con coeficientes generales, Lagrange tuvo la idea de empezar con una función simétrica f0 de las raíces que admiten todas las n! permutaciones de las raíces. Tal función, señala, pudiera ser x1 + x2 +…+ xn. Entonces él escogería una función ϕ1 que admite únicamente algunas de las sustituciones. Supóngase que ϕ1 toma para las n! permutaciones posibles, digamos, r diferentes valores; ϕ1 será entonces una raíz de una ecuación de grado r cuyos coeficientes son funciones racionales de ϕ0 y los coeficientes de la ecuación general dada. La ecuación de grado r puede ser construida. Más aún, si se toma ϕ0 como una de las funciones simétricas que relaciona raíces con coeficientes, entonces los coeficientes de la ecuación de grado r son conocidos por completo en términos de los coeficientes de la ecuación general dada. Si la ecuación de grado r pudiera ser resuelta algebraicamente, entonces ϕ1sería conocida en términos de los coeficientes de la ecuación original. Entonces se escoge una función ϕ2 admitiendo sólo algunas de las permutaciones que admite ϕ1. Puede ϕ2 tomar, digamos, s valores diferentes bajo las sustituciones que admite ϕ1. Por ello, ϕ2 será una de las raíces de u na ecuación de grado s cuyos coeficientes son funciones racionales de ϕ1 y los coeficientes de la ecuación general dada. Los coeficientes de esta ecuación de grado s-ésimo serán conocidos si la ecuación de grado r-ésimo que tiene ϕ1 como una de sus raíces puede resolverse. Si es posible resolver algebraicamente la ecuación de grado s-ésimo, entonces ϕ2 será conocida en términos de los coeficientes de la ecuación original.
Continuamos así hasta ϕ3, ϕ4,... llegando a la función final, que tomamos como x1. Si en este caso, las ecuaciones de grado r, s,… pueden ser resultas algebraicamente, se conocerá x1 en términos de los coeficientes de la ecuación general dada. Las otras raíces x2, ;x3,…, xn surgen del mismo proceso. Las ecuaciones de grado r, s,…, son llamadas ahora ecuaciones resolventes[278].
El método de Lagrange fue útil para las ecuaciones generales de segundo, tercer y cuarto grado; aunque haya también intentado resolver la ecuación de quinto grado de esta manera, lo encontró tan difícil que lo abandonó. Así como para la cúbica únicamente se tenía que resolver una ecuación de segundo grado, para la de quinto grado había que resolver una de sexto. En vano buscó Lagrange hallar una función resolvente (en su sentido del término) que verificara una ecuación de grado menor que cinco. Sin embargo, su trabajo no proporcionó criterio alguno para escoger ϕi que satisficieran ecuaciones resolubles algebraicamente. También, su método se aplicaba únicamente a la ecuación general porque sus dos proposiciones básicas suponen que las raíces son independientes.
Lagrange llegó a concluir que la solución de la ecuación general de grado superior (para n > 4) mediante operaciones algebraicas resultaba imposible con toda probabilidad (para ecuaciones especiales de grado superior ofreció poco Lagrange). Decidió que o el problema está más allá de las capacidades humanas o la naturaleza de las expresiones de las raíces debía ser diferente a todo lo que hasta ese tiempo se conocía. Gauss también, en sus Disquisitiones de 1801, declaró que el problema no podía resolverse.
El método de Lagrange, a pesar de su falta de éxito, proporciona una visión de la razones para los éxitos cuando n ≤ 4 y los fracasos cuando n > 4; esta perspicacia fue capitalizada por Abel y Galois (cap. 31). Más aún, la idea de Lagrange de que uno debe considerar el número de valores que una función racional toma cuando sus variables son permutadas llevó a la teoría de grupos de permutaciones o de sustituciones. De hecho, tenía el teorema de que el orden de un subgrupo (el número de elementos) debe ser un divisor del orden del subgrupo. En el trabajo de Lagrange, que precedió cualquier otro trabajo en teoría de grupos, dicho resultado adopta la forma de que el número r de valores que toma es un divisor de n!
Influenciado por Lagrange, Paolo Ruffini (1765-1822) —matemático, doctor, político y ardiente discípulo de Lagrange— hizo varios intentos durante los años 1799 a 1813 para probar que la ecuación general de grado superior al cuarto no podía ser resuelta algebraicamente. En su Teoría generale delle equazioni (Teoría general de las ecuaciones)[279], Ruffini tuvo éxito en demostrar, por el mismo método de Lagrange, que no existe ninguna ecuación resolvente (en el sentido de Lagrange) que satisfaga una ecuación de grado menor de cinco. De hecho, demostró que ninguna función racional de n elementos toma tres o cuatro valores bajo las permutaciones de los n elementos cuando n > 4. Grosso modo, intentó probar en sus Riflessioni intorno alia soluzione delle equazioni algebraiche generali (Reflexiones en torno a la solución de la ecuación general algebraica)[280], que la solución algebraica de la ecuación general de grado n > 4 era imposible. Este esfuerzo no fue conclusivo, aunque, en un principio, Ruffini pensó que era correcto. Ruffini usó, pero no probó, el teorema auxiliar, conocido hoy como el teorema de Abel, de que si una ecuación es resoluble usando radicales, las expresiones para las raíces se dan en forma tal que los radicales en ellos sean funciones racionales con coeficientes racionales de las raíces de la ecuación dada y las raíces de unidad.
3. Determinantes y teoría de la eliminación
El estudio de un sistema de ecuaciones lineales, que nosotros escribimos ahora como

donde las xi son conocidas y las yj desconocidas, fue iniciado antes de 1678 por Leibniz. En 1693[281], Leibniz usó un conjunto sistemático de índices para los coeficientes de un sistema de tres ecuaciones lineales en dos incógnitas x e y. Eliminó las dos incógnitas del sistema de las tres ecuaciones lineales y obtuvo un determinante, que actualmente denominamos el resultante del sistema. La anulación de este determinante expresa el hecho que hay una x y una y que satisfacen las tres ecuaciones.
La solución de ecuaciones lineales simultáneas de dos, tres y cuatro incógnitas por el método de determinantes fue creada por Maclaurin, probablemente en 1729, y publicada póstumamente en su Treatise of Algebra (Tratado de Algebra, 1748). Aunque no sea muy buena la notación, su regla es la que usamos hoy en día y que Cramer publicó en su Introduction a l'analyse des lignes courbes algébriques (Introducción al análisis de líneas curvas algebraicas, 1750). Cramer dio la regla para determinar los coeficientes de la cónica general,
A + By + Cx + Dy2 + Exy + x2 = 0
pasando por cinco puntos dados. Sus determinantes fueron, como en el presente, la suma de los productos formados al tomar uno y sólo un elemento de cada fila y columna, con el signo de cada producto determinado por el número de cambios de los elementos a partir de un orden fijado, siendo positivo el signo si este número era par o negativo si era impar. En 1764, Bezout[282] sistematizó el proceso de determinar los signos de los términos de un determinante. Dadas n ecuaciones lineales homogéneas con n incógnitas, Bezout demostró que la anulación del determinante de los coeficientes (la anulación del resultante) es una condición para que existan soluciones diferentes de cero.Vandermonde[283] fue el primero en dar una exposición coherente y lógica de la teoría de los determinantes como tales —esto es, aparte de las soluciones de ecuaciones lineales—, aunque también los aplicó a la solución de ecuaciones lineales. Asimismo, proporcionó una regla para desarrollar un determinante usando menores de segundo orden y sus menores complementarios. En el sentido de que él fue quien más se concentró en los determinantes, se le considera el fundador de la teoría.
En un ensayo de 1772, «Recherches sur le calcul intégral et sur le systéme du monde» («Investigaciones sobre el cálculo integral y el sistema del mundo»)[284], Laplace, refiriéndose al trabajo de Cramer y Bezout, probó algunas de las reglas de Vandermonde y generalizó su método de desarrollar determinantes al usar un conjunto de menores de r filas y los menores complementarios. Este método es aún conocido por su nombre[285].
La condición para que un conjunto de tres ecuaciones lineales no homogéneas con dos incógnitas tengan una solución común: la anulación del resultante expresa también el resultado de eliminar x e y de las tres ecuaciones; pero el problema de la eliminación se extiende en otras direcciones. Dados dos polinomios
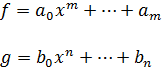
Euler, en el capítulo 19 del segundo volumen de su Introductio, da dos métodos de eliminación. El segundo es el precursor del método multiplicativo de Bezout, mejor descrito por Euler en su ensayo de 1764[286]. El método de Bezout resultó ser el más ampliamente aceptado y, por tanto, debemos examinarlo. En su Cours de mathématique (Curso de matemáticas, 1764-69), considera las dos ecuaciones de grado n,
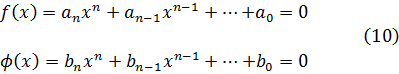
La teoría de la eliminación también fue aplicada a dos ecuaciones, f(x,y) = 0 y g(x, y) = 0, de grado mayor que 1. La motivación era establecer el número de soluciones comunes a las dos ecuaciones o bien, geométricamente, encontrar el número de intersecciones de las curvas correspondientes a las ecuaciones. El sorprendente método para eliminar una incógnita de f(x,y) = 0 y g(x,y) = 0, primero esbozado por Bezout en su ensayo de 1764, lo presentó en su Théorie générale des équations algébriques (Teoría general de las ecuaciones algebraicas, 1779). La idea de Bezout era que multiplicando f(x,y) y g(x,y) por polinomios adecuados, F(x) y G(x), respectivamente, podía formar
R (y) = F(x) f(x,y) + G(x) g(x,y) (11)
Más aún, buscó F y G tales que el grado de R(y) resultara tan pequeño como fuera posible.La cuestión del grado de la eliminante también fue contestada por Bezout en su Théorie (e independientemente por Euler en el ensayo de 1764). Ambos dieron como respuesta mn, el producto de los grados de f y g, y ambos probaron este teorema reduciendo el problema a uno de eliminación a partir de un conjunto auxiliar de ecuaciones lineales. Este producto es el número de puntos de intersección de las dos curvas algebraicas. Jacobi[288] y Minding[289] también dieron el método de Bezout de eliminación para las dos ecuaciones, pero ninguno menciona a Bezout. Pudo suceder que el trabajo de Bezout no les fuera conocido.
4. La teoría de números
En el siglo XVIII, la teoría de números aparecía como una serie de resultados desconectados. Los trabajos más importantes en la materia fueron el Anleitung zur Algebra (Guía de álgebra, edición alemana, 1770) de Euler y el Essai sur la théorie des nombres (Ensayo sobre la teoría de números, 1798) de Legendre. La segunda edición apareció en 1808 bajo el título Théorie des nombres (Teoría de números), y una tercera edición difundida en tres volúmenes apareció en 1830. Los problemas y resultados que describiremos son un pequeño ejemplo de lo que se hizo.
En 1736, Euler demostró[290] el teorema menor de Fermat, a saber, que si p es un primo y a es primo con p, apa es divisible por p.
Muchas pruebas de este mismo teorema fueron dadas por otros matemáticos de los siglos XVIII y XIX. En 1760, Euler generalizó este teorema[291] al introducir la función ϕ o indicador de n; ϕ(n) es el número de enteros < n y primos con n, de tal forma que si n es primo, ϕ(n) es n 1. [La notación ϕ(n) fue introducida por Gauss.] Entonces Euler probó que si a es un primo relativo de n,
aϕ(n) 1
es divisible por n.En cuanto a la famosa conjetura de Fermat sobre xn+yn = zn, Euler probó[292] que era correcta para n = 3 y n = 4; el caso n = 4 había sido probado por Frénicle de Bessy. Este trabajo de Euler tuvo que ser completado por Lagrange, Legendre y Gauss. Legendre probó[293] entonces la conjetura para n = 5. Como veremos, la historia de los esfuerzos para probar la conjetura de Fermat es muy extensa.
Fermat también había conjeturado (cap. 13, sec. 7) que la fórmula
![]()
Un tema con muchas subdivisiones es el de la descomposición de enteros de varios tipos en otras clases de enteros. Fermat había afirmado que cada entero positivo es la suma de como mucho cuatro cuadrados (la repetición de un cuadrado como en 8 = 4 + 4, está permitida si es contado el número de veces que aparece). A lo largo de un período de cuarenta años, Euler continuó intentando probar este teorema y obtuvo resultados parciales[295]. Usando parte del trabajo de Euler, Lagrange[296] probó el teorema. Ni Euler ni Lagrange obtuvieron el número de representaciones.
Euler, en un ensayo de 1754-55, únicamente se refirió a él y, en otro ensayo de la misma revista[297], probó la aseveración de Fermat de que cada primo de la forma 4n + 1 es únicamente descomponible en suma de dos cuadrados. Sin embargo, la prueba de Euler no siguió el método de descenso que Fermat había bosquejado para este teorema. En otro ensayo[298], Euler probó también que cada divisor de la suma de los cuadrados de dos primos relativos es la suma de dos cuadrados.
Edward Waring (1734-98) estableció, en su Meditationes Algebraicae (Meditaciones algebraicas, 1770), el teorema ahora conocido como «Teorema de Waring»: que cada entero es, o un cubo o la suma de a lo más nueve cubos; también cada entero es o una potencia cuarta o la suma de a lo más 19 potencias cuartas. También conjeturó que cada entero positivo puede ser expresado como la suma de a lo más r potencias k-ésimas, con r dependiendo de k. Estos teoremas no los demostró[299].
Christian Goldbach, un prusiano enviado a Rusia, en una carta dirigida a Euler el 7 de junio de 1742, estableció sin prueba alguna que cada entero par es la suma de dos primos y cada entero impar, o bien es un primo o la suma de tres primos. La primera parte de la aserción es ahora conocida como la conjetura de Goldbach y sigue siendo un problema abierto. La segunda aserción se sigue de hecho de la primera, ya que si n es impar se substrae cualquier primo p de ella. Entonces np es par.
Entre los resultados que tratan de la descomposición de números y son algo más especializados están la prueba de Euler de que x4y4 y x4 + y4 no pueden ser cuadrados[300]. Euler y Lagrange probaron muchas de las aserciones de Fermat en el sentido de que ciertos números primos pueden ser expresados en formas particulares. Por ejemplo, Euler demostró[301] que un primo de la forma 3n + 1 puede ser expresado en la forma x2 + 3y2 de manera única.
Los números amigos y perfectos continuaron interesando a los matemáticos. Euler [302] proporcionó 62 pares de números amigos incluyendo los tres pares ya conocidos. Dos de sus pares eran incorrectos. También demostró, en un ensayo publicado póstumamente[303], el recíproco del teorema de Euclides: cada número par perfecto es de la forma 2p-1 (2p 1), donde el segundo factor es primo.
John Wilson (1741-1793), alumno sobresaliente en Cambridge, pero que se convirtió en abogado y juez, estableció un teorema que aún lleva su nombre: para cada primo p, la cantidad (p 1)! + 1 es divisible por p; además, si es divisible por q, entonces q es primo. Waring publicó el argumento en sus Meditationes Algebraicae (Mediationes Algebraicas) y Lagrange lo probó en 1773[304].
El problema de resolver la ecuación x2Ay2 = 1 con números enteros ya ha sido discutida (cap. 13, sec. 7); Euler, en un ensayo de 1732-1733, la llamó erróneamente la ecuación de Pell, y el nombre ha quedado. Su interés en esta ecuación se debía a que necesitaba sus soluciones para resolver ax2 + bx + c = y2 con enteros; escribió varios ensayos sobre este último tema. En 1759, Euler dio un método para resolver la ecuación de Pell al expresar √A como una fracción continua[305]. La idea de Euler era que los valores x e y que satisfacen la ecuación son tales que las proporciones x/y son convergentes (en el sentido de fracciones continuas) a √A. Falló en probar que su método siempre proporciona soluciones y todas están dadas por las fracciones continuas que desarrollan √A. Lagrange[306] demostró en 1766 la existencia de soluciones para la ecuación de Pell y dio una forma más sencilla en ensayos posteriores[307].
Fermat afirmó que podía determinar cuándo la ecuación más general x2 — Ay1 = B era resoluble con enteros y que podía resolverla cuando era posible. La ecuación fue resuelta por Lagrange en los dos ensayos mencionados.
El problema de proporcionar todas las soluciones enteras de la ecuación general
ax2 + 2 bxy + cy2 + 2dx + 2ey + f = 0
donde los coeficientes son enteros fue atacado también. Euler proporcionó tipos incompletos de soluciones, y Lagrange[308] proporcionó la solución completa. En el siguiente volumen de sus Memoires[309] (Memorias) dio una solución más sencilla.Tal vez el descubrimiento más original y de mayor trascendencia del siglo XVIII, respecto a la teoría de números, es la ley de reciprocidad cuadrática. Usa la noción de resultantes o residuos cuadráticos. En el lenguaje introducido por Euler en el ensayo de 1754-1755 y adoptado por Gauss, si existe una x tal que x2p es divisible por q, entonces se dice que p es el residuo o resto cuadrático de q; si no hay tal x, se dice que q no es residuo cuadrático de q. Legendre (1808) inventó un símbolo que ahora se usa para representar cualquiera situación: (p/q) y significa para cualquier número p y cualquier primo q
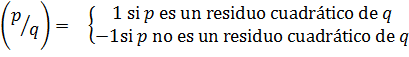
(p/q)(q/p) = (-1)(p-1)(q-1)/4.
Esto significa que si el exponente de (-1) es par, p es un residuo cuadrático de q y q es el residuo cuadrático de p, o ninguno es un residuo cuadrático del otro. Cuando el exponente es impar, lo que sucede cuando p y q son de la forma 4k + 3, un primo será residuo cuadrático del otro pero no al revés.Detallamos la historia de esta ley. Euler, en un ensayo de 1783[310], expuso cuatro teoremas y un quinto teorema resumen que establece muy claramente la ley de la reciprocidad cuadrática. Sin embargo, no demostró estos teoremas. El trabajo de este ensayo data de 1772 y aún incorpora trabajo previo. Kronecker observó en 1875[311] que el enunciado de la ley está de hecho contenido en un ensayo muy anterior de Euler[312]. Sin embargo, la «prueba» de Euler estaba basada sobre cálculos. En 1785, Lagrange anunció la ley independientemente, aunque cita otro ensayo de Euler, en el mismo volumen del Opuscula, en su propio ensayo sobre este tema. Su prueba[313] era incompleta. En su Théorie des nombres[314] (Teoría de números), enunció de nuevo la ley y dio una nueva prueba; sin embargo, ésta también era incompleta, porque supuso que hay un número infinito de primos en ciertas progresiones aritméticas. El deseo por encontrar lo que está detrás de esta ley y derivar sus muchas implicaciones constituyó un tema clave de investigaciones desde 1800 y ha llevado a resultados importantes, algunos de los cuales consideramos en capítulos posteriores.
El trabajo sobre la teoría de números en el siglo XVIII se cierra con el trabajo clásico de Legendre (Théorie, de 1798). A pesar de que contiene un buen número de resultados interesantes, en su dominio como en otros (tal como las integrales elípticas), Legendre no incluyó grandes innovaciones. Se podría reprocharle el presentar una colección de proposiciones de dónde sus concepciones generales podrían haber sido extraídas, pero no lo fueron: lo hicieron más adelante sus sucesores.
Bibliografía
- Cajori, Florian: «Historical note on the graphical representation of imaginaries before the time of Wessel», Amer. Math. Monthly, 19, 1912, pp.167-171.
- Cantor, Moritz: Vorlesungen uber Geschichte der Mathematik, B. G. Teubner, 1898 y 1924; Johnson Reprint Corp., 1965, vol. 3, cap. 107; vol. 4, pp.153-198.
- Dickson, Leonard E.: History of the Theory of Numbers, 3 vols., Chelsea (reimpresión), 1951.
- «Fermat’s last theorem», Annals of Math., 18, 1971, pp. 161-187
- Euler, Leonhard: Opera Omnia (1), vols. 1-5, Orell Fussli, 1911-1944.
- Vollstándige Anleitung zur Algebra (1770) = Opera Omnia (1), 1.
- Fuss, Paul H. von, ed.: Correspondance mathématique et physique de quelques célebres géométres du XVIIIéme siécle, 2 vols. (1843), Johnson Reprint Corp., 1967.
- Gauss, Cari Friedrich: Werke, Kónigliche Gessellschaft der Wissenschaften zu Góttingen, 1876, vol. 3, pp. 3-121
- Gerhardt, C. I.: Der Briefwechsel von Gottfried Wilhelm Leibniz mit Mathematikern, Mayer und Muller, 1899; Georg Olms (reimpresión), 1962.
- Heath, Thomas L.: Diophantus of Alexandria, 1910, Dover (reimpresión), 1964, pp. 267-380.
- Jones, P. S.: «Complex numbers: an example of recurring themes in the developments of mathematics», The Mathematics Teacher, 47, 1954, pp. 106-114, 257-263, 340-345.
- Lagrange, Joseph Louis: Œuvres, Gauthier-Villars, 1867-1869, vols. 1-3, ensayos relevantes.
- «Additions aux éléments d’algébre d’Euler», Œuvres, Gauthier-Villars, 1877, vol. 7, pp. 5-179.
- Legendre, Adrien Marie: Théorie des nombres, 4.a ed., 2 vols., A Blanchard (reimpresión), 1955.
- Muir, Thomas: The theory of determinants in the historical order of development, 1906, Dover (reimpresión), 1960, vol. 1, pp. 1-52.
- Ore, Oystein: Number theory and its History, McGraw-Hill, 1948.
- Pierpont, James: «Lagrange’s place in the theory of substitutions», Amer. Math. Soc. Bulletin, 1, 1894-1895, pp. 196-204.
- «Zur Geschichte der Gleichung des V. Grades (bis 1958)», Monatshefte für Mathematik und Physik, 6, 1895, pp. 15-68.
- Smith, H. J. S.: Report on tbe Tkeory of Numbers, 1867, Chelsea (reimpresión), 1965; también en vol. 2 de Collected mathematical papers of H. J. S. Smith, 1894, Chelsea (reimpresión), 1965.
- Smith, David Eugene: A Source Book in Mathematics, 1929, Dover (reimpresión) 1959, vol. 1, selecciones relevantes. Una de las selecciones es una traducción al inglés de la segunda demostración de Gauss del teorema fundamental del álgebra.
- Struik, D.J.: A Source Book in Mathematics, 1200-1800, Harvard University Press, 1969, pp. 26-54, 99-122.
- Vandiver, H. S.: «Fermat’s last theorem», Amer. Math. Monthly, 53, 1946, pp. 555-578.
- Whiteside, Derek T.: The mathematical works of Isaac Newton, Johnson Reprint Corp., 1967, vol. 2, pp. 3-134. Esta sección contiene la Universal Arithmetic (Aritmética Universal) en inglés.
- Wussing, H. L.: Die Génesis der abstrakten Gruppenbegriffes, VEB Deutscher Verlag der Wissenschaften, 1969.
Capítulo 26
Las matemáticas de 1800
Cuando no podemos usar el compás de las matemáticas o la antorcha de la experiencia (...) es cierto que no podemos dar un solo paso hacia adelante.
Voltaire
1. La aparición del análisis1. La aparición del análisis
2. La motivación del trabajo del siglo XVIII
3. El problema de la demostración
4. La base metafísica
5. La expansión de la actividad matemática
6. Un vistazo adelante
Bibliografía
Si el siglo XVII ha sido correctamente llamado el siglo de los genios, entonces el siglo XVIII puede denominarse el siglo de los ingeniosos. A pesar de que los dos siglos fueron prolíficos, los autores del siglo XVIII, sin haber introducido ningún concepto tan original o fundamental como el del cálculo, sino mediante el ejercicio virtuoso de una técnica, explotaron y adelantaron el poder del cálculo para producir lo que ahora son ramas importantes: series, ecuaciones diferenciales ordinarias y parciales, geometría diferencial y el cálculo de variaciones. Al extender el cálculo a estas áreas diversas, construyeron lo que es ahora el más amplio dominio de las matemáticas, que nosotros llamamos análisis (a pesar de que la palabra ahora incluye un par de ramas las cuales los matemáticos del siglo XVIII apenas tocaron). El progreso en geometría analítica y álgebra, por otro lado, difícilmente fue algo más que una extensión menor de lo que el siglo XVII había iniciado. Aún el gran problema del álgebra, la solución de ecuaciones de grado n-ésimo, recibió atención porque era necesario en el análisis como, por ejemplo, en la integración por el método de fracciones simples.
Durante el primer tercio, o algo así, del siglo, los métodos geométricos eran usados con libertad; pero Euler y Lagrange, en particular, reconocieron la efectividad superior de los métodos analíticos, reemplazando deliberada y gradualmente los argumentos geométricos por analíticos. Los muchos libros de texto de Euler son ejemplos de cómo podía ser usado el análisis. Hacia el final del siglo, Monge revivió la geometría pura, aunque la utilizó en gran medida para dar un significado intuitivo y una guía al trabajo en análisis. Normalmente Monge es considerado como un geómetra, pero ello se debe a que, al trabajar durante una época en la que la geometría se había agotado, le infundió nueva vida mostrando su importancia, al menos para los fines arriba propuestos. De hecho, en un ensayo publicado en 1786 adjudicó implícitamente mayor importancia al análisis, haciendo la observación de que la geometría podía progresar, ya que el análisis era susceptible de ser empleado para estudiarla. Euler, como muchos otros, no buscó en principio nuevas ideas geométricas. El interés primario y los últimos resultados se dieron en el trabajo analítico.
El argumento clásico sobre la importancia del análisis se le debe a Lagrange en su Mecánique analytique. Escribe en su prefacio:
Nosotros ya tenemos varios tratados sobre mecánica, pero el plan de éste es enteramente nuevo. Me he propuesto el problema de reducir esta ciencia [mecánica], y el arte de resolver problemas pertenecientes a ella, a fórmulas generales cuyo simple desarrollo proporciona todas las ecuaciones necesarias para la solución de cada problema (...). No se encontrarán diagramas en este trabajo. Los métodos que expongo en él no demandan ni construcciones ni razonamientos geométricos o mecánicos, sino únicamente operaciones algebraicas analíticas sujetas a un procedimiento uniforme y regular. Aquellos que gustan del análisis disfrutarán al ver cómo la mecánica se convierte en nueva rama de él, y me estarán agradecidos por haber extendido su dominio.Laplace también subrayó el poder del análisis, en su Exposition du systéme du monde (Exposición del sistema del mundo) dice
El análisis algebraico nos hace olvidar rápidamente el objetivo principal [de nuestras investigaciones] al enfocar nuestra atención en combinaciones abstractas y es únicamente al final cuando regresamos a nuestro objetivo original. Pero al abandonarse a las operaciones del análisis, se es llevado por la generalidad de su método y a las ventajas inestimables de transformar el razonamiento por procedimientos mecánicos a resultados frecuentemente inaccesibles a la geometría. Tal es la fecundidad del análisis, que es suficiente con traducir dentro de este lenguaje universal verdades particulares para ver surgir de su propia expresión multitud de nuevas e inesperadas verdades. Ningún otro lenguaje tiene la capacidad para la elegancia que surge de una larga sucesión de expresiones ligadas una a otra viniendo todas de una idea fundamental. Por lo tanto, los geómetras [matemáticos] de este siglo, convencidos de la superioridad del análisis, se han dedicado principalmente a extender su dominio y empujar hacia atrás sus fronteras.[315]Unas cuantas características del análisis requieren aclaración. El énfasis de Newton sobre la derivada y la antidiferenciación fue conservado, de tal manera que el concepto de sumación rara vez fue usado. Por otro lado, el concepto de Leibniz, esto es, la forma diferencial de la derivada y la notación de Leibniz se hicieron habituales, a pesar de que, a lo largo del siglo, las diferenciales leibnizianas no tuvieran un significado preciso. Las primeras diferenciales dy y dx de una función y = f(x) fueron legitimizadas en el siglo XIX (cap. 40, sec. 3), pero las diferenciales de orden superior —aquellas usadas libremente por los hombres del siglo XVIII— no han sido asentadas sobre fundamentos establecidos con rigor aún hoy día. El siglo XVIII también continuó la tradición leibniziana de la manipulación formal de las expresiones analíticas y virtualmente acentuaron esta práctica.
La importancia asignada al análisis tuvo implicaciones que los autores del siglo XVIII no apreciaron. Profundizó la separación entre el concepto de número y la geometría e implícitamente menospreció el problema de los fundamentos mismos del sistema numérico, del álgebra y del propio análisis. Este problema sería crítico en el siglo XIX. Es curioso que los matemáticos del siglo XVIII aún se llamaban a sí mismos geómetras, término en boga durante las épocas precedentes en que la geometría preponderaba sobre las matemáticas.
2. La motivación del trabajo del siglo XVIII
Mucho más que en cualquier otro siglo, el trabajo matemático del siglo XVIII estuvo directamente inspirado por problemas de la física. Bien puede decirse que el objetivo del trabajo no eran las matemáticas, sino la solución de problemas físicos; las matemáticas sólo significaban un medio para fines físicos. Laplace, aunque sea tal vez un caso extremo, las consideraba únicamente una herramienta al servicio de la física y de hecho él mismo estaba interesado por completo en su valor para la astronomía.
La rama principal de la física era, por supuesto, la mecánica, y particularmente la mecánica celeste. La mecánica se convirtió en el paraíso de las matemáticas, como Leonardo había predicho, porque sugirió muchas direcciones de investigación. Tan extenso era el interés de las matemáticas para los problemas de la mecánica que d’Alembert en su Encyclopédie y Denis Diderot (1713-1784) en sus Pensées sur Pinterprétation de la nature (Pensamientos sobre la interpretación de la naturaleza) escribieron sobre una transición de la era de las matemáticas del siglo XVII a la era de la mecánica del siglo XVIII. En efecto, creían que la obra matemática de hombres como Descartes, Pascal y Newton era el passé, y que la mecánica llegaría a ser el máximo interés de los matemáticos. Generalmente, en su opinión, la matemática era útil tan sólo porque servía a la física. El siglo XVIII se concentró en torno a la mecánica de sistemas discretos de masas y de los medios continuos. Por un tiempo, la óptica estuvo relegada al fondo.
En realidad, acontecía lo opuesto a las afirmaciones sostenidas por Diderot y D’Alembert. La interpretación verdadera fue expresada —a la luz de desarrollos futuros— por Lagrange, cuando dijo que aquellos que gustaban del análisis estarían ya satisfechos de ver cómo la mecánica se convertía en una nueva rama de éste. Dicho más abiertamente, el programa iniciado por Galileo y seguido conspicuamente por Newton, orientado a expresar los principios físicos básicos como argumentos matemáticos cuantitativos y deducir nuevos resultados físicos mediante argumentos matemáticos, había avanzado mucho. A partir de ese hecho, la física se tornaba más y más matemática, al menos en las áreas donde los principios físicos eran suficientemente entendidos. La incorporación cada vez mayor de importantes ramas de la física dentro de marcos de referencia matemáticos fundó la física matemática.
Las matemáticas no empezaron únicamente a abarcar las ciencias, sino que, como no había una separación tajante entre ciencia y lo que llamaríamos ingeniería, los matemáticos se propusieron los problemas tecnológicos como una materia de estudio. Euler, por ejemplo, trabajó en el diseño de barcos, la acción de las velas, balística, cartografía y otros problemas prácticos. Monge realizó su trabajo en excavación y relleno y el diseño de aspas de molino, tan en serio como cualquier problema de geometría diferencial o ecuaciones diferenciales.
J. F. (Jean-Etienne) Montucla (1725-1799), en su Histoire des mathématiques (Historia de las Matemáticas, 2.a ed., 1799-1802) dividió las matemáticas en dos partes, una, «comprendiendo aquellas cosas que son puras y abstractas, y la otra, aquellas que uno llama compuestas o más ordinariamente, físico-matemáticas». Su segunda parte comprendía campos que pueden ser enfocados y tratados matemáticamente, tales como mecánica, óptica, astronomía, arquitectura militar y civil, acústica, música, así como los seguros. En la óptica incluyó la dióptrica y aun la optometría, catóptrica y perspectiva. La mecánica incluía la dinámica y la estática, hidrodinámica e hidrostática. La astronomía cubría geografía, astronomía teórica, astronomía esférica, gnómica (e.g., cuadrantes de sol), cronología y navegación. Montucla también incluyó la astrología, la construcción de observatorios y el diseño de barcos.
3. El problema de la demostración
La mezcla de las matemáticas y la física constituyó un hecho crucial en el siglo XVIII, más que la motivación generada por la propensión a resolver los problemas físicos mediante las matemáticas. El principal avance, como se anotó, fue el análisis. Sin embargo, la propia base del cálculo no sólo resultaba poco clara, sino que había estado en duda casi desde el inicio de las investigaciones en la materia en el siglo XVII . El pensamiento del siglo XVIII era ciertamente libre e intuitivo. Se ignoraron cuestiones delicadas del análisis, tales como la convergencia de series e integrales, el intercambio del orden de la diferenciación y la integración, el uso de diferenciales de grado superior y los problemas en torno a la existencia de integrales y las soluciones de ecuaciones diferenciales. El que los matemáticos hayan sido capaces de avanzar de alguna manera se debió a que las reglas para efectuar las operaciones eran claras. Habiendo formulado los problemas físicos matemáticamente, los virtuosos se dedicaron a trabajar, y surgieron nuevas metodologías y conclusiones. Las matemáticas en sí mismas eran puramente formales. Euler estaba tan fascinado por las fórmulas que difícilmente podía abstenerse de manipularlas. ¿Cómo se habían atrevido los matemáticos a aplicar sólo reglas y luego aseverar la seguridad de sus conclusiones?
El significado físico de las matemáticas guió los pasos matemáticos y aportó continuamente argumentos parciales para cubrir los pasos no matemáticos. En esencia, el razonamiento no se diferenciaba de una prueba de un teorema de geometría, donde algunos factores totalmente obvios en la figura son usados aunque ningún axioma o teorema los apoye. Finalmente, lo correcto de las conclusiones físicas ofreció seguridad de que las matemáticas debían ser correctas.
Otro elemento en el pensamiento de las matemáticas del siglo XVIII apoyaba los argumentos: el hombre confiaba en los símbolos mucho más que en su lógica. Ya que las series infinitas tenían la misma forma simbólica para todos los valores de x, la distinción entre los valores de x para los cuales la serie convergía y los valores para los que divergía no parecía demandar atención. Y, aunque reconocían que algunas series, tales como 1 + 2 + 3 +..., tenían una suma infinita, intentaron darle un significado a la suma en vez de cuestionar la sumatoria.
Del mismo modo, el uso un tanto libre de los números complejos descansaba sobre la confianza otorgada a los símbolos. A partir del hecho de que expresiones de segundo grado, ax2 + bx + c, podían ser expresadas como producto de factores lineales donde los ceros eran reales, resultaba igualmente claro que debía haber factores lineales cuando los ceros eran complejos. Las operaciones formales del cálculo, diferenciación y antidiferenciación se aplicaron a nuevas funciones a pesar del hecho de que los matemáticos eran conscientes de la falta de claridad en sus ideas. Esta confianza en el formalismo los cegó de alguna manera. Así, su dificultad en ampliar la noción de función fue causada por el apego que tenían a la convicción de que las funciones debían ser expresables por medio de fórmulas.
Los matemáticos del siglo XVIII eran conscientes de los requerimientos matemáticos de prueba. Hemos visto que Euler intentó justificar el uso de sus series divergentes, y Lagrange, entre otros, ofreció una fundamentación para el cálculo. Pero los pocos esfuerzos para lograr rigor, significativos porque muestran que los niveles de rigor varían con el tiempo, no hicieron lógico el trabajo del siglo, y las gentes adoptaron casi de buena gana la postura de lo que no puede ser curado debe ser duradero. Estaban tan intoxicados con su éxito con los argumentos relacionados con la física, que cada vez se mostraban más indiferentes al rigor que faltaba. Impresiona mucho la confianza extrema en las conclusiones, mientras que la teoría estaba tan mal apoyada. Dado que los matemáticos del siglo XVIII se habían propuesto seguir adelante tan ciegamente sin apoyo lógico, a este período se le ha llamado la época heroica de las matemáticas.
Quizá porque los pocos esfuerzos por hacer más sólido el análisis culminaron en fracasos y cuestiones adicionales de rigor surgidas del trabajo analítico subsecuente estaban desesperadamente faltas de solución, algunos matemáticos abandonaron su empeño en afianzar la teoría, y, como la zorra con las uvas, se alejaron conscientemente del rigor de los griegos. Sylvestre-François Lacroix (1765-1843), en la segunda edición de sus tres volúmenes Traité du calcul différentiel et du calcul intégral (Tratado de cálculo diferencial y cálculo integral)i dice, en el prefacio al volumen 1 (p. 11), «tales pequeñeces como aquellas por las que se preocupan los griegos, nosotros no las necesitamos». La actitud típica del siglo era: ¿Por qué complicarse probando con razonamientos oscuros cosas de las que uno nunca duda en primera instancia, o por demostrar lo que es más evidente por medio de lo que es menos evidente?
Hasta la geometría euclídea tuvo críticas sobre la base de que ofrecía pruebas donde ninguna parecía necesitarse. Clairaut afirmó en sus Eléments de géométrie (Elementos de Geometría, 1741):
No es sorprendente que Euclides tenga dificultades para demostrar que dos círculos que se cortan no tienen el mismo centro, que la suma de los lados de un triángulo comprendido dentro de otro es más pequeña que la suma de los lados del triángulo menor. Este geómetra tuvo que convencer a sofistas obstinados que se glorificaban en rechazar las verdades más evidentes; de tal forma que la geometría debe, como la lógica, basarse en un razonamiento formal para refutar las sutilezas (...). Pero las cosas han cambiado. Todo razonamiento concerniente a lo que el sentido común sabe de antemano, sirve únicamente para esconder la verdad y agotar al lector, y es ignorado hoy día.
Esta actitud del siglo XVIII fue también expresada por Josef María Hoene-Wronski (1778-1853), quien fue un gran algoritmista pero no se interesaba por el rigor. La Comisión de la Academia de Ciencias de París criticó uno de sus ensayos porque carecía de rigor; Wronski respondió que esto era «pedantería, que prefiere el medio al fin».
Los matemáticos eran, en su mayoría, conscientes de su propia indiferencia hacia el rigor. D’Alembert comentó en 1743: «Hasta el presente (...) más importancia se ha dado a engrandecer el edificio que a iluminar la entrada, a elevarlo aún más que a asentar los cimientos». Por consiguiente, el siglo XVIII abrió nuevos caminos como hasta entonces no se había hecho. Las grandes creaciones, habida cuenta del pequeño número de matemáticos, fueron más numerosas que en cualquier otro siglo. Las gentes de los siglos XIX y XX, inclinados a despreciar el tosco, a menudo temerario, producto del siglo XVIII, subrayaron sus excesos y fallos a fin de enaltecer sus triunfos.
4. La base metafísica
A pesar de que los matemáticos sí reconocieron que sus creaciones no habían sido reformuladas en términos del método deductivo de Euclides, confiaban en la verdad de las matemáticas, apoyándose en parte —como hemos notado— en la veracidad física de sus conclusiones, pero también en bases filosóficas y teológicas. La verdad quedaba garantizada porque las matemáticas estaban desenterrando el orden matemático del universo. La clave de la filosofía de la última parte del siglo XVII y del XVIII, especialmente la expresada por Thomas Hobbes, John Locke y Leibniz, era la armonía preestablecida entre la razón y la naturaleza. Esta doctrina no había sido atacada desde el tiempo de los griegos. El problema era entonces: ¿carecían de la precisión de las pruebas puramente matemáticas las leyes matemáticas, que tan claramente se ajustan a la naturaleza? A pesar que el siglo XVIII únicamente desempolvó unas piezas, eran verdades fundamentales. La precisión asombrosa de las deducciones matemáticas, especialmente en mecánica celeste, significaba confirmación gloriosa de la confianza del siglo en el diseño matemático del universo.
Los autores del siglo XVIII estaban del mismo modo convencidos de que ciertos principios matemáticos debían ser ciertos por el diseño matemático que los incorporaba. Así, ya que un universo perfecto no permitiría el desperdicio, su acción era la mínima requerida para obtener sus propósitos. De aquí que el Principio de Acción Mínima fuese, como afirmaba Maupertuis y secundaba Euler en su Methodus Inveniendi, incuestionable.
La convicción de que el mundo estaba diseñado matemáticamente se derivó de la unión previa de la ciencia y la teología. Podemos recordar que la mayoría de las principales figuras de los siglos XVI y XVII no fueron sólo profundamente religiosos, sino que encontraron en sus creencias teológicas inspiración y convicción vital para su trabajo científico. Copérnico y Kepler estaban convencidos de que la teoría heliocéntrica era cierta, porque Dios debió haber preferido una teoría más simple. Descartes creía que nuestras ideas innatas, entre ellas los axiomas de las matemáticas, son verdaderas, y que nuestro conocimiento es sólido, sobre la convicción de que Dios no nos engañaría, de tal forma que negar la verdad y claridad de las matemáticas sería negar a Dios. Newton, como hemos mencionado, concebía que el valor importante de sus esfuerzos científicos era el estudio del trabajo de Dios y el apoyo de la religión revelada. Muchos pasajes en sus trabajos son glorificaciones a Dios, y el escolio general, al final del libro III de sus Principia, en gran parte es un tributo a Dios, reminiscente de Kepler. La explicación de Leibniz sobre la concordancia entre los mundos real y matemático, y su defensa última de la aplicabilidad de su cálculo al mundo real, consistía en la unidad del mundo y Dios. Por tanto, las leyes de la realidad no podían desviarse de las leyes ideales de las matemáticas. El universo era lo más perfecto concebible, el mejor de todos los mundos posibles, y el pensamiento racional revelaba sus leyes.
A pesar de que permanecía la creencia en el diseño matemático de la naturaleza, el siglo XVIII eliminó finalmente las bases filosóficas y religiosas para tal creencia. El meollo de la posición filosófica básica, la doctrina de que el universo estaba diseñado por Dios, fue subestimada gradualmente por las explicaciones puramente físico-matemáticas. La motivación religiosa para el trabajo matemático había empezado a perder fuerza ya en el siglo XVII . Galileo había llamado la atención. Dice en una de sus cartas: «Aunque por mi parte, cualquier discusión sobre las Sagradas Escrituras puede esperar para siempre; ningún astrónomo o matemático que se mantenga dentro de los límites propios ha hecho incursiones en tales cosas». Así pues, Descartes, al afirmar la invariabilidad de las leyes de la naturaleza, había implícitamente limitado el papel de Dios. Newton confinó las acciones de Dios para mantener al mundo funcionando de acuerdo a su plan: usó la figura del lenguaje de un relojero vigilando un reloj en reparación. Así, el papel atribuido a Dios se hizo más y más restringido; y, en cuanto a la idea de que las leyes universales (que el propio Newton reveló) estaban incluyendo movimientos celestiales y terrestres, dichas concepciones empezaron a dominar la escena intelectual, y como continuó el acuerdo entre predicciones y observaciones, afirmando la perfección de estas leyes, entonces Dios se hundió cada vez más en el fondo y las leyes matemáticas del universo se convirtieron en el foco de atención. Leibniz vio que los Principia implicaban un mundo funcionando de acuerdo con un plan con o sin Dios, y atacó el libro como anticristiano. Pero cuanto más se adelantaba en el desarrollo de las matemáticas en el siglo XVIII, más retrocedía la inspiración y motivación religiosa para el trabajo matemático.
Lagrange, a diferencia de Maupertuis y Euler, negó cualquier implicación metafísica en el Principio de Acción Mínima. La preocupación por obtener resultados significativos en física, reemplazó el interés por el diseño de Dios. Respecto a la preocupación de la física matemática, el total rechazo de Dios y de cualesquiera principios metafísicos que se apoyaban en su existencia, lo realizó Laplace. Hay una historia bastante bien conocida de cuando Laplace dio a Napoleón una copia de su Mécanique celeste, Napoleón indicó: «(...) M. Laplace, me dicen que ha escrito usted este extenso libro sobre el sistema del universo y nunca ha mencionado a su Creador». Se dice que Laplace repuso: «No he tenido necesidad de esa hipótesis». Hacia el final del siglo la etiqueta «metafísica» se aplicaba a un argumento en términos de reproche, aunque con frecuencia se usaba para condenar lo que un matemático no podía entender. Así, la teoría de las características de Monge, no entendida por sus contemporáneos, se consideró metafísica.
5. La expansión de la actividad matemática
Las academias de ciencias, fundadas en la mitad y final del siglo XVII , patrocinaron y apoyaron —a lo largo del siguiente siglo— la investigación matemática más que las universidades. Las academias también apoyaron a las revistas, convertidas en portadoras del nuevo trabajo. Tal vez el único cambio en las actividades de las academias sea que, en 1795, la Academia de Ciencias de París fue reconstituida como una de las tres divisiones del Instituto de Francia.
En Alemania, antes de 1800, las universidades no hacían investigación y ofrecían un par de años requeridos de artes liberales seguidos por especializaciones en leyes, teología o medicina. Los grandes matemáticos no se encontraban en las universidades, estaban ligados a la Academia de Ciencias de Berlín. Sin embargo, en 1810, Alexander von Humboldt (1769-1859) fundó la Universidad de Berlín e introdujo la idea radical de que los profesores debían disertar sobre lo que a ellos les interesara y los estudiantes podían seguir los cursos que ellos quisieran. Así, por primera vez, los profesores podían disertar sobre sus investigaciones. Jacobi expuso en Königsberg, desde 1826 en adelante, su trabajo sobre funciones elípticas, aunque esto no era lo usual y otros maestros tenían que cubrir sus clases regulares. En el siglo XIX muchos de los reinos germanos, ducados y ciudades libres instauraron universidades que apoyaban la investigación hecha por los profesores.
Las universidades francesas del siglo XVIII, al menos hasta la Revolución, no eran mejores que las de Alemania. No obstante, el nuevo gobierno decidió fundar universidades de alto nivel para la enseñanza y la investigación. El trabajo organizativo estuvo a cargo de Nicolás de Condorcet, dedicado activamente a las matemáticas. La Ecole Polytechnique, fundada en 1794, tuvo en Monge y Lagrange a sus primeros profesores de matemáticas. Los estudiantes competían por ser admitidos y, supuestamente, debían recibir el entrenamiento que les permitiría convertirse en ingenieros u oficiales del ejército. De hecho, el nivel matemático de los cursos era muy alto y los graduados quedaban capacitados para realizar investigación matemática. A través de este entrenamiento y de las notas publicadas, la escuela ejercía una influencia amplia y fuerte. En 1808, el gobierno francés fundó la Ecole Nórmale Superieure, precedida por la Ecole Nórmale, fundada en 1794, y que únicamente duró unos meses. La nueva Ecole se dedicó a la formación de maestros y estuvo dividida en dos secciones: humanidades y ciencias. Aquí también los estudiantes competían por la admisión; eran ofrecidos cursos avanzados; las facilidades para estudiar e investigar eran grandes y a los mejores estudiantes se les orientaba hacia la investigación.
Las naciones europeas, durante el siglo XVIII, diferían considerablemente en su producción matemática. Francia era el país a la cabeza, seguido por Suiza. Alemania estaba relativamente inactiva, en cuanto a los científicos alemanes se entendía, aunque Euler y Lagrange gozaran del apoyo de la Academia de Ciencias de Berlín. Inglaterra también languidecía. Brook Taylor, Matthew Steward (1717-1785) y Colin Maclaurin eran los únicos matemáticos prominentes. Sorprende la escasa producción inglesa, a la vista de su gran actividad durante el siglo XVII , pero la explicación se encuentra rápidamente: los matemáticos ingleses no sólo se habían aislado personalmente del continente a consecuencia de la controversia entre
Newton y Leibniz, sino que también padecieron el seguir los métodos geométricos de Newton, dedicándose a estudiarlo en lugar de analizar la naturaleza. Incluso en su trabajo analítico usaron la notación de Newton para fluxiones y fluyentes y rechazaron leer cualquier cosa escrita en la notación de Leibniz. Más aún, en Oxford y Cambridge, a ningún judío o disidente de la Iglesia de Inglaterra le era dado, incluso, ser estudiante. En 1815, en Inglaterra, las matemáticas se agotaban en su última exhalación y la astronomía corría casi la misma suerte.
En el primer cuarto del siglo XIX, los matemáticos británicos empezaron a interesarse en el trabajo sobre el cálculo y sus extensiones, cuyo desarrollo en el continente había seguido sin cambios: en Cambridge (1813) fue formada la Sociedad Analítica con objeto de estudiar este trabajo. George Peacock (1791-1858), John Herschel (1792-1871), Charles Babbage y otros más se propusieron el análisis de los principios del «d-ismo» —esto es, la notación leibniziana en el cálculo, contra aquella de la «época del punto», o notación newtoniana—. Pronto, el cociente dy/dx reemplazó a ŷ, y los libros del texto y artículos del continente se hicieron accesibles a los estudiantes ingleses. Babbage, Peacock y Herschel tradujeron una edición en un solo volumen del Traité (Tratado) de Lacroix, publicándolo en 1816. En 1830, los ingleses estaban capacitados para unirse al trabajo del continente. El análisis en Inglaterra resultó ser en gran parte física matemática, aunque algunas vertientes del trabajo completamente nuevas, como la teoría algebraica de invariantes y la lógica simbólica, también fueron iniciadas en este país.
6. Un vistazo adelante
Como sabemos, hacia el final del siglo XVIII los matemáticos habían creado un buen número de nuevas ramas de las matemáticas. Pero los problemas de estas ramas se habían hecho extremadamente complicados, y, con muy pocas excepciones, no se habían creado nuevos métodos para tratarlos. Los matemáticos comenzaron a sentirse bloqueados. Lagrange escribió a D’Alembert el 21 de septiembre de 1781:
«Me parece que la mina de las matemáticas es ya muy profunda, y que al menos que uno descubra nuevas vetas, será necesario, en algún momento, abandonarla. La física y la química ofrecen ahora una explotación más rica y fácil; también el gusto de nuestro siglo parece ir por completo en esta dirección y no es imposible que las cátedras de geometría en la Academia se conviertan algún día en lo que las cátedras de árabe son actualmente en las universidades»[316].Euler y D’Alembert estuvieron de acuerdo con Lagrange en que las matemáticas habían casi agotado sus ideas, y no vieron grandes mentes en el horizonte. Este miedo fue expresado tan temprano como en 1754 por Diderot en sus Pensamientos sobre la interpretación de la Naturaleza: «Me atrevo a decir que en menos de un siglo no quedarán tres grandes geómetras matemáticos en Europa. Esta ciencia muy pronto llegará a un punto estático donde los Bernoullis, Maupertuis, Clairuts, Fontaines, D’Alemberts y Lagranges la hubieran dejado. (...) No iremos más allá de este punto.»
Jean-Baptiste Delambre (1749-1822), secretario permanente de la sección de matemáticas y física del Instituto de Francia, en un informe (Rapport historique sur les progrés des Sciences mathématiques depuis 1789 et sur leur état actuel (Informe histórico sobre el progreso de las ciencias matemáticas desde 1789 y sobre su estado actual), París, 1810) dijo: «Sería difícil y precipitado analizar las posibilidades que el futuro ofrece al avance de las matemáticas; en casi todas sus ramas se está bloqueando por barreras infranqueables; la perfección del detalle parece ser la única cosa que queda por hacer. Todas estas dificultades parecen anunciar que el poder de nuestro análisis se encuentra casi agotado (...).»
La predicción más sabia fue hecha en 1781 por Condorcet, quien estaba impresionado por el trabajo de Monge:
(...) a pesar de tantos trabajos coronados frecuentemente con el éxito, estamos lejos de haber agotado todas las aplicaciones del análisis a la geometría, y en lugar de creer que nos hemos acercado al final donde estas ciencias deben pararse porque ya han llegado al límite de las fuerzas del espíritu humano, nosotros debemos confesar que en su lugar estamos únicamente en los primeros pasos de una carrera inmensa. Estas nuevas aplicaciones [prácticas], independientemente de la utilidad que tengan en sí mismas, son necesarias para el progreso del análisis en general: dan nacimiento a cuestiones que uno no pensaría proponer; piden crear nuevos métodos. Los procesos técnicos son hijos de la necesidad; podríamos decir lo mismo de los métodos de las ciencias más abstractas. Pero nosotros debemos las últimas a necesidades más nobles, la necesidad de descubrir las verdades nuevas o de conocer mejor las leyes de la naturaleza.Así, se ven en las ciencias muchas teorías brillantes que han permanecido sin aplicarse por mucho tiempo, convirtiéndose de repente en el fundamento de las más importantes aplicaciones; y, del mismo modo, aplicaciones que son muy simples en apariencia dando nacimiento a las ideas de las teorías más abstractas, para las cuales nadie ha sentido alguna necesidad, y dirigiendo el trabajo de geómetras [matemáticos] en estas direcciones (...).
Por supuesto Condorcet estaba en lo cierto. De hecho, en el siglo XIX, las matemáticas se expandieron aún más que en el siglo XVIII. En 1783, el año en que ambos, Euler y D’Alembert, murieron, Laplace tenía treinta y cuatro años de edad, Legendre treinta y uno, Fourier quince y Gauss seis.
La nueva matemática tal cual era la veremos en los siguientes capítulos. Pero debemos anotar aquí algunos de los agentes para la propagación de resultados a los que nos referiremos más tarde. Ante todo, hubo un vasto desarrollo en cuanto al número de revistas de investigación. El Journal de l’Ecole Polytecbnique fue fundado al mismo tiempo que se organizó la escuela. En 1810, Joseph-Diez Gergonne (1771-1859) inició los Anuales de Mathématiques Purés et Appliquées, que estuvo editándose hasta 1831, siendo ésta la primera revista puramente matemática. Al mismo tiempo, August Leopold Crelle (1780-1855), una figura notable porque fue un buen organizador y ayudó a un buen número de jóvenes a obtener trabajo en las universidades, inició el Journal für die reine unangewandte Mathematik (Revista para matemáticas puras y aplicadas) en 1826[317]. Por medio de este título, Crelle intentó exponer que deseaba ensanchar la visión de los intereses de los matemáticos. A pesar de las intenciones de Crelle, la revista fue llenada rápidamente con artículos escritos por matemáticos especializados y con frecuencia se referían a esta publicación humorísticamente como el Journal für reine unangewandte Mathematik (Revista para matemáticas puramente no aplicadas). A esta revista también se la llama Diario de Crelle y, de 1855 a 1880, como Borchardt’s Journal. En 1795 las Mémoires de l'Académie des Sciences se convirtieron en las Mémoires de l'Académie des Sciences de l'Institut de France. En 1835, la Academia de Ciencias de París también inició las Comptes Rendus, para cumplir el propósito de dedicar cuatro páginas o menos a noticias breves de nuevos resultados. Existe una historia apócrifa de que la restricción de las cuatro páginas intentaba limitar a Cauchy, quien había estado escribiendo prolíficamente.
En 1836, Liouville fundó el análogo francés del Diario de Crelle, El Journal de Mathématiques Purés et Appliquées, al que se refiere uno frecuentemente como Diario de Liouville. Louis Pasteur (1822-1895) fundó los Anuales Scientifiques de l'Ecole Nórmale Supérieure en 1864, mientras que Gastón Darboux (1842-1917) lanzaba Le Bulletin des Sciences Mathématiques en 1870. Entre otras numerosas revistas, debemos mencionar los Mathematische Annalen (1868), el Acta Mathematica (1882) y el American Journal of Mathematics, la primera revista de matemáticas en los Estados Unidos de Norteamérica, fundada en 1878 por J. J. Sylvester, cuando era profesor en la Johns Hopkins University.
Otro tipo de agente ha promovido la actividad matemática desde el siglo XIX. Los matemáticos de diversos países formaron sociedades profesionales como la London Mathematical Society, primera en su género y organizada en 1865, la Societé Mathematique de France (1872), la American Mathematical Society (1888) y la Deutsche Mathematiker-Vereinigung (1890), las cuales mantuvieron reuniones regulares en las que se presentaban artículos; cada una patrocinaba una o más revistas, además de aquellas ya mencionadas, tales como el Bulletin de la Societé Mathématique de France y los Proceedings of the London Mathematical Society.
Como el bosquejo anterior de nuevas organizaciones y revistas indica, las matemáticas se expandieron enormemente en el siglo XIX y esto se hizo posible porque una pequeña aristocracia de matemáticos fue suplantada por un grupo mucho más amplio. El aumento de la enseñanza permitió la entrada de muchos más estudiantes de todos los niveles económicos. La tendencia se había iniciado ya en el siglo XVIII. Euler fue hijo de un pastor; D’Alembert fue un hijo ilegítimo criado por una familia de escasos recursos; Monge, hijo de un mercader, y Laplace nació en una familia campesina. La participación de las universidades en la investigación, la composición de libros de texto y la formación sistemática de científicos, iniciada por Napoleón, produjo mayor número de matemáticos.
Bibliografía
- Boutroux, Pierre: l'Ideal scientifique des mathématiques, Libraire Félix Alean, 1920.
- Brunschvicg, León: Les Etapes de la philosophie mathématique, Presses Universitaires de France, 1947, Caps. 10-12.
- Hankins, Thomas L.: Jean d’Alembert: Science and Enlightenment, Oxford University Press, 1970.
- Hille, Einar: «Mathematics and mathematicians from Abel to Zermelo», Mathematics Magazine, 26, 1953, pp. 127-146.
- Montucla, J. F.: Histoire des mathématiques, 2.a ed., 4 vols., pp. 1799-1802, Albert Blanchard (reimpresión), 1960.
Capítulo 27
Funciones de una variable compleja
La trayectoria más corta entre dos verdades en el dominio real pasa a través del dominio complejo.
Jacques Hadamard
1. Introducción1. Introducción
2. Los principios de la teoría de funciones complejas
3. La representación geométrica de los números complejos
4. Los fundamentos de la teoría de funciones complejas
5. La visión de Weierstrass de la teoría de funciones
6. Funciones elípticas
7. Las integrales hiperelípticas y el teorema de Abel
8. Riemann y las funciones multívocas
9. Integrales y funciones abelianas
10. Aplicaciones conformes
11. La representación de funciones y los valores excepcionales
Bibliografía
Desde el punto de vista técnico, la creación más original del siglo XIX fue la teoría de funciones de una variable compleja. Esta materia es con frecuencia llamada teoría de funciones; no obstante, su descripción abreviada implica más de lo que se intenta. Esta nueva rama de las matemáticas dominó el siglo XIX casi tanto como las extensiones directas del cálculo habían dominado el siglo XVIII. La teoría de funciones, una rama muy fértil de las matemáticas, ha sido llamada la alegría matemática del siglo. También ha sido aclamada como una de las teorías más armoniosas de las ciencias abstractas.
1. Los principios de la teoría de funciones complejas
Como ya hemos visto, los números complejos, y aun las funciones complejas, entraron en las matemáticas en relación con la integración de fracciones simples, la determinación de los logaritmos de números complejos y negativos, las aplicaciones conformes y la descomposición de un polinomio con coeficientes reales. De hecho, los matemáticos del siglo XVIII hicieron muchas más cosas con los números y funciones complejos.
En su ensayo sobre hidrodinámica, Ensayo sobre una nueva teoría de la resistencia de los fluidos (1752), D’Alembert considera el movimiento de un cuerpo a través de un fluido homogéneo, ideal, carente de peso y en este estudio considera el siguiente problema. Busca determinar dos funciones p y q cuyas diferenciales son
dq = M dx + N dy, dp — N dx — M dy. (1)
Ya que las cantidades N y M entran en ambas dp y dq, se sigue que
![]()
![]()
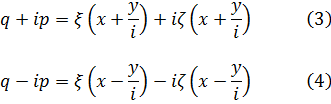
Euler mostró cómo usar funciones complejas para evaluar integrales reales. Escribió una serie de ensayos desde 1776 hasta su muerte en 1783, que fueron publicados a partir de 1788, y dos de los cuales fueron publicados en 1793 y 1797[318]. Euler subraya que toda función de z para la cual z = x + iy toma la forma M + iN, donde M y N son funciones reales, también toma, para z = x - iy, la forma M - iN. Esto, afirma, es el teorema fundamental de los números complejos. Usa esta aserción para evaluar integrales reales.
Supóngase
![]()
![]()
![]()
![]()
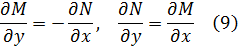
Laplace también utilizó funciones complejas para evaluar integrales. En una serie de ensayos que empiezan en 1782 y que finalizan con su famosa Théorie analytique des probabilités (Teoría analítica de las probabilidades, 1812), pasa de integrales reales a complejas, como lo hizo Euler, para evaluar integrales reales. Laplace reclamó la prioridad, ya que los ensayos de Euler fueron publicados después que los suyos. Sin embargo, aún los ensayos de 1793 y 1797 ya mencionados se leyeron a la Academia de San Petersburgo en marzo de 1777. Incidentalmente, en este trabajo Laplace presentó lo que ahora nosotros llamamos el método de la transformada de Laplace para la solución de ecuaciones diferenciales.
La obra de Euler, D’Alembert y Laplace constituyó un progreso significativo en la teoría de funciones. Sin embargo, existe una limitación esencial en su trabajo. Ellos dependían de la separación de las partes real e imaginaria de f(x + iy) para llevar a cabo su trabajo analítico. La función compleja no era realmente la entidad básica. Es claro que estos autores estaban aún muy insatisfechos con el uso de las funciones complejas. Laplace, en su libro de 1812, señala: «Esta transición de real a imaginario puede ser considerada como un método heurístico, que es como el método de inducción, usado por largo tiempo por los matemáticos. Sin embargo, si se usa el método con gran cuidado y limitación, uno siempre será capaz de probar los resultados obtenidos». Insiste en que los resultados deben ser verificados.
3. La representación geométrica de los números complejos
Un paso vital que hizo el surgimiento de una teoría de funciones de una variable compleja intuitivamente más razonable fue la representación geométrica de los números complejos y de las operaciones algebraicas entre estos números. Que todos aquellos hombres —Cotes, De Moivre, Euler y Vandermonde— pensaran realmente los números complejos como puntos en el plano se sigue del hecho que, al intentar resolver xn - 1 = 0, pensaron las soluciones
![]()
En 1797 el autodidacta navegante (nacido noruego) Caspar Wessel (1745-1818) escribió un ensayo titulado «Sobre la representación analítica de la dirección; un intento», el cual fue publicado en las memorias de 1799 de la Academia Real de Dinamarca. Wessel buscó representar geométricamente segmentos lineales dirigidos (vectores) y operaciones entre ellos. En este ensayo un eje de imaginarios con √-1 (él escribe ε por √-1) como una unidad asociada es introducido junto con el eje x usual con unidad real 1. En la representación geométrica de Wessel, el vector OP (Fig. 27.1) es el segmento lineal OP trazado desde el origen O en el plano de unidades +1 y √-1, y el vector es representado por el número complejo, a + b √-1. Análogamente, el vector OQ es el segmento lineal OQ y es representado por otro número, digamos c + d√-1.
Entonces Wessel define las operaciones con vectores al definir las operaciones con números complejos en términos geométricos.
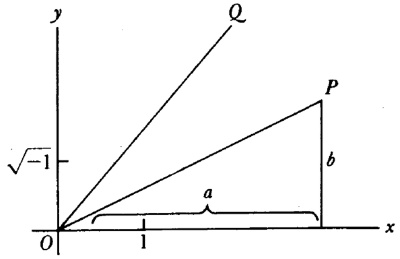
Figura 27.1
Una interpretación geométrica de números complejos en cierta forma diferente fue proporcionada por el suizo Jean Robert Argand (1768-1822). Argand, que era autodidacta y tenedor de libros, publicó un libro breve, Essai sur une maniere de représenter les quantités imaginaires dans les constructions géométriques (Ensayo sobre una manera de representar las cantidades imaginarias en las construcciones geométricas, 1806)[319]. Aquí observa que los números negativos eran una extensión de los números positivos que resulta de combinar la dirección con la magnitud. Entonces pregunta, ¿podemos extender el sistema numérico real al añadir nuevos conceptos? Consideremos la secuencia 1, x, -1. ¿Podemos encontrar una operación que convierta a 1 en x, y luego al repetirse sobre la x convierta x en -1?
Figura 27.2
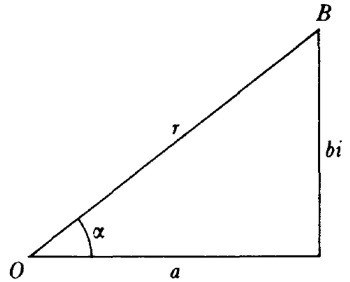
Figura 27.3
Gauss fue más eficaz en lograr la aceptación de los números complejos. Los usó en varias de sus pruebas del teorema fundamental del álgebra (cap. 25, sec. 2). En las primeras tres pruebas (1799, 1815 y 1816) presupone la correspondencia uno a uno de puntos del plano cartesiano con los números complejos. Esto no es de hecho el dibujo de x + iy, sino el de x e y como coordenadas de un punto en el plano real. Más aún, las demostraciones en realidad no usan la teoría de funciones complejas porque separa las partes real e imaginaria de las funciones.
Gauss es más explícito en una carta a Bessel de 1811[320], donde dice que a + bi está representada por el punto (a, b) y que puede irse de un punto a otro del plano complejo por muchas trayectorias. No hay duda, si uno juzga por el pensamiento mostrado en las tres pruebas y en otros trabajos no publicados, algunos de los cuales discutiremos en breve, que para 1815 Gauss estaba en completa posesión de la teoría geométrica de números y funciones complejas, a pesar de que dijo en una carta de 1825 que «la verdadera metafísica de √-1 es elusiva».
Sin embargo, si Gauss aún tenía algunos escrúpulos, para 1831 ya los había superado, y describió públicamente la representación geométrica de los números complejos. En el segundo comentario a su ensayo «Theoria Residuorum Biquadraticorum» (Teoría de los Residuos Bicuadráticos)[321] y en el «Anzaige» (anuncio y breve descripción) de este ensayo que escribió para el Göttingische gelehrte Anzeigen del 23 de abril de 1831[322], Gauss es muy explícito acerca de la representación geométrica de los números complejos. En el inciso 38 del ensayo no solamente proporciona la representación de a + bi como un punto (no como un vector, como Wessel y Argand) en el plano complejo, sino que además describe la adición y multiplicación geométrica de los números complejos. En el «Anzeige»[323], Gauss menciona que la transferencia de la teoría de los residuos bicuadráticos en el dominio de los números complejos puede molestar a quienes no están familiarizados con estos números y que los puede dejar con la impresión que la teoría de los residuos queda en el aire. Por lo tanto, repite lo que ha dicho en el propio ensayo acerca de la representación geométrica de los números complejos. Señala que mientras las fracciones, números negativos y números reales eran ahora bien entendidos, los números complejos habían sido meramente tolerados a pesar de su gran valor. Para muchos, éstos habían aparecido para ser sólo un juego con los símbolos. Pero en esta representación geométrica uno encuentra que: «el significado intuitivo de los números complejos está completamente establecido y no se necesita nada más para admitir estas cantidades en el dominio de la aritmética (itálicas añadidas)». También afirma que si a las unidades 1, —1 y √-1 no se les hubiera asignado los nombres de unidades positivas, negativas e imaginarias, sino que se les hubiera llamado directa, inversa y lateral, la gente no habría tenido la impresión de que existía algún misterio oscuro en estos números. La representación geométrica, afirma, sitúa la verdadera metafísica de los números imaginarios bajo una nueva luz. Introdujo el término «número complejo» como opuesto al de número imaginario[324], y usó i para √-1.
4. Los fundamentos de la teoría de funciones complejas
Gauss también introdujo algunas ideas básicas acerca de las funciones de una variable compleja. En una carta a Bessel de 1811[325], acerca de un ensayo de Bessel sobre la integral logarítmica, ∫dx/x, Gauss señala la necesidad de tener en cuenta los límites imaginarios (complejos). Enseguida pregunta, ¿qué debería uno interpretar por ∫f(x)dx[Gauss escribe ∫ϕ(x)dx] cuando el límite superior es a + bi? De hecho, si uno deseara aclarar los conceptos, uno debería suponer que x toma incrementos pequeños a partir de ese valor de x para el cual la integral es 0 hasta el valor a + bi y entonces sumar todos los ϕ(x)dx... Pero el paso continuo de un valor de x a otro en el plano complejo tiene lugar sobre una curva y es por lo tanto posible ir sobre muchas trayectorias. Afirmo ahora que la integral ∫ϕ(x)dx tiene un valor único aún tomada sobre varias trayectorias siempre que ϕ(x) tome un valor único y no se haga infinita en el espacio comprendido por las dos trayectorias. Este es un teorema muy bello cuya demostración no es difícil y que proporcionaré en alguna ocasión pertinente». Gauss no dio esta prueba. También afirma que si ϕ(x) se hace infinita, entonces dx puede tomar muchos valores, dependiendo de si uno toma una trayectoria cerrada que encierre el punto en el que ϕ(x) se haga infinita una, dos o muchas veces.
Más adelante, Gauss regresa al caso particular de ∫dx/x y dice que, saliendo a partir de x = 1 y dirigiéndose a algún valor a + bi, se obtiene un único valor para la integral si la trayectoria no encierra x = 0; pero si lo hace, se debe añadir 2πi o -2πi al valor obtenido al ir de x = 1 a x = a + bi sin encerrar x = 0. Así, existen muchos logaritmos para una a + bi dada. Más adelante, en la misma carta, Gauss dice que la investigación de las integrales de funciones de argumentos complejos debe proporcionar resultados muy interesantes. Así, aun antes de que Gauss hubiera publicado sus segunda y tercera pruebas del teorema fundamental, donde, como en la primera prueba, evitó el uso directo de números y funciones complejas excepto para escribir ocasionalmente a + b√-1, ya tenía ideas muy definidas acerca de las funciones complejas y de las integrales de tales funciones.
Poisson notó en 1815, y lo discutió en un ensayo de 1820[326], el uso de las integrales de funciones complejas tomadas sobre trayectorias en el plano complejo. Como ejemplo da
Aquí pone x = e‘e, donde 6 va desde (2n + l)jr a 0, y obtiene, al tratar la integral como un límite de sumas, el valor —(2n +\)jií.
Más adelante nota que el valor de la integral no tiene que ser el mismo cuando es tomada sobre una trayectoria imaginaria o cuando es tomada sobre una real. Menciona el ejemplo,
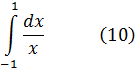
Más adelante nota que el valor de la integral no tiene que ser el mismo cuando es tomada sobre una trayectoria imaginaria o cuando es tomada sobre una real. Menciona el ejemplo,
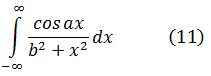
![]()
A pesar de que estas observaciones de Gauss y Poisson son en realidad significativas, ninguno publicó algún ensayo importante en la teoría de funciones complejas. Esta teoría fue fundada por Augustin Louis Cauchy. Nacido en París en 1789, en 1805 ingresó en la Ecole Polytechnique, donde estudió ingeniería. Debido a su pobre salud le fue aconsejado por Lagrange y Laplace dedicarse a las matemáticas. Tuvo cátedra en la Ecole Polytechnique, la Sorbonne y el Collége de France. La política tuvo efectos inesperados en su carrera. Fue un ardiente monárquico y apoyó a los Borbones. Cuando en 1830 una rama distante de los Borbones tomó el poder en Francia, rehusó jurar lealtad a la nueva monarquía y renunció a su plaza en la Ecole Polytechnique. Se exilió en Turín, dedicándose a enseñar latín e italiano por algunos años. En 1838 regresó a París, donde trabajó como profesor de diversas instituciones religiosas, hasta el momento, después de la revolución de 1848, cuando el gobierno tomó su control y abolió los juramentos y lealtades. En 1848, Cauchy tuvo la cátedra de astronomía matemática en la Faculté des Sciences de la Sorbonne. A pesar de que Napoleón III restauró el juramento en 1852, le permitió a Cauchy olvidarlo. Al condescendiente gesto del Emperador, Cauchy respondió donando su salario a los pobres de Sceaux, donde vivía. Cauchy, un profesor admirable y uno de los más grandes matemáticos, murió en 1857.
Cauchy tenía intereses universales. Conocía la poesía de su época y fue el autor de un trabajo sobre la prosa hebrea. En matemáticas escribió más de setecientos artículos, siguiendo en número únicamente a Euler. En una edición moderna, sus trabajos llenan veintiséis volúmenes y abarcan todas las ramas de las matemáticas. En mecánica escribió importantes trabajos sobre el equilibrio de pesos y de membranas elásticas y sobre ondas en medios elásticos. En la teoría de la luz se ocupó de la teoría de ondas que Fresnel había empezado y de la dispersión y la polarización de la luz. Avanzó inmensamente en la teoría de los determinantes y contribuyó con teoremas básicos a las ecuaciones diferenciales ordinarias y parciales.
El primer artículo significativo de Cauchy en la dirección de la teoría de funciones complejas es su «Memoire sur la théorie des intégrales définies» («Memoria sobre la teoría de integrales definidas»). Este ensayo se leyó ante la Academia de París en 1814; sin embargo, no fue enviado para su publicación hasta 1825 y fue publicado en 1827[327]. En la publicación Cauchy añadió dos notas que seguramente reflejan desarrollos entre 1814 y 1825 y la posible influencia del trabajo de Gauss durante este período. Por el momento, consideremos el propio artículo. Cauchy afirma en el prefacio que se orientaba en este trabajo a tratar de rigorizar el paso de real a imaginario en procedimientos usados por Euler desde 1759 y por
Laplace desde 1782 para evaluar integrales definidas, y de hecho, Cauchy cita a Laplace, quien observó que el método requería rigorización. Pero el propio artículo no trata este problema. Trata la cuestión del cambio del orden de la integración en integrales dobles que surgen en las investigaciones hidrodinámicas. Euler había dicho en 1770[328] que este intercambio estaba permitido cuando los límites para cada una de las variables bajo el signo de la integral fueran independientes entre sí, y Laplace, aparentemente, estaba de acuerdo, porque utilizó este recurso en repetidas ocasiones.
Específicamente, Cauchy trató la relación

Figura 27.4
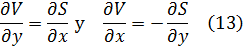
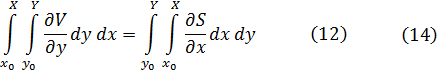
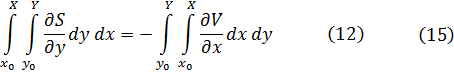
Todo lo anterior se encuentra en el artículo de 1814, y realmente no da indicaciones explícitas de cómo interviene la teoría de las funciones complejas. Más aún, a pesar de que Cauchy usó funciones complejas para evaluar integrales reales definidas, de la misma manera que lo habían hecho Euler y Laplace, este uso no manejaba funciones complejas como entidad básica. Tan tarde como en 1821, en su Cours d’analyse (Curso de Análisis)[331] dice que

En este libro trata de números complejos y variables complejas u + √-1v, donde u y v son funciones de una variable real, pero siempre en el sentido que las dos componentes reales son su contenido significante. Las funciones de valores complejos de una variable compleja no fueron consideradas.
En el año 1822, Cauchy dio algunos pasos hacia adelante. A partir de las relaciones
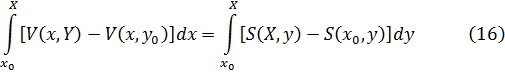
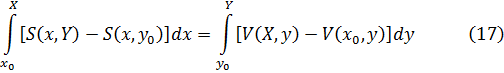
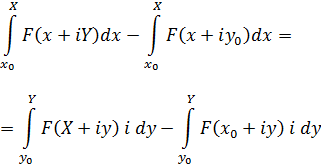
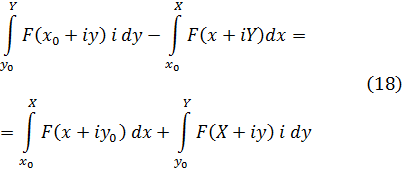
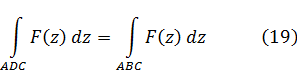
Las ideas anteriores las da Cauchy en una nota de 1822, en su Resumé des leçons sur le calcul infinitésimal (Resumen de las lecciones sobre el cálculo infinitesimal)[332], y en una nota a pie de página del artículo de 1814 que fue publicado en 1827. A partir de estos últimos escritos podemos ver cómo fue Cauchy de las funciones reales a las complejas.
En 1825, Cauchy escribió otro ensayo. «Memóire sur les intégrales définies prises entre des limites imaginaires» («Memoria sobre las integrales definidas tomadas entre límites imaginarios»), pero no fue publicada hasta 1874[333]. Este ensayo está considerado por muchos como el más importante, y uno de los más bellos en la historia de la ciencia, aunque por largo tiempo el propio Cauchy no apreció su valor.
En dicho texto considera nuevamente la cuestión de calcular integrales reales por el método de sustituir valores complejos por constantes y variables. Trata
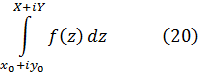
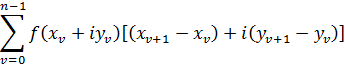
Cauchy formula el teorema como sigue: si f(x + iy) es finita y continua para x0x ≤ X e y0 ≤ y ≤ Y, entonces el valor de la integral (20) es independiente de la forma de las funciones x = ϕ(t) y y = ψ(t). Su prueba del teorema usa el método del cálculo de variaciones. Considera como una trayectoria alternativa ϕ(t) + εu(t), ψ(t) + εv(t), y muestra que la primera variación de la integral con respecto a ε es nula. Esta prueba no es satisfactoria. En ella Cauchy no sólo utiliza la existencia de la derivada de f(z), sino también la continuidad de la derivada, a pesar de que no supone ninguno de los hechos en el enunciado de su teorema. La explicación es que Cauchy creía que una función continua siempre es diferenciable y que la derivada puede ser discontinua únicamente donde la propia función es discontinua. La creencia de Cauchy era razonable en tanto que al principio de su trabajo una función significaba para él, como para otros muchos en los siglos XVIII y XIX, una expresión analítica, y la derivada está dada inmediatamente por las reglas formales de diferenciación.
En el artículo de 1825 Cauchy es más claro aún acerca de una idea importante que ya había aparecido en el mismo artículo de 1814 y en una nota a pie de página a aquel ensayo. Considera lo que sucede cuando f(z) es discontinua dentro o sobre la frontera del rectángulo (Fig. 27.4). Entonces el valor de la integral a lo largo de dos trayectorias diferentes puede ser diferente. Si en z1 = a + ib, f(z) es infinito, pero el límite
![]()
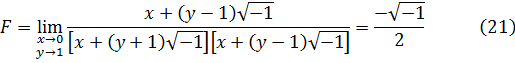
En su Exercices[335], Cauchy señala que el residuo de f(z) en z1 es también el coeficiente del término (z - a1)-1 en el desarrollo de f(z) en potencias de z - a1. Mucho más tarde, en un artículo de 1841[336], Cauchy proporcionó una nueva expresión para el residuo en el polo, a saber,
![]()
Es evidente, a partir de lo que Cauchy añadió en las notas a pie de página a su ensayo de 1814 y por lo que escribió en su magistral ensayo de 1825, que debió haber pensado mucho y profundamente para percatarse de que las relaciones entre pares de funciones reales logran sus formas más sencillas cuando son introducidas cantidades complejas. Cuánto conocía del asunto a partir de los trabajos de Gauss y Poisson, no se sabe.
Durante los años de 1830 a 1838, cuando vivía en Turín y en Praga, sus publicaciones se hicieron dispersas. Se refiere a ellas y repite la mayor parte del trabajo en sus Exercices d’analyse et de physique mathématique (.Ejercicios de análisis y de física matemática. 4 vols., 1840-1847). En un ensayo de 1831, publicado más tarde[337], obtuvo el siguiente teorema: la función f(z) puede ser expandida de acuerdo con la fórmula de Maclaurin en una serie de potencias que es convergente para toda z cuyo valor absoluto es más pequeño que aquellos para los cuales la función o sus derivadas cesan de ser finitas o continuas. (Las únicas singularidades que Cauchy conocía son las que ahora nosotros llamamos polos.) Muestra que esta serie es menor término a término que una serie geométrica convergente cuya suma es
![]()
En la prueba del teorema, primero muestra que
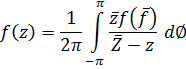
En este teorema Cauchy también supone la existencia y continuidad de la derivada como siguiéndose necesariamente de la continuidad de la función misma. En el momento en que reprodujo este material en su Exercices, había intercambiado correspondencia con Liouville y Sturm y añadió al argumento del teorema anterior que la región de convergencia acaba en el valor de z para el que la función y su derivada cesan de ser finitos o continuos. Pero no estaba convencido que se deba añadir condiciones sobre la derivada, y en trabajos posteriores las eliminó.
En otro trabajo importante sobre la teoría de funciones complejas, «Sur les intégrales qui s’étendent á tous les points d’une courbe fermée» («Sobre las integrales que se extienden a todos los puntos de una curva cerrada»)[338] Cauchy relaciona la integral de una f(z) = u + iv analítica alrededor de una curva encerrando un área [simplemente conexa] a una integral sobre el área. De esta manera si u y v son funciones de x e y,
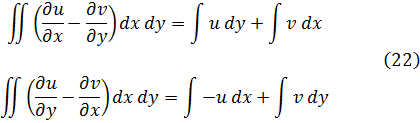
![]()
En el artículo de 1846 mencionado con anterioridad y en otro del mismo año[339], Cauchy cambió su punto de vista sobre las funciones complejas, en contra de su trabajo de 1814, 1825 y 1826. En lugar de estar interesado en las integrales definidas y su cálculo, pasó a la teoría de funciones complejas en sí misma y a construir una base para esta teoría. En este segundo artículo de 1846, proporciona un nuevo argumento sobre la ∫f(z) dz a lo largo de una curva arbitraria cerrada: si la curva encierra polos, entonces el valor de la integral es 2πi veces la suma de los residuos de la función en estos polos; esto es,
![]()
También tomó el tema de las integrales de funciones con valores múltiples[340]. En la primera parte del ensayo, donde trata integrales de funciones con un valor único, no dice mucho más de lo que ya había señalado Gauss en su carta a Bessel a propósito de ∫dx/x o ∫dx/(l +x2). Claro, las integrales tienen valores múltiples y sus valores dependen de la trayectoria de integración. Pero Cauchy va más allá para considerar funciones con valores múltiples bajo el signo integral. Aquí afirma que si el integrando es una expresión para las raíces de una ecuación algebraica o trascendente, por ejemplo ∫w3dz donde x3 = z, y si uno integra sobre una trayectoria cerrada y regresa al punto inicial, entonces el integrando representa ahora otra raíz. En estos casos el valor de la integral sobre la trayectoria cerrada no es independiente del punto inicial, y el continuar alrededor de la trayectoria da diferentes valores de la integral. Pero si uno va alrededor de la trayectoria suficientes veces de tal forma que w regrese a su valor original, entonces los valores de la integral se repetirán y la integral es una función periódica de z. Los módulos de periodicidad (índices de periodicité) de la integral ya no son, como en el caso de funciones con un valor, representables por los residuos. Las ideas de Cauchy sobre las integrales de funciones multivaluadas eran aún demasiado vagas.
Durante veinticinco años, a partir de 1821, Cauchy desarrolló la teoría de funciones complejas por sí solo. En 1843, algunos compatriotas empezaron a tomar algún interés en su trabajo. Pierre-Alphonse Laurent (1813-1853), quien trabajaba solo, publicó un resultado importante obtenido en 1843. Mostró[341] que dada una función discontinua en un punto aislado, en lugar de una expansión de Taylor uno debe utilizar una expansión con potencias crecientes y decrecientes de la variable. Si la función y su derivada son univalentes y continuas en un anillo cuyo centro es un punto aislado a, entonces la integral de la función tomada sobre las dos fronteras circulares del anillo, pero en direcciones opuestas y debidamente expandidas, proporciona una expansión convergente dentro del propio anillo y con potencias crecientes y decrecientes de z. Esta expresión de Laurent es
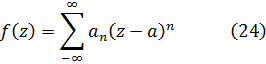
El tema de estas funciones multivaluadas fue retomado por Víctor-Alexandre Puiseux. En 1850, Puiseux publicó un famoso ensayo[343] sobre funciones algebraicas complejas dadas por f(u, z) = 0, siendo f un polinomio en u y z. Primero hizo una clara distinción entre polos y puntos de ramificación que Cauchy apenas percibió e introdujo la noción de un punto singular esencial (un polo de orden infinito), sobre el que Weierstrass había llamado la atención independientemente. Tal punto es ejemplificado por e1/z en z = 0. A pesar de que Cauchy había considerado en el artículo de 1846 la variación de funciones multivaluadas simples a lo largo de trayectorias que encerraban puntos de ramificación, Puiseux clarificó también esta cuestión. Muestra que si u1 es una solución de f(u, z) = 0 y z varía a lo largo de alguna trayectoria, el valor final de y1 no depende de la trayectoria, con tal que la trayectoria no encierre algún punto en el cual u1 es infinita o algún punto donde u1 es igual a alguna otra solución (esto es, un punto de ramificación).
Puiseux también mostró que el desarrollo de una función de z alrededor de un punto de ramificación z = a debe incluir potencias fraccionarias de z - a. Más adelante mejoró el teorema de Cauchy sobre la expansión de una función en serie de Maclaurin. Puiseux obtuvo una expansión para una solución u de f(u,z) = 0 no en potencias de z sino en potencias de z - c, y, por lo tanto, válida en un círculo con c como centro y sin contener ningún polo ni punto de ramificación. Después, Puiseux permite a c variar a lo largo de la trayectoria de manera que los círculos de convergencia coinciden en forma tal que el desarrollo dentro de un círculo puede ser extendido a otro. De esta manera, empezando con un valor de u en cualquier punto, uno puede seguir su variación a lo largo de cualquier trayectoria.
Mediante sus importantes investigaciones sobre funciones multivaluadas y sus puntos de ramificación en el plano complejo, y por su trabajo inicial sobre integrales de tales funciones, Puiseux llevó el trabajo inicial de Cauchy en teoría de funciones al final de lo que podría ser llamado la primera etapa. Las dificultades en la teoría de funciones multivaluadas y las integrales de tales funciones aún tenían que ser superadas. Cauchy escribió otros artículos sobre las integrales de funciones multivaluadas[344], en los que intentaba seguir el trabajo de Puiseux; y a pesar de que introdujo la noción de líneas de corte (lignes d’arrét), aún estaba confundido acerca de la distinción entre polos y puntos de ramificación. Esta materia de las funciones algebraicas y sus integrales habría de continuarla Riemann (sec. 8).
En otros artículos de las Comptes Rendus de 1851[345], Cauchy ofreció algunos argumentos más cuidadosos sobre las propiedades de las funciones complejas. En particular, afirmó que la continuidad de las derivadas, así como también la continuidad de la función compleja misma, es necesaria para la expansión en series de potencias. También señaló que la derivada en z = a de u como una función de z es independiente de la dirección en el plano x + iy cuando z se aproxima a a, y que u satisface d2u/dx2 + d2u/dy2 = 0.
En estos artículos de 1851, Cauchy introdujo nuevos términos. Usó monotypique y también monodrome cuando la función era univalente para cada valor de z en algún dominio. Una función es monogéne si para cada z solamente tiene una derivada (esto es, la derivada es independiente de la trayectoria). Una función monódroma y monógena que nunca es infinita es llamada synectique. Más tarde, Charles A. A. Briot (1817-1882) y Jean-Claude Bouquet (1819-1885) introdujeron «holomorfa» en lugar de synectique y «meromorfa» si la función poseía únicamente polos en el dominio.
5. La visión de Weierstrass de la teoría de funciones
Mientras que Cauchy desarrollaba la teoría de funciones sobre la base de las derivadas e integrales de funciones representadas por expresiones analíticas, Karl Weierstrass desarrolló una nueva visión. Nacido en Westfalia en 1815, Weierstrass ingresó en la Universidad de Bonn a estudiar leyes. Después de cuatro años, se cambió a las matemáticas en 1838, pero no completó su doctorado. En su lugar se aseguró una licencia del estado para llegar a ser profesor de gymnasium (instituto) y desde 1841 a 1854 enseñó a los jóvenes, materias tales como gramática y gimnasia. Durante estos años no tuvo contacto alguno con el mundo matemático, a pesar de que trabajó duro en la investigación matemática. Los pocos resultados que publicó durante este período le aseguraron un puesto enseñando materias de índole técnica en el Instituto Industrial de Berlín. En ese mismo año ingresó en la Universidad de Berlín y llegó a profesor en 1864. Se mantuvo en esta posición hasta su muerte, en 1897.
Fue un hombre metódico y esmerado. Contrariamente a Abel, Jacobi y Riemann, no tuvo destellos de intuición. De hecho, desconfiaba de la intuición e intentó poner el razonamiento matemático sobre una base firme. Mientras que la teoría de Cauchy descansaba sobre unos fundamentos geométricos, Weierstrass intentó construir la teoría de los números reales; cuando esto estuvo hecho (Cap. 41, sec. 3), alrededor de 1841, construyó la teoría de funciones analíticas sobre la base de las series de potencias, técnica que aprendió de su maestro Christof Gudermann (1798-1852), y el proceso de prolongación analítica. Este trabajo fue llevado a cabo en los cuarenta, aunque no lo publicó en aquel entonces. Contribuyó en muchos otros temas en la teoría de funciones y trabajó en el problema de los n cuerpos en astronomía y en la teoría de la luz.
Es difícil fechar las creaciones de Weierstrass, ya que muchas no las publicó una vez logradas. Mucho de lo que había hecho fue conocido por el mundo matemático a través de sus clases en la Universidad de Berlín. Cuando publicó su Werke (Obras) en los 1890, no se preocupó por la prioridad, ya que muchos de sus resultados, mientras tanto, habían sido editados por otros. El se interesaba más por presentar su método para desarrollar la teoría de funciones.
El uso de las series de potencias para representar funciones complejas dadas en forma analítica ya era conocida. Sin embargo, la tarea —dada una serie de potencias que define una función en un dominio restringido, derivar otra serie de potencias que define la misma función en otros dominios sobre la base de teoremas de series de potencias— fue atacada por Weierstrass. Una serie de potencias en 2 - a que es convergente en un círculo C de radio r cerca de a representa una función que es analítica en cada valor de 2 en el círculo C. Escogiendo un punto b en el círculo y usando los valores de la función y sus derivadas dados por la serie original, es factible obtener una nueva serie de potencias en z - b cuyo círculo de convergencia C' corta al primer círculo. En los puntos comunes a los dos círculos las dos series proporcionan el mismo valor de la función. Sin embargo, en los puntos de C' que son exteriores a C, los valores de la segunda serie son una continuación analítica de la función definida por la primera serie. Prolongando tanto como fuera posible a partir de C' sucesivamente a otros círculos, se obtiene la continuación analítica completa f(z). La f(z) completa es la colección de valores de los puntos 2 en todos los círculos. Cada serie se llama un elemento de la función.
Es posible que, durante la extensión del dominio de la función por la adjunción de más y más círculos de convergencia, uno de los nuevos círculos pueda cubrir parte de un círculo que no lo preceda inmediatamente en la cadena, y los valores de la función en esta parte común del nuevo círculo y uno anterior pueden no coincidir. Entonces la función es multivaluada.
Los puntos singulares (polos o puntos de ramificación), que pudieran surgir en este proceso, que necesariamente están sobre los límites de los círculos de convergencia de las series de potencias, son incluidos en la función por Weierstrass si el orden de un punto singular es finito, ya que en dicho punto es posible una expansión en potencias de (z - z0)1/n teniendo únicamente un número finito de términos con exponentes negativos. Para obtener expansiones cerca de z = ∞, Weierstrass usa series en 1/z. Si el elemento de función converge en el plano entero, Weierstrass lo llama una función entera, y si no es una función entera racional, esto es, no es un polinomio, entonces tiene una singularidad esencial en ∞ (e.g. sen z).
Weierstrass también proporcionó el primer ejemplo de una serie de potencias cuyo círculo de convergencia es su frontera natural; esto es, el círculo es una curva de puntos singulares, y un ejemplo de una expresión analítica que puede representar diferentes funciones analíticas en diferentes partes del plano.
6. Funciones elípticas
Durante la primera mitad del siglo, paralelamente al desarrollo de los teoremas básicos de la teoría de funciones complejas, hubo un desarrollo especial concerniente a las funciones elípticas y más tarde a las funciones abelianas. No hay duda de que Gauss obtuvo un buen número de resultados importantes en la teoría de funciones elípticas, ya que muchos de éstos fueron encontrados después de su muerte en artículos que no había publicado. Sin embargo, los fundadores reconocidos de la teoría de funciones elípticas son Abel y Jacobi.
Niels Henrik Abel (1802-1829) fue hijo de un pastor protestante pobre. Como estudiante en Cristianía (Oslo, Noruega), tuvo la suerte de contar con Berndt Michael Holboe (1795-1850) como maestro. Este último reconoció el genio de Abel y predijo, cuando Abel tenía diecisiete años de edad, que se convertiría en el mejor matemático de todo el mundo. Después de estudiar en Cristianía y en Copenhague, Abel recibió una beca que le permitió viajar. En París fue presentado a Legendre, Laplace, Cauchy y Lacroix, pero lo ignoraron. Habiendo agotado sus fondos, viajó a Berlín, donde residió los años de 1825 a 1827 con Crelle. Regresó a Cristianía tan cansado que le fue necesario, según él mismo escribió, asirse de la puerta de una iglesia. Para ganar dinero impartió clases a estudiantes jóvenes. Empezó a recibir mayor atención a través de sus trabajos publicados y Crelle pensó que le podría asegurar una plaza de profesor en la Universidad de Berlín. Pero Abel contrajo la tuberculosis y murió en 1829.
Abel conoció la obra de Euler, Lagrange y Legendre sobre integrales elípticas y pudo haber obtenido de ahí sugerencias para el trabajo que emprendió a partir de comentarios hechos por Gauss, especialmente en su Disquisitiones Arithmeticae. El mismo empezó a escribir artículos en 1825. Presentó su ensayo principal sobre integrales a la Academia de Ciencias de París el 30 de octubre de 1826, para ser publicado en su revista. Este ensayo, «Mémoire sur une proprieté générale d’une classe trés-etendue de fonctions trascendantes» (Memoria sobre una propiedad general de una clase muy amplia de funciones trascendentes), contiene el gran teorema de Abel (sec. 7). Fourier, que era secretario de la Academia por aquellos días, leyó la introducción del artículo y refirió el trabajo a Legendre y Cauchy para ser evaluado, siendo este último el responsable principal. El artículo era largo y difícil, ya que contenía muchas ideas nuevas. Cauchy lo dejó de lado para favorecer su propio trabajo. Legendre lo olvidó. Después de la muerte de Abel, cuando su fama ya estaba bien establecida, la Academia buscó el artículo; encontrándolo en 1841, y fue publicado[346]. Abel editó otros ensayos sobre la teoría de ecuaciones y funciones elípticas en la revista de Crelle y en los Anuales de Gergonne. Aparecieron a partir de 1827. Debido a que el artículo principal de Abel de 1826 no fue publicado hasta 1841, otros autores, al conocer los teoremas más limitados que salieron a la luz entre estas fechas, obtuvieron de forma independiente muchos de los resultados de Abel de 1826.
El otro descubridor de las funciones elípticas fue Cari Gustav Jacob Jacobi (1804-1851). A diferencia de Abel, vivió una vida callada. Nacido en Potsdam de familia judía, estudió en la Universidad de Berlín y en 1827 llegó a ser profesor en Königsberg. En 1842 tuvo que dejar su puesto por su mala salud. Le fue otorgada una pensión del gobierno prusiano y se retiró a Berlín, donde murió en 1851. Su fama fue grande aún en vida, y sus alumnos divulgaron sus ideas por muchos lugares.
Jacobi enseñó funciones elípticas durante muchos años. Su estilo se convirtió en el modelo según el cual se construyó la propia teoría de funciones. También trabajó en determinantes funcionales (Jacobianos), ecuaciones diferenciales ordinarias y parciales, dinámica, mecánica celeste, dinámica de fluidos y funciones e integrales hiperelípticas. Con frecuencia se le asigna a Jacobi la etiqueta de matemático puro, pero, como la mayoría de sus contemporáneos y matemáticos que le precedieron, tomó muy en serio la investigación de la naturaleza.
Mientras que Abel estaba trabajando en funciones elípticas, Jacobi, quien también había leído el trabajo de Legendre sobre integrales elípticas, empezó a trabajar sobre las funciones correspondientes. Presentó un escrito a la Astronomische Nachrichten[347], pero sin demostraciones. Casi simultáneamente, Abel publicó por su parte sus «Recherches sur les fonctions elliptiques» (Investigaciones sobre las funciones elípticas)[348]. Ambos habían llegado a la idea clave de trabajar con las inversas de las funciones integrales elípticas, idea que Abel poseía desde 1823. Después Jacobi proporcionó demostraciones de los resultados que había publicado en 1827 en diversos artículos en la revista de Crelle, entre los años 1828 y 1830. De ahí en adelante, ambos publicaron sobre funciones elípticas, pero mientras que Abel murió en 1829, Jacobi vivió hasta 1851 y pudo publicar mucho más. En particular, el trabajo de Jacobi Fundamenta Nova Theoriae Functionum Ellipticarum (Fundamentos de la Nueva Teoría de Funciones Elípticas) de 1829[349] se convirtió en un texto clave sobre funciones elípticas.
A través de cartas de Jacobi, Legendre se familiarizó con los trabajos de Jacobi y Abel. Escribió a Jacobi el 9 de febrero de 1828: «es una gran satisfacción para mí el ver a dos jóvenes matemáticos que han cultivado tan exitosamente una rama del análisis que por mucho tiempo ha sido mi campo favorito, pero que no se ha recibido como merece en mi propio país». Entonces Legendre publicó tres suplementos (1829 y 1832) a su Traité des fonctions elliptiques (Tratado de Funciones Elípticas, 2 vols., 1825-1826), en los que describió los logros del trabajo de Jacobi y Abel.
La integral elíptica general es
![]()
Para ser precisos, Legendre había introducido (cap. 19, sec. 4) las integrales elípticas F(k, (p), E(k,(p) y Ji(n,k,<p). Fue Abel quien, alrededor de 1826, observó que si, para considerar por ejemplo F(k,(p), uno estudiaba

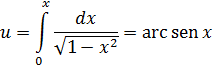
Jacobi introdujo[350] la notación ϕ = am u para la función |ϕ| de u definida por (26). También introdujo
![]()
sn2 u + cn2 u = 1,
ydn2 u + k2sn2 u =1.
Si ϕ es cambiada en -ϕ, entonces u cambia de signo. De aquí queam(-u) = -amu
sn(-u) = -sn u
cn(-u) = cnu,
dn(-u) = dnu.
El papel de π en las funciones trigonométricas aquí es jugado por la cantidad K definida por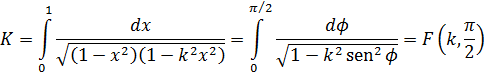
Lo que es importante (pero que no demostrado allí) acerca de K y K' es que
sn(u ± 4K) = snu
cn(u + 4K) = cnu
dn(u ± 2K) = dnu.
De aquí que 4K es un período de las funciones elípticas sn u y cn u, y 2K es un período de dn u.Las funciones sn u, en u y dn u están definidas de esta manera para x y u reales. Abel tenía lo que él consideraba como un elemento de cada función, ya que cada uno está definido únicamente para valores reales. Su siguiente idea fue definir las funciones elípticas en su totalidad mediante la introducción de valores complejos de u. En cuanto al conocimiento de funciones complejas, en su visita a París, Abel conoció el trabajo de Cauchy. De hecho ya había estudiado el teorema del binomio para valores complejos de la variable y del exponente. La extensión primero a valores imaginarios puros fue lograda mediante lo que se llama la transformación imaginaria de Jacobi. Abel introdujo
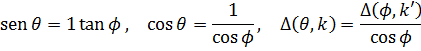
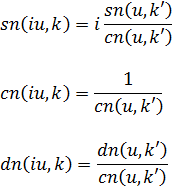
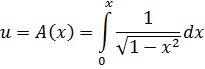
![]()
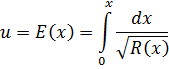
E(x1) + E(x2) = E(x3),
donde x3 es una función racional conocida de x1, x2, y1, y2 e y = √R(x). Abel pensó que para la función inversa x = ϕ(u) debía existir un teorema sencillo de suma y éste fue el caso. Dicho resultado aparece también en su ensayo de 1827. Se deduce entonces que para u y v reales![]()
Habiendo definido las funciones elípticas para valores reales e imaginarios de los argumentos, Abel, con los teoremas aditivos, fue capaz de extender las definiciones a valores complejos. Porque, si z = u + iv, sn z = sn(u+ iv) tiene significado en función del teorema aditivo, en términos de las sn, cn y dn de u y de iv separadamente. También se sigue que
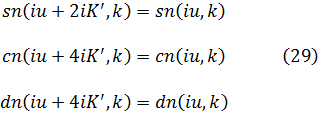
Necesitan, por tanto, ser estudiadas únicamente en un paralelogramo (Fig. 27.5) del plano complejo, ya que éstas repiten su comportamiento en todo paralelogramo congruente.
Las funciones elípticas, además de ser univalentes y doblemente periódicas, tienen una única singularidad esencial en De hecho estas propiedades pueden utilizarse para definir las funciones elípticas, que tienen polos dentro de cada paralelogramo periódico.
Figura 27.5
Muchos de los resultados de Abel fueron obtenidos aparte por Jacobi, cuya primera publicación en este campo —mencionada anteriormente— apareció en 1827. Jacobi era consciente del hecho de que el método básico que había utilizado en su Fundamenta Nova insatisfactorio, y en cierto grado, en ese libro y en conferencias subsecuentes, usó un punto de partida diferente. Sus conferencias nunca fueron publicadas por completo, pero su contenido esencial es bastante conocido a través de cartas y notas dirigidas a sus alumnos. En su nueva manera, construyó su teoría de las funciones elípticas sobre la base de funciones auxiliares llamadas funciones theta, que están ilustradas por la
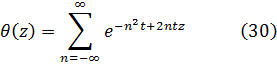
En un artículo importante en 1835[351], Jacobi demostró que una función univaluada de una variable que para cualquier valor finito del argumento tiene el carácter de una función racional (lo cual significa que es una función meromorfa) no puede tener más de dos períodos y la razón de los períodos es necesariamente un número que no es real. Este descubrimiento abrió una nueva dirección de trabajo, a saber, el problema de encontrar todas las funciones doblemente periódicas. En 1844[352] Liouville, en una comunicación a la Academia Francesa de Ciencias, mostró cómo desarrollar una teoría completa de funciones elípticas doblemente periódicas a partir del teorema de Jacobi. Esta teoría fue una contribución importante a las funciones elípticas. En la periodicidad doble Liouville había descubierto una propiedad esencial de las funciones elípticas y un punto de vista que unificaba la teoría, pese a que las funciones doblemente periódicas son una clase más general que aquellas designadas por Jacobi como elípticas. Sin embargo, todas las propiedades fundamentales de las funciones elípticas se mantienen para las funciones doblemente periódicas.
Weierstrass retomó las funciones elípticas alrededor de 1860. Supo del trabajo de Jacobi mediante el de Gudermann, y del trabajo de Abel a través de sus artículos, los cuales le impresionaron tanto que constantemente recomienda la lectura de Abel a sus alumnos. Para su certificado de maestro tomó un problema que le había dado Gudermann: representar funciones elípticas como cocientes de series de potencias. Lo hizo. Como profesor, en sus clases re-trabajó constantemente su teoría de las funciones elípticas.
Legendre había reducido las integrales elípticas a tres formas canónicas que incluían la raíz cuadrada de un polinomio de cuarto grado. Weierstrass llegó a tres formas diferentes con la raíz cuadrada de un polinomio de tercer grado[353], a saber
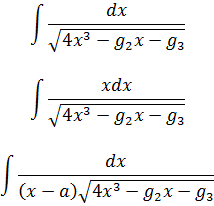
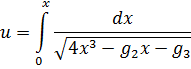
![]()
La doblemente periódica de Weierstrass hace el papel de sn u, en la teoría de Jacobi y es la más sencilla de las funciones doblemente periódicas. Demostró que toda función elíptica puede ser expresada simplemente en términos de Ƥ(u) y la derivada de esta función. La «trigonometría» de las funciones elípticas es más sencilla en la formulación de Weierstrass, pero las funciones de Jacobi y las integrales de Legendre son mejores para el trabajo numérico.
De hecho, Weierstrass empezó con un elemento de su φ(u), a saber,
![]()
A pesar de que no debemos entrar en detalles específicos, no podemos dejar las funciones elípticas sin mencionar el trabajo de Charles Hermite (1822-1901), quien era profesor en la Sorbona y en la Ecole Polytechnique. A partir de sus días de estudiante, Hermite se ocupó siempre de las funciones elípticas. En 1892 escribió: «No puedo abandonar las funciones elípticas; donde la cabra está sujeta, ahí debe pastar». Obtuvo resultados básicos en la propia teoría y estudió la relación con la teoría de números. Aplicó las funciones elípticas a la solución de la ecuación polinómica de quinto grado y trató problemas de mecánica usando estas funciones. También es conocido por su demostración de la trascendencia de e y su introducción de los polinomios de Hermite.
7. Las integrales hiperelípticas y el teorema de Abel
El éxito obtenido en el estudio de las integrales elípticas (25) y las funciones correspondientes motivaron a los matemáticos a atacar un caso aún más difícil, las integrales hiperelípticas.
Las integrales hiperelípticas son de la forma
![]()
![]()
![]()
Entre las integrales de la forma (32) hay algunas que son finitas en todas partes. Las básicas son
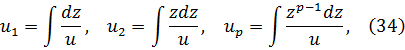
Para el caso n = 6 (y p = 2) las integrales de la segunda clase están ejemplificadas por
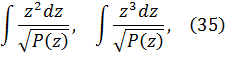
Las integrales hiperelípticas son funciones del límite superior z si el límite inferior es fijo. Supongamos que denotamos una de estas funciones por w. Entonces, como en el caso de las integrales elípticas, uno podría formularse la pregunta de cuál es la función inversa z de w. Este problema lo atacó Abel, pero no lo resolvió. Más adelante, lo atacó Jacobi[354]. Consideremos con Jacobi el caso particular de las integrales hiperelípticas

Jacobi decidió considerar combinaciones de tales integrales. Guiado por el teorema de Abel (véase más adelante), cuyo enunciado conocía al menos por haber sido publicado por este tiempo, Jacobi hizo lo siguiente. Consideremos las ecuaciones
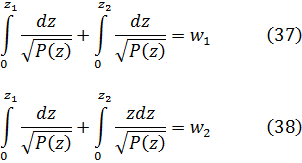
El estudio de una generalización de las integrales elípticas e hiperelípticas fue iniciado por Galois, pero los pasos iniciales más significativos fueron dados por Abel en su artículo de 1826. Consideró (32), esto es,
![]()
f(u, z) = 0 (40)
Las ecuaciones (39) y (40) definen lo que se llama una integral abeliana, que para aquel entonces incluía como casos especiales las integrales elípticas e hiperelípticas.A pesar de que Abel no llevó muy lejos el estudio de las integrales abelianas, demostró un teorema clave en la materia. El teorema básico de Abel es una generalización muy amplia del teorema de adición para funciones elípticas (cap. 19, sec. 4). El teorema y su demostración están en el artículo de París de 1826 y su enunciado en el Diario de Crelle de 1829[355]. Consideremos la integral
![]()
Para obtener un enunciado mucho más preciso, sea y la función algebraica de x definida por la ecuación
f(x, y) = yn + A1yn-1 + ... + An =0 (42)
donde las Ai son polinomios en x y el polinomio (42) es irreducible a factores de la misma forma. Sea R(x,y) cualquier función racional de x e y. Entonces la suma de cualquier número m de integrales similares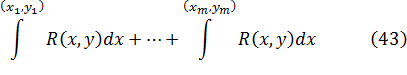
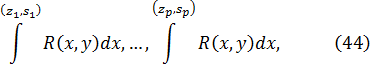
En el caso de estas integrales hiperelípticas donde f = y2 — P(x) y P(x) es un polinomio de grado sexto y donde p, que es (n - 2)/2, es 2, la parte principal del teorema de Abel dice que
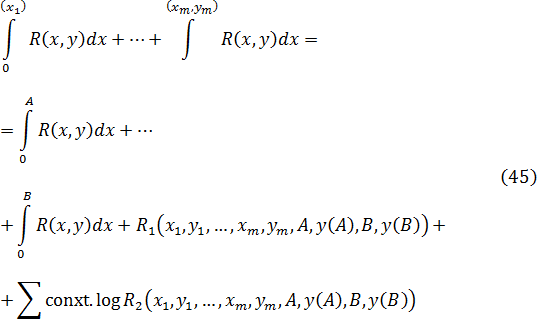
Abel, de hecho, calculó el número p para unos pocos casos del general f(x,y) = 0.
A pesar de que no vio la verdadera importancia de este resultado sí reconoció la noción de género antes que Riemann y fundó las integrales abelianas. Su ensayo fue muy difícil de entender, en parte porque intentó demostrar lo que hoy en día llamaríamos un teorema de existencia mediante el cálculo del resultado. Demostraciones posteriores simplificaron considerablemente la de Abel (véase también Cap. 39, sec. 4). Abel no consideró el problema de la inversión. Todo el trabajo sobre la inversa de las integrales hiperelípticas y abelianas, hasta la llegada de Riemann a la escena, fue impedido por los métodos, tan limitados, de manejar las funciones multivaluadas.
8. Riemann y las funciones multívocas
Alrededor de 1850, un período de éxitos en la teoría de funciones llegó a su fin. Métodos rigurosos, tales como los que proporcionó Weierstrass, aclararon la dirección de los resultados, y las demostraciones incuestionables de existencia denotan en cualquier disciplina matemática una importante, pero última, etapa de su desarrollo. El desarrollo posterior debe estar precedido por un período de descubrimientos libres, numerosos, inconexos, por lo regular hechos por accidente y, tal vez, creaciones desordenadas. El teorema de Abel fue uno de esos pasos. A Riemann se debe un nuevo período de descubrimiento en la teoría de funciones algebraicas, sus integrales y sus funciones inversas. De hecho, Riemann ofreció una teoría mucho más amplia, a saber, el tratamiento de las funciones multivaluadas, hasta entonces únicamente tocadas por Cauchy y Puiseux, y a partir de entonces allanó el camino para un gran número de diferentes avances.
George Friedrich Bernhard Riemann (1826-1866) fue alumno de Gauss y de Wilhelm Weber. Llegó a Göttingen en 1846 para estudiar teología, pero rápidamente se cambió a matemáticas. Su tesis doctoral de 1851, escrita bajo la dirección de Gauss, y titulada «Grundlagen fur eine allgemeine Theorie des Functionen einer veranderlichen complexen Grosse» («Fundamentos de una teoría general de funciones de una variable compleja»)[356] es un ensayo básico de la teoría de funciones complejas. Tres años más tarde se convirtió en un Privatdozent en Göttingen, esto es, gozaba del privilegio de dar clases a estudiantes y cobrar una cuota. Para calificarse como Privatdozent tuvo que escribir su Habilitationsschrift: «Uber die Darstellbarkeit einer Function durch eine trigonometrische Reihe» («Sobre la representación de una función mediante una serie trigonométrica»), y dio una conferencia cualificadora, la Habilitationsvortrag, «Uber die Hypothesen welche der Geometrie zu Grunde liegen» («Sobre las hipótesis en las que está fundada la geometría»). Estas fueron seguidas por una serie de famosos artículos. Riemann fue el sucesor de Dirichlet como profesor de matemáticas en Göttingen en 1859. Murió de tuberculosis.
Riemann es frecuentemente descrito como un matemático puro, pero esto está muy lejos de ser cierto. A pesar de que hizo numerosas contribuciones a las matemáticas propiamente dichas, estaba profundamente interesado en la física y las relaciones de las matemáticas con el mundo físico. Escribió ensayos sobre el calor, la luz, la teoría de gases, el magnetismo, la dinámica de fluidos y la acústica. Intentó unificar la gravitación con la luz e investigar el mecanismo del oído humano. Su trabajo sobre los fundamentos de la geometría buscó asegurar lo que es absolutamente seguro acerca de nuestro conocimiento del mundo del espacio físico (cap. 37). El mismo Riemann asegura que su trabajo sobre las leyes físicas fue su interés primordial. Como matemático, usó libremente sus intuiciones geométricas y argumentos físicos. Parece posible, sobre la base de las pruebas dadas por Félix Klein, que las ideas de Riemann sobre funciones complejas le fueron sugeridas por sus estudios sobre el flujo de corrientes eléctricas a lo largo de un plano. La ecuación del potencial es central en esa materia y lo fue también en el acercamiento de Riemann a las funciones complejas.
La idea clave en la visión de Riemann de las funciones multivaluadas es la noción de superficie de Riemann. La función w2 = z es multivaluada y, de hecho, existen dos valores de w para cada valor de z. Para trabajar con esta función y mantener los dos conjuntos de valores √z y -√z aparte, esto es, para separar las ramas, Riemann introdujo un plano de valores de z para cada rama. Incidentalmente, también introdujo un punto sobre cada plano correspondiente a z = ∞. Los dos planos se consideran como si uno cayera sobre el otro y unidos, lo primero de todo, en aquellos valores de z donde las ramas dan los mismos valores de w. Así para w2 = z los dos planos, u hojas como son llamados, están unidos en z = 0 y z = ∞.
Ahora, w = +√z está representada por los valores de z únicamente en la hoja superior y w = -√z mediante los valores de z de la hoja inferior. Mientras que uno considere los valores de z de la hoja superior, se entiende que es necesario calcular w1 = +√z.
Figura 27.6
Para distinguir las trayectorias sobre una hoja de aquellas sobre la otra, acordamos en el caso de w2 = z considerar el eje x como una rama cortada. Esto une los puntos z = 0 y z = ∞. Esto significa que siempre que z cruce esta cortadura, esa rama de w debe ser tomada como perteneciente a la hoja por la que pasa z. La rama cortada debe no ser necesariamente el eje x pero debe, en el caso presente, unir 0 e ∞. Se dice que 0 e ∞ son puntos de ramificación porque las ramas de w2 = z se intercambian cuando z describe una curva cerrada alrededor de cada una de ellos.
La función w2 = z y, consecuentemente, su superficie de Riemann asociada, son especialmente sencillas. Consideremos la función w2 = z3 - z. Esta función también tiene dos ramas que se hacen iguales a z = 0, z = 1, z = -1 y z = ∞. A pesar de que no presentaremos el argumento completo, los cuatro puntos son puntos de ramificación, ya que si z realiza un circuito alrededor de cualquiera de ellos, el valor de w cambia a partir de ese de una rama a otra. Las cortaduras de las ramas pueden ser tomadas como los segmentos de 0 a 1, 0 a -1, 1 a ∞ y -1 a ∞. Cuando z cruza cualquiera de estas cortaduras, el valor de w cambia de aquellos que toma en una rama a los de la segunda.
Para funciones multivaladas mucho más complicadas, la superficie de Riemann es más complicada. Una función con n valores requiere de una superficie de Riemann con n hojas. Puede haber muchos puntos de ramificación, y se deben introducir cortaduras de rama uniendo cada dos. Es más, las hojas que se unen en algún punto de ramificación no son necesariamente las mismas que las que se unen en otro. Si k hojas coinciden en algún punto, se dice que el orden del punto es k -1. Sin embargo, dos hojas de una superficie de Riemann pueden tocarse en un punto, pero las ramas de la función es posible que permanezcan sin cambiar cuando z gira completamente en torno al punto. Entonces el punto no es un punto de ramificación.
No es posible representar fielmente las superficies de Riemann en un espacio tridimensional. Por ejemplo, las dos hojas para w2 = z deben intersecarse a lo largo del eje x positivo si es representada en tres dimensiones, de modo que uno debe ser cortado a lo largo del eje x positivo, mientras que las matemáticas requieren un paso suave de la primera hoja a la segunda y, entonces, después de una vuelta alrededor de z = 0, se regresa de nuevo a la primera hoja.
Las superficies de Riemann no sólo son una manera de representar funciones mutivaluadas, sino que, en efecto, es la forma de hacer tales funciones univaluadas sobre la superficie, como opuesta al plano de las z. Con ello, teoremas acerca de funciones univaluadas pueden ser extendidos a funciones multivaluadas. Por ejemplo, el teorema de Cauchy acerca de integrales de funciones univaluadas estando 0 sobre una curva limitando un dominio (en el que la función es analítica) fue extendido por Riemann a funciones multivaluadas. El dominio de analiticidad debe ser simplemente conexo (contractible en un punto) sobre la superficie.
Riemann pensaba su superficie como una duplicación de n hojas de plano, completada cada réplica por un punto en el infinito. Sin embargo, es difícil seguir todos los argumentos para tal superficie visualizándolos en términos de los n planos interconectados. De aquí que los matemáticos, desde los tiempos de Riemann, hayan sugerido modelos equivalentes que son más fáciles de contemplar. Es sabido que un plano puede ser transformado en una esfera mediante una proyección estereográfica (Cap. 7, sec. 5). Por eso podemos construir un modelo de la superficie de Riemann considerando n esferas concéntricas de aproximadamente el mismo radio. La sucesión de esferas es la misma que la de las hojas del plano. Los puntos de ramificación de estos planos y las cortaduras de las ramas son de la misma manera transformadas a esferas, de forma tal que estas esferas se envuelven una a otra a lo largo de cortaduras de ramas. Ahora pensamos el conjunto de esferas como el dominio de z, y la función multivaluada w de z es univalente en este conjunto de hojas esféricas.
En nuestra exposición de las ideas de Riemann, hemos empezado con una función f(w,z) = 0, que es un polinomio irreductible en w y en z, y hemos señalado lo que es una superficie de Riemann. Esta no fue la manera de hacerlo Riemann. El empezó con una superficie de Riemann y propuso mostrar que existe una ecuación f(w,z) = 0 que pertenece a ella y, además, que existen otras funciones univalentes y multivalentes definidas sobre la superficie de Riemann.
La definición de Riemann de una función analítica univalente f(z) = u + iv es que la función es analítica en un punto y en su entorno si es continua y diferenciable y satisface lo que ahora llamamos las ecuaciones de Cauchy-Riemann
![]()
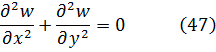
Específicamente, Riemann supone que una función w de posición sobre la superficie de Riemann está determinada, excepto una constante aditiva, por la función real u(x,y) si u está sujeta a las siguientes condiciones:
- Satisface la ecuación del potencial en todos los puntos sobre la superficie donde sus derivadas no son infinitas.
- Si u debe ser una función multivaluada, sus valores en cualquier punto sobre la superficie difieren en combinaciones lineales de múltiplos enteros de constantes reales. (Estas constantes reales son las partes reales de los módulos de periodicidad de w, que discutiremos más adelante.)
- u puede tener (polos) infinitos específicos de cierta forma en puntos fijados sobre la superficie. Estos infinitos deben pertenecer a las partes reales de los términos que dan los infinitos en w. Supone, más adelante, como una condición subsidiaria el que u pueda tener valores finitos a lo largo de una curva cerrada delimitando una porción de la superficie o que haya una relación entre los valores en la frontera de u y v. Riemann es vago en cuanto a lo general que pueda ser esta relación.

Para determinar u, la herramienta esencial de Riemann fue lo que él llamó el principio de Dirichlet, ya que lo aprendió de Dirichlet; pero lo extendió a dominios sobre las superficies de Riemann y, además, prescribió singularidades para u en el dominio y también saltos (condiciones 2 y 3 de las anteriores). El principio de Dirichlet dice que una función u que minimiza la integral de Dirichlet
Una vez que la existencia de las funciones sobre una superficie de Riemann, como dominio, había sido establecida, era posible demostrar que existe una ecuación fundamental que está asociada a la superficie dada; esto es, existe una f(w,z) = 0 que tiene a la superficie dada como su superficie. De qué manera la superficie corresponde a la relación entre w y z, Riemann no lo aclara. De hecho, esta f(w,z) = 0 no es única: a partir de cada función racional w1 de w y z sobre la superficie puede obtenerse a través de f(w,z) = 0 otra ecuación f1 (w1,z) = 0, la cual, si es irreductible, tiene la misma superficie de Riemann. Esta es una característica del método de Riemann.
Para investigar más a fondo las clases de funciones que pueden existir sobre una superficie de Riemann, es necesario conocer la noción de Riemann de la conexión de una superficie de Riemann. Una superficie de Riemann puede tener curvas frontera, o ser cerrada como una esfera o un toro. Si es la superficie riemanniana de una función algebraica, esto es si f(w,z) = 0 define w como una función de z y si f es un polinomio en w y z, entonces la superficie es cerrada. Si f es irreductible, esto es, no puede ser expresado como producto de tales polinomios, entonces la superficie consiste en una pieza y se dice que es conexa.

Figura 27.7
Riemann deseaba asignar un número que indicara la conexión de la superficie. Consideraba los polos y los puntos de ramificación como partes de la superficie, y dado que pensaba en funciones algebraicas, sus superficies eran cerradas. Quitando una pequeña porción de una de las hojas, la superficie tenía una curva frontera C. Entonces imaginó la superficie como cortada por una curva que no se intersecaba a sí misma y que va del borde C a otro punto del borde C. Tal curva es llamada sección cruzada (Querschnitt). Esta sección y C son consideradas como una nueva frontera y puede ser hecho un segundo corte, empezando en algún punto de la (nueva) frontera y finalizando en otro, no cruzando la (nueva) frontera.
Un número suficiente de estas secciones cruzadas es introducido de tal forma que se corte una superficie de Riemann que pueda ser múltiplemente conexa en una única superficie simplemente conexa. Así, si una superficie es simplemente conexa, no se necesita lo anterior y la superficie es conexa (Grundzahl). Una superficie es doblemente conexa si mediante un corte apropiado es cambiada en una única superficie simplemente conexa. Entonces la conectividad es dos. Un anillo plano y una superficie esférica con dos agujeros son ejemplos de lo dicho. Una superficie es llamada triplemente conexa cuando mediante dos cortes apropiados es convertida en una única superficie simplemente conexa. Entonces la conectividad es tres. Un ejemplo es la (superficie de un) toro con un agujero. En general, se dice que una superficie es N-mente conexa o tiene conectividad (o conexión) N si mediante N - 1 cortes puede ser convertida en una superficie simplemente conexa. Una superficie esférica con N agujeros tiene conectividad N.
Ahora es posible relacionar la conectividad de una superficie de Riemann (con una frontera) y el número de puntos de ramificación. Cada punto de éstos, digamos, ri, debe ser contado de acuerdo con la multiplicidad del número de ramas de la función que se cruzan en dicho punto. Si el número es wi, i = 1, 2,..., r, entonces la multiplicidad de wi es wi-1. Supongamos que la superficie tiene q hojas. Entonces la conectividad N está dada por

![]()
Un caso especial de considerable importancia es la superficie
w2 = (z - a1)(z - a2) ... (z - an),
que tiene una superficie de Riemann con dos hojas. Hay un número finito n de puntos de ramificación, y z = ∞ es un punto de ramificación donde n es impar. Entonces Σwi = n o n + 1 y 2q = 4.El género p de la superficie está dado por

Aun en el caso de funciones univaluadas definidas sobre el plano ordinario, las integrales de tales funciones pueden ser multivaluadas. De esta manera
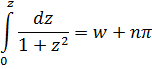
U + m1I1 + m2I2 + ... + + mnIn
donde los m1, m2, ..., mn son enteros. Los Ii son, generalmente, números complejos.9. Integrales y funciones abelianas
A pesar de que cuatro importantes artículos de Riemann publicados en el Journal fur Mathematil[357] repiten muchas de las ideas de su disertación, están principalmente dedicados a las integrales y funciones abelianas. El cuarto ensayo es el que proporcionó a la materia su mayor desarrollo. Los cuatro son difíciles de entender: «eran libros con siete sellos». Afortunadamente, muchos matemáticos brillantes trabajaron más adelante y dieron cabal explicación del material. Riemann colocó a la par el trabajo de Abel y Jacobi, el cual surgió en gran parte de las funciones reales, y el tratamiento de Weierstrass, que se valió de funciones complejas.
A partir del hecho de que Riemann había aclarado el concepto de funciones multivaluadas, podría haber sido más claro en lo concerniente a las integrales abelianas. Sea f(w,z) = 0 la ecuación de una superficie de Riemann y sea ∫R(w,z,)dz una integral de una función racional de w y z sobre esta superficie de Riemann. Riemann clasificó las integrales abelianas como sigue. Entre las integrales de funciones racionales de w y z sobre una superficie de Riemann determinada por la ecuación f(w,z) = 0, existen algunas que, a pesar de ser funciones multivaluadas sobre la superficie sin cortar, son finitas en todas partes. Estas son llamadas integrales de primera clase. El número de tales integrales linealmente independientes es igual al género p de la superficie si la conectividad es 2p + 1. Si se hacen 2p cortes, cada integral es una función univalente para una trayectoria en la región acotada por los cortes. Si la trayectoria debe cruzar un corte, entonces el módulo de periodicidad que discutimos en la sección anterior debe ser usado y el valor de la integral es: si w es su valor desde un punto fijo hasta z, entonces todos los posibles valores son
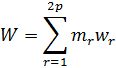
Las integrales de segunda clase tienen infinitos algebraicos pero no logarítmicos. Una integral elemental de segunda clase tiene un infinito de primer orden en un punto sobre la superficie de Riemann. Si E(z) es un valor de la integral en un punto sobre la superficie (el límite superior de la integral), entonces todos los valores de la integral están incluidos en
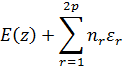
Las integrales que tienen infinitos logarítmicos son llamadas integrales de tercera clase. Sucede que cada una debe tener dos infinitos logarítmicos. Si dicha integral no tiene infinitos algebraicos, esto es, no hay términos algebraicos en la expansión de la integral cerca de cualquiera de los puntos en los cuales tiene infinitos logarítmicos, entonces la integral es llamada integral elemental de tercera clase. Existen p + 1 integrales elementales linealmente independientes de tercera clase teniendo sus infinitos logarítmicos en los mismos dos puntos sobre la superficie de Riemann. Toda integral abeliana es la suma de integrales de las tres clases.
El análisis de las integrales abelianas arroja luz sobre qué clase de funciones pueden existir en una superficie de Riemann. Riemann trata dos clases de funciones; la primera consiste en funciones univaluadas sobre la superficie cuyas singularidades son polos. La segunda clase consiste en funciones que son univaluadas sobre la superficie obtenida con cortes, pero discontinuas a lo largo de cada corte. Por supuesto, tal función difiere en una constante compleja hv en un lado del v-ésimo corte de su valor en el otro lado. Este segundo tipo de función también puede tener polos e infinitos logarítmicos. Riemann muestra que las funciones de primera clase son algebraicas y las de segunda son integrales de funciones algebraicas.
También hay funciones que son finitas en todos los lugares sobre la superficie. Se representan tales funciones por medio de funciones de la primera clase anterior. También podemos construir funciones algebraicas sobre una superficie combinando integrales de segunda y tercera clase. De esta manera, Riemann demostró que las funciones algebraicas pueden ser representadas por una suma de funciones trascendentes. También las funciones univalentes algebraicamente infinitas en un número dado de puntos pueden representarse mediante funciones racionales. Una función que es univalente sobre la superficie entera es el integrando de una integral finita en todas partes. La función puede entonces ser representada como una función racional en w y x y puede tener la forma
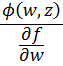
La importancia de las funciones racionales sobre una superficie de Riemann se deriva del hecho, arriba mencionado, de que toda función univalente sobre la superficie y que no tenga singularidades esenciales es una función racional. Tal función tiene tantos ceros como polos y toma todo valor el mismo número de veces. Más aún, una vez que la función f(w,z) = 0, que define la superficie, está fijada, todas las otras funciones de posición sobre la superficie son coextensivas en su totalidad con funciones racionales de w y z e integrales de tales funciones.
Weierstrass también trabajó sobre las integrales abelianas durante la década de los 60. Pero él y los otros seguidores de Riemann en este campo construyeron funciones trascendentes a partir de funciones algebraicas, procedimiento opuesto del de Riemann. Lo hicieron así porque tenían razones para desconfiar del principio de Dirichlet. Weierstrass, en un artículo leído en 1870[358], señaló que la existencia de una función que minimiza la integral de Dirichlet no había sido establecida. El propio Riemann tenía otra manera de pensar. Reconoció el problema de establecer la existencia de una función minimizadora para la integral de Dirichlet, antes que Weierstrass hiciera su argumento, pero declaró que el principio de Dirichlet era una herramienta conveniente que estaba disponible; la existencia de la función u, dijo, era correcta, de todos modos. La observación de Helmholtz en este punto es también interesante: «... para los físicos el [uso del] principio de Dirichlet se mantiene como prueba»[359].
Otra de las nuevas investigaciones en teoría de funciones complejas que inició Riemann es la inversión de las integrales abelianas, esto es, determinar la función z de u cuando
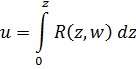
Uno de los resultados más notables para las funciones sobre superficies de Riemann de género p es conocido ahora como el teorema de Riemann-Roch. El trabajo sobre este resultado fue iniciado por Riemann y completado por Gustav Roch (1839-1866)[360]. Esencialmente, el teorema determina el número de funciones meromorfas linealmente independientes sobre la superficie que tienen a lo más un conjunto de específico finito de polos. Más detalladamente, supongamos que w es una función univaluada sobre la superficie y tiene polos de primer orden en los puntos c1,..., cm pero no en otro lado. Las posiciones ci no son necesariamente independientes. Si q funciones linealmente independientes (funciones adjuntas) se anulan en ellos, entonces w contiene m — p + q + 1 constantes arbitrarias, y es una combinación lineal de múltiplos arbitrarios de m - p + q funciones, cada una con p - q + 1 polos del primer orden, p - q de los cuales son comunes a todas las funciones en la combinación.
10. Aplicaciones conformes
Para completar la teoría de su tesis doctoral, Riemann acaba con algunas aplicaciones de la teoría de funciones a la representación conforme. El problema general de la representación conforme de un plano en un plano (que proviene del trazado de mapas) fue resuelto por Gauss en 1825. Su resultado se reduce al hecho que tal aplicación es establecida por cualquier f(z) analítica —aunque Gauss no utilizó la teoría de funciones complejas—. Riemann sabía que una función analítica establecía una representación conforme del plano z en el plano w, pero le interesaba extender esto a las superficies de Riemann. Así se abrió un nuevo capítulo en la representación conforme.
Al final de su tesis Riemann proporciona el siguiente teorema: dadas dos superficies planas simplemente conexas (incluye dominios simplemente conexos sobre superficies de Riemann) pueden ser aplicadas uno a uno y conformemente una sobre otra, y un punto interior y un punto frontera sobre una superficie pueden ser asignados a puntos interiores y puntos frontera sobre el otro escogidos arbitrariamente. Así, la aplicación está determinada en su totalidad. Este teorema contiene como caso especial el resultado básico de que, dado cualquier dominio simplemente conexo D con una frontera que contiene más que un punto y dado un punto A de este dominio y una dirección T en este punto, existe una función w = f(z) que es analítica en D y aplica D conforme y biunívocamente dentro de un círculo de radio 1 centrado en el origen del plano w. Bajo esta aplicación A va al origen y T es enviado en la dirección del eje real positivo. Este último aserto es descrito usualmente como el teorema de la aplicación de Riemann.
Riemann demostró este teorema usando el principio de Dirichlet, pero en aquellos días, al hallarse que era erróneo, los matemáticos buscaron una prueba más sólida. Cari Gottfried Neumann y Hermann Amandus Schwarz demostraron (1870) que era posible aplicar una región plana simplemente conexa sobre un círculo. Sin embargo, no pudieron manejar dominios simplemente conexos con varias hojas.
En algunas ocasiones, el interés dedicado a aplicar una región simplemente conexa conformemente sobre un círculo es explicado por el hecho de que, para aplicar una región simplemente conexa sobre otra conformemente, es suficiente aplicar cada una sobre un círculo y entonces el producto de las dos aplicaciones conformes hará el resto.
Mientras que la prueba del teorema de Riemann permanecía abierta, se obtuvieron varios resultados especiales sobre aplicaciones conformes. De éstos, uno de los más útiles para la solución de ecuaciones en derivadas parciales fue dado por Schwarz[361] y Elwin Bruno Christoffel[362]. Su teorema muestra cómo aplicar un polígono y su interior (Fig. 27.8) en el plano z, conformemente, dentro de la mitad superior del plano w.
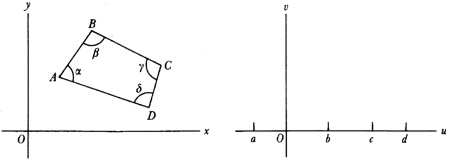
Figura 27.8
11. La representación de funciones y los valores excepcionales
El desarrollo de la teoría de funciones complejas continuó en la segunda mitad del siglo XIX y tendremos ocasión, en capítulos posteriores, de considerar algunos resultados. Sin embargo, unas pocas de entre tantas creaciones que se apoyan primordialmente sobre las propias funciones complejas serán tratadas aquí.
Entre las funciones complejas univalentes, las funciones enteras, esto es, aquellas que no tienen singularidades en la parte finita del plano, que incluyen polinomios, ez, sen z y cos z demostró ser de considerable interés, ya que son, groso modo, las análogas de las funciones reales elementales. Para tales funciones, el teorema de Liouville establece que toda función entera acotada es una constante[363]. Weierstrass extendió a funciones enteras el teorema sobre descomposición de polinomios reales en factores lineales. El teorema de Weierstrass[364], el cual probablemente proviene de los 40, es llamado teorema de factorización, y dice que si G(z) es una función entera que no se anula idénticamente sino que tiene un número infinito de raíces (esto es, no es un polinomio), entonces G(z) puede ser escrita como un producto infinito

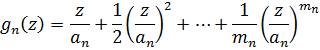
A las funciones enteras siguen en complejidad las funciones meromorfas, las cuales pueden tener únicamente polos en la región finita del plano complejo. En su ensayo de 1876[365], Weierstrass demostró que una función meromorfa puede ser expresada como un cociente de dos funciones enteras. El teorema fue extendido por Gösta Mittag-Leffler (1846-1927) en un ensayo de 1877[366]. Una función meromorfa en una región arbitraria puede ser expresada como cociente de dos funciones, ambas analíticas en la región. En ambos teoremas de Weierstrass y Mittag-Leffler, el numerador y denominador no se anulan en el mismo lugar en la región.
Otro tema que llamó la atención de numerosos matemáticos es el del rango de valores que pueden tomar diversos tipos de funciones complejas. (Charles) Emile Picard (1856-1941), profesor de análisis superior en la Sorbona y secretario perpetuo de la Academia de Ciencias de París, obtuvo una serie de resultados. En 1879[367], Picard demostró que una función entera puede omitir a lo más un valor finito sin reducirse a una constante, y si existieran al menos dos valores cada uno de los cuales es tomado un número finito de veces, entonces la función es polinómica. En cualquier otro caso, la función toma cada valor, aparte del excepcional, un número infinito de veces. Si la función es meromorfa, siendo el infinito un valor admisible, pueden ser omitidos a lo más dos valores sin que la función se reduzca a una constante.
En el mismo artículo, extendió un resultado de Julián W. Sochozki (1842-1927) y Weierstrass, y demostró que en cualquier entorno de un punto singular esencial aislado, una función toma todos los valores, a excepción de a lo más un valor (finito). El resultado es muy profundo y tiene multitud de consecuencias. Por supuesto, un buen número de otros resultados y pruebas alternativas fueron creados y llevaron el problema hasta bien entrado el siglo XX.
En el campo de las funciones complejas, el siglo XIX finalizó con el regreso a los fundamentos. Las demostraciones del teorema de la integral de Cauchy en el siglo XIX se basaron en el hecho de que df/dz es continua. Edouard Goursat (1858-1936) demostró [368] el teorema de Cauchy, ∫f(z)dz = 0 alrededor de una curva cerrada C, sin suponer la continuidad de la derivada f'(z) en la región cerrada limitada por la curva C. La existencia de f'(z) era suficiente. Goursat señaló que la continuidad de f(z) y la existencia de la derivada eran suficientes para caracterizar la analiticidad.
Como ha mostrado nuestro bosquejo del surgimiento de la teoría de las funciones complejas, queda demostrado que Cauchy, Riemann y Weierstrass son los tres principales fundadores de la teoría de funciones. Por largo tiempo, sus respectivas ideas, y métodos, fueron seguidos independientemente por sus seguidores. Más adelante se fusionaron las ideas de Cauchy y Riemann y las ideas de Weierstrass fueron gradualmente reducidas a partir del punto de vista Cauchy-Riemann, de tal forma que la idea de empezar a partir de las series de potencias ya no es básica. El rigor de la visión de Cauchy-Riemann se mejoró, de tal forma que desde este punto de vista la perspectiva de Weierstrass no se toma como esencial. La unificación completa se llevó a cabo al principio del siglo XX.
Bibliografía
- Abel, N. H.: Œuvres completes, 2 vols., 1881, Johnson Reprint Corp., 1964. : Mémorial publié a l'occasion du centénaire de sa naissance,Jacob Dibwad, Cristianía, 1902.
- Brill, A., y Noether, M.: «Die Entwicklung der Theorie der algebraischen Funktionen in álterer und neuerer Zeit», Jabres, der Deut. Math. -Verein., 3, 1892/1893, 109-556, en particular 155-186.
- Brun, Viggo: «Niels Henrik Abel. Neue biographische Funde». Jour. fur Math., 193. 1954, 239-249.
- Cauchy, A. L.: Œuvres completes, 26 vols., Gauthier-Villars, 1882-1938, ensayos relevantes.
- Crowe, Michael J.: A history of vector analysis, University of Notre Dame Press, 1967, Cap. I.
- Enneper, A.: Elliptische Funktionen: Theorie und Geschichte,2.a ed., L. Nebert, 1890.
- Hadamard, Jacques: Notice sur les travaux scientifiques de M. Jacques Hadamard,Gauthier-Villars, 1901.
- Jacobi, C. G. J.: Gesammelte Werke, 7 vols., y suplemento, G. Reimer, 1881-1891; Chelsea reprint, 1968.
- Jourdain, Philip E. B.: «The Theory of Functions with Cauchy and Gauss», Bibliotecha Mathematica, (3), 6, 1905, 190-207.
- Klein, Félix: Vorlesungen über die Entwicklung der Mathematik im 19. Jahrhundert,2 vols., Chelsea (reimpresión), 1950.
- Levy, Paul, et al.: «La vie et l’Œuvre de J. Hadamard», L'Enseignement Mathématique, (2), 13, 1967, 1-72.
- Markuschewitsch, A. I.: Skizzen zur Geschichte der analytischen Funktionen, V. E. B. Deutscher Verlag der Wissenschaften, 1955.Mittag-Leffler, G.: «An introduction to the Theory of Elliptic Functions», Annals of Math., 24, 1922-1923, 271-351. :«Die ersten 40 Jahre des Lebens von Weierstrass», Acta Math., 39, 1923, 1-57.
- Ore, O.: Niels Henrik Abel, Mathematician Extraordinary,University of Minnesota Press, 1957.
- Osgood, W. F.: «Allgemeine Theorie der analytischen Funktionen», Encyk. der Math. Wiss., B. G. Teubner, 1901-1921, II Bl, 1-114.
- Reichardt, Hans, ed.: Gauss: Leben und Werke, Haude und Spenersche Verlagsbuchhandlung, 1960; G. Teubner, 1957, 151-182.
- Riemann, Berhard: Gesammelte mathematische Werke, 2.a ed., Dover (reimpresión), 1953.
- Schlesinger, L.: «Uber Gauss’ Arbeiten -zu Funktionenlehre», Nachrichten König. Ges. der Wiss. zu Gótt., 1912, Beiheft, 1-143, también en los Werke de Gauss, 10, 77 sgs.
- Smith, David Eugene: A Source Book in Mathematics., 2 vols., Dover (reimpresión), 1959, pp. 55-66, 404-410.
- Staeckel, Paul: «Integration durch imnagináres Gebiet», Bibliotecha Mathematica, (3), 1, 1900, 109-128.
- Valson, C. A.: La vie et les travaux du barón Cauchy, 2 vols., Gauthier-Villars, 1868.
- Weierstrass, Karl: Mathematische Werke, 7 vols., Mayer und Müller, 1895-1924.
Capítulo 28
Las ecuaciones en derivadas parciales en el siglo XIX
El estudio profundo de la naturaleza es la fuente más fértil de los descubrimientos matemáticos.
Joseph Fourier
1. Introducción1. Introducción
2. La ecuación de calor y las series de Fourier
3. Soluciones explícitas: la integral de Fourier
4. La ecuación del potencial y el teorema de Green
5. Coordenadas curvilíneas
6. La ecuación de ondas y la ecuación de ondas reducida
7. Sistemas de ecuaciones en derivadas parciales
8. Teoremas de existencia
Bibliografía
El campo de las ecuaciones en derivadas parciales, que tuvo sus inicios en el siglo XVIII, rejuveneció en el XIX. De la misma manera que se extendieron las ciencias naturales, tanto en la variedad como en la profundidad de los fenómenos investigados, el número de nuevos tipos de ecuaciones diferenciales se incrementó; y aun los tipos ya conocidos, la ecuación de ondas y la ecuación del potencial, fueron aplicados a nuevas áreas de la física. Las ecuaciones en derivadas parciales se convirtieron, y permanecieron, en el corazón de las matemáticas. Su importancia para las ciencias físicas es únicamente una de las razones para asignarles este lugar central. Desde el punto de vista de las propias matemáticas, la solución de ecuaciones diferenciales parciales creó la necesidad de desarrollos matemáticos en la teoría de funciones, el cálculo de variaciones, desarrollos en series, ecuaciones diferenciales ordinarias, álgebra y geometría diferencial. La materia ha logrado tal extensión que en este capítulo únicamente podemos describir algunos de los resultados más importantes.
Hoy en día, estamos acostumbrados a clasificar las ecuaciones diferenciales en tipos. Al inicio del siglo XIX, se sabía tan poco de la materia que no se podía haber tenido la idea de distinguir los distintos tipos. Los problemas físicos dictaban qué ecuaciones debían ser atacadas y los matemáticos pasaban libremente de un tipo a otro sin reconocer diferencias entre ellos, que hoy en día consideramos fundamentales. El mundo físico era, y es aún, indiferente a las clasificaciones matemáticas.
2. La ecuación de calor y las series de Fourier
El primer gran paso del siglo XIX, y desde luego uno de enorme importancia, fue dado por Joseph Fourier (1768-1830). Fourier había sido un muy buen estudiante de matemáticas, pero se había propuesto convertirse en un oficial del ejército. Negándosele una comisión, ya que era hijo de un sastre, se refugió en el sacerdocio. Cuando se le ofreció una plaza de profesor en la escuela militar a la que él había asistido aceptó y entonces las matemáticas se covirtieron en el interés de su vida.
Como otros científicos en sus días, Fourier se ocupó del flujo del calor. El flujo tenía interés como problema práctico en el manejo de metales en la industria, y como problema científico en los intentos por determinar la temperatura en el interior de la tierra, la variación de dicha temperatura con respecto al tiempo, y otras cuestiones. Sometió un ensayo básico sobre la conducción del calor a la Academia de Ciencias de París en 1807[369]. El artículo fue juzgado por Lagrange, Laplace y Legendre y fue rechazado. Pero la Academia deseaba motivar a Fourier para desarrollar sus ideas y propuso el problema de la propagación del calor como materia del gran premio que sería asignado en 1812. Fourier sometió una versión revisada en 1811, que fue juzgada por los anteriormente mencionados, y otros. Ganó el premio, pero fue criticado por su falta de rigor y por lo mismo no fue publicado en las Mémoires de la Academia en aquellos días. Fourier se resintió del trato de que fue objeto. Continuó trabajando sobre el calor y, en 1822, publicó con uno de los clásicos de las matemáticas: Théorie Analytique de la chaleur (Teoría analítica del calor)[370]. Incorporaba la primera parte de su artículo de 1811, prácticamente sin un solo cambio. Este libro es la fuente principal para las ideas de Fourier. Dos años más tarde se convirtió en el secretario de la Academia y vio la oportunidad de hacer que se publicara en las Mémoires[371] su artículo de 1811 conservando su forma original.
En el interior de un cuerpo sujeto a pérdida o aumento de calor, por lo general la temperatura no está distribuida uniformemente y cambia en cualquier lugar con el tiempo, lo que hace que la temperatura T sea una función del espacio y el tiempo. La forma precisa de la función depende del contorno del cuerpo, la densidad, el calor específico del material, la distribución inicial de T, esto es, la distribución en el tiempo t = 0, y las condiciones mantenidas sobre la superficie del cuerpo. El primer problema importante que Fourier consideró en su libro fue la determinación de la temperatura T en un cuerpo homogéneo e isótropo como una función de x, y, z y t. Demostró, sobre la base de principios físicos, que T debe satisfacer la ecuación diferencial parcial, llamada ecuación de calor en tres dimensiones,
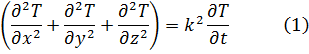
Más adelante, Fourier resolvió problemas específicos de conducción de calor. Debemos considerar un caso que es típico de su método, el problema de resolver la ecuación (1) para la barra cilíndrica cuyos extremos se mantienen a 0o de temperatura y cuya superficie lateral está aislada de tal manera que el calor no fluye a través de ella. Ya que esta barra supone únicamente un espacio de una dimensión (1) se convierte en
![]()
![]()
T(x, 0) = f(x) para 0 < x < l (4)
Para resolver este problema, Fourier usó el método de separación de variables. ConsideróT(X, t) = ϕ(x)ψ(t) (5)
Substituyendo en la ecuación diferencial, obtuvo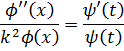
ϕ''(x) + λk2ϕ(x) (6)
yψ'(t) + λψ(t) (7)
Sin embargo, las condiciones (3), en virtud de (5), implicaban queϕ'(0) = 0 ϕ(l) = 0 (8)
La solución general de (6) esϕ'(x) = b sen (√λkx + c)
La condición de que ϕ(0) = 0 implica que c = 0. La condición ϕ(1) = 0 impone una limitación sobre λ, a saber que √λ debe ser un múltiplo entero de π/kl. De aquí que haya un número infinito de valores admisibles λν de λ, o bien![]()
Ya que la solución general de (7) es una función exponencial y ahora λ está limitada a λv, entonces, en virtud de (5), Fourier obtuvo que
![]()
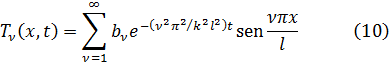
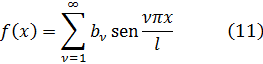
Fourier procedió a contestar estas cuestiones. Aunque para ese tiempo era ya algo consciente del problema del rigor, procedió formalmente en el espíritu del siglo XVIII. Para seguir el trabajo de Fourier haremos, para simplificar, l = π.Así consideramos
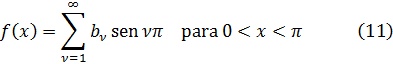
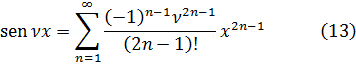
para reemplazar sen νx en (12). Entonces, intercambiando el orden de las sumatorias, operación incuestionada en aquel tiempo, obtiene
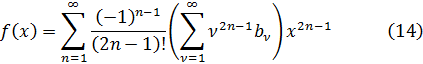
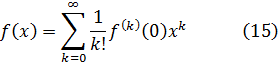
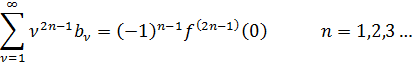
En un problema previo, donde se había enfrentado a este mismo tipo de sistema, Fourier tomó los primeros k términos y la constante de la derecha de las primeras k ecuaciones, resolvió éstas, y, obteniendo una expresión general para las bvk, las cuales denotan los valores aproximados de las bv obtenidos a partir de las primeras k ecuaciones, concluyó audazmente que
![]()

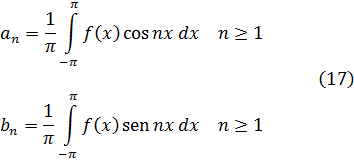
Entonces Fourier realizó algunas observaciones sorprendentes. Notó que cada bvpodía ser interpretada como el área bajo la curva y = (2/π)f(x)sen νx para x entre 0 y π.Tal área tiene sentido aún para funciones muy arbitrarias. Las funciones no requieren ser continuas o pueden ser conocidas sólo gráficamente. De aquí, Fourier concluyó que todafunción f(x)podía ser representada como
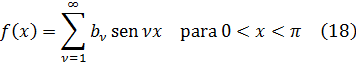
Cuánto sabía Fourier del trabajo de sus predecesores, no está claro. En un artículo de 1825, afirma que Lacroix le había informado del trabajo de Euler, pero no dice cuándo sucedió esto. De cualquier manera, Fourier no fue disuadido por el trabajo de sus predecesores. Tomó una gran variedad de funciones f(x),calculó las primeras bv para cada función y dibujó la suma de unos pocos primeros términos de la serie de senos (18) para cada una. A partir de esta evidencia gráfica dedujo que la serie siempre representa f(x)sobre 0 < x < π, sin importar si la representación se mantiene fuera del intervalo. Señala en su libro (p. 198) que dos funciones pueden coincidir en un cierto intervalo pero no necesariamente fuera del intervalo. La incapacidad de ver esto explica por qué matemáticos de épocas anteriores no podían aceptar que una función arbitraria podía ser desarrollada en una serie trigonométrica. Lo que la serie proporciona es la función en el dominio de 0 a n, en el caso presente, y repeticiones periódicas de ella fuera.
Una vez que Fourier obtuvo el sencillo resultado anterior para las bv,como Euler, se dio cuenta de que cada bvpodía ser obtenida multiplicando la serie (18) por sen νx e integrando de 0 a π.También señala que este procedimiento es aplicable a la representación
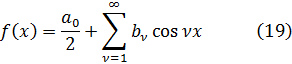
![]()
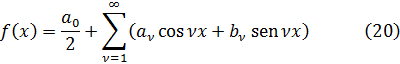
Fourier nunca proporcionó una prueba completa con respecto a que una función «arbitraria» se podía representar por una serie como (20). En su libro proporciona algunos elementos sueltos, y en la discusión final de este punto (párrafos 415, 416 y 423) ofrece un esbozo de la prueba. Pero, aun ahí, Fourier no establece las condiciones que una función debe satisfacer para ser desarrollable en serie trigonométrica. Sin embargo, la convicción de Fourier de que esto era posible está expresada a lo largo de todo el libro. También dice[372] que esta serie era convergente sin importar cómo pudiera ser f(x), tanto si era posible o no asignar una expresión analítica a f(x) y si la función sigue o no una ley regular. La convicción de Fourier de que cualquier función puede ser desarrollada en serie de Fourier se apoyaba sobre la evidencia geométrica descrita anteriormente. Acerca de esto dice en su libro (p. 206): «Nada nos ha parecido a nosotros más conveniente que las construcciones geométricas para demostrar la verdad de los nuevos resultados y para proporcionar claramente las formas que el análisis emplea para sus expresiones.»
El trabajo de Fourier incorporó varios avances importantes. Además de llevar más lejos la teoría de las ecuaciones diferenciales parciales, forzó una revisión de la noción de función. Supóngase que la función y = x está representada por una serie de Fourier (20) en el intervalo (-π, π) . La serie repite su comportamiento en cada intervalo de longitud 2π. De aquí que la función dada en la serie se vea como está trazada en la Figura 28.1.

Figura 28.1
Ya hemos mencionado que el ensayo de 1807 de Fourier, en el que había sostenido que una función arbitraria puede ser desarrollada en una serie trigonométrica, no fue bien recibido por la Academia de Ciencias de París. En particular, Lagrange negó firmemente la posibilidad de tales desarrollos. A pesar de que únicamente criticó la falta de rigor en el artículo, estaba ciertamente muy incómodo por la generalidad de las funciones que Fourier manejaba, ya que Lagrange aún creía que una función estaba determinada por sus valores en un intervalo arbitrariamente pequeño, lo que es cierto para las funciones analíticas. De hecho, Lagrange regresó al problema de la cuerda vibrante y, sin mayor perspicacia que la que ya había mostrado en trabajos anteriores, insistió en defender la afirmación de Euler de que una función arbitraria no podía ser representada por una serie trigonométrica. Poisson aseguró posteriormente que Lagrange había mostrado que una función arbitraria puede ser representada por una serie de Fourier, pero Poisson —quien envidiaba a Fourier— dijo esto para robarle el mérito a Fourier y dárselo a Lagrange.
El trabajo de Fourier también hizo explícito otro hecho que estaba implícito en el trabajo de Euler y Laplace en el siglo XVIII. Estos habían desarrollado funciones en series de funciones de Bessel y polinomios de Legendre para poder resolver problemas específicos. El hecho general que una función podía ser desarrollada en una serie de funciones como las funciones trigonométricas, funciones de Bessel y polinomios de Legendre fue puesto a la luz por el trabajo de Fourier. Demostró, más adelante, cómo la condición inicial impuesta sobre la solución de una ecuación diferencial parcial podía ser satisfecha y así se avanzó en las técnicas de solución de dichas ecuaciones. El ensayo de Fourier de 1811, aunque no fue publicado hasta 1824-1826, mientras tanto fue hecho accesible a otros; sus ideas, en un principio aceptadas dificultosamente, finalmente ganaron su aceptación.
El método de Fourier fue seguido inmediatamente por Simeón Denis Poisson (1781-1840), uno de los más grandes analistas del siglo XIX y un físico matemático de primera clase. A pesar de que su padre había querido que estudiara medicina, se convirtió en estudiante y más tarde profesor de la fuente francesa de las matemáticas del siglo XIX: l’Ecole Polytechnique. Trabajó en la teoría del calor, fue uno de los fundadores de la teoría matemática de la elasticidad y uno de los primeros en sugerir que la teoría del potencial gravitacional podía ser extendida a la electricidad estática y al magnetismo.
Poisson estaba tan impresionado con la afirmación de Fourier de que funciones arbitraria podían ser desarrolladas en una serie de funciones que pensó que todas las ecuaciones diferenciales parciales podían ser resueltas mediante series; cada término de la serie sería asimismo un producto de funciones (cf. [10]), uno para cada variable independiente. Estas expansiones, pensó, comprenden las soluciones más generales. También creyó que si una expansión divergía, eso significaba que se debía buscar una expansión en términos de otras funciones. Por supuesto, Poisson era demasiado optimista.
A partir de 1815, él mismo resolvió buen número de problemas de conducción del calor y utilizó desarrollos en funciones trigonométricas, polinomios de Legendre y armónicos superficiales de Laplace. Encontraremos parte de este trabajo más adelante. Gran parte del trabajo de Poisson sobre conducción de calor fue presentado en su Théorie mathématique de la chaleur (Teoría matemática del calor, 1835).
3. Soluciones explícitas: la integral de Fourier
A pesar del éxito e impacto de las series de Fourier como soluciones de ecuaciones diferenciales parciales, uno de los mayores esfuerzos durante el siglo XIX fue hallar soluciones en forma explícita, esto es, en términos de funciones elementales e integrales de tales funciones. Tales soluciones, al menos las de tipo conocido en los siglos XVIII y XIX, eran más manejables, más perspicaces y más fácilmente usables en los cálculos.
El método más significativo para resolver ecuaciones diferenciales parciales en forma explícita, que surgió del trabajo iniciado por Laplace, fue la integral de Fourier. La idea se debe a Fourier, Cauchy y Poisson. Es imposible asignar prioridad a este descubrimiento tan importante, ya que todos ellos presentaron ensayos orales a la Academia de Ciencias que no fueron publicados sino hasta algún tiempo después. Pero cada uno escuchó los ensayos de los otros, y resulta imposible aseverar, a partir de las publicaciones, lo que cada uno de ellos tomó de las versiones orales.
En la última sección de su ensayo ganador de 1811, Fourier trató la propagación del calor en dominios que se extendían al infinito en una dirección. Para obtener una respuesta a tales problemas, empieza con la forma general de la solución de la ecuación del calor para un dominio acotado, a saber (cf[10]),
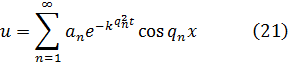
donde las qn están determinadas por las condiciones de frontera y las an por las condiciones iniciales. Fourier considera ahora las qncomo abscisas de una curva y las an como ordenadas de esa curva. Entonces an = Q(qn) donde Q es una función de q. Entonces reemplaza (21) por
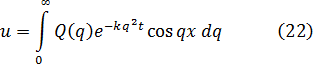
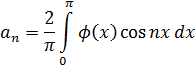
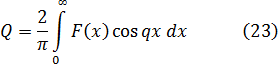
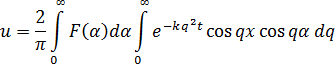
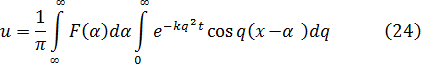
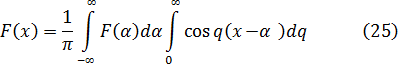

La derivación de Cauchy de la integral de Fourier es de alguna manera similar. El artículo en el que apareció, «Théorie de la propagation des ondes» («Teoría de la propagación de ondas»), recibió el premio de la Academia de París de 1816[373]. Este artículo es la primera investigación profunda sobre las ondas en la superficie de un fluido, una materia iniciada por Laplace en 1778. A pesar de que Cauchy establece las ecuaciones hidrodinámicas generales, se limita casi inmediatamente a casos especiales. En particular, considera la ecuación
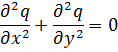
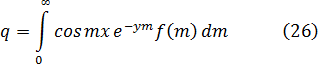

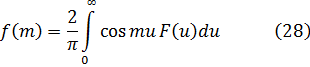

Poco tiempo después de que Cauchy entregara su ensayo ganador, Poisson, quien no podía competir por el premio, pues era miembro de la Academia, publicó un trabajo importante sobre ondas de agua, «Mémoire sur la théorie des ondes» («Memoria sobre la teoría de ondas»)[374]. En su trabajo deriva la integral de Fourier casi de la misma manera que Cauchy.
4. La ecuación del potencial y el teorema de Green
El siguiente avance significativo se centró en la ecuación del potencial, aunque el resultado principal, el teorema de Green, tiene aplicaciones en muchos otros tipos de ecuaciones diferenciales. La ecuación del potencial había figurado en el trabajo del siglo XVIII sobre gravitación y también en los estudios sobre conducción del calor del siglo XIX, referentes a que, cuando la distribución de la temperatura en un cuerpo, aunque varíe de punto a punto, permanece igual a pesar de que el tiempo varía, o cuando permanece en estado de reposo, entonces T en (1) es independiente del tiempo y la ecuación del calor se reduce a la ecuación del potencial. El interés puesto en la ecuación del potencial para el cálculo de la atracción gravitacional continuó al inicio del siglo XIX, pero acentuándose por una nueva clase de aplicaciones a la electrostática y magnetostática. Aquí, también, la atracción de los elipsoides constituyó un problema clave.
Una corrección en la teoría de la atracción gravitacional, expresada por la ecuación del potencial, fue hecha por Poisson[375]. Laplace (cap. 22, sec. 4) había supuesto que la ecuación del potencial
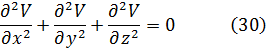
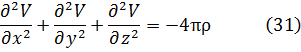
En este mismo artículo Poisson llamó la atención sobre la utilidad de la función V en investigaciones eléctricas, señalando que su valor sobre la superficie de cualquier conductor debe ser constante cuando la carga eléctrica está distribuida sobre toda la superficie. En otros artículos resolvió un buen número de problemas relativos a la distribución de la carga sobre las superficies de cuerpos conductores cuando los cuerpos se encuentran cerca uno de otro. Su principió básico fue que la fuerza electrostática resultante en el interior de cualquiera de los conductores debía ser cero.
A pesar del trabajo de Laplace, Poisson, Gauss y otros, casi nada se conocía, hacia 1820, acerca de las propiedades generales de las soluciones de la ecuación del potencial. Se pensaba que la integral general debía contener dos funciones arbitrarias, de las cuales una proporciona el valor de la solución sobre la frontera, y la otra, la derivada de la solución sobre la frontera. Sin embargo, se conocía, en el caso de la conducción de calor en estado estable, en la que la temperatura satisface la ecuación del potencial, que la temperatura o distribución del calor a través de un cuerpo tridimensional está determinada cuando sólo la temperatura está determinada sobre la superficie. De aquí que una de las funciones arbitrarias en la supuesta solución general de la ecuación del potencial debe estar dada por alguna otra condición.
En este punto, George Green (1793-1841), un matemático inglés autodidacta, se dedicó a tratar la electricidad estática y el magnetismo de una manera completamente matemática. En 1828, Green publicó un panfleto impreso en forma privada, An essay on the application of Mathematical Analysis to the Theories of Electricity and Magnetism (Un ensayo sobre la aplicación del análisis matemático a las teorías de la electricidad y el magnetismo). Esto fue ignorado hasta que sir William Thomson (lord Kelvin, 1824-1907) lo descubrió, reconoció su gran valor y lo publicó en el Journal für Mathematic[376]. Green, quien aprendió de los artículos de Poisson, llevó también la noción de función potencial a la electricidad y al magnetismo.
Empezó con (30) y demostró los siguientes teoremas: Sean U y V dos funciones continuas cualesquiera de x, y y z cuyas derivadas no son infinitas en ningún punto de un cuerpo arbitrario. El principal teorema asegura que (usaremos ΔV para el lado izquierdo de (30), aunque no fue usado por Green)
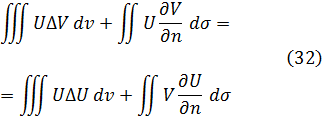
Green demostró más adelante que el requisito de que V y cada una de sus primeras derivadas fueran continuas en el interior del cuerpo puede ser impuesto en lugar de una condición de frontera sobre las derivadas de V. A la luz de este hecho, Green representó V en el interior del cuerpo, en términos de su valor V sobre la frontera (función que estaría dada) y en términos de otra función U que tiene las propiedades:
a. U debe ser 0 sobre la superficie;
b. en un punto P fijo pero indeterminado en el interior, U se hace infinita como 1/r, donde r es la distancia de cualquier otro punto a partir de P;
c. U debe satisfacer la ecuación del potencial (30) en el interior.
Si U es conocida, y podría ser más fácilmente encontrada porque satisface condiciones más simples que V, entonces V puede ser representada en todo punto interior por

Green aplicó este teorema y sus conceptos a problemas eléctricos y magnéticos. En 1833 [378] estudió también el problema del potencial gravitacional para elipsoides de densidades variables. En su trabajo, Green demostró que cuando V está dada sobre la frontera de un cuerpo, existe sólo una función que satisface ΔV = 0 en todo el cuerpo, no tiene singularidades y toma los valores dados en la frontera. Para hacer esta prueba, Green asumió la existencia de una función que minimiza
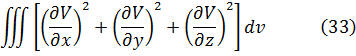
En su ensayo de 1835, Green realizó gran parte del trabajo en n dimensiones en lugar de tres y también proporcionó importantes resultados sobre lo que nosotros llamamos ahora funciones ultraesféricas, que son generalizaciones de n variables de los armónicos esféricos de Laplace. Ya que la obra de Green no fue bien conocida por mucho tiempo, algunos otros hicieron parte de su trabajo independientemente.
Green es el primero de los grandes matemáticos británicos en seguir las corrientes del trabajo hecho en el continente después de la introducción del análisis en Inglaterra. Su trabajo inspiró la gran escuela de físico-matemáticos de Cambridge, que incluía a sir William Thompson, sir Gabriel Stokes, lord Rayleigh y Clerk Maxwell.
Los logros de Green fueron seguidos por la obra maestra de Gauss de 1839[379], «Allgemeine Lehrsátze in Beziehung auf die im verkehrten Verhaltnisse des Quadrats der Entfernung wirkenden Anziehungs-und Abstossungs-krafte» («Teoremas generales sobre fuerzas atractivas y repulsivas que actúan de acuerdo con el inverso del cuadrado de la distancia»). Gauss demostró rigurosamente el resultado de Poisson, a saber, que ΔV = -4πρ en un punto dentro de la masa actuante, bajo la condición de que ρ es continua en ese punto y en un pequeño dominio alrededor de él. Esta condición no se satisface sobre la superficie de la masa actuante. En la superficie las cantidades ∂V/∂x2, ∂2V/∂y2, y ∂2V/∂z2 tienen saltos.
Hasta ahora el trabajo realizado en torno a la ecuación del potencial y la ecuación de Poisson suponía la existencia de una solución. La prueba de Green de la existencia de una función de Green se apoyaba por completo en un argumento físico. Desde el punto de vista de la existencia, el problema fundamental de la teoría del potencial era mostrar la existencia de una función potencial V, la que William Thomson, alrededor de 1850, llamó una función armónica, cuyos valores están dados sobre la frontera de una región y que satisface ΔV = 0 en la región. Se podía establecer esto directamente, o establecer la existencia de la función U de Green y de ahí obtener V. El problema de establecer la existencia de la función de Green o de la misma V es conocido como el problema de Dirichlet o el primer problema de contorno de la teoría del potencial, el problema de existencia más básico y antiguo de la materia. El problema de encontrar una V que satisface ΔV = 0 en una región cuando la derivada normal de V es especificada sobre la frontera, es llamado problema de Neumann, en homenaje a Cari G. Neumann (1832-1925), un profesor de Leipzig. A este problema se le denomina segundo problema fundamental de la teoría del potencial.
Una aproximación al problema de establecer la existencia de una solución para ΔV = 0, que Green ya había utilizado (véase [33]), fue puesta en evidencia por William Thomson. En 1847[380], Thomson anunció el teorema o principio que en Inglaterra lleva su nombre y que en el continente se menciona como el principio de Dirichlet, ya que así lo llamó Riemann. A pesar de que Thomson lo enunció en una forma un poco más general, la esencia del principio puede ser expuesta así: considérese la clase de todas las funciones U que tienen derivadas de segundo orden continuas en los dominios interior y exterior T y T', respectivamente, separados por una superficie S. Las U deben ser continuas en todas partes y tomar sobre S los valores de una función continua f. La función V que minimiza la integral de Dirichlet
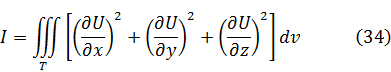
El trabajo de Riemann sobre funciones complejas dio una nueva importancia al problema de Dirichlet y al principio en sí mismo. La «prueba» de Riemann de la existencia de V en su tesis doctoral usó el caso bidimensional del principio de Dirichlet, pero no era rigurosa, de lo que se dio cuenta él mismo.
Cuando en su ensayo de 1870[381], Weierstrass presentó una crítica del principio de Dirichlet, mostró que la existencia a priori de una U minimizante no estaba apoyada por argumentos sólidos. Era correcto que para todas las funciones U diferenciablemente continuas que van continuamente del interior a los valores de frontera prescritos, la integral tiene una cota inferior. Pero que exista una función U0 en la clase de funciones diferenciables continuas que alcance la cota inferior, eso no fue establecido.
Otra técnica para la solución de la ecuación del potencial emplea la teoría de funciones complejas. A pesar de que D’Alembert, en su trabajo de 1752 (cap. 27, sec. 2), y Euler en problemas especiales, habían usado esta técnica para resolver la ecuación del potencial, no fue sino hasta mediados del siglo XIX cuando la teoría de funciones complejas se empleó vitalmente en la teoría del potencial. La relevancia de la teoría de funciones para la teoría del potencial se apoya en el hecho de que si u + iv es una función analítica de z, entonces ambas u y v satisfacen la ecuación de Laplace. Más aún, si u satisface la ecuación de Laplace, entonces la función conjugada v tal que u + iv es analítica necesariamente existe (cap. 27, sec. 8).
Cuando la ecuación Δu = 0 se utiliza en el flujo de fluidos, la función u(x,y) es lo que Helmholtz llamó potencial de velocidades y entonces ∂u/∂x y ∂u/∂y representan las componentes de la velocidad del fluido en cualquier punto (x,y). En el caso de la electricidad estática, u es el potencial electrostático y ∂u/∂x y ∂u/∂y son las componentes de la fuerza eléctrica. En ambos casos las curvas u = const. son líneas equipotenciales y las curvas v = const., que son ortogonales a u = const., son el flujo o líneas de corriente (líneas de fuerza para la electricidad). A la función v(x,y) se la llama función de corriente. La introducción de esta función, claramente, es una ayuda por su significado físico.
Una de las ventajas del uso de la teoría de las funciones complejas en la solución de la ecuación del potencial se deriva del hecho de que si F(z) = F(x + iy) es una función analítica, de tal manera que sus partes real e imaginaria satisfacen ΔV = 0, entonces la transformación de x e y en ξ y η por
![]()
ζ = ξ + iη
nos da otra función analíticaG(ζ) = G(ξ + iη)
y sus partes real e imaginaria también satisfacen ΔV(ξ, η) = 0. Ahora bien, si el problema original del potencial ΔV = 0 tiene que ser resuelto en algún dominio D, entonces por la adecuada elección de la transformación, el dominio D', en el que la transformada ΔV = 0 tiene que ser resuelta puede ser mucho más simple. Aquí el uso de transformaciones conformes tal como la transformación de Schwarz-Christoffel, es de gran utilidad.No vamos a seguir el uso de la teoría de las funciones complejas en la teoría del potencial porque los detalles de su uso van más allá de cualquier metodología básica en la solución de ecuaciones diferenciales parciales. Sin embargo, de nuevo es importante mencionar que muchos matemáticos se resistieron al uso de funciones complejas porque todavía no se reconciliaban con los números complejos. En la universidad de Cambridge, aún en 1850, se utilizaban artificios engorrosos a fin de evitar el uso de las funciones complejas. El libro de Horace Lamb Treatise on the Mathematical Theory of the Motion of Fluids (Tratado sobre la teoría matemática del movimiento de fluidos), publicado en 1879 y todavía un clásico (ahora conocido como Hydrodynamics (Hidrodinámica)), fue el primer texto en reconocer la aceptación de la teoría de funciones en Cambridge.
5. Coordenadas curvilíneas
Green introdujo un número considerable de ideas importantes cuya significación se extendía más allá de la ecuación del potencial. Gabriel Lamé (1795-1870), matemático e ingeniero preocupado en principio por la ecuación del calor, introdujo otra técnica importante: se valió de un sistema de coordenadas curvilíneas, que también podía ser usado para muchos tipos de ecuaciones. Lamé señaló en 1833[382] que la ecuación del calor había sido resuelta únicamente para cuerpos conductores cuyas superficies son normales a los planos coordenados x = const., y = const. y z = const. La idea de Lamé consistió en introducir nuevos sistemas de coordenadas y las correspondientes coordenadas en la superficie. Con ciertas restricciones esto lo habían hecho Euler y Laplace, quienes usaron coordenadas esféricas ρ, θ y ϕ, en cuyo caso las superficies coordenadas ρ = const., θ = const. y ϕ = const. son esferas, planos y conos, respectivamente. Conociendo las ecuaciones que transforman las coordenadas rectangulares en esféricas es posible, como lo fue para Euler y Laplace, transformar la ecuación del potencial de coordenadas rectangulares a esféricas.
El valor de los nuevos sistemas de coordenadas y superficies tiene dos sentidos. Primero, una ecuación diferencial parcial en coordenadas rectangulares puede no ser separable en ecuaciones diferenciales ordinarias en este sistema, pero podría ser separable en algún otro sistema. Segundo, el problema físico podría requerir una condición de contorno, digamos, sobre una elipsoide. Tal frontera, simplemente es representada en un sistema coordenado donde una familia de superficies consiste de elipsoides, mientras que en un sistema rectangular se usa una ecuación relativamente complicada. Además, después que es empleada la separación de variables en el propio sistema de coordenadas, esta condición de frontera se aplica a sólo una de las ecuaciones diferenciales ordinarias resultantes.
Lamé introdujo diversos nuevos sistemas de coordenadas con el propósito expreso de resolver la ecuación de calor en estos sistemas[383]. Su sistema principal fueron las tres familias de superficies dadas por las ecuaciones
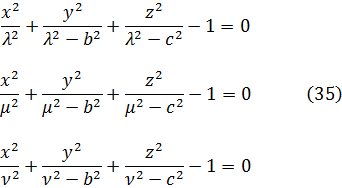
Lamé transformó la ecuación de calor para el caso del estado estacionario (la temperatura es independiente del tiempo), esto es, la ecuación del potencial, a estas coordenadas, y demostró que podía usar la separación de variables para reducir la ecuación a tres ecuaciones diferenciales ordinarias. Por supuesto, estas ecuaciones deben ser resueltas sujetas a las apropiadas condiciones en la frontera. En un ensayo de 1839[384], Lamé estudió aún más la distribución de la temperatura en el estado estacionario en un elipsoide de tres ejes, y dio una solución completa del problema tratado en su artículo de 1833. En este artículo de 1839 introdujo también otro sistema de coordenadas curvilíneas, ahora llamado el sistema esferoconal, donde las superficies coordenadas son una familia de esferas y dos familias de conos. Lamé utilizó también este sistema para resolver problemas de conducción de calor. Lamé escribió muchos otros ensayos sobre la conducción del calor utilizando coordenadas elipsoidales, incluyendo un segundo de 1839 en el mismo volumen del Journal de Mathématiques, donde trata casos especiales del elipsoide[385].
La cuestión de las familias de superficies mutuamente ortogonales tenía tan obvia importancia en la solución de ecuaciones en derivadas parciales que se convirtió en una materia de investigación en sí y por sí misma. En un artículo de 1834[386] Lamé consideró las propiedades generales de tres familias cualesquiera de superficies mutuamente ortogonales y proporcionó un procedimiento para expresar una ecuación diferencial parcial en cualquier sistema ortogonal de coordenadas, una técnica que se ha venido utilizando continuamente desde entonces.
(Heinrich) Eduard Heine (1821-1881) siguió las huellas de Lamé. Heine, en su tesis doctoral de 1842[387], determinó el potencial (temperatura en el estado estacionario) no únicamente para el interior de una elipsoide de revolución cuando el valor del potencial está dado sobre la superficie, sino también para el exterior de dicho elipsoide y para la concha entre elipsoides cofocales de revolución.
Lamé estaba tan impresionado por lo que él y otros habían logrado mediante el uso de sistemas de coordenadas triplemente ortogonales que pensó que todas las ecuaciones diferenciales parciales se podían resolver encontrando un sistema adecuado. Más tarde se dio cuenta de que esto era un error. En 1859 publicó un libro sobre la materia Leçons sur les coordonnées curvilignes (Lecciones sobre las coordenadas curvilíneas).
Aunque del uso de familias mutuamente ortogonales de superficies como superficies coordenadas no resolvió todas las ecuaciones diferenciales parciales, abrió una nueva técnica que podía explotarse ventajosamente en muchos problemas. El uso de coordenadas curvilíneas se llevó a otras ecuaciones diferenciales parciales. Así, Emile Leonard Mathieu (1835-1900), en un ensayo de 186 8 [388], trató las vibraciones de una membrana elíptica, que involucra la ecuación de ondas, e introdujo coordenadas cilíndricas elípticas y funciones apropiadas para estas coordenadas, ahora llamadas funciones de Mathieu (cap. 29, sec. 2). En el mismo año, Heinrich Weber (1842-1913), trabajando en la ecuación ∂2u/∂x2 + ∂2u/∂y2 + k2u = 0, la resolvió[389] para un dominio limitado por una elipse completa y también para la región limitada por los dos arcos de elipses cofocales y dos arcos de hipérbolas cofocales con las elipses. El caso especial en el que las elipses se convierten en parábolas cofocales fue tratado también, y aquí Weber introdujo funciones apropiadas para las expansiones en este sistema de coordenadas, ahora llamadas funciones de Weber o funciones cilíndricas parabólicas. En su Cours de physique mathématique (Curso de física matemática, 1873), Mathieu atacó nuevos problemas usando elipsoides e introdujo otras funciones nuevas.
Nuestra discusión —iniciada con Lamé— en torno al uso de coordenadas curvilíneas, describe únicamente el inicio de su trabajo. Muchos otros sistemas de coordenadas se habían introducido ya, al igual que funciones especiales resultantes de resolver ecuaciones diferenciales ordinarias que surgen de la separación de variables[390]. La mayor parte de esta teoría de funciones especiales fue creada por físicos, tal y como se iban necesitando de acuerdo a sus propiedades en problemas concretos (véase también el cap. 29).
6. La ecuación de ondas y la ecuación de ondas reducida
Tal vez el tipo más importante de ecuación diferencial parcial es la ecuación de ondas. En tres dimensiones espaciales la forma básica
es
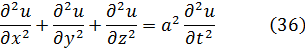
Donde la separación de variables es posible, la técnica para resolver (36) no es diferente de lo que hizo Fourier con la ecuación del calor o lo hecho por Lamé después de expresar la ecuación del potencial en algún sistema de coordenadas curvilíneas. El uso por Mathieu de las coordenadas curvilíneas para resolver la ecuación de ondas mediante la separación de variables es típico de cientos de artículos.
Tratando la ecuación como un todo se obtuvo una clase distinta e importante de resultados para la ecuación de ondas. El primero de estos resultados importantes es para problemas de valores iniciales y se remonta hasta Poisson, quien trabajó sobre esta ecuación durante los años de 1808 a 1819. Su logro principal[391] fue la fórmula para la propagación de una onda u(x,y,z,t) cuyo estado inicial está descrito por las condiciones iniciales
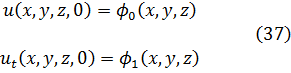
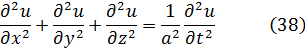
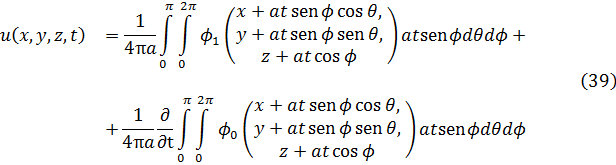
Para obtener alguna indicación de lo que significa el resultado de Poisson, consideremos un ejemplo físico.
Supongamos que la perturbación inicial está originada por un cuerpo V (Fig. 28.2) con frontera S de tal manera que ϕ0 y ϕ1 están definidas sobre V y son 0 fuera de V.
Nosotros decimos que la perturbación original está localizada en V. Físicamente, una onda sale de V y se extiende en el espacio.
Figura 28.2
En t = d/a, la esfera Sat únicamente toca a S, así que el frente de la onda emanando de S llega precisamente a P. Entre t = d/a y t = D/a la esfera Sat corta a V y de ese modo u(P,t) ≠ 0.
Finalmente, para t > D/a, la esfera Sat no cortará a S (la región entera V cae dentro de Sat); es decir, la perturbación inicial ha pasado a través de P. Así, de nuevo u(P,t) = 0. El instante t = D/a corresponde al paso del borde de la onda a través de P. En cualquier tiempo dado t, el borde anterior de la onda toma la forma de una superficie que separa los puntos a los que ha llegado la perturbación de aquellos a los que no lo ha hecho. Este borde anterior es la envolvente de la familia de esferas con centros sobre S y con radios at. El borde posterior de la onda en el tiempo t es una superficie que separa puntos en los que la perturbación existe de aquellos en los que la perturbación ya pasó. Vemos, entonces, que la perturbación que está localizada en el espacio da origen en cada punto P a un efecto que sólo dura por un tiempo finito. Más aún, la (perturbación) de onda tiene un borde anterior y uno posterior. Este fenómeno, en su totalidad, es llamado el principio de Huygens.
Una forma bastante diferente de resolver problemas de valor inicial para la ecuación de ondas fue creado por Riemann en el transcurso de su trabajo sobre la propagación de ondas de sonido de amplitud finita[392]. Riemann considera una ecuación diferencial lineal de segundo orden que puede ser puesta en la forma
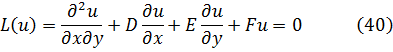
Figura 28.3

Riemann introdujo los segmentos PP1 y PP2 de las características (él no usó este término) x = ξ, y = η pasando por P. Ahora se aplica una generalización del teorema de Green (en dos dimensiones) a la expresión diferencial L(u). Para expresar el teorema en una forma resumida, introduzcamos
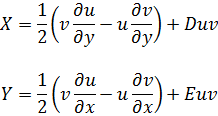

Además de satisfacer (41), Riemann requiere de v que cumpla[394]
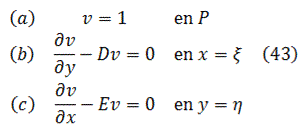

Ahora, u está dada en P1 y P2. La función v debe ser encontrada resolviendo M(v) = 0 y cumpliendo las condiciones en (43). De esta forma, lo que logra el método de Riemann es cambiar el problema original del valor inicial para u en otro tipo de problema de valor inicial, ahora para v. Generalmente, el segundo problema es más fácil de resolver. En el problema físico de Riemann fue especialmente fácil encontrar v. Sin embargo, la existencia general de tal v no fue establecida por Riemann.
El método de Riemann, como fue descrito con anterioridad, es útil únicamente para el tipo de ecuación especificada por la ecuación de ondas (ecuaciones hiperbólicas) en dos variables independientes y no podía ser extendido directamente. La extensión del método a más de dos variables independientes se enfrenta a la dificultad de que la función de Riemann se hace singular sobre la frontera del dominio de integración y la integral diverge. El método ha sido extendido, pero incrementando las complicaciones.
El progreso en la solución de la ecuación de ondas por otros métodos está íntimamente conectado con los llamados problemas de estado estacionario que condujeron a la ecuación de onda reducida. La ecuación de onda, por su misma forma, incluye la variable tiempo. En muchos problemas físicos, donde uno está interesado en ondas armónicas simples, se supone que u = w(x,y,z)eikt, y sustituyendo esto en la ecuación de ondas se obtiene
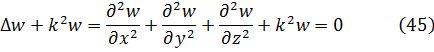
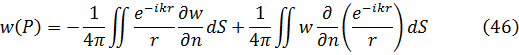
Gustav R. Kirchhoff (1824-1887), uno de los más grandes físico-matemáticos alemanes del siglo XIX, se valió del trabajo de Helmholtz para obtener otra solución del problema de valor inicial para la ecuación de ondas. Supongamos que Δw + k2w = 0 viene de
![]()

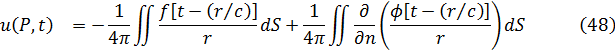
Hemos hecho notar que Riemann usó una especie de generalización del teorema de Green. La generalización ulterior del teorema de Green que emplea la ecuación diferencial adjunta y que es llamado también teorema de Green, proviene de un ensayo de Paul Du Bois Reymond (1831-1889)[397] y de la Théorie générale des surfaces (Teoría general de superficies) de Darboux[398]; ambos citan el ensayo de Riemann de 1858/1859. Si la ecuación dada es
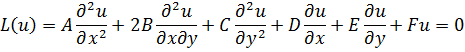
![]()
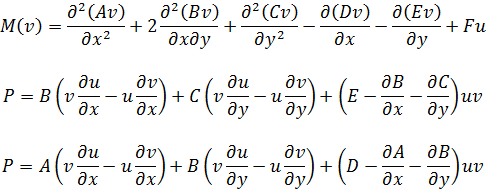
La importancia del teorema de Green reside en que puede ser usado para obtener soluciones de algunas ecuaciones diferenciales parciales. Así, ya que la ecuación elíptica puede ser siempre puesta en la forma
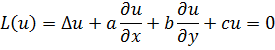
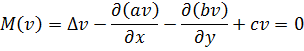
![]()
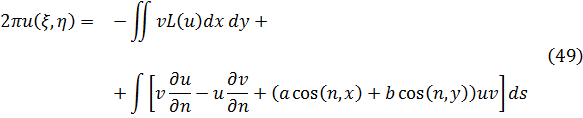
7. Sistemas de ecuaciones en derivadas parciales
En el siglo XVIII las ecuaciones diferenciales del movimiento de fluidos fueron el primer sistema importante de ecuaciones diferenciales parciales. En el siglo XIX fueron creados tres sistemas fundamentales más —las ecuaciones de la dinámica de fluidos para medios viscosos, las ecuaciones del medio elástico y las ecuaciones de la teoría electromagnética.
La adquisición de las ecuaciones del movimiento de fluidos cuando la viscosidad está presente (como siempre está) siguió un camino tortuoso. Euler había proporcionado las ecuaciones del movimiento de un fluido que no es viscoso. Desde los tiempos de Lagrange ya había sido reconocida la diferencia esencial entre el movimiento de un fluido cuando existe un potencial de velocidades y cuando no. Llevado por una analogía formal con la teoría de la elasticidad y por la hipótesis de moléculas animadas por fuerzas repulsivas, Claude L. M. H. Navier (1785-1836), profesor de mecánica de la Ecole Polytechnique y de la Ecole des Ponts et Chaussées, obtuvo la ecuación básica en 1821[399]. Las ecuaciones de Navier-Stokes, como son ahora identificadas, son
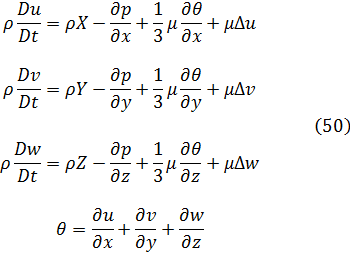
Las ecuaciones las obtuvo también Poisson en 1829 [400]. Después fueron encontradas de nuevo en 1845 sobre la base de la mecánica del continuo por George Gabriel Stokes (1819-1903), profesor de matemáticas de la universidad de Cambridge, en su ensayo «On the theories of the internal friction of fluids in motion» («Sobre las teorías de la fricción interna de fluidos de movimiento»)[401]. Stokes se propuso explicar la acción de la fricción en todos los líquidos conocidos, lo que causa que el movimiento ceda al convertirse la energía cinética en calor. Los fluidos, en virtud de su viscosidad, se adhieren a las superficies de los sólidos y de esta manera ejercen fuerzas tangenciales sobre ellos.
La elasticidad fue fundada por Galileo, Hooke y Mariotte, y cultivada por los Bernoulli y Euler, aunque éstos trataron problemas específicos. Para resolverlos combinaron hipótesis ad hoc sobre cómo las vigas, varillas y láminas se comportaban bajo tensiones, presiones y pesos. La teoría propiamente dicha es una creación del siglo XIX. Desde el principio del siglo XIX un buen número de grandes hombres trabajaron persistentemente para obtener las ecuaciones que gobiernan el comportamiento de los medios elásticos, lo que incluye el aire. Estos científicos eran principalmente ingenieros y físicos; Cauchy y Poisson son los grandes matemáticos de entre ellos, aunque Cauchy era ingeniero por su formación.
Los problemas de elasticidad incluyen el comportamiento de cuerpos bajo tensión, donde se considera qué posición de equilibrio tomarán las vibraciones de los cuerpos cuando permanecen en movimiento por una perturbación inicial o mediante una fuerza aplicada continuamente, y, en el caso del aire y los cuerpos sólidos, la propagación de las ondas a través de ellos. El interés por la elasticidad en el siglo XIX fue intensificado por la aparición, alrededor de 1820, de una teoría ondulatoria de la luz, iniciada por el físico Thomas Young (1773-1829) y por Augustin-Jean Fresnel (1788-1827), un ingeniero. La luz era concebida como un movimiento de ondas en el éter y el éter era pensado como un medio elástico. De aquí que la propagación de la luz a través del éter se convirtiera en un problema básico. Otro estímulo para el fuerte interés por la elasticidad en el siglo XIX lo fueron los experimentos (1787) de F. F. Chladni (1756-1827) sobre las vibraciones del vidrio y metal, en las que mostró las líneas nodales. Estas deben ser relacionadas con los sonidos proporcionados por, como ejemplo, una piel de tambor vibrando.
El trabajo para obtener las ecuaciones básicas de la elasticidad fue largo y lleno de escollos porque se sabía poco de la estructura interna o molecular de la materia; era difícil comprender cualquier problema físico. Las hipótesis hechas en cuanto a los cuerpos sólidos, el aire y el éter variaban de un autor a otro y estaban en disputa. En el caso del éter, que supuestamente penetraba los cuerpos sólidos, dado que la luz pasaba a través de algunos de ellos y era absorbida por otros, la relación de las moléculas del éter con las moléculas del cuerpo sólido también provocó grandes dificultades. No pretendemos seguir las teorías físicas de los cuerpos elásticos, nuestro entendimiento en este terreno no es claro ni aún hoy día.
Navier [402] fue el primero (1821) en investigar las ecuaciones generales del equilibrio y las vibraciones de los cuerpos elásticos. Se suponía que el material era isótropo y las ecuaciones contenían una constante única representando la naturaleza del sólido. En 1822, estimulado por el trabajo de Fresnel, Cauchy había creado otro enfoque de la teoría de la elasticidad[403]. Las ecuaciones de Cauchy contenían dos constantes para representar el material del cuerpo, y para un cuerpo isótropo son
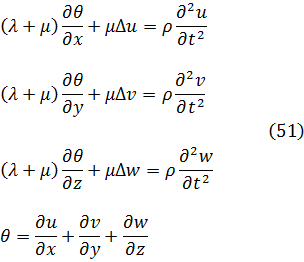
El triunfo más espectacular del siglo XIX, con un enorme impacto sobre la ciencia y la tecnología, fue la derivación por Maxwell de las leyes del electromagnetismo[405]. Maxwell, utilizando las investigaciones eléctricas y magnéticas de numerosos predecesores, notablemente las de Faraday, introdujo la noción de corriente de desplazamiento —las ondas de radio son una forma de corriente de desplazamiento— y con esta noción formuló las leyes de la propagación de ondas electromagnéticas. Sus ecuaciones, más convenientemente enunciadas en la forma vectorial adoptada posteriormente por Oliver Heaviside, son cuatro en número y hacen intervenir el campo eléctrico de intensidad E, el campo magnético de intensidad H, la constante dieléctrica ε del medio, la permeabilidad magnética μ del medio y la densidad de carga p. Las ecuaciones[406] son
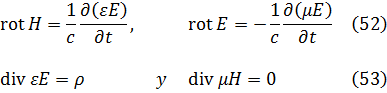
Trabajando únicamente con estas ecuaciones, Maxwell predijo que las ondas electromagnéticas viajaban a través del espacio y a la velocidad de la luz. Sobre la base de la identidad de las dos velocidades, se atrevió a asegurar que la luz es un fenómeno electromagnético, una predicción que ha sido ampliamente confirmada desde entonces.
No se conocen métodos generales para resolver ninguno de los sistemas de ecuaciones anteriores. Sin embargo, los científicos del siglo XIX se dieron cuenta gradualmente de que en el caso de las ecuaciones diferenciales parciales, ya fueran simples ecuaciones o sistemas, las soluciones generales no son tan claramente útiles como las soluciones para problemas específicos donde las condiciones iniciales y de frontera están dadas, y el trabajo experimental también puede ayudar haciendo suposiciones simplificadas útiles. Los escritos de Fourier, Cauchy y Riemann llevaron más lejos esta tendencia. El trabajo sobre la solución de los muchos problemas de valor inicial y de frontera a los que especializaciones de estos sistemas dieron origen es enorme y la gran mayoría de los matemáticos del siglo se dedicaron a dichos problemas.
8. Teoremas de existencia
Así como los matemáticos de los siglos XVIII y XIX crearon un vasto número de tipos de ecuaciones diferenciales, se encontraron con que los métodos para resolver muchas de estas ecuaciones no estaban prontos. De la misma manera que en el caso de las ecuaciones polinominales, donde los esfuerzos por resolver ecuaciones de grado mayor que cuatro fallaron, y Gauss se volvió hacia la prueba de la existencia de una raíz (cap. 25, sec. 2), así en el caso de las ecuaciones diferenciales el fracaso en encontrar soluciones explícitas, las que por supuesto demuestran ipso fado la existencia, forzaron a los matemáticos a volverse hacia demostraciones de la existencia de las soluciones. Tales pruebas, a pesar de que no exhiben una solución, ni la dan de una manera útil, cumplen varios propósitos. Las ecuaciones diferenciales fueron en casi todos los casos la formulación matemática de problemas físicos. No se garantizaba que las ecuaciones matemáticas pudieran ser resueltas; una demostración de la existencia de una solución podría asegurar, al menos, que la búsqueda de una solución no representaba un imposible. La prueba de existencia también contestaría la pregunta: ¿qué debemos saber acerca de una situación física dada, esto es, qué condiciones iniciales y de frontera aseguran una solución, preferentemente única? Otros objetivos, tal vez no previstos al inicio del trabajo sobre teoremas de existencia, fueron reconocidos de inmediato. ¿La solución cambia continuamente con las condiciones iniciales, o algún fenómeno enteramente nuevo aparece cuando las condiciones de frontera o iniciales son variadas ligeramente? Así, una órbita parabólica que se obtiene para un valor de la velocidad inicial de un planeta puede cambiar a una órbita elíptica como consecuencia de un pequeño cambio de la velocidad inicial. Tal diferencia en la órbita es físicamente de lo más significativo. Más aún, algunas de los métodos de solución, tal como el uso del principio de Dirichlet, o el teorema de Green, presuponían la existencia de una solución particular. La existencia de estas soluciones particulares no había sido establecida.
Antes de dar algunas breves indicaciones del trabajo sobre teoremas de existencia, puede ser útil señalar una clasificación de las ecuaciones diferenciales parciales que fue de hecho bosquejada bastante tarde en este siglo. A pesar de que Laplace y Poisson habían realizado algunos esfuerzos hacia la clasificación, reduciendo estas ecuaciones a formas normales, la clasificación introducida por Du Bois Reymond se ha hecho obligada. En 1889[407], Du Bois Reymond clasificó, por medio de sus características, las ecuaciones lineales homogéneas más generales de segundo orden
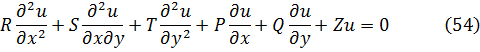
Tdx2 - Sdxdy + Rdy2 = 0
Las características son imaginarias, reales y distintas, o reales y coincidentes de acuerdo con que seaTR - S2 > 0, TR - S2 < 0, TR - S2 = 0.
Du Bois Reymond llamó estos casos elíptico, hiperbólico y parabólico, respectivamente, y señaló que introduciendo nuevas variables reales independientesξ = ϕ(x,y) η = ψ(x,y)
la ecuación anterior siempre puede ser transformada en uno de los tres tipos de formas normales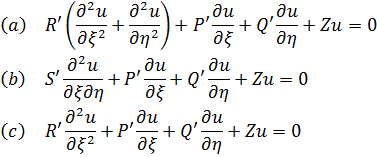
Las condiciones suplementarias que pueden ser impuestas difieren para los tres tipos de ecuaciones. En el caso elíptico (a) se considera un dominio acotado del plano xy y se especifica el valor de u en la frontera (o una condición equivalente) y se pregunta por el valor de u en el dominio. Para el problema de valor inicial de la ecuación diferencial hiperbólica (b) se debe especificar u y ∂u/∂n sobre alguna curva inicial. También puede haber condiciones en la frontera. Las condiciones iniciales apropiadas para el caso parabólico (c) no fueron especificadas en aquel momento, aunque ahora es sabido que una condición inicial y condiciones en la frontera pueden ser impuestas. Esta clasificación de las ecuaciones diferenciales parciales se extendió a ecuaciones con más variables independientes, ecuaciones de orden superior, y a sistemas. A pesar de que la clasificación y las condiciones suplementarias no eran conocidas a principios de siglo, gradualmente los matemáticos advirtieron las distinciones y éstas figuraron en los teoremas de existencia que fueron capaces de demostrar.
El trabajo sobre los teoremas de existencia se convirtió en una actividad de mayor relevancia con Cauchy, quien insistió en que la existencia puede ser establecida frecuentemente cuando aún no esté disponible una solución específica. En una serie de artículos[408], Cauchy hizo notar que cualquier ecuación diferencial parcial de orden superior a uno puede ser reducida a un sistema de ecuaciones diferenciales parciales, y se ocupó de la existencia de una solución para el sistema. Llamó a su método el calcul des limites (cálculo de límites), pero es conocido ahora como el método de las funciones mayorantes. La esencia del método es mostrar que una serie de potencias en las variables independientes con un dominio definido de convergencia satisface el sistema de ecuaciones. Ilustraremos el método en relación con el trabajo de Cauchy sobre ecuaciones diferenciales ordinarias (cap. 29, sec. 4). Su teorema cubre únicamente el caso de coeficientes analíticos en las ecuaciones y condiciones iniciales analíticas.
Para obtener una idea concreta del trabajo de Cauchy, vamos a considerar lo que implica para la ecuación de segundo orden en dos variables independientes
r = f(z, x, y, p, q, s, t) (55)
donde, como es usual, r = ∂2z/∂x2 y f es analítica en todas las variables. En este caso se debe especificar sobre la recta inicial x = 0 que sea![]()
El trabajo de Cauchy sobre sistemas lo realizó independientemente, y de alguna manera mejorado, Sophie Kowalewski (1850-1891)[409], que fue alumna de Weierstrass y prosiguió sus ideas. La Kowalewski es una de las pocas mujeres matemáticas distinguidas. En 1816, Sophie Germain (1776-1831) obtuvo un premio por un ensayo sobre elasticidad que le otorgó la Academia Francesa. Kowalewski, ganó asimismo el premio de la Academia de París, con un trabajo de 1888 sobre la integración de las ecuaciones del movimiento para un cuerpo sólido rotando alrededor de un punto fijo; en 1889 llegó a ser profesor de matemáticas en Estocolmo. Las demostraciones de Cauchy y Kowalewski fueron mejoradas posteriormente por Goursat[410].
Si, en lugar de (55), la ecuación de segundo orden dada es de la forma
G(z, x, y, p, q, r, s,t) = 0, (56)
es necesario resolverla en r antes de que pueda ser puesta en la forma (55). Para considerar un caso simple, pero esencial, si la ecuación es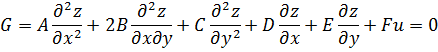
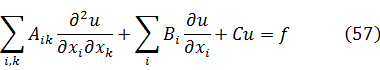
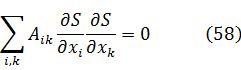
Esta teoría de las características para el caso de dos variables independientes era conocida por Monge y por André-Marie Ampère (1775-1836). Su extensión para ecuaciones de segundo orden en más de dos variables independientes lo efectuó por primera vez Albert Victor Bácklund (1845-1922)[411], pero este caso no fue ampliamente conocido hasta que no lo rehízo Jules Beudon [412].
En su Leçons sur la propagation des ondes (Lecciones sobre la propagación de ondas, 1903), Jacques Hadamard (1865-1963), el gran matemático francés de este siglo, generalizó la teoría de las características para ecuaciones diferenciales parciales de segundo orden en las variables dependientes ξ, η y ζ y las variables independientes x1, x2…xn. El problema de Cauchy para este sistema es: dados los valores de ξ, η, ζ y ∂ξ/∂Xn, ∂η/∂Xn y ∂ζ/∂Xn, sobre la «superficie» Mn-1 de dimensión n - 1, encontrar las funciones ξ, η y ζ . Los valores de ξ, η, ζ y ∂ξ/∂xn, ∂η/∂xn y ∂ζ/∂xn sobre la «superficie» lados a menos que Mn-1 satisfaga una ecuación diferencial parcial de primer orden de sexto grado, digamos H = 0. Todas las «superficies» que cumplen H = 0 son «superficies» características. De acuerdo con la teoría de ecuaciones diferenciales parciales de primer orden, la ecuación diferencial H = 0 tiene líneas (curvas) características definidas por
Las características juegan ahora un papel vital en la teoría de ecuaciones en derivadas parciales. Por ejemplo, Darboux [413] proporcionó un método poderoso para integrar ecuaciones diferenciales parciales de segundo orden en dos variables independientes que se basa en la teoría de las características: transforma el problema en la integración de una o más ecuaciones diferenciales ordinarias e incluye los métodos de Monge, Laplace y otros.
Otro caso de teoremas de existencia trataba el problema de Dirichlet, esto es, estableciendo la existencia de una solución para ΔV = 0, ya fuera directamente o por medio del principio de Dirichlet. La primera prueba de existencia del problema de Dirichlet en dos dimensiones (pero no del principio de Dirichlet de minimizar la integral de Dirichlet) fue proporcionado por Hermann Amandus Schwarz (1843-1921), alumno de Weierstrass, a quien sucedió en Berlín en 1892, quien le sugirió el problema. Bajo hipótesis generales acerca de la curva frontera y usando un proceso llamado el procedimiento de la alternativa[414] , demostró la existencia de una solución.[415]
En el mismo año, 1870, Cari G. Neumann proporcionó otra demostración de la existencia de una solución al problema de Dirichlet en tres dimensiones[416], usando el método de medias aritméticas, a pesar de que él mismo tampoco usó el principio de Dirichlet[417]. La principal exposición de sus ideas está en su Vorlesungen uber Riemann’s Theorie des AbeVschen Intégrale (Lecciones sobre la teoría de Riemann de las integrales abelianas)[418].
Entonces Poincaré [419] utilizó el méthode de balayage (el método de «barrido»), que ataca el problema construyendo una sucesión de funciones no armónicas en el dominio R pero tomando los valores de contorno correctos, haciendo las funciones más y más armónicas.
Finalmente, David Hilbert reconstruyó el método del cálculo de variaciones de Thomson y Dirichlet, y estableció el principio de Dirichlet como un método para probar la existencia de una solución del problema de Dirichlet. En 1899[420], Hilbert demostró que bajo las condiciones adecuadas sobre una región, los valores en la frontera y las funciones admisibles U, se cumple el principio de Dirichlet, e hizo del principio de Dirichlet una herramienta poderosa en la teoría de funciones. En otras publicaciones respecto a trabajos realizados en 1901[421], Hilbert proporcionó condiciones más generales.
La historia del principio de Dirichlet es notable. Green, Dirichlet, Thomson y otros de sus contemporáneos lo consideraban como un método bien fundado, utilizándolo libremente. Más adelante, Riemann, en su teoría de funciones complejas, demostró que era un instrumento extraordinario para llegar a resultados importantes. Todos estos hombres eran conscientes de que la cuestión fundamental de la existencia no estaba aclarada, aún antes de que Weierstrass anunciara su crítica de 1870, que desacreditó el método durante varias décadas. Entonces Hilbert rescata el principio que fue usado y difundido en este siglo. Si el progreso que se había logrado con el uso de este principio hubiera esperado el trabajo de Hilbert, gran parte del trabajo sobre teoría del potencial y teoría de funciones del siglo XIX se hubiera perdido.
La ecuación de Laplace ΔV = 0 es la forma básica de las ecuaciones diferenciales elípticas. Se establecieron muchos más teoremas de existencia para más ecuaciones diferenciales elípticas generales, tales como
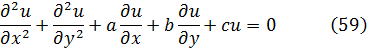
Los teoremas discutidos hasta aquí han tratado generalmente de ecuaciones diferenciales y datos iniciales o de frontera analíticos. Sin embargo, tales condiciones son demasiado restrictivas para las aplicaciones, porque los datos físicos dados pueden no ser analíticos. Otra clase importante de teoremas trata de condiciones menos restringidas. Daremos un solo ejemplo. El método de Riemann, que se aplica a la ecuación hiperbólica, se apoya en la existencia de su función característica v y, como señalamos, la existencia de v no fue establecida por Riemann.
Para este caso hiperbólico (véase [40]), Du Bois Reymond buscó en 1889 las condiciones adecuadas y obtuvo resultados[424] que, expresados para el caso donde x = const. e y = const. son las características, dicen: dadas dos funciones continuas u y ∂u/∂n a lo largo de una curva AB que no es cortada más de una vez por cualquier línea característica, existe entonces una y solamente una solución u de la ecuación diferencial que toma los valores dados de u y ∂u/∂n a lo largo de AB. Esta solución está definida en el rectángulo determinado por las características que pasan por A y B. Si en lugar de esto se dan los valores de una función continua u sobre dos segmentos de características que colindan uno con otro, entonces de nuevo u está determinada únicamente en el rectángulo determinado por las características. En términos de x, y y u como coordenadas espaciales, el primer resultado afirma que la superficie u(x,y) pasa a través de una curva dada en el espacio y con una inclinación dada. El segundo resultado significa que la solución o superficie está encerrada en el espacio determinado por dos curvas que se cortan. Para condiciones iniciales continuas u y ∂u/∂n (y u en el segundo caso), las soluciones serán regulares o bien satisfacen la ecuación diferencial en todo punto de los rectángulos descritos anteriormente. Las discontinuidades en u y ∂u/∂n se propagarán a lo largo de las características en el rectángulo.
Una gran cantidad de trabajo sobre la existencia de los valores característicos para Δu + k2u = 0, considerada en el dominio D, fue realizada en la segunda mitad del siglo. El resultado principal es que, para un dominio dado y bajo cualquiera de las condiciones en la frontera u = 0, ∂u/∂n = 0, ∂u/∂n + hu = 0 (h > 0 cuando la normal está dirigida fuera del dominio), existe siempre un número infinito de valores discretos de k2, y que para cada uno de ellos existe una solución. En dos dimensiones, las vibraciones de una membrana fijada a lo largo de su frontera ilustran este teorema. Los valores de k son las frecuencias de la infinidad de vibraciones puramente armónicas. Las soluciones correspondientes proporcionan la deformación de la membrana al llevar a cabo sus oscilaciones características.
El primer gran paso fue la demostración de Schwarz[425] de la existencia de la primera función característica de
Δu + ξ f(x,y)u = 0
esto es, la existencia de una U1 tal queΔU1 + k12f(x, y)U1 = 0
y U1 = 0 sobre la frontera del dominio considerado. Su método proporcionó un procedimiento para encontrar la solución y permitió el cálculo de k12. Picard[426] estableció entonces la existencia del segundo valor característico k22.En su artículo de 1885, Schwarz también demostró que cuando el dominio varía continuamente, el valor de k12, el primer número característico, también varía continuamente; y al mismo tiempo que el dominio se hace más pequeño, k12 se incrementa sin límite. Así, una membrana pequeña da origen a un primer armónico superior.
En 1894, Poincaré [427] demostró la existencia y las propiedades esenciales de los valores característicos de
Δu + λu = f (60)
con λ complejo, en un dominio tridimensional acotado, con u = 0 sobre la frontera. La existencia de u fue demostrada mediante una generalización del método de Schwarz. Acto seguido demostró que u(λ) es una función meromorfa de la variable compleja λ y que los polos son reales; éstos son justamente los valores propios λn. Entonces obtuvo las soluciones características Ui; esto es,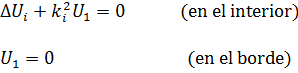
Físicamente, el resultado de Poincaré tiene el significado siguiente. La función f en (60) puede pensarse como una fuerza aplicada. Las oscilaciones libres de un sistema mecánico son aquellas en que las oscilaciones forzadas degeneran y se hacen infinitas. De hecho, (60) es la ecuación de un sistema oscilante excitado por una fuerza variando periódicamente de amplitud f; y las soluciones características son las oscilaciones libres del sistema, que, una vez excitadas, continúan indefinidamente. Las frecuencias de las oscilaciones libres, que son proporcionales a ki, se calculan mediante el método de Poincaré como los valores √λi para los cuales la oscilación forzada u se hace infinita.
Al final del siglo, la teoría sistemática de problemas de frontera y de valores iniciales para ecuaciones diferenciales parciales, que datan del ensayo fundamental de Schwarz de 1885, aún era muy joven. El trabajo en esta área se extendió rápidamente en el siglo XX.
Bibliografía
- Bacharach, Max: Abriss der Geschicbte der Potentialtheorie, Vandenhoeck y Ruprecht, 1883.
- Burkhardt, H.: «Entwicklungen nach oscillirenden Functionen und Integration der Differentialgleichungen der mathematischen Physik», Jahres. der Deut. Matb.-Verein., vol. 10, 1908, 1-1804.
- Burkhardt, H. y Franz Meyer, W.: «Potentialtheorie», Encyk. der Math. Wiss., B. G. Teubner, 1899-1916, II A7b, 464-503.
- Cauchy, Augustin Louis: Œuvres completes, Gauthier-Villars, 1890 (2), 8.
- Fourier, Joseph: The Analytical Theory of Heat (1822). Dover, reimpresión de la traducción inglesa, 1955. : Œuvres, 2 vols., Gauthier-Villars, 1888-1890; Georg Olms (reimpresión), 1970.
- Green, George: Essay on the Application on Mathematical Analysis to the Theories of Electricity and Magnetism, 1828, reimpresa por Wezata Melins Aktiebolang, 1958; también en Ostwald’s Klassiker 61 (en alemán), Wilhelm Engelmenn, 1895. : Mathematical Papers, Macmillan, 1871; Chelsea (reimpresión), 1970.
- Heine, Eduard: Handbuch der Kugelfunktionen, 2 vols., 1878-1881, Physika Verlag (reimpresión), 1961.
- Helmholtz, Hermann von: «Theorie der Luftschwingungen in Róhren mit offenen Enden», Ostwald’s Klassiker der exakten Wissenschaften, Wilhelm Engelmenn, 1896.
- Klein, Félix: Vorlesungen uber die Entwicklung der Mathematik im 19. Jahrhundert, 2 vols., Chelsea (reimpresión), 1950.
- Langer, R. E.: «Fourier Series, the Génesis and Evolution of a Theory», Amer. Math. Monthly 54, Part II, 1947, 1-86.
- Pockels, Friederich: Über die partidle Differentialgleichung Au + k2p = 0, B. G. Teuber, 1891.
- Poincaré, Henri: Œuvres, Gauthier-Villars, 1954, 9.
- Rayleigh, lord (Strutt, John William): The Theory of Sound, 2.a ed., 2 vols., Dover (reimpresión), 1945.
- Riemann, Bernhard: Gesammelte mathematische Werke, 2.a ed., Dover (reimpresión), 1953, pp. 156-211.
- Sommerfield, Arnold: «Randwertaufgaben in de Theorie der partiellen Differentiallgleichungen», Encyk. der math. Wiss., B. G. Teubner, 1899-1916, II A7c, 504-570.
- Todhunter, Isaac y Pearson, Karl: A History of the Theory of Elascticity, 2 vols., Dover (reimpresión), 1960.
- Whittaker, sir Edmund: History of the Theories of Aether and Electricity, ed. rev., Thomas Nelson and Sons, 1951, vol. I.
Capítulo 29
Las ecuaciones diferenciales ordinarias en el siglo XIX
La física no solamente nos ha dado la ocasión de resolver problemas (...) sino que también nos ha hecho presentir la solución.
Henri Poincaré
1. Introducción1. Introducción
2. Soluciones con series y funciones especiales
3. La teoría de Sturm-Liouville
4. Teoremas de existencia
5. La teoría de singularidades
6. Las funciones automorfas
7. El trabajo de Hill sobre soluciones periódicas de las ecuaciones lineales
8. Ecuaciones diferenciales no lineales: la teoría cualitativa
Bibliografía
Las ecuaciones diferenciales ordinarias surgieron en el siglo XVIII como una respuesta directa a problemas físicos. Al estudiar fenómenos físicos complicados, notablemente en los trabajos sobre la cuerda vibrante, los matemáticos llegaron a las ecuaciones en derivadas parciales. En el siglo XIX, los papeles que jugaron estas dos materias se invirtieron. El esfuerzo para resolver ecuaciones diferenciales parciales por el método de separación de variables condujo al problema de resolver ecuaciones diferenciales ordinarias. Más aún, puesto que las ecuaciones diferenciales parciales fueron expresadas en diversos sistemas de coordenadas, las ecuaciones diferenciales ordinarias resultantes que se presentaron eran extrañas e insolubles en forma explícita. Los matemáticos recurrieron a soluciones en series infinitas, que son actualmente conocidas como funciones especiales, de funciones trascendentes superiores como opuestas a las funciones trascendentes elementales tales como sen x, exy log x.
Después de mucho trabajo sobre la amplia variedad de ecuaciones diferenciales ordinarias, fueron dedicados algunos estudios teóricos profundos a ciertos tipos de tales ecuaciones. Estas investigaciones teóricas también diferenciaron el trabajo efectuado en el siglo XIX del que se hizo en el XVIII. Las contribuciones del nuevo siglo fueron tan vastas que, como en el caso de las ecuaciones diferenciales parciales, no podemos esperar revisar todos los desarrollos principales. Nuestros temas sólo representan un ejemplo de lo que fue creado durante el siglo.
2. Soluciones con series y funciones especiales
Como acabamos de observar, para resolver las ecuaciones diferenciales ordinarias que resultaron del método de separación de variables aplicadas a ecuaciones diferenciales parciales, los matemáticos, sin preocuparse gran cosa por la existencia y forma que las soluciones deberían tener, retomaron el método de las series infinitas (cap. 21, sec. 6). De las ecuaciones diferenciales ordinarias que resultaron de la separación de variables, la más importante es la ecuación de Bessel.
x2y" + xy' + (x2n2)y = 0 (1)
donde n, un parámetro, puede ser complejo y x también puede ser complejo. Sin embargo, para Friedrich Wilhelm Bessel (1784-1846), matemático y director del observatorio astronómico de Königsberg, n y x eran reales. Casos especiales de esta ecuación datan de 1703, cuando Jacques Bernoulli los mencionó como una solución particular en una carta a Leibniz, y más tarde en trabajos más extensos de Daniel Bernoulli y Euler (cap. 21, secs. 4 y 6 y cap. 22, sec. 3). Asimismo, aparecieron casos especiales en los escritos de Fourier y Poisson. El primer estudio sistemático de las soluciones de esta ecuación fue hecho por Bessel[428] mientras trabajaba sobre el movimiento de los planetas. La ecuación tiene dos soluciones independientes para cada n, denotadas hoy en día por Jn(x) y Yn(x), llamadas las funciones de Bessel de la primera y segunda clase, respectivamente. Bessel, cuyo trabajo sobre la ecuación se remonta a 1816, proporcionó primero la relación integral (para n entero)
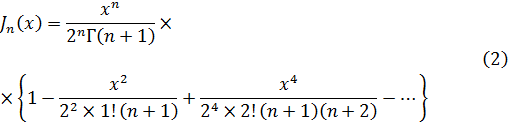
xJn+1(x) - 2nJn(x) + xJn-1(x) = 0,
y muchas otras relaciones concernientes a la función de Bessel de primera clase. La generalización de la función de Bessel Jn(x) a n y x complejas fue hecha por varios autores[429], con (2) como forma correcta.Debido a que han de existir dos soluciones independientes para una ecuación de segundo orden, muchos matemáticos las buscaron. Cuando n no es un entero, esta segunda solución es /_„(x). Para n entero, la segunda solución fue proporcionada por Carl G. Neumann[430]. Sin embargo, la forma más comúnmente adoptada hoy día fue dada por Hermann Hankel (1839-1873)[431], a saber,

f(z) = α0J0(z) + α1J1(z) + α2J2(z) + …
donde las αi son constantes y pueden ser determinadas.Muchos matemáticos, trabajando por lo general en mecánica celeste, llegaron independientemente a las funciones de Bessel y a cientos de otras relaciones y expresiones para estas funciones. Alguna idea de la vasta literatura sobre dichas funciones puede obtenerse revisando A treatise on the Theory of Bessel Functions (Un tratado sobre la teoría de las funciones de Bessel)[433] de G. N. Watson.
Los polinomios de Legendre o funciones esféricas de una variable y las funciones de esféricas de superficie, que son funciones de dos variables, habían sido ya presentadas por Legendre y Laplace (cap. 22, sec. 4). Los polinomios de Legendre satisfacen la ecuación diferencial de Legendre.
(1 — x2)y" - 2 xy'+ n(n + l)y = 0.
Esta ecuación, como la conocemos, resulta de la separación de variables aplicada a la ecuación del potencial expresada en coordenadas esféricas. En 1833, Robert Murphy (murió en 1843), miembro de la universidad de Cambridge, escribió un texto, Elementary Principies of the Theories of Electricity, Heat and Molecular Actions (Principios elementales de las teorías de electricidad, calor y acciones moleculares). En él reunió algunos viejos resultados sobre los polinomios de Legendre y obtuvo algunos nuevos. Puesto que los principales resultados eran conocidos, no presentaremos los detalles del trabajo de Murphy, excepto para puntualizar que fue sistemático y demostró que «cualquier» función f(x) puede ser desarrollada en términos de las Pn(x) aplicando la integración término a término y la propiedad de la ortogonalidad (teorema integral).Heine,[434] tratando el problema del potencial para el exterior de un elipsoide de revolución y para la concha entre elipsoides de revolución cofocales (cap. 28, sec. 5), introdujo armónicos esféricos de segunda clase, denotados comúnmente por Qn(x), que dan una segunda solución independiente de la ecuación de Legendre. Las funciones de Legendre, como las funciones de Bessel, habían sido extendidas a n complejos y x complejos y habían sido obtenidas[435] gran número de representaciones alternativas y relaciones entre ellas.
El estudio de las funciones especiales que surgen como soluciones en serie de ecuaciones diferenciales ordinarias fue llevado más lejos por Gauss en su famoso ensayo de 1812 sobre las series hipergeométricas[436]. En este ensayo, Gauss no hizo uso de la ecuación diferencial
x(1 - x)y" + (γ — (α + β + 1)x)y' - αβy = 0
pero sí lo hizo en material inédito[437]. Por supuesto, la ecuación y la solución en serie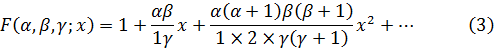

Lamé introdujo otra clase de funciones especiales[438]. En el cap. 28, sec. 5, señalamos que Lamé, trabajando sobre una distribución de temperatura en estado estacionario en un elipsoide, separó la ecuación de Laplace en coordenadas elipsoidales ρ, μy ν. Este proceso dio las mismas ecuaciones diferenciales ordinarias en cada una de las tres variables, a saber,
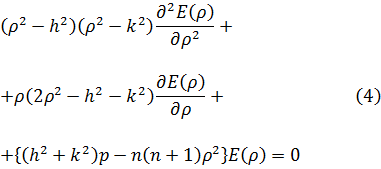
![]()
La segunda solución de la ecuación de Lamé (resultante de otras condiciones o propiedades de E(g)) es
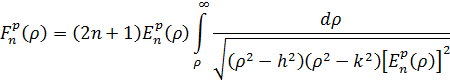
Las ecuaciones diferenciales
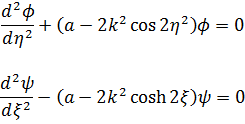
x = h cosh ξ cos η y = h senh ξ sen η
donde x = ±h, y = 0 son los focos de las elipses e hipérbolas cofocales de la familia de elipses y la familia de hipérbolas en el sistemade coordenadas elípticas. La variedad de formas en las que las ecuaciones de Mathieu están escritas, y las muchas notaciones para sus soluciones usadas por diferentes autores presenta una visión confusa. Las funciones definidas por cualquiera de las ecuaciones diferenciales fueron llamadas funciones de Heine del cilindro elíptico, y ahora son llamadas funciones de Mathieu. Mathieu y Heine fueron los primeros en obtener expresiones en series para las soluciones, y buscaron fijar el parámetro a de tal forma que una clase de soluciones sea periódica y de período 2n. El problema de encontrar soluciones periódicas —las más importantes para aplicaciones físicas— siguió a lo largo del siglo. En 1883[442], Gastón Floquet (1847-1920) publicó una discusión completa de la existencia y propiedades de las soluciones periódicas de las ecuaciones diferenciales lineales de orden w-ésimo teniendo coeficientes periódicos con el mismo período w. Habiendo sido determinadas las propiedades generales de las soluciones, autores posteriores dedicaron considerable atención al problema de descubrir métodos prácticos para hallarlas. No se encontraron métodos generales (cf. sec. 7).
Heinrich Weber (1842-1913), en 1868, introdujo una clase de funciones especiales que se estudió extensamente[443] Weber estaba interesado en integrar Δu + k2u = 0 en un dominio encerrado por dos parábolas. Por tanto, el cambio de coordenadas rectangulares a coordenadas parabólicas (que son una clase límite de coordenadas elípticas) a través de la transformación
x = ξ2 - η2 , y = 2ξη.
Para ξ = const., y para η = const., las dos familias de curvas son familias de parábolas, con cada miembro de una familia cortando los miembros de la otra ortogonalmente. Las ecuaciones diferenciales ordinarias que Weber derivó de la ecuación de ondas reducida por separación de variables son
La clase de funciones especiales es aún más extensa de lo que podemos indicar aquí. Los tipos mencionados anteriormente, y muchos otros que fueron introducidos, sirven para resolver ecuaciones diferenciales en dominios acotados y representar funciones arbitrarias (usualmente las funciones iniciales de un problema de ecuaciones diferenciales parciales) en aquel dominio. La limitación a dominios acotados está impuesta por la propiedad de ortogonalidad. En el caso básico de las funciones trigonométricas este dominio es porque, por ejemplo,
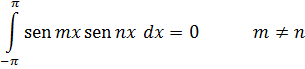
Para trabajar con todos estos tipos de funciones especiales se debe conocer íntimamente sus propiedades de la misma manera que se conocen las propiedades de las funciones elementales. Como estas funciones especiales son más complicadas, las propiedades lo son de la misma manera. La literatura, tanto en artículos originales como en textos, es increíblemente vasta. Tratados completos han sido dedicados a las funciones de Bessel, funciones esféricas, funciones elipsoidales, funciones de Mathieu y de otros tipos.
3. La teoría de Sturm-Liouville
Los problemas implicando ecuaciones diferenciales parciales de la física matemática contienen comúnmente condiciones de frontera, tales como la condición de que la cuerda vibrante debe estar fija en los extremos. Cuando el método de separación de variables se aplica a una ecuación diferencial parcial, esta ecuación se descompone en dos o más ecuaciones diferenciales ordinarias, y las condiciones de frontera sobre la solución deseada se convierten en condiciones de frontera sobre una ecuación diferencial ordinaria. La ecuación ordinaria contiene generalmente un parámetro, que de hecho resulta del procedimiento de separación de variables y las soluciones se obtienen usualmente para valores particulares del parámetro. Estos valores son llamados los valores propios o valores característicos y la solución para cualquier valor propio es llamada una función propia. Más aún, para satisfacer la condición o condiciones iniciales del problema original es necesario expresar una función f(x) dada en términos de las funciones propias (véase, por ejemplo, [11] del cap. 28).
Estos problemas de determinar los valores propios y las funciones propias de una ecuación diferencial ordinaria con condiciones de frontera y de desarrollar una función dada en términos de una serie infinita de las funciones propias, que datan aproximadamente de 1750, se hicieron más prominentes al tiempo que se introducían nuevos sistemas de coordenadas y nuevas clases de funciones tales como las funciones de Bessel, los polinomios de Legendre, las funciones de Lamé y las funciones de Mathieu surgieron como funciones propias de ecuaciones diferenciales ordinarias. Dos autores, Charles Sturm (1803-1855), profesor de mecánica de la Sorbona, y Joseph Liouville (1809-1882), amigo de Sturm y profesor de matemáticas del College de France, decidieron atacar el problema general para cualquier ecuación diferencial de segundo orden. Sturm trabajó desde 1883 en problemas de ecuaciones diferenciales parciales, principalmente sobre el flujo de calor en una barra de densidad variable, y de aquí que fuera completamente consciente de los problemas de valores propios y funciones propias.
Las ideas matemáticas que aplicó a este problema[446] están estrechamente relacionadas con sus investigaciones de la «realidad» y distribución de las raíces de las ecuaciones algebraicas. Sus ideas en ecuaciones diferenciales, dice, provinieron de su estudio de ecuaciones en diferencias y de un paso al límite.
Liouville, informado por Sturm de los problemas sobre los que estaba trabajando, se dedicó a la misma materia[447] Los resultados en los varios artículos de estos dos autores están bastante detallados, y son resumidos de manera más conveniente en notación moderna como sigue. Consideraron la ecuación general de segundo orden
Ly'' + My' +λNy = 0 (5)
donde L, M y N son funciones continuas de x, L no es cero y λ es un parámetro. Tal tipo de ecuación puede ser transformada, multiplicando por![]()
![]()
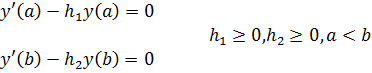
a. El problema tiene una solución que no es cero únicamente cuando λ toma cualquiera de los valores de la sucesión λn de números positivos que van hasta ∞
b. Para cada λn, las soluciones son múltiplos de una función vn, que se puede normalizar mediante la condición
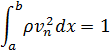
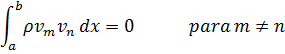
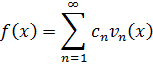
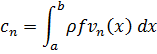
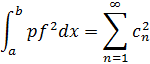

4. Teoremas de existencia
Hemos notado con anterioridad, bajo este mismo tema de las ecuaciones diferenciales parciales del siglo XIX, que cuando los matemáticos encontraron más y más difícil el problema de obtener soluciones para ecuaciones diferenciales específicas, se hicieron la pregunta: ¿dada una ecuación diferencial, tiene una solución para condiciones iniciales y condiciones de frontera dadas? El mismo movimiento, igualmente esperado, ocurrió en las ecuaciones diferenciales ordinarias. Que la cuestión de la existencia fuese ignorada por tanto tiempo se debe en parte a que las ecuaciones diferenciales surgieron de problemas físicos y geométricos, y era intuitivamente claro que estas ecuaciones tenían soluciones.
Cauchy fue el primero en considerar la cuestión de la existencia de las soluciones de ecuaciones diferenciales y tuvo éxito al proporcionar dos métodos. El primero aplicable a
y' = f(x,y) (6)
fue creado en algún momento entre 1820 y 1830 y resumido en sus Exercices d’analyse.[450]Este método, lo esencial del cual puede ser encontrado en Euler[451], utiliza la misma idea implicada en la integral como el límite de una suma. Cauchy deseaba demostrar que existe una y solamente una y = f(x) que satisface (6) y que cumple la condición inicial de que y0= f(x0). Dividió (x0, x) en n partes Δx0, Δxl,.., Δxn_, y formó
yi+1 = yi + f(xi, yi) Δxi
donde las xi son cualquier valor de x en Δxi. Entonces, por definición,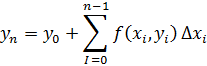
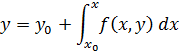
Cauchy supuso que f(x,y) y fy son continuas para todos los valores reales de x e y en el rectángulo determinado por los intervalos (x0,x) e (y0,y). En 1876, Rudolph Lipschitz (1832-1903) debilitó las hipótesis del teorema[452]. Su condición esencial fue que para todas las (x,y1) y (x,y2) en rectángulo |x - x0| ≤ a, |y - y0| ≤ b, esto es, para dos puntos cualesquiera con la misma abscisa, existe una constante k tal que
|f(x,y1) - f(x,y2)| < K(y1 - y2).
Esta condición es conocida como la condición de Lipschitz y el teorema de existencia es llamado teorema de Cauchy-Lipschitz.El segundo método de Cauchy para establecer la existencia de soluciones para ecuaciones diferenciales, el método de las funciones dominantes o mayorantes es más extensamente aplicable que el primero, y fue aplicado por Cauchy en el dominio complejo. El método fue presentado en una serie de ensayos en las Comptes Rendus durante los años de 1839 a 1842[453]. El método fue llamado por Cauchy calcul des limites porque proporciona límites inferiores dentro de los cuales la solución cuya existencia se establece converge seguramente. Briot y Bouquet simplificaron el método y su versión[454], se convirtió en la habitual.
Para ilustrar el método veamos cómo se aplica a
y' = f(x,y),
donde f es analítica en x e y. El teorema que ha de ser establecido dice así: si para![]()
![]()
El método de demostración, que esbozamos solamente, se vale en primera instancia del hecho de que f(x,y) es analítica en un entorno de (x0,y0), que por conveniencia tomamos como (0,0): existe un círculo de radio a alrededor de x0 = 0y un círculo de radio b alrededor de y0 = 0 en el cual f(x,y) es analítica. Entonces f(x,y) tiene una cota superior M para todos los valores de x e y en los círculos respectivos. Ahora, el propio método para obtener la serie (8) garantiza que satisface formalmente (7). El problema es demostrar que la serie converge.
Para este fin se introduce la función mayorante
![]()
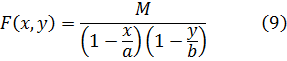
![]()
![]()
El método, por sí mismo, no determina el radio preciso de convergencia de la serie para y. Numerosos esfuerzos se dedicaron, por tanto, a demostrar que el radio puede ser extendido. Sin embargo, los artículos no proporcionan el dominio total de convergencia y son de poca importancia práctica.
Liouville publica por primera vez un tercer método para establecer la existencia, para una ecuación de segundo orden, de soluciones de ecuaciones diferenciales ordinarias, el cual probablemente era conocido por Cauchy[455] . Este es el método de aproximaciones sucesivas y ahora se le atribuya a Emile Picard, dado que proporcionó el método en la forma general[456]. Para la ecuación en x e y reales,
y' = f(x, y),
donde f(x,y) es analítica en x e y, y cuya solución y = f(x) debe pasar por (x0,y0) el método es introducir la sucesión de funciones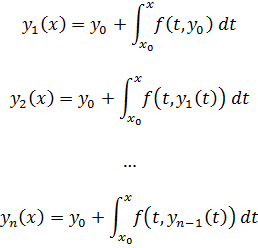
Los diversos métodos descritos anteriormente no sólo se aplicaron a ecuaciones diferenciales ordinarias de orden superior, sino también a sistemas de ecuaciones diferenciales para variables con valores complejos. De esta manera, Cauchy extendió su segundo tipo de teoremas de existencia a sistemas de ecuaciones diferenciales ordinarias de primer orden en n variables dependientes. También, con su método del calcul des limites, trató sistemas en el dominio complejo[457]. El resultado de Cauchy es como sigue: dado el sistema de ecuaciones
![]()
x = ξ, y0 = η0,…, yn-1 = ηn-1
en potencias enteras positivas dex - ξ, y0 - η0,…, yn-1 - ηn-1
Entonces, existen n series de potencias en x — ξ, convergentes en el entorno de x = ξ las cuales, cuando son sustituidas en las y0, ..., yn-1en (12), satisfacen las ecuaciones. Estas series de potencias son únicas, proporcionan una solución regular del sistema y toman los valores iniciales. En esta generalidad, el resultado puede encontrarse en la «Mémoire sur l’emploi du nouveau calcul, appelé calcul des limites, dans l’intégration d’un systéme d’équations différentielles» («Memoria sobre el empleo del nuevo cálculo, llamado cálculo de límites, en la integración de un sistema de ecuaciones diferenciales»)[458]. La idea era darse satisfacción con el establecimiento de la existencia y con obtener la solución en el entorno de un punto en el plano complejo. Weierstrass obtuvo igual resultado en el mismo año (1842), pero no lo publicó hasta que aparecieron sus Werke (Obras) en 1894[459].5. La teoría de singularidades
A mediados del siglo XIX, el estudio de las ecuaciones diferenciales ordinarias tomó un nuevo curso. Los teoremas de existencia y la teoría de Sturm-Liouville presuponen que las ecuaciones diferenciales contienen funciones analíticas, o, al menos, funciones continuas en el dominio donde las soluciones son consideradas. Por otro lado, algunas de las ecuaciones diferenciales ya consideradas, tales como las de Bessel, Legendre y la ecuación hipergeométrica, cuando son expresadas de manera que el coeficiente de la segunda derivada sea la unidad, tienen coeficientes que son singulares, y la forma de las soluciones en serie en los entornos de los puntos singulares, particularmente los de la segunda solución, es peculiar. A partir de aquí los matemáticos se dirigieron al estudio de las soluciones en los entornos de los puntos singulares, esto es, puntos en los cuales uno o más de los coeficientes son singulares. El punto en el que todos los coeficientes son al menos continuos y (comúnmente) analíticos es llamado punto ordinario.
Las soluciones en los entornos de puntos singulares son obtenidas como series y el conocimiento de la forma adecuada de las series debe estar disponible antes de calcularlas. Este conocimiento sólo se obtiene a partir de la ecuación diferencial. El nuevo problema fue descrito por Lazarus Fuchs (1833-1902) en un artículo de 1866 (véase más abajo). «En la situación actual de la ciencia el problema de la teoría de las ecuaciones diferenciales no es tanto reducir una ecuación dada a cuadraturas, como deducir a partir de la misma ecuación el comportamiento de sus integrales en todos los puntos del plano, esto es, para todos los valores de la variable compleja.» Para este problema, fue el trabajo de Gauss sobre series hipergeométricas el que señaló el camino. Las grandes figuras fueron aquí Riemann y Fuchs, este último alumno de Weierstrass y su sucesor en Berlín. La teoría resultante es llamada teoría fuchsiana de las ecuaciones diferenciales lineales.
La atención en esta nueva área se concentró sobre las ecuaciones diferenciales lineales de la forma
y(n) + p1(z)y(n-1) +…+ pn(z)y = 0 (13)
donde las pi(z) son funciones analíticas univalentes de z compleja, excepto en puntos singulares aislados. Esta ecuación fue muy estudiada porque sus soluciones abarcaban todas las funciones elementales y aun algunas funciones superiores, tales como las funciones modulares y automorfas que encontraremos más adelante.Antes de considerar las soluciones en y dentro de un entorno de puntos singulares, señalemos un teorema básico que se sigue del teorema de existencia de Cauchy para sistemas de ecuaciones diferenciales ordinarias, probado directamente por Fuchs[460], aunque reconoció su deuda con las clases de Cauchy. Si los coeficientes pi,..., pn son analíticos en el punto a y en algún entorno de ese punto, y si están dadas condiciones iniciales arbitrarias para y ysus primeras n - 1 derivadas en z = a, entonces existe una solución en serie de potencias única para y en términos de z de la forma
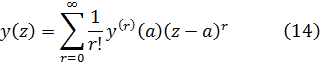
Briot y Bouquet iniciaron el estudio de las soluciones en los entornos de los puntos singulares[461]. Ya que sus resultados para ecuaciones lineales de primer orden fueron rápidamente generalizados, consideraremos los tratamientos más generales.
A fin de llegar al comportamiento en el entorno de los puntos singulares, Riemann propuso un enfoque poco usual. A pesar de que las pi(z) en (13) se suponen funciones analíticas univalentes, excepto en puntos singulares aislados, las soluciones yi(z), analíticas excepto posiblemente en los puntos singulares, no son en general univalentes sobre el dominio entero de los valores de z. Supongamos que tenemos un conjunto fundamental de soluciones, yi(z), i = 1, 2,..., n, esto es, n soluciones independientes de la clase especificada en el teorema anterior. Entonces la solución general es
y = c1y1 + c2y2 + ... + cnyn,
donde las ci son constantes.Si ahora rastreamos el comportamiento de una yi analítica a lo largo de una trayectoria cerrada envolviendo un punto singular, y¡ cambiará entonces su valor a otra rama de la misma función aunque permanezca no obstante como solución de la ecuación diferencial. Como cualquier solución es una combinación lineal de n soluciones particulares, las nuevas yi, digamos yi' son una combinación de las yi. Así obtenemos
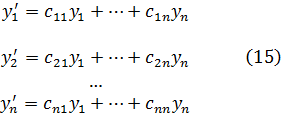
El enfoque de Riemann para obtener el carácter de las soluciones en el entorno de los puntos singulares apareció en su artículo de 1857 «Beitrage zur Theorie die Gauss’sche Reihe F(α, β, γ, x) darstellbaren Functionen»[464] («Contribución a la teoría gaussiana de las series F(α, β, γ, x) representando funciones»). La ecuación diferencial hipergeométrica, como Gauss la llamaba, tiene tres puntos singulares, 0, 1 e ∞. Riemann demostró que, para x compleja, para obtener conclusiones acerca del comportamiento de las soluciones particulares alrededor de los puntos singulares de la ecuación de segundo orden, no es necesario conocer la propia ecuación diferencial, sino más bien saber cómo dos soluciones independientes se comportan cuando la variable independiente recorre trayectorias cerradas alrededor de tres puntos singulares. Esto es, debemos conocer las transformaciones
y1' = c11y1 + c12y2, y2' = c21y1 + c22y2
para cada punto singular.De esta manera, la idea de Riemann, al tratar funciones definidas por ecuaciones diferenciales, fue derivar las propiedades de las funciones de un conocimiento del grupo de monodromía. Su artículo de 1857 trataba la ecuación diferencial hipergeométrica, pero se planteaba tratar las ecuaciones diferenciales ordinarias lineales de orden w-ésimo con coeficientes algebraicos. En un fragmento escrito en 1857, no publicado hasta que sus obras escogidas aparecieron en 1876[465], Riemann consideró ecuaciones más generales que las de segundo orden con tres puntos singulares. Consecuentemente, supone que tiene n funciones uniformes, finitas y continuas, excepto en ciertos puntos asignados arbitrariamente (los puntos singulares) y sometidos a una substitución lineal fijada arbitrariamente cuando z describe un circuito cerrado alrededor de cierto punto. Demuestra entonces que tal sistema de funciones satisface una ecuación diferencial lineal de orden n-ésimo. Pero no demuestra que los puntos de ramificación (puntos singulares) y las sustituciones puedan ser escogidas arbitrariamente. Aquí su trabajo fue incompleto y dejó abierto un problema conocido como el problema de Riemann: dados m puntos al,.., am en el plano complejo, y asociada a cada uno de ellos una transformación lineal de la forma (15), demostrar sobre la base de suposiciones elementales acerca del comportamiento del grupo de monodromía asociado con estos puntos singulares (siempre y cuando tal comportamiento no esté ya determinado) que está determinada una clase de funciones yl,..., yn que satisface una ecuación diferencial lineal de orden n-ésimo con las dadas como puntos singulares y tales que cuando la z recorre una trayectoria cerrada alrededor de las ai, las yt sufren la transformación lineal asociada con las ai
Guiado por el ensayo de Riemann de 1857 sobre la ecuación hipergeométrica, Fuchs llevó más lejos el trabajo sobre singularidades. Fuchs y sus estudiantes, empezando en 1865[466], estudiaron las ecuaciones diferenciales de orden n-ésimo, mientras que Riemann había publicado nada más que sobre la ecuación diferencial hipergoemétrica de Gauss. Fuchs no siguió el enfoque de Riemann, sino que trabajó directamente con la ecuación diferencial lineal, hasta extender totalidad de la teoría de ecuaciones diferenciales al dominio de la teoría de funciones complejas.
En los ensayos mencionados anteriormente, Fuchs publicó su trabajo principal sobre ecuaciones diferenciales ordinarias. Empieza con la ecuación diferencial lineal de orden n cuyos coeficientes son funciones racionales de x. Mediante un examen cuidadoso de la convergencia de las series que satisfacen formalmente la ecuación, encuentra que los puntos singulares de la ecuación son fijos, esto es, independientes de las constantes de integración, y pueden ser encontrados antes de integrar, ya que son los polos de los coeficientes de la ecuación diferencial.
Más adelante demuestra que un sistema fundamental de soluciones sufre una transformación lineal con coeficientes constantes cuando la variable independiente z describe un circuito encerrando un punto singular. De este comportamiento de las soluciones deriva expresiones válidas para ellas en una región circular encerrando aquel punto y extendiéndose al punto singular siguiente. Establece la existencia de sistemas de n funciones uniformes, finitas y continuas con excepción de los entornos de ciertos puntos y sometidas a sustituciones lineales con coeficientes constantes cuando la variable z describe circuitos cerrados alrededor de estos puntos.
Luego Fuchs consideró qué propiedades debe tener una ecuación diferencial de la forma (13) en función que sus soluciones en un punto singular z = a tengan la forma
(z - a)s[ϕ0 + ϕ1 log (z - a)+…+ ϕλ logλ (z - a)]
donde s es algún número (que más adelante puede ser especificado) y las ϕ, pueden ser funciones univalentes en un entorno de z = a que pueden tener polos de orden finito. Su respuesta fue que una condición necesaria y suficiente es que pr(z) = (z - a)-r P(z), donde P(z) es analítica cerca de z = a. Así, p1(z) tiene un polo de orden uno y, así sucesivamente. Tal punto a es llamado punto singular regular (Fuchs lo llamó un punto de determinación).Fuchs estudió también una clase más específica de ecuaciones de la forma (13). Una ecuación lineal homogénea de este tipo es llamada de tipo fuchsiano cuando tiene en el peor de los casos puntos singulares regulares en el plano complejo extendido (incluyendo el punto del ∞). En este caso las pi(z) deben ser funciones racionales de z. Por ejemplo, la ecuación hipergeométrica tiene puntos singulares regulares en z = 0, 1 y ∞.
Pero el estudio de las integrales de las ecuaciones diferenciales en un entorno de un punto dado no proporciona necesariamente las propias integrales. El estudio fue tomado como el punto de partida para la investigación de las integrales completas. A partir de las grandes investigaciones de Fuchs, los matemáticos han tenido éxito en extender la clase de ecuaciones diferenciales ordinarias lineales que pueden ser integradas explícitamente. Con anterioridad, únicamente las ecuaciones lineales de orden n con coeficientes constantes y la ecuación de Legendre
![]()
Más allá de resultados generales sobre los tipos de integrales que pueden tener clases especiales de ecuaciones diferenciales, existe una aproximación con series a las soluciones en el punto z = a donde la ecuación tiene un punto singular regular. Si el origen es el punto, entonces la ecuación tiene la forma
![]()
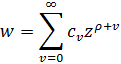
El problema de Riemann también fue atacado durante la última parte del siglo XIX, pero sin éxito hasta que Hilbert en 1905[468] y Oliver D. Kellogg (1878-1932)[469], con la ayuda de la teoría de ecuaciones integrales, que había sido desarrollada mientras tanto, proporcionaron la primera solución completa. Demostraron que la transformación generadora del grupo de monodromía puede ser prescrita arbitrariamente.
6. Las funciones automorfas
Poincaré y Félix Klein estudiaron a continuación la teoría de las soluciones de las ecuaciones diferenciales lineales. La teoría que ellos introdujeron es llamada funciones automorfas, materia que, aunque importante por otras varias aplicaciones, juega un papel fundamental en la teoría de ecuaciones diferenciales.
Henri Poincaré (1854-1912) era profesor de la Sorbona. Sus publicaciones, casi tan numerosas como las de Euler y Cauchy, cubren un rango muy amplio de matemáticas y física matemática. Sus investigaciones en física, que no tendremos ocasión de discutir, incluyeron la atracción capilar, elasticidad, teoría del potencial, hidrodinámica, propagación del calor, electricidad, óptica, teoría electromagnética, relatividad y sobre todo, mecánica celeste. Poincaré tenía una visión penetrante y de cada problema que estudió obtuvo su carácter esencial. Enfocaba agudamente un problema y lo examinaba detalladamente. También creía en el estudio cualitativo de todos los aspectos del problema.
Las funciones automorfas son generalizaciones de las funciones circulares, hiperbólicas, elípticas u otras funciones del análisis elemental. La función sen z no cambia de valor si z es reemplazada por z + 2mπ, donde m es cualquier entero. También se puede decir que la función se mantiene sin alteración en su valor si z está sujeta a cualquier transformación del grupo z' = z + 2mπ. La función hiperbólica senh z se mantiene sin alteración en su valor si z está sujeta a cualquier transformación del grupo z' = z + 2πmi. Una función elíptica se mantiene invariante en su valor bajo las transformaciones del grupo z' = z + mw + m'w' donde w y w' son los períodos de la función. Todos estos grupos son discontinuos (término introducido por Poincaré); esto es, todas las transformaciones de cualquier punto bajo las transformaciones del grupo son finitas en número en cualquier dominio acotado cerrado.
El término función automorfa es usado ahora para incluir funciones que son invariantes bajo el grupo de transformaciones
![]()
Las primeras funciones automorfas estudiadas fueron las funciones modulares elípticas. Estas funciones son invariantes bajo el grupo modular, que es aquel subgrupo de (16) donde a, b, c y d son enteros reales y ad - be = 1, o bajo algún subgrupo de este grupo. Estas funciones modulares elípticas se derivan de las funciones elípticas. No las seguiremos aquí, ya que no entran en la teoría básica de las ecuaciones diferenciales.
Las funciones automorfas más generales fueron introducidas para estudiar ecuaciones diferenciales lineales de segundo orden
![]()
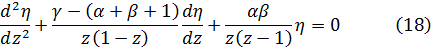
Riemann, en sus clases de 1858-1859 sobre las series hipergeométricas y en un ensayo póstumo de 1867 sobre superficies mínimas, e, independientemente, Schwarz[470] establecieron lo siguiente. Sean η1 y η2 dos soluciones particulares cualesquiera de la ecuación (17). Todas las soluciones son expresadas como
η = m η1 + n η2
Cuando z recorre una trayectoria cerrada alrededor de un punto singular, η1 y η2 pasan a serη11 = a η1 + b η2, η22 = c η1 + d η2
y permitiendo que z recorra trayectorias cerradas alrededor de todos los puntos singulares se obtiene el grupo completo de tales transformaciones lineales, que es el grupo de monodromía de la ecuación diferencial.Ahora, sea ζ(z) = η1 / η2. Cuando z recorre una trayectoria cerrada, el cociente ζ es transformado en
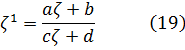
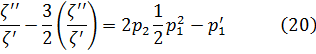
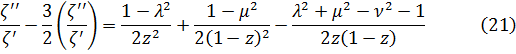
Después Riemann y Schwarz demostraron que toda solución particular ζ(z) de la ecuación (21), cuando λ, μ y ν son reales, es una aplicación conforme de la parte superior del plano z (Fig. 29.1) dentro de un triángulo curvilíneo con arcos circulares en el plano ζ cuyos ángulos son λπ, μπ y νπ.
Figura 29.1
El trabajo de Poincaré y Klein arranca de este punto. Klein realizó cierto trabajo básico sobre funciones automorfas antes de 1880. Durante los años 1881-1882, trabajó con Poincaré, quien también había llevado a cabo algún trabajo previo sobre la materia después de que su atención fue atraída por el trabajo de Fuchs mencionado con anterioridad. En 1884, Poincaré publicó cinco artículos importantes sobre funciones automorfas en los primeros cinco volúmenes del Acta Mathematica. Cuando el primero de éstos fue publicado en el primer volumen de la nueva Acta Mathematica, Kronecker advirtió al editor Mittag-Leffler que este artículo inmaduro y obscuro mataría a la revista.
Guiado por la teoría de funciones elípticas, Poincaré inventó una nueva clase de funciones automorfas[471]. Esta clase fue obtenida considerando la función inversa del cociente de dos soluciones linealmente independientes de la ecuación
![]()
![]()
La construcción de Poincaré de las funciones automorfas (en el segundo artículo de 1882) estaba basada en su serie theta. Sean las transformaciones del grupo (22)

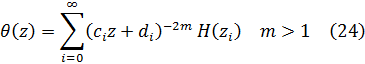
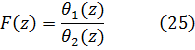
Las funciones fuchsianas son de dos tipos, uno que existe sobre todo el plano, y otro que sólo existe en el interior del círculo fundamental. La función inversa de una función fuchsiana es, como vimos anteriormente, el cociente de dos integrales de una ecuación diferencial lineal de segundo orden con coeficientes algebraicos. Tal ecuación, que Poincaré llamó ecuación fuchsiana, puede ser integrada por medio de funciones fuchsianas.
Más adelante, Poincaré[473] extendió el grupo de transformaciones (22) a coeficientes complejos y consideró varios tipos de tales grupos, a los que llamó kleinianos. Nos debemos conformar aquí con notar que un grupo es kleiniano si, esencialmente, no es finito ni fuchsiano sino que, por supuesto, es de la forma (22) ydiscontinuo en cualquier parte del plano complejo. Para estos grupos kleinianos, Poincaré obtuvo nuevas funciones automorfas, esto es, funciones invariantes bajo los grupos kleinianos, a las que llamó funciones kleinianas. Estas funciones tienen propiedades análogas a las fuchsianas; sin embargo, la región fundamental para las nuevas funciones es más complicada que un círculo. Incidentalmente, Klein había considerado las funciones fuchsianas, mientras que Lazarus Fuchs no. Klein, por tanto, protestó contra Poincaré. Poincaré respondió llamando a la siguiente clase de funciones automorfas, a pesar de que él mismo las descubrió, kleinianas, ya que —como alguien observó perversamente— éstas nunca fueron consideradas por Klein.
Más adelante, Poincaré mostró cómo expresar las integrales de ecuaciones lineales de orden w-ésimo con coeficientes algebraicos, teniendo únicamente puntos singulares regulares, con ayuda de las funciones kleinianas. Así, esta clase completa de ecuaciones diferenciales lineales se resuelve mediante el uso de las nuevas funciones trascendentes de Poincaré.
7. El trabajo de Hill sobre soluciones periódicas de las ecuaciones lineales
Mientras que estaba siendo creada la teoría de funciones automorfas, el trabajo en astronomía estimuló el interés sobre una ecuación diferencial ordinaria de segundo orden, que de alguna manera era más general que la ecuación de Mathieu. Toda vez que el problema de los n cuerpos no estaba resuelto explícitamente y sólo se disponía de soluciones en serie muy complicadas, los matemáticos volvieron a preferir soluciones periódicas.
La importancia de las soluciones periódicas surge del problema de la estabilidad de una órbita de un planeta o satélite. Si un planeta es ligeramente desplazado de su órbita, dándosele alguna pequeña velocidad, se plantea esta cuestión: ¿oscilará alrededor de su órbita para volver tal vez a ella después de cierto tiempo, o se alejará de ella? En el primer caso la órbita es estable, y en el último inestable. Así, la pregunta de si el movimiento primario de los planetas o cualesquiera irregularidades en sus movimientos son periódicos es vital.
Como sabemos (cap. 21, sec. 7), Lagrange había encontrado soluciones periódicas especiales en el problema de los tres cuerpos. No se llegó a nuevas soluciones periódicas de dicho problema hasta que George William Hill (1838-1914), el primer gran matemático americano, realizó sus trabajos sobre la teoría lunar. En 1877, Hill publicó en privado un ensayo notablemente original sobre el movimiento del perigeo de la Luna[474]. También publicó un artículo muy importante sobre el movimiento de la Luna en el American Journal of Mathematics[475]. Su trabajo fundó la teoría matemática de las ecuaciones diferenciales lineales homogéneas con coeficientes periódicos.
La primera idea importante de Hill (en su ensayo de 1877) consistió en determinar una solución periódica de las ecuaciones diferenciales para el movimiento de la Luna, que se aproximaba al movimiento factual observado. Después formuló ecuaciones para las variaciones a partir de esta solución periódica, lo que condujo a un sistema de cuarto orden de ecuaciones diferenciales lineales con coeficientes periódicos. Conociendo algunas integrales, fue capaz de reducir su sistema de cuarto orden a una única ecuación diferencial lineal de segundo orden
![]()
![]()
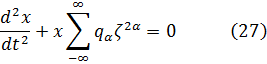
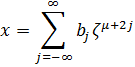
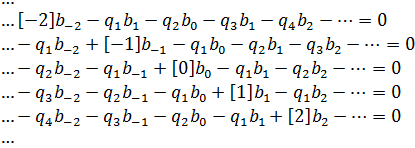
[j] = (μ + 2j)2 - q0
Hill hizo el determinante de los coeficientes de las incógnitas bj igual a 0. Primero determinó las propiedades de las infinitas soluciones para μ y proporcionó fórmulas explícitas para determinar las μ. Con estos valores de μ, resolvió el sistema de una infinidad de ecuaciones homogéneas lineales en las infinitas bj para la razón de las bj a b0. Hill demostró que la ecuación diferencial de segundo orden tiene una solución periódica y que el movimiento del perigeo de la Luna es periódico.El trabajo de Hill fue menospreciado hasta que Poincaré[476] demostró la convergencia del procedimiento y, de este modo, colocó a la teoría de los determinantes infinitos y sistemas infinitos de ecuaciones lineales sobre una base sólida. La atención de Poincaré y los esfuerzos finales de Hill dieron importancia a éste, ayudando también a la materia en cuestión.
8. Ecuaciones diferenciales no lineales: la teoría cualitativa
Poincaré inició, bajo el estímulo del trabajo de Hill, un nuevo enfoque en la búsqueda de soluciones periódicas para ecuaciones diferenciales gobernando los movimientos planetarios y la estabilidad de las órbitas planetarias y de los satélites. Puesto que las ecuaciones relevantes son no lineales, Poincaré estudió esta clase. Las ecuaciones diferenciales ordinarias no lineales prácticamente habían aparecido desde el principio de la materia como, por ejemplo, la ecuación de Riccati (cap. 21, sec. 4), la ecuación del péndulo y las ecuaciones de Euler del cálculo de variaciones (cap. 24, sec. 2), aunque no se desarrollaron métodos generales para su solución.
En vista del hecho de que las ecuaciones del movimiento de incluso tres cuerpos no pueden ser resueltas explícitamente en términos de funciones conocidas, el problema de estabilidad no puede ser resuelto examinando la solución. Por lo tanto, Poincaré buscó métodos mediante los cuales el problema sería resuelto examinando las propias ecuaciones diferenciales. La teoría iniciada por él se llamó teoría cualitativa de las ecuaciones diferenciales. La presentó en cuatro artículos, todos bajo el mismo título: «Mémoire sur les courbes définies par una équation différentielle» («Memoria sobre las curvas definidas por una ecuación diferencial»)50. Las preguntas que buscaba contestar fueron enunciadas por él mismo con estas palabras: «¿Describe una curva cerrada el punto que se mueve? ¿Se mantiene siempre en el interior de cierta porción del plano? En otras palabras, y hablando en el lenguaje de la astronomía, nos hemos preguntado si la órbita es estable o inestable.»
Poincaré empezó con ecuaciones no lineales de la forma
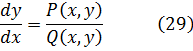
En el análisis de las clases de soluciones que puede tener la ecuación (29), Poincaré encontró que los puntos singulares de la ecuación[477] diferencial (los puntos en que ambas P y Q se anulan) juegan un papel importante. Estos puntos singulares son indeterminados o irregulares en el sentido de Fuchs. Aquí Poincaré usó trabajos previos de Briot y Bouquet (sec. 5), pero se limitó a valores reales y a estudiar el comportamiento de la solución entera en lugar de circunscribirse a un entorno de los puntos singulares. Distinguió cuatro tipos de puntos singulares y describió el comportamiento de las soluciones alrededor de tales puntos.
El primer tipo de punto singular es el foco (foyer), el origen en la Figura 29.2, y la solución describe una espiral alrededor y se aproxima al origen cuando va de -∞ a ∞. Este tipo de solución es considerada estable.
Figura 29.2
Figura 29.3
Entre otros muchos resultados, Poincaré encontró que pueden existir curvas cerradas que no tocan a ninguna de las curvas que satisfacen la ecuación diferencial. Llamó a estas curvas cerradas ciclos sin contacto. Una curva que satisface la ecuación diferencial no puede tocar tal ciclo en más de un punto, y si cruza el ciclo no lo puede volver a cruzar. Tal curva, si es la órbita de un planeta, representa un movimiento inestable.
Además de los ciclos sin contacto, existen curvas cerradas que Poincaré llamó ciclos límite. Estas son curvas cerradas que satisfacen la ecuación diferencial y a las que otras soluciones se aproximan asintóticamente, esto es, sin llegar nunca al ciclo límite.
Figura 29.4
En el tercero de los artículos sobre esta materia, Poincaré estudió ecuaciones de primer orden de grado superior y de la forma F(x,y,y') = 0, donde F es un polinomio en x, y e y'. Para estudiar estas ecuaciones, Poincaré consideró x, y e y' como tres coordenadas cartesianas y consideró la superficie definida por la ecuación diferencial. Si esta superficie tiene género 0 (forma de una esfera), entonces las curvas integrales tienen las mismas propiedades que en el caso de las ecuaciones diferenciales de primer grado. Para otros géneros, los resultados sobre las curvas integrales pueden ser bastante diferentes. Así, para un toro surgen muchas nuevas circunstancias. Poincaré no completó su estudio. En el cuarto artículo (1886), estudió las ecuaciones de segundo orden y obtuvo algunos resultados análogos a los de las ecuaciones de primer orden.
Mientras continuaba sus trabajos sobre los tipos de soluciones de la ecuación diferencial (29), Poincaré consideró una teoría más general dirigida al problema astronómico de los tres cuerpos. En un ensayo premiado, «Sur le probléme de trois corps et les équations de la dynamique» («Sobre el problema de los tres cuerpos y las ecuaciones de la dinámica»)[478], consideró el sistema de ecuaciones diferenciales
![]()
![]()
Los detalles del trabajo de Poincaré son demasiado especializados para considerarlos aquí. Primero generalizó trabajos anteriores de Cauchy sobre soluciones de sistemas de ecuaciones diferenciales ordinarias donde este último utilizó su calcul des limites. Luego, Poincaré demostró la existencia de las soluciones periódicas que buscaba y aplicó lo aprendido en el estudio de las soluciones periódicas del problema de los tres cuerpos para el caso donde las masas de dos de los cuerpos (pero no la del Sol) son pequeñas. De esta forma se obtienen tales soluciones suponiendo que las dos pequeñas masas se mueven en círculos concéntricos alrededor del Sol y están en el mismo plano. Se pueden obtener otras suponiendo que para μ = 0, las órbitas son elipses y que sus períodos son conmensurables. Con estas soluciones, y usando la teoría que había desarrollado para este sistema, obtuvo otras soluciones periódicas. En suma, demostró que existe una infinidad de posiciones iniciales y velocidades iniciales tales que las distancias mutuas de los tres cuerpos son funciones periódicas del tiempo. (Tales soluciones también son llamadas periódicas.)
En su artículo de 1890, Poincaré dedujo muchas otras conclusiones acerca de las soluciones periódicas y casi periódicas del sistema (30). Entre ellas está el muy notable descubrimiento para tal sistema de una nueva clase de soluciones previamente desconocida. Las denominó soluciones asintóticas. Existen dos clases. En la primera, la solución aproxima la solución periódica asintóticamente cuando t aproxima -∞o cuando t aproxima +∞. La segunda clase consiste en soluciones doblemente asintóticas: soluciones que aproximan una solución periódica cuando t aproxima a -∞ y +∞. Hay una infinidad de tales soluciones doblemente asintóticas. Todos los resultados de este artículo de 1890 y muchos otros están en Les Méthodes nouvelles de la mécanique céleste (Los nuevos métodos de la mecánica celeste) de Poincaré)[479].
El trabajo de Poincaré sobre la estabilidad del sistema solar tuvo éxito sólo parcialmente. La estabilidad es aún un problema abierto. De hecho, también lo es la cuestión respecto a si la órbita de la Luna es estable; muchos científicos piensan que no lo es.
La estabilidad de las soluciones de (29) se analiza mediante la ecuación característica, a saber,
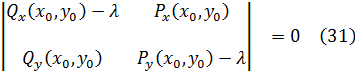
El estudio cualitativo de las ecuaciones no lineales avanzó mediante la introducción por Poincaré de argumentos topológicos (en el primero de los cuatro artículos en el Journal de Mathématiques). Para describir la naturaleza de un punto singular introdujo la noción de índice. Considérese un punto singular P0 y la curva cerrada simple C rodeándolo. En cada intersección de C con las soluciones de
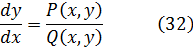
Figura 29.5
La naturaleza de las trayectorias se determina por la ecuación característica, y de forma que el índice I de una curva puede ser determinado sólo por el conocimiento de la ecuación diferencial. Se puede demostrar que
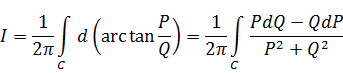
Después de Poincaré, el trabajo más significativo sobre soluciones de ecuaciones de la forma (32) se debe a Ivar Bendixson (1861-1935). Uno de sus resultados[481] principales da un criterio mediante el cual, en ciertas regiones, se demuestra que no existe ninguna trayectoria cerrada. Sea D una región donde ∂Q/∂x + ∂P/∂y tiene el mismo signo. Entonces, la ecuación (32) no tiene solución periódica en D.
El teorema ahora llamado en honor de Poincaré y Bendixson, que está contenido en el artículo último de 1901, proporciona un criterio positivo para la existencia de una solución periódica de (32). Si P y Q están definidas y son regulares en — ∞ < x, y < ∞ y si cuando t se aproxima a ∞ una solución x(t), y(t) permanece dentro de una región acotada del plano (x,y) sin aproximarse a puntos singulares, entonces existe al menos una curva solución cerrada de la ecuación diferencial.
El estudio de ecuaciones no lineales que inició Poincaré fue ensanchado en varias direcciones. Se mencionará también otro tema iniciado en el siglo XIX. Las ecuaciones diferenciales lineales que estudió Fuchs poseen la propiedad que los puntos singulares están fijos y, de hecho, son determinados por los coeficientes de las ecuaciones diferenciales. En el caso de ecuaciones no lineales los puntos singulares pueden variar con las condiciones iniciales y son llamados puntos singulares movibles (o móviles). Así, la ecuación y' + y2 = 0tiene la solución general y = 1/(x - c) donde c es arbitraria. La localización de la singularidad en la solución depende del valor de c. El fenómeno de los puntos singulares movibles lo descubrió Fuchs[482]. El estudio de los puntos singulares movibles y las ecuaciones de segundo orden no lineales con y sin tales puntos singulares fue abordado por muchos científicos, en especial, por Paul Painlevé (1863-1933). Una característica interesante es que muchos de los tipos de ecuaciones de segundo orden de la forma y" = f(x,y,y') requieren para su solución nuevos tipos de funciones trascendentes, ahora llamadas trascendentes de Painlevé[483].
El interés por las ecuaciones no lineales se ha incrementado en el siglo XX. Las aplicaciones han ido de la astronomía a problemas de comunicaciones, servomecánica, sistemas de control automático y electrónico. El estudio también se ha desplazado del aspecto cualitativo a las investigaciones cuantitativas.
Bibliografía
- Acta Mathematica, vol. 38, 1921. Este volumen está dedicado en su totalidad a artículos sobre la obra de Poincaré por varios grandes matemáticos.
- Bocher, M.: «Randwertaufgaben bei gewohnlichen Differentialgleichungen», Encyk. der Math. Wiss., B. G. Teubner, 1899-1916, II, A7a, 437-463. : «Boundary problems in one dimensión», Internat. Cong. of Math., Proc., Cambridge, 1912, 1, 163-195.
- Burkhardt, H.: Entwicklungen nach oscillirenden Functionen und Integration der Differential gleichungen der mathematischen Physik». Jabres, der Deut. Math.-Verein, 10, 1908, 1-1804.
- Craig, T.: «Some of the developments in the Theory of Ordinary Differential Equations between 1878 and 1893». N. Y. Math. Soc. Bull., 2, 1893, 119-134.
- Fuchs, Lazarus: Gesammelte mathematische Werke, 3 vols., 1904-1909, Georg Olms (reimpresión), 1970.
- Heine, Eduard: Handhuch der Kugelfunktionen, 2 vols., 1878-1881, Physika Verlag (reimpresión) 1961.
- Hilb, E.: «Lineare Differentialgleichungen im komplexen Gebiet», Encyk. der Math. Wiss., B. G. Teubner, 1899-1916, II, B5. : «Nichtlineare Differentialgleichungen», Encyk. der Math. Wiss., B. G. Teubner, 1899-1916, II, B6.
- Hill, George W.: Collected Mathematical Works, 4 vols., 1905, Johnson Reprint Corp., 1965.
- Klein, Félix: Vorlesungen uher Entwicklung der Mathematik im 19. Jahrhundert, vol. I, Chelsea (reimpresión), 1950. : Gesammelte mathematische Ahhandlungen, Julius Springer, 1923, vol. 3.
- Painlevé, P.: «Le Probléme moderne de l’intégration des équations différentielles», Third Internat. Math. Cong. in Heidelherg, 1904, 86-99, B. G. Teubner, 1905. : «Gewohnliche Differentialgleichungen, Existenz der Losungen», Encyk. der Math. Wiss., B. G. Teubner, 1899-1916, II, A4a.
- Poincaré, Henri: Œuvres, 1, 2 y 5, Gauthier-Villars, 1928, 1916 y 1960.
- Riemann, Bernhard: Gesammelte mathematische Werke, 2.a ed., 1892, Dover (reimpresión), 1953.
- Schlesinger, L.: «Bericht uber die Entwickelung der Theorie der linearen Differentialgleichungen seit 1865», Jahres. der Deut. Math.-Verein., 18, 1909, 133-266.
- Wangerin, A.: «Theorie der Kugelfunktionen und der verwandten Funktionen», Encyk. der Matb. Wiss., B. G. Teubner, 1899-1916, II, A10. Wirtinger, W.: «Riemanns Vorlesungen uber die hypergeometrische Reihe und ihre Bedeutung», Third Internat. Math. Cong. in Heidelberg, 1904, B. G. Teubner, 1905, 121-139.
Capítulo 30
El cálculo de variaciones en el siglo XIX
Aunque penetrar en los misterios íntimos de la naturaleza y aprender desde allí las causas verdaderas de los fenómenos no nos sea permitido, puede suceder, sin embargo, que ciertas hipótesis ficticias pueden ser suficientes para explicar muchos fenómenos.
Leonhard Euler
1. Introducción1. Introducción
2. La física matemática y el cálculo de variaciones
3. Extensiones matemáticas del propio cálculo de variaciones
4. Problemas relacionados en el cálculo de variaciones
Bibliografía
Como hemos visto, el cálculo de variaciones fue fundado esencialmente por Euler y Lagrange durante el siglo XVIII. Más allá de los problemas físico-matemáticos de diversas clases, existía una motivación fundamental para su estudio, a saber, el Principio de Mínima Acción, que en manos de Maupertuis, Euler y Lagrange se convirtió en el principio básico de la física matemática. Los científicos del siglo XIX continuaron su labor sobre la acción mínima y el gran estímulo del cálculo de variaciones, a lo largo de la primera mitad del siglo, vino de esta dirección. Físicamente, el interés radicaba en la ciencia de la mecánica y particularmente en problemas de astronomía.
2. La física matemática y el cálculo de variaciones
La exitosa formulación de Lagrange hizo de las leyes de la dinámica en términos de su Principio de Acción Mínima, sugirió que la idea debería ser aplicada a otras ramas de la física. Lagrange[484] proporcionó un principio de mínimo para la dinámica de fluidos (aplicable a fluidos compresibles y no compresibles) a partir del cual derivó las ecuaciones de Euler para la mecánica de fluidos (cap. 22, sec. 8) y se jactó con claridad al decir que un principio de mínimo gobernaba este campo como lo hacía con el movimiento de partículas y de cuerpos rígidos. También se resolvieron muchos problemas de elasticidad con el cálculo de variaciones en la primera parte del siglo XIX por Poisson, Sophie Germain, Cauchy y otros; también este trabajo ayudó a mantener el campo activo, aunque no se vieron nuevas ideas matemáticas del cálculo de variaciones en esta área o en la famosa contribución de Gauss a la mecánica: el Principio de Mínima Restricción[485].
La primera novedad digna de mención respecto a este punto se debe a Poisson, que valiéndose de las coordenadas generalizadas de Lagrange, siguió inmediatamente sus dos ensayos para empezar con[486] las ecuaciones de Lagrange (cap. 24, sec. 5)
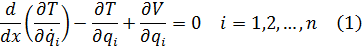
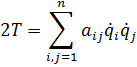
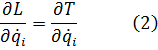
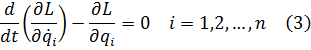
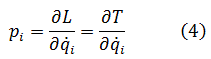
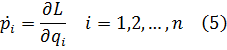
A William R. Hamilton se debe el gran cambio en la formulación de los principios de acción mínima, importante para el cálculo de variaciones y las ecuaciones diferenciales parciales. Hamilton llegó a la dinámica por medio de la óptica. Su meta en física consistió en formar una estructura matemática deductiva a la manera del tratamiento de la mecánica de Lagrange.
Hamilton también empezó con un principio de acción mínima y se proponía deducir otros nuevos. Sin embargo, su actitud hacia tales principios difería profundamente de la de Maupertuis, Euler y Lagrange. En un ensayo publicado en el Dublin University Review[487] dice: «Pero, aunque la ley de acción mínima ha obtenido así un rango entre los más altos teoremas de la física, sin embargo sus pretensiones de una necesidad cosmológica, sobre la base de la economía en el universo, por lo común son rechazados hoy. Y justo el rechazo aparece, entre otras razones, porque la cantidad que se pretendía economizar con frecuencia es gastada suntuosamente.» Ya que en algunos fenómenos de la naturaleza, incluso muy sencillos, la acción es maximizada, Hamilton prefería hablar de un principio de acción estacionaria.
En una serie de artículos del período de 1824 a 1832, Hamilton desarrolló su teoría matemática de la óptica y transfirió ideas que había introducido allí a la mecánica. Escribió dos ensayos básicos[488]. El más pertinente es el segundo de ellos. Aquí introduce la integral de acción, a saber, la integral en el tiempo de la diferencia entre las energías cinética y potencial
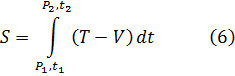
![]()
![]()
El principio hamiltoniano de acción mínima asevera que el movimiento es de hecho el que hace la acción estacionaria. Para sistemas conservativos, esto es, donde las componentes de fuerza son derivables de un potencial que es función únicamente de la posición, T + V = const. De aquí que, T - V = 2T - const., y el principio de Hamilton se reduce al de Lagrange, pero, como se notó, el principio de Hamilton también se mantiene para sistemas no conservativos. Asimismo, la energía potencial V puede ser una función del tiempo y aun de las velocidades; esto es, en coordenadas generalizadas V= V(q1,..., `qn, `q1,..., `qn, t).
Si, al escribir T - V igual a L, escribimos la integral de acción (6) como
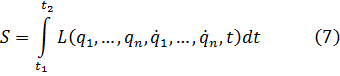
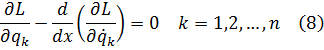
Ahora introduce (véase (4)
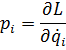
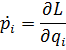
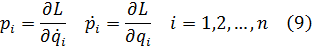
En su segundo artículo (1835), Hamilton simplifica este sistema de ecuaciones. Introduce una nueva función H, la cual está definida mediante
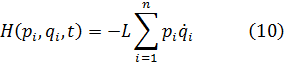
Esta función es físicamente la energía total, ya que se puede mostrar que la sumatoria es igual a 2T. La transformación de L a H es llamada transformación de Legendre, ya que fue usada por Legendre en su trabajo sobre ecuaciones diferenciales ordinarias. El que H sea una función de las pi, qi y t, mientras que T = T - T sea una función de las qi, `qi y t, resulta del hecho de que, dado que pi = ∂L/∂qi podemos resolver para las `qi y sustituir en L.
Con (10), se puede mostrar que las ecuaciones diferenciales del movimiento (9) toman la forma

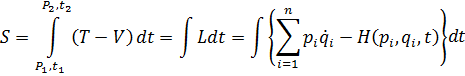
Para usar las ecuaciones de Hamilton del movimiento es posible frecuentemente expresar H en un sistema apropiado de coordenadas p y q de tal forma que el sistema de ecuaciones (11) sea resoluble para las pi y qi como funciones del tiempo. En particular, si podemos seleccionar coordenadas de tal forma que H dependa únicamente de las pi, el sistema es resoluble.
En un artículo de 1837[489] , y en conferencias sobre dinámica de los años de 1842 y 1843, que fueron publicadas en 1866 en el clásico Vorlesungen über Dynamik (Lecciones sobre dinámica), Jacobi demostró que el proceso de Hamilton es susceptible de invertirse. En la teoría de Hamilton, si se conoce la acción S o el hamiltoniano H, es posible formar las 2n ecuaciones diferenciales canónicas e intentar dar solución al sistema. La idea de Jacobi era encontrar coordenadas Pj y Qj de tal forma que H sea tan simple como sea posible, y entonces las ecuaciones diferenciales (11) serían integradas fácilmente. Específicamente, buscó la transformación
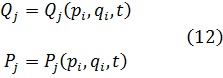
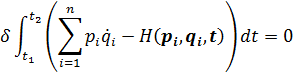
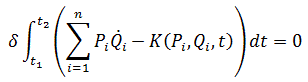
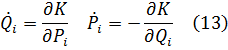
![]()
y Qi y Pi son constantes. Más aún,
![]()
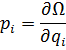
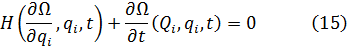
Ω (α1, α2,…,αn,q1, q2,…,qn, t,
Ahora bien, es un hecho de la teoría de transformaciones de Jacobi que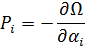
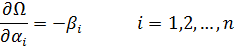
![]()
La aportación de Hamilton representó la culminación de una serie de esfuerzos encaminados a hallar un principio amplio a partir del cual podían ser derivadas las leyes del movimiento de varios problemas de la mecánica. Inspiró la lucha por obtener principios variacionales similares en otras ramas de la física matemática, tales como la elasticidad, teoría electromagnética, relatividad y teoría cuántica. Los principios que han sido derivados, aun el principio de Hamilton, no son necesariamente las aproximaciones más prácticas a la solución de problemas particulares. Más bien, el atractivo de tales formulaciones generales se apoya en intereses filosóficos y estéticos, aunque los hombres de ciencia ya no infieren que la existencia de un principio máximo-mínimo sea una prueba de la sabiduría y eficiencia de Dios.
Desde el punto de vista de la historia de las matemáticas, el trabajo de Hamilton y Jacobi es significativo porque motivó más investigación no solamente en el cálculo de variaciones, sino también sobre sistemas de ecuaciones diferenciales ordinarias y ecuaciones diferenciales parciales de primer orden.
3. Extensiones matemáticas del propio cálculo de variaciones
Los resultados de Euler y Legendre ofrecían nada más condiciones necesarias (cap. 24), pues, por ejemplo, en el caso más sencillo, para maximizar o minimizar la integral
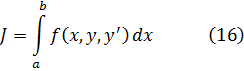
Considérense las curvas que satisfacen la ecuación (característica) de Euler; tales curvas son llamadas extrémales. Para el problema básico del cálculo de variaciones, existe una familia de extrémales pasando por un punto dado A. Supóngase ahora que A es uno de los extremos entre los que buscamos una curva maximante o minimizante. Dada cualquier otra extremal, el punto límite de la intersección de otras extrémales conforme se acercan al extremal es el punto conjugado de A sobre ese extremal. Otra manera de verlo es decir que tenemos una familia de curvas y éstas posiblemente tienen a su vez una envolvente. El punto de contacto de cualquier extremal y la envolvente de la familia es el punto conjugado de A sobre ese extremal. Entonces la condición de Jacobi es que si y(x) es un extremal entre los puntos extremos A y B del problema original, ningún punto conjugado debe estar sobre la extremal entre A y B ni ser el mismo B.
Lo que esto significa de una manera concreta se verá a través de un ejemplo.

Figura 30.1
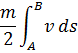
Jacobi reconsideró la segunda variación δ2J (cap. 24, sec. 4). Si escribimos y + et(x) en lugar de la y + δy de Lagrange y si a y b son las abscisas de A y B entonces
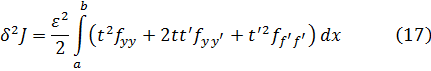

![]()
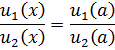
Jacobi demostró también que no se necesita resolver la ecuación accesoria. Dado que se debe resolver la ecuación de Euler en cualquier caso, sea y = y(x,c1,c2) la solución general de esa ecuación, esto es, la familia de extremales. Entonces se tomaría u1 como ∂y/∂c1, y u2 como ∂y/∂c2.
Jacobi dedujo dos conclusiones a partir de este trabajo sobre puntos conjugados. La primera fue que si a lo largo del extremal de A a B hay un punto conjugado de A, entonces es imposible un máximo o un mínimo. Jacobi estaba esencialmente en lo correcto con esta conclusión.
Sobre la base de sus consideraciones sobre puntos conjugados, Jacobi concluyó además que un extremal (una solución de la ecuación de Euler) tomado entre A y B para la cual fy'y' > 0 a lo largo de la curva y que no tiene ningún punto conjugado entre A y B (o en B) suministra un mínimo para la integral original. El argumento correspondiente con fy'y' < 0 —según aseveró— se mantiene para un máximo. De hecho, estas condiciones suficientes no eran correctas, como veremos dentro de unos momentos. En este ensayo de 1837, Jacobi enunció resultados y proporcionó indicaciones breves de las demostraciones. Las demostraciones completas de los enunciados correctos fueron suministradas por otros estudiosos de épocas posteriores.
Aparte del valor específico de los resultados de Jacobi para la existencia de una función maximizadora o minimizadora, su trabajo hizo evidente que el progreso en el cálculo de variaciones no podía ser guiado por la teoría de máximos y mínimos del cálculo ordinario.
Durante treinta y cinco años ambas conclusiones de Jacobi se aceptaron como correctas. Durante este período los artículos sobre la materia eran imprecisos respecto a los enunciados y dudosos en las demostraciones; había poca claridad en la formulación de los problemas y contenían errores de todo tipo. Entonces, Weierstrass realizó su trabajo sobre el cálculo de variaciones. Presentó sus resultados durante las conferencias que dio en Berlín en 1872, pero no las publicó él mismo. Sus ideas motivaron un nuevo interés, impulsando mayor actividad en la materia y afinando el pensamiento, tal como lo hiciera el trabajo de Weierstrass en otros dominios.
El primer punto importante de Weierstrass era que los criterios hasta entonces establecidos para un mínimo o un máximo —los de Euler, Legendre y Jacobi— eran limitados porque la supuesta curva minimizadora o maximizadora y(x) se comparaba con otras curvas y(x) + et(x), donde de hecho se daba por supuesto que et(x) y et'(x), o lo que Lagrange llamó δy y δy', eran pequeñas a lo largo del rango de x de A a B. Esto es, y(x) estaba siendo comparada con una clase limitada de otras curvas, y en cuanto a la satisfacción de los tres criterios lo hacía mejor que cualquier otra de estas curvas de comparación.
Figura 30.2
Weierstrass demostró en 1879 que para las variaciones débiles las tres condiciones —que la curva sea un extremal (una solución de la ecuación de Euler), que fy'y' > 0 a lo largo del extremal y que cualquier punto conjugado de A debe caer más allá de B— son claramente condiciones suficientes para que el extremal produzca un mínimo de la integral J (fy'y' > 0 para un máximo).
Más adelante, Weierstrass consideró variaciones fuertes. Para estas variaciones, introdujo primero una cuarta condición necesaria: definió una nueva función llamada función E, o función exceso, mediante
![]()
Entonces (en 1879), Weierstrass dirigió su atención a las condiciones suficientes para un máximo (o un mínimo) cuando se permiten variaciones fuertes. Para formular sus condiciones suficientes es necesario introducir el concepto de campo de Weierstrass.
Figura 30.3
Figura 30.4
En 1900, Hilbert[491] introdujo su teoría de la integral invariante, la cual simplificó grandemente la condición de suficiencia. Hilbert hizo la pregunta: ¿es posible determinar la función p(x,y) de tal forma que la integral
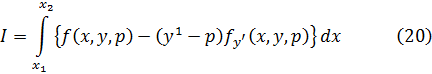
![]()
4. Problemas relacionados en el cálculo de variaciones
Nuestra exposición de la historia del cálculo de variaciones ha estado concentrada intensamente en la integral
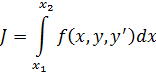
No rastrearemos la historia detallada de estos problemas porque no surgió de ahí ninguna característica básica de las matemáticas, aunque los problemas son significativos y se haya realizado considerable trabajo sobre ellos hasta el presente. Es tal vez digno de mención el que el problema de las superficies mínimas, que requiere resolver la ecuación
(1 + q2)r — 2pqs + (1 + p2)t = 0
había estado dormitando después del artículo de Ampère de 1817 hasta que el físico belga Joseph Plateau (1801-1883) en un libro de 1873, Statique expérimentale et théorique des liquides soumis aux seules formes moléculaires (Estática experimental y teórica de los líquidos sometido únicamente a sus formas moleculares), mostró que si uno sumerge cables teniendo la forma de curvas cerradas dentro de una solución de glicerina (o agua jabonosa) y entonces los retira, una película de jabón que tiene la forma de la superficie de área mínima, se apoyará en el borde del alambre. Así los matemáticos recibieron nuevos impulsos para considerar superficies mínimas acotadas por una curva cerrada en el espacio. Ya que la curva o curvas frontera pueden ser bastante complicadas, de hecho la solución explícita analítica para la superficie mínima sería imposible de obtener. Este problema, ahora conocido como el problema de Plateau, condujo a trabajar sobre la demostración de al menos la existencia de las soluciones, de las que pueden ser deducidas algunas propiedades de las soluciones.Bibliografía
- Dresden, Arnold: «Some recent work in the Calculus of Variations», Amer. Math. Soc. Bull, 32, 1926, 475-521.
- Duren, W. L., Jr.: «The development of sufficient conditions in the Calculus of Variations», University of Chicago Contributions to the Calculus of Variations, I, 1930, 245-349, University of Chicago Press, 1931. Hamilton, W. R.: The Mathematical Papers, 3 vols., Cambridge University Press, 1931, 1940 y 1967.
- Jacobi, C. G. J.: Gesammelte Werke, G. Reimer, 1886 y 1891, Chelsea (reimpresión), 1968, vols. 4 y 7. Vorlesungen über Dynamik (1866), Chelsea (reimp.), 1968. También en vol. 8 de los Gesammelte Werke de Jacobi.
- McShane, E. J.: «Recent developments in the Calculus of Variations», Amer.
- Math. Soc. Semicentennial Publications, II, 1938, 69-97.
- Porter, Thomas Isaac: «A history of the classical isoperimetric problem»,
- University of Chicago Contributions to the Calculus of Variations, II, 475-517, University of Chicago Press, 1933.
- Prange, Georg: «Die allgemeinen Integrationsmethoden der analytischen Me- chanik», Encyk. der Math. Wiss., B. G. Teubner, 1904-1935, IV, 2, 509-804.
- Todhunter, Isaac: A History of the Calculus of Variations in the Nineteenth Century, Chelsea (reimpresión), 1962.
- Weierstrass, Karl: Werke, Akademische Verlagsgesellschaft, 1927, vol. 7.
Capítulo 31
La teoría de Galois
Desafortunadamente, lo que se reconoce poco es que los libros científicos más valiosos son aquellos en los cuales el autor indica claramente lo que él no sabe, porque en general un autor impresiona a sus lectores escondiendo las dificultades.
Evariste Galois
1. Introducción1. Introducción
2. Ecuaciones binómicas
3. El trabajo de Abel sobre la solución de ecuaciones por radicales
4. La teoría de resolubilidad de Galois
5. Los problemas de construcción geométrica
6. La teoría de los grupos de sustituciones
Bibliografía
El centro escénico del álgebra a principios del siglo XIX lo ocupaba la solución de ecuaciones polinominales. Durante este período, Galois resuelve definitiva y comprensiblemente el problema general referente a qué ecuaciones se resolvían mediante operaciones algebraicas. No solamente creó el primer cuerpo coherente de teoría algebraica, sino que además introdujo nuevas nociones que habrían de desarrollarse en otras teorías algebraicas con mayor posibilidad de aplicación. En particular, los conceptos de grupo y cuerpo surgieron de sus investigaciones y las del Abel.
2. Ecuaciones binómicas
Ya hemos discutido (cap. 25, sec. 2) los esfuerzos inútiles de Euler, Vandermonde, Lagrange y Ruffini para resolver algebraicamente ecuaciones de grado mayor que 4 y la ecuación binomial xn - 1 = 0. Gauss obtuvo un gran éxito. En la última sección de sus Disquisitiones Arithmeticae[492]. Gauss consideró la ecuación
xp - 1= 0 (1)
donde p es primo[493]. A menudo dicha ecuación es llamada ecuación ciclotómica o ecuación de la división del círculo. El último término se refiere al hecho de que sus raíces son, por el teorema de De Moivre,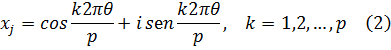
Gauss demostró que las raíces de esta ecuación pueden expresarse racionalmente en términos de las raíces de una serie de ecuaciones
Z1 = 0, Z2 = 0, … (3)
cuyos coeficientes son racionales en las raíces de las ecuaciones precedentes de la sucesión. Los grados de la ecuación (3) son precisamente los factores primos de p - 1. Existe un Zi para cada factor, incluso si está repetido. Además, cada una de los Zi - 0 se resolverá por radicales y así la ecuación (1) también puede resolverse por radicales.Este resultado es, por supuesto, de importancia primordial para el problema de resolver algebraicamente la ecuación general de grado n. Demuestra que algunas ecuaciones de grado alto se resuelven por radicales; por ejemplo, una ecuación de quinto grado si 5 es un factor de p - 1 o una ecuación de grado séptimo si 7 es tal factor.
El resultado es también de gran importancia para el problema geométrico de construir polígonos regulares de p lados. Si p - 1 no contiene otros factores más que 2, entonces el polígono es construible con regla y compás, ya que los grados de la ecuación (3) son siempre 2 y cada una de sus raíces es construible en términos de sus coeficientes. Así, estamos en condiciones de construir todos los polígonos de un número primo de lados p si p - 1 es una potencia de 2. Tales primos son 3, 5, 17, 257, 65537,... Alternativamente, es posible que un polígono regular sea construido si p es un primo de la formaGauss indica (art. 365) que a pesar de que la construcción geométrica de polígonos regulares de 3, 5 y 15 lados, y de aquellos que se derivan inmediatamente de ellos —por ejemplo, 2n, 2n.3, 2n.5, 2n.15, donde n es un entero positivo— era conocida en el tiempo de Euclides, en un intervalo de 2000 años no se habían descubierto nuevos polígonos construibles y los geómetras fueron unánimes al declarar que no se podía construir otros.
Gauss pensó que su resultado llevaría a todo tipo de intentos por encontrar nuevos polígonos construibles con un número primo de lados. Entonces advierte: «Siempre que p - 1 contiene otros factores primos además de 2, llegamos a ecuaciones superiores, a saber, a una o más ecuaciones cúbicas si 3 entra una vez o con más frecuencia como factor de p - 1, a ecuaciones del quinto grado si p - 1 es divisible por cinco, etc. y podemos demostrar con todo rigor que estas ecuaciones superiores no pueden ser evitadas o hechas depender de ecuaciones de grado inferior; y aunque los límites de este trabajo no nos permiten dar una demostración aquí, seguimos pensando que es necesario indicar este hecho y decir que no se debe seguir buscando construir otros polígonos [de un número primo de lados] que aquellos proporcionados por nuestra teoría, como por ejemplo, polígonos de 7, 11, 13 y 19 lados, y así emplear este tiempo en vano.»
Más adelante, Gauss considera (art. 366) polígonos de cualquier número de lados n y asevera que un polígono regular de n lados es construible si y sólo si n = 2i p1.p2,..., pn, donde los p1, p2,...,pn son primos distintos de la forma
![]()
La construcción de polígonos regulares había interesado a Gauss desde 1796, cuando concibió su primera demostración de que un polígono de 17 lados es construible. Existe una historia acerca de este descubrimiento y es útil su repetición. Este problema de construcción ya era famoso: un día Gauss se acercó a su profesor A. G. Kästner, de la Universidad de Göttingen, con la demostración de que este polígono es construible. Kästner no creía en tal aseveración y buscó deshacerse de Gauss, como hoy en día los profesores despiden a los trisectores de ángulos. En lugar de tomar su tiempo para examinar la demostración de Gauss y encontrar el supuesto error en ella, Kästner le dijo a Gauss que la construcción carecía de importancia, ya que todas las construcciones prácticas eran conocidas. Por supuesto, Kästner sabía que la existencia de construcciones prácticas o aproximadas era irrelevante para el problema teórico. Para interesar a Kästner en su demostración, Gauss le señaló que había resuelto una ecuación algebraica de grado diecisiete. Kästner respondió que la solución era imposible. Pero Gauss respondió que había reducido el problema a resolver una ecuación de menor grado. «Oh, está bien», se burló Kästner, «yo ya he hecho lo mismo». Más tarde Gauss le pagó a Kästner, quien también se enorgullecía de su poesía, elogiando a Kästner como el mejor poeta entre los matemáticos y el mejor matemático entre los poetas.
3. El trabajo de Abel sobre la solución de ecuaciones por radicales
Abel leyó el trabajo de Lagrange y Gauss sobre la teoría de ecuaciones y cuando aún estudiaba el grado de preparatoria atacó el problema de la solubilidad de ecuaciones de grado superior siguiendo el tratamiento de Gauss de la ecuación binómica. Primero, Abel pensó que había resuelto la ecuación general de quinto grado por radicales. Pero pronto, convencido de su error, intentó evidenciar que tal demostración no era posible (1824-1826). Primero tuvo éxito en demostrar el teorema: las raíces de una ecuación soluble por radicales pueden ser dadas de tal forma que cada uno de los radicales que aparece en las expresiones para las raíces es expresable como una función racional de las raíces de la ecuación y ciertas raíces de la unidad. Abel usó entonces su teorema para demostrar[496] la imposibilidad de resolver por radicales la ecuación general de grado mayor que cuatro.
La demostración de Abel, realizada ignorando el trabajo de Ruffini (cap. 25, sec. 2), es indirecta e innecesariamente complicada. Su artículo también contenía un error en una clasificación de funciones, que afortunadamente no era esencial para el argumento. Más tarde publicó otras dos demostraciones más elaboradas. Una demostración simple, sencilla y rigurosa basada en las ideas de Abel la proporcionó Kronecker en 1879[497].
Así, el problema de la solución de ecuaciones generales de grado mayor que cuatro fue zanjada por Abel. También consideró algunas ecuaciones especiales. Tomó[498] el problema de la división de la lemniscata (resolver xn - 1 = 0 es el equivalente al problema de la división del círculo en n arcos iguales) y llegó a una clase de ecuaciones algebraicas, ahora llamadas ecuaciones abelianas, resolubles por radicales. La ecuación ciclotómica (1) es un ejemplo de ecuación abeliana. Más generalmente, una ecuación es abeliana si todas sus raíces son funciones racionales de una de ellas, esto es, si las raíces son x1, θ1(x1), θ2(x2), θn-1 (xn-1) donde las θi son funciones racionales. Existe también la condición que
θα(θβ(x1) = θβ(θα(x1)
para todos los valores de α y de β de l a n - 1.En este último trabajo introdujo dos conceptos (aunque no la terminología): cuerpo y polinomio irreducible en un cuerpo dado. Por cuerpo de números, como Gauss más tarde, dio a entender una colección de números tales que la suma, diferencia, producto y cociente de dos números cualesquiera en la colección (excepto la división por 0) están también en la colección. Así, los números racionales, los números reales y los números complejos forman un cuerpo. Se dice que un polinomio es reducible en un cuerpo (comúnmente el cuerpo al cual pertenecen los coeficientes) si puede ser expresado como el producto de dos polinomios de grados menores y con coeficientes en el cuerpo. Si el polinomio no puede ser expresado de tal forma se dice que es irreducible.
Abel atacó entonces el problema de caracterizar todas las ecuaciones que son resolubles por radicales y había comunicado algunos
resultados a Crelle y a Legendre poco antes de que la muerte se lo llevara en 1829.
4. La teoría de resolubilidad de Galois
Después de la obra de Abel la situación era como sigue: a pesar de que la ecuación general de grado superior a cuatro no era soluble por radicales, había muchas ecuaciones especiales, tales como las ecuaciones binómicas xp = a, p primo, y las ecuaciones abelianas que eran solubles por radicales. La finalidad ahora era determinar qué ecuaciones son solubles por radicales. Esta tarea justamente iniciada con Abel, la adoptó Evariste Galois (1811-1832). Nacido de padres holgados y bien educados, asistió a uno de los renombrados liceos de París e inició su estudio de las matemáticas a los quince años de edad. Esta materia se convirtió en su pasión y se abocó con empeño a estudiar los trabajos de Lagrange, Gauss, Cauchy y Abel. Ignoró las otras materias. Galois quiso entrar en la Ecole Polytechnique, pero posiblemente porque falló en explicar con suficiente detalle las preguntas que tenía que contestar oralmente en el examen de admisión, o tal vez porque los examinadores no lo entendieron, fue rechazado en dos intentos. Por tales circunstancias, entró a la Ecole Préparatoire (era el nombre entonces de la Ecole Nórmale, y era escuela muy inferior por aquellos días). Durante la revolución de 1830, que arrojó del trono a Charles X e instaló a Louis Philippe, Galois criticó públicamente al director de la escuela por haber dejado de apoyar la revolución y este hecho produjo su expulsión. Fue arrestado en dos ocasiones por ofensas políticas, y pasó casi el último año y medio de su vida en prisión, de donde sale para morir en un duelo el 31 de mayo de 1832.
Durante su primer año en la Escuela, Galois publicó cuatro artículos. En 1829 presentó dos artículos sobre la solución de ecuaciones a la Academia de Ciencias. Estos le fueron confiados a Cauchy, quien los perdió. En enero de 1830 presentó a la Academia otro escrito cuidadosamente redactado sobre sus investigaciones, el cual se le envió a Fourier, quien murió poco después, y dicho ensayo también se perdió. Siguiendo la sugerencia de Poisson, Galois (1831) escribió un nuevo ensayo sobre sus investigaciones. Este texto, «Sur les conditions de résolubilité des équations par radicaux» («Sobre las condiciones de resolubilidad de las ecuaciones por radicales»)[499], su único artículo completo sobre su teoría de la solución de ecuaciones, le fue devuelto por Poisson como ininteligible, con la recomendación de que debería escribir una explicación más amplia. La noche anterior a su duelo, Galois bosquejó precipitadamente un apresurado resumen de sus investigaciones que confió a un amigo, August Chevalier. Este resumen se ha conservado.
En 1846, Liouville editó y publicó en el Journal de Mathématiques[500] parte de los artículos de Galois, incluyendo una revisión de su artículo de 1831. Más adelante, el Cours d’algebre supérieure (Curso de álgebra superior, 3.a ed.) de Serret de 1866, proporcionó una exposición de las ideas de Galois. Camile Jordán, en 1870, en su libro Traité des substitutions et des équations algébraiques (Tratado de las sustituciones y de las ecuaciones algebraicas), hace la primera presentación clara y completa de la teoría de Galois.
Galois estudió el problema de caracterizar las ecuaciones solubles por radicales mejorando las ideas de Lagrange, aunque también derivó algunas sugerencias del trabajo de Legendre, Gauss y Abel. Propuso considerar la ecuación general, la cual es, por supuesto
xn + a1xn-1 + ... + an-1x + an = 0 (4)
donde, como en el trabajo de Lagrange, los coeficientes deben ser independientes o arbitrarios por completo, y ecuaciones particulares, tales comox4 + px2 + q = 0 (5)
donde únicamente dos coeficientes son independientes. El pensamiento central de Galois consistió en evitar la construcción de los resolventes de Lagrange (cap. 25, sec. 2) de la ecuación polinómica dada, una construcción que requiere gran habilidad y que no tiene una metodología clara.Como Lagrange, Galois hace uso de la notación de sustituciones o permutaciones de las raíces. Así, si xl, x2, x3 y x4 son las cuatro raíces de una ecuación de cuarto grado, el intercambio de x1 y x2en cualquier expresión en las xi es una sustitución. Esta sustitución particular está indicada por

Para asegurar algún entendimiento de las ideas de Galois consideremos la ecuación[501]
x4 + px2 + q = 0,
donde p y q son independientes. Sea R el cuerpo formado por las expresiones racionales en p y q con coeficientes en el cuerpo de los números racionales, una expresión típica es (3p2 - 4q)/(q2 - 7p). Se dice con Galois que R es el cuerpo obtenido al añadir las letras o indeterminadas p y q a los números racionales. Este cuerpo R es el cuerpo o dominio de racionalidad de los coeficientes de la ecuación dada y se dice que la ecuación pertenece al cuerpo R. Como Abel, Galois no usó los términos cuerpo o dominio de racionalidad, pero sí usó este concepto.Sucede que nosotros sabemos que las raíces de la ecuación de cuarto grado son

Ahora considérese x12 -x32, que es igual a √(p2 - 4q). Adjuntamos este radical a R, y formamos el cuerpo R', esto es, formamos el cuerpo más pequeño conteniendo R y √(p2 - 4q). Entonces
x12 - x32 = √(p2 - 4q) (6)
es una relación en R'. Ya que x1 + x2 = 0 y x3 + x4 = 0 también tenemos quex12 = x22 y x32 = x42
Entonces, a la vista de los dos últimos hechos podemos decir que las cuatro primeras de las ocho sustituciones anteriores hacen la relación (6) en R' verdadera, pero las últimas cuatro no. Entonces las cuatro sustituciones, si dejan invariante toda relación verdadera en R’ entre las raíces, son el grupo de la ecuación en R’. Las cuatro son un subgrupo de las ocho.Ahora supongamos que adjuntamos a R' la cantidad √[(-p - D)/2], donde D = √(p2 - 4q) y se forma el cuerpo R". Entonces
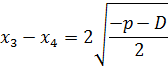
Si ahora adjuntamos a R" la cantidad √[(-p - D)/2] obtenemos R'". En R'" tenemos
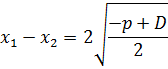
Podemos ver a partir de la discusión anterior que el grupo de una ecuación es clave para su solubilidad, ya que el grupo expresa el grado de indistinción de las raíces. Nos dice lo que desconocemos acerca de las raíces.
Había muchos grupos, o más estrictamente un grupo de sustituciones y subgrupos sucesivos, relacionados con lo anterior. Ahora el orden del grupo (o subgrupo) es el número de elementos contenidos en él. De esta forma, tenemos grupos de órdenes 24, 8, 4, 2 y 1. El orden de un subgrupo divide siempre el orden del grupo (sec. 6). El índice de un subgrupo es el orden del grupo en el cual está, dividido por el orden del subgrupo. Así, el índice de un subgrupo de orden ocho es tres.
El esbozo anterior muestra meramente las ideas con las que trataba Galois. Su trabajo procedió como sigue: dada una ecuación general o particular, primero demostró cómo se encontraba el grupo G de esta ecuación en el cuerpo de los coeficientes, esto es, el grupo de las sustituciones de las raíces que deja invariante cada relación entre las raíces con los coeficientes en ese cuerpo. Por supuesto, se ha de encontrar el grupo de las ecuaciones sin conocer las raíces. En nuestro ejemplo anterior, el grupo de la ecuación cuártica era de orden 8 y el cuerpo de los coeficientes era R. Habiendo encontrado el grupo G de la ecuación, se busca en seguida el subgrupo mayor H en G. En nuestro ejemplo éste fue el subgrupo de orden 4. Si existieran dos o más subgrupos mayores, tomamos cualquiera. La determinación de H es una cuestión de pura teoría de grupos y es susceptible de realizarse. Habiendo encontrado H, se puede encontrar mediante un conjunto de procedimientos, considerando únicamente operaciones racionales, una función (p de las raíces cuyos coeficientes pertenecen a R y que no cambia de valor bajo las sustituciones en H, pero sí varía con las otras sustituciones en G. En nuestro ejemplo anterior la función era x12 - x32. De hecho, es posible obtener una infinidad de tales funciones. Por supuesto, necesitamos encontrar tal función sin conocer las raíces. Existe un método de construcción de una ecuación en R una de cuyas raíces es la función 0. El grado de esta ecuación es el índice de H en G. Esta ecuación es llamada una resolvente parcial[503]. En nuestro ejemplo, la ecuación es t2 - (p2 - 4q) = 0 y su grado es 8/4 o bien 2
Ahora bien, se debe ser capaz de resolver la resolvente parcial para encontrar la raíz ϕ. En nuestro ejemplo ϕ es √(p2 - 4q). Se adjunta ϕ a R obteniendo un nuevo cuerpo R'. Entonces el grupo de la ecuación original con respecto al cuerpo R' resulta ser H.
Ahora repetimos el procedimiento. Tenemos el grupo H, de orden 4 en nuestro ejemplo, y el cuerpo R', y buscamos el subgrupo mayor en H. En nuestro ejemplo, era el subgrupo de orden 2. Llamemos a este subgrupo K. Ahora obtenemos una función de las raíces de la ecuación original cuyos coeficientes pertenecen a R' y cuyo valor no varía bajo cada sustitución en K, pero es cambiado por otras sustituciones en H. En nuestro ejemplo esta ecuación es t2 - 2(- p - √(p2 - 4q)) = 0. El grado de dicha ecuación es el índice de K con respecto a H, esto es, 4/2 ó 2. Tal ecuación es la segunda revolvente parcial.
Ahora se debe ser capaz de resolver esta ecuación revolvente y obtener una raíz, la función ϕ1 y adjuntar este valor a R' y así formar el cuerpo R". Con respecto a R", el grupo de la ecuación es K.
Repetimos de nuevo el proceso. Encontramos el subgrupo máximo L en K. En nuestro ejemplo éste era justamente la sustitución identidad E. Buscamos una función de las raíces (con coeficientes en R") que conserve su valor bajo E pero no por otras sustituciones de K. En nuestro ejemplo tal función era la x1 — x2. Para obtener esta ϕ2 sin conocer las raíces debemos construir una ecuación en R" teniendo la función ϕ2 como raíz. En nuestro ejemplo la ecuación es t2 - 2(-p + √(p2 - 4q) = 0. El grado de esta ecuación es el índice de L en K. En nuestro ejemplo este índice era 2/1 ó 2. Tal ecuación es la tercera revolvente parcial. Debemos resolverla para encontrar el valor de ϕ2.
Al adjuntar esta raíz a R" obtenemos un cuerpo R'". Supongamos que hemos llegado al estadio final donde el cuerpo de la ecuación original en R'" es la substitución identidad E.
Galois demostró que cuando el grupo de una ecuación con respecto a un cuerpo dado es justamente E, entonces las raíces de la ecuación son elementos de ese cuerpo. Por tanto las raíces están en el cuerpo R'" y conocemos el cuerpo en que están las raíces, porque R'" fue obtenido a partir del cuerpo conocido R por la adjunción de cantidades conocidas. Existe un proceso directo para encontrar las raíces mediante operaciones racionales en R"'.
Galois proporcionó un método para encontrar el grupo de una ecuación dada, las resolventes sucesivas y los grupos de la ecuación con respecto a los cuerpos de coeficientes sucesivamente ampliados que resultan de añadir las raíces de estas resolventes sucesivas del grupo original. Estos procesos incluyan mucha teoría pero, como señaló el propio Galois, su trabajo no estaba dirigido a ser un método práctico para resolver ecuaciones.
Luego, Galois aplicó la teoría anterior al problema de resolver ecuaciones polinomiales por medio de operaciones racionales y radicales. Aquí presentó otra noción de la teoría de grupos. Supongamos que H es un subgrupo de G. Si se multiplican las sustituciones de H por cualquier elemento g de G, entonces se obtiene una nueva colección de sustituciones que será denotada por gH, indicando la notación que la sustitución g primero se realiza y luego es aplicado cualquier elemento de H. Si gH = Hg para cada g en G, entonces H es llamado un subgrupo normal (autoconjugado o invariante) en G.
Recordamos que el método de Galois de resolver una ecuación requiere encontrar y resolver las resolventes sucesivas. Galois demostró que cuando el resolvente que sirve para reducir el grupo de una ecuación, digamos de G a H, es una ecuación binómica xp = A de grado primo p, entonces H es un subgrupo normal en G (y de índice p), e inversamente, si H es un grupo subnormal en G y de índice primo p entonces la resolvente correspondiente es una ecuación binómica de grado p o puede ser reducida a una de ese tipo. Si todas las resolventes sucesivas son ecuaciones binomiales, podemos resolver la ecuación original mediante radicales, pues sabemos que podemos pasar del cuerpo inicial al cuerpo final en el que están las raíces mediante adjunciones sucesivas de radicales. Inversamente, si una ecuación es soluble por radicales, entonces el conjunto de las ecuaciones resolventes debe existir, y son ecuaciones binomiales.
Así, la teoría de la resolubilidad mediante radicales es, en una visión general, la misma que la teoría de la solución dada anteriormente, excepto que en la serie de subgrupos
G, H, K, L,..., E
cada uno debe ser un subgrupo máximo normal (no ser un subgrupo de cualquier subgrupo normal mayor) del grupo precedente. Tal serie es llamada una serie de composición. Los índices de H en G, K en H y así en adelante, son llamados los índices de la serie de composición. Si los índices son números primos la ecuación es soluble por radicales, y si los índices no son primos no lo es. Cuando uno continúa hasta encontrar la sucesión de subgrupos normales maximales puede haber una elección; esto es, puede existir más de un subgrupo normal maximal de orden máximo en un grupo dado o subgrupo. Uno puede escoger cualquiera, aunque a partir de ahí los subgrupos pueden diferir. Pero resultará el mismo conjunto de índices aunque el orden en el que aparezcan difiera (véase el teorema de Jordan-Hölder más adelante). El grupo G, que contiene una serie de composición de índices primos, se dice que es resoluble.¿Cómo es que la teoría de Galois muestra que la ecuación general de grado n no es soluble por radicales para n > 4 mientras que para n ≤ 4 sí lo es? Para la ecuación general de grado w-ésimo el grupo está compuesto por todas las n! substituciones de las n raíces. Este grupo es llamado el grupo simétrico de grado n. Su orden es por supuesto n!. No es difícil encontrar la serie de composición para cada grupo simétrico. El subgrupo normal maximal, que es llamado el subgrupo alternado, es de orden n!/2. El único subgrupo normal del grupo alternado es el elemento identidad. De aquí que los índices sean 2 y n!/2. Pero el número n!/2, para n >4, nunca es primo. De aquí que la ecuación general de grado mayor que 4 no sea soluble por radicales. Por otra parte, la ecuación cuadrática puede ser resuelta con ayuda de una única ecuación resolvente. Los índices de la serie de composición consisten únicamente en el número 2. La ecuación general de tercer grado requiere para su solución dos ecuaciones resolventes de la forma y2 = A y z3 = B. Estas son, por supuesto, resolventes binomiales. Los índices de la serie de composición son 2 y 3. La ecuación general de cuarto grado puede ser resuelta con cuatro ecuaciones resolventes binomiales, una de grado 3 y tres de grado 2. Los índices de la serie de composición son, entonces, 2, 3, 2, 2.
Para ecuaciones con coeficientes numéricos, como opuestas a aquellas con coeficientes literales independientes, Galois proporcionó una teoría similar a la descrita con anterioridad. Sin embargo, el proceso de determinar la solubilidad mediante radicales es más complicado, a pesar de que los principios básicos son los mismos.
Galois demostró también algunos teoremas especiales. Si uno tiene una ecuación irreducible de grado primo cuyos coeficientes están en un cuerpo R y cuyas raíces son todas funciones racionales de dos de la raíces con coeficientes en R, entonces la ecuación es soluble mediante radicales. También demostró el recíproco: toda ecuación irreducible de grado primo que es soluble mediante radicales tiene la propiedad que cada una de las raíces es una función racional de dos de ellas con coeficientes en R. Tal ecuación es llamada ahora ecuación galoisiana. El ejemplo más simple de ecuación galoisiana es xp - A = 0. La noción es una extensión de las ecuaciones abelianas.
Como un epílogo, Hermite[504] and Kronecker (en una carta a Hermite)[505] y en un artículo posterior[506] resolvieron la ecuación de quinto grado por medio de funciones modulares elípticas. Esto es análogo al uso de funciones trigonométricas para resolver el caso irreducible de la ecuación cúbica.
5. Los problemas de construcción geométrica
Los matemáticos del siglo XVIII no dudaron que los famosos problemas de construcción pudieran ser resueltos. El trabajo de Galois proporcionó un criterio de constructibilidad que eliminó algunos de los famosos problemas.
Cada caso de una construcción con regla y compás requiere encontrar un punto de intersección, ya sea de dos rectas, una recta y un círculo, o dos círculos. Con la introducción de la geometría de coordenadas se reconoció que, en términos algebraicos, tales pasos significan la solución simultánea de dos ecuaciones lineales, una lineal o una cuadrática, o dos ecuaciones cuadráticas. En cualquier caso, lo peor que interviene algebraicamente es una raíz cuadrada.
De aquí que las cantidades sucesivas encontradas por pasos o construcciones sucesivas son en el peor de los casos el resultado de una cadena de raíces cuadradas que se aplican a cantidades dadas. Por consiguiente, las cantidades constructibles deben estar en cuerpos obtenidos por la adjunción al cuerpo conteniendo las cantidades dadas de únicamente raíces cuadradas de cantidades dadas o construidas después. Podemos llamar a tales extensiones cuerpos de extensión cuadrática.
Al llevar a cabo las construcciones sucesivas deben ser observadas unas cuantas restricciones. Por ejemplo, algunos de los procesos permiten el uso de una recta o círculo arbitrario. Así, al bisecar un segmento de recta podemos usar círculos más grandes que la mitad del segmento de recta. Uno debe escoger este círculo en el cuerpo o en el cuerpo de extensión construible de los elementos dados. Esto puede ser hecho.
También sucede que los cuerpos de extensión pueden contener elementos complejos porque, por ejemplo, puede aparecer la raíz cuadrada de una coordenada negativa. Estos elementos complejos son constructibles, porque las partes real e imaginaria de las cantidades complejas que aparecen son cada una de ellas raíces de una ecuación real y estas raíces son construibles.
Dado un problema de construcción, uno halla primero una ecuación algebraica cuya solución es la cantidad deseada. Esta cantidad debe pertenecer a algún cuerpo de extensión cuadrática del cuerpo de las cantidades dadas. En el caso del polígono regular de 17 lados esta ecuación es x17 - 1 = 0 y la cantidad dada puede ser tomada como el radio del círculo unitario. La ecuación irreducible relevante es x16 + x15 + ... +1 = 0. En términos de la teoría de Galois la condición necesaria y suficiente para que una ecuación sea soluble con raíces cuadradas es que el orden del grupo de Galois de la ecuación sea una potencia de 2. Este es el caso para la ecuación x16 +... + 1 = 0 y la serie de composición es 2, 2, 2, 2. Esto significa que las resolventes son ecuaciones binomiales de grado 2, de tal forma que únicamente son añadidas raíces cuadradas al cuerpo racional original determinado por el radio dado del círculo unidad. Con este criterio de Galois se puede demostrar la proposición de Gauss de que un polígono regular con un número p primo de lados puede ser construido con regla y compás si y sólo si el número p tiene la forma
Pero el criterio de Galois no se aplica en absoluto al problema de cuadrar el círculo. Aquí la cantidad dada es el radio del círculo. La ecuación correspondiente es x2 = πr2. A pesar de que esta ecuación es únicamente cuadrática, no es cierto que su solución pertenece a un cuerpo de extensión cuadrática del cuerpo determinado por la cantidad dada, ya que π no es un irracional algebraico (cap. 41, sec. 2). El trabajo de Galois, entonces, no sólo respondió por completo a la cuestión de qué ecuaciones son solubles con operaciones algebraicas, sino que dio un criterio general para determinar la constructibilidad con regla y compás de figuras geométricas.
En cuanto concierne a los famosos problemas de construcción, debemos decir que antes de que la teoría de Galois se les aplicara, Gauss y Wantzel habían determinado cuáles de los polígonos regulares son construibles (sec. 2), y Wantzel, en un ensayo de 1837[507], demostró que el ángulo general no podía ser trisecado, ni tampoco se podía duplicar un cubo. Demostró que cada cantidad constructible debe satisfacer una ecuación de grado 2n, y esto no es cierto en los dos casos mencionados.
6. La teoría de los grupos de sustituciones
En su trabajo sobre la solubilidad de ecuaciones (cap. 25, sec. 2), Lagrange presentó como la clave para su análisis las funciones de las n raíces que toman el mismo valor bajo algunas permutaciones de las raíces. A continuación, se propuso estudiar, en los mismos ensayos, funciones con el propósito de determinar los diferentes valores que toman con los n! posibles valores que las n! permutaciones de las n variables (las raíces) pueden originar. Trabajos posteriores de Ruffini, Abel y Galois prestaron una mayor importancia a este tema. El hecho de que una función racional de n letras tome el mismo valor bajo alguna colección de permutaciones o sustituciones de las raíces significa, como ya hemos visto, que esta colección es un subgrupo del grupo simétrico total. Esto fue observado explícitamente por Ruffini en su Teoría genérale de le equazioni (Teoría General de las Ecuaciones, 1799). De aquí que lo que Lagrange inició significara una manera de estudiar subgrupos de un grupo de sustituciones. El modo más directo es, por supuesto, estudiar el propio grupo de sustituciones y determinar sus subgrupos. Ambos métodos para estudiar la estructura o composición de grupos de sustituciones se convirtieron en una materia activa seguida con un interés en sí y para sí misma, a pesar que no se ignoró la conexión con la solubilidad de las ecuaciones. La teoría de sustituciones o grupos de permutaciones fue la primera gran investigación que en última instancia promovió el surgimiento de la teoría abstracta de grupos. Aquí debemos hacer mención de algunos teoremas concretos sobre grupos de sustituciones que se obtuvieron durante el siglo XIX.
El propio Lagrange estableció un resultado importante, que en lenguaje moderno afirma que el orden de un subgrupo divide el orden del grupo. Pietro Abbati (1768-1842), en una carta del 30 de septiembre de 1802 —publicada posteriormente[508] —comunicó a Ruffini la demostración de este teorema.
En su libro de 1799 Ruffini presentó, aunque de una manera vaga, las nociones de transitividad y primitividad. Un grupo de permutaciones es transitivo si cada letra del grupo es reemplazada por cada una de las otras letras bajo las varias permutaciones del grupo. Si G es un grupo transitivo y los n símbolos o letras pueden ser divididos en r subconjuntos diferentes σi, i = 1, 2,...,r, conteniendo cada subconjunto si símbolos de tal forma que cualquier permutación de G o permuta los símbolos de las σi entre ellos mismos, o reemplaza estos símbolos por los símbolos de las σj, esto para cada i = 1,2,...r, entonces G es llamado imprimitivo. Si no es posible tal separación de los n símbolos, entonces el grupo transitivo es llamado grupo primitivo. Ruffini demostró también que no existe un subgrupo de orden k para todo k en un grupo de orden n.
Cauchy, motivado por el trabajo de Lagrange y Ruffini, escribió un artículo importante sobre los grupos de sustituciones[509]. Con la teoría de ecuaciones a la vista, demostró que no existe un grupo de n letras (grado n) cuyo índice relativo a la totalidad del grupo simétrico en n letras sea menor que el máximo número primo que no excede n, a menos que el índice sea 2 ó 1. Cauchy estableció este teorema en el lenguaje de los valores de las funciones: el número de valores diferentes de una función no simétrica de n letras no puede ser menor que el máximo primo p menor que n, a menos que sea 2.
Galois realizó el mayor avance en la introducción de conceptos y teoremas acerca de grupos de sustituciones. Su concepto más importante lo constituyó la noción de subgrupo normal (invariante o autoconjugado). Otro concepto para grupos debido a Galois es el de isomorfismo entre dos grupos, esto es, una correspondencia uno-a-uno entre los elementos de los dos grupos tal que si a.b. = c en el primero, entonces para los elementos correspondientes en el segundo a'.b' = c'. También presentó las nociones de grupos simples y compuestos. Un grupo que carece de subgrupo invariante es simple; si no es compuesto. A propósito de estas nociones, Galois expresó la conjetura[510] de que el grupo simple más pequeño cuyo orden es un número compuesto es un grupo de orden 60.
El trabajo de Galois no fue conocido hasta que Liouville publicó partes de él en 1846, y aun entonces el contenido no era fácilmente accesible. Por otro lado, los trabajos de Lagrange y Ruffini sobre grupos de sustituciones, apoyados en el lenguaje de los valores que puede tomar una función de n letras, se hicieron bien conocidos. De aquí que la solución de ecuaciones retrocediera, y cuando Cauchy volvió a la teoría de las ecuaciones se concentró en los grupos de sustituciones. Durante los años de 1844 a 1846 escribió multitud de ensayos. En el principal[511], sistematizó muchos de los resultados anteriores y demostró un buen número de teoremas especiales sobre grupos primitivos, transitivos y demostró la aserción de Galois de que todo grupo finito (de sustituciones) cuyo orden es divisible por un primo p contiene al menos un subgrupo de orden p. El artículo principal fue seguido por un gran número de otros publicados en las Comptes Rendus de la Academia de París entre los años 1844 y 1846[512]. La mayor parte de su trabajo versaba sobre valores formales (esto es no numéricos) que las funciones de n letras pueden tomar al cambiarse las letras y en encontrar funciones que toman un número dado de valores.
Después de que Liouville publicase parte del trabajo de Galois, Serret impartió cursos sobre ello en la Sorbona y en la tercera edición de su Cours proporcionó una mejor exposición textual de la teoría de Galois. El trabajo de clarificar las ideas de Galois sobre la solubilidad de ecuaciones y el desarrollo de la teoría de los grupos de sustituciones continuaron a la par a partir de ahí. En su texto, Serret proporcionó una forma mejorada del resultado de Cauchy de 1815. Si una función de n letras toma menos de p valores, donde p es el mayor primo menor que n, entonces la función no admite más de dos valores.
Uno de los problemas que Serret subrayó en el texto de 1866 pide todos los grupos que pueden formarse con n letras. Este problema ya había atraído la atención de Ruffini; y él, Cauchy y el mismo Serret, en su ensayo de 1850[513], proporcionaron un buen número de resultados parciales, como también lo hizo Thomas Penyngton Kirman (1806-1895). A pesar de muchos esfuerzos y cientos de resultados parciales, el problema sigue sin solución.
Después de Galois, Camile Jordán (1838-1922) fue el primero en añadir conceptos significativos a la teoría de Galois. En 1869[514], demostró un resultado básico. Sea Gi un subgrupo maximal autoconjugado (normal) de G0, G2 un subgrupo maximal autoconjugado de G1, y así en adelante hasta que la serie termina en el elemento identidad. Esta serie de subgrupos es llamada una serie de composición de Gq. Si Gi+1 es cualquier subgrupo autoconjugado de orden r en Gi cuyo orden es p, entonces Gi puede ser descompuesto en A = p/r clases. Dos elementos están en la misma clase si uno es el producto del otro y un elemento de Gí+1. Si a es cualquier elemento en una clase y b cualquier elemento en otra, el producto estará en la misma tercera clase. Estas clases forman un grupo para el cual Gi+l es el elemento identidad y el grupo es llamado grupo cociente o grupo factor de Gi por Gi+1. Se denota por Gi/Gi+l, notación introducida por Jordán en 1872. Los grupos cociente G0/G1, G1/G2, ... son llamados los grupos factores de composición de G0 y sus órdenes se conocen como los factores de composición o índices de composición. Puede haber más de una serie de composición en G0. Jordán demostró que el conjunto de factores de composición es invariante excepto para el orden en el que pueden aparecer y (Ludwig) Otto Hölder (1859-1937), profesor de la Universidad de Leipzig, demostró[515] que los grupos cocientes mismos eran independientes de las series de composición; esto es, el mismo conjunto de grupos cocientes estaría presente para cualquier serie de composición. Los dos resultados son llamados el teorema de Jordan-Hölder.
El conocimiento de los grupos de sustituciones (finitos) y su conexión con la teoría de ecuaciones de Galois hasta 1870, fue organizado en un libro magistral de Jordán, su Traité des substitutions et des équations algébriques (Tratado de las sustituciones y de las ecuaciones algebraicas, 1870). En su libro, Jordán —como casi todos los autores que lo precedieron— usó como definición de grupo de sustituciones la de que es una colección de sustituciones tales que el producto de dos miembros cualesquiera de la colección pertenece a la colección. Las otras propiedades que comúnmente postulamos hoy en día en la definición de un grupo (cap. 49, sec. 2) se utilizaron, pero fueron incorporadas como propiedades obvias de tales grupos o como condiciones adicionales, aunque no especificadas en la definición. El Traité presentó nuevos resultados e hizo explícitos para grupos de sustituciones las nociones de isomorfismo (isomorphisme holoédrique) y homomorfismo (isomorphisme mériédrique), siendo la última una correspondencia de varios-a-uno entre los dos grupos tal que a.b = c implica a'.b' = c'. Jordán añadió resultados fundamentales sobre grupos transitivos y compuestos. El libro también contiene la solución de Jordán al problema propuesto por Abel, determinar las ecuaciones de un grado dado que son resolubles por radicales y reconocer si una ecuación dada pertenece o no pertenece a esta clase. Los grupos de las ecuaciones solubles son conmutativos. Jordán los llamó abelianos y el término abeliano se aplicó a los grupos conmutativos a partir de entonces.
Poco tiempo después de haber aparecido el Traité, el profesor de matemáticas noruego Ludwig Sylow (1832-1918) demostró otro teorema importante sobre grupos de sustituciones. Cauchy había demostrado que todo grupo cuyo orden es divisible por un número primo p debe contener uno o más subgrupos de orden p. Sylow [516] amplió el teorema de Cauchy. Si el orden de un grupo es divisible por p, siendo p primo, pero no por pα+1 entonces el grupo contiene uno y sólo un sistema de subgrupos conjugados de orden pα.[517]
Sylow prueba en el mismo artículo que todo grupo de orden pαes resoluble, esto es, que los índices de una sucesión de subgrupos maximales invariantes son primos.
Otro enfoque diferente de los grupos de sustituciones, y en última instancia de los grupos generales, fue sugerido por una investigación puramente física. Auguste Bravais (1811-1863), físico y mineralólogo, estudió grupos de movimientos[518] para determinar las estructuras posibles de los cristales. Este estudio se reduce matemáticamente a la investigación de las transformaciones lineales en tres variables
xi' = ai1x + ai2y + ai3z, i = 1, 2, 3,
de determinante +1 ó -1 y condujo a Bravais a treinta y dos clases de estructuras moleculares simétricas que pueden aparecer en los cristales.El trabajo de Bravais impresionó a Jordán y se propuso investigar lo que llamó la representación analítica de grupos y que ahora se denomina la teoría de representación de grupos. De hecho, Serret, en la edición de 1866 de su Cours, había considerado la representación de sustituciones mediante transformaciones de la forma
![]()
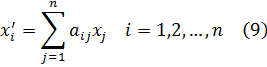
Ya que los grupos de sustituciones son finitos, tienen que imponerse algunas restricciones a las transformaciones de tal manera que el grupo de transformaciones sea finito. Galois había considerado tales transformaciones[519] y las limitó de tal forma que los coeficientes y las variables toman valores en un cuerpo finito de orden primo. En 1878[520], Jordán enunció que una sustitución homogénea lineal (9) de período finito p puede ser transformada linealmente en la forma canónica
yi' = εiyi i = 1, 2, ..., n
donde las εi son raíces p-ésimas de la unidad. El teorema lo demostraron varios autores[521], y esto constituyó el inicio de buen número de investigaciones sobre la determinación de los posibles grupos de sustituciones lineales de orden dado y de una forma binaria o ternaria (dos y tres variables). También la determinación de los subgrupos de grupos de sustituciones lineales y las expresiones algebraicas invariantes por todos los miembros de un grupo o subgrupo promovieron mucha investigación.Inmediatamente después de conocer el ensayo de Bravais, Jordán se propuso la primera gran investigación en grupos infinitos. En su ensayo «Mémoire sur les groupes de mouvements» («Memoria sobre los grupos de movimientos»)[522], Jordán señala que la determinación de todos los grupos de movimientos (únicamente consideraba traslaciones y rotaciones) es equivalente a la determinación de todos los posibles sistemas de moléculas tales que cada movimiento de cualquier grupo transforma el sistema correspondiente de moléculas en sí mismo. Por tanto, estudió los varios tipos de grupos y los clasificó. Los resultados no son tan significativos como el hecho de que su artículo inició el estudio de las transformaciones geométricas en el marco de los grupos y los geómetras se apresuraron a seguir esta línea de pensamiento (cap. 38, sec. 5).
Otro desarrollo de la mitad del siglo XIX es tan notable como instructivo. Arthur Cayley, muy influenciado por el trabajo de Cauchy, reconoció que la noción de grupo de sustituciones podía ser generalizada. En tres artículos[523], Cayley presentó la noción de un grupo abstracto. Utilizó un símbolo de operador general 6 aplicado a un sistema de elementos x,y,z,... y habló de θ como aplicado para dar una función x',y',z',... de x,y,z,... Señaló que en particular θ puede ser una sustitución. El grupo abstracto contiene muchos operadores θ,ϕ,.... θϕ es un (producto) compuesto de dos operaciones y el compuesto es asociativo pero no necesariamente conmutativo. Su definición general de grupo supone un conjunto de operadores 1, α, p,..., todos ellos diferentes y tales que el producto de dos cualesquiera de ellos en cualquier orden, o el producto de cualquiera por sí mismo, pertenece al conjunto[524]. Menciona las matrices bajo la multiplicación y los cuaterniones (con la adición) como constituyendo grupos. Desafortunadamente, la introducción por Cayley del concepto de grupo abstracto no atrajo la atención en su tiempo, en parte porque las matrices y los cuaterniones eran nuevos y no bien conocidos, y los otros muchos sistemas matemáticos que podían ser incluidos en la noción de grupo o estaban aún por desarrollarse o no se había reconocido que lo eran. La abstracción prematura cae en oídos sordos, ya pertenezcan a matemáticos, ya a estudiantes.
Bibliografía
- Abel, H. H.: Œuvres completes. (1881), 2 vols., Johnson Reprint Corp., 1964.
- Bachmann, P.: «Uber Gauss’ zahlentheoretische Arbeiten», Nachrichten König. Ges. der. Wiss. zu Gött., 1911, 455-518. También en los Werke de Gauss, 10, Parte 2, 1-69.
- Burkhardt, H.: «Endliche discrete Gruppen», Encyk. der. Math. Wiss., B. G. Teubner, 1903-1915, I, Parte I, 208-226. : «Die Anfánge der Gruppentheorie und Paolo Ruffini», Abhandlungen zur Geschichte der Mathematik, Heft 6, 1892, 119-159.
- Burns, Josephine E.: «The Foundation Period in the History of Group Theory», Amer. Math. Monthly, 20, 1913, 141-148.
- Dupuy, P.: «La vie d’Evariste Galois», Ann. de l'Ecole Norm. Sup. (2), 13, 1896, 197-266.
- Galois, Evariste: «Œuvres», Jour. de Math., 11, 1846, 381-444. : Œuvres Mathématiques, Gauthier-Villars, 1897. : Ecrits et mémoires mathématiques (ed. por R. Bourgne y J. P. Azra), Gauthier-Villars, 1962.
- Gauss, C. F.: Disquisitiones Arithmeticae (1801), Werke, vol. 1, König. Ges. der Wiss., zu Göttingen, 1870. Traducción al inglés de Arthur A. Clarke, S. J., Yale University Press, 1966.
- Hobson, E. W.: Squaring the árele and other monographs, Chelsea (reimpresión), 1953.
- Hölder, Otto: «Galois’sche Theorie mit Anwendungen», Encyk. der Math. Wiss., B. G. Teubner, 1898-1904, I, Parte I, 480-520. Hay versión española, L. Infeld, El elegido de los dioses, México, Siglo XXI, 1974.
- Infeld, Leopold: El elegido de los dioses. México, Siglo XXI, 1974.
- Jordán, Camille: Œuvres, 4 vols., Gauthier-Villars, 1961-1964. : Traité des substitutions et des équations algébriques (1870), GauthierVillars (reimpresión), 1957.
- Kiernan, B. M.: «The Development of Galois Theory from Lagrange to Artin», Archive for History of Exact Sciences, 8, 1971, 40-154.
- Lebesgue, Henri: Notice sur la vie et les travaux de Camille Jordán, Gauthier-Villars, 1923. También en Notices d’historie des mathématiques de Lebesgue, pp. 44-65, Instituí de Mathématiques, Genéve, 1958.
- Miller, G. A.: «History of the Theory of Groups to 1900», Collected Works, vol. 1, 427-467, University of Illinois Press, 1935.
- Pierpont, James: «Lagrange’s place in the Theory of Substitutions», Amer. Math. Soc. Bull, 1, 1894-1895, 196-204. : «Early History of Galois Theory of Equations», Amer. Math. Soc. Bull., 4, 1898, 332-340.
- Smith, David Eugene: A Source Book in Mathematics, Dover (reimpresión), 1959, vol. 1, 232-252, 253-260, 261-266, 278-285.
- Verriest, G.: Œuvres mathématiques d’Evariste Galois (ed. 1897), 2.a ed., Gauthier-Villars, 1951.
- Wiman, A.: «Endliche Gruppen linearer Substitutionen», Encyk. der Math. Wiss., B. G. Teubner, 1898-1904, I, Parte 1, 522-554.
- Wussing, H. L.: Die Génesis des abstrakten Gruppenbegriffes, VEB Deutscher Verlag des Wiss., 1969.
Capítulo 32
Cuaterniones, vectores y algebras lineales asociativas
Los cuaterniones fueron descubiertos por Hamilton después de haber realizado su obra realmente importante y, aunque ingeniosamente bellos, han sido un demonio ambiguo para aquellos que los han tocado de alguna manera... El vector es un superviviente inútil, o una derivación de los cuaternios y nunca ha sido de la menor utilidad para criatura alguna.
Lord Kelvin
1. El fundamento del álgebra sobre la permanencia de la forma1. El fundamento del álgebra sobre la permanencia de la forma
2. La búsqueda de un «número complejo» tridimensional
3. La naturaleza de los cuaterniones
4. El cálculo de la extensión de Grassmann
5. De los cuaterniones a los vectores
6. Algebras lineales asociativas
Bibliografía
El trabajo de Galois sobre la solubilidad de ecuaciones mediante procesos algebraicos cerró un capítulo del álgebra y, a pesar de que presentó ideas tales como las de grupo y dominio de racionalidad (cuerpo) que rendirían fruto más tarde, la completa explotación de estas ideas tuvo que esperar otros desarrollos. La siguiente gran creación algebraica, iniciada por William R. Hamilton, abrió nuevos dominios, mientras rompía con viejas convicciones acerca de cómo debían comportarse los «números».
Para apreciar la originalidad del trabajo de Hamilton hay que examinar cómo se entendía la lógica del álgebra ordinaria en la primera parte del siglo XIX. Hacia 1800 los matemáticos empleaban con libertad los varios tipos de números reales y aun complejos, pero la definición precisa de estos distintos tipos de números no se hallaba a disposición de los matemáticos, ni tampoco existía una justificación de las operaciones con ellos. Las expresiones de insatisfacción hacia el estado de cosas fueron muy numerosas, pero estaban sumergidas en la masa de nuevas creaciones del álgebra y el análisis. Las mayores inquietudes parecían estar causadas por el hecho de que se manipulaban las letras como si tuvieran las propiedades de los enteros; sin embargo, los resultados de estas operaciones eran válidos cuando números cualesquiera sustituían las letras. Ya que no se había realizado el desarrollo de la lógica de los diversos tipos de números, no era posible ver que éstos poseían las mismas propiedades formales de los enteros positivos y, consecuentemente, que expresiones literales que simplemente se mantenían para cualquier clase de números reales o complejos deben poseer las mismas propiedades —esto es, que el álgebra ordinaria es únicamente aritmética generalizada—. Parecía como si el álgebra de expresiones literales poseyera una lógica en sí misma, que respondía de su efectividad y corrección. De aquí que los matemáticos atacaran hacia 1830 el problema de justificar las operaciones con expresiones literales o simbólicas.
Este problema lo consideró primero George Peacock (1791-1858), profesor de matemáticas en la universidad de Cambridge. Para justificar las operaciones con expresiones literales que podían mantenerse para números negativos, irracionales y complejos hizo la distinción entre álgebra aritmética y álgebra simbólica. La primera trataba con símbolos representando los enteros positivos, y por lo mismo se encontraba sobre tierra firme. Aquí se permitían únicamente operaciones que condujeran a enteros positivos. El álgebra simbólica adopta las reglas del álgebra aritmética pero suprime las restricciones a enteros positivos. Todos los resultados deducidos en el álgebra aritmética, cuyas expresiones son generales en forma pero particulares en valor, son resultados de la misma manera que en álgebra simbólica, donde son generales en valor así como en forma. Así aman = am+n se mantiene en álgebra aritmética cuando m y n son enteros positivos y por lo mismo se mantiene en álgebra simbólica para todas las m y n. Asimismo, la serie para (a + b)n donde n es un entero positivo, si fuera presentada en forma general sin referencia a un término final, es válida para todas las n. El argumento de Peacock es conocido como el principio de permanencia de la forma.
La formulación explícita de este principio fue proporcionada en el «Report on the Recent Progress and Present State of Certain Branches of Analysis» («Informe sobre los avances recientes y estado presente de ciertas ramas del análisis») de Peacock en el que no sólo informa sino que afirma dogmáticamente. En el álgebra simbólica, dice:[525]
- Los símbolos son ilimitados tanto en valor como en representación.
- Las operaciones sobre ellos, cualesquiera que sean, son posibles en todos los casos.
- Las leyes de combinación de los símbolos son de tal clase que coinciden universalmente con las del álgebra aritmética cuando estos símbolos son cantidades aritméticas, y cuando las operaciones a las que se sujetan son llamadas con los mismos nombres que en el álgebra aritmética.
Peacock reafirmó este principio en la segunda edición de su Treatise on Algebra (Tratado de Algebra)[526], pero aquí también presenta una ciencia formal del álgebra. En este Tratado, Peacock establece que el álgebra, como la geometría, es una ciencia deductiva. Los procesos del álgebra tienen que estar basados sobre un enunciado completo del cuerpo de las leyes que dictan las operaciones usadas en el proceso. Los símbolos para las operaciones no tienen, al menos para la ciencia deductiva del álgebra, ningún otro sentido que aquel dado por las leyes. Así, la adición no significa más que cualquier proceso que obedece las leyes de la adición del álgebra. Sus leyes son, por ejemplo, las leyes asociativa y conmutativa de la adición y la multiplicación, y la ley de que si ac = bc y c ≠ 0, entonces a = b.
Aquí fue derivado el principio de la permanencia de la forma de la adopción de los axiomas. Este enfoque allanó el camino para un pensamiento más abstracto en el álgebra y en particular influenció el pensamiento de Boole sobre el álgebra de la lógica.
A lo largo de la mayor parte del siglo XIX, se aceptó la visión del álgebra afirmada por Peacock. Fue apoyada, por ejemplo, por Duncan F. Gregory (1813-1844), un tataratataranieto de James Gregoty, del siglo XVII . Gregory escribió en un ensayo «On the real nature of syrnbolic algebra» («Sobre la verdadera naturaleza del álgebra simbólica»)[527]:
La luz a la que consideraré el álgebra simbólica es como la ciencia que trata la combinación de las operaciones definidas, no por su naturaleza, esto es, por lo que son o lo que hacen, sino por las leyes de las combinaciones a las que están sujetas... Es cierto que estas leyes han sido en muchos casos sugeridas (como Mr. Peacock ha dicho convenientemente) por las leyes conocidas de las operaciones de los números, pero el paso dado del álgebra aritmética a la simbólica es que, dejando de lado la naturaleza de las operaciones que los símbolos que usamos representan, suponemos la existencia de clases de operaciones desconocidas sujetas a estas mismas leyes. Así somos capaces de probar ciertas relaciones entre las diferentes clases de operaciones, que, cuando son expresadas entre los símbolos, se llaman teoremas algebraicos.
En este ensayo, Gregory insistió en las leyes conmutativa y distributiva, términos introducidos por François-Joseph Servois (1767-1847)[528].
La teoría del álgebra como ciencia de los símbolos y las leyes de sus combinaciones fue llevada más lejos por Augustus de Morgan, quien escribiera varios artículos sobre la estructura del álgebra[529]. Su Trigonometry and Double Algebra (Trigonometría y Algebra Doble, 1849) contiene también sus puntos de vista. Las palabras álgebra doble significaban el álgebra de los números complejos, mientras que álgebra simple significaba el álgebra de los números negativos. Anterior al álgebra simple es la aritmética universal, que cubre el álgebra de los números reales positivos. El álgebra —decía de Morgan— es una colección de símbolos carentes de significado y operaciones entre estos símbolos. Los símbolos son 0, 1, +, -, ×, :, ()(), y letras. Las leyes del álgebra son las leyes que obedecen estos símbolos, por ejemplo, la ley conmutativa, la ley distributiva, las leyes de los exponentes, un número negativo por un positivo es negativo, a - a = 0, a : a = 1, y las leyes derivadas. Las leyes básicas son seleccionadas arbitrariamente.
Los axiomas del álgebra aceptados a mediados del siglo XIX son:
- Cantidades iguales sumadas a una tercera dan cantidades iguales.
- (a + b) + c = a + (b + c).
- a + b = b + a.(a + b) + c = a + (b + c).
- Iguales añadidos a iguales dan iguales.
- Iguales añadidos a desiguales dan desiguales.
- a(bc) =(ab)c
- ab = ba.
- a(b + c) = ab + ac.
Es difícil para nosotros ver lo que este principio significa exactamente. Formula la cuestión de por qué los varios tipos de números poseen las mismas propiedades que los números enteros. Pero Peacock, Gregory y De Morgan querían hacer del álgebra una ciencia independiente de las propiedades de los números reales y complejos y por lo mismo veían el álgebra como una ciencia de símbolos sin interpretación y sus leyes de combinación. En efecto, fue ésa la justificación de la suposición que las mismas propiedades fundamentales se mantenían para todos los tipos de números. Esta fundamentación no solamente era vaga, sino también poco elástica. Los autores insistían en un paralelismo entre el álgebra aritmética y la general tan rígido que, si se mantenía, destruiría la generalidad del álgebra. Parece que no se percataban de que una fórmula que es verdadera con una interpretación de los símbolos puede no serlo con otra.
El principio de la permanencia de la forma, un dictado arbitrario, no podía servir como fundamento sólido para el álgebra. De hecho, los desarrollos con los que trataremos en este capítulo lo desacreditan. El primer paso, que hizo obvia la necesidad para los números complejos de este principio, lo dio Hamilton cuando fundó la lógica de los números complejos sobre las propiedades de los números reales.
Hamilton no estaba satisfecho con un fundamento meramente intuitivo refiriéndose a los números complejos, aunque éstos estuvieran fundados intuitivamente, al representarlos como puntos o segmentos de recta dirigidos en el plano. En su artículo «Conjugate Functions and on Algebra as the Sciencie of Pure Time» («Funciones conjugadas y sobre el álgebra como la ciencia del tiempo puro»)[530], Hamilton señaló que un número complejo a + bi no es una suma en el sentido en que 2 + 3 lo es. El uso del signo más es un accidente histórico y bi no puede ser añadido a a. El número complejo a + bi no es más que una pareja ordenada (a,b) de números reales. La peculiaridad que i ó √-1 introduce en las operaciones con los números complejos está incorporada por Hamilton en las definiciones de las operaciones con pares ordenados. Así, si a + bi y c + di son dos números complejos entonces
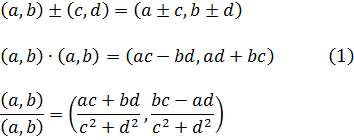
2. La búsqueda de un «número complejo» tridimensional
La noción de vector, esto es, un segmento de línea dirigido que puede representar la magnitud y dirección de una fuerza, una velocidad o una aceleración, entró en las matemáticas calladamente. Aristóteles sabía que las fuerzas podían ser representadas como vectores y que la acción combinada de dos fuerzas se obtenía por lo que es vulgarmente conocido como la ley del paralelogramo; esto es, que la diagonal del paralelogramo formado por los dos vectores a y b (Fig. 32.1), proporciona la magnitud y dirección de la fuerza resultante. Simón Stevin empleó la ley del paralelogramo en problemas de estática y Galileo enunció la ley explícitamente.

Figura 32.1
Este empleo de los números complejos para representar vectores en el plano se hizo bien conocido hacia 1830. Sin embargo, la utilidad de los números complejos es limitada. Si varias fuerzas actúan sobre un cuerpo, no están necesariamente en el mismo plano. Para tratarlas algebraicamente es necesario un análogo tridimensional de los números complejos. Se pueden usar las coordenadas cartesianas (x,y,z) de un punto para representar un vector desde el origen al punto, pero no había operaciones con las tripletas de números para representar las operaciones con los vectores. Estas operaciones, como en el caso de los números complejos, deberían incluir la adición, substracción, multiplicación y división y además obedecer a las leyes usuales asociativa, conmutativa y distributiva de tal forma que las operaciones algebraicas se aplicasen con libertad y eficacia. Los matemáticos iniciaron una búsqueda de lo que fue llamado el número complejo tridimensional y su álgebra.
Wessel, Gauss, Servois, Möbius y otros trabajaron en este problema. Gauss[531] escribió una nota breve e inédita fechada en 1819 sobre mutaciones del espacio. Pensó en los números complejos como desplazamientos; a + bi era un desplazamiento de a unidades a lo largo de una dirección fija, seguido por un desplazamiento de b unidades en una dirección perpendicular. De aquí intentó construir un álgebra de números de tres componentes, en la cual la tercera componente representaría un desplazamiento en una dirección perpendicular al plano de a + bi. Llegó a un álgebra no conmutativa, pero no se trataba del álgebra requerida por los físicos. Más aún, ya que no lo publicó, este trabajo tuvo poca influencia.
La creación de un análogo espacial útil de los números complejos se le debe a William R. Hamilton (1805-1865). Después de Newton, Hamilton es el más grande de los matemáticos ingleses y, como a Newton, se le considera aún más grande como físico que como matemático. A la edad de cinco años, Hamilton podía leer latín, griego y hebreo. A los ocho añadió italiano y francés; a los diez podía leer árabe y sánscrito, y a los catorce, persa. Un encuentro con un brillante calculador le inspiró estudiar matemáticas. Entró en el Trinity College, en Dublin, en 1823, y allí destacó como un alumno brillante. En 1822, a la edad de diecisiete años, preparó un artículo sobre caústicas, leído ante la Real Academia Irlandesa dos años después, pero no se publicó, porque se le pidió que trabajara su texto y lo ampliara. En 1827 presentó a la Academia una versión revisada, que tituló «A theory of systems of rays» («Una teoría de sistemas de rayos»), donde hizo una ciencia de la óptica geométrica. Exponía lo que se denominan las funciones características de la óptica. El artículo fue publicado en 1828 en las Transactions of the Roy al Irish Academy[532].
En 1827, mientras seguía estudiando la licenciatura, recibe el nombramiento de profesor de astronomía del Trinity College, con el título de Astrónomo Real de Irlanda. Sus funciones como profesor consistían en impartir cátedra sobre ciencia y administrar el observatorio astronómico. No realizó un gran trabajo en esto último, pero fue un buen maestro. En 1830 y 1832 publicó tres suplementos a «Una teoría de sistema de rayos». En el tercer ensayo[533] predijo que un rayo de luz propagándose en direcciones especiales en un cristal biaxial haría surgir un cono de rayos refractados. Este fenómeno fue confirmado experimentalmente por Humphrey Lloyd, su amigo y colega. Sus ideas en óptica las trasladó a la dinámica y en este campo escribió dos artículos muy famosos (cap. 30), donde aplica el concepto de función característica que había desarrollado en óptica. También aportó un sistema de integrales completas y rigurosas para las ecuaciones diferenciales del movimiento de un sistema de cuerpos. Su principal obra matemática fue sobre los cuaterniones, que discutiremos en breve. La versión final de este trabajo la presentó en sus Lectures on Quaternions (Lecciones sobre Cuaterniones, 1853) y en dos volúmenes publicados póstumamente, Elements of Quaternions (Elementos de Cuaterniones, 1866).
Hamilton usaba las analogías con destreza para razonar pasando de lo conocido a lo desconocido. A pesar de que poseía una fina intuición, no tuvo grandes ideas, aunque trabajó dura y largamente en problemas especiales para ver qué aspectos podían ser generalizados. Gozaba de paciencia y era sistemático al analizar muchos ejemplos específicos, y estaba dispuesto a efectuar tremendos cálculos para verificar o demostrar un punto. Sin embargo, en sus publicaciones únicamente se observan los resultados generales pulidos y compactos.
Era profundamente religioso y este interés fue el más importante para él. Luego, en orden de importancia, colocaba la metafísica, matemáticas, poesía, física y literatura general. Escribió poesía, pensaba que las ideas geométricas creadas en su tiempo, el uso de elementos infinitos y elementos imaginarios en los trabajos de Poncelet y ChasIes (cap. 35), estaban estrechamente relacionados con la poesía. Aunque era un hombre modesto, admitía y aun enfatizaba que el amor a la fama mueve y motiva a los grandes matemáticos.
La aclaración por Hamilton de la noción de número complejo le permitió pensar con mayor claridad acerca del problema de presentar una analogía tridimensional para representar los vectores en el espacio. Pero el efecto inmediato fue frustrar sus esfuerzos. Todos los números conocidos por los matemáticos de su tiempo poseían la propiedad conmutativa de la multiplicación, y era natural para Hamilton creer que los números tridimensionales o de tres componentes que él buscaba debían poseer esta misma propiedad al igual que las otras propiedades que poseían los números reales y complejos. Después de algunos años de esfuerzo, Hamilton se vio obligado a hacer dos compromisos. El primero era que sus nuevos números contenían cuatro componentes, y el segundo, que resultaba necesario sacrificar la ley conmutativa de la multiplicación. Ambas características fueron revolucionarias para el álgebra. Llamó a los nuevos números cuaterniones (o cuaternios).
Retrospectivamente, es fácil observar sobre bases geométricas que los nuevos «números» tenían que contener cuatro componentes. El nuevo número, considerado como un operador, se suponía que haría rotar un vector dado alrededor de un eje dado en el espacio, y estirar o contraer el vector. Para estos propósitos, son necesarios dos parámetros (ángulos) a fin de fijar el eje de rotación; un parámetro ha de especificar el ángulo de rotación y el cuarto el estiramiento o contracción del vector dado.
El propio Hamilton describió su descubrimiento de los cuaterniones[534]:
Mañana será el decimoquinto cumpleaños de los cuaterniones. Ellos surgieron a la vida, o a la luz, ya crecidos, el 16 de octubre de 1843, cuando me encontraba caminando con la Sra. Hamilton hacia Dublín, y llegamos al puente de Broughman. Es decir, entonces y ahí cerré el circuito galvánico del pensamiento y las chispas que cayeron fueron las ecuaciones fundamentales entre I, J, K; exactamente como las he usado desde entonces. Saqué, en ese momento, una libreta de bolsillo, que todavía existe, e hice una anotación, sobre la cual, en ese mismo preciso momento, sentí que posiblemente sería valioso el extender mi labor por al menos los diez (o podían ser quince) años por venir. Pero entonces era justo decir que esto sucedía porque sentí en ese momento que un problema había sido resuelto, un deseo intelectual aliviado, deseo que me había perseguido por lo menos los quince años anteriores.Anunció la invención de los cuaterniones en 1843, durante una reunión de la Real Academia Irlandesa, y después dedicó el resto de su vida a desarrollar la teoría, y escribió muchos ensayos en torno a ellos.
3. La naturaleza de los cuaterniones
Un cuaternión es un número de la forma
3 + 2i + 6j + 7k (2)
donde las i, j y k tienen un papel semejante al que juega i en los números complejos. La parte real, 3 arriba, es llamada la parte escalar del cuaternión, y el resto, la parte vectorial. Los tres coeficientes de la parte vectorial son coordenadas rectangulares cartesianas de un punto P, mientras que i, j y k son llamadas las unidades cualitativas que geométricamente están dirigidas a lo largo de los tres ejes. El criterio de igualdad de dos cuaterniones es que sus partes escalares deben ser iguales y que los coeficientes de sus unidades, i, j y k han de ser respectivamente iguales. Dos cuaterniones se suman sumando sus partes escalares y sumando los coeficientes de cada una de las unidades i, j y k para formar los nuevos coeficientes de estas unidades. La suma de dos cuaternios es, por lo tanto, otro cuaternio.Todas las reglas algebraicas familiares de multiplicación son supuestamente válidas al operar con cuaterniones, excepto que al formar productos de estas unidades i, j y k, las siguientes reglas, que abandonan la ley de conmutatividad, se cumplen
jk = i, kj = -i, ki = j, ik = -j ij = k, ji = -k
i2 = j2 = k2 =-i. (3)
Así, sip = 3 + 2i + 6j + 7k y q = 4 + 6i + 8j + 9k
entoncespq=(3 + 2i + 6j + 7k)(4 + 6i + 8j + 9k) = -111 + 24i + 72j + 75k.
mientras queqp = (4 + 6i + 8j + 9k)(3 +2i + 6j + 7k) = - 111 + 28i + 24j + 75k.
Hamilton demostró que la multiplicación es asociativa. Este es el primer uso de ese término[535].La división de un cuaternión por otro puede ser efectuada también, pero el hecho de que la multiplicación no es conmutativa implica que dividir un cuaternión p por un cuaternión q puede significar encontrar r tal que p = qr o tal que p = rq. El cociente r no necesita ser el mismo en los dos casos. El problema de la división se maneja mejor al introducir q-1 o 1/q. Si q = a + bi + cj + dk se define q' como a - bi - cj - dk y N(q), llamado la norma de q, como a2 + b2 + c2 + d2. Entonces N(q) = qq' = q'q. Por definición q-1 = q/N(q) y q-1 existe si N(q) ≠ 0. También qq-1 = 1 y q-1q = 1. Ahora, para encontrar la r tal que p = qr tenemos q-1p = q-1qr o bien r = q-1p. Para encontrar la r tal que p = rq tenemos pq-1 = rqq-1 o r = pq-1.
Que los cuaterniones pueden ser usados para girar y estirar o contraer un vector dado en otro vector dado se demuestra fácilmente. Sólo se debe mostrar que es posible determinar las a, b, c y d tales que
(a + bi + cj + dk)(xi + yj + zk) = (x'i + y'j + z'k).
Multiplicando el lado izquierdo como cuaterniones e igualando los coeficientes correspondientes de los lados derecho e izquierdo obtenemos cuatro ecuaciones en las incógnitas a, b, c y d. Estas cuatro ecuaciones son suficientes para determinar las incógnitas.Hamilton introdujo también un operador diferencial importante. El símbolo ∇, que es una A invertida —que Hamilton llamó «nabla» porque se asemeja a un antiguo instrumento musical hebreo de ese nombre— se emplea para el operador
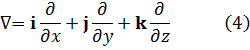
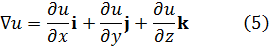
También, haciendo v = v1i + v2j + v3k una función de punto continua, donde las v1, v2 y v3, son funciones de x, y y z, Hamilton introdujo
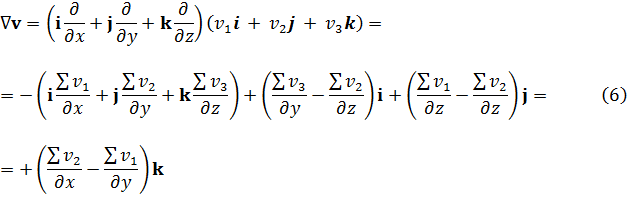
El entusiasmo de Hamilton por los cuaterniones no tuvo límites. Creía que su invención era tan importante como el cálculo y que sería el instrumento clave en la física matemática. El mismo llevó a cabo algunas aplicaciones a la geometría, óptica y mecánica. Sus ideas fueron apoyadas entusiastamente por su amigo Peter Guthrie Tait (1831-1901), profesor de matemáticas en el Queen’s College y posteriormente profesor de historia natural en la universidad de Edimburgo. En muchos artículos, Tait motivó a los físicos a adoptar los cuaterniones como herramienta básica. Incluso se vio envuelto en largas discusiones con Cayley, quien tomó un punto de vista muy tibio en cuanto a la utilidad de los cuaterniones. Pero los físicos ignoraron los cuaterniones y continuaron trabajando con las coordenadas cartesianas convencionales. Sin embargo, como veremos más adelante, el trabajo de Hamilton condujo indirectamente a un álgebra y análisis de vectores que los físicos adoptaron ansiosamente.
Los cuaterniones de Hamilton demostraron ser de importancia inconmensurable para el álgebra. Una vez que los matemáticos se dieron cuenta de que un sistema de números útil y con sentido podía ser construido y además carecer de la propiedad conmutativa de los números reales y complejos, se sintieron más libres para considerar creaciones que se alejaban aún más de las propiedades usuales de los números reales y complejos. Esta conciencia era necesaria antes de que el álgebra y análisis vectorial pudieran ser desarrollados, porque los vectores violan aún más leyes ordinarias del álgebra de que lo que lo hacen los cuaterniones (sec. 5). Aún más general, el trabajo de Hamilton condujo a la teoría de álgebras lineales asociativas (sec. 6). El propio Hamilton inició un trabajo sobre los hipernúmeros que contenían n componentes o n-uplas[536], pero fue su trabajo sobre los cuaterniones lo que estimuló los nuevos trabajos sobre las álgebras lineales.
4. El cálculo de la extensión de Grassmann
Mientras que Hamilton desarrollaba sus cuaterniones, otro matemático, Hermann Gunther Grassmann (1809-1877), aunque no mostrara talento matemático en su juventud y careciera de educación universitaria en matemáticas, pero que más tarde se convirtió en maestro del gymnasium (instituto) en Stettin, Alemania, así como en una autoridad en sánscrito, estaba desarrollando una generalización más audaz de los números complejos. Grassmann tuvo sus ideas antes que Hamilton, pero no las publicó hasta 1844, un año después de que Hamilton anunciara su descubrimiento de los cuaterniones. En ese año publicó su Die lineale Ausdehnungoslehre (El cálculo de la extensión). Debido a que cubrió las ideas con doctrinas místicas y a que su exposición fue abstracta, los matemáticos de mentalidad más práctica y los físicos encontraron su trabajo vago y poco legible; como consecuencia, el trabajo, aunque era altamente original, permaneció casi en el anonimato por varios años. Grassmann publicó una edición revisada: Die Ausdehnungslehre (La extensión), en 1862, donde simplificó y amplió el trabajo original, pero su estilo y carencia de claridad repelieron de nuevo a los lectores.
A pesar de que la exposición de Grassmann estaba casi inextricablemente ligada con ideas geométricas —de hecho, él estaba interesado en la geometría— abstraeremos las nociones algebraicas que han probado ser de incalculable valor. Su noción básica, que llamó cantidad extensiva (extensive Grösse) es un tipo de hipernúmero con n componentes. Para estudiar sus ideas discutiremos el caso n = 3. Consideremos dos hipernúmeros
La adición y sustracción de estos hipernúmeros está definida mediante
![]()
![]()
![]()
A partir de estas definiciones se sigue que el producto interno α|β de α y β está dado por
α|β = α1β1 + α2β2 + α3β3 y α|β = βα
El valor numérico o magnitud a de un hipernúmero a está definido como √α|α = √(α12 + α22 + α32). Así, la magnitud de α es igual numéricamente a la longitud del vector-línea que lo representa geométricamente. Si θ denota el ángulo entre los vectores-línea α y β entonces![]()
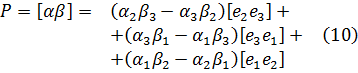
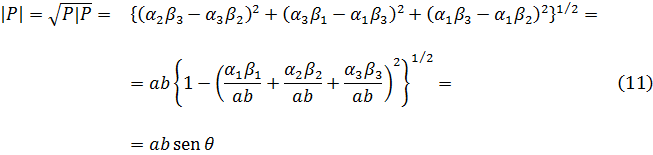
El producto interno de Grassmann de dos hipernúmeros primarios para tres dimensiones es equivalente a (con signo menos) la parte escalar del producto de cuaterniones de Hamilton de dos vectores; y, de nuevo en el caso tridimensional, el producto externo de Grassmann, si reemplazamos [e2e3] por e1, y así con los demás, es precisamente el producto de cuaterniones de Hamilton de dos vectores. Sin embargo, en la teoría de los cuaterniones, el vector es una parte subsidiaria del cuaternión mientras que en el álgebra de Grassmann el vector aparece como la cantidad básica.
Otro producto fue formado por Grassmann al tomar el producto (interno) escalar de un hipernúmero γ con el producto (exterior) vectorial de dos hipernúmeros α y β. Este producto Q es para el caso tridimensional
Q=[αβ]γ = (α2β3 - α3β2)γ1 + (α3β1 - α1β3)γ2 + (α1β2 - α2β1)γ3
En forma de determinante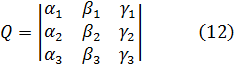
Grassmann consideró (para hipernúmeros de n componentes) no solamente los dos tipos de productos descritos con anterioridad, sino también productos de orden superior. En un ensayo de 1855[537], proporcionó dieciséis tipos diferentes de productos para hipernúmeros. Además, dio el significado geométrico de los productos e hizo aplicaciones a la mecánica, magnetismo y cristalografía.
Parece como si el tratamiento de Grassmann de los hipernúmeros de n partes fuese innecesariamente general, ya que hasta ahí, al menos las partes útiles de los hipernúmeros, contenían como mucho cuatro partes. Aun así, el pensamiento de Grassmann llevó a los matemáticos a la teoría de los tensores (cap. 48), que, como veremos, son hipernúmeros. Otras ideas geométricas y la noción de invariancia tendrían que ser conocidas por los matemáticos antes que llegara el día de los tensores. A pesar de que la concepción de los hipernúmeros condujo a varias generalizaciones, no hubo ningún desarrollo del análisis (e.g., cálculo) de los hipernúmeros n-dimensionales de Grassmann. La razón es simplemente que nunca se encontraron aplicaciones para tal tipo de análisis. Como veremos, existe un extenso análisis para tensores, pero éstos tienen su origen en la geometría riemanniana.
5. De los cuaterniones a los vectores
La obra de Grassmann permaneció ignorada por un tiempo, mientras que, como hemos anotado, los cuaterniones recibieron gran atención casi de inmediato. Sin embargo, no eran lo que los físicos realmente necesitaban. Ellos buscaban un concepto que no estuviera disociado, sino, al contrario, más relacionado con las coordenadas cartesianas de lo que lo estaban los cuaterniones. El primer paso en la dirección de tal concepto lo dio James Clerk Maxwell (1831-1879), fundador de la teoría electromagnética, uno de los más grandes físicos matemáticos y profesor de física en la universidad de Cambridge.
Maxwell conoció el trabajo de Hamilton y aunque supo del trabajo de Grassmann, no lo había visto. Singularizó las partes escalar y vectorial de los cuaterniones de Hamilton y puso énfasis sobre estas nociones separadas[538]. Sin embargo, en su famoso A Treatise on Electricity and Magnetism (Tratado de electricidad y magnetismo, 1873) hizo mayores concesiones a los cuaterniones y habla de las partes escalar y vectorial de un cuaternión, aunque las trata como entidades separadas. Un vector —dice (p. 10)— requiere tres cantidades (componentes) para su especificación que se interpretan como longitudes a lo largo de los tres ejes coordenados. Este concepto de vector es la parte vectorial de los cuaterniones de Hamilton, y así lo expone Maxwell. Hamilton había introducido una función vectorial v de x, y y z con componentes v1, v2 y v3, había aplicado el operador
Maxwell señala entonces que el operador ∇ repetido proporciona

Maxwell notó en su artículo de 1871 que el rotacional de un gradiente de una función escalar y la divergencia de rotacional de una función vectorial son siempre cero. También establece que el rotacional del rotacional de una función vectorial v es el gradiente de la divergencia de v menos el laplaciano de v. (Esto es cierto únicamente en coordenadas rectangulares.)
Maxwell usó comúnmente los cuaterniones como la entidad matemática básica o al menos hizo frecuentes referencias a los cuateriones, tal vez para ayudar a sus lectores. Sin embargo, su trabajo aclaró que los vectores eran la verdadera herramienta para el pensamiento físico y no sólo un esquema abreviado de escritura, como alguien mantenía. De este modo fue creada en el tiempo de Maxwell una gran parte del análisis vectorial al tratar las partes escalares y vectoriales de los cuaterniones por separado.
La ruptura formal con los cuaterniones y la inauguración de una nueva materia independiente, el análisis vectorial tridimensional, fue hecho independientemente por Josiah Willard Gibbs y Oliver Heaviside a principio de los 1880. Gibbs (1839-1903), profesor de matemáticas en Yale College, pero principalmente un físico-químico, había impreso (1881-1884) para distribución privada entre sus estudiantes un panfleto sobre los Elements of vector analysis (Elementos del Análisis Vectorial)[540]. Su punto de vista se expone en una nota introductoria:
Los principios fundamentales del siguiente análisis son familiares bajo una forma ligeramente diferente a los estudiantes de los cuaterniones. La manera como la materia es desarrollada de alguna manera es diferente de lo que se hace en los tratados sobre cuaterniones, consistiendo simplemente en dar una notación adecuada para aquellas relaciones entre los vectores, o entre vectores y escalares, que parecen más importantes, y que se prestan ellas mismas más fácilmente a las transformaciones analíticas, y para explicar algunas de estas transformaciones. Como precedente de tal desviación del uso de los cuaterniones puede ser citado el Kinematics (Kinemática) de Clifford. En este contexto puede ser mencionado el mismo Grassmann, a cuyos sistemas se asemeja el siguiente método en algunos aspectos más cercanamente que el de Hamilton.
Aunque impreso para circulación privada, el panfleto de Gibbs sobre análisis vectorial fue ampliamente conocido. El material se incorporó finalmente en un libro escrito por E. B. Wilson y basado sobre las clases de Gibbs. El libro de Gibbs y Wilson titulado Vector Analysis (Análisis Vectorial) apareció en 1901.
Oliver Heaviside (1850-1925) fue en la primera parte de su carrera científica un ingeniero que aplicó su trabajo a telégrafos y teléfonos. Se retiró a la vida campestre en 1874, y se dedicó a escribir, principalmente sobre electricidad y magnetismo. Heaviside estudió los cuaterniones en los Elementos de Hamilton, pero había sido repelido por tantos teoremas particulares. Pensaba que los cuaterniones eran demasiado difíciles de aprender para ingenieros ocupados y construyó su propio análisis vectorial, que para él era únicamente una forma abreviada de las coordenadas cartesianas ordinarias. En artículos escritos durante los 1880 en la revista Electrician, usó su análisis vectorial libremente. Más adelante, en su trabajo en tres volúmenes Electromagnetic Theory (Teoría Electromagnética, 1893, 1899 y 1912) aportó gran cantidad de álgebra vectorial en el vol. I. El tercer capítulo, de alrededor de 175 páginas, está dedicado a los métodos vectoriales. Su desarrollo de la materia está esencialmente en armonía con el de Gibbs, aunque no le gustaba la notación de Gibbs y adoptó la suya propia basada en la notación cuaterniónica de Tait.
Según la formulación de Gibbs y Heaviside, un vector no es más que la parte vectorial de un cuaternión, pero considerado independientemente de cualesquiera cuaterniones. Así un vector v es
v = ai + bj + ck
donde i, j y k son vectores unitarios a lo largo de los ejes x, y y z, respectivamente. Los coeficientes a, b y c son números reales y se les llama componentes. Dos vectores son iguales si las componentes respectivas son iguales y la suma de dos vectores es el vector que tiene como componentes la suma de las componentes respectivas de los sumandos.Se introdujeron dos tipos de multiplicación, ambas útiles físicamente. El primer tipo, conocido como multiplicación escalar, se define así: multiplicamos v y v' = a'i + b'j + c'k como polinomios ordinarios y, usando el punto como un símbolo de multiplicación, fijamos
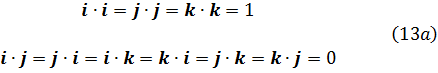
El producto escalar de dos vectores es novedoso algebraicamente en otro aspecto —no permite un proceso inverso—. Esto es, no siempre podemos encontrar un vector o un escalar q tal que v/v' = q. Así, si q fuera un vector, q·v' sería un escalar y no sería igual al vector v. Por otra parte, si q fuera un escalar, entonces, a pesar de que qv' está definido como qa'i + qb'j + qc'k, sería raro que qa' = a, qb' = b y qc' = c donde a, b y c son los coeficientes de v. A pesar de la ausencia de un cociente, el producto escalar es útil.
La interpretación física del producto escalar es fácilmente expresable como lo siguiente: si v' es una fuerza (0Fig. 32.2) cuya dirección y magnitud están representadas por el segmento de recta de O a P', entonces la efectividad de la fuerza al empujar un objeto en O, digamos, en la dirección de OP, donde OP representa a v, es la proyección de OP' sobre OP o bien OP' cos < ϕ donde ϕ es el ángulo entre OP' y OP. Si OP es de una unidad de longitud, la proyección de OP' es precisamente el valor del producto v·v'.
Figura 32.2
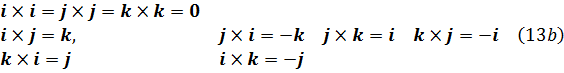
v x v' = (bc' - b'c)i + (ca' - ac')j + (ab' - b'a)k
El producto vectorial de dos vectores es un vector. Su dirección puede demostrarse que es perpendicular a las de v y v' y señala la dirección que un tornillo a derechas se mueve cuando es girado de v a v' siguiendo el menor ángulo.El producto vectorial de dos vectores paralelos es cero, aunque ningún factor lo es. Más aún, este producto, como el producto de cuaterniones, no es conmutativo. Además, no es ni siquiera asociativo. Por ejemplo, i x j x j puede significar (i x j) x j = k x j = -i ó i x (j x j) = i x 0 = 0.
No existe el inverso de la multiplicación vectorial. Para que el cociente de v por v' sea un vector q tendríamos que tener
v = v' x q
Y esto requiere, cualquiera que sea q, que v' sea perpendicular a v, lo que podría no ser el caso para empezar. Si q fuera un escalar, sería accidental que qa'i + qb'j + qc'k fuera igual a v.
Figura 32.3
El álgebra de vectores es extendida a vectores variables y a un cálculo de vectores. Por ejemplo, el vector variable v(t) = a(t)i + b(t)j + c(t)k, donde a(t), b(t) y c(t) son funciones de t, es una función vectorial. Si los diversos vectores que se obtiene para valores distintos de t son trazados a partir de O como origen (Fig. 32.4), los extremos de estos vectores describen una curva.
Figura 32.4
y = x2 + 7,
digamos, y el cálculo de vectores ha sido desarrollado para estas funciones vectoriales, así como hay uno para funciones ordinarias. Los conceptos de gradiente de u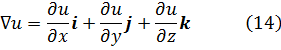
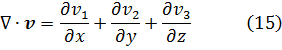
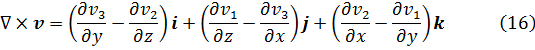
fueron abstraídos de los cuaterniones.
Muchos teoremas básicos del análisis pueden ser expresados en forma vectorial. Así, al resolver las ecuaciones diferenciales parciales del calor, Ostrogradsky[541] hizo uso de la siguiente conversión de la integral de volumen a la integral de superficie:
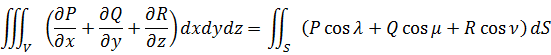
si F es un vector cuyas componentes son P, Q y R y n es la normal a S entonces
![]()
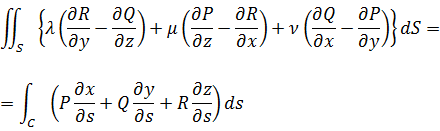
![]()
Cuando Maxwell escribió las expresiones y ecuaciones del electromagnetismo, especialmente las ecuaciones que ahora llevan su nombre, las escribió en general separando las componentes de los vectores involucrados en grad u, div v, y rot v. Sin embargo, Heaviside escribió las ecuaciones de Maxwell en forma vectorial (cap. 28 (52)).
Es cierto que los cálculos con vectores y funciones vectoriales se hacen frecuentemente apoyándose en las componentes cartesianas, pero es altamente importante pensar también en términos de una entidad singular, el vector, y en términos de gradiente, divergencia y rotacional. Estos tienen un significado físico directo, por no decir nada del hecho de que los pasos técnicos complicados pueden realizarse directamente con los vectores, como cuando nos reemplaza d·(u(x,y,z) x ν (x,y,z)) por su equivalente v·dxu - u·dxv. También se habían dado definiciones integrales del gradiente, divergencia y rotacional, haciendo estos conceptos independientes de cualquier definición de coordenadas. Así, en lugar de (14) tenemos, por ejemplo,
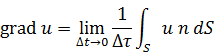
Poco después que el análisis vectorial fuera creado, surgieron muchas controversias entre los que proponían los cuaterniones y los que postulaban los vectores, a fin de decidir qué resultaba más útil. Los cuaternionistas fueron fanáticos en cuanto al valor de los cuaterniones, pero los que proponían el análisis vectorial se mostraron igualmente partidistas. En un lado estaban alineados los grandes defensores de los cuaterniones, tales como Tait; en el otro, Gibbs y Heaviside. A propósito de la controversia, Heaviside señaló sarcásticamente que para el tratamiento de los cuaterniones, los cuaterniones son el mejor instrumento. Por otro lado, Tait descubrió el álgebra vectorial de Heaviside como «un tipo de monstruo hermafrodita, compuesto por las notaciones de Grassmann y Hamilton». El libro de Gibbs demostró ser de un valor inestimable para promover la causa de los vectores.
El asunto se decidió finalmente en favor de los vectores. Los ingenieros recibieron bien el análisis vectorial de Gibbs y Heaviside, aunque los matemáticos no. Para los inicios del presente siglo, los físicos también estaban bastante convencidos de que el análisis vectorial era lo que ellos necesitaban. Los libros de texto sobre la materia aparecieron pronto en todos los países y son ahora comunes. Finalmente, los matemáticos siguieron e introdujeron los métodos vectoriales en las geometrías analítica y diferencial.
La influencia de la física en estimular la creación de entidades matemáticas tales como los cuaterniones, los hipernúmeros de Grassmann y los vectores debe considerarse importante. Estas creaciones se hicieron parte de las matemáticas. Pero su significado se extiende más allá de la adición de nuevas materias. La introducción de estas distintas cantidades abrió una nueva visión —no solamente hay una álgebra de los números reales y complejos, sino muchas álgebras diversas. Algebras lineales asociativas
6. Algebras lineales asociativas
Desde el punto de vista puramente algebraico, los cuaterniones eran atractivos, ya que proporcionaban un ejemplo de un álgebra que tenía las propiedades de los números reales y complejos excepto para la conmutatividad de la multiplicación. Durante la segunda mitad del siglo XIX, fueron explorados muchos sistemas de hipernúmeros, en parte para ver qué variedades podían crearse, y aun retener muchas propiedades de los números reales y complejos.
Cayley[543] proporcionó una generalización de ocho unidades de cuaternios reales. Sus unidades fueron 1, e1, e2,...,e7, con
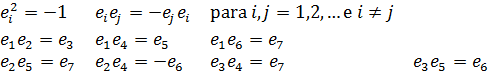
Un número general (octoniano) x está definido por
x = x0 + x1e1 + …+xqeq
donde las xi son números reales. La norma de x, N(x), es por definiciónN(x) = x02 + x12 + ... + xq2.
La norma del producto iguala el producto de las normas. La ley asociativa de la multiplicación falla en general (como lo hace la ley conmutativa de la multiplicación). Las divisiones a derecha e izquierda, excepto por cero, son siempre posibles y únicas, un hecho éste pasado por alto por Cayley y demostrado por Leonard Eugene Dickson[544] . En artículos posteriores, Cayley proporcionó otras álgebras de hipernúmeros difiriendo en algo de la anterior.Hamilton en su Lecciones sobre cuaterniones[545] introdujo también los bicuaterniones, esto es, cuaterniones con coeficientes complejos. Notó que la ley del producto no se mantiene para los bicuaterniones; esto es, dos bicuaterniones diferentes de cero pueden tener un producto igual a cero.
William Kingdom Clifford (1845-1879), profesor de matemáticas y mecánica del University College de Londres, creó otro tipo de hipernúmeros[546], que también llamó bicuaterniones. Si q y Q son cuaterniones reales, si w es tal que w2 = 1, y si w conmuta con todo cuaternión real, entonces q + wQ es un bicuaternión. Los bicuaterniones de Clifford satisfacen la ley del producto de la multiplicación, pero la multiplicación no es asociativa. En su trabajo posterior, Clifford introdujo las álgebras que llevan su nombre. Hay álgebras de Clifford con unidades 1, e1,...,en-1 tales que el cuadrado de cada ei = -1 y eiej = ejeipara i ≠ j. Cada producto de dos o más unidades es una nueva unidad y por lo mismo hay 2n unidades diferentes. Todos los productos son asociativos. Una forma es un escalar multiplicado por una unidad y un álgebra es generada por la suma y el producto de las formas.
El flujo de nuevos sistemas de hipernúmeros continuó surgiendo y la variedad se hizo enorme. En un ensayo, «Linear Associative Algebra» («Algebra Lineal Asociativa») leído en 1870 y publicado en forma litográfica en 1871[547] , Benjamín Peirce (1809-1880), profesor de matemáticas en la universidad de Harvard, definió y proporcionó un resumen de las álgebras lineales asociativas ya conocidas en sus días. La palabra lineal significa que el producto de dos unidades primarias cualesquiera es reducido a una de las unidades como cuando i multiplicado por j se reemplaza por k en los cuaterniones y la palabra asociativa significa que la multiplicación es asociativa. La adición en estas álgebras tiene las propiedades comunes de los números reales y complejos. En este ensayo, Peirce introdujo la idea de un elemento nilpotente, esto es, un elemento A tal que An = 0 para algún entero positivo n, y un elemento idempotente, esto es, An = 1 para algún n. También demostró que un álgebra donde al menos un elemento no es nilpotente posee un elemento idempotente.
La cuestión de por qué se concedía tanta libertad con tal variedad de tales álgebras también se les había ocurrido a los matemáticos durante el mismo período en que estaban creando álgebras específicas. Gauss era un convencido (Werke, 2, 178) de que una extensión de los números complejos que conservara las propiedades básicas de los números complejos resultaba imposible. Es significativo que cuando Hamilton buscó un álgebra tridimensional para representar los vectores en el espacio, conformándose con los cuaterniones carentes de conmutatividad, no pudo probar que no había un álgebra conmutativa tridimensional. Tampoco Grassmann tenía tal prueba.
Más tarde se formularon los teoremas precisos. En 1878 F. Georg Frobenius (1849-1917)[548] demostró que las únicas álgebras lineales asociativas con coeficientes reales (de las unidades primarias), con un número finito de unidades primarias, un elemento unidad para la multiplicación, y obedeciendo las leyes del producto son las de los números reales, los números complejos y los cuaterniones reales. El teorema lo demostró independientemente Charles Sanders Peirce (1839-1914) en un apéndice al artículo de su padre[549]. Otro resultado importante, al que Weierstrass había llegado en 1861, establece que las únicas álgebras lineales asociativas con coeficientes reales o complejos (de las unidades primarias), con un número finito de unidades primarias, obedeciendo la ley del producto y con multiplicación conmutativa, son las de los números reales y complejos. Dedekind obtuvo el mismo resultado alrededor de 1870. El resultado de Weierstrass fue publicado en 1884[550] y el de Dedekind el año siguiente[551].
En 1898, Adolf Hurwitz (1859-1919)[552] demostró que los números reales, los números complejos, los cuaterniones reales y los bicuaterniones de Clifford son las únicas álgebras lineales asociativas que cumplen la ley del producto.
Estos teoremas son valiosos porque nos dicen lo que podemos esperar en las extensiones del sistema de los números complejos si deseamos conservar al menos algunas de sus propiedades algebraicas.
Si Hamilton hubiera conocido estos teoremas, se habría evitado años de labor en su búsqueda de un álgebra tridimensional vectorial.
El estudio de las álgebras lineales con un número finito, y aun infinito, de unidades generadoras (primarias) y con o sin división continuó siendo una materia activa bien entrado el siglo XX. Autores como Leonard Eugene Dickson y J. H. M. Wedderburn contribuyeron mucho a la teoría.
Bibliografía
- Clifford, W. K.: Collected Mathematical Papers (1882), Chelsea (reimpresión), 1968.
- Collins, Joseph V.: «An elementaiy exposition of Grassmann’s Ausdehnungslehre», Amer. Maíh. Month. 6, 1899, varias partes, y 7, 1900, varias partes.
- Coolidge, Julián L.: + History of geometrical methods, Dover (reimpresión),
- 1963, pp. 252-264.
- Crowe, Michael J.: A History of vector analysis, University of Notre Dame Press, 1967.
- Dickson, Leonard E.: Linear Algebras, Cambridge University Press, 1914.
- Gibbs, Josiah, W. y Wilson, E. B.: Vector analysis (1901). Dover (reimpresión), 1960.
- Grassmann, H. G.: Die linéale Ausdehnungslehre (1844), Chelsea (reimpresión), 1969. : Gesammelte matbematische und physikaliscbe Werke, 3 vols., B. G. Teubner, 1894-1911; vol. 1, Parte I, 1-319 contiene Die linéale Ausdehnungslehre; vol. 1, Parte II, 1-383 contiene Die Ausdehnungslehre.
- Graves, R. P.: Life of Sir William Rowan Hamilton, 3 vols., Longmans Green, 1882-1889.
- Hamilton, sir William R.: Elements of quatemions, 2 vols., 1866, 2.a ed., 1899-1901, Chelsea (reimpresión), 1969. : Mathematical papers, Cambridge University Press, 1967, vol. 3. : «Papers in memoiy of Sir William R. Hamilton», Scripta Math., 1945; also in Scripta Math., 10, 1944, 9-80.
- Heaviside, Oliver: Electromagnetic theory, Dover (reimpresión), 1950, vol. 1.
- Klein, Félix: Vorlesungen über die Entwicklung der Mathematik im 19. Jahrhundert, Chelsea (reimpresión), 1950, vol. 1, pp. 167-191; vol. 2, pp. 2-12.
- Maxwell, James Clerk: The Scientific Papers, 2 vols., Dover (reimpresión), 1965.
- Peacock, George: «Report on the recent progress and present State of certain branches of analysis», British Assn. for Advancement of Science Report for 1833, Londres, 1834. : A treatise on algebra, 2 vols., 2.a ed., Cambridge University Press, 1845; Scripta Mathematica (reimpresión), 1940.
- Shaw, lames B.: Synopsis of linear associative algebra, Carnegie Institution of Washington, 1907.
- Smith, David Eugene: A source book in maíhematics, Dover (reimpresión), 1959, vol. 2, pp. 677-696.
- Study, E.: «Theorie der gemeinen und hóheren complexen Grössen», Encyk. der Math. Wiss., B. G. Teubner, 1898, I, 147-183.
Capítulo 33
Determinantes y matrices
1. Introducción
2. Algunos nuevos usos de los determinantes
3. Los determinantes y las formas cuadráticas
4. Matrices
Bibliografía
Tanta es la ventaja de un lenguaje bien construido que su notación simplificada a menudo se convierte en fuente de teorías profundas.
P. S. Laplace
Los determinantes y matrices fueron objeto, durante el siglo XIX, de gran atención, que produjo miles de artículos y, sin embargo, no constituyeron una gran innovación en matemáticas. El concepto de vector, que desde el punto de vista matemático no es más que una colección de tripletas ordenadas, tiene un significado físico directo como una fuerza o una velocidad, y con esto se describe matemáticamente de inmediato lo que la física dice. Lo mismo se aplica con igual fuerza al gradiente, la divergencia y el rotacional. De esta forma, aunque matemáticamente dy/dx es sólo un símbolo para una expresión larga con el límite de Δy/Δx, la derivada es en sí misma un concepto poderoso que nos permite pensar directa y creativamente acerca de sucesos físicos. Así, aunque las matemáticas superficialmente consideradas no son más que un lenguaje o una abreviación, sus conceptos más vitales son aquellos que proporcionan claves para nuevas esferas del pensamiento. En contraste, los determinantes y las matrices representan únicamente innovaciones del lenguaje. Son expresiones estenográficas para ideas que ya existen en una forma más complicada. Por sí mismas no dicen directamente algo que no esté ya dicho por las ecuaciones o transformaciones, aunque en formas mucho más amplias. Ni los determinantes ni las matrices han influido profundamente el curso de las matemáticas a pesar de su utilidad como expresiones compactas y de lo sugestivo de las matrices como expresiones compactas para la discusión de los teoremas generales de la teoría de grupos. Sin embargo, ambos conceptos han demostrado ser herramientas altamente útiles y son hoy día parte del aparato de las matemáticas.
2. Algunos nuevos usos de los determinantes
Los determinantes surgieron en la solución de sistemas de ecuaciones lineales (cap. 25, sec. 3). Este problema y la teoría de la eliminación, la transformación de coordenadas, el cambio de variables en las integrales múltiples, la solución de los sistemas de ecuaciones diferenciales que surgen en el movimiento planetario, la reducción de las formas cuadráticas en tres o más variables y los haces de formas (un haz es el conjunto A + λB, donde A y B son formas específicas y A es un parámetro) a formas canónicas, todos dieron lugar a varios tipos nuevos de determinantes. Este trabajo del siglo XIX se siguió directamente del trabajo de Cramer, Bezout, Vandermonde, Lagrange y Laplace.
La palabra determinante, usada por Gauss para el discriminante de la forma cuadrática ax + 2bxy + cy2, la aplicó Cauchy a los determinantes que ya habían aparecido en los trabajos del siglo XVIII. La disposición de los elementos en cuadrado y la notación de subíndices dobles también se le deben a él[553]. Así, un determinante de tercer orden se escribe como (las líneas verticales fueron introducidas por Cayley en 1841)
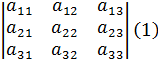
![]()
![]()
Heinrich F. Scherk (1798-1885), en su Mathematische Abhandlungen(Disertación Matemática, 1825), aportó varias nuevas propiedades de los determinantes. Formuló las reglas para la adición de dos determinantes que tienen una columna o fila en común y para la multiplicación de un determinante por una constante. Asimismo, estableció que el determinante de un cuadro que tiene como fila una combinación de dos o más filas es cero, y que el valor de un determinante triangular (todos los elementos superiores o inferiores de la diagonal principal son cero) es el producto de los elementos sobre la diagonal principal.
James Joseph Sylvester (1814-1897) se distinguió como uno de los estudiosos empeñados, por un período de cincuenta años, en la teoría de determinantes. Después de ganar el segundo Wrangler en los exámenes matemáticos (tripos), por ser judío se le impidió enseñar matemáticas en la universidad de Cambridge. De 1841 a 1845 fue profesor de la universidad de Virginia. Más adelante regresó a Londres y trabajó como actuario y abogado en 1845 a 1855. Se le ofreció la posición relativamente baja de profesor en una academia militar en Woolwich (Inglaterra) y en ella estuvo hasta 1871. Algunos años de actividades misceláneas fueron seguidos por su nombramiento de profesor en la universidad Johns Hopkins, donde, empezando en 1876, impartió cátedra en teoría de invariantes. Inició la investigación en matemáticas puras en los Estados Unidos y fundó el American Journal of Mathematics. En 1884 regresó a Inglaterra, y a la edad de setenta años se convirtió en profesor de la universidad de Oxford, posición que mantuvo hasta su muerte.
Sylvester fue una persona vivaz, sensible, estimulante, apasionada, y aun excitable. Sus discursos eran brillantes y ocurrentes y presentaba sus ideas con gran fogosidad y entusiasmo. En sus artículos utilizaba un lenguaje brillante. Introdujo mucha terminología nueva y bromeaba comparándose a sí mismo con Adán, quien había dado los nombres a las bestias y las plantas. Aunque él relacionó muchos campos diversos, tales como la mecánica y la teoría de los invariantes, no se prestaba a trabajar en teorías de una manera sistemática y detallada. De hecho, frecuentemente publicaba conjeturas, y aunque muchas de éstas eran brillantes otras eran incorrectas. Lamentándose, reconocía que sus amigos del continente «cumplimentaban sus poderes de adivinación a costa de su juicio». Sus principales contribuciones versaron sobre ideas combinatorias y abstracciones a partir de desarrollos más concretos.
Uno de los logros más importantes de Sylvester fue un método mejorado para eliminar las x de los polinomios de grado n-ésimo y m-ésimo, al cual llamó método dialítico[556]. Así, para eliminar x de las ecuaciones
a0x3 + a1x2 + a2x + a3, = 0
b0x2 + b1x + b2 = 0
formó el determinante de quinto orden
La fórmula para la derivada de un determinante cuando los elementos son funciones de t fue dada por Jacobi en 1841[558]. Si las aijson funciones de i, Aij es el menor complementario de aij, y D es el determinante entonces
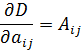
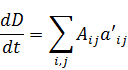
Los determinantes fueron empleados en otro contexto, a saber, en el cambio de variables de una integral múltiple. Jacobi (1832 y1833) encontró primero los resultados particulares. Más adelante, Eugene Charles Catalan (1814-1894), en 1839[559], proporcionó el resultado que hoy en día es familiar a los estudiantes de cálculo. De ese modo, la integral doble
![]()
![]()
![]()
Jacobi dedicó un ensayo importante[560] a los determinantes funcionales. En este artículo considera n funciones u1,...,un cada una de las cuales es una función de x1, x2,...xn y formula la cuestión de cuándo, de tales n funciones, pueden ser eliminadas las xi de tal manera que las ui estén relacionadas por una ecuación. Si esto no es posible, se dice que las funciones ui son independientes. La respuesta es que si el jacobiano de las ui con respecto a las xi se anula, las funciones no son independientes e inversamente. También aporta el teorema del producto para jacobianos. Esto es, si las ui son funciones de las yiy las yi son funciones de las xi, entonces el jacobiano de las ui con respecto a las xi es el producto del jacobiano de las ui con respecto a las yiy el jacobiano de las yi con respecto a las xi.
3. Los determinantes y las formas cuadráticas
En el siglo XVIII ya se había introducido el método para resolver el problema de transformar las ecuaciones de las secciones cónicas y superficies cuádricas a formas más simples mediante la selección de ejes coordenados que tienen las direcciones de los ejes principales. La clasificación de las superficies cuádricas en términos de los signos de los términos de segundo grado cuando la ecuación se encuentra en forma canónica, esto es, cuando los ejes principales son los ejes coordenados, la aportó Cauchy en su Leçons sur les applications du calcul infinitésimal á la géométrie (Lecciones sobre las aplicaciones del cálculo infinitesimal a la geometría, 1826)[561]. Sin embargo, no estaba claro que resulte siempre el mismo número de términos positivos y negativos en la reducción a la forma canónica. Sylvester contestó esta pregunta con su ley de inercia de formas cuadráticas en n variables[562]. Ya se sabía que
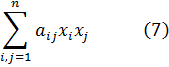
y12+ … + ys2 - ys2 - … - yr-22 (8)
mediante una transformación real lineal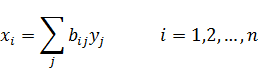
La ley fue redescubierta y probada por Jacobi[564]. Si una forma es positiva o cero para todos los valores reales de las variables, se la llama definida positiva. Entonces todos los signos de (8) son positivos, y r = n. Es llamada semidefinida si puede tomar valores positivos o negativos (en cuyo caso r < n), y definida negativa cuando la forma es siempre negativa o cero (y r = n). Estos términos los introdujo Gauss en su Disquisitiones Arithmeticae (sec. 271).
El estudio posterior de la reducción de formas cuadráticas supone la noción de ecuación característica de una forma cuadrática o de un determinante. Una forma cuadrática en tres variables se escribía, comúnmente, durante el siglo XVIII y la primera parte del XIX, como
Ax2 + By2 + Cz2 + 2 Dxy + 2 Exz + 2 Fyz
y en tiempos más recientes comoa11x12 + a22x22 + a33x32 + 2a12x1x2 + 2a13x1x3 + 2a22x2x3 (9)
En la última notación la forma era asociada con el determinante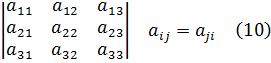
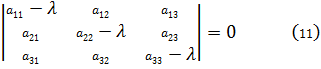
La noción de ecuación característica aparece implícitamente en el trabajo de Euler[566] sobre la reducción de las formas cuadráticas en tres variables a sus ejes principales, aunque haya fallado en probar la «realidad» de las raíces características. La noción de ecuación característica aparece explícitamente en el trabajo de Lagrange sobre sistemas de ecuaciones diferenciales lineales[567], y en el trabajo de Laplace en la misma área[568].
Lagrange, al tratar con el sistema de ecuaciones diferenciales para el movimiento de seis planetas en su época, estaba interesado en las perturbaciones seculares (de largos períodos) que estos éstos ejercían sobre los otros. Su ecuación característica (también llamada ecuación secular) era para un determinante de orden seis y los valores de A determinaban soluciones del sistema. Fue capaz de descomponer la ecuación de sexto grado y obtener información acerca de las raíces. Laplace demostró en su Mécanique céleste que si todos los planetas se mueven en la misma dirección, entonces las seis raíces características son reales y distintas. La «realidad» de los valores característicos para el problema cuadrático en tres variables fue establecido por Hachette, Monge y Poisson[569].
Cauchy reconoció el problema del valor característico común en la obra de Euler, Lagrange y Laplace. En sus Leçons de 1826[570] tomó el problema de la reducción de la forma cuadrática en tres variables y demostró que la ecuación característica es invariante para cualquier cambio de los ejes rectangulares. Tres años más tarde, en sus Exercices de mathématiques (Ejercicios de matemáticas)[571], atacó el problema de las desigualdades seculares de las trayectorias planetarias. En el transcurso de su trabajo demostró que dos formas cuadráticas en n variables

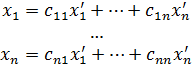
Su trabajo se reduce a lo siguiente: si A y B son dos formas cuadráticas cualesquiera dadas, entonces se puede considerar la familia (Schaar) de formas uA + vB, donde u y v son parámetros arbitrarios. Las raíces latentes de la familia son los valores de la proporción -u/v para los que el determinante de la familia |uaij + vbij| es cero. Cauchy demostró que las raíces latentes son todas reales en el caso especial de que una de las formas es definida positiva para todos los valores de las variables reales distintos de cero. Ya que el determinante de uA + vB es simétrico (dij = dji) y B podía ser el determinante identidad (bij = 0 para toda i ≠ j y bü =1), Cauchy demostró que cualquier determinante simétrico real de cualquier orden tiene raíces características reales. Los resultados de Cauchy, duplicados por los de Jacobi en 1834[572], excluían la raíces latentes iguales. El término ecuación característica se debe a Cauchy[573].
La noción de determinantes semejantes también surgió del trabajo sobre transformaciones. Dos determinantes A y B son semejantes si existe un determinante P distinto de cero tal que A = P-1BP. Las transformaciones semejantes fueron consideradas por Cauchy, quien mostró en sus Leçons de 1826[574] que tienen los mismos valores característicos. La importancia de las transformaciones semejantes radica en clasificar transformaciones proyectivas (cap. 38, sec. 5), un problema que por largo tiempo fue tratado sintéticamente. Si una figura F es relacionada con una figura G por una transformación lineal A y si otra transformación B transforma F en F' y G en G', la transformación C que lleva F en G' tendrá las mismas propiedades que A. La transformación es C = BAB-1 ya que B-1 lleva F' en F, A lleva F en G, y B lleva G en G'.
En 1858, Weierstrass[575] proporcionó un método general para reducir dos formas cuadráticas simultáneamente a sumas de cuadrados. También probó que si una de las formas es definida positiva, la reducción es posible aun cuando algunas de las raíces latentes sean iguales. El interés de Weierstrass en este problema surgió de un problema dinámico de pequeñas oscilaciones cerca de una posición de equilibrio, y demostró, por medio de su trabajo sobre formas cuadráticas, que la estabilidad no es destruida por la presencia de períodos iguales en el sistema, contrariamente a las suposiciones de Lagrange y Laplace.
En 1851[576], Sylvester, trabajando en el contacto y la intersección de curvas y superficies de segundo grado, fue llevado a considerar la clasificación de familias de tales cónicas y superficies cuadráticas. En particular, buscó la forma canónica de cualquier familia. Escribiendo una familia en la forma A + λB donde
A = ax2 + by2 + cz2 + 2dyz + 2ezx + 2fxy
B = Ax2 + By2 + Cz2 + 2Dyz + 2Ezx + 3Fxy
consideró el determinante
Weierstrass[577] completó la teoría de las formas cuadráticas y extendió la teoría de las formas bilineales; una forma bilineal es
a11x1y1 + a12x1y2 +…+ annxnyn
Usando la notación de los divisores elementales de Sylvester, Weierstrass obtuvo la forma canónica de la familia A + λB, donde A y B no son necesariamente simétricas, pero sí sujetas a la condición de que |A + λB| no es idénticamente cero. Además, demostró el inverso de un teorema debido a Sylvester. El inverso establece que si el determinante de A + λB coincide en sus divisores elementales con el determinante de A' + λB', entonces se puede encontrar un par de transformaciones lineales que transforman simultáneamente A en A' y B en B'.Entre la multitud de teoremas sobre determinantes están los que se dedican a la solución de m ecuaciones lineales en n incógnitas,
Henry J. S. Smith (1826-1883)[578] introdujo los términos menor aumentado (o ampliado) y no ampliado para discutir la existencia y número de soluciones de, por ejemplo, un sistema como
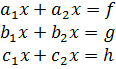
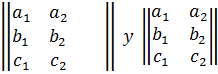
Se obtuvieron nuevos resultados sobre determinantes a lo largo del siglo XIX. Como una ilustración tenemos un teorema demostrado por Hadamard en 1893[579], aunque conocido y demostrado por muchos otros antes y después de esta fecha. Si los elementos del determínate D = |dij| satisfacen la condición de que |dij ≤ A entonces
|D| ≤ An · nn/2
Los teoremas anteriores sobre determinantes sólo representan un pequeño ejemplo de la multitud de los que han sido establecidos. Además de una gran variedad de otros teoremas sobre determinantes generales, hay cientos de otros sobre determinantes de formas especiales tales como los determinantes simétricos (aij = aij), determinantes antisimétricos aij = -aij), ortogonantes (determinantes de transformaciones coordenadas ortogonales), determinantes orlados (determinantes extendidos por la adición de filas y columnas), determinantes compuestos (los elementos son determinantes ellos mismos), y muchos otros tipos especiales.4. Matrices
Diríamos que el campo de las matrices estuvo bien desarrollado aun antes de crearse. Los determinantes, como sabemos, fueron estudiados a partir de mediados del siglo XVIII. Un determinante contiene un cuadro de números y por lo general interesa el valor del cuadro, dado por la definición del determinante. Parecía deducirse de la inmensa cantidad de trabajo sobre los determinantes que el cuadro podía ser estudiado en sí mismo y manipulado para muchos propósitos, fuera o no el valor del determinante lo interesante. Quedaba por reconocerse que al cuadro como tal se le podía proporcionar una identidad independiente de la del determinante. El cuadro por sí mismo es llamado matriz. La palabra matriz fue usada por primera vez por Sylvester[580] cuando en realidad deseaba referirse a un cuadro rectangular de números y no podía usar la palabra determinante, aunque en aquella ocasión sólo le interesaban los determinantes que podía formar a partir de los elementos del cuadro rectangular. Más tarde, como ya hemos hecho notar en la sección precedente, los cuadros ampliados se emplearon con libertad sin hacer mención alguna de las matrices. Las propiedades básicas de las matrices, como veremos, fueron también establecidas en el desarrollo de los determinantes.
Es cierto, como dice Arthur Cayley (en el artículo de 1855 al que nos referiremos más abajo), que lógicamente la idea de matriz precede a la de determinante, pero históricamente el orden fue el inverso y esto se debe a que las propiedades básicas de las matrices ya estaban claras cuando fueron introducidas las matrices. Así, la impresión general entre los matemáticos referente a que las matrices representaban una creación altamente original e independiente inventada por los matemáticos puros cuando adivinaron la utilidad potencial de la idea es erróneo. Porque el empleo de las matrices estaba bien establecido se le ocurrió a Cayley introducirlas como entidades diferentes. Dice: «ciertamente no obtuve la noción de matriz de alguna manera a partir de los cuaterniones; fue directamente de la de determinante o como una forma conveniente de expresar las ecuaciones:
x' = ax + by
y' = cx + dy.
Y así introdujo la matriz![]()
Cayley, nacido en 1821, de una antigua y talentosa familia inglesa, mostró habilidad matemática en la escuela. Sus profesores convencieron a su padre para enviarlo a Cambridge, en vez de ponerlo en los negocios de la familia. En Cambridge fue el decano de los «wrangler» en los exámenes de matemáticas (tripos) y ganó el premio Smith. Lo seleccionaron como un Fellow del Trinity College en Cambridge y tutor asistente, pero después de tres años la abandonó porque deseaba tomar las órdenes sagradas. Volvió a las leyes y dedicó los quince años siguientes a esa profesión. Durante este período fue capaz de emplear un tiempo considerable en las matemáticas y publicó cerca de 200 artículos. Y durante este período empezó también su larga amistad, y colaboración, con Sylvester.
En 1863 obtiene el nombramiento para la recién creada cátedra Sadleriana de matemáticas en Cambridge. Excepto por el año 1882, en que estuvo en la universidad Johns Hopkins como invitado de Sylvester, permaneció en Cambridge hasta su muerte, acaecida en 1895. Fue un escritor muy prolífico y creador de varias áreas: la geometría analítica de n dimensiones, la teoría de los determinantes, transformaciones lineales, superficies alabeadas y teoría de matrices. Junto con Sylvester, fundó la teoría de invariantes. Por estas contribuciones tan numerosas recibió muchos honores.
Contrariamente a Sylvester, Cayley fue un hombre de temperamento equilibrado, juicio sobrio y serenidad, generoso en ayudar y apoyar a otros. Además de su trabajo excelente en el derecho y prodigiosos logros en matemáticas, encontró tiempo para su interés en la literatura, pintura, arquitectura y viajes.
Fue en relación con el estudio de los invariantes bajo transformaciones lineales (cap. 39, sec. 2) como Cayley introdujo por primera vez las matrices para simplificar la notación[581]. Aquí proporcionó algunas nociones básicas. Esto fue seguido por su principal contribución a la materia, «A memoir on the theory of matrices» («Una memoria sobre la teoría de las matrices»)[582].
Por brevedad daremos las definiciones de Cayley para matrices 2 por 2 y 3 por 3, a pesar de que las definiciones son válidas para matrices n por n y en algunos casos para matrices rectangulares. Dos matrices son iguales si sus elementos correspondientes son iguales. Cayley define la matriz cero y la matriz unidad como
Cayley toma directamente de la representación del efecto de dos transformaciones sucesivas la definición de multiplicación de dos matrices. Así, si la transformación
x' = a11x + a12y
y' = a21x + a22y
es seguida por la transformaciónx" = b11x' + b12y'
y" = b21x' + b12y'
entonces la relación entre x", y"y x, y está dada porx" = (b11a11 + b12a21)x + (b11a12 + b12a22)y
y" = (b21a11 + b22a21)x + (b21a12 + b12a22)y
De aquí Cayley definió el producto de las matrices como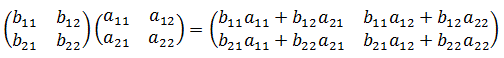
En este mismo artículo, establece que el inverso de
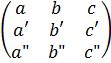
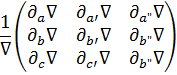
Cuando d = 0, la matriz es indeterminada (en terminología moderna, singular) y no tiene inversa. Cayley aseguró que el producto de dos matrices puede ser cero sin ser alguna de ellas necesariamente cero, si cualquiera de ellas es indeterminada. En realidad, Cayley estaba equivocado, han de ser indeterminadas las dos. Porque si AB = 0, A ≠ 0, B ≠ 0 y sólo A es indeterminada, entonces la inversa B-1 de B existe, y ABB-1 = 0. B-1 = 0. Pero BB-1 = I. Por tanto, AI = 0 y A = 0.
La matriz transversa (traspuesta o conjugada) se define como aquella obtenida cambiando filas y columnas. Se argumenta (sin prueba) que (LMN)' = N'M'L' donde la prima denota traspuesta. Si M' = M entonces M se llama simétrica, y si M’ = -M entonces M es antisimétrica (o alternada). Cualquier matriz puede ser expresada como la suma de una matriz simétrica y una antisimétrica.
Otro concepto tomado de la teoría de determinantes es la ecuación característica de una matriz cuadrada. Para la matriz M está definida como
|M - xI| = 0,
donde |M - xI| es el determinante de la matriz M — xI e I es la matriz unitaria. Así si![]()
x2 - (a + d)x + ad - be = 0 (13)
Las raíces de esta ecuación son las raíces características (valores propios) de la matriz.En el artículo de 1858, Cayley anunció lo que ahora es conocido como el teorema de Cayley-Hamilton para matrices cuadradas de cualquier orden. El teorema dice que si x es sustituida por M en (13), la matriz resultante es la matriz cero. Cayley afirma que él ha verificado este teorema para el caso de 3 por 3 y que no se requiere más prueba. La asociación de Hamilton con este teorema se apoya en el hecho de que al introducir en sus Lecciones sobre cuaternios[583] la noción de una función vectorial lineal r' de otro vector r, aparece una transformación lineal de x,y y z en x', y' y z'. Demostró que la matriz de esta transformación satisface la ecuación característica de esa matriz, aunque no pensó formalmente en términos de matrices.
Otros matemáticos encontraron propiedades particulares de las raíces características de algunas clases de matrices. Hermite[584], demostró que si la matriz M = M*, donde M* es la traspuesta de la matriz formada al reemplazar cada elemento de M por su conjugado complejo (tales M son llamadas ahora hermitianas), entonces las raíces características son reales. En 1861, Clebsch[585] dedujo del teorema de Hermite que las raíces características diferentes de cero de una matriz antisimétrica real son imaginarias puras. Luego Arthur Buchheim[586] (1859-1888), demostró que si M es simétrica y si los elementos son reales, las raíces características son reales, aunque este resultado ya había sido establecido para los determinantes por Cauchy[587]. Henty Taber (1860-?), en otro ensayo[588], afirmó como evidente que si
xn - m1xn-1 + m2xn-2 - ... ± mn = 0
es la ecuación característica de cualquier matriz cuadrada M, entonces el determinante M es mn, y si entendemos por menor principal de una matriz el determinante de un menor cuya diagonal es parte de la diagonal principal de M, entonces mi es la suma de los i menores principales. En particular, entonces, mu que es también la suma de las raíces características, es la suma de los elementos de la diagonal principal. Esta suma es llamada traza de la matriz. Las demostraciones de las afirmaciones de Taber fueron proporcionadas por William Henry Metzler (1863-?)[589].Frobenius[590] formuló una pregunta relacionada con la ecuación característica. Buscó el polinomio mínimo —el polinomio de menor grado— que satisface la matriz. Estableció que es el formado a partir de los factores del polinomio característico y es único. No fue hasta 1904[591] cuando Kurt Hensel (1861-1941) demostró la unicidad de la afirmación de Frobenius. En el mismo artículo, Hensel también demostró que si f(x) es un polinomio mínimo de una matriz M yg(x) es cualquier otro polinomio satisfecho por M, entonces f(x) divide a g(x).
Frobenius[592] introdujo la noción de rango de una matriz en 1879, aunque en relación con los determinantes. Una matriz A con m filas y n columnas (de orden m por n) tiene menores con k filas de todos los órdenes desde 1 (los elementos de A mismos) hasta el menor de los dos enteros m y n inclusive. Una matriz tiene rango r si y solamente si tiene al menos un menor de orden r cuyo determinante no es cero mientras que los determinantes de todos los menores de orden superior a r son cero.
Dos matrices A y B pueden ser relacionadas de diversas maneras. Son equivalentes si existen dos matrices no singulares U y V tales que A = UBV. Sylvester había demostrado en su trabajo sobre determinantes[593] que el máximo común divisor d11 de los menores con i filas de B es igual al máximo común divisor di de los menores con i filas de A. Entonces H. J. S. Smith, trabajando con matrices con elementos enteros, demostró[594] que cada matriz A de rango p es equivalente a una matriz diagonal con elementos h1 h2,...,hp debajo de la diagonal principal y tal que bi divide a hi + 1. Los cocientes ht = d1, h2 = d2/d1,... son llamados los factores invariantes de A. Además, si
![]()
Estas ideas sobre factores invariantes y divisores elementales, que surgen del trabajo de Sylvester y Weierstrass sobre determinantes (como se señaló anteriormente), fueron trasladadas a las matrices por Frobenius en su ensayo de 1878. El significado de estos factores invariantes y divisores elementales para matrices es que la matriz A es equivalente a la matriz B si y solamente si A y B tienen los mismos divisores elementales o factores invariantes.
Frobenius realizó más trabajo con los factores invariantes en su artículo de 1878 y organizó la teoría de los factores invariantes y divisores elementales en forma lógica[595]. El trabajo en el artículo de 1878 le permitió a Frobenius dar la primera demostración general del teorema de Cayley-Hamilton y modificar el teorema cuando algunas de las raíces latentes (raíces características) de la matriz son iguales. En este ensayo demostró que cuando AB-1 = B-1A, en cuyo caso existe un cociente bien definido A/B, entonces (A/B)-1 = B/A y que (A-1)T = (AT)-1 donde AT es la traspuesta de A.
Las matrices ortogonales han recibido considerable atención. Aunque el término haya sido usado por Hermite en 1854[596], la definición formal no es publicada hasta 1878 por Frobenius (véase referencia anterior). Una matriz M es ortogonal si es igual a la inversa de la traspuesta, esto es, si M = (MT)-1. Además de la definición, Frobenius demostró que si S es una matriz simétrica y T una matriz antisimétrica, una matriz ortogonal puede ser escrita en la forma (S — T)/(S + T) o más simplemente (I - T)/(I + T).
La noción de matrices semejantes, como muchos otros conceptos de la teoría de matrices, vino del trabajo anterior sobre determinantes, tan alejado en el tiempo como el de Cauchy. Dos matrices cuadradas A y B son semejantes si existe una matriz no singular P tal que B = P-1AP. Las ecuaciones características de dos matrices semejantes A y B son la misma y las matrices tienen los mismos factores invariantes y los mismos divisores elementales. Para matrices con elementos complejos, Weierstrass demostró este resultado en su ensayo de 1868 (aunque él trabajó con determinantes). Ya que una matriz representa una transformación lineal homogénea, matrices similares pueden ser pensadas como si representaran la misma transformación pero referidas a dos sistemas coordenados diferentes.
Usando el concepto de matrices similares y de ecuación característica, Jordán[597] demostró que una matriz puede ser transformada a una forma canónica. Si la ecuación característica de una matriz J es
f(λ) = λn + b1λn-1 + ... + bn = 0
y sif(λ) = (λ - λ1)l1... (λ - λk)lk
donde las λi son diferentes, entonces sea
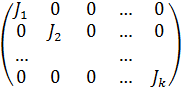
Frobenius también trató, en su ensayo de 1878, la transformación de semejanza de A en B, bajo el nombre de transformaciones contragredientes. En la misma discusión trató la noción de matrices congruentes o transformaciones cogredientes. Esto nos dice que si A = PTBP entonces A es congruente con B, escrito A = B. Por ejemplo, la transformación de la matriz A que resulta del intercambio simultáneo de las mismas filas y columnas de A es una transformación congruente. De igual manera, una matriz simétrica A de rango r puede ser reducida por medio de una transformación congruente a una matriz diagonal del mismo rango, esto es:
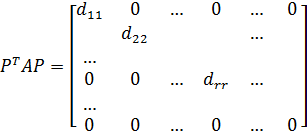
En su artículo de 1892 del American Journal of Mathematics, Metzler introdujo las funciones trascendentes de una matriz, escribiendo cada una como una serie de potencias de una matriz. Dio las series para eM, e-M, log M, sen M y sen-1M. Así
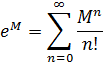
Tanto los determinantes como las matrices han sido extendidos al caso de orden infinito. Los determinantes infinitos estaban involucrados en el trabajo de Fourier para la determinación de los coeficientes de una serie de Fourier de una función (cap. 28, sec. 2) y en el trabajo de Hill sobre la solución de ecuaciones diferenciales ordinarias (cap. 29, sec. 7). Artículos aislados sobre determinantes infinitos se escribieron entre estos dos grandes investigadores del siglo XIX, pero la mayor actividad es posterior a Hill.
Las matrices infinitas estaban incluidas implícita y explícitamente en el trabajo de Fourier, Hill y Poincaré, quien completó el trabajo de Hill. Sin embargo, el gran impulso aplicado al estudio de las matrices infinitas vino de la teoría de las ecuaciones integrales, (cap. 45). No podemos dedicar aquí espacio a la teoría de los determinantes y matrices de orden infinito[598].
En el trabajo básico sobre matrices, los elementos son números reales ordinarios aunque una gran parte de lo que se ha hecho en nombre de la teoría de números estaba circunscrito a elementos enteros. Sin embargo, éstos pueden ser números complejos y, por supuesto, casi cualquier otra cantidad. Naturalmente, las propiedades que las matrices poseen dependen de las propiedades de los elementos. Espacio significativo de la investigación de la última parte del siglo XIX y el inicio del XX se dedica a las propiedades de las matrices cuyos elementos están en un cuerpo abstracto. La importancia de la teoría de matrices en el instrumental del XIX de la física moderna no puede ser tratada aquí, pero en relación con ello es de interés un argumento profético hecho por Tait: «Cayley está forjando las armas para las futuras generaciones de físicos».
Bibliografía
- Bernkopf, Michael: «A history of infinite matrices», Archive for History of Exact Sciences, 4, 1968, 308-358.
- Cayley, Arthur: The collecíed mathematicalpapers, 13 vols., Cambridge University Press (1889-1897), Johnson Reprint Corp., 1963.
- Feldman, Richard W., Jr.: (Seis artículos sobre matrices con diversos títulos). The Mathematics Teacher, 55, 1962, 482-484, 589-590, 657-659; 56, 1963, 37-38, 101-102, 163-164.
- Frobenius, F. G.: Gesammelte Ahhandlungen, 3 vols., Springer-Verlag, 1968. Jacobi, C. G. J.: Gesammelte Werke, Georg Reimer, 1884, vol. 3. MacDuffee, C. C.: The Theory of Matrices, Chelsea, 1946.
- Muir, Thomas: The theory of determinants in the historical order of development(1906-1923), 4 vols., Dover (reimpresión), 1960. : List of writings on the theory of matrices, Amer. Jour. of Math., 20, 1898, 225-228.
- Sylvester, James Joseph: The Collecíed Mathematical Papers, 4 vols., Cambridge University Press, 1904-1912.
- Weierstrass, Karl: Mathematische Werke, Mayer und Muller, 1895, vol. 2.
FIN
Parte II
Notas: